
Abstract
The entity-relationship extraction model has a significant influence in relation extraction. The existing model cannot effectively identify the entity-relationship triples in overlapping relationships. It also has the problem of long-distance dependencies between entities. In this paper, an inter span learning for document-level relation extraction model is proposed. Firstly, the model converts input of the BERT pre-training model into word vectors. Secondly, it divides the word vectors to form span sequences by random initial span and uses convolutional neural networks to extract entity information in the span sequences. Dividing the word vector into span sequences can divide the entity pairs that may have overlapping relationships into the same span sequence, partially solving the overlapping relationship problem. Thirdly, the model uses inter span learning to obtain entity information in different span sequences. It fuses entity type features and uses Softmax regression to achieve entity recognition. Aiming at solving the problem of long-distance dependence between entities, inter span learning can fuse the information in different span sequences. Finally, it fuses text information and relationship type features, and uses Linear Layer to classify relationships. Experiments demonstrate that the model improves the F1-score of the DocRED dataset by 2.74% when compared to the baseline model.
Introduction
Entity-relationship extraction is to extract entity relationships from unstructured text [1] and convert unstructured text into structured data by analyzing it. Entity-relationship extraction is useful for building knowledge graphs [2], question-answering systems [3] and information retrieval [4]. The entity-relationship triple [5] is one of the basic representation methods of entity relationship. A triple of the form < entity, relation, entity> [6] consisting of two entities and the relation between them represents the semantic relation between entities in the text. Existing entity-relation extraction methods can be divided into two categories: the pipeline relation extraction methods and the joint relation extraction methods. Among them, the pipeline extraction method [7] divides the relationship extraction task into two independent subtasks, firstly, identifying the entities in the given text, and then identifying the relationship between entities. The joint model extraction method [8] recognizes the entities and the relationship between entities at the same time. When studying the entity-relationship extraction at document-level, the relationship between entity pairs may appear in different sentences, so the information of the whole document needs to be considered in the process of entity relationship extraction. References to the same entity may appear in different sentences in a text. An example on the DocRED dataset is shown in Fig. 1. Entities and their referents appearing in different sentences may correspond to different entity relationships. In order to more accurately identify entity relationships in whole texts, inter span learning needs to be performed in entity relationship extraction. The relationship between entity pairs requires fusion inference. There are many entity relationship triples in the document, and the relationship between them is relatively weak [9], so it is necessary to carry out related logical reasoning [10] to better capture the entity relationship information in the document.

Example of DocRED dataset. In this figure, those with the same color refer to the same entities. Reference can occur within the same sentence or between sentences.
Since there may be overlapping relations in the text, it will also affect the effect of relation extraction. The relations in the text are divided into three categories, Normal, Entity Pair Overlap (EPO) and Single Entity Overlap (SEO), as shown in Table 1. Entity Pair Overlap means that there is more than one relationship between two entity pairs; Single Entity Overlap means that two or more entities have a relationship with a certain entity.
The examples of normal, single entity overlap, and entity pair overlap
Although good results have been achieved so far, the current model is not so perfect for the research on the overlapping relationship in the whole text and the long-distance dependence between entities. This paper focuses on these two problems. We propose an inter span learning model for document-level relation extraction, ISLM. This method combines span to perform entity relation extraction on document-level text. First, the BERT pre-training language model (BERT-BASE-CASED) is used to encode the text. After BERT pre-training, word vectors are used to divide into span sequences, and the Convolutional Neural Networks are used to extract entity information in span sequences. Second, using inter span learning mechanism to obtain the entity representation which is located in different span sequences. In order to extract entity information, coreference resolution is used to produce mentions cluster. Entity recognition is performed using Softmax Regression after fusing entity type features. Finally, Linear Layers are used for relation classification after fusing text information and relation type information. For the overlapping relationship problem in the text, divide entity tokens that may have overlapping relationships into the same span sequence. When performing entity recognition between span sequences, entities that may have overlapping relationships in the span sequence can be effectively identified, thereby effectively solving the overlapping relationship problem. Aiming at the problem of long-distance dependence between entities, entities that may have relationships are relatively far away. We use inter-span learning to effectively obtain the relationship between entities that are far away in the span sequences, thereby effectively solving the long-distance dependency problem between entities to a certain extent.
Overall, the following are significant contributions to this paper: An inter span learning model for document-level relation extraction based on span and multi-sentence learning are proposed. Different from existing methods, this paper performs span division after BERT pre-processing to form span sequences, entity extraction within span sequences. The issue of overlapping relations in the text is successfully resolved. This method uses inter span learning mechanism to get entities in different span sequences, which has the advantage that can obtain entities that are far away, and these entities have certain semantic relationships between them. This can effectively solve the problem of long-distance dependencies between entities. Through the analysis of the DocRED dataset, where compared to the current models, the methodology suggested in this research produced the best results.
