
Abstract
In this paper, a question answering method is proposed for educational knowledge bases (KBQA) using a question-aware graph convolutional network (GCN). KBQA provides instant tutoring for learners, improving their learning interest and efficiency. However, most open domain KBQA methods model question sentences and candidate answer entities independently, limiting their effectiveness. The proposed method extracts description information and query entity sets for a specific question, processes them with Transformer and pre-trained embeddings of the knowledge base, and extracts a subgraph of candidate answer sets from the knowledge base. The node information is updated by GCN with two attention mechanisms expressed by the question description and query entity set, respectively. The query description information, query entity set, and candidate entity representation are fused to calculate the score and predict the answer. Experiments on MOOC Q&A dataset show that the proposed method outperforms benchmark models.
Keywords
Introduction
Resource Description Framework (RDF) is a standard for representing data and knowledge in a structured format that can be easily processed by machines. It is a language used to describe resources on the web and their relationships with each other. RDF provides a way to represent and exchange information on the web in a machine-readable format, which enables the integration of data from multiple sources. RDF is based on a graph-based data model, where resources are represented as nodes and relationships between them are represented as edges. Each node and edge is identified by a URI, which provides a unique identifier for the resource. RDF uses triples to represent information, where a triple consists of a subject, a predicate, and an object. The subject represents the resource being described, the predicate represents the relationship between the subject and object, and the object represents the value of the relationship. RDF is widely used in the Semantic Web, which is a vision of the web where information is organized in a way that can be easily understood and processed by machines. RDF provides a standardized way to represent and exchange data on the web, making it possible to create applications that can integrate data from multiple sources and provide more intelligent and personalized services to users.
In recent years, the rapid development of internet technology has led to the emergence of various online education platforms, resulting in the accumulation of massive educational resources and teaching data [1]. A knowledge base (also known as a knowledge map) stores a large number of entities and their rich semantic relationships in the form of RDF triples, providing a useful way to organize massive information in the field of education and attracting increasing attention. Specifically, an education knowledge base can aggregate scattered and disordered education data into a structured knowledge form that is easy to retrieve, modify, and save, thereby reducing the user’s costs and achieving cognitive upgrades quickly [2]. For example, Yu et al. from Tsinghua University proposed the Massive Open Online Course (MOOC) knowledge base MOOCCube, which contains entities such as concepts, courses, teacher and student behaviors [3], along with their interactive information, supporting various teaching and research needs. Xu and Guo proposed a knowledge base of knowledge points suitable for K12 education [4], with nodes including knowledge points, schools, and teachers. Experiments demonstrated that the use of the knowledge base effectively improves the accuracy of education resource recommendation. Lin et al. used interactive data generated by university teachers in scientific research and teaching activities to build a knowledge base of university teachers [5], including teachers, research directions, scientific research achievements, and social part-time jobs, providing qualitative and quantitative data support for teacher evaluation.
The integration of educational knowledge bases has paved the way for intelligent question and answer services in the education sector. These knowledge bases offer learners precise and intelligent counseling services, addressing a crucial need in online education platforms. However, the existing research on question and answer systems for educational knowledge bases is lacking and fails to meet the demands of the evolving education landscape[6–8].
Unlike open-domain knowledge bases, educational domain knowledge bases have fewer relationships (such as GRAFT-NET [9], PullNet [10], MHGRN [11], and EmbedKGQA [12]), making it necessary to develop question answering models that can effectively capture unique and valuable entity representations for educational questions. Existing question answering methods in the open domain rarely consider the influence of questions on entity representation, further highlighting the need for specialized approaches in the education field.
To address these challenges, this paper proposes a question answering method for educational knowledge bases based on Graph Convolutional Networks (GCN). The approach decomposes a specific question into its description information and query entity set, representing them separately. Subsequently, an answer candidate subgraph is constructed using the query entity set and processed through a double attention graph convolution network. Attention is calculated based on the question description information and the query entity set. Finally, using these representations, candidate entities are scored to predict the answers.
