
Abstract
In the era of big data, the complexity of data is increasing. Problems such as data imbalance and class overlap pose challenges to traditional classifiers. Meanwhile, the importance of imbalanced data has become increasingly prominent, it is necessary to find appropriate methods to enhance classification performance of classifiers on such datasets. In response, this paper proposes a mixed sampling method (ISODF-ENN) based on iterative self-organizing (ISODATA) denoising diffusion algorithm and edited nearest neighbors (ENN) data cleaning algorithm. The algorithm first uses iterative self-organizing clustering algorithm to divide minority class into different sub-clusters, then it uses denoising diffusion algorithm to generate new minority class data for each sub-cluster, and finally it uses ENN algorithm to preprocess majority class data to remove the overlap with the minority class data. Each sub-cluster is oversampled according to sampling ratio, so that the oversampled minority class data also conforms to the distribution of original minority class data. Experimental results on keel datasets demonstrate that the proposed method outperforms other methods in terms of F-value and AUC, effectively addressing the issues of class imbalance and class overlap.
Introduction
Data imbalance has always been a prominent problem in machine learning. When a dataset contains significant differences in the number of instances among classes, it is considered an imbalanced dataset. Specifically, a class with a larger number of instances is referred to as majority class, while a class with a smaller number of instances is referred to as minority class [1]. Because we mainly focus on minority class data in imbalanced problems, the minority class is commonly referred to as positive class and labeled with class label 1, while the majority class is referred to as negative class and labeled with class label 0. Class imbalance is a common issue in various real-life applications, such as credit card fraud detection, network intrusion detection, disease diagnosis, and spam email filtering,etc [2–5]. The number of minority data in these fields is relatively small, but it is more worthy of study than majority class data. However, traditional classifiers such as support vector machine (SVM), decision tree (DT), and naive bayesian (NB) classifiers tend to focus on achieving the highest overall accuracy, so all data are treated equally [6]. Consequently, the accuracy of classification on majority class data is high and the accuracy of classification on minority class data is relatively low, which cannot handle imbalanced datasets effectively. As a result, traditional classifiers are not effective in handling imbalanced datasets [7].
In addition to data imbalance, the classification of imbalanced data is often affected by class overlap and data noise [8, 9]. Some studies found that in some datasets, class overlap has a more significant negative impact on classifiers than data imbalance [10, 11]. This poses a greater challenge to deal with imbalanced data. In order to effectively address the issue of imbalanced data classification, researchers have proposed numerous methods. We categorize these methods into two main groups: data-level and algorithm-level. Data-level methods involve altering the distribution of the original data to balance the sample quantities. Common data-level methods include undersampling, oversampling, and mixed sampling. Undersampling achieves balance by reducing the number of samples in the majority class. However, excessive removal of majority class samples can lead to the loss of its inherent data characteristics, thereby reducing classification accuracy. Oversampling achieves balance by increasing the number of samples in the minority class. But simple oversampling approaches can lead to overfitting and introduce noise. Mixed sampling combines these two methods to alleviate the drawbacks of individual approaches. Algorithm-level methods primarily focus on modifying the classification algorithm directly. They are mainly categorized into cost-sensitive learning and ensemble learning methods. Cost-sensitive learning takes into account the cost of misclassification of each data point. So misclassification of minority class data will be assigned a higher cost compared to majority class data. Ensemble learning methods make decisions by combining the votes of multiple weak classifiers. However, algorithm-level methods often have limitations that require appropriate cost matrices designed for the dataset, and ensemble learning typically needs to be used in conjunction with data-level methods.
In the past few decades, several algorithms have been proposed to effectively improve the performance of classifiers on imbalanced datasets. SMOTE (Synthetic Minority OverSampling Technique) [12] algorithm has become a popular oversampling method since its inception. The algorithm generates minority samples by linear interpolation instead of simple random replication, which alleviates the problem of overfitting and partially address the problem of imbalanced data. However, SMOTE treats all minority class instances equally, which can lead to noise generation and alterations to the data distribution, ultimately increasing the degree of sample overlap [13]. To address this issue, Borderline-SMOTE (B-SMO) [14] divides minority class into three categories (safe, danger, and noise), and only oversamples the instances classified as danger to distinguishe the boundary and non-boundary regions of the minority class. Xu proposed an oversampling algorithm combining SMOTE and k-means (KNSMOTE) [15]. KNSMOTE clusters the minority data through k-means, then calculates the safe samples in the sub-clusters, and synthesizes new data by linear interpolation of the safe samples Lin [16] proposed a clustering-based under-sampling method (KmUnder): this method clusters the data in the data preprocessing stage, add the step of clustering the data before under-sampling, and the number of clusters remains the same as the number of minority classes. The cluster center or the nearest neighbor of the cluster center is used as the sample of the majority class and merged with the minority class to obtain a balanced dataset. Tomek Links (TL) [17] and ENN [18] are widely used for data cleaning. TL improves the classification performance of classifiers by removing Tomek links, while ENN enhances it by eliminating misclassified majority class samples.
