
Abstract
Social network attackers leverage images and text to disseminate sensitive information associated with pornography, politics, and terrorism,causing adverse effects on society.The current sensitive information classification model does not focus on feature fusion between images and text, greatly reducing recognition accuracy.To address this problem, we propose an attentive cross-modal fusion model (ACMF), which utilizes mixed attention mechanism and the Contrastive Language-Image Pre-training model.Specifically, we employ a deep neural network with a mixed attention mechanism as a visual feature extractor. This allows us to progressively extract features at different levels. We combine these visual features with those obtained from a text feature extractor and incorporate image-text frequency domain information at various levels to enable fine-grained modeling. Additionally, we introduce a cyclic attention mechanism and integrate the Contrastive Language-Image Pre-training model to establish stronger connections between modalities, thereby enhancing classification performance.Experimental evaluations conducted on sensitive information datasets collected demonstrate the superiority of our method over other baseline models. The model achieves an accuracy rate of 91.4% and an F1-score of 0.9145. These results validate the effectiveness of the mixed attention mechanism in enhancing the utilization of important features. Furthermore, the effective fusion of text and image features significantly improves the classification ability of the deep neural network.
Keywords
Introduction
The rapid development of the internet has sparked urgent attention to the security of social network content [1]. The content and dissemination forms of sensitive information related to pornography, politics, and terrorism have become more diverse.Compared to single modality, multimodal sensitive information that combines text and image is easier to spread and more destructive to public safety.Therefore, research on multimodal sensitive information classification [2] can not only help governments quickly identify sensitive information, but also effectively purify the network ecological environment.
Computer vision and Natural language processing are two of the most useful and powerful technologies to deal with the classification of sensitive information.Alshalan et al. [3] proposed a model based on CNN and recursive neural network to detect hate speech on Twitter. Gangwar et al. [4] proposed a deep CNN architecture (AttM-CNN) combining attention mechanism and metric learning for pornographic image classification.The metaherstics also shows significant potential in tackling machine learning hyperparameters optimisation challenge [5]. Zare et al. [6] proposed a method based on Diferential Evolution (DE)/currentto-best/1 for enhancing the FA’s movement process. The proposed modifcation increases the global search ability and the convergence rates. Multimodal classification [7] which aims to classify a pair, or a group, of different types of data into categories, has attracted extensive attention from academia and society.However,the sensitive information in the form of combining images with text limits the accuracy of single mode recognition.Current multimodal methods for capturing the components of multimodal contexts are too simple to extract high-order complementary information from multimodal contexts.
In order to address these challenges, our study proposes an innovative multimodal fusion model called ACMF. ACMF incorporates a hybrid attention mechanism and a transformer architecture to effectively capture the correlation between image and text, as well as the significance of abstract image features across various regions and levels. The primary contributions of our study are summarized as follows: the image features were extracted utilizing the hybrid attention mechanism, which effectively mines relevant information. On the other hand, the text features were modeled using the state-of-the-art transformer structure, which has demonstrated remarkable performance in various natural language processing tasks. To fuse the image and text features, we mapped the image feature representation domain to align with the text feature representation domain. Additionally, we employed a multimodal adaptive analysis method to capture and model the correlation between image and text information. By incorporating two attention mechanisms into our feature extraction process, we aim to improve the representation and discrimination capabilities of the image features, ultimately enhancing the overall classification performance of the sensitive information detection model. A feature fusion module based on cyclic attention mechanism is constructed, which can effectively promote the interaction between image features and text features. Moreover, the fusion effect of features is further improved through multiple cycle fusion. The multi-task joint learning combined with CLIP task not only ensures the full utilization of graphic features, but also enhances the correlation between graphic features, and carries out weighted summation of graphic feature loss and classification loss, so as to enhance the efficiency of online learning.
The rest of this paper is organized as follows: Section2 introduces the overview of related approaches. Section 3 describes the proposed method in detail. Section 4 presents the datasets, experimental setup, baseline and the results obtained from applying the proposed method.Section 5 presents the conclusion of this study.