In summary, this paper introduces a novel approach to question answering in educational knowledge bases using GCN. By considering the unique characteristics of educational domain knowledge bases, this method aims to provide accurate and intelligent answers to educational questions, addressing the limitations of existing approaches.
The main contributions of this paper include: This paper introduces a question answering framework for educational knowledge bases that is based on joint embedding. The framework independently models the description information, query entities, and candidate entity subgraphs in question sentences. These pieces of information are then fused together, and the score is predicted through a feedforward neural network. In order to address the limitations of current question answering methods that are often single and struggle to capture question-specific information during candidate entity modeling, this paper proposes a double-attention graph convolutional neural network for question perception. The experimental results on a real educational knowledge base question and answer (KBQA) dataset demonstrate that the proposed model outperforms the benchmark model’s performance.
Related research
The field of open domain knowledge base question and answer (Q&A) continues to advance, with several promising techniques showing improvements. These include Pre-trained Language Models (PLMs), Graph Neural Networks (GNNs), hybrid approaches, and multi-hop reasoning models.
PLMs, such as BERT and GPT, have demonstrated state-of-the-art performance in various natural language processing tasks [13, 14], including open domain knowledge base Q&A. They excel in capturing complex and subtle relationships between questions and candidate answer entities. Additionally, they possess the ability to perform zero-shot and few-shot learning. However, PLMs require large amounts of training data and computational resources, and there are concerns regarding bias and interpretability.
GNNs have proven effective in modeling intricate relationships between entities and capturing their structural information. By utilizing graph-based representations of entities and their relationships, GNNs have achieved promising results in knowledge base Q&A [15, 16]. Nonetheless, scalability remains a challenge for GNNs, as they may require significant computational resources to handle large-scale knowledge bases.
Hybrid approaches, which combine different techniques such as PLMs and GNNs, attempt to leverage the strengths of multiple models to improve performance. These approaches aim to address the limitations of individual methods and achieve better results in open domain knowledge base Q&A [17, 18].
Multi-hop reasoning models aim to address complex questions that require multiple steps of inference or reasoning [19, 20]. By considering the relationships between various pieces of information in the knowledge base, these models can provide more comprehensive and accurate answers. However, multi-hop reasoning models may suffer from scalability issues and may require additional computational resources.
The latest methods in open domain knowledge base Q&A, including PLMs, GNNs, hybrid approaches, and multi-hop reasoning models, offer distinct advantages and face specific challenges. Future research should focus on further improving these techniques to enhance the performance, scalability, and interpretability of open domain knowledge base Q&A systems.
Knowledge base question-answering methods can be broadly categorized into semantic-parsing methods and joint-embedding methods.
Semantic-parsing methods involve parsing natural language questions, converting them into logical expressions, and generating query statements that match the knowledge base. These queries are then executed to obtain the answer. For example, Reddy et al. proposed a semantic-parsing method based on semantic graphs [21]. This method analyzes question sentences, constructs a semantic graph comprising nodes (entities, variables, or types) and edges (relationships and operators). This graph represents a subgraph of the knowledge base and facilitates question mapping. The answer is obtained through a specific graph-matching method. Similarly, Yih et al. introduced a semantic-parsing framework for question and answer using a knowledge base by introducing a query graph [22]. Semantic parsing is simplified as a phased search-generation process of the query graph, and the answer is predicted using the entity link of the query graph and a convolutional neural network. While these methods have achieved some results and are easy to understand, their multiple modules and steps can lead to error accumulation and poor training performance.
On the other hand, joint-embedding methods leverage representation learning to embed the question and candidate answers into a unified vector space. The answer is then determined by calculating the distance in this space. For instance, Dong et al. proposed MCCNNs (multi-column convolutional neural networks), which employ a multi-column convolutional network to process questions and obtain their representation vectors [23]. Questions are understood as one-hop or multi-hop relationships in the knowledge base and are embedded in the same vector space. Finally, the score is calculated using classical knowledge base embedding methods likeComplEx [24].
