
Abstract
Nowadays in China, Sina Weibo has become the most popular microblog platform and researches about it are proposed increasingly. In this paper, the problem of emotion classification of Weibo’s posts is addressed in a hierarchical way using a constrained topic model and Support Vector Regression (SVR). Based on this topic model which is variation of Latent Dirichlet Allocation (LDA), an implicit emotion detection algorithm is proposed to identify the underlying emotions. Meanwhile, the constraints are generated based on prior knowledge extraction approaches to compact LDA in order to generate domain-specified topics. Furthermore, a hierarchical emotion structure is employed to classify emotions more precisely into 19 classes. This hierarchy can meet different research granularities. The whole architecture is proposed aimed at alleviating the pain of misclassification caused by feature imbalance and decreasing the labor cost. The experiment results validate that our model outperforms traditional methods with precision, recall and F-scores.
Introduction
Due to the convenient networks and the fast-paced modern life, virtual social contact has turned into the major communication pattern for its flexible and interactivity. People upload posts to express their opinions and record daily lives on the social media platforms. Sina Weibo, the representative of Chinese microblog platforms, attracts millions of Chinese users to share their ideas, views and opinions together on it. The interaction of microbloggers such as thumping down a post or participate in a hot topic motivates them to update posts frequently. This makes microblog posts sufficient and valuable for companies and researchers. In conclusion, the extensive use of microblog has drawn attention of industry and academia, more and more scholars are making elaborate efforts on the relevant studies. Meanwhile, as sentiment analysis is always a hot topic in NLP, it is natural to apply sentiment analysis on microblog posts. However, there are many slang words and abbreviations in these mass messages due to the colloquial format of them. To cope with these informal texts with grammar and spelling errors is a challenging task.
To implement this task, the following challenges must be taken into consideration: First, microblog post is a kind of short text that it has a space constraints to 140 words. This length limitation makes it difficult for LDA to extract topics for the few word co-occurrence of each post. This leads LDA to generate broad topics and word sparsity since some useful wordpairs appearing with low frequencies will be ignored and some too common words are selected to many topics. Then, Chinese is a language with euphemistic terms and reserved manner. Consequently, many sentences in Chinese do not express microbloggers’ emotions directly but the holders’ opinions or feelings can be implied by contexts. Meanwhile, the online texts are full of internet lingoes and abbreviations which can not be recognised by unequipped models. In previous works, these implicit messages are discarded because distinguishing implicit subjective sentences from factual ones is a tough task for traditional methods. Last but not least, the huge amount of mass messages signifies the active demand to unsupervised and semi-supervised models to accomplish the tasks. As data grows, the manual annotation must be costly. To reduce the labor effort and imporve machine bootstrapping properly as much as possible is the key point of data preprocessing.
With these considerations, in this paper a novel emotion classification architecture is present to classify Weibo posts. We utilize a variational topic model based on LDA to reduce feature space’s complexity and train the model well. Then we choose SVR to be the classifier which can get the threshold automatically. SVR is a package in Libsvm [1] which can dynamically select the classification threshold instead of a fixed one in SVM. To obtain results with all kinds of granularities and satisfy different research needs, we expand our work with an emotion tree which contains 19 emotion classes. It is first proposed by [2]. Our goal is to build a model coping with corpus automatically with proper manual guidance.
To settle the problems raised above and apply to an actual application scenarios, our work highlights as follows: A semi-supervised model based on LDA is presented. LDA is a widely used toolkit in NLP and it is a three-layer bayesian networks which can describe the documents in a probabilistic way. In topic model, every document can be illustrated as a mixture of topic distribution while every topic is displayed as a word distribution. However, LDA will obtain too broad topics in short texts for there are not enough words to learn and build networks. Some constraints and pre-existing knowledge are prepared to guide topic model. The constraints can enforce the proper features into model because they extract prior knowledge from corpus. This constrained topic model is utilized to identify implicit emotions. This model can distinguish implicit emotions from factual ones persisting for smoothed training sets. At last, a hierarchical classification is proposed to filter a more pure corpus for each category.
The remaining parts of this paper are organized as follows. The next section is devoted to related works. Section 3 introduces the proposed approaches about detecting emotion classes. In Section 4, the experimental results are reported, evaluated and discussed. Finally, Section 5 presents our conclusions and future work.
