
Abstract
With the rapid development of information science and social networks, the Internet has accumulated various data containing valuable information and topics. The topic model has become one of the primary semantic modeling and classification methods. It has been widely studied in academia and industry. However, most topic models only focus on long texts and often suffer from semantic sparsity problems. The sparse, short text content and irregular data have brought major challenges to the application of topic models in semantic modeling and topic discovery. To overcome these challenges, researchers have explored topic models and achieved excellent results. However, most of the current topic models are applicable to a specific model task. The majority of current reviews ignore the whole-cycle perspective and framework. It brings great challenges for novices to learn topic models. To deal with the above challenges, we investigate more than a hundred papers on topic models and summarize the research progress on the entire topic model process, including theory, method, datasets, and evaluation indicator. In addition, we also analyzed the statistical data results of the topic model through experiments and introduced its applications in different fields. The paper provides a whole-cycle learning path for novices. It encourages researchers to give more attention to the topic model algorithm and the theory itself without paying extra attention to understanding the relevant datasets, evaluation methods and latest progress.
Introduction
In the era of dramatic network technology and information science development, massive amounts of text data can be accelerated on the Internet. Since most of these data are unstructured, extracting important and expected information from them might be challenging. The topic model is a typical text mining and modeling technique widely applied in topic mining, text classification, emotion analysis, and other closely related fields [1–5]. With the probabilistic Latent Semantic Analysis (pLSA) [6] and the Latent Dirichlet Allocation (LDA) [7] making significant progress in text modeling, topic model research entered a rapid development stage. Shortly after that, researchers successively proposed the Dirichlet Multinomial Mixture (DMM) [8, 9], Biterm Topic Model (BTM) [10] and Correlated Topic Model (CTM) [11]. These models have higher text processing efficiency and field subdivision than LDA.
Based on previous research experience, we reviewed more than a hundred papers on topic models to analyze and summarize the common topic model modeling method [12–14]. The research result can provide the novices with preliminary guidance and research progress of topic models. Obviously, many researchers [15–23] have also reviewed topic models. In particular, Fan et al. [24] reviewed the short text topic model from the improvement, classification, application, etc., to provide a comprehensive reference for the study of the short text topic model. However, this review only focused on short texts and didn’t analyze on the general application of the topic model. Robertsus et al. [25] reviewed the topic model that aims at social media from methods to evaluation. They classified the topic model through the features (content, social interactions, and temporary aspects) used by the models and analyzed the datasets and indicators commonly used in model evaluation. However, this article lacks an introduction to the development and evolution of the topic model and only introduces the topic model that deals with social network text. It is difficult to provide good guidance for novices. Tan et al. [26] analyzed the latest research progress in emotion analysis based on data processing techniques, classification methods, datasets, etc., and made prospects for developing emotion analysis methods. However, this article did not conduct a performance evaluation of emotion analysis methods, making it difficult to demonstrate various methods’ performance advantages and disadvantages clearly. And the introduced methods only focus on emotion analysis and do not have good generalizations. The above articles often reviewed the topic model from a specific perspective. They lack a whole-cycle perspective and contain several inadequacies regarding the model types and evaluation indications. We systematically studied the topic model method from the research progress, datasets, evaluation indicators, performance experiment, and application fields to provide a whole-cycle perspective for the topic model research. Through the above research work, we summarized the topic model into the following three categories: traditional topic models, word vector-based topic models and neural network-based topic models.
In traditional topic models, Meng et al. [27] utilized a hybrid doctor recommendation model based on an online medical platform to recommend the most suitable doctor according to patients’ needs. Shi et al. [28] adopted a dynamic topic modeling method based on self-aggregation (SADTM) to capture topic distribution and aggregate short texts, which achieved topic feature mining for short text. Toubia et al. [29] proposed a topic model for innovative document research, providing auxiliary assistance for writing these documents. The traditional topic models rely on the information provided by the corpus for topic inference. Therefore, it is generally difficult to achieve good results when using these models for topic inference of social network short texts. Researchers have introduced word vectors technology to overcome the above weakness in topic model modeling. Das et al. [30] utilized multivariate Gaussian distribution to replace the topics parameterized representation of LDA in Gaussian LDA (GLDA) modeling. It improved the processing performance of out-of-vocabulary words in held-out documents. Li et al. [31] adopted the Generalized Polya Urn (GPU) model to enhance the semantic relevance under the same topic during DMM sampling. It directly extended DMM to the Generalized Polya Urn Dirichlet Multinomial Mixture (GPU-DMM). Yao et al. [32] proposed Knowledge Graph Embedding LDA (KGE-LDA) by embedding knowledge graphs in the topic modeling process, significantly improving semantic coherence. The word vector-based topic models basically don’t alter the assumptions and sampling methods of the benchmark model and cluster similar documents by using word vectors. This type of model solves the problem of sparse topic words in short texts, improving the document aggregation and classification accuracy of topic words. With the development of neural networks, some scholars found it could better utilize semantic similarity between words by using neural networks during topic modeling. Based on neural networks, Cao et al. [33] proposed the Neural Topic Model (NTM), which overcame the weaknesses of topic distribution singly and initialization sensitively. The NTM combined the words and documents efficiently under a unified framework. Wang et al. [34] utilized the Topic Attention Model (TAM) to solve the issue of representing topics only by words in the standard topic model, which reduced the perplexity of document modeling. Yin et al. [35] utilized the Spatial-Temporal LDA (ST-LDA) to enhance the inference ability for personal interest in different regions, thereby recommending higher-quality interest points for users. Miao et al. [36] proposed the Neural Variable Document Model (NVDM), which performed semantic analysis on discrete texts. The neural network-based topic models no longer use the distribution assumption and sampling method of the probabilistic topic model. These models use neural network nodes or weight matrices instead of distribution assumptions and use algorithms (i.e., backpropagation [37, 38], stochastic gradient [39–41], and adagrad, etc.) for model parameter training. In addition, the neural network structure can also be combined with word vectors for topic modeling, which improves the utilization of semantic similarity between words.
The main contributions of this paper are as follows: We comprehensively discussed the topic model method, including its development process, evaluation indicators, performance experiment, application status, and other elements, to provide a whole-cycle perspective for studying the topic model method. The paper can help novices understand the topic model method quickly and accurately. We assessed the research developments for the topic model in recent years, discussed the topic model’s current problems and potential solutions, and provided reference information for the correlational study. All the above work indicated the direction of future research for scholars. After reviewing various topic models within the previous five years, we compared and summarized the application fields and advantages of frequently used topic models. This information can give reference for researchers to select the topic model in their research interests. We collected and compared the widely used datasets for indicator evaluation to further study the topic models’ primary evaluation indicators. Meanwhile, we proposed the critical evaluation basis for the datasets and indicator selection criteria in the performance evaluation of the topic model.
This paper is organized as follows: The typical topic models’ relevant work and research progress are summarized in section 2. We compare and analyze the evaluation indicators for the topic model and the corresponding selection criteria in section 3. In section 4, we mainly analyze the statistical results of topic models through experiments and introduce their applications in different fields. The challenges and their development trend are analyzed in section 5. Finally, we conclude the paper with research progress, evaluation indicators, and application field of the topic model; In addition, we prospect the application of graph neural network (GNN) in topic modeling.
Related work and research progress on typical topic models
Typical topic models include traditional topic models and those integrated with deep learning [42–44]. Traditional topic models include LDA, DMM, CTM, BTM, and others, which provide essential methods for natural language processing and information retrieval. However, these models perform poorly in text mining, document classification, and processing of social short texts such as Twitter, microblogs, and Facebook. To overcome the above issues, scholars have proposed improved topic models [45–48], such as the supervised Latent Dirichlet Allocation (sLDA) [49] and Latent Feature-Biterm Topic Model (LF-BTM) [50]. In particular, to solve the short text sparseness, topic models based on deep learning have been proposed, such as the Correlated Gaussian Topic Model (CGTM) [51], Affinity Regularized NMF for LTM (NMF-LTM) [52], and Neural Sparse Topic Coding (NSTC) [53] model. We summarize the topic model parameters and their explanation in Table 1.