Knowledge base question-answering methods can be classified into semantic-parsing and joint-embedding approaches. While semantic-parsing methods involve converting questions into logical expressions and matching them with the knowledge base, joint-embedding methods focus on representing questions and candidate answers in a unified vector space and calculating the distance to determine the answer. Both approaches have their advantages and limitations, and further research is needed to improve their performance and efficiency.
The joint embedding method is highly effective in extracting the deep features of questions and knowledge bases, leading to excellent prediction performance. However, current methods in this approach only utilize the structural information in the knowledge base and do not incorporate the impact of question information. As a result, they often fall short in their modeling capabilities. To address this issue, this paper proposes a question-perception graph convolution network for entity modeling. This model comprehensively considers the impact of question description and related query entities during the information transmission of graph convolution.
Question-answering model based on the convolution of a question-perception graph
In order to enable the graph convolution network to learn the specific entity representation of the question, this paper introduces the attention of question perception to model the question description information and the corresponding query entity, respectively. The overall model architecture is shown in Fig. 1. Formally, for the question to be answered q, it contains the set of entities to be queried ɛ H . For example, the set of query entities corresponding to the question in Fig. 1 contains [Li Hua] and [Zhang Tao]. This set is used as the seed list to obtain the adjacent subgraph G q of order h from the knowledge base, whose node set is ɛ q , and the value of h should ensure that the answer set ɛ T corresponding to question q is a subset of ɛ q . In order to solve the question and answer problem of this kind of educational knowledge base, this paper uses the three-stage calculation method of question modeling, sub graph modeling and answer prediction. This chapter will introduce in detail from the following three aspects: question modeling based on transformer and knowledge base embedding, subgraph modeling based on question perception graph convolution, and answer prediction and loss function.

Overall architecture of proposed model.
In this paper, the question description is separated from the entity to be queried for question modeling. Specifically, the question description can capture the more essential intention unrelated to the entity, while the entity to be queried can be modeled according to the structural information of the original knowledge base. The two adopt the “late fusion” strategy in information fusion to achieve complete semantic supplement when predicting the answer. For the question, this paper first converts the entity into the special symbol “ENT”, and then the Chinese word segmentation tool “jieba” for word segmentation is used to get the serialized representation of the question q = [w1, w2, ⋯ , wn-1, w
n
], where n represents the length of the sentence and w
i
represents the i word. Then the Transformer with multiple heads’ attention is used to model and calculate the question expression e
q
in formula (1) [25].
Here are the detailed instructions for modeling Transformers with multiple heads of attention:
Step 1: Input encoding: The input sequence is first encoded using an embedding layer, which maps each token to a vector representation. This is followed by position encoding, which adds positional information to the embeddings.
Step 2: Multi-head attention: The next step is to perform multi-head attention. In this step, the input sequence is split into multiple segments or heads, and attention is calculated independently for each head. This allows the model to attend to different parts of the input sequence in parallel.
Step 3: Attention calculation: For each head, attention is calculated by computing a query, key, and value matrix. The query matrix is derived from the previous layer’s output, while the key and value matrices are derived from the input sequence. The attention weights are computed as the dot product of the query and key matrices, normalized using a softmax function. The output of the attention calculation is then the weighted sum of the value matrix, where the attention weights serve as the weights.
Step 4: Residual connections and layer normalization: The output of the attention calculation is added to the input sequence to create a residual connection. The residual connection is then normalized using layer normalization to improve training stability.
Step 5: Feedforward layer: The output of the attention layer is then passed through a feedforward neural network, which contains two linear layers with a ReLU activation in between. This allows the model to learn more complex relationships between the input sequence and the output.
Step 6: Residual connections and layer normalization: The output of the feedforward layer is added to the output of the attention layer to create another residual connection. Like before, this is normalized using layer normalization.
