
Abstract
People will increasingly get expedited and diverse means of accessing news as societies progress. Furthermore, there is a noticeable increase in the prevalence of incorrect and misleading information. Our research is motivated by the significant concerns regarding the detrimental impacts of disinformation on the general public, political stability, and trust in the media. The scarcity of Vietnamese-language datasets can be attributed to the predominant focus of false news detection studies on datasets only in English. Detection investigations of fake news have predominantly relied on supervised machine learning algorithms, which possess notable limitations when confronted with unclassified news articles that are either authentic or untrue. The utilization of Knowledge Graphs (KG) and Graph Convolutional Networks (GCN) holds promise in addressing the constraints of supervised machine learning algorithms. To address these problems, we propose an approach that integrates KG)into the procedure for detecting fake news. We utilize the Vietnamese Fake News Detection dataset (VFND-vietnamese-fake-news), comprising authentic and deceptive news articles from reputable Vietnamese newspapers such as vnexpress, tuoitre, and have been collected from 2018 to 2023. News articles are only labeled as real or fake after experiencing independent verification. The Glove embedding (Global Vectors for Word Representation) is employed to establish a knowledge network for the given dataset. This knowledge graph’s construction is accomplished using the Word Mover’s Distance (WMD) algorithm in conjunction with the K-nearest neighbor approach; GCN approach and the input KG train models to discern between real and fake news. With labeling half of the input dataset, the experimental findings indicate a notable level of accuracy, reaching up to 85%. Our research holds significant importance in identifying fake news, particularly within the context of the Vietnamese language.
Keywords
Introduction
Accompanied by the strong development of the Internet today, the quantity of news is increasing, by various communication media, along with the amount of fake and false information. This has serious consequences, affecting faulty social life in many fields. Consequently, fake news detection problems are a topic of concern and research implemented in the recent past. Researchers in the field of fake news detection mention that this is a significant problem today. However, many current practical challenges exist, such as the quantity of news exploding. The news article needs to be cross-checked for the origin and content. Besides, we must demonstrate all relevant facts to determine whether the news article is real or fake. Nonetheless, identifying trust in any news is very difficult in most scenarios. The actual or fake news must match the specific topics of news in the real world, such as sports, culture, society, economy, law, medicine, health, etc. [1]
In the fake news prediction framework, the news articles will default to fake news as superstitious news that does not confirm the source; news based on scientifically recognized sources, knowledge, theories, and hypotheses is false. [2–4]. Our research focuses on fake news prediction by using the knowledge graph (KG) to determine whether the news is fake or real.
The fake news detection framework based on the KG approach is divided into the following stages (see Fig. 1):

Stages in fake news detection framework.
Currently, there are many drawbacks to fake news detection, such as only research done with English datasets [5] and there isn’t research done with Vietnamese datasets. Additionally, the content-based and supervised classification for fake news detection has relatively low accuracy. Moreover, these methods often require substantial labeled data, which is challenging to obtain in most real-world scenarios. Therefore, research on fake news prediction with Vietnamese data is essential. In addition, the dataset to detect fake news in Vietnam is very limited. The current fake news forecasting studies mostly use supervised learning algorithms, which has a significant limitation when the amount of information is massive, while the amount of news labeled real or fake only accounts for a small percentage. The result of supervised learning models’ accuracy is often meager [4, 6].
In addition, Graph Neural Networks (GNNs) is a group of new techniques focusing on deep learning techniques on graph-based structure [5]. Before applying GNNs to fake news methodology, GNNs had been completely implemented in different machine learning algorithms and NLP methodology, including object detection, sentiment analysis, and machine translation, with many successes. Moreover, the fast development of many GNNs has been gained by enhancing many methodologies, including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Autoencoders through deep learning algorithms. Currently, there are many different variants of GCNs in many real-world applications can be mentioned as recommendation systems, healthcare, e-commerce, traffic management, selling retail, and marketing, etc.
The utilization of a graph-based representation can enhance the identification of fake news. This representation involves depicting news items as a graph structure, wherein each article’s various components, such as words, entities, or phrases, are represented as nodes. Graph Convolutional Neural Networks (GCNNs) enable the presence of all news articles as graph structures, allowing the model to represent the complicated interactions and dependencies among these elements effectively. Besides, Graph Convolutional Neural Networks (GCNN) are qualified to efficiently catch information from both the node-level and graph level coincidentally. Node-level information encompasses the characteristics of individual pieces inside each distinct article, such as words and sentences.
On the other hand, graph-level information takes into account contextual patterns and global relationships within the graph. This enables the machine to acquire contextually informed representations, potentially enhancing the precision of fake news prediction. Graph Convolutional Neural Networks (GCNNs) have been specifically developed to exhibit strong resilience and adaptability in the face of irregularities within graphs, such as nodes with various phases or the absence of particular relations. In fake news identification, where networks exhibit dynamic and developing characteristics, Graph Convolutional Neural Networks (GCNNs) offer a versatile approach for effectively managing diverse graph structures.
Although LSTM and GRU models are adequate for analyzing sequential data, they may only partially exploit the structure information inherent in graphs, such as the interconnections between users or articles. When comparing other approaches, it is evident that GCNN effectively integrates graph structure comprehension and feature extraction functionalities inside a single model. This characteristic renders GCNN especially well-suited for detecting fake news, as it acknowledges the importance of relational information in this context.
In favor of resolving the circumstantial that labeled datasets for fake news detection in the actual world are commonly extremely limited and sparse. In this research, we propose a method using knowledge graphs and semi-supervised classification to detect news fake or real. On a high level, our approach in this paper includes many vital points, such as: Embedding all news documents in the dataset into Euclidean space. Building up a news articles similarity graph from the dataset and developing a knowledge graph. Forecasting of missing labels using semi-supervised graph learning methods.
The main contribution of our research can be summed up as follows: We are developing a Vietnamese dataset of fake news using news articles from Internet newspapers such as vnexpress, tuoitre, baomoi, etc. They are the most popular newspaper in the Vietnamese language. We combine the VFND-Vietnamese-fake-news dataset, and finally, we have a dataset with a wide variety of topics, using input for the proposed method. We are using the word embeddings method to get implicit representations of the dataset about all news in the lower-dimensional Euclidean space. After that, proceed to catch a recapitulative resemblance between news articles by a graph visualization schema. We are implementing the fake news detection subject using a semi-supervised classification method to detect whether a new document is real or fake. It uses Graph Neural Network techniques that can practice proficiently with extremely finite labeled data. We are accomplishing a general evaluation of the proposed method in our research with the real fake news dataset, representing that the proposed method has more outstanding than previous content-based approaches and requires fewer labels.