Related work
The emotion classification of online reviews has been a hot topic in recent years. There are two main research lines in emotion classification: the lexicon-based ones [3, 4] and machine learning ones [5, 6, 7, 8]. The former are often based on lexicons and linguistic resources. These methods generally consider the frequencies of the opinion words nearing the aspects. Whether the feature is positive or negative relies on the opinion word nearby whose polarity is already labeled on the lexicons. Sometimes some common words will be classified to many categories or none of them. This phenomenon will lead many uncorrelated features to be gathered in the same cluster. In a way, these are rule-dependent methods providing fine-annotated lexicons.
Consequently, some researchers introduce topic model, attempting to solve this problem in a statistical way. Topic model describes a document as a component of topics each of which is a mixture of words. Topic model can be used to construct features, reduce data dimensions and form word clusters [9, 10, 11]. It is a sharp tool in NLP. LDA has been the most popular topic model since it is proposed. Due to the inception of these works, many variations have been proposed. In 2008, Mcauliffe and Blei proposed a supervised topic model sLDA [7] to predict movie ratings from reviews. And Brody and Elhadad presented an unsupervised research work [12] to extract aspects and determine semantic orientations. In 2013, topic model was first introduced to identify implicit features in Xu et al.’s work to accomplish opinion mining of product reviews [13]. Hu et al. presented an interactive topic model which allows users to iteratively refine the topics by adding constraints that enforce some sets of words to appear together in the same topic [14].
In this paper, we introduce a topic model with hard constraints to ensure each aspect relating to a single certain emotion class. Furthermore, we aim at building a more accurate training set, thus we apply the algorithm to mining the implicit aspects emotion sentences. The concept of implicit feature first appeared at Liu et al.’s work [15]. In their study, they mentioned the denifition: Implicit feature is a feature that does not appear in the review directly but can be implied, which means the feature can be deduced from the sentence. In their paper, they illustrated the concept of implicit product feature with a digital camera review: “The camera is too large”. They stated that ‘large’ is implied to the feature ‘size’ although the word ‘size’ does not appear in the comment. The feature ‘size’ is indicated by the phrase ‘too large’, so it is implicit. In this work, we incorporate the implicit aspect detection and topic model together to fullfill multiple subtasks in one procedure.
Methodology
Problem definition
Problem definition is formulized as follows:
So the posts containing emotions can be defined as
Framework
The framework is visualized in Fig. 1. First, the noises in the raw posts are deleted and preprocessing is proposed. Second, the preprocessed posts are segmented and refined as informative terms
The architecture of proposed method.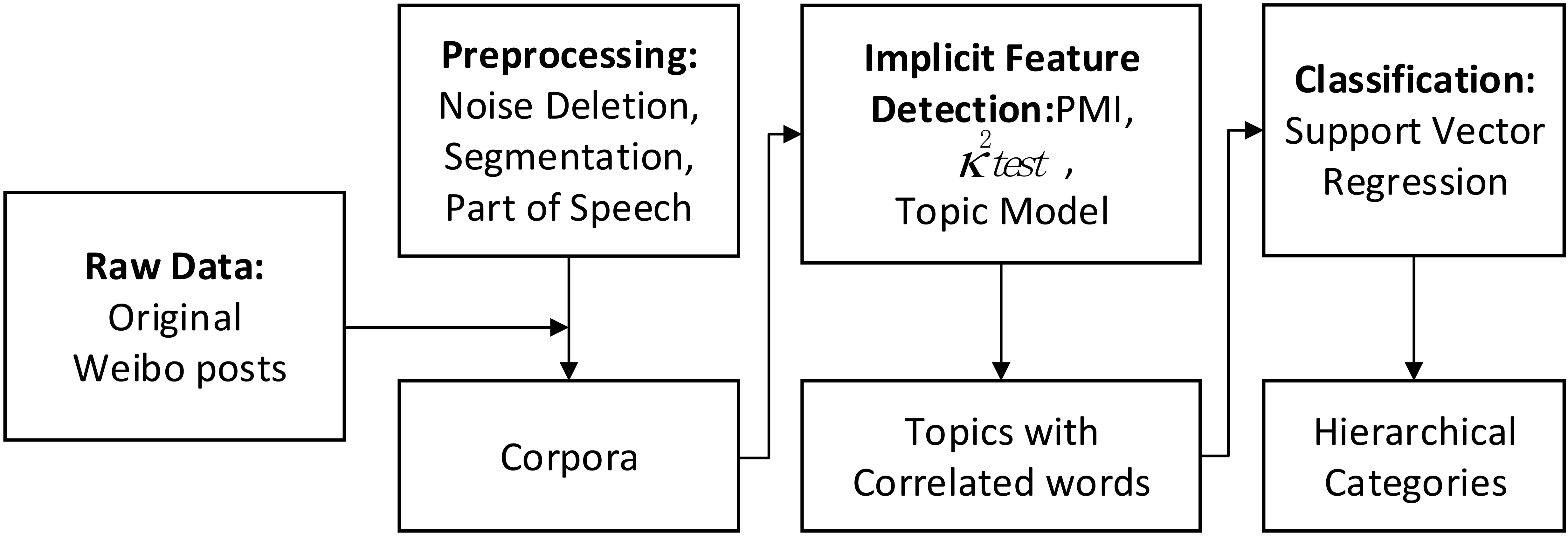
A microblog post contains not only the word strings, but also vedios, images, emotions, hashtags and so on. However, some of them are noisy for this research, so we delete the irrelevant elements which are useless for sentiment analysis in this work.