Topic model parameter and its explanation
Topic model parameter and its explanation
Introduction and comparative analysis of four common benchmark models
In 2003, Blei et al. proposed the first complete probabilistic hierarchical topic model based on the research for the pLSA model. It consists of the following three layers: document, topic, and word. The LDA connects all the document parameters through the probability generation model. The basic assumptions of LDA are as follows: According to document set D and the prior parameters α and β, the topic assignment sequence Zd,w of the vocabulary in each document is inferred. According to the sequence Zd,w, the document-topic distribution probability matrix θ and the topic-vocabulary distribution probability matrix φ are obtained. In 2006, Blei et al. constructed an improved model based on the LDA by introducing a lognormal distribution and covariance matrix, which compensated for the shortcoming that the LDA cannot reflect the correlation between the extracted topics. Nigam et al. proposed the Dirichlet Polynomial Mixture Model (DMM), which was usually used to process short text. Yan et al. utilized the BTM to overcome feature sparsity issues in short texts. This method mines all word pairs from the text set and directly infers the topic on the biterm sets, compensating for the problem of short text sparsity.
The structures of the four models are shown in Fig. 1, and the probability formulas and application scenarios are shown in Table 2. According to Table 2, DMM and LDA are approximate in terms of time complexity, and both are lower than the BTM and CTM. The CTM has the highest time complexity due to requiring additional time to estimate hyperparameters from hyper distributions. The time complexity of the BTM is the second highest, and its complexity primarily depends on the biterm scale mined from the document set. When the BTM is applied to short text classification, the biterm set mined is small due to the characteristics of short text. So the time complexity of the BTM is close to LDA.
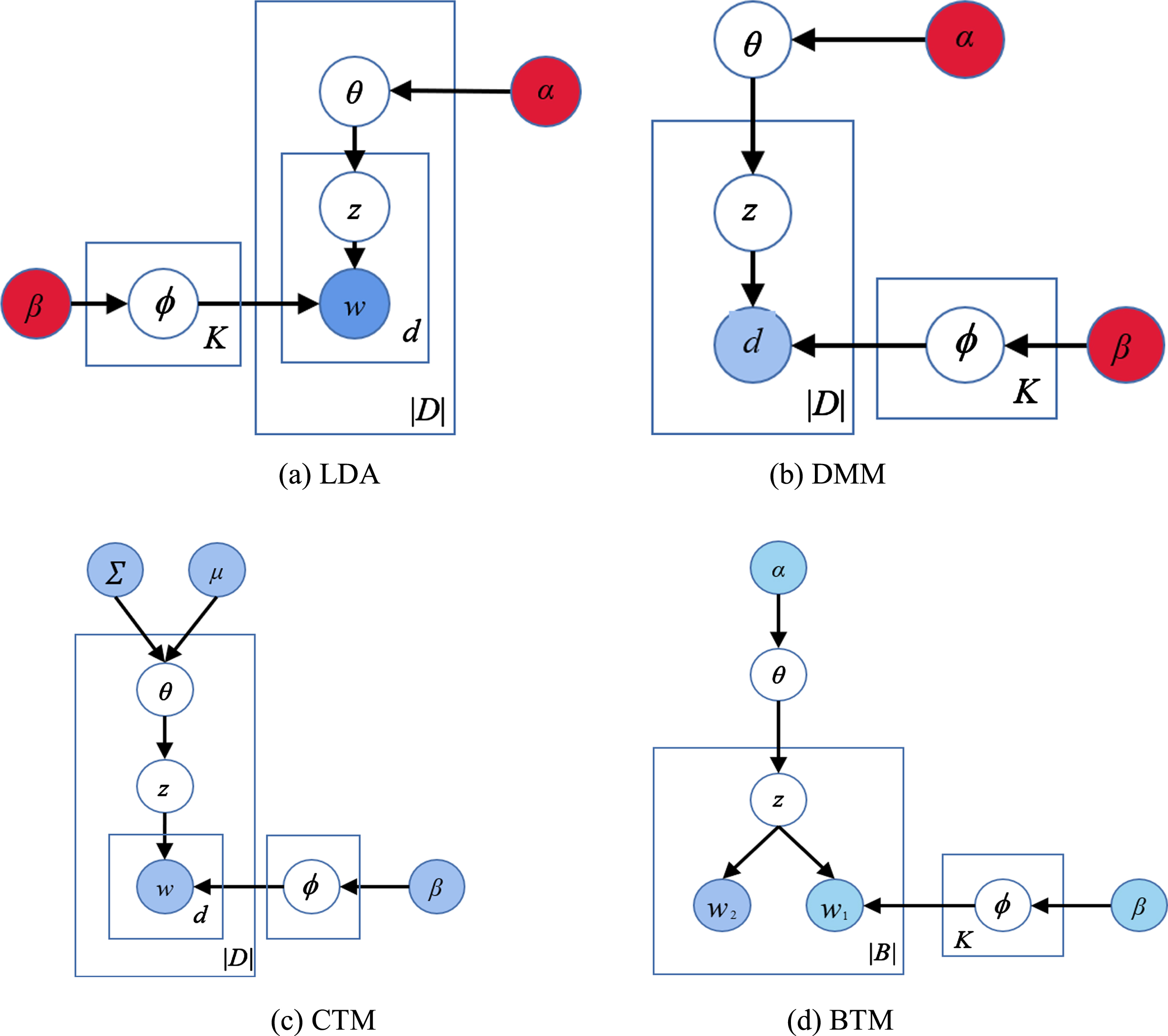
Structure of the topic model.
Topic model formula and its application scenarios
Topic models have contributed to researching information retrieval and natural language processing. With the continuous accumulation of data on the Internet, the current basic topic model has difficulty meeting scholars’ research needs in relevant fields. Therefore, scholars have explored the ways of improving and optimizing the basic topic model with a high matching degree to meet the actual needs of their professional research [54–57]. We summarize the advantages, disadvantages, parameter learning methods, and application fields for some extended models in Table 3.
Basic model extension
Basic model extension
(1) AOTM
Research on user preferences mining has received extensive attention with the rapid development of short video platforms (Bilibili, Kuaishou and YouTube) and social media (microblogs, Zhihu, and Twitter). Although the topic model is an effective tool for understanding text content, it cannot be directly used for user preference research due to two shortcomings: The first is that users’ comments are usually brief and severely lack data. The second is that users’ feedback is usually mixed with opinions expressed in the original comment. Therefore, Yang et al. [70] proposed the Author co-occurrence Topic Model (AOTM) for normal texts and users’ comments which were short texts (Fig. 2). This model allows each author of the short text to be in a group through considering the authorship, and it only represents a probability distribution on the topic of the short text.
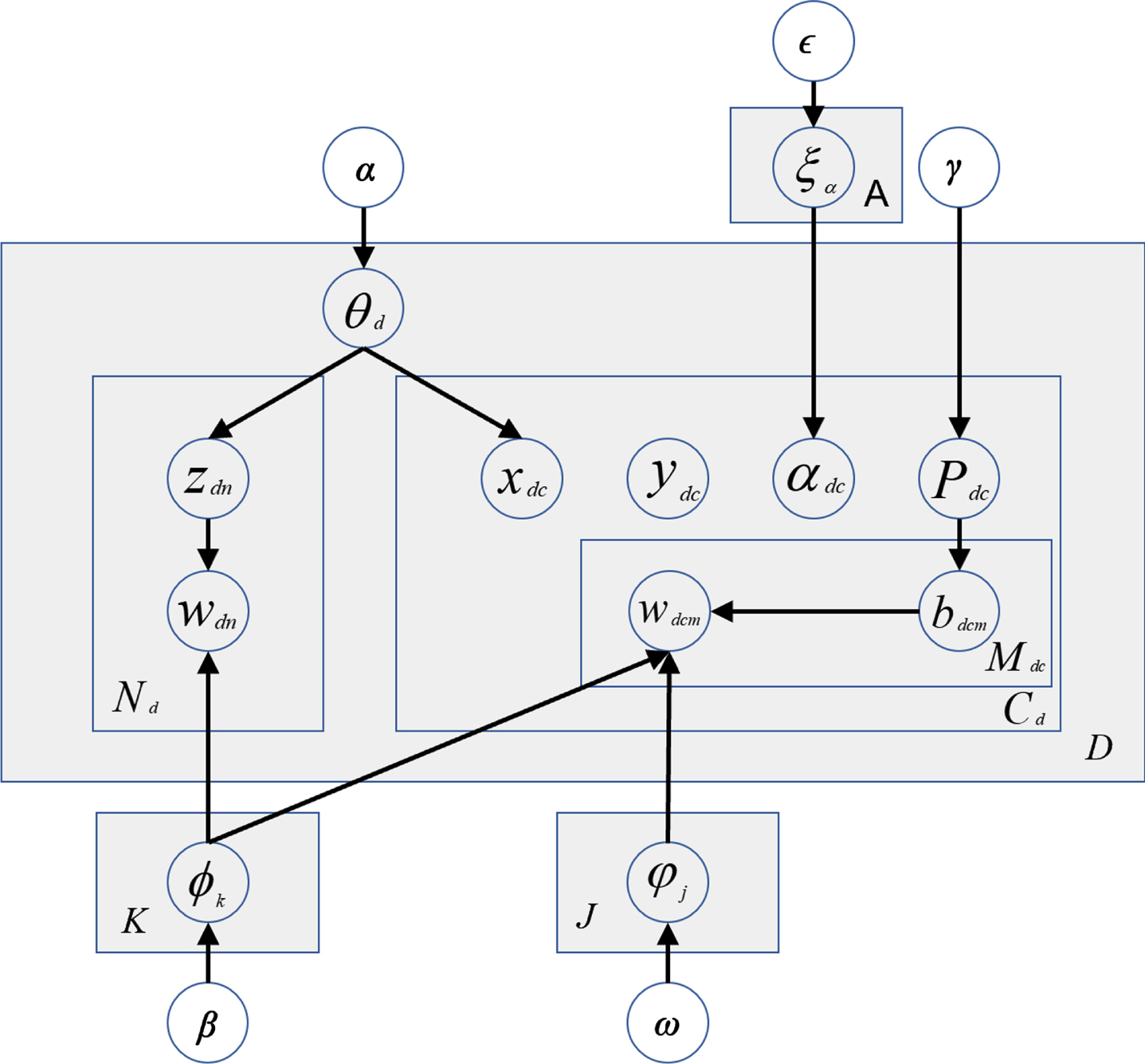
The structure of AOTM.