In recent years, there has been an increasing number of methods using deep learning to address the issue of imbalanced data. Among these, a representative approach involves the use of generative adversarial networks (GAN) [19] to generate synthetic samples that resemble the original distribution. Ding [20] proposes a method based on the combination of clustering and generative adversarial network(TWGAN-GP). This method undersamples the majority class data by clustering method, and then uses GAN to generate minority data to achieve a balanced dataset. But GAN usually suffer from problems such as gradient vanishing and mode collapse, and are not suitable for dealing with discrete forms of data. The denoising diffusion model generates samples by adding noise to original samples and learning the reverse diffusion process, which is operable and flexible. Based on this, this paper proposes a method combining the improved denoising diffusion algorithm based on clustering and ENN algorithm to solve imbalanced datasets. The main contributions of this study are as follows:
1. We propose an improved denoising diffusion model, which uses ISODATA to preprocess the data before synthesizing the data to improve the distribution of the synthetic data.
2. We propose an improved denoising diffusion model. The reverse process is trained through the BP neural network to improve the learning ability of the model for discrete data.
3. Solve the problem of data overlap in imbalan-ced data through the ENN algorithm.
Preliminary theory
Dynamic clustering
Clustering is an important method for data processing, and it is also commonly used in unsupervised learning [21]. Systematic clustering methods do not allow for those samples that were misclustered before to be re-clustered, while dynamic clustering methods enable samples to move from one class to another. The dynamic clustering method is one of the widely used methods, which consider two concepts: (1) incrementality of the learning methods to devise clustering methods and (2) self-adaptation of the learned model (parameters and structure) [22].
Dynamic clustering first selects the initial point to obtain initial clusters. Then in the classification process, class centers are repeatedly calculated to update the cluster until certain conditions are met, according to some regulations. The framework of this process is shown in Fig. 1.

Basic process framework of dynamic clustering.
The ENN algorithm is an undersampling method that deletes samples closest to the minority class samples from the majority class samples. The basic idea of this algorithm is that noise and outliers in the sample space are isolated points far away from other normal samples, and minority class samples may be interfered by noise points, thereby affecting the performance of classifiers. Therefore, ENN algorithm deletes samples by judging the number of minority samples contained in the k nearest neighbors of the sample.
ISODF-ENN mixed sampling algorithm
The ISODF-ENN algorithm preprocesses minority class data using ISODATA. During the iterative process, the algorithm can search for the optimal clustering solution. Subsequently, the denoising diffusion algorithm is applied to each sub-cluster to synthesize new data. The new data synthesized from all sub-clusters constitute the new minority data. The sampling weight of sub-clusters is denoted as T.