Reposted and repeated posts. The reposted posts are deleted while the users’ own comments are remained. Likewise, only one post of those repeated ones is kept.
Image and vedio. There are lots of images and vedios posted by users to illustrate their posts. However, they are helpless for this research and are definitely removed.
Username. Users often notify others by a symbol @ in their posts. For instance, “I do not agreed with you @BigEye”. ‘BigEye’ here is another user’s username. However, in this work, these usernames are definitely not affective. So the usernames and symbols are removed.
Hashtag. There are multifarious funny discussions on Weibo all the time. Users can participate in the discussion by adding the popular topics between two symbols # in the posts. For instance, “Scrambled eggs with tomatoes in which some sugar is added is my favorite. # What is the taste of Tomato scrambled eggs? Sweet or salty? #”. The topic segments are usually declarative sentences describing phenomena or questions arousing discussions. Surely they have no emotions, so the topics and symbols# are deleted.
Link. The links in the posts are linked to the further introduction of something. Obviously they contain no sentiments. These sentences starting with “http://” are deleted.
Position information. Position Information usually appears at the end of posts. These locations on the form of “I am here:” or “I am at:” are supplementaries but not for emotions. This kind of segments are removed.
Factual sentence. Factual sentences are declarative sentences which describe facts, e.g.,“Today is friday. It’s a cloudy day.” There is not any emotion in these sentences at all, so they are removed after implicit emotion detection. However, distinguishing factual sentences from implicit reviews is still a tough task.
Conflicting word or too common word. If a word relates to different emotions with high frequencies, it is defined as a conflicting word. It is possible that a word can describe several emotions or can not indicate any emotions. These words are noisy for classification and removed.
Feature etraction and selection
Choosing appropriate features is important for the following work. We first apply Part of Speech (POS) to select feature candidates. We employ the NLPIR,1 widely used segmentation toolkit in Chinese, to complete the tokenization. When people express their feelings, most of the vocabularies usually converge into nouns, verbs, adjectives and adverbs. So we select these kinds of words and remove others. Then we use the PMI and
Topic model is a generative statistical model which can detect the latent sementic correlations. The constrained topic model is derived from the basic LDA. In 2003, Blei et al. proposed a generative probabilistic model named LDA [9]. LDA can depict data in a statistical way. The basic idea of LDA is that documents can be represented as mixtures over latent topics where topics are associated with a distribution over the words of the vocabulary. Then the probability of each word
In this work, we expand the basic LDA with pre-existing knowledge which is derived from Andrzejewski and Zhu’s work [16]. We employ the concept of Topic in Set. For this scheme, the core process of inferring topics is updated as Eq. (4). In Andrzejewski and Zhu’s work, they set constraints for every word, which narrowed down the topic searching scope, facilitated the step of inferencing latent topics. Likewise, in this work we combine emotion lexicons to form the constraints. The constraint is formulized as the indicator
As Liu et al. first proposed in their work [15], sentences may imply sentiments but contain no emotions such as this post: “Tomorrow’s party is canceled. I have been waiting the whole summer for it. From now on, please do not talk to me!” There is not any emotion aspects appearing at the sentences. However, human beings can easily feel the disappointment of the reviewer. The emotion disappointment is implied in this post. Meanwhile, it is difficult to distinguish a factual sentence from an implicit emotional one for machines. Without manual annotation and priori information, machines are inclined to judge this posts as no emotions. At the same time, it is a high labor cost to annotate while the data increases. So we present an implicit aspect detection algorithm to identify these sentences and increase the accuracy of selecting useful data. Recently, some researchers commit themselvies to extract implicit aspects [4, 6, 13, 17, 18, 19, 20].