The paper is organized as follows: Section 1: Introduce a general problem that needs to be resolved, the main contribution of our research. Section 2: The literature survey of existing research on fake news detection. Section 3: Some preliminary definitions associated with the fake news detection problem. Section 4: The objectives of this research are the proposed method of fake news detection using knowledge graphs and semi-supervised learning. Section 5: Experiment and Discussion. Section 6: The conclusion and future works.
The research topic of detecting fake news has grown into an emerging subject in modern communication media. Current veracity analysis methods can be broadly classified into a couple of sections [6, 7]: utilizing news data for handling social information/context, extracting linguistic, syntactic, lexical features or visual characteristics from news documents to obtain particular features as well as exciting patterns that usually happen in fraudulent documents.
Visual features recognize fake photos intentionally created to create realism in fake news. Context-based authenticity analysis methods include the characteristics of user data on social sites and social systems [8]. The user’s social site profile estimates the user’s features and reliability. Traits derived from their social posts describe their social behavior.
Pathak et al. [9] presented detailed discussions of the characteristics of publicly available datasets for authenticity analysis techniques and compared performance with modern machine learning, deep learning, and a combination of supervised and unsupervised learning methods.
Jackie Ayoub et al. [10] proposed a method explainable natural language processing model based on DistilBERT and Shapley Additive ex Planations (SHAP) to combat misinformation about COVID-19 due to their efficiency and effectiveness on a larger dataset for AAAI2021 — COVID-19 Fake News Detection Shared Task.
S. Selva Birunda et al. [11] proposed a method using Gradient Boosting Algorithm to fake news detection on social media. A novel Score-based Multi-Source Fake News Detection framework is presented in this work to automate the detection of fake news from multiple news sources. This framework extracts the text-based features from genuine and fake news articles using the Term Frequency-Inverted Document Frequency. After that, the credibility score of the sources is calculated based on the site_url features and Top Level Domain. By assimilating the text-based elements with the credibility score of multi-source, the credibility of the news is estimated. The proposed framework is applied to the Machine Learning (ML) classifiers to examine their performance in detecting fake news.
S. Sridhar et al. [12] used Multitask Learning with a Bidirectional LSTM Capsule neural network (BiLSTM CapsNet) model to detect fake news articles. The proposed system is a Multitask Learning model that can categorize the news articles collected from the web as fake or real. The title and content of the pieces are modeled as BiLSTM subtasks, and the CapsNet model is the meta classifier.
S. Rastogi et al. [13] proposed an integrated approach to disinformation detection on social media. The authors provide a comprehensive framework adapted from several scholarly studies in this study. The framework can detect information into various types, namely fundamental, disinformation, and satire, based on authenticity and intention. The process highlights interdisciplinary approaches derived from fundamental social science theories, integrating them with modern computational tools and techniques.
The modern survey of semi-supervised and unsupervised methods in the reliability analysis of web content is detailed by Saini et al. [14].
Another research using heterogeneous Graph Neural Networks for the AAAI2021-COVID-19 English dataset to detect fake news on social networks is proposed by Andrea Stevens Karnyoto et al. [15]
Nikhil Mehta et al. [16] proposed Continually Improving Social Context Representations using Graph Neural Networks.
Recent research assessments [6] have shown that the accuracy of content-based classification using CNN techniques could be much higher. Furthermore, approaches like these consistently require a significant amount of labeled data, which can be challenging to obtain in many real-world scenarios.
Research [15] and [16] are state-of-the-art research in the recent past using the Graph Neural Networks method to detect fake news problems and up to 85% accuracy in the author’s research. However, they are completed with datasets of a specific topic about Covid-19 news which needs to be covered the other issues.
Another drawback is that the above research has been done only with the English dataset; there isn’t research done with the Vietnamese dataset.
Preliminaries
Document embeddings
Document embeddings in Euclidean space refer to representing text documents as vectors in a high-dimensional Euclidean space, where the distance between these vectors captures the similarity or dissimilarity between the corresponding documents. Document embedding is a constructing process of equivalence operations, impressions in the mathematical structure of each word from the suitable corpus. This is a method of mapping all terms into numerical vector space. It has been demonstrated to be an essential procedure for Natural Language Processing (NLP) applications recently, enabling diverse machine learning methods that trust on vector constructing as input to richer graphics for document input datasets.
News article embedding is typically trained using unsupervised algorithms and constructed through transfer learning from large-scale unlabeled datasets. This process involves converting the words in a document into vectors of a specified dimension within a specific vector space. The conversion from words to vectors employs a neural network approach to capture the essential values of these vectors. The number of dimensions for a vector can range from a small integer to several hundred. By visualizing the vectors, words with similar or related meanings exhibit proximity, indicating that the overall semantic meaning of words has been captured through an appropriate learning method. The proposed approach in this research involves utilizing comprehensive word vectors to embed all the words within each news document in the datasets, visualizing them in Euclidean space.
We propose a semi-supervised classification approach utilizing the pre-trained Global Vectors for Word Representation Stanford (Glove) word embedding method with a 400-dimensional embedding to construct a comprehensive vector representation for mapping all news documents in the datasets. This method considers each entity present in every news document. Subsequently, a semantic vector is determined to map to each respective news document.
By projecting word vectors into an n-dimensional space, the procedure ensures that similar words are situated closer to one another while talks with different connotations are positioned farther apart. One of the notable advantages of the Glove method, compared to other embedding methods like Word2Vec, is its emphasis on global statistics rather than local statistics. The Glove is derived from the principle of co-occurrence matrix theory, where the co-occurrence matrix captures the frequency of word pairs appearing together within the given documents. In many cases, the co-occurrence matrix is decomposed using dimensionality reduction techniques such as Singular Value Decomposition (SVD) and Principal Component Analysis (PCA) algorithms [17].
Construct similarity graph
This classification step is mandatory with graph data input and is accomplished by building up a resemblance graph visualizing the proximity among various nodes, i.e., for our research, it is every news document. In most scenarios in the actual world, we can imagine any graph in the form of a k-nearest-neighbor graph. Especially toward every news document, we prospect K-Nearest-Neighbors in a news document embedding space. The K Neighbors can be confirmatory by manipulating a distance call as Word Mover’s Distance (WMD) amidst every news article with the others.