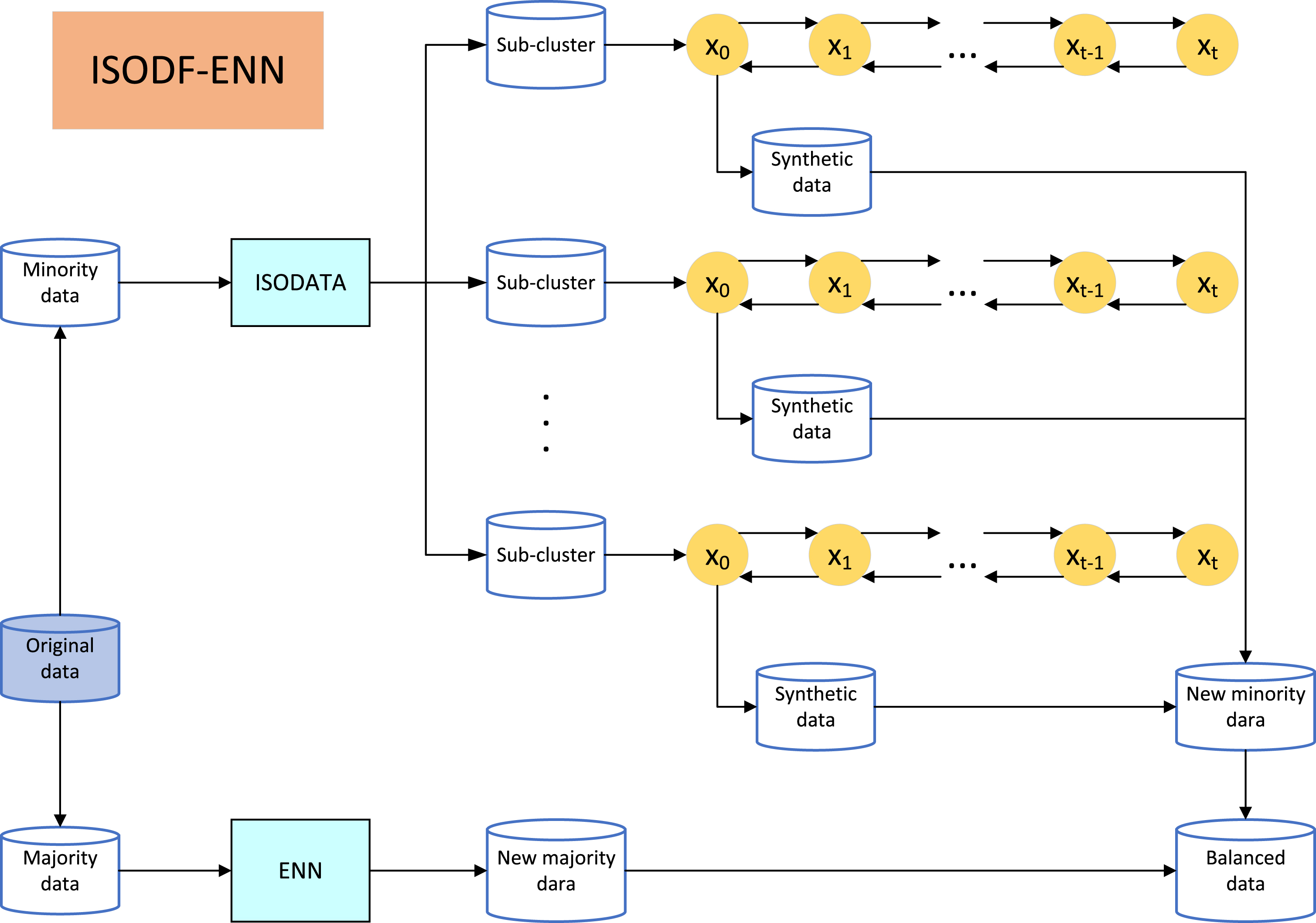
Basic process framework of ISODF-ENN.
ISODATA is a dynamic clustering algorithm, the k is set to different value according to different datasets [23]. Therefore, we need a suitable method to determine the value of k. Silhouette coefficient is a commonly used method to select the appropriate number of clusters, which is suitable for distance-based clustering algorithms. This method calculates the average distance a(i) from the sample point to other samples in the same cluster and the average distance b(i) from the sample point to other cluster samples. The definition formula of silhouette coefficient is given in Equation 3. The larger the silhouette coefficient, the better the clustering effect. The optimal k value determined by silhouette coefficient make the clustering of ISODATA algorithm more accurate for data clustering and improve the performance and effectiveness of classifiers.
ISODATA algorithm is improved on the basis of k-means algorithm. In order to obtain a better clustering effect, this algorithm “merges” or “splits” sub-clusters according to the parameters to form new clusters. The iterative process is shown in Fig. 3.
The iterative process of ISODATA algorithm.
The parameters that need to be determined and adjusted in the calculation are mainly include:
K: The expected number of cluster centers.
θ N : The minimum number of samples that a class should have, otherwise, this class should be cancelled.
θ S : A class sample standard deviation threshold, indicators of class division.
θ C : Distance threshold for clustering centers, the minimum distance between two centers.
L: Maximum logarithm of cluster centers that can be merged in an iterative operation.
I: Maximum number of iterations allowed.
In the initial stage of ISODF-ENN algorithm, it is necessary to preprocess the training set. That is, minority classes in training set are clustered to be divided into different sub-clusters. In this algorithm, the number of sub-clusters is determined according to silhouette coefficient for each dataset, and then oversampled according to the sampling ratio. The purpose is to eliminate the imbalance between different classes of the dataset and the imbalance between different sub-clusters of the same class to ensure the quality of synthetic samples and prevent overfitting.