Our implicit detection method is applied to the first level’s classification. Algorithm 3.5 illustrates the processes. First, the explicit emotion sentences are selected to explicit data set
Implicit Emotion Detection[1] Select Explicit Sentences
Emotion classification
The four-level emotion hierarchy is presented to satisfy different research granularities. The first level distinguish the emotions from the statements, which can be implemented after identifying the implicit feature detection. Then the second-layer has two semantic orientations: positive and negative. The third stage’s categories are derived from the six-emotion structure which is mostly applied in previous works. Finally, the leaf nodes refine the six-emotion to 19 classes. Every upper level’s results can generate a good corpus for its lower level. Meanwhile, every level’s results impact their subclassifications vastly. The tree is presented in Fig. 2.
Emotion classification in four-level hierarchy.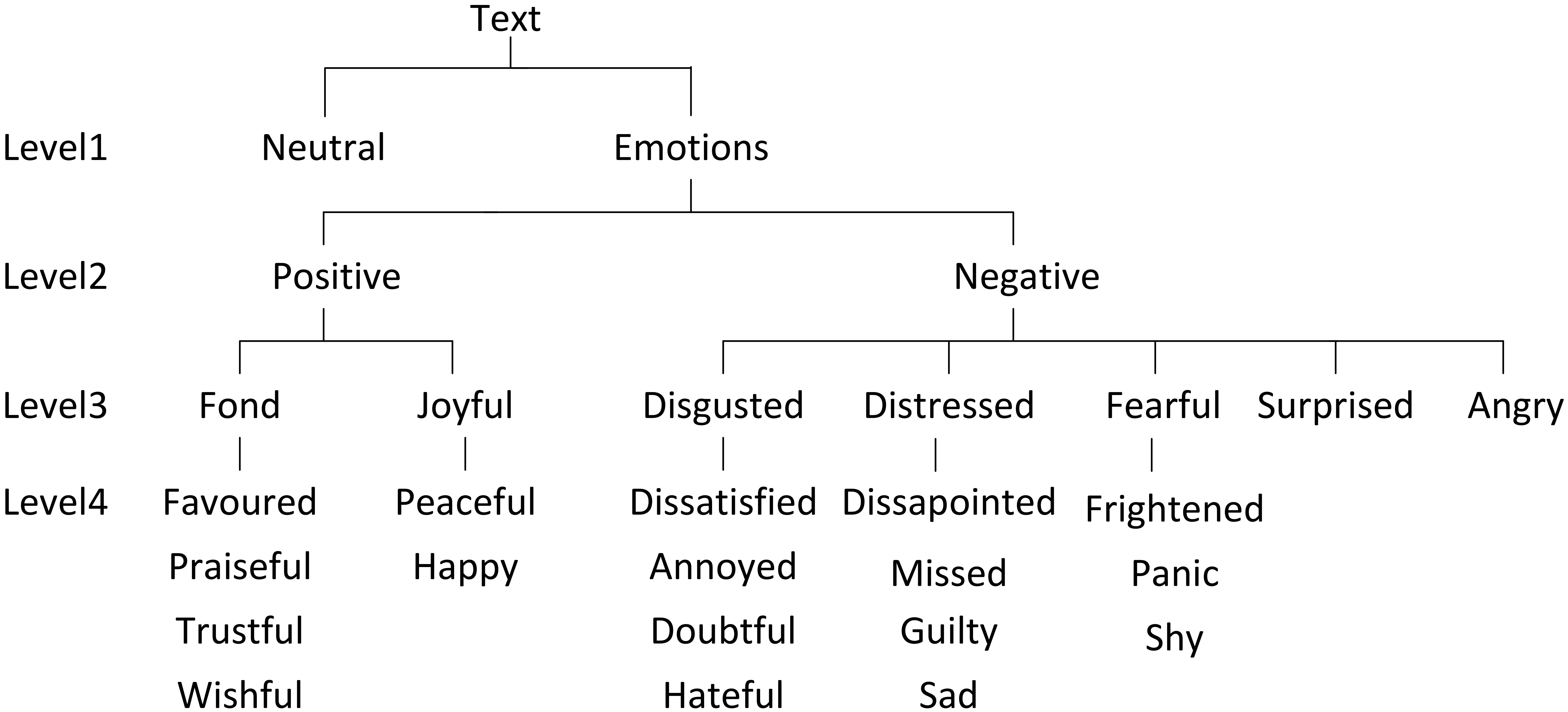
SVR is a particular implementation of support vector machines (SVM), a principled and very powerful method that in the few years since its introduction has already outperformed most other systems in a wide variety of applications [21]. In this work, a SVR package in Libsvm is employed to construct the hierarchy. While training, there are two parameters to investigate in SVR: model parameter
The procedures of obtaining classifier’s parameters.[1] initialize max_distance
Details of the microblog dataset
Data set description
As there is no benchmark of fine-grained classification for Chinese posts, we collect our data from Sina Weibo2 users’ posts. For data’s authenticity and practicality, we crawled posts and reviews randomly from 18:00 to 24:00 on June 5th, 2015. We collect 9976 posts after preprocessing. Three annotators marked the data separately. The disagreed annotations are finally decided by the first author. There are several principles for anotation:
The posts contains both implicit and explicit emotions are labeled as explicit. The posts with more than one emotions are deleted as noises. The implicit posts are labled seperately by three annotators and the disagreed ones are decided by first author.