We describe the generation process of AOTM short text and regular text in Fig. 3.
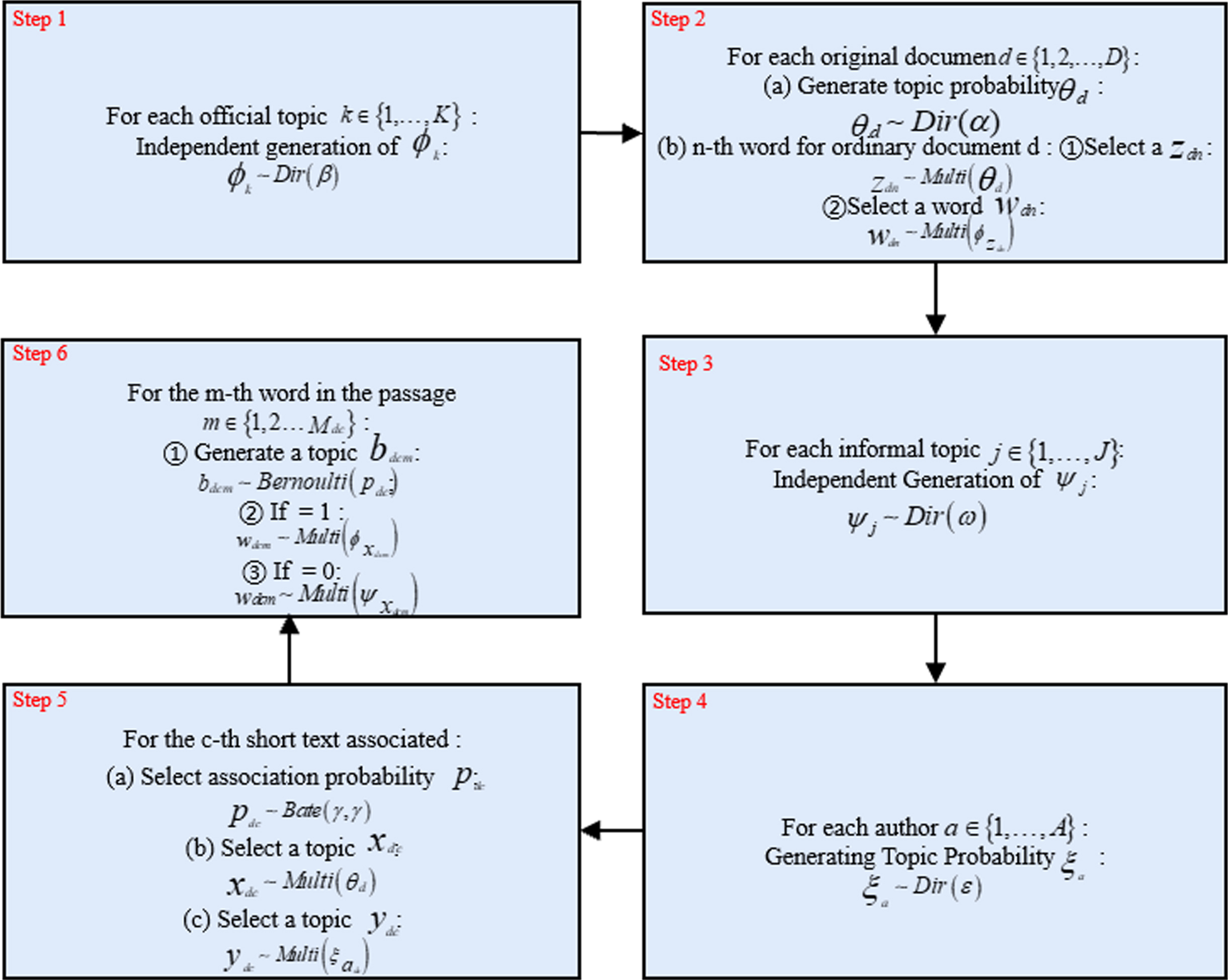
AOTM generation process.
According to the generation process of AOTM in Fig. 3, we can derive the complete posterior distribution with Equation (1).
(2) LTM
Li et al. [71] adopted the Latent Topic Model (LTM) to solve the overfitting and time consumption problems of SATM [72] in the large-scale corpus, which is a generalized topic model for short text mining. The LTM didn’t include the extra short text generation process. Li et al. considered that the extended text members were unknown. And they thought the short text was a part of the regular long text, which produced by the standard topic model. The LTM is shown in Fig. 4.
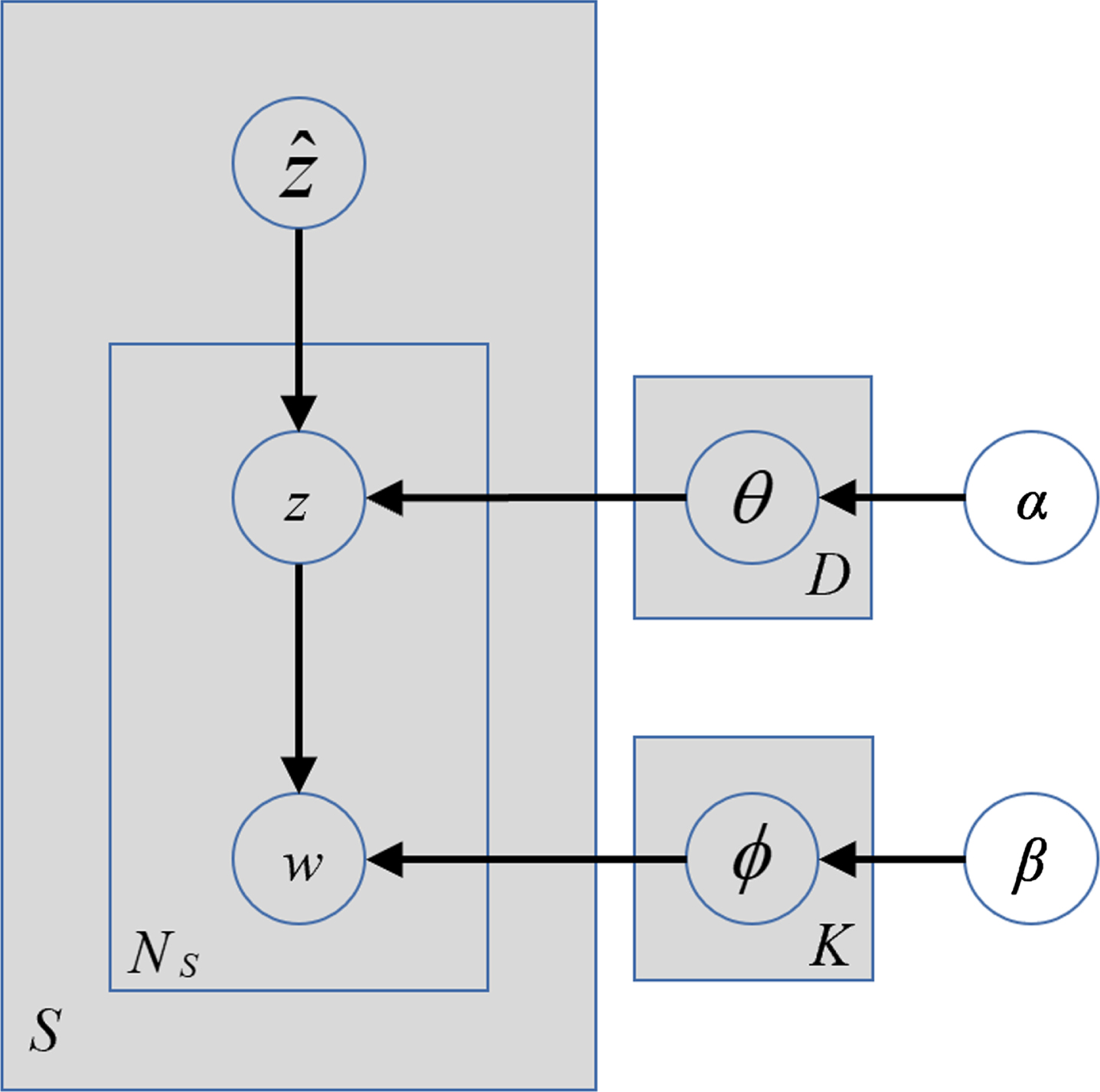
The structure of LTM.