For ISODATA clustering algorithm, the basic process is as follows: Input minority class data {x
i
, i = 1, 2, . . . , N}, preselect N
c
initial cluster centers {Z1, Z2, . . . , Z
N
c
}. Assign N samples to the nearest sub-cluster S
j
, if,
If the number of samples N
j
in S
j
is less than θ
N
, the sub-cluster is removed, and the number of sub-classes N
c
is reduced by 1. The samples from the removed sub-class are reassigned to the remaining sub-class with the smallest distance. Update each cluster center:
Calculate the average distance between the samples in each sub-cluster s
j
and each cluster center:
Calculate the overall average distance of all sub-classes to other classes:
Judgment of division, merge or cessation. If the number of iterative operations has reached I times, that is, the last iteration, then set θ
C
=0, and the algorithm ends. If If the number of iterations is even, or N
c
≥ 2K, the algorithm proceeds to the tenth step without any splitting. However, if neither of these conditions are met, it goes to the eighth step to perform the splitting. Splitting step: Calculate the standard deviation of the samples in each class. For each sub-class S
j
, the standard deviation is calculated by the following formula:
The individual components of the vector are:
In Equation 9, i = 1, 2, . . . , n is the dimension of the sample feature vector, j = 1, 2, . . . , N
c
is the number of sub-clusters, N
j
is the number of samples in sub-cluster S
j
. Find the maximum component σ
jmax
. For σ
jmax
, if σ
jmax
>θ
S
, one of the following two conditions is satisfied:
Merging steps: For all cluster centers, calculate the distance between any two cluster centers:
In the set, D
i
1
j
1
<D
i
2
j
2
< ⋯ <D
i
L
j
L
. Merge from the smallest D
ij
to get a new center:
If it is the last iterative operation, this algorithm ends, otherwise, if the operator needs to change the input parameters, this algorithm return to the first step; if the input parameters remain unchanged, the algorithm proceed to the second step. In this step, the number of iterative operations should be incremented by 1 each time.
Split the sub-cluster S
j
into two clusters, with the new cluster centers being represented by σ
jmax
plus Kσ
jmax
and σ
jmax
minus Kσ
jmax
. After the split, N
c
= N
c
+ 1. If this step completes the split operation, then the algorithm go to the second step, otherwise, it continues.

Denoising diffusion model also known as diffusion model. The diffusion model is a generative model based on Markov chains. The diffusion model disrupts the original data by continuously adding Gaussian noise and then learns to reverse this noise to recover the data. Therefore, the model consists of three parts: the forward noise-addition process, the reverse denoising process, and the training process.
Forward noise-addition stage
The forward noise-addition process gradually introduces noise to the original data until it becomes completely random noise. Given data distribution x0 ∼ q (x). Then the forward process refers to adding Gaussian noise to the data xt-1 at time t-1 to obtain x
t
, which is defined as q (x
t
- xt-1). As t increases, x
t
approaches pure noise. Given the hyperparameters of the Gaussian distribution, with a mean of
An important feature of the diffusion model is that x
t
at any time can be expressed by x0 and β. Define α
t
and
Through reparameterization, we can get any sample x t obeying the distribution q (x t |x0).
The noise adding process is shown in Fig. 4. It can be seen that as t increases, the original data gradually becomes random noise.