There are about 39% of the posts are implicit. Meanwhile, the emotion with highest ratio is happy and it account for 7.83% of the data set. However, some emotions such as shy, hateful and guilty are much less than others. The data set is not balanced about emotions. So the hierarchical classification can prune irrelevant information and obtain a more pure training set for the further classification.
Sampling performance with different iteration.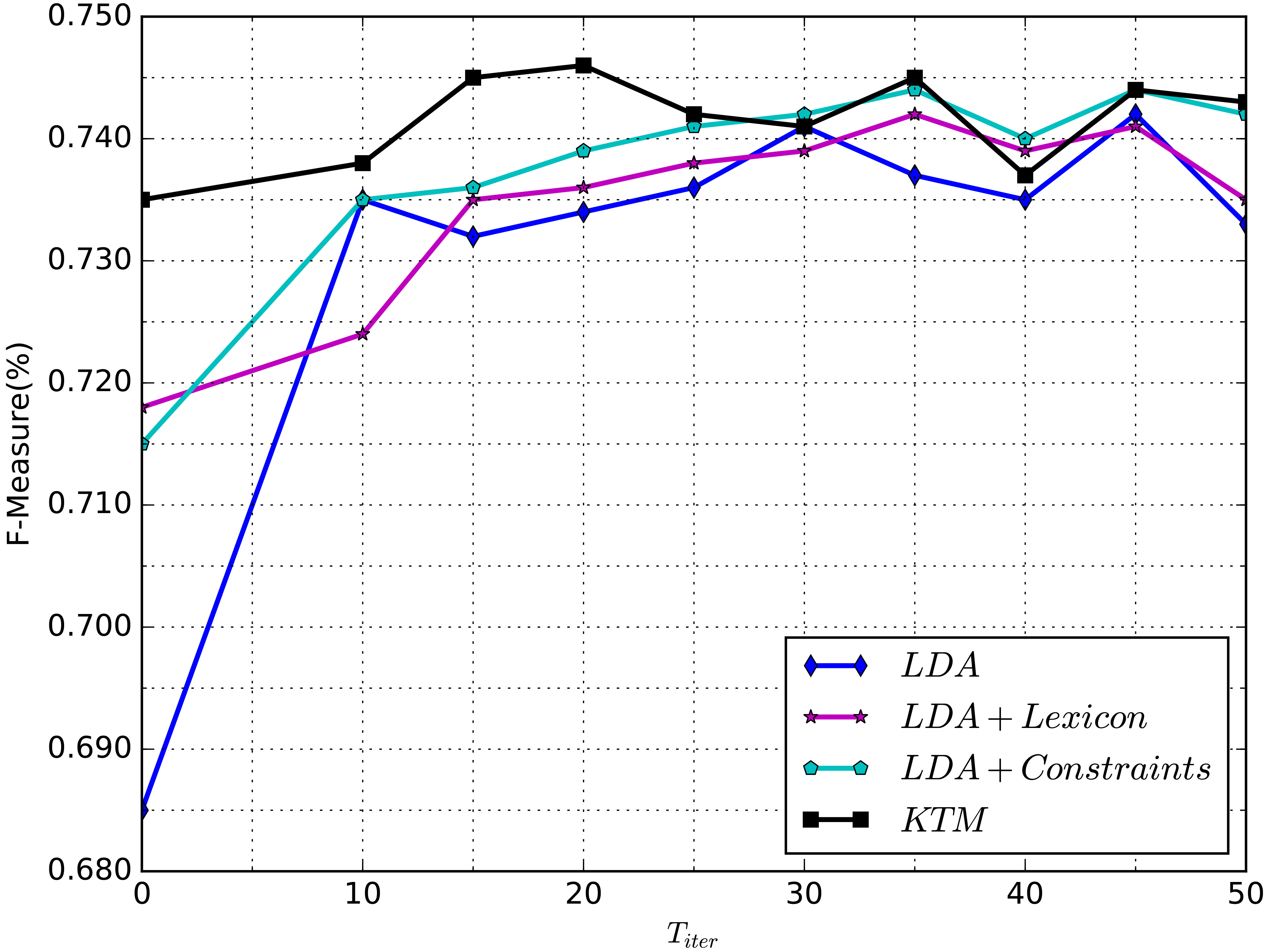
Constrained topic model under different document length.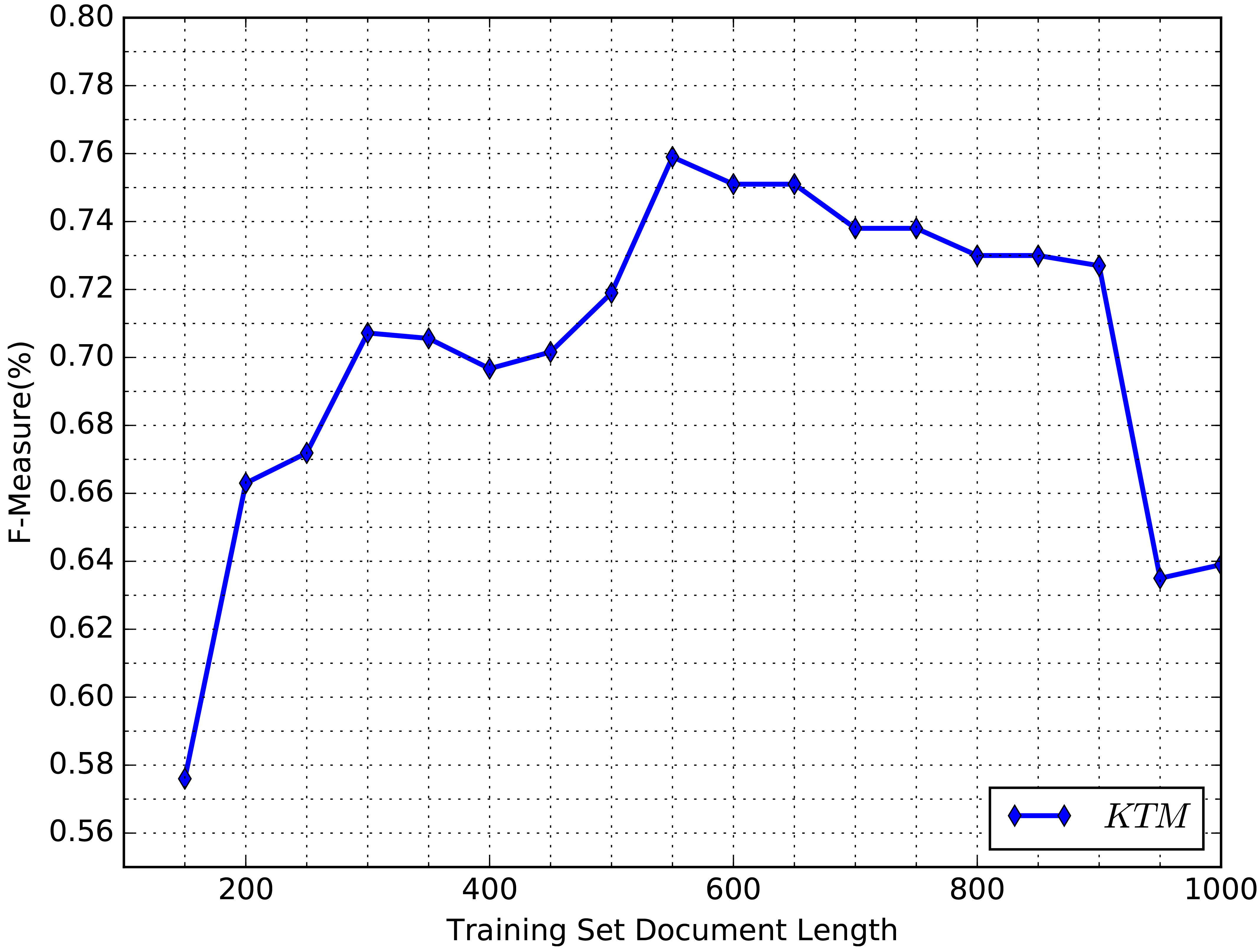
Tang et al. summarized the elements impacting the performance of LDA [22]. The length of document
Four test groups are set for comparison. F1-score are introduced to measure the results for it is a good standard for skewed classes problem. Group 1 applies the basic LDA to detect the implicit emotion posts. Group 2 introduces a dictionary containing 50,000 emotion words base on Group 1. Group 3 uses Topic in Set constraints and Group 4, the constrained topic model, adds on all the pre-existing knowledge. We apply the investigation to test implicit posts. Seen from the Fig. 3 we can get the conclusion that prior kownledge, including emotion lexicons and constraints, upgrades topic model perfectly.