Extracting entity relationships from unstructured text is a useful task in natural language processing, which is also a necessary step to build a knowledge graph to provide support for downstream related tasks [11]. At present, the mainstream entity-relationship extraction methods can be roughly divided into two types: pipeline entity-relationship extraction method and joint entity-relationship extraction method [12].
The pipeline extraction method
The relationship extraction task is divided into two separate subtasks using the pipeline extraction approach. Nayak T et al. [13] introduces the use of Bi-LSTM (Bidirectional Long Short-Term Memory Network) model and Attention mechanism to obtain long-distance dependencies information, which effectively solves the problem that the sentence is long and the distance between entities is far away which affects the relation extraction effect. Eberts M et al. [14] introduces the random division of input text combined with span, positive and negative sample information for entity relationship extraction, which effectively solves the problem of overlapping relationships in texts. Zeng D et al. [15] introduces the use of Deep Convolutional Neural Networks to extract lexical, which effectively solves the problem of relation classification that requires complex pre-processing. For adding the Attention mechanism to complete relationship classification, Guo X et al. [16] introduces the use of a neural network combined with RNN (Recurrent Neural Network) and CNN (Convolutional Neural Network). It can extract higher-level text information and obtain sentence feature information. Guo Z et al. [17] introduces adding entity type and relation alias information and inputting it into a Graph Convolutional Neural Network to improve the effect of entity-relation extraction.
The joint extraction method
The pipeline method does not need to manually construct features [18] and has high accuracy [19], so it is widely used, but because the error in the entity recognition task may be transmitted to the relationship classification task, it causes the problem of error propagation [20–22]. Therefore, in recent years, researchers have gradually focused on the research of joint entity-relationship extraction methods. Verga P et al. [23] introduces the use of multi-sentence learning to detect entity-relationship pairs in the biomedical domain, and solves the problem of ignoring inter-sentence relationships and redundant computations in biomedical domain texts. Yao Y et al. [24] introduces the document-based dataset DocRED, and uses a baseline model for relation extraction, which provided a benchmark for comparison for later researchers. Wang H et al. [25] introduces the use of a BERT pre-training model to encode textual information, and then uses two Linear layers to extract the relationship. The model achieves good results, but cannot use logical inference to judge the possible entity relationships in DocRED dataset. Yuan C et al. [26] introduces the use of the BERT pre-training model to encode text information, and uses the self-attention mechanism to obtain the feature information of the sentences to extract the entity-relationship information. It solves the problem that the text feature information is easy to ignore. Xu B et al. [27] introduces that the self-attention module sets up the transformation module and runs through the entire network, which can effectively carry out logical reasoning within a document. Sahu S K et al. [28] introduces the use of Graph Convolutional Neural Networks to extract document-level relations. It mainly used inter-sentence and intra-sentence dependencies. Zaporojets K et al. [29] introduces the document-level relation extraction dataset DWIE. The model paid more attention to entity-centric annotation, and applied graph convolutional neural network to document-level entity-relation extraction. Eberts M et al. [30] introduces the first document-level entity relationship extraction at the entity level, which uses multi-sentence learning to extract entity and relationship information within a document. However, the outcomes of entity relationship extraction may not be optimal if there are somewhat complicated overlapping relationships and the issue of long-distance dependencies between entities in the text.
Method
This section describes the joint extraction model proposed in this paper based on span and inter span learning. The main purpose is to effectively solve the problem of overlapping relationships in the text and long-distance dependencies between entities.
In this paper, we first transform the text into word vectors using the BERT pre-training model, and then divide the word vectors into span sequences through random initial span. The random initial span is automatically generated by the model, but we set the maximum span value so that the length of the formed span sequence is within the maximum value we set. Second, we extract the entities from the span sequences using convolutional neural networks. The overlapping relationship issue can be efficiently resolved by splitting the word vector into span sequences, which can divide entity pairs that might have overlapping relationships into the same span sequence. Thirdly, we extract the entity information from adjacent span sequences via inter-span learning. In order to extract entity, we use coreference resolution to form a mentions cluster. Integrates entity type features and uses Softmax regression to perform entity classification. We fuse entity type features and use Softmax regression to achieve entity recognition. Aiming at the problem of long-distance dependence between entities, inter span learning can fuse the information in different span sequences. Finally, Linear layer is used for relation classification by fusing textual information and relation type features. The overall frame diagram of the model is shown in Fig. 2.