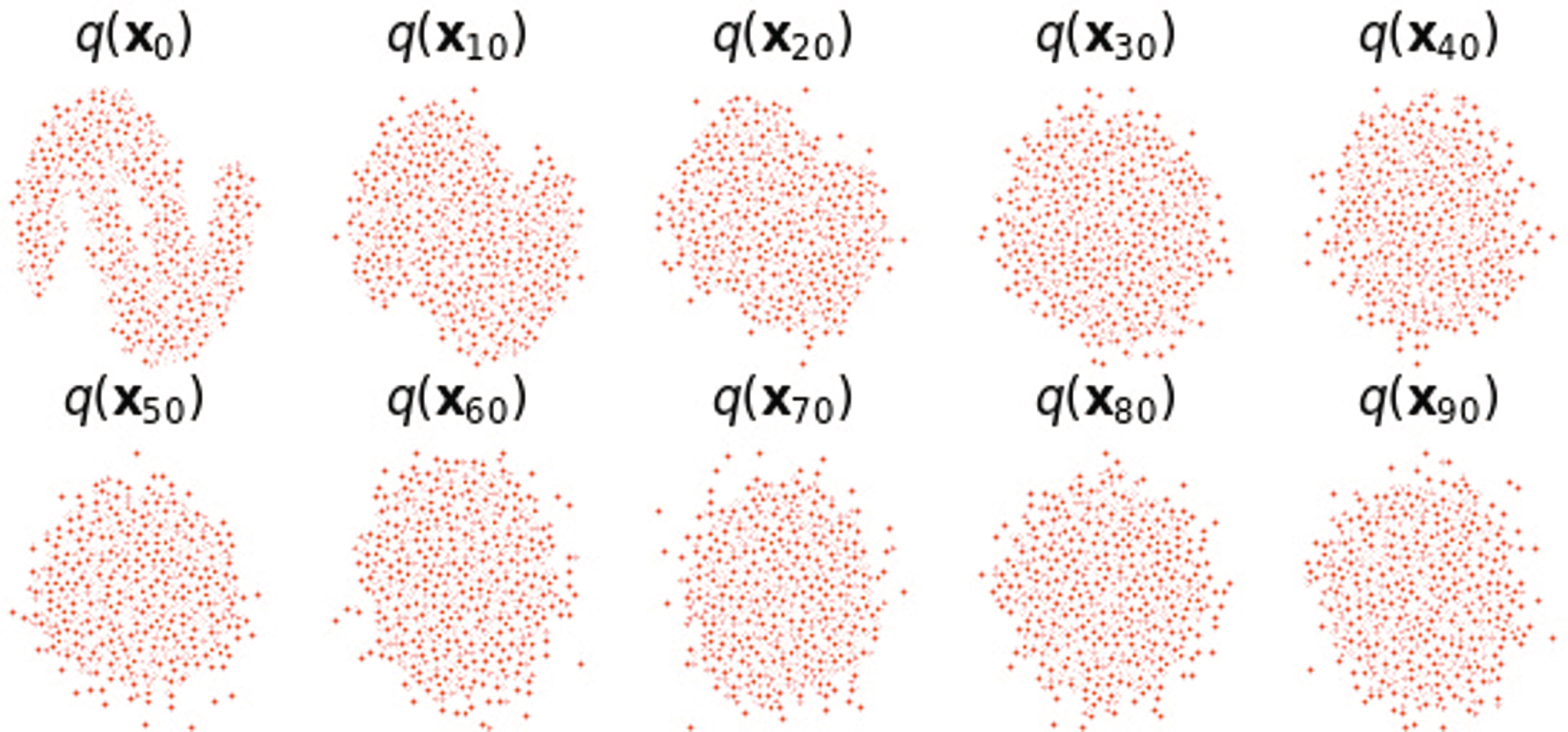
Data distribution after adding noise 90 times to the original data.
After adding noise, we need to restore the original data x0 from the complete standard Gaussian distribution x
T
∼ N (0,

Schematic diagram of noise addition and denoising in the diffusion model, q (xt-1|x t ) is unknown, and use deep learning to predict the probability distribution p θ .
Assuming that the noise removed by the reverse process also conforms to the Gaussian distribution, and the Gaussian distribution is determined by the mean μ
θ
and the variance ∑
θ
, then p (xt-1|x
t
) can be expressed as:
Combining all time steps, we can get:
Although we cannot get the reversed distribution q (xt-1|x t ), if we know x0, we can infer:
The mean μ
q
(x
t
|x0), variance ∑
q
(t) and x0 are:
We bring x0 into the mean.
It can be seen from Equation 22 and the definition of variance, the mean is dependent on the data, while the variance depends on a linear timetable.
The denoising process is shown in Fig. 6.

The data distribution of the noise-added data after reverse denoising.
We model the denoising process using neural networks, aiming to minimize the disparity between actual noise and estimated noise by maximizing the evidence lower bound of the variational autoencoder. This optimization enhances both mean and variance. The loss function is illustrated in Equation 23.
This algorithm uses Backpropagati (BP) neural network for noise prediction. BP neural network is a commonly used feedforward neural network, consisting of an input layer, a hidden layer and an output layer. Input data is passed through the network from the input layer to the output layer. Each neuron receives input from the previous layer, adds a bias variable through a weighted sum, and then performs nonlinear processing through an activation function to obtain an output. The error is propagated backwards from the output layer to the hidden and input layers by computing the difference between the output and the target. This is achieved by computing the gradient of each neuron and distributing the error to each connection weight.