Following the anotating principles, we manually annotate the data. There are 1622 posts are implicit. When users express their feeling, their expressions often converge to a specific vocabulary set. We list the high probabilistic words under each emotion in our corpus estimated by constrained topic model. These words can reflect the close correlations to these emotions. However, the corpus is just a small part of the short text online, the word associations might deviate from the reality. So the emotion lexicons and pre-existing knowledge enrich the representations of the model. Twenty top words are selected to help forming the training attributes and part of them are listed in the following ranking table.
Group setting
Group setting
Levels 1 and 2 results
Constrained topic model with different 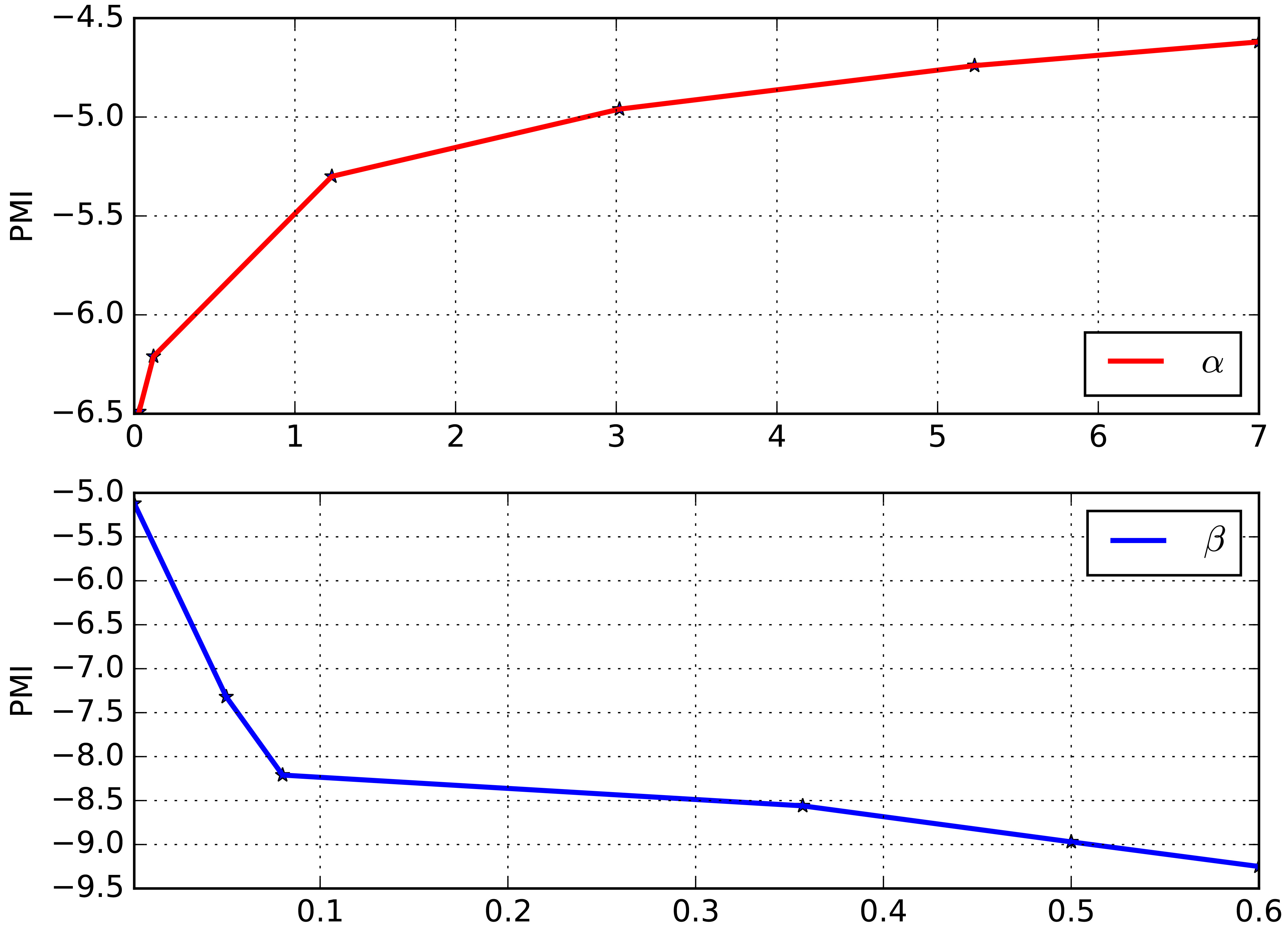
Levels 3 and 4 results
Hierarchical results
The whole model’s performance is reported in this section. We set four experimental groups (G1–G4). As shown in Table 2, Group 1 is only applied with basic LDA and flat classification. Group 2, in contrast, is applied with implicit feature detection. Group 3 is optimized by hierarchical emotion tree on the basis of Group 2. All the optimizations are adopted by Group 4. All of the results are the average values of 10 independent runs. In hierarchical classification, each test example is classified from the top level successively to the bottom level. The results, which are also level 3’s and level 4’s results, are presented in Table 4. Hierarchical classification can improve the performance of more than half of the classifiers. In flat classification, it is hard to distinguish the examples belong to its class and others when given the whole dataset for each classifier. Meanwhile, hierarchical classification cuts off most irrelevant examples by upper-level classifiers and makes it easier for lower-level ones to classify. As we can see from Table 4, the performance becomes better when applied with implicit feature selection and psychological emotion dictionary. The bold-font values represent the best results of the experiments in the result tables.
Every single classifier’s performance is illustrated by the level results. Every classifier is trained to identify instances between itself and its siblings. For example, when disappointed, guilty, sad and missed’s classifiers are trained, the training examples are inherited from their superclass distressed.