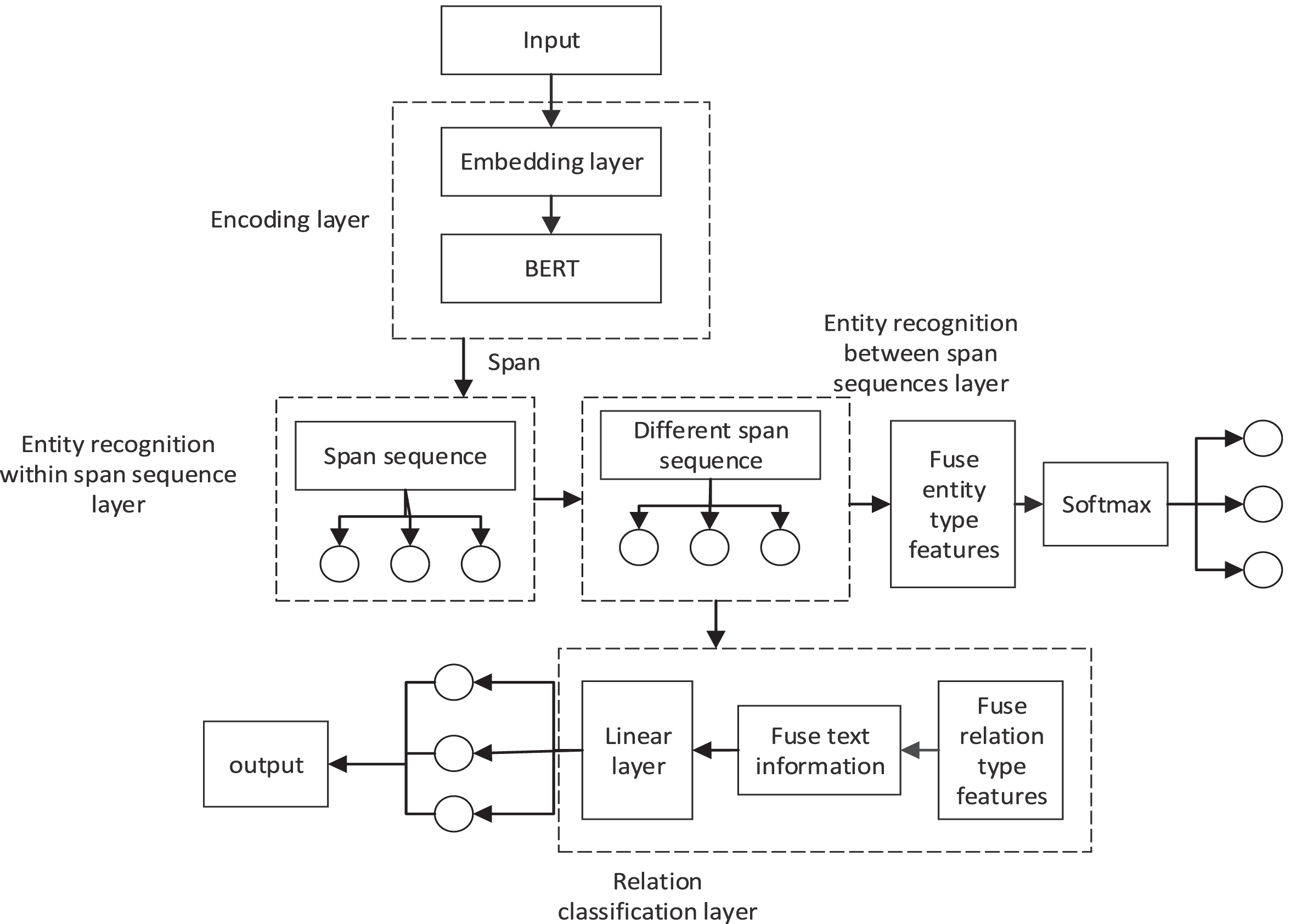
Model frame diagram. In this diagram, our model is divided into four modules.
The main task of the encoding layer is to encode the text information into a matrix vector. The encoding layer uses the BERT pre-training language model to obtain the semantic features of the sentence. The semantic features of the sentence are expressed as X = [x1, x2, x3, x4, …, x n ] semantic information.
First, the input sequence is represented as word vectors through the embedding layer, and the expression of the i-th token in the processed word vector is shown in formula (1):
Among them, Wtoken (ti) is represented as token embedding and Wpos (ti) is represented as position embedding. The model in this paper uses BPE (Byte-Pair Encoded) encoding [31]. It can effectively reduce the number of words in the vocabulary. Then, we input it into the BERT (BERT-BASE-CASED) pre-training model for encoding. The BERT pre-training model contains 12 hidden layers, each with a size of 768. The encoded result in the sentence is shown in formula (2):
Where E represents the word vector formed by token embedding and position embedding; and H b is the output of the hidden layers. Then, the semantic representation H b of the sentence is obtained from the text through the BERT model, which is used in subsequent tasks.
The main task of this layer is to identify entities in the span sequences by using Convolutional Neural Networks (CNN). Compared with the method of BIO (B-begin, I-inside, O-outside) annotation [32, 33], the problem of overlapping relationship in text can be effectively solved by using initial span to divide into span sequences. The framework of the model is shown in Fig. 3.