To prevent overfitting, we use random deactivation. During the learning process of the neural network, the weights of some hidden layer nodes are randomly reset to zero. Since the nodes affected by zeroing are different in each iteration, each node of the neural network will contribute content. In this experiment, the coefficient of random deactivation is 0.5, that is, half of the neural nodes are deactivated randomly.
In imbalanced datasets, the number of samples in minority classes is very small, which makes them very susceptible to data overlap. As a result, the classifier cannot accurately distinguish between different classes. In some imbalanced datasets, the boundaries between minority and majority classes may be blurred. When data overlap occurs, conventional classification algorithms may be influenced by majority class, which will cause the minority class data to be ignored. Therefore, after minority class synthetic data, we use ENN algorithm to clean the data.
Time complexity analysis
The ISODATA clustering algorithm requires calculating distances between data points within each sub-cluster and distances between the centroids of different sub-clusters in each iteration. Therefore, the time complexity of the ISODATA algorithm is O (n2). The diffusion algorithm is applied to each sub-cluster to generate new minority-class data points. The denoising diffusion algorithm consists of a noise-adding process and a denoising process. The time complexity of the noise-adding process depends only on the step size and requires linear time. The denoising process involves training a BP neural network to reverse the noise-adding process, resulting in a time complexity of O (n2). The ENN algorithm needs to search for the nearest neighbor of each data, so the time complexity of this process is O (n2) Consequently, the time complexity of the ISODF-ENN algorithm is O (n2).
Experimental analysis
Experimental data
To examine classification performance of ISODF-ENN algorithm, this paper select 8 groups of imbalanced datasets on KEEL (https://www.keel.es) [24] for experiments. The number of these datasets ranges from small to large, and from slightly imbalanced to highly imbalanced. Table 1 gives the basic information of these datasets. The first list shows the name of datasets, and the second list shows the number of samples of datasets. The third list shows the number of features of datasets. The fourth list is the imbalance degree of the dataset, and the fifth list is the number of sub-clusters after clustering of the dataset. Formula 24 is the calculation method of the imbalance degree of datasets. Figure 7 shows the best k value for the dataset by silhouette coefficient.
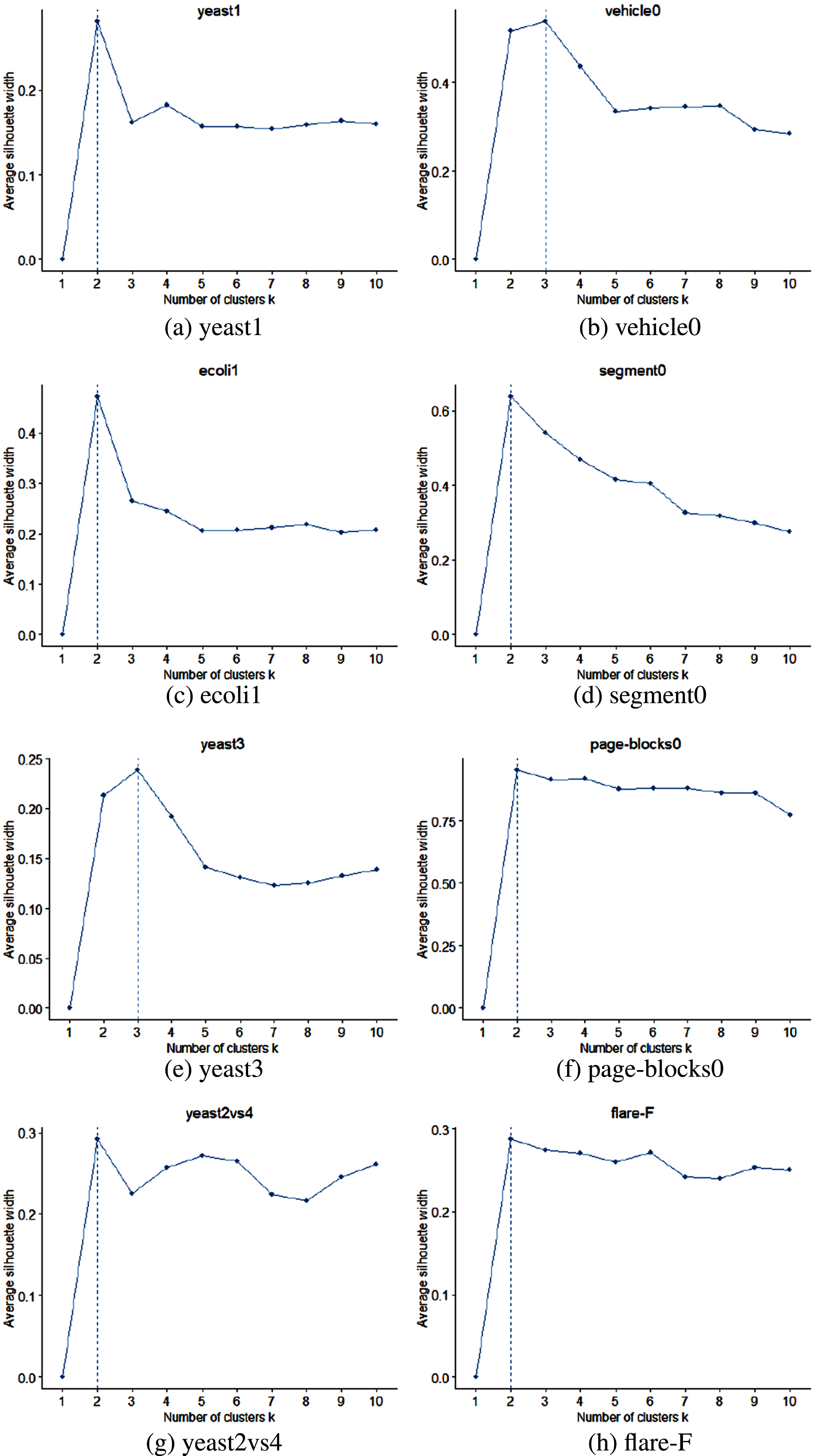
The optimal k values to datasets through the silhouette coefficient.
Description of experimental data set
Define R
aug
for assessing the overlap ratio of imbalanced data, where a higher value indicates a greater degree of data overlap [25]. The calculation equation is:
C0 and C1 represent majority class samples and minority class samples, and X
im
is the m-th sample of C
i
.
The overlapping area of the dataset is shown in Table 2, where R neg is the overlapping area of the majority class data, R pos is the overlapping area of the minority class data, and the calculation formula is shown in Equation 26.