The K-nearest-neighbor (KNN) is defined as a graph in which two nodes, “p” and “q, existing one edge amidst them if node “p” is a node of the k nearest vertices in all other different neighbors and reverse. Any of the nearest KNNs represent one locality into n-dimensional space and is specified to use one “close relationship” anywhere proximity commonly supposed in distance to measure words as a WMD. Therefore, for a given problem in vector space, we build the KNN graph of the points by manipulating the distance amongst each couple of news documents and relating each news article to the nearest k points [17].
The WMD measure is a function of the distance between the documents. In our research, a news document is represented by a document with the lowest text classification error rate. An accurate representation of the distance between two documents is helpful in document compensation, text clustering, multilingual document matching, and many others. Two news documents are “A” and “B,” in which |A| and |B| is the count of exclusive words that ultimately appear within both of them.
Every word “w” of news document “A” is transformed into any word of news document “B” and T
ij
> =0 represents the separation that the word “w” in news document “A” have to move to transform to the word “w” in news document “B” and T is the streaming matrix stray. Toward turn to news document “A” totally in news document “B”, we determine the accomplished outflow from i to j must match B represented mathematically in Equation (1) as follows: [17]
The WMD separation between two news documents is meant as the smallest weighted accumulative cost mandatory in favor of transforming every word from news document “A” to news document “B” expressed as Equation (2):
The official WMD between two news articles is meant the optimized explanation value to the sequence transport clarification; this is a distinctive circumstance of the Earth’s distance in Equations (3)–(5):
WMD is initiated from current events in the embedding of words that define semantically meaningful descriptions of those words co-occurring in sentences between two news articles [17]. Effortless to learn, implement and be independent of the influence of every hyperparameter. Effortless represents the range between two content news articles and could be cleavage and meant as the sparse distances in various words. Usually contains part of crucial information shown by Glove and Word2vec methods and achieves high precision.
Neural Networks algorithms have archived massive success in recent years. Proximate Neural Networks variants could only be practiced with ordinary or Euclidean data. In contrast, most data worldwide have graph-based structure essentials, meaning non-Euclidean data. As a result, the data structure revolution has guided modern improvements in Graph Neural Networks.
Graph Convolutional Network (GCN) is an improved model of a convolutional neural network that operates straightway with graph-based structures. The preference for a convolutional methodology is encouraged through a localized primary approximation of spectral graph convolutions. The model scale is linear to the count of edges of the histogram using a powered layer-spread rule based on direct estimation of the spectral textures on the graph. The GCN model can learn hidden layer representations encoding the pair node features and graph-based structure to a degree helpful with semi-supervised algorithms [18, 19].
GCN is a philosophical extension of CNN, in which the convolution procedure is implemented in the histogram, alternatively, the pixels constituting the image. Since CNNs help catch knowledge from images and this knowledge can be recognizable to distribute pictures, an approximate proposal and be constructed on histograms. A strain approximate to the CNN strain can be recognizable in the GCN scenarios to catch the resemblance in the histogram. Graph structure using the GCN method has a limitation of hyperparameters, resulting in these techniques taking up small memory and knowledge levels constructed to yield remarkable results compared to traditional classification algorithms [19].
Generally, neural network algorithms use non-linear operating functions to perform non-linear features within implicit dimensions. The transition equivalence in the neural network is realized in the following correspondence where represents the activation function, H(1+1) and H(l) represents the feature at the lth layer, and 1 + 1th, weight W (l) and bias b
l
at class l in Equation (6).
The forward transition equation in the GCN can be expressed in Equation (7).
Matrix “A” is an adjacency matrix that represents a relationship among nodes in a graph-based structure in the actual world. The adjacency matrix A allows the model to practice character representations firm the connection of nodes. Bias b is also ignored to help the model be more transparent. The above equation is a primary approximation of the convolution of a spectral graph that transmits knowledge through neighboring nodes in a graph.
The primary purpose of GCN is to determine the function of features on a graph by taking an input character matrix X of size N x D in which N is the count of nodes, and D is the count of features. Matrix “A” is an adjacency matrix representing every input graph structure. Matrix A and matrix X are inputs to the GCN construction that produce a Z-level node output (N x F character matrix, where F is the count of output features in each node) [19].
One non-linear operation performing a universal neural network layer in the GCN be expressed in Equations (8) and (9).
With (0)=X is the initial input data, H(L)=Z is the node output in the final layer (or z for the graph data output), L is the count of layers, W (l) is the weight match for the lth neural network layer and σ is a non-linear operation performing. Rather than using matrix A for semi-supervised classification in the actual world scenarios, it can be expressed in Equation (10).
When Perform further spread by GCN model. Place the row sigmoid function in the final layer of the GCN model. Compute cross-entropy lossing with the determined node labeled. Backpropagation of the losing and reform new weight matrix “W” for every layer.