Step 7: Repeat steps 2–6 for multiple layers: The above steps are repeated for multiple layers to create a deep, hierarchical model. Each layer takes as input the output of the previous layer and passes its output as input to the next layer.
The multi-head attention mechanism allows the model to attend to different parts of the input sequence in parallel, while the residual connections and layer normalization help improve training stability and allow for faster convergence. The feedforward layer allows the model to learn more complex relationships between the input sequence and the output.
In order to effectively obtain the structure information of the entity to be queried in the original knowledge base, the model uses the knowledge base embedding technology to initialize the vector representation to obtain the entity representation matrix
•Entity Representation Matrix E: The entity representation matrix E is a matrix that represents all the entities in a knowledge graph. Each row of the matrix corresponds to an entity and contains its embedding vector. The embedding vector is a dense vector that represents the entity’s semantic meaning in the knowledge graph. The embedding vectors are learned through a training process that aims to capture the relationships between entities in the knowledge graph.
•Embedding Vector of Entity E i : The embedding vector of an entity E i is a dense vector that represents the semantic meaning of that entity in the knowledge graph. This vector is a row vector in the entity representation matrix E, corresponding to the entity E i . The embedding vector is learned through a training process that takes into account the relationships between entities in the knowledge graph, as well as the co-occurrence patterns of entities in text.
In open-domain QA systems, the entity representation matrix E and the embedding vectors of entities E i are used to represent the semantic meaning of entities in the knowledge graph. These representations are then used to match the question to the relevant entities in the knowledge graph and generate the answer. The matching process typically involves measuring the similarity between the question and the entity embedding vectors, and selecting the entities with the highest similarity scores as the answer candidates.
Distmult method is adopted by default for embedding in this paper [26]. Based on this, the representation e
H
of the query entity set ∈
H
can be extracted by embedding the entity into the vector mean in formula (2):
The DistMult method is a type of knowledge graph embedding model that represents entities and relations as low-dimensional vectors in a continuous space. It is a bilinear model that computes the score of a triple (h, r, t) as the dot product of the vector representations of the head entity h, relation r, and tail entity t.
In the context of query answering, if there are multiple query entities in the question, one approach is to represent each query entity as a separate vector and then combine them to form a query vector. The query vector can be obtained by taking the average of the individual entity vectors or by using other aggregation methods that take into account the relative importance of each entity to the question.
However, simply averaging the embeddings of multiple query entities may not be sufficient if the different query entities have different importance to the question. In this case, it may be more effective to use a weighted average or some other form of aggregation that takes into account the importance of each entity. For example, one approach is to use attention mechanisms to dynamically weigh the contribution of each entity to the query vector based on its relevance to the question. The choice of aggregation method depends on the specific task and the nature of the query entities, and it may require experimentation to determine the most effective approach.
Graph convolution neural network has gradually attracted widespread attention due to its powerful graph structure modeling ability [27]. It generally follows the pattern of iterative message passing to capture the structured information of the neighborhood of nodes. The representation of layer k + 1 is usually based on the representation of layer k. The graph convolution operation (message passing mechanism) is obtained in formula (3):
Where,
Wherein,
FF represents the feedforward neural network layer, and the symbol “;” represents the splicing operation between vectors. Through the calculation of equations (6) and (7), the graph volume will comprehensively consider the question description information and the corresponding query entity when transmitting information, so the information related to the question will be enhanced and the irrelevant information will be weakened, so the model can better model the entity representation and predict the answer. At the last layer of the graph convolution network, record the node representation
Feedforward neural network (FNN), abbreviated as feedforward network, is a type of artificial neural network. The Feedforward neural network adopts a unidirectional multi-layer structure. Each layer contains several neurons. In this type of neural network, each neuron can receive signals from the previous layer of neurons and generate outputs to the next layer. The 0th layer is called the input layer, the last layer is called the output layer, and the other intermediate layers are called hidden layers (or hidden layers, hidden layers). The hidden layer can be one layer. It can also be multiple layers. There is no feedback in the whole network, and the signal propagates unidirectionally from the input layer to the output layer, which can be represented by a Directed acyclic graph.