Overlap ratio percentage of datasets
In the experiment, in order to ensure the accuracy of experimental results as much as possible, we use 5-fold cross-experimental verification, and the experiment is repeated 10 times, and the final experimental result is the average value of these 10 experiments.
In the two-class problem, classification results of classifiers on the sample have four cases, which are displayed by the confusion matrix, as shown in Table 3. TP and TN represent the number of correctly classified samples belonging to the minority class and the majority class respectively. FP represents the number of samples of the majority class predicted as the minority class, and FN is the number of minority class data predicted as the majority class.
Confusion matrix
Confusion matrix
According to Table 3, the following evaluation indexes can be obtained:
TPR is the true positive rate, which represents the proportion of correctly classified minority classes in minority data. TNR is the true negative rate, which represents the proportion of correctly classified majority classes in majority data.
F-value is based on the harmonic average of precision and recall. It is a comprehensive evaluation index of precision and recall, which can more accurately display the classification accuracy of positive sample. The AUC value is a common indicator used to evaluate the pros and cons of the binary classification model. The higher the AUC value, the better the effect of the model. Its value is the area under the ROC curve. The abscissa of the ROC curve is FPR and the ordinate is TPR. By adjusting the positive class probability threshold of the classifier, multiple sets of FPR and TPR are obtained, and the ROC curve is drawn to obtain the AUC value [26].
ISODATA algorithm relies on continuously updating the center position of the cluster to obtain better clustering effect. This algorithm considers the intra-class imbalance of minority data, and clusters minority data to oversamples in the sub-cluster. Therefore, the quality of clustering directly affects the results of subsequent oversampling [27]. If the clustering effect is poor, the distribution of the synthesized minority data is quite different from the distribution of the original minority data. This will generate a lot of noise, and cover up the data characteristics of the original minority data, and affect classification performance of classifiers on the minority data. It is necessary to determine the appropriate parameters of ISODATA to obtain the best clustering effect.
In this section, we discuss the potential impact of the sample standard deviation threshold θ S , the cluster center distance threshold θ C and the number of iterations I on the performance of ISODF-ENN, and select appropriate parameters. Since θ S and θ C influence each other, we are talking about the multiple relationship between θ S and θ C . Because the distance between two cluster centers is greater than the standard deviation between samples, Mul is defined as the multiple of θ C greater than θ S . Mul takes values at 5, 20, 50, 100, and I takes values at 5, 10, 20, 30. The corresponding results are shown in Tables 4 and 5.