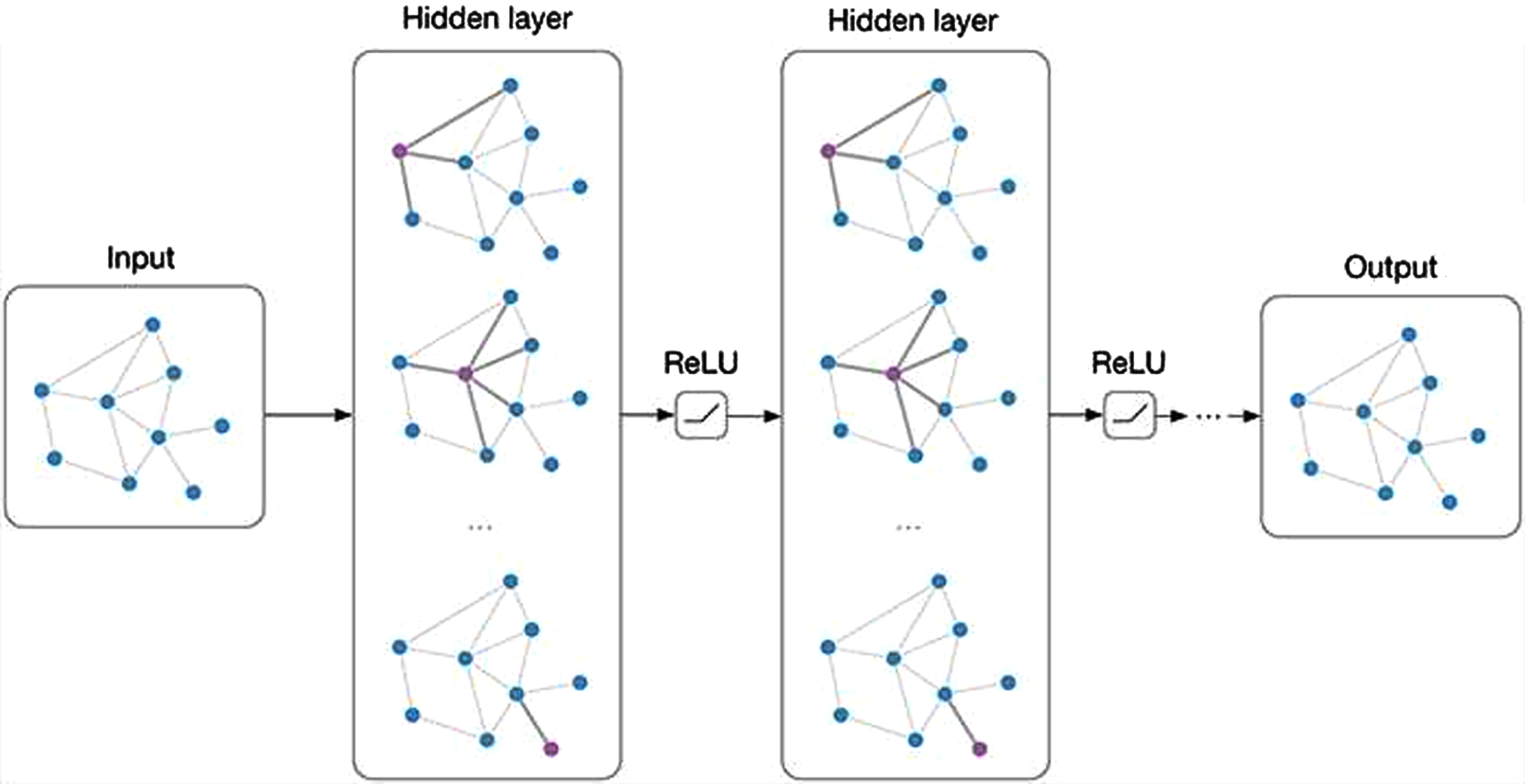
Graph convolution networks model.
Based on Fig. 2, the backpropagation method is a widely utilized algorithm for training artificial neural networks. In order to facilitate the procedure of learning, many inputs are necessary. The inputs encompass the following:
Training data: The backpropagation technique often necessitates a collection of labeled training datasets, wherein each instance comprises input attributes and their matching marked output. These models are employed to modify the weights and biases of the neural network throughout learning.
Neural Network Architecture: The structure of the neural network have to be defined, including the number of layers, the number of neurons in each layer, and their connectivity. They determine the number of parameters (including weights and biases) that need to be adjusted by backpropagation.
Activation function: An activation function is often used to introduce non-linearity for each neuron in a neural network. The activation function selection can impact the accuracy and convergence rate of backpropagation. The frequently utilized activation functions encompass the sigmoid, rectified linear unit (ReLU), and hyperbolic tangent (tanh).
Learning rate: The learning rate is a parameter that determines the magnitude of the adjustments made to the weights and biases throughout the backpropagation process. The selection process should be conducted cautiously to prevent excessive deviation or hindered progress toward convergence.
Error function: An error function, sometimes called a loss function or cost function, is required to calculate the difference between the neural network’s anticipated and intended output. Standard error functions in statistical analysis and machine learning encompass the mean squared error (MSE) and cross-entropy loss.
Based on Fig. 2, the objective of the backpropagation algorithm is to iteratively optimize the neural network’s weights and biases to minimize the error or loss function. The principal outcomes of the backpropagation technique are: Updated weights and biases: Following each iteration of the backpropagation algorithm, the neural network’s consequences and preferences undergo updates determined by the computed gradients. The revised parameters embody the acquired neural network knowledge derived from the training data. Prediction or output: The neural network can generate predictions for novel and previously unknown input data after training through the backpropagation algorithm. The neural network’s output signifies its forecast for a specific input, determined by the acquired weights and biases. Convergence information: During the training phase, backpropagation can monitor and record supplementary data, such as the loss value at each iteration or the criterion for convergence. This data assists in tracking the advancement of the educational process and ascertaining the appropriate cessation of instruction.
In our research, we collect news data from Internet newspapers in the Vietnamese language, including vnexpress, tuoitre, and bao moi, i.e., using the News-Please, BeautifulSoup, and UserAgent libraries in Python language combined with the dataset VFND-vietnamese-fake-news-datasets. After that, we conduct data processing, such as extracting the title and content of the news article and pre-processing the data. As a result, each new article is saved into two files: title and content. Next, we build a knowledge graph model for the dataset using Glove and Word Mover’s Distance (WMD) algorithms. Finally, the GCN algorithm trains the real and fake news prediction model with two parameters, K = 3 and K = 5.
This section uses data from many fields, such as sports, culture, society, economy, law, medicine, health, etc., to increase the input data’s diversity. From there, the knowledge graph diversity, coverage, accuracy, and performance are also higher. (see Fig. 3)
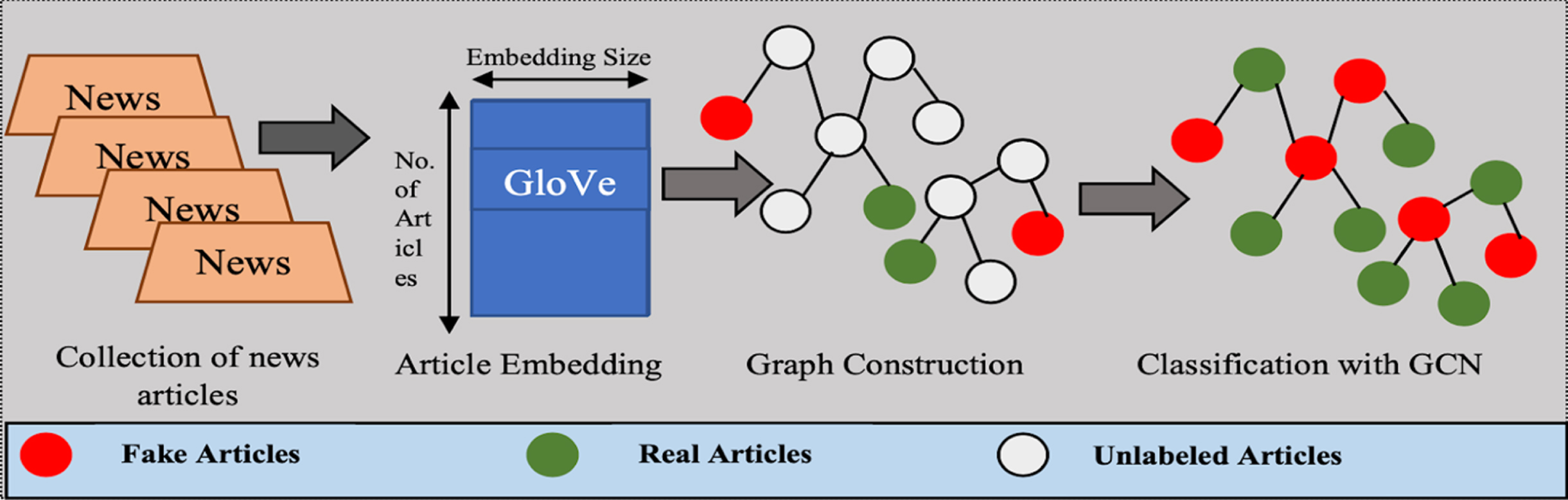
Fake news detection model by semi-supervised learning method.