In the LTM short text pair set, K represents the topics’ quantity, D represents the original documents’ quantity, and S represents the short text pairs’ quantity. The LTM generation process is shown in Fig. 5.

LTM generation process.
The posterior conditional probability of
The posterior conditional probabilities of z/K topics are given in Equation (3).
Traditional topic model primarily rely on word co-occurrence models to generate document topics without considering the semantic structure in general. Short texts have the issue of data sparseness due to insufficient context information, which makes processing it become a limitation of the traditional topic model [73–76]. Therefore, researchers enhance the topic models’ generalization capacity by word embedding technology [77, 78]. The generated topic words are more consistent semantically during the word embedding topic model which are utilized for short text processing. Researchers have proposed various topic models for multiple objects. Each word in the sentiment analysis text often carries emotional and topic information. While some words tend to represent subjective feelings, others tend to express objective truths. Guo et al. [79] proposed a Bias-Sentiment-Topic (BST) model for microblog sentiment analysis based on word embedding, simultaneously combined with the relationship between bias, emotion, and topic. In the research on community Q&A, it is challenging to propose a semantic embedded joint learning framework due to the multiview and sparse data characteristics of community Q&A. Based on the Bayesian model, Sang L et al. [80] adopted Multimodal Multiview Semantic Embedding (MMSE) to break through the research bottleneck of community Q&A. Gao et al. quantified the relationship between words in mining the topic evolution by the Encoder-only Transformer Language Model (ETLM). They also proposed a conditional random field regularized correlated topic model (CCTM) based on ETLM. The CCTM can simultaneously focus on the topic evolution of normal documents and the evolution law of the topic with time. Shi et al. [81] proposed the Cbow Topic Model (CTM), which can solve the high-dimensional data problem in large-scale event texts. This paper organizes the document-topic distribution, topic-word distribution, and the role of distribution representation learning of each model in Table 4. It clearly shows the similarities and differences between the topic models based on word embedding.
Comparison of auxiliary probabilistic topic models based on word vectors
Comparison of auxiliary probabilistic topic models based on word vectors
Traditional topic models are often applied to the semantic mining of long text. Due to the lack of word co-occurrence patterns and the topic feature sparse in short texts, it is difficult for traditional topic models to mine high-quality topics from short texts. To solve the above issues, Zhao et al. [86] utilized word vector representation and entity vectors to construct a Variational Auto-Encoder Topic Model (VAETM). The model generation process is shown in Fig. 6. The Variational Auto-Encoder (VAE) is an encoding-decoding network proposed by Kingma et al. [87]. In VAE, the encoder compresses the input data d into a potential feature z, and the decoder reconstructs the signal
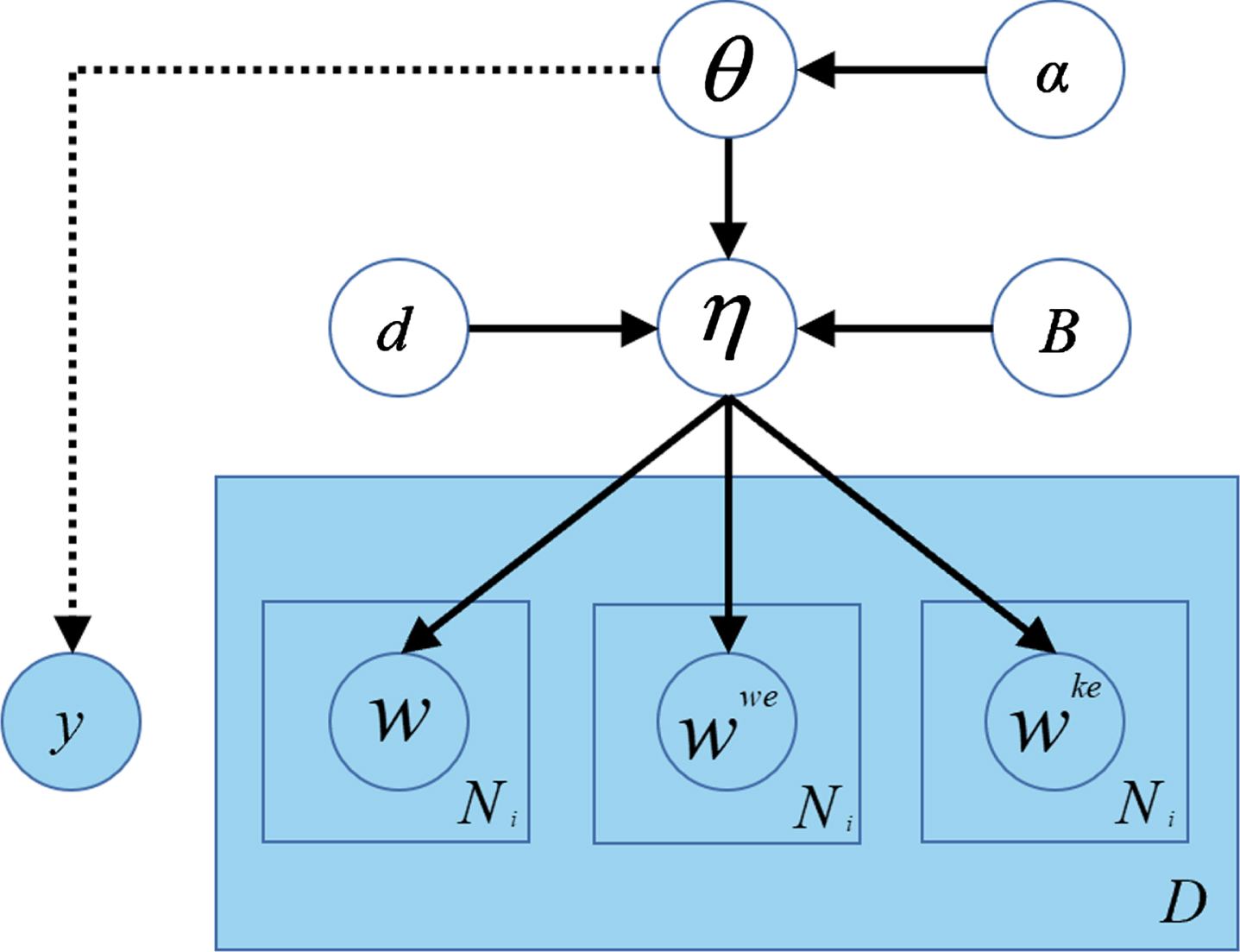
Generation model in VAETM.