Computing neighbor triplet (u,r,v): In graph-based models, neighbor triplets (u,r,v) can be computed by iterating over each node u in the graph, and for each node u, iterating over its neighbors v and the edges r that connect them. For example, in a graph neural network, the neighbor triplet (u,r,v) can be computed by aggregating the embeddings of u, r, and v using a set of learnable parameters. In a knowledge graph embedding model, the neighbor triplet (u,r,v) can be computed by projecting the embeddings of u and v onto a shared space, and then computing a score based on the similarity between the projected embeddings.
Computing attention score: In attention-based models, attention scores can be computed by computing a similarity function between a query vector and a set of key vectors. The query vector can be a hidden state in a recurrent neural network or the output of a previous layer in a feedforward neural network. The key vectors can be a set of embeddings representing a sequence of inputs, such as words in a sentence or items in a list. The similarity function can be a dot product or a learned function such as a multi-layer perceptron. The resulting scores can be normalized using a softmax function and used to compute a weighted sum of the value vectors, which can be used as the output of the attention mechanism.
Based on the modeling of question and query subgraph in the previous paper, this paper splices the question representation, query entity representation and candidate node representation, and uses feedforward neural network and sigmoid function to calculate the score in formula (9).
The sigmoid function is a mathematical function that maps any input value to an output value between 0 and 1. It is commonly used in machine learning and neural networks as an activation function, which introduces non-linearity into the output of a neural network node.
When predicting the answer, select the entity with the highest score in the subgraph as the answer according to the above calculation. Finally, the overall loss function of the model is defined by binary cross entropy in formula (10).
Question representation, query entity representation and candidate node representation are spliced, and Feedforward neural network and sigmoid function are used. sq,i is their calculated score. 0 < yq,i < 1 is weighted. Loss is the sum of each weighted entropy. Weighted entropy is a Loss function, which is often used in multi classification problems. Compared with the Cross entropy Loss function, weighted entropy considers the relationship between categories, and can better deal with the situation of category imbalance. Specifically, weighted entropy assigns higher weights to a few categories, making the model more focused on these categories, thereby improving the model’s classification performance for minority categories.
To obtain the answer subgraph of a question answering model based on question perception graph convolution, these steps are can followed:
•Construct the question perception graph by using the question as the input and applying graph convolutional neural network (GCN) to encode the information in the graph.
•Extract the relevant nodes from the question perception graph that are likely to contain the answer to the question. This can be done by using a graph attention mechanism or other techniques to identify the most salient nodes in the graph.
•Once the relevant nodes have been identified, extract the subgraph that contains these nodes and their edges.
•Apply additional graph convolutional layers to the subgraph to refine the representations of the nodes and edges based on the context of the question.
•Use the refined subgraph representations to predict the answer to the question, either by selecting a node in the subgraph or by generating a new node and its associated edges as the answer.
This approach combines the power of graph convolutional neural networks with attention mechanisms to extract the most relevant information from a knowledge graph or other data source, and then uses this information to generate an answer to the question.
The components needed for building the graph neural network
There are several components that are typically needed for building a graph neural network (GNN). These include:
•Graph data: GNNs require input in the form of a graph, which is typically represented as a set of nodes and edges with associated features.
•Node features: Each node in the graph may have associated features, such as node labels, attributes, or metadata. These features can be used to inform the node representation and update process.
•Edge features: Each edge in the graph may have associated features, such as edge weights or types. These features can be used to inform the edge representation and update process.
•Message passing: GNNs typically use a message passing mechanism to propagate information between nodes in the graph. This involves passing messages along the edges of the graph and updating the node representations based on the received messages.
•Aggregation: After receiving messages from their neighbors, nodes typically perform an aggregation step to combine the received information into a new node representation.
•Non-linear transformation: GNNs may use non-linear transformations, such as activation functions or multi-layer perceptrons, to update the node representations.