Based on Fig. 3, the proposed method in our research includes the following steps: Collect data from newspapers and the VFND-vietnamese-fake-news dataset, and perform input data for the proposed method. Divide the input data into a training set of 70%, and a test set of 30%. Document embedding using Glove embedding. And visualize all news documents by the mean vector of the corresponding Glove embedding. Building similarity graph using WMD with K-nearest Neighbor and developing knowledge graph fake news dataset. Training model with the GCN algorithm to classify unlabeled nodes in the dataset. Evaluate the method on the test dataset.
In this section, we collect news data from Vnexpress, tuoitre sites in many different fields such as sports, culture, society, economy, law, and health, i.e., Each news document will be collected under as a JSON file that includes fields like “authors,” “date_download,” “date_modify,” “filename,” “main text,” “title,” “URL.”
Our dataset contains over 1200 news articles, of which 300 are determined fake news, about 300 are selected accurate news articles, and more than 600 are unlabeled. News articles in this research are published from 2018 to 2023 on various topics, including sports, culture, society, economy, law, medicine, and health, i.e.
Data pre-processing
After data collection, we implement many steps to pre-process the dataset before applying our proposed method; The process can be summarized in the steps as follows: Data cleaning: This step eliminates symbols, emojis, and punctuation marks that do not contribute significantly to the meaning of the text, and removes annoying characters, most commonly redundant HTML, and Javascript tags. Example:<b>He is a doctor. ->He is a doctor. Data transformation: The primary intent of this step is to convert the input data into a format more appropriate for data mining problems. The process includes many tasks, including normalizing numerical data, creating dummy variables, and encoding distinct data. Data reduction: For this step, we choose a section of the data that is appropriate for data mining problems. The process includes feature selection (mean is filtering a subset of the element) and feature extraction (mean is extracting new details from the data). Data discretization: This step aims to change from sequential numerical data to specific definitive data helpful for decision trees and other distinct data mining methods. Sentence segmentation: In Vietnamese, sentences are usually separated by “.” Example: Bác H Word segmentation: In Vietnamese, words are not separated by space. For example, the term “anh hùng” (hero) contains two syllables. Word normalization: The purpose is to return words to the correct syntax and spelling, making calculations more accurate. Remove stopwords dataset: The dataset is defined as words that manifest many times in the document but do not have much meaning in the original dataset. Example: this, that, it, them, etc
 a lịch sr Vi
a lịch sr Vi
Building a knowledge graph
Next step, we will build a knowledge graph (KG) model for real and fake news datasets. In which all entities of a news article perform each node, and each edge is the distance between that paper and other news articles. Likely a graph is an impression as the k nearest neighbor graph. Specifically, we intend to find the nearest neighbor in a specific embedding space with each news article. The k-nearest neighbor can be defined by computing the distance of Word Mover among a news article and others [17].
A KG usually details all entities and the relationship amidst them in the dataset. A KG can be determined as KG={E, R, S}, in which E manifests the set of entities, R is the set of relationships, and S is the triple set. A news article “A” is a set of entities in this news article, including the title, the entire content document, and the label that is determined true or false, which may be unlabeled. A KG is also effective with content fact-checking problems and detecting fake or accurate news articles.
As the final result of building a KG, we have a KG with vertices representing entities in news articles; edges are each relationship between these entities. The primary mission of content fact-checking is to check if a target triple (h, r, t) is correct firmly an established knowledge graph. The object of detecting fake news problems is to check if a target news document is accurate, strongly firm its title and primary content, and other homologous knowledge graphs. The final KG is used for input data for the semi-supervised classification method of detecting fake news.
Applying the real or fake news classification model
In this section, we use the implementation steps of the GCN method are shown as follows: (see Fig. 4)

Implementation steps of the GCN method.
The principal intention of the graph classification method can predict the labels for unlabeled nodes based on a determined graph and labeled nodes. A node in the graph generally indicates an actual world goal, i.e., in our research, it means a news article. The graph-based structure has had large to describe objects in the real world and the relationship among them. Node or graph classification could help detect unlabelled node labels in the graph-based depiction, whereas, with this intention, various researchers leverage relationships amidst nodes in graphs to increase the classification capacity.
The GCN method is one of the noticeable divergent Graph Neural Networks techniques applied in many actual applications using non-Euclidean real-world data based on graph-based structures. The main divergence between CNN and GNN is that GNN is commonly divergent from CNN, built to operate on nonuniform or non-Euclidean data, other than CNN can function only implemented in scenarios with the elemental data is ordinary (mean is Euclidean data). Convolution in GCN is a nearly similar functionality to the convolution with the CNN method. It means propagating the input neurons, including weights noticed as kernels or strains, acts as a sliding window, and activates the network to train characters from neighboring units. Several layers can include themes of different weights, but when a similar layer is, a similar strain will be used and noticed as weight sharing. The specific alternative of GCN is applied in our proposed semi-supervised classification method as Spectral Graph Convolutional Network [19].