In Fig. 6, the quantity of documents is expressed as D, the words in document i are expressed as W, the number of words in document i is defined as N, the word vector in the document is expressed as
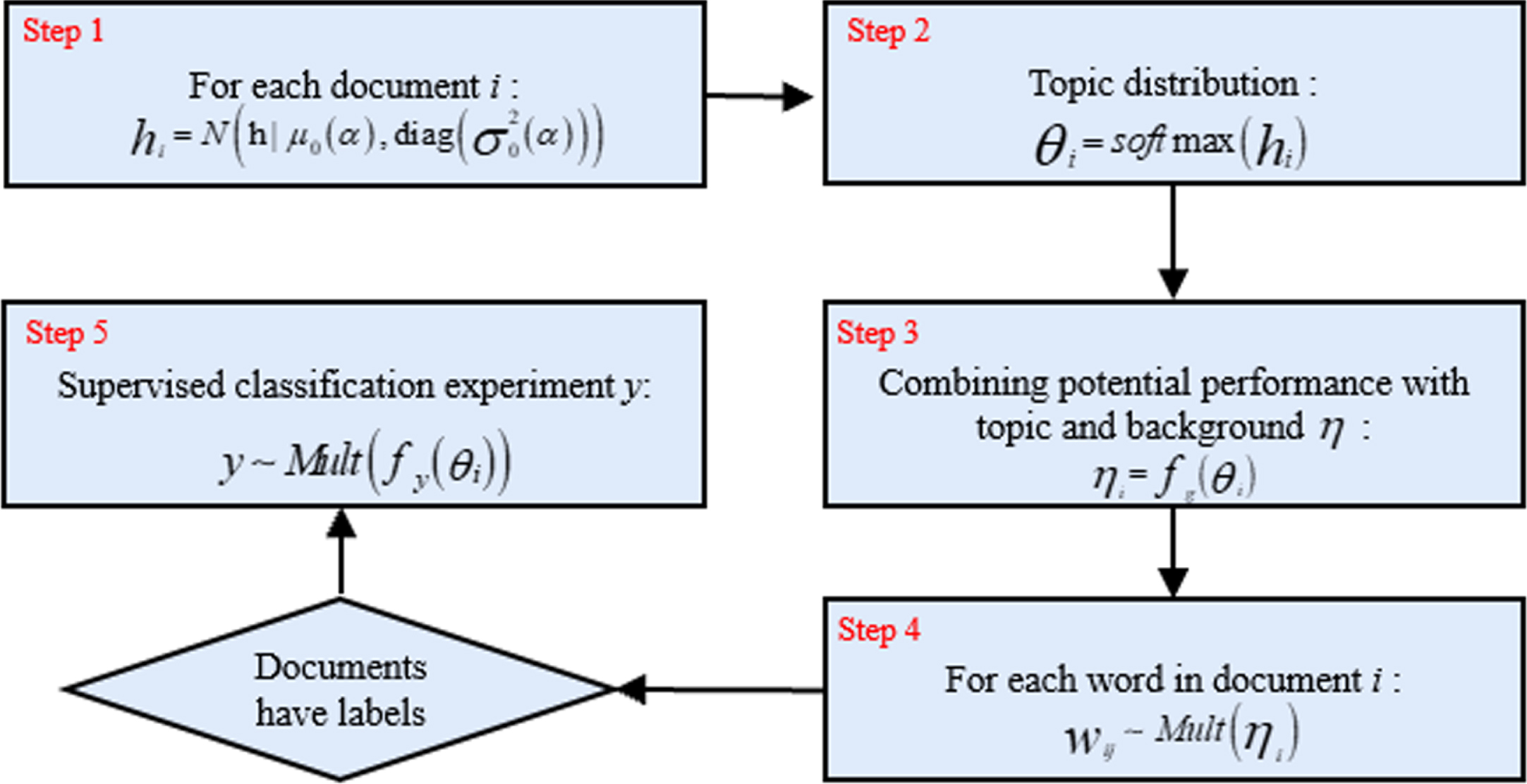
The generation processes of VAETM.
The objective function of the VAETM is expanded to Equation (4).
The traditional topic models obtained the correlation structure between potential topics with a logical-normal distribution instead of the Dirichlet prior. Word embedding was proven to capture semantic rules. So the semantic relevance between words can be calculated directly in the word embedding space, such as using cosine values. Xun et al. proposed a Correlated Gaussian Topic Model (CGTM) based on word embedding (Fig. 8). The CGTM is directly modeled in a continuous word embedding space through additional word-level information. This model replaces words in the document with the meaningful words for embedding, and established a multivariate Gaussian distribution model. Then, this model learns the topic correlation between continuous Gaussian topics. The generation processes of CGTM are shown in Fig. 9.
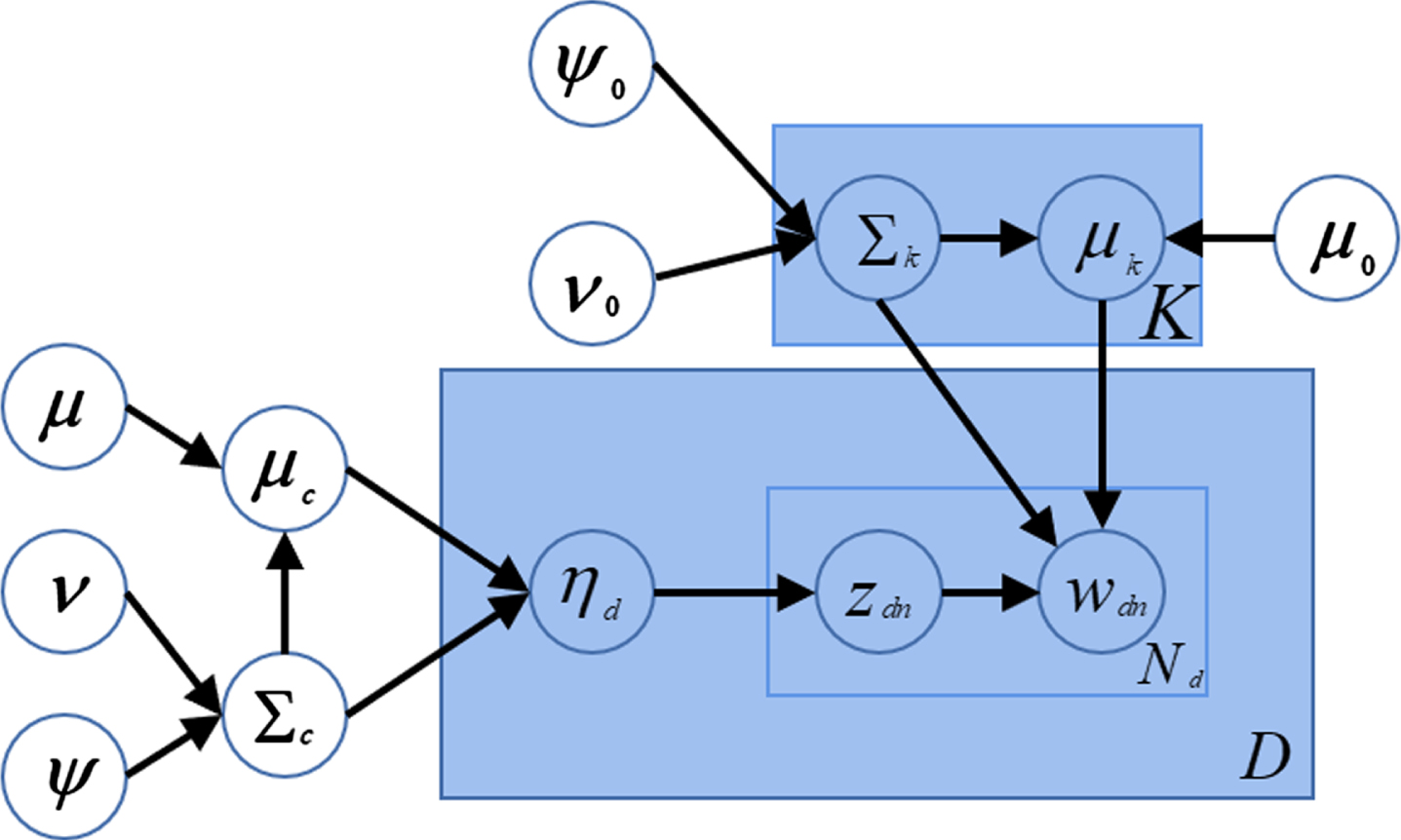
The structure of CGTM.

The generation processes of CGTM.