•Pooling: GNNs may use pooling or downsampling mechanisms to reduce the size of the graph and enable processing of larger graphs.
The particular design choices behind these components can vary depending on the specific GNN architecture and application. For example, different message passing mechanisms, aggregation functions, and non-linear transformations may be used depending on the task at hand and the structure of the input graph. Additionally, different pooling strategies may be used to enable processing of larger graphs or to capture different aspects of the graph structure.
Experimental results and analysis
Experimental data set
The experimental dataset uses the large-scale online education knowledge base MOOCCube constructed by Tsinghua University [3], and the MOOC Q&A dataset is used for the question and answer experiment of the knowledge base. The knowledge base contains 706 real online courses, 700 concepts, and 4723 users, as well as 10 types of relationships such as concept domain, course video, and concept sequence, forming a total of 52195 triples. The detailed statistical information of the knowledge base is shown in Table 1. MOOC Q&A contains two kinds of problems: one-hop and multi-hop. The one-hop question involves only a head entity and a relationship in the knowledge base, while the multi-hop question may contain multiple entities, and to answer such questions, we need to reason from multiple facts in the knowledge base. The number of one-hop and multi-hop problems is 5504 and 13637, respectively. In the experiment, they are divided into training set, verification set, and test set according to the proportion of 80%, 10%, and 10%.
Statistics of entities and relations in knowledge base of MOOC Q&A
Statistics of entities and relations in knowledge base of MOOC Q&A
In the experiment, this paper uses the “Jieba” word segmentation tool to segment the question, and uses the DistMult method to embed the entities in the knowledge base. The default embedding dimension is 200. For the one-hop and multi-hop problems, the order of the adjacent subgraph Gq extraction time is set to 1 and 2, respectively. Similarly, the number of layers of the graph convolution network is set to 1 and 2, respectively. The word embedding dimension, the transformer hidden layer dimension, and the graph convolution network dimension are all set to 200 by default. Each feed-forward network layer is activated by the ReLU function, and a dropout layer with a drop rate of 0.1 is added to enhance the generalization performance of the model. During training, this paper uses the Adam algorithm with a learning rate of 0.002 to optimize and sets the maximum number of iterations to 30 [28].
Comparison model and evaluation index
In order to verify the effectiveness of the model proposed in this paper, a comparison experiment is conducted using EmbedKGQA, the current optimal model. In this model, the question is treated as a one-hop or multi-hop reasoning process of the relationships in the knowledge base, thus making the knowledge base question and answer analogous to the link prediction task. The score of the candidate entity is calculated through the score function of the link prediction. In the experiment, TransE [29], DistMult [26], ComplEx [24], and RotatE [30] were used as the score functions to predict the answers. The prediction accuracy (ACC) and mean reciprocal rank (MRR) are selected as performance evaluation indicators. ACC measures whether the entity with the highest prediction score appears in the actual answer list. MRR indicates the average reciprocal ranking of the entities in the answer set in the prediction list. Their calculation methods are given in formulas (11) and (12).
Where, M represents the number of questions; ɛ T is the actual answer set of question q; p is the entity with the highest score of model prediction; The function I indicates whether the element is in the collection, and its value range is {0,1}; r i indicates the ranking of entity i in the forecast answer list.
The DistMult method is a knowledge graph embedding model that represents entities and relations as low-dimensional vectors in a continuous space, and it is capable of handling multi-hop questions in a natural way.
When presented with a multi-hop question, the model first identifies the query entities and relations in the question, and represents them as low-dimensional vectors. It then performs a series of graph traversals by computing the scores of all possible entity-pairings using the DistMult scoring function, and selecting the most promising entities that are likely to be connected by the required relation. This process is repeated for each hop in the question until the final answer is obtained.
This approach is effective because the DistMult model is able to capture the complex relationships between entities and relations in a knowledge graph, and use this information to reason about the answer to a multi-hop question. By representing entities and relations as low-dimensional vectors, the model is able to perform efficient graph traversals and identify the most promising paths between entities.