In order to prevent overfitting in our research, we have implemented the following techniques: Increasing data collection: We collect the diversity of the model’s input data with various topics. Besides, the dataset is collected from news articles from 2018 to 2023. We also combine with VNFD-fake-news-dataset. Hence, the input is diverse and prevents overfitting in our proposed method. Dropout: We implement the GCN algorithm with dropout = 0.5 to help reduce the model’s reliance on specific nodes or features, making it more robust and less inclined to overfitting. Early stopping: We implement early stopping to prevent overfitting. This technique monitors the model’s performance on a validation set during training and controls the training process when the validation loss starts increasing, indicating overfitting is occurring. Cross-validation: To prevent overfitting, we split the dataset into multiple folds, and performing cross-validation can help assess the model’s performance more accurately. The final result is an average of ten cross-validation performances in our research. Graph regularization and hyperparameter tuning: We implement the GCN algorithm with many different values parameters, including learning rate, weight decay, and dropout rate, to prevent overfitting in our research. The final result is an average of ten groups of values parameters.
We used accuracy, precision, recall, and F1-score metrics to evaluate the model’s performance with the dataset. Tests were performed with two other values of K (including K = 3, K = 5) and different ratios of the labeled training data from 20% to 50%. GCN involves layers = 5 to feature extraction with intermediate indiscreet ReLU effect and dropout layers. GCN model with five layers is trained for 1000 epochs with dropout = 0.5, learning rate = 0.005, hidden = 16, and weight _ decay = 5e-4. The results implemented are shown in the below table: (see Tables 1 and 2).
Performance evaluation results of the model with K = 3
Performance evaluation results of the model with K = 3
Performance evaluation results of the model with K = 5
Based on the results of Tables 1 and 2, we hold that with K = 5, the measures to evaluate the model’s performance will be better than that of K = 3. Besides, as the amount of labeled data increases, the precision of the detecting fake news method also increases. The model in the research has the highest precision, 85.1%, in the case of labeled data accounting for 50% of the total input data in our research.
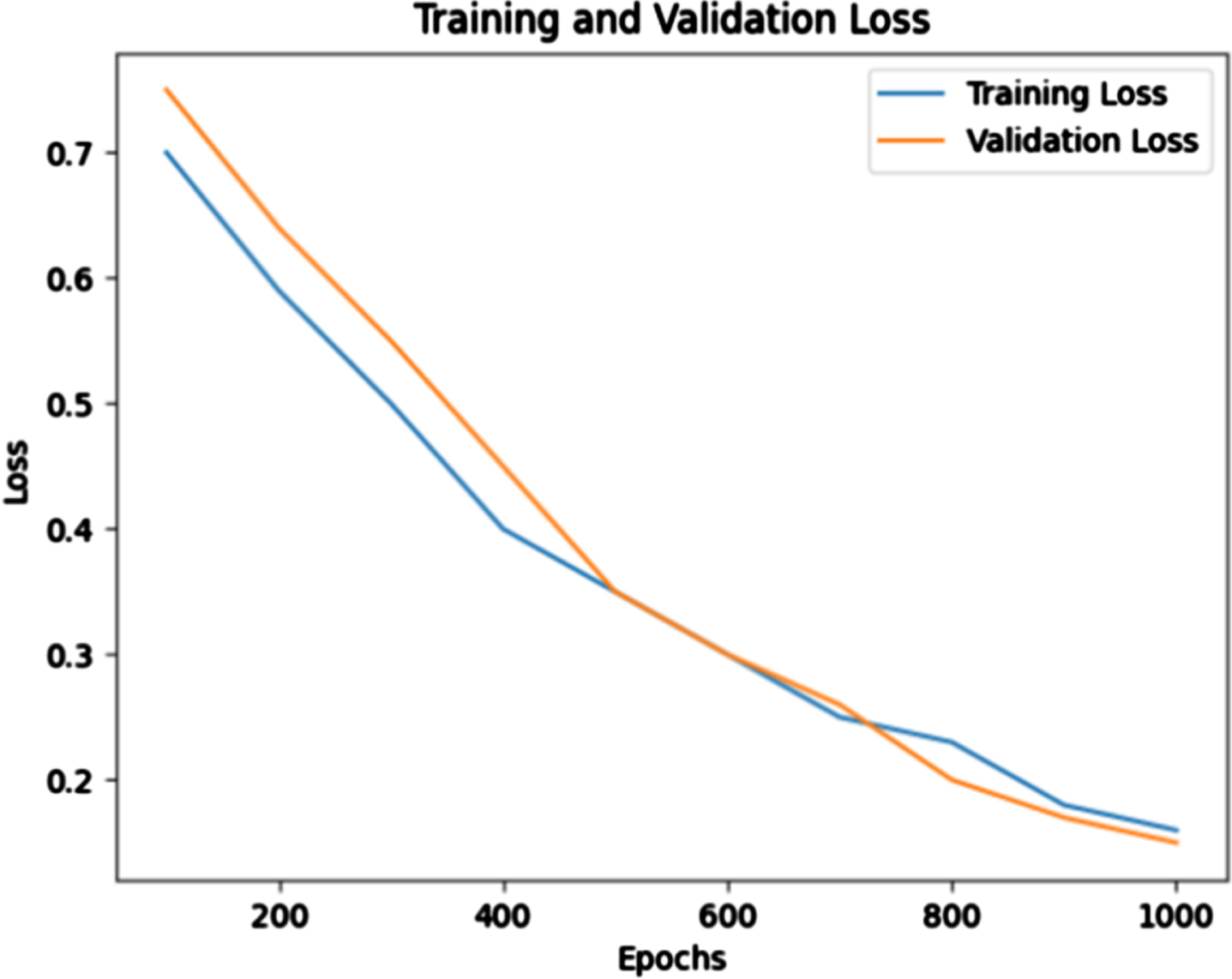
Based on the results shown in Figs. 5 and 6, accuracy increases through each epoch, and the error (loss) decreases. When the dataset was trained through 1000 epochs, the precision of the model reached 85.1% with a training/validation dataset ratio of 70/30 percent.