Table 3 presents the binary classification results on levels 1 and 2. The results show that Group 4, equipped with all the optimization methods, performs the best. Group 4’s F1-scores on Level 2 are almost 0.9 and its F1-score achieves around 0.85 on Level 1. The feature selection method’s efficiencies can be proved by the comparison of Groups 2 and 3. We can see that the latter outperforms the former, which filters many noises and reserves highly correlated features.
Table 4 displays the performance of third stage and the buttom. As seen from the table, a conclusion can be drawn that as the classes grows, the hierarchical classification has the main impact to experiment result while the implicit feature detection is not important so much as it has played a role in the first level.
The whole hierarchy’s result is proposed in Table 5. The difference between level results and hierarchy results is that the hierarchy is tested using the whole corpus and passes through this four-level structure from root to leavies. This result shows that in multi-classification problem, it weakens the classifiers as the classes grow and the dispersion of data to each category.
Conclusion
This paper has presented a hierarchical classification strategy to classify the emotions in micro-blog posts. Unlike many existing works, it applies a four-stage emotion structure, combining the proposed methods to obtain different emotion granularities. This classification method can decrease the inaccuracy caused by data imbalance. Meanwhile, it applies an implicit emotion detecting algorithm to identify the implicit emotion sentences. As we count from the data, there is almost 40% of the setences are implicit. The implicit detection algorithm is incorperated in the constrained topic model with pre-existing knowledge, which is called to extract features and reduce the dimensions. Results show that excellent performance is exhibited. As observed in the experiments, there are three aspects which can be improved in future work: 1) Users tend to display their funny experiences and positive attitudes rather than negatives. Consequently, this emotional imbalance calls for more accuracy training sets. Hierarchical models can generate the fine training data and meet this requirement. 2) It classifies the emotions at sentence level in this paper. However,the main emotion of the entire post may different from its sentences. How to get the correct emotions of the users will be solved in future work. 3) As seen from Table 1, the data size is not large enough which may have a main influence to the experimental results. More data are needed to validate the experiment.
Footnotes
Acknowledgments
This work is sponsored by National Natural Science Foundation of China (Grant No: 61673235).