Related work
Classification of single-modal sensitive information
Most studies on sensitive information classification have focused on single- modal data, such as image classification or text classification. CNNs can automatically extract abstract features from the original pixels [8] and identify image information [4] and have thus made remarkable achievements in the field of image processing. In addition, various swarm intelligence algorithms improve the global search ability and the convergence rates, which is very enlightening to the algorithm optimization of artificial intelligence [9, 10]. Banaeeyan et al. [11] used the residual neural network (ResNet) to detect nudity in an automated process. Perez et al. [12] proposed a pornographic video classification method by using CNN and static motion information.
Natural language processing is witnessing rapid advances and yields excellent results in tasks such as semantic analysis, sentiment analysis, and sentence modeling [13]. Feature selection and feature extraction methods are also more optimized [14, 15]. Pan et al. [16] proposed a sentiment analysis model for Chinese online course reviews by using an efficient transformer that enables parallel input of word vectors for predicting sentiment polarization. Zivkovic et al. [17] proposed an arithmetic optimization algorithm (AOA) - based approach that can improve the classification of fake news results by reducing the number of features and achieve high accuracy. Kar et al. [18] proposed an optimal feature extraction and hybrid diagonal gated recurrent neural network (FE-DGRNN) for hate speech detection and sentiment analysis in multilingual code-mixed texts.Agushaka et al. [19] proposed a novel population-based metaheuristic algorithm called the Gazelle Optimization Algorithm (GOA), inspired by the gazelles’ survival ability in their predator-dominated environment.The results show that GOA is a potent tool for optimization that can be adapted to solve problems in different optimization domains.Hu et al. [20] proposed an adaptive hybrid dandelion optimizer called DETDO to address the shortcomings of weak DO development, easy to fall into local optimum and slow convergence speed.
Single-modal algorithms have limitations in real-world sensitive information classification because sensitive information in social networks mainly exists in the hybrid form of images and texts. Traditional single-modal algorithms cannot deal with multimodal information. In response to this, in this study, we designed a more targeted algorithm based on multimodal sensitive information to improve the sensitive information classification performance.
Classification of multimodal sensitive information
The outstanding performance of deep neural networks (DNNs) in single-modal recognition for sensitive images, texts, audios, and videos enables reidentifying fused multimodal sensitive information. Multimodal feature fusion classification allows the correction of the internal error from a single information source [21] and combines the features extracted from each mode, thus achieving more accurate and robust classification. Weng et al. [22] proposed an XMATL frame- work based on MAT-LSTM that combines text features with user behavior to detect toxic articles (e.g., rumors, pornography, and fraudulent content) on social networks. To improve the effectiveness of multilingual toxic comment detection, Song et al. [23] proposed a hybrid model combining monolingual and multilingual models that can fuse monolingual and multilingual features from different BERT models. Zhang et al. [2] proposed an end-to-end deep learning (DL)-based multimodal fusion network that splices image-text features by using the attention mechanism and has been employed for multimodal rumor detection on social networks.
According to the studies, the multimodal algorithm improves model stability and prevents errors in a single mode from affecting the model judgment. Image data contains visual information while text data contains semantic information. Fusion of these two types of data utilizes their respective advantages and achieves complementary effects. Multimodal information processing facilitates mining of hidden sensitive information and reduction of recognition errors. However, existing methods do not consider the importance of image region features and channel features, resulting in insufficient mining of image and text features and lack of mode correlation establishment. In sensitive information detection, decision-level fusion makes it difficult for the model to capture the correlation between image and text features. Based on this, the ACMF model is proposed. It uses a mixed attention mechanism and Bert to extract image and text features, constructs a cyclic attention feature fusion module after cross combination of text and image features, and compares the similarity of text and image using the CLIP model to optimize the network weight of text and image feature extraction. Finally, multi-modal features are classified after weighted summation to improve the classification accuracy of multi-modal sensitive information.