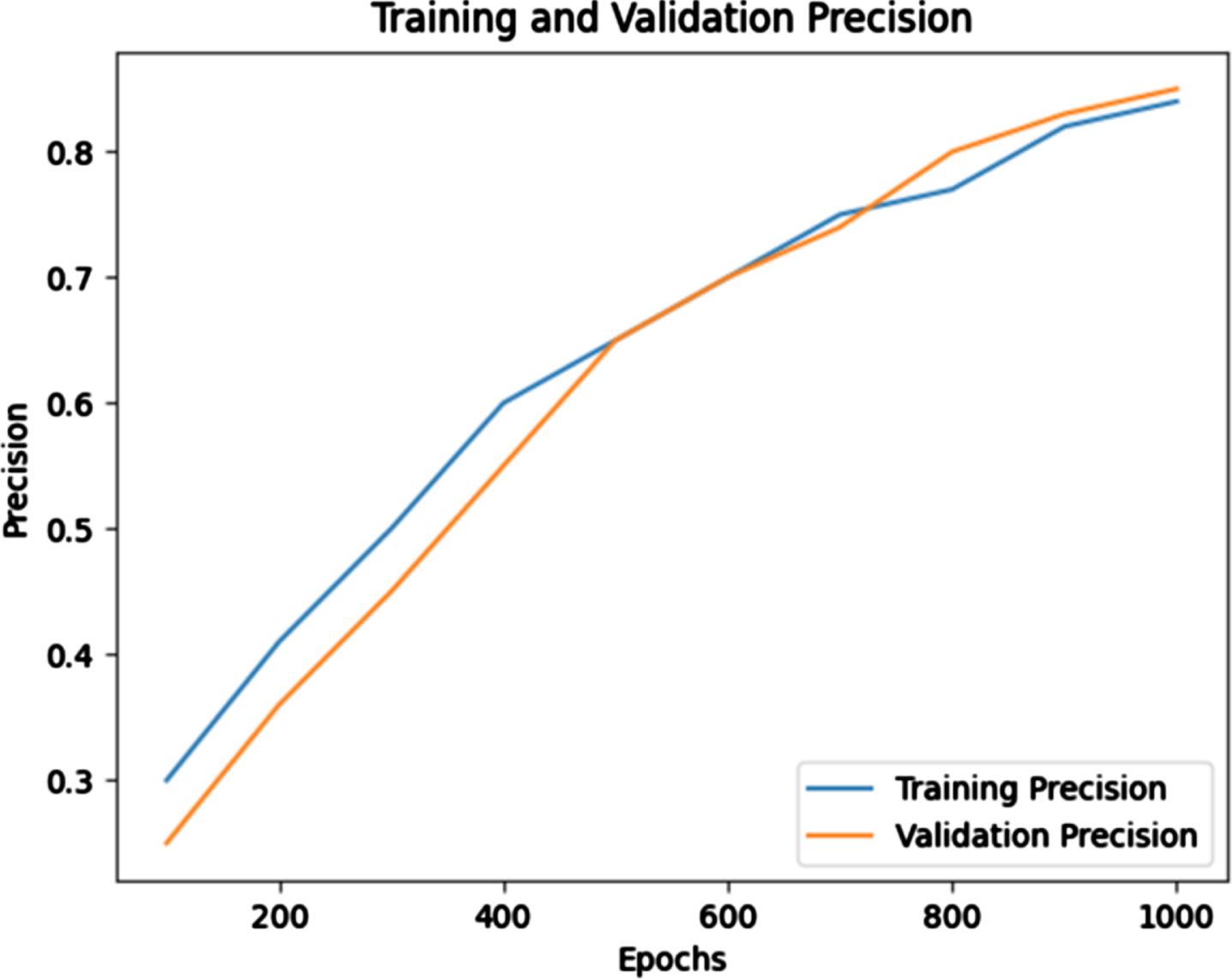
Training and validation precision for each epoch.
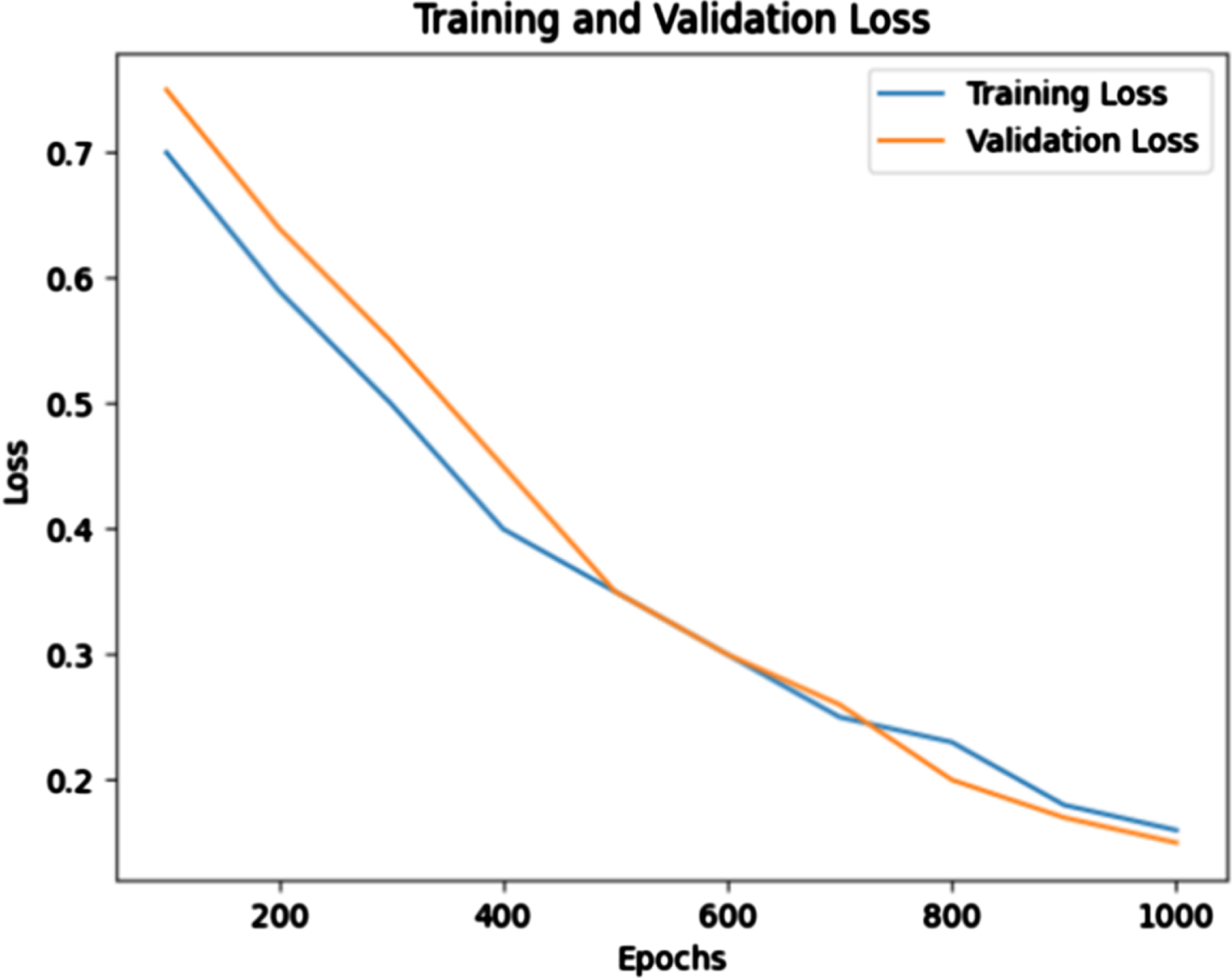
Training and loss precision for each epoch.