In comparative experiments on multi-hop question answering datasets, the DistMult method has been shown to achieve state-of-the-art performance, demonstrating its effectiveness in handling multi-hop questions.
Comparison of experimental results
Table 2 shows the performance comparison of this model and EmbedKGQA method on the MOOC Q&A dataset. On the whole, it can be seen that the proposed model has achieved excellent performance in the indicators of one-hop and multi-hop question answering. Except that the MRR of multi-hop is slightly less than (0.009) the score function of the ComplEx EmbedKGQA, other indicators are better than the comparison model, among which the improvement is the largest compared to the TransE model, and the four indicators are improved by 0.129, 0.120, 0.241, and 0.210 respectively. Similarly, compared to the optimal EmbedKGQA using the ComplEx, the one-hop ACC, MRR, and multi-hop ACC also achieved 0.011, 0.008, and 0.004 improvements, respectively. This shows the effectiveness of this model.
Comparison of experimental performance
Comparison of experimental performance
In order to verify the real effect of the double attention mechanism of question perception on answer prediction proposed in this paper, attention ablation experiments were conducted. The results of these experiments are presented in Table 3. The “Attention 1” and “Attention 2” in the table refer to the description information about questions and the attention of the corresponding query entity calculated by equations (6) and (7), respectively. According to Table 3, the ablation of either one or both attention scores reduces the experimental performance, indicating that each attention has a positive effect on the improvement of the experimental performance. Additionally, the impact of Attention 2 is slightly higher than that of Attention 1, which shows that when modeling candidate answers for graph convolution, the model pays more attention to the association between them and query entities.
Results of ablation experiments
Results of ablation experiments
In order to explore the impact of the initial embedding matrix of entities in the knowledge base on question-answering performance, this paper uses different initial embedding methods for experiments. Figure 2 shows the performance comparison of the models using TransE, DistMult, ComplEx, and RotatE. It can be seen that the initialization embedding method has little impact on the overall model, and the model can achieve good performance with each embedding method.
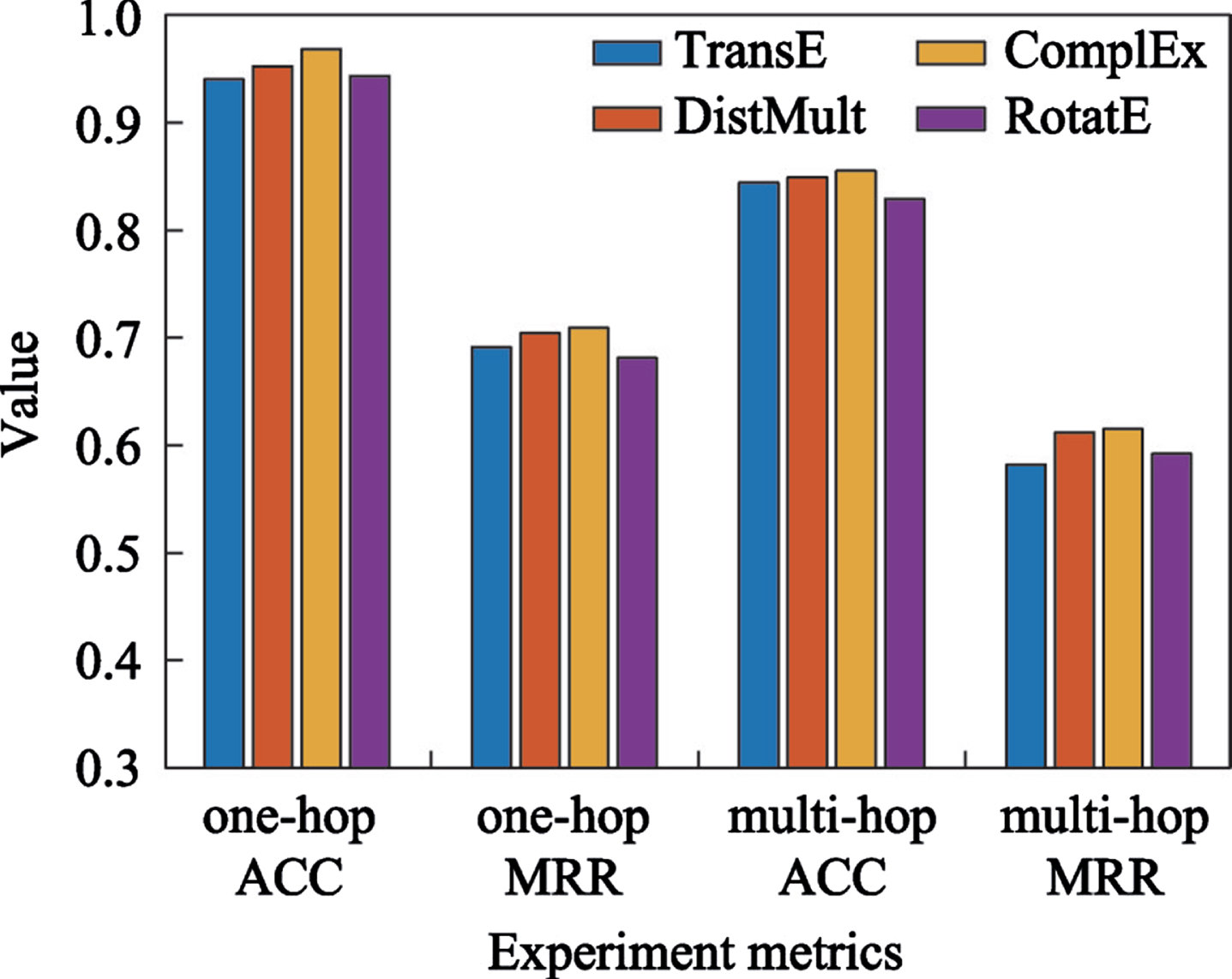
Impact of initialization embedding method on Q&A performance.