Proposed Architecture: ACMF
The ACMF model, as depicted in Fig. 1, comprises several key components for effective multimodal sensitive information classification. These components include an image feature extraction module, a text feature extraction module, a cycle attention feature fusion module, a CLIP text-image feature similarity comparison module, and a multimodal sensitive information classification module.To begin with, image features and text features are extracted using a convolutional neural network (CNN) and BERT (Bidirectional Encoder Representations from Transformers) respectively. These extraction modules incorporate a mixed attention mechanism to capture relevant information from both modalities.Next, the cross-fusion of image features and text features is performed, resulting in hybrid features that encompass both visual and textual information. This fusion enables a comprehensive representation of the multimodal content. The cyclic attention mechanism is then employed to facilitate the weighted fusion of image features and text features. This mechanism ensures effective interaction and information transfer between the two modalities, enhancing the overall representation ability of the features.To further enhance the representation and similarity analysis of the multimodal features, the CLIP module is introduced. The CLIP module enables similarity matching between image and text features, strengthening the relationship between the two modalities. Finally, based on the fused multimodal features, the multimodal sensitive information classification module classifies the data into categories such as pornography, politics, terrorism, and others.The comprehensive architecture of the ACMF model, as outlined above, provides a robust framework for capturing and integrating multimodal features, enabling effective classification of sensitive information.

Structure of the ACMF model.
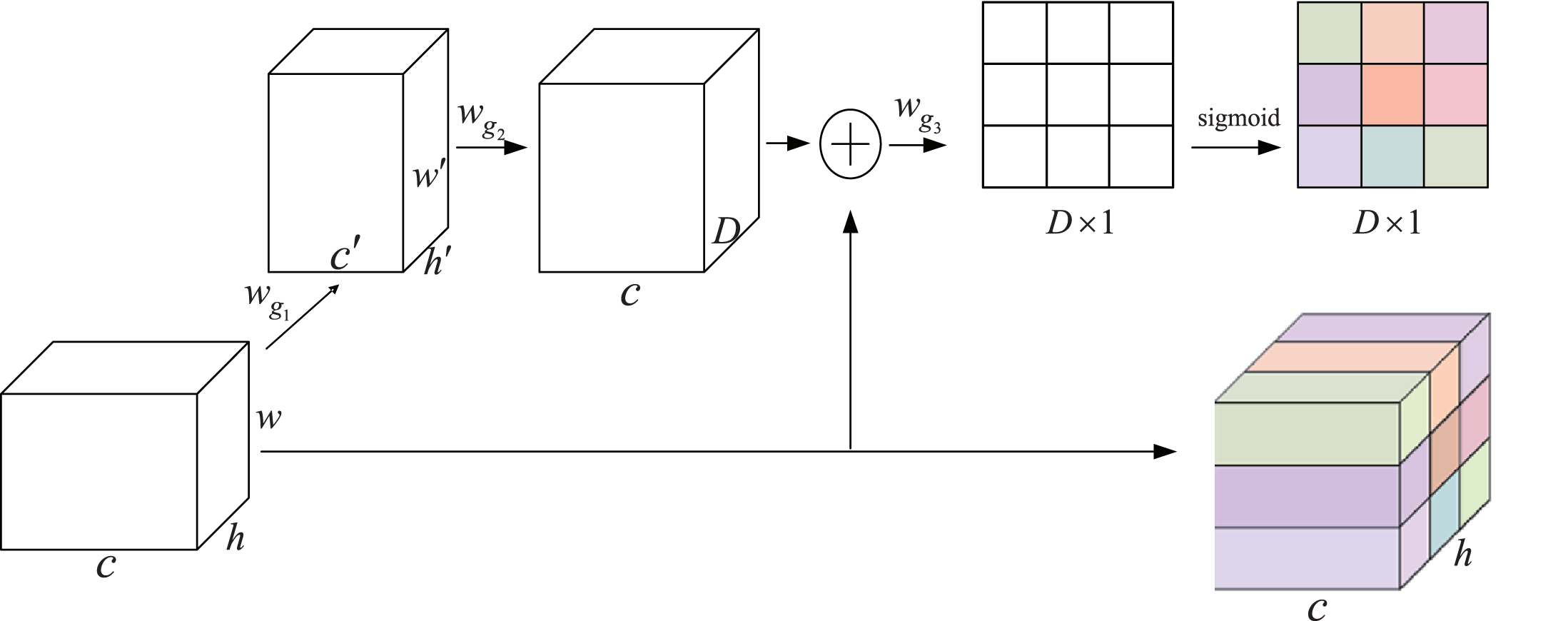
In image processing, traditional CNNs generally accord the same attention to each region in an image. However, in classification tasks, different regions of the image contribute differently to the task. Thus, the focus should be on the regions that are related to the task. For example, in the classification of terrorism-related images, features such as guns and ammunition require special attention; thus, regions related to these features should be assigned a higher weight in discrimination, whereas background regions should be assigned a lower weight. The correlation between feature regions and classification tasks should be learned when extracting image features; thus, in the proposed model, the spatial attention mechanism is used.
The proposed ACMF model fuses the shallow and deep image features through residual connection, thus improving the feature utilization efficiency of the model. However, different channels of the CNN extract different levels of abstract features. Traditional CNNs treat the output feature of each channel equally and cannot process the information of the channel features. In view of this problem, in the proposed model, the channel attention mechanism is adopted and the importance of each channel is determined for the categorization task. This channel attention mechanism is combined with the spatial attention mechanism to form the hybrid attention mechanism model.
Spatial attention mechanism model
Suppose there are I multimodal sensitive information image-text samples χ ={ x1, x2, ⋯ , x
I
}, For the i -th sample, the classification label is y
i
∈ { yi0, yi1, yi2, yi3 }, where yi0, yi1, yi2, yi3 represent the four categories: normal, terrorism-related, political, and pornographic. Each multimodal sensitive information is divided into two modes x ={ x
v
, x
t
}, where superscripts v and t represent visual and textual forms, respectively. For a given sample of multimodal sensitive information x
i
,the task is to classify it correctly. In CNNs, the feature space of image
Structure of spatial attention mechanism.
After several layers of convolution, the output features
The results obtained from the above operations are used to determine the dependencies between the channels. The dependencies are then combined with the feature maps of various feature channels to obtain channel features with adaptive importance. This process can be expressed as follows:

Structure of channel attention mechanism.
The text feature extraction module utilizes a pretrained BERT [24] structure for fine-tuning to extract sensitive text features and employs a 12 two-way transformer layer stack. The transformer structure obtains the encoding of each word in a sentence, which contains the dependency of the word on other words in the sentence, and assigns it a global acceptance domain. In addition, the proposed model permits parallel computation.
The text information in the i -th multimodal sensitive information sample is denoted as
In order to improve the interaction of feature information of image text and make full use of pixel features and text features as far as possible, this paper designs a set of circular attention feature fusion module. Now the image features
In order to ensure the high efficiency of multi-modal feature fusion, this paper designs a cycle attention structure such as Formula (8) to ensure more adequate transmission and interaction of mixed features.
In order to enhance the image-text feature association, CLIP model is introduced in this paper, and BERT word embedding structure is adopted to map the words or phrases in the vocabulary to the real vector T1-TN. Then the picture is mapped to the feature vector I1-IN through attention mechanism module, so as to construct the image-text feature mixing matrix for fusion. Finally, by comparing the similarity between the text features and the image features, the feature weight with stronger ability to represent the text features is obtained. Its confusion matrix is shown in Fig. 5.
The calculation process of CLIP network is as follows:

Text and image feature fusion matrix.
The weights of the image and text features learned using the multimodal adaptive neural network are used for obtaining the weighted sum of the image-text features. After outputting the multimodal fusion features, three fully connected layers are added as hidden layers to enable the model to capture the nonlinear high-order correlation between the multimodal fusion features and sensitive information classes. The formalized definition of the hidden layer is as follows:
Finally, the loss function of the CLIP task in Section 3.4 is simultaneous to obtain the loss function of the overall multitask network of ACMF, which is expressed as follows:
In this section, we first describe the data sets and experimental setup. Then, we evaluate our proposed method and compare it with other state-of-the-art methods. Finally, we show the ablation study used to investigate our proposed method.
Datasets
To illustrate our work, we collected a real-world set of data from the Internet, known as the NSASI datasets, which includes 11694 items. Each image-text pair was labeled by three annotators. A majority vote was employed to filter inconsistent entries. The data set contains 3596 pornographic information,2001 political information, 2234 terrorism information and 3863 normal information.The ratio of training set to test set is 7:3. The details of data usage in this paper are as follows: 1) only the image part of NSASI dataset is used for single-modal image sensitive information classification; 2) Single-modal text sensitive information classification only uses the text part of NSASI dataset; 3) Multi-modal image-text sensitive information classification uses the full image-text data of NSASI dataset.
Experimental settings
The experimental environment uses Windows 10 operating system, NVIDIA GeForce 1080Ti graphics card for model training and testing. CPU configuration is Intel(R) Core(TW) i7-10700CPU, CUDA version 10.1, Python language environment is 3.8 model framework using Pytorch deep learning framework version 1.11.0.
Accuracy, precision, recall, F1- score, and receiver operating characteristic (ROC) curve were used to evaluate the performance of the models.In this paper, the training parameters of ACMF model were determined by combining the previous scholars’ parameter tuning experience and a large number of experimental comparisons. The maximum sentence length in the BERT Chinese pretraining language model was set as 32,the batch size was set as 8 during training, the learning rate was 5e-5, a 12-layer transformer structure was selected, the dimension of text features obtained from BERT was 768,the image was rgb color image, the training scale was 224*224*3.In the network, a leaky ReLu activating function is applied to all fully connected layers, while the value of dropout is 0.5 for the purpose of avoiding overfitting. Adam optimizer is also applied to better select the model parameters.
Baselines
In order to evaluate the performance of the proposed method, the prediction results on the the above data set is quantified and compared with the results of single-modal sensitive information detection models. IM denotes image modality, TM means text modality, and IM-TM corresponds to a multimodal form that combines images with texts.
The proposed model was compared with popular image classification benchmark models, namely ChildNet [25], ResNet-34 [26], DenseNet [27] and EfficientNetV2 [28] and text classification benchmark models, namely TextCNN [29], and LSTM [30].

Confusion matrices for different models.
As shown in Table 1, ACMF is significantly better than the baseline method in most indicators, indicating that the mixed attention mechanism and cyclic attention mechanism proposed in this paper can effectively improve the performance of sensitive news detection, and the method combining CLIP model with image and text information can improve the detection accuracy. The effect of multimodal fusion model is better than single modal model. When the multimodal sensitive datasets was used, the accuracy of the ACMF model was 12%, 4%, 7.2% and 4.8% higher than that of Child-Net, ResNet-34, TextCNN and LSTM respectively, indicating that multimodal feature fusion can considerably improve the sensitive information classification performance. CLIP model and cyclic attention mechanism can learn the correlation between image and text features, thereby improving the classification accuracy. The single-modal image feature was used for classifying the four types of information, the accuracy of Child-Net, ResNet-34, DenseNet and EfficientNetV2 was between 79.4% and 88.2%, and the performance of EfficientNetV2 was considerably better than that of Child-Net and ResNet-34, thereby reflecting the effectiveness of deep learning methods in sensitive image detection. In the NSASI datasets, the accuracy of EfficientNetV2, ResNet-34 and Densenet was 3% 4% higher than that of TextCN and LSTM,which intuitively illustrates the greater impact of image features on the accuracy of model detection. The accuracy of text detection is low, which may be related to Chinese homophones and polysemy. Therefore, if the detection of sensitive information only relies on text features, it will lead to high false positive rate and degradation of model performance. Combining the rich visual information in the image features with the text features can effectively improve this problem.
The performance of each model on sensitive datasets
The performance of each model on sensitive datasets
To study the correlation between categories, a confusion matrix was introduced to visualize the fine-grained classification performance of models. Each column represents the predicted category, and each row represents the actual category. The confusion matrixes (Fig. 6) of the single-modal models, namely EfficientNetV2 and LSTM, and the multimodal fusion ACMF model were experimentally compared. The ACMF model exhibited a higher classification accuracy than other models in distinguishing sensitive information. Furthermore, the classification effect of ACMF was relatively even and did not exhibit a particularly inferior accuracy for a certain class.

ROC curves of different models.
The complexity of the ACMF model was measured using the number of parameters and floating point operations per second (FLOPS). As shown in Table 2, the multimodal ACMF model modified using the BERT model had slightly more parameters than the original model, but it was acceptable. From the perspective of FLOPS, ACMF exhibited great advantages over other common visual environment models, namely ResNet50 and ResNet101, and did not require much in terms of hardware resources. Therefore, the training and prediction of the proposed ACMF model are not time-consuming, and the model can be deployed and run in real-world scenarios.
The model classification performance was also studied using the ROC curve (Fig. 7). The ACMF model had a smoother ROC curve than the other models and exhibited a considerably improved area under the curve (AUC), indicating that the ACMF multimodal fusion classification model had higher robustness and stability in the task of classifying multimodal sensitive information of the four categories.
Comparison of model complexity
In order to more intuitively show that the ACMF model has better performance in the classification of sensitive image-text information, we randomly select four types (pornography, politics, terrorism and normal) of pictures to show the results, as shown in Table 3. It can be seen from the results that the ACMF model can accurately recognize multimodal sensitive information. In addition, for the similarity of images and texts, the similarity of images and text features of the same category can reach more than 0.96, which shows that the scheme designed in this paper has good performance.
Examples of sensitive analysis of image-text pairs with the proposed module
In order to study the effectiveness of each module proposed in model ACMF, we perform separate ablation analyses by removing some modules. As can be seen from Table 4, experimental results revealed the advantages of the attention mechanism in classification, especially Model-cyl+att with mixed attention and multimodal cycle attention, the accuracy of which was 2.4% and 1.6% higher than that of Model-cyl+CLIP and Model-att+CLIP and the precision was 0.0254 and 0.0182 higher than that of Model-cyl+CLIP and Model-att+CLIP, respectively. The ACMF model that employed image-text classification on the multi modal sensitive datasets demonstrated an accuracy increase of 4.2% and 5.2% compared with ACMF-I and ACMF-T, respectively. These improvements indicate that multimodal features are better than single-modal features for sensitive information classification. The ACMF has improved 1.59 percentage points compared to Model-cyl+mix in F1 score, indicating that the cycle attention feature fusion using adaptive mechanism can improve the model performance. As shown in Fig. 7. The accuracy, precision, recall, and F1-score of ACMF model were better than other models, thus, demonstrating that the multimodal feature fusion classification method with CLIP guided mix attention for sensitive information classification greatly improves the performance of multimodal sensitive information classification. Based on Mixed Attention and CLIP Model greatly improves the performance of multimodal sensitive information classification.
Experimental results of ACMF ablation
Experimental results of ACMF ablation
This study presents a novel approach for fine-grained multimodal sensitive information classification, aiming to effectively fuse heterogeneous image and text features. The proposed ACMF model combines image feature information and text feature information to enable more accurate identification of multimodal sensitive information.The integration of the mixed attention mechanism and the CLIP model in the ACMF model enables the learning of image and text features with enhanced expression capability. The model adaptively learns the weights of these features, resulting in improved representation of multimodal information. By leveraging these weighted multimodal features, the ACMF model achieves accurate classification of sensitive information.

Experimental results of ACMF ablation.
The proposed ACMF model introduces a novel approach to multimodal fusion for sensitive information classification, leveraging the mixed attention mechanism and the CLIP model. This model establishes a new baseline in the field, opening up opportunities for further advancements. However, there are some limitations, including dataset, semantic understanding, model scalability, cross-domain application, and security and privacy issues. To overcome these limitations, it is necessary to improve data sets, improve semantic understanding, design more efficient data processing methods, explore cross-domain applications, and strengthen data security and privacy protection. Future studies can focus on fine-tuning the parameters used in the ACMF model to enhance the classification accuracy even further. By optimizing the model’s parameters, researchers can potentially achieve improved performance and more accurate identification of sensitive information. Moreover, with the rapid increase in the number of users sharing short videos on social networking sites, it has become crucial to address the security concerns associated with sensitive content in these videos. Future research can explore the combination of audio, image, and text features to develop effective methods for classifying multimodal sensitive videos. These future research directions have the potential to advance the field of multimodal sensitive information classification and contribute to the development of more comprehensive and robust security systems for social networking platforms.