With the results of our research, when comparing with the detecting fake news results from other studies in the recent past, we have the following results: (see Table 3).
Comparison of research results with other fake news prediction methods
Method 1: The proposed method by Bali et al. [20]
Method 2: The proposed method by K. Agarwalla et al. [21]
Method 3: The proposed method by Hamid Karimi and Jiliang Tang [22].
Method 4: The proposed method by Dinesh Kumar Vishwakarma et al. [23]
Method 5: Andrea Stevens Karnyoto et al. [15] employed a graph neural network to identify fake news on social networks in the AAAI2021 COVID-19 English dataset.
Method 6: Piyush Vyas et al. [24] proposed a plan to detect fake news on the web using by LSTM-based approach to the COVID-19 pandemic topic.
Method 7: Eslam Amer et al. [25] proposed a content-based fake news detection method using GRU.
Our proposed method surpasses other strategies in identifying fake news on the same dataset when comparing comparison outcomes. This result is credited with employing GCN and WMD approaches, which may gauge the separation between articles and increase the knowledge graph’s precision. This study’s suggested strategy has shown to be quite effective at spotting bogus news, particularly for Vietnamese data.
Furthermore, our research outperforms the most recent methodology by creating a broad dataset including various issues. Our investigation demonstrates the superiority of prediction based on the knowledge graph compared to other ways, even though Method 5, the most recent sophisticated method, focuses only on determining actual or false news connected to Covid-19. The knowledge graph performs better when context and real-world descriptions are incorporated. This represents the first thorough assessment of a knowledge graph-based approach applied to the problem of false news identification, which is a significant milestone.
Furthermore, employing a complete input knowledge graph dataset covering diverse topics and different types of news yields better results than an incomplete knowledge graph. With a model precision result of 85.1%, our proposed method exhibits substantial promise in forecasting fake news using Vietnamese data. This accurate detection enables us to mitigate the detrimental effects of fake news that impact various aspects of society. Moreover, it empowers the government to take appropriate measures to prevent the dissemination of such news, both domestically and internationally. Consequently, it facilitates practical actions against perpetrators of fake news. Our research contributes significantly to the intriguing field of fake news detection, achieving an impressive accuracy of 85.1% specifically for Vietnamese datasets - an accomplishment yet unexplored by prior studies.
The most possible in our research robustness lies in utilizing KG and GCNN techniques, which can maintain the effectiveness of fake news detection. This is accomplished by the integration of external knowledge derived through KG. To sufficiently capture semantic context and identify fake news, KG offers a structured representation of data and relationships between things. By employing this further information, the proposed model can exhibit reduced vulnerability to manipulation or noise in particular news articles.
The scalability of our proposed method includes the dimensions, elaborateness, and computing capability of the GCNN and KG techniques in the fake news detection method. Implementing knowledge graphs can pose issues in terms of processing and memory requirements. Moreover, the computational cost of training GCNN on large graphs might be powerful. It is possible to employ effective graph selection techniques to improve the scalability of the method to more extensive datasets and KG.
The generalization of KG employed in our research represents the total information context. It includes a wide range of disciplines, which helps improve the generalizability of the fake news detection model. This implies that the model can detect fabricated news across many subjects and circumstances beyond the limitations of solely relying on the information provided in the training dataset.
The transferability of KG and GCNN approaches lies in their ability to facilitate transferability between comparable tasks within misinformation detection. The model’s acquired representations of things and interactions after being trained on a sizable KG can be helpful for tasks like rumor detection, fact-checking, or systematic classification. Educational institution. The ability to be easily transported can decrease the necessity for individual models for each activity and enhance the efficient use of resources.
GCNNs have exhibited consequential expressive capabilities when representing and modeling data with graph structures. Higher-level representations can be obtained by pooling information from adjacent nodes in the graph using a sequence of graph convolutional layers. This technique enables the model to comprehend intricate designs and interrelationships among entities effectively, facilitating enhanced accuracy in classifying fake news.
Fake news is one of the burning problems and causes many severe consequences in today’s society. Nonetheless, one of the most difficult in detecting fake news is collecting data and labeling each news document in such a vast data block today for the input of supervised learning algorithms. Therefore, we proposed a method for our research. The main benefaction of the study included developing detection datasets in Vietnamese, building knowledge graph models for Vietnamese datasets, and detecting fake news for Vietnamese data using knowledge graphs. The knowledge graph for fake news detection with Vietnamese news documents is an essential key in our research, with the advantage is to fully represent the meaning of the entities in each news document and the relationship between the entities, making it more effective to verify the accuracy of the news document than the document data many times. Besides, this is also the first knowledge graph dataset for detecting fake news in the Vietnamese language.
Based on implement results, we clearly show that our proposed method achieves a precision of 85.1% with the dataset developed in our research, and the labeled ratio is 50%. This can resolve drawbacks of recent forms of fake news detection; they can’t have high results with limited labeled datasets like the dataset in our research. Besides, developing authentic and fake news datasets in the Vietnamese language with many different topics is the basis. It helps create the premise for future research on detecting fake news.
This research is also the first research about fake news detection in the Vietnamese language. With the good results of this model, this will be an essential step in predicting fake news for the Vietnamese dataset.
We continue collecting data from newspapers and social networks, such as Facebook, Zalo, etc., according to various topics to diversify input data. Besides, we will experiment with other Vietnamese data pre-training models, like PhoBert - Pre-trained language models for Vietnamese, to enhance the precision of the model in scenarios the labeled data is too small compared with the total input dataset in the model. We also aim to improve the semi-supervised learning algorithm that classifies real or fake news by training with various parameters to improve our proposed method’s precision.
Footnotes
Acknowledgments
This research is funded by Vietnam National University Ho Chi Minh City (VNU-HCMC) under grant number DS2023-26-01.