The impact of Mul on AUC for ISODF-ENN by DT
The impact of Mul on AUC for ISODF-ENN by DT
The impact of I on AUC for ISODF-ENN by DT
For clarity, the AUC results of the DT classifier are presented here. And the best results for the parameters on each dataset are highlighted in bold. As can be seen from Tables 5, there are no universal optimal parameters for all data sets. However, Mul is between 50-100 and I is 20, which performs better on most data sets. The specific settings depend on the researchers’ needs in actual application scenarios.
In order to verify the feasibility of the ISODF-ENN algorithm, we used the original data as a baseline and selected seven different sampling methods as the comparison group, including SMOTE [12], KNSMOTE [15], KmUnder [16], TL [17], SMOTE+ ENN [28], GAN [19], TWGAN-GP [20]. Verify the above algorithms on datasest shown in Table 1, and combines the DT classification algorithm to obtain the F-value and AUC. Because division of the dataset and synthesis of new samples in the experiment are accidental, this experimental results are performed ten times and averaged. The results are shown in Table 6, and best values are shown in bold.
By comparing the above algorithms, it can be observed that ISODF-ENN algorithm has a good effect on the classification of imbalanced datasets. In Table 6, ISODF-ENN achieved the best F-value on 5 datasets and the best AUC on 7 datasets. In datasets that the best values were not achieved, the IR of yeast1 was 2.46, R aug was 43.26, the IR of vehicle0 was 3.25, R aug was 8.21, the IR of flare-F was 23.79, R aug was 95.96, and the IR of segment0 was 6.02, R aug was 2.74. It can be observed that, except for the flare-F dataset, the IR or R aug of ISODF-ENN in datasets where it did not achieve the best performance is relatively low. Particularly, when the IR is lower, the algorithm’s performance improvement is less noticeable. On the flare-F dataset, the F-value of ISODF-ENN is close to the best value, indicating that this algorithm significantly improves performance on datasets with high imbalance and overlap.
Significance test
To better assess whether there are significant differences between ISODF-ENN and other methods, we employed the Friedman test. The Friedman test is based on ranking performance rather than actual performance evaluation, making it less susceptible to the influence of outliers. In this experiment, we first calculated the performance rankings of the nine methods in each dataset and then presented the final rankings in the form of averages. The average rankings of F-value and AUC are shown in Figs. 8 9.

Friedman test of F-value of different algorithms.

Friedman test of AUC of different algorithms.
It can be observed that our algorithm achieves a significant advantage in both the F-value and AUC evaluation metrics. This indicates that the excellence of ISODF-ENN is highly consistent across various performance measures.
Furthermore, in this section, quantitative analysis was conducted using the Friedman test. We analyzed the differences between the nine methods based on the significance value p. If the corresponding p-value is less than 0.05, it indicates the presence of a difference; if the corresponding p-value is greater than 0.05, it suggests no significant difference. The specific test results are shown in Table 7. From the p-values, it can be confirmed that the performance differences among the nine methods are not random, and there is a significant difference between different methods.
Evaluation index results of different algorithms combined with DT classifier on the data set
Friedman test quantitative analysis
To investigate the effectiveness of various modules, we conducted ablation experiments. Using the original data as the baseline, evaluation metrics for ENN, the diffusion model based on ISODATA (ISODF), and ISODF-ENN are shown in the Figs. 10 11.
It can be observed that the evaluation metrics of ENN and ISODF are superior to the original data on the most of datasets, and ISODF-ENN outperforms ENN and ISODF on all datasets. This indicates the effectiveness of various modules, which play a positive role in enhancing the classifier’s classification performance.

F-value of each algorithm after ablation experiment.

AUC of each algorithm after ablation experiment.
Aiming to solve the problem of performance degradation of traditional classifiers on imbalanced datasets and improve the accuracy of minority class data classification, this paper proposes a mixed sampling method based on ISODATA clustering. ISODF-ENN uses oversampling method to synthesize new minority class data and form a new balanced dataset. Meanwhile, clustering was performed on the minority class data, followed by applying a denoising diffusion algorithm to generate new minority class data for each sub-cluster, and the ENN algorithm was used to clean the boundary data. This effectively solves the problem of blurred class boundaries and improves the quality of the synthesized data. After verification, this algorithm has high accuracy in the classification of minority class samples, and this algorithm can be used in the classification of imbalanced data.
Acknowledgments
This work is supported by National Natural Science Foundation of China (No. 62103350) and Shandong Provincial Natural Science Foundation (ZR2020QF046).