τ and
The neural network-based topic models characterized the text generation process that contains potential topic information with neural networks. In these models, they input data by document word bags, which added corresponding word vectors and other network layers to generate the document. Cao et al. combined feedforward neural networks to propose an NTM at the AAAI conference in 2015, which began the research on neural network-based topic models. Compared with the traditional topic model, the NTM has a simple structure and does not require prior assumptions. Meanwhile, it can obtain high-quality topic representation and accurate classification. With the occurrence of topic model construction from the neural network level, scholars proposed BERTopic [88], Context Reinforced Neural Topic Model (CRNTM) [89], Neural SparseMax Topic Models (NSMTM) [90], and other topic models [91–94]. This paper compares network structure, characteristics, and application fields of each model. The similarities and differences between the topic models based on conventional neural network structures are shown in Table 5.
The comparison of topic models based on mainstream neural network structures
The comparison of topic models based on mainstream neural network structures
In recent years, topic model combined with neural variational inference has achieved good effects. Compared with the traditional topic models, the neural network-based topic models often approximate marginal distributions through deep neural networks to obtain strong generalization capabilities. Due to neural network-based methods having unsupervised properties, it is a challenge to directly utilize the topic proportion of a specific document for downstream prediction tasks for optimal performance. Therefore, Wang et al. proposed a TAM (Fig. 10) for supervised neural topics by recurrent neural networks (RNN). The model designs a new method in the attention mechanism, utilizing the percentage of topics in a specific document and the global topic vector learned by the neural network topic model. The TAM model adopted the word bag representation of Gaussian Softmax Construction (GSM) and the word label sequence of RNN for document input. The GSM fits the generation process of the document to estimate the specific topic distribution t. The sequence of word label
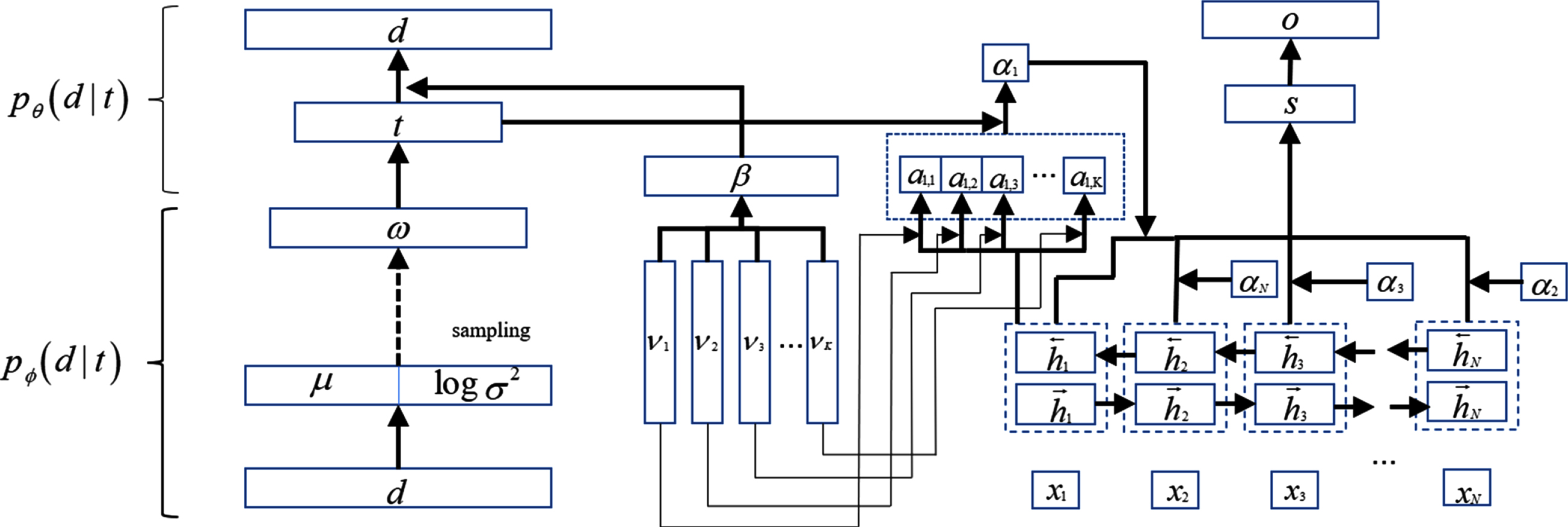
The structure of TAM.
The left part of Fig. 10 is an unsupervised neural network-based topic model through variational autoencoder learning. The right part is a supervised RNN model that encodes the input words by Bi-GRU. The two parts are jointly learned by backpropagation inference, and the joint distribution is shown in Equation (6).
Although the NTM performs well in extracting interpretable potential topics and text representation, there are two significant limitations: 1) The feedforward neural network has a shallow structure. It is often difficult to consider the contextual information of the entire text, resulting in insufficient ability of feature representation. 2) The sparsity of feature representation in the topic’s semantics space is neglected. To overcome the above problems, some researchers proposed the NSTC, NSMTM, and Semantic Reinforcement Neural variational Sparse Topic Model (SR-NSTM) [97]. The SR-NSTM (Fig. 11) utilized the parameterized probability distribution of a neural network to construct the text generation process. Meanwhile, it combined a bidirectional long-short-term memory network to embed contextual information at the document-level. Because the LSTM can effectively capture long-term dependencies between words, it is often used in document-level semantic coding. The generation processes of each document in the SR-NSTM model are shown in Fig. 12.

The structure of SR-NSTM.

The generation processes of SR-NSTM.
Equation (7) is the calculation method for maximizing the probability of word counting w in the document during the generation process.
Recently, scholars paid attention to methods that can efficiently evaluate the effectiveness of topic models. Currently, the performance evaluation methods of the topic model mainly include perplexity, topical consistency, categorical clustering, topic significance, topic diversity, topic distance, and others. The generally used datasets for performance evaluating of topic models are shown in Table 6.
Generally used datasets for performance evaluating of topic models
Generally used datasets for performance evaluating of topic models
The perplexity indicator is usually applied to evaluate the generalization ability of the topic model. Generalization ability refers to the adaptability of the topic model to unknown data. The lower perplexity, the stronger the generalization ability of the language topic mode. And the higher the modeling accuracy, the better the model performance. The perplexity formula of the language model is shown in Equation (8).
Topic consistency is one of the important indicators for topic model performance evaluation. It evaluates the model’s performance through the consistency between the topic words. Furthermore, the ability to generate simple topic words is also one of the evaluation indicators of this method.
Topic cohesion
The cohesion score is essential for quantitatively evaluating the topic’s semantic consistency [98]. The keywords with semantic consistency often appear in the same document. And the topic cohesion can be utilized to evaluate the consistency between each discovered topic automatically. Particularly, for the specific topic z, the T words most relevant to the topic are denoted by
The topics’ quantity is K, and the words’ quantity most related to topic k is T. Pointwise mutual information [99] (PMI) and normalized pointwise mutual information [100] (NPMI) are expressed as Equations (10) and (11).
Clustering purity and entropy are often used to evaluate the quality of topic detection. Many researchers have verified that the topic detection rate is positively correlated with the clustering purity, and is negatively correlated with the clustering entropy [101]. The calculation formula of cluster purity is shown as Equation (12).
The calculation of the cluster entropy for cluster i is defined in Equation (13).
Artificial evaluation method
Evaluation indicators such as perplexity are less effective for some document sources with complex and unlabeled text corpora. Therefore, in this case, a manual evaluation is often more reliable. The manual evaluation method is subjective in evaluating whether the topic is meaningful. Researchers usually utilize this method directly analyzing the semantic understanding of the most relevant 5 to 10 topic words, which were generated by the language model to obtain the subjective evaluation of the topic model.
Semantic retrieval ability
The semantic retrieval ability of the topic model is usually evaluated to assess the semantic expression and modeling ability further. This method uses the modeling results in semantic retrieval: The query sentences are utilized to retrieve the social network information, and then the query sentences are sorted according to the similarity with the information searched. Finally, the topic model retrieval ability is evaluated according to the retrieval results returned by the model. Some scholars utilize the topic-word distribution and topic-time distribution, which generated by an algorithm, to calculate the producing probability of query sentences for each piece of information. They also adopted this probability to evaluate the semantic retrieval ability of the algorithm. The probability is higher, and the semantic retrieval ability is stronger.
This section introduces several key indicators of the current topic model evaluation from different aspects, and provides the basis for the model performance evaluation. However, due to the different application conditions of each indicator, the correlation between each indicator impacts the evaluation results. Therefore, in practical application, researchers still need to select the optimal evaluation method to assess the model’s performance according to the reality. If necessary, a multi-indicator evaluation method should be integrated based on the correlation between each indicator, which can achieve the optimal effect for evaluating the topic model’s performance.