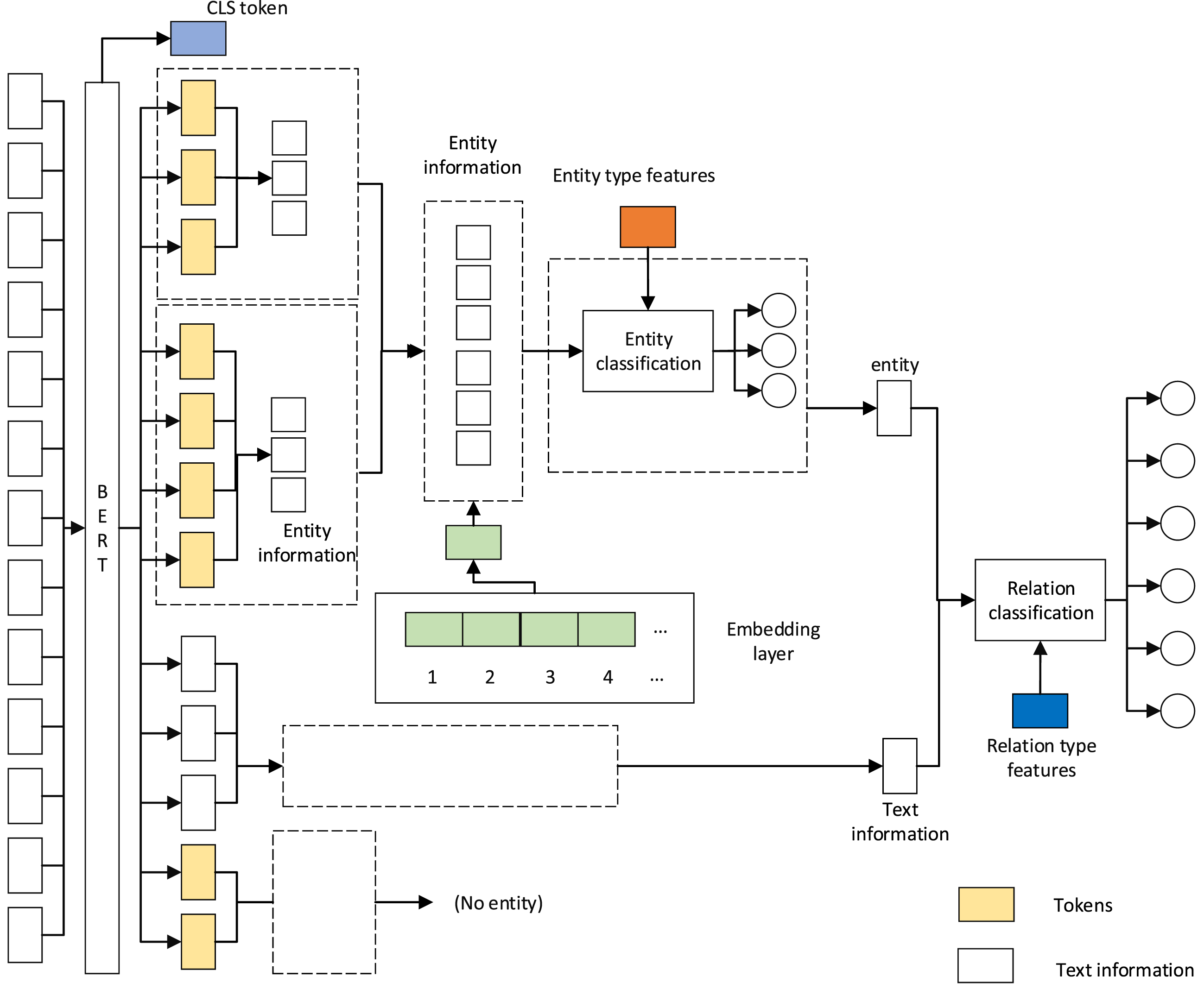
The framework of the Model. In this model, the yellow means tokens and many tokens form span sequences; the green means embedding matrix; the orange means predefined entity type features; the dark bule means predefined relation type features; the light blue means the CLS tokens.
The acquired semantic representation information, which is abstained in the encoding layer is divided according to a random initial span to form span sequences, and the length of the span sequence will not exceed the set maximum span value. This paper sets the maximum span sequence length to 11, and describes how to determine the maximum span value in section 4.5. The random initial span is generated by the model, and the generated span sequence is composed of many tokens. The span sequence after division is shown in formula (3):
We extracting entity information in span sequences using Convolutional Neural Networks (CNN) is shown in Fig. 4. The use of Convolutional Neural Networks (CNN) can effectively reduce the complexity of the model and increase the generalization and robustness of the model.