In order to explore the impact of the embedding dimension on experimental performance, this paper conducted a grouping experiment with a step size of 100-500 on the interval of 100. In the experiment, the word embedding dimension, the transformer hidden layer dimension, and the graph convolution network dimension were all set uniformly. Figure 3 shows the experimental results. It can be seen that when the embedded dimension is less than 200, the increase of the dimension will marginally improve the model’s performance; when the dimension is greater than 200, its impact on the model is small, and the performance of the model tends to be stable. This indicates that the effect of the embedding dimension on the experimental performance is not very significant.

Impact of embedding dimension on performance.
This research paper introduces a novel approach to question answering in educational knowledge bases. The proposed method utilizes a convolutional network and a question perception graph to model candidate entity representations. Attention scores are calculated based on the description information in the question and the query entity set, allowing for effective information transmission in the graph convolution.
Experimental results demonstrate the effectiveness of the proposed method. Ablation experiments further confirm the positive impact of the two attentions on prediction performance. The method shows promise in improving the accuracy and efficiency of question answering in educational settings.
Future work will focus on enhancing question modeling by incorporating large-scale pre-trained language models, which can capture more complex relationships between the question and candidate answer entities. Additionally, investigations into effective fusion techniques for various types of information, such as query entities and candidate answer entities, will be carried out to further improve the performance of the method.
In conclusion, the proposed method offers a valuable contribution to the field of data-driven smart education by providing instant tutoring through question answering in educational knowledge bases. Its effectiveness is demonstrated through experimental results, and future directions aim to enhance its applicability and accuracy in educational settings and beyond.
Footnotes
Acknowledgments
This work was supported by China Association of Higher Education, 2023 Higher Education Scientific Research Project: Research on Innovation of Production-Teaching Integration and Collaborative Education Model for Business English Majors under Digital Economy, High Education Association (2023) 100: 23WYJ0307.