Statistical analysis results and applications of topic models
In this section, we mainly analyzed the statistical results of the topic model through experiments, and introduced its applications in different fields.
Statistics data analysis results
To analyze the statistical results of the topic model, we constructed multiple sets of experiments by using the Sina Microblog dataset. PMI is adopted as an evaluation indicator in the experiment.
Dataset
This performance evaluation uses the Sina microblog as the experimental dataset. Sina microblog contains a large amount of short text data, with a total of 200 000 pieces of data. This dataset is composed of data crawled from Sina microblog using users as random seeds. Each obtained information only contains textual information, retaining the original microblog content and excluding the corresponding microblog reporters. Simultaneously delete blog posts with no more than ten words, including word segmentation, removing inactive words, and deleting words that appear less than seven times.
Evaluating indicator
PMI is one of the critical indicators of topic model consistency evaluation, which can well reflect the model performance. Table 6 shows the generally used datasets for performance evaluation of the topic model. The calculation method of PMI is shown in Equation (10).
Experiment setting
We set the topic number K to 50 and 100, respectively, and calculate the PMI of the representative models selected from the three types of topic models. Among them, the representative models selected from the traditional topic model are LDA, LTM, and GSDMM; The word vector-based topic model selects UMHE, CTM, and HTMH as representative models; The representative models selected for the neural network-based topic model are DSSM, GRNN and UATM.
The result and analysis of the experiment
The results of PMI with K varying from 50 to 100 are shown in Table 7.
Comparison of topic coherence
Comparison of topic coherence
From Table 7, we can see that the performance of the neural network-based topic model is better than the other types. The main reason is that the neural network-based topic model mainly uses deep learning technology to reconstruct the model text generation process and uses the sparse constraint of topic vocabulary to enhance the quality of topic words in the modeling process. The word vector-based topic model performs worse than the neural network-based topic model in the Sina microblog dataset. The word vector-based topic model usually uses word vector technology to enhance the model’s generalization ability and then realizes high-quality topic extraction in a short text. The traditional topic model performs the weakest in all categories. The primary cause is that the traditional topic models are difficult to effectively learn contextual semantic relationships in text, so their semantic modeling ability is poor.
With the continuous development of the topic model in recent decades, its application fields are also extending [102–106], including the pharmaceutical industry, tourism, finance and other fields. The topic model from the retrieval and recommendation field, the cross-media modeling field, and the topic summary field will be introduced in this section.
Retrieval and recommendation field
With the development of the information era, search engines provide excellent convenience for users, allowing them to obtain information quickly. At the same time, the matching accuracy of query input and search results has become an essential indicator for evaluating search engine performance. Therefore, developers have paid great attention to search engines performance. However, most of the query users’ input is relatively short and usually contains a variety of retrieval intentions. So personalized retrieval can well meet the actual needs of users. In addition to considering the semantic similarity between documents and query sentences, the personalized retrieval method also combines users’ interests to obtain optimal recommendations. Thus, their interests, browsing history, and so on can be matched. Personalized retrieval is essential for a customized recommendation for answering queries. Recently, the research on recommendation algorithms has been increasing and deepening. Shi et al. [107] utilized a User-based Aggregation Topic Model (UATM) to research user preferences and intention distribution. They analyzed the collected Sina microblog user data and content delivery. Yin et al. proposed a Spatial-Temporal LDA (ST-LDA), which was a probability generation model of latent class. Firstly, the ST-LDA divides the geographical space into multiple regions. Then it infers the interest distribution of single user on series topics based on the content (labels, categories) of accessed Point of Interest (POI) in each region. The structure of the ST-LDA is shown in Fig. 13. It is a generative model of the user’s location, time, role and text in the check-in record. The ST-LDA can mine potential topics and regions, then realize the unified learning of different users’ interests and location preferences.

The structure of the ST-LDA.
Shao et al. [108] combined multimodal data with a comprehensive Sentiment-aware Multimodal Topic Model (SMTM) to achieve personalized and travel recommendation. The SMTM (Fig. 14) conducts topic mining from multiple fields, such as tourists’ subjectivity and attractiveness. In addition, the tourists’ emotional attitude toward classic topics is also included in the evaluation factors, and travel recommendations are made accordingly.
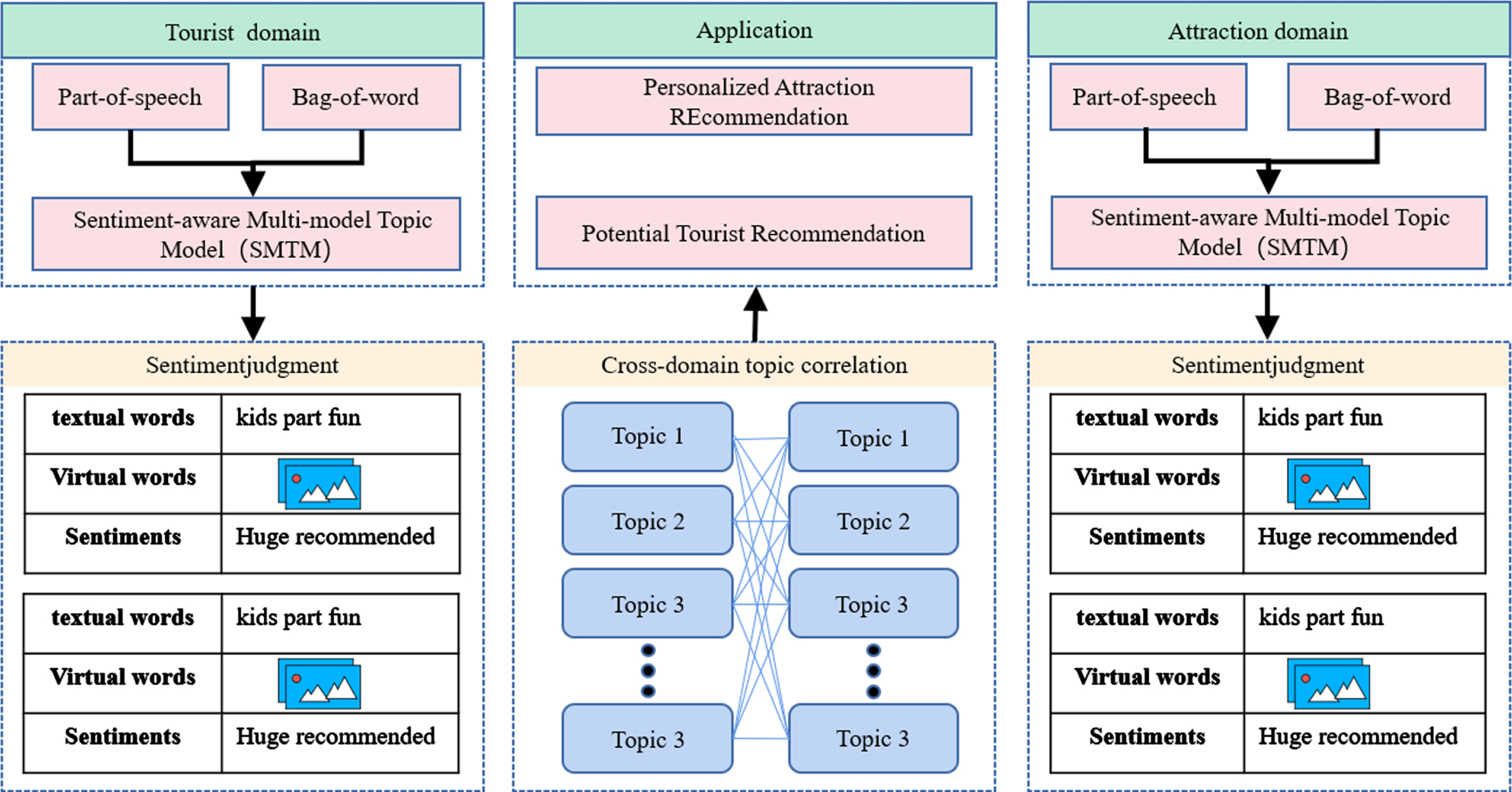
SMTM travel recommendation framework.
Online shopping is an indispensable activity in daily life. Meanwhile, providing a means for customers to discover their favorite commodity quickly is particularly important. The collaborative filtering algorithm generates recommendations through interaction rates between the user and the product. Na et al. [109] believed that the number of user tags could reflect user preference to a certain extent. Therefore, the collaborative filtering algorithm of User-Item-Tag Latent Dirichlet Allocation (UITLDA) was proposed. Compared with the users’ current comments, the previous comments have a relatively weak impact. So the delay function was introduced into the prediction calculation of UITLDA. It will accurately recommend commodities for users’ according to their preferences. The user project and label topic modeling process of UITLDA are shown in Fig. 15. Figure 16 shows that UITLDA infers the topic distribution aimed at users, their items and tags. It then combined two constraints into another new distribution.

UITLDA user project and label topic modeling process.
The modeling process of UITLDA.
The topic model’s application in the recommendation field is not only tourism and commodity recommendations. There exists a Space-Time Periodic Task (STPT) model based on simulated user log records in the remote sensing image recommendation field [110]. Chen et al. [111] proposed the Spatial-Temporal Embedding Topic model (STET) to compensate for the defects of the STPT model. Regarding forum recommendation, the cognitive load of online participants has increased dramatically due to the increasing number of posts produced in the forum. Peng et al. proposed a Sentiment and Behavior Topic Model (SBTM) to obtain the text content relevant to the participants’ concerns rapidly and precisely.
In topic recommendation, Kowald et al. [112] developed a cognitive-inspired hashtag recommendation method (BLLI,S) that involved the influence of time on personal and social topic tags in the prediction model. Ang Li et al. [113] proposed a Multiview Scholar Clustering Topic (MSCT) model that considered both scholar’s interest and double-view (internal and external) information with a clustering method for the accurate analysis of scholar clustering. It provided a reference for scholar recommendations. Furthermore, Zeng et al. [114] utilized a knowledge graph based on user perception to capture relevant news information and proposed a topic model applied to recommend accurate news for users. Meanwhile, Ji et al. [115] utilized a Social Period Aware Topic Model (SPATM) to distinguish user interests and social preferences. The SPATM achieved personalized venue recommendations for users. The topic model has a good recommendation application effect in the medical field. Yang et al. [116] proposed a doctor recommendation model based on the system decision model for considering patient preferences and opinions.
Modern information retrieval technology mainly includes single-media and cross-media information retrievals. Single-media information retrieval requires query words, and retrieval sets belonging to the same modality, such as retrieving text by text or retrieving image by image. Cross-media information retrieval integrates different modalities. It utilizes the associated information in other modalities to achieve retrieval of each other between additional modality information. Cross-media information retrieval has become popular academic research in the world. As an important development direction for information retrieval research in the future, it has received extensive attention from scholars [117–119].
A vital research field involves the cross-media data of mining and analyzing to solve the semantic gap. Adversarial learning methods [120, 121] are essential in image, text, and speech generation. New data distribution is promoted by establishing the adversary and game mechanism in the processes of generation and discriminative [122]. Liu et al. [123] proposed a Semantic Similarity-based Adversarial Cross-media Retrieval (SSACR) method in which two neural network models were trained with negative training. The SSACR method mainly includes input, mapping, distribution, similarity, and discriminative network. This method performs feature extraction, mapping, judgement and other operations on each image-text-semantic three tuple through the above network. At the same time, it minimizes errors. The overall processes of SSACR are shown in Fig. 17.

SSACR overall processes.
In modern information society, with the increasing diversity and diversification of social platforms and the rapid development of social networking services (SNS) [124–126], the new trend is building a shared content model based on multiple social networking websites to describe the same user. Liu et al. [127] adopted a CrossSiteLDA (c-LDA), which is a reliable cross-site user-generated content model to conduct test research. The test result indicated the model was better than the existing model regarding performance indicators such as confusion and semantic consistency.
In recent years, academia and commercial circles have paid extensive attention to research on Twitter topic derivation [128, 129]. Moreover, information interconnection and social platforms (YouTube, microblogs, and TikTok) play essential roles in the real-time spread of news events. However, the texts on Twitter and TikTok are short and informal, and the vector identifier vocabulary in these texts is extremely sparse. Therefore, the methods of accurately and comprehensively obtaining summary statements have become a popular research topic for scholars. Wang et al. proposed a Hashtag Graph-based Topic Model (HGTM) [130]. The HGTM (Fig. 18) regards the Twitter text as semi-structured and uses the label relationship in the label graph to mine the semantic relationship between words. This model utilized the Dirichlet prior hyper-parameters to calculate the topic distribution matrix of each hash label, and the word distribution matrix of the topic. The test result showed that HGTM has a solid ability to deal with the text sparse and noise problems on Twitter. Compared with the baseline model, this model can mine more specific and coherent topics.

The structure of HGTM.
In social networks such as Twitter, there are not only common topics but also occurrences of emergency topics (disaster news, rescue information, and leadership elections). Learning about emergency topics quickly and accurately can guide and control public opinion and online rumors. So scholars have proposed SATM, Burty Biterm Topic Model (BBTM) [131], Sparse RNN-Topic Model (SRTM) [132], and other topic models. However, it is often difficult to accurately locate emergency topics through the above models separately in the actual process. Therefore, Shi et al. [133] developed a modeling method based on RNN and social network emergency topic discovery (RTM-SBTD) to overcome this issue. The method consists of the following four parts: data preprocessing, RNN-based prior knowledge learning, sparse topic model construction based on the ‘spike and slab’ prior, and social network emergency topic discovery.
The RTM-SBTD method is compared with online LDA, BBTM, SARTM, and other methods regarding topic discovery accuracy, novelty, consistency, and quality. The results show that the RTM-SBTD method is better than other methods.
Although the current topic models have made significant progress compared with the primitive topic models, the following challenges still exist in the use of the topic model: Short text precise modeling. Existing topic models perform well when applied to typical corpora. Nevertheless, poor performance is unavoidable when it is used on short texts produced by social media platforms (Twitter, microblogs and so on), which tend to be colloquial, highly noisy, and nonstandard. In the future, external data from WordNet and Wikipedia can enhance short texts’ semantic analysis and processing. In contrast, internal data can reduce short text noise and improve the effectiveness of short text topic models. Fine-grained context semantic awareness. Bert has demonstrated its significant benefits in text summarization and keyword extraction, becoming the optimal technology to replace word2vec as a word vector topic model. With the continuous exploration and optimization of the topic model, Bert will be applied to text mining innovatively. Text generation applications for specific topics. Generative adversarial networks (GANs), as a joint training model, composes of generative and judgment models. It has been used in sentence-level text generation, such as single-text summarization and human-machine conversation. However, scholars should focus on improving the application of this technology in text generation for specific topics. Model semantic understanding. Research on knowledge graphs has accumulated abundant achievements. Scholars should integrate high-quality prior knowledge and rich document semantic information in the research results of the knowledge graph into the modeling process of the topic model to enhance the semantic understanding ability of the model.
Conclusion
The relevant work and research progress, evaluation indicators, datasets, performance experiment, and application field of topic model were systematically studied to promote the topic model’s development in this paper. First of all, we evaluated various topic models’ research progress and characteristics. Then we discussed four widely used basic topic models and briefly introduced topic models based on word vectors and neural networks. After that, common evaluation indicators were illustrated to provide a valuable reference for comparing and selecting topic model performance indicators and datasets. Meanwhile, we also compared and summarized standard datasets used in topic model performance evaluation. Moreover, we conducted performance evaluation experiments on three types of models by using PMI. The application status of the topic model in recommendation and retrieval, cross-media modeling, and topic summarization were introduced. Finally, we also summarized the problems in applying the topic models in various fields.
With the development of GNN technology, its solid semantic relevance and modeling capabilities have been shown. In the future, we will combine GNN with topic models to improve topic modeling capabilities.
Footnotes
Author contributions
G.C. constructs the framework of this paper and puts forward the writing idea of this paper. L.S., Z.W. and Q.Y. complete the analysis and summary of the research progress of the topic model. J.L. and T.L. provided opinions on the structure of the paper in the process of writing the paper. G.C., Q.Y. and L.S. conducted the overall writing of the paper. All authors of this article read the full text and agree to the published version of the manuscript.
Data availability
This article contains no data or material other than the articles used for the review and referenced.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant No. 42377200), the State Key Laboratory of Geohazard Prevention and Geoenvironment Protection (No. SKLGP2021K005), the Natural Science Foundation of Hebei Province of China (No. D2022508002), Suzhou Science and Technology Plan Project (SYG202034), Guangxi Key Laboratory of Trusted Software (No. KX202315), and the Innovation Capability Enhancement Plan Project of Hebei Province, China (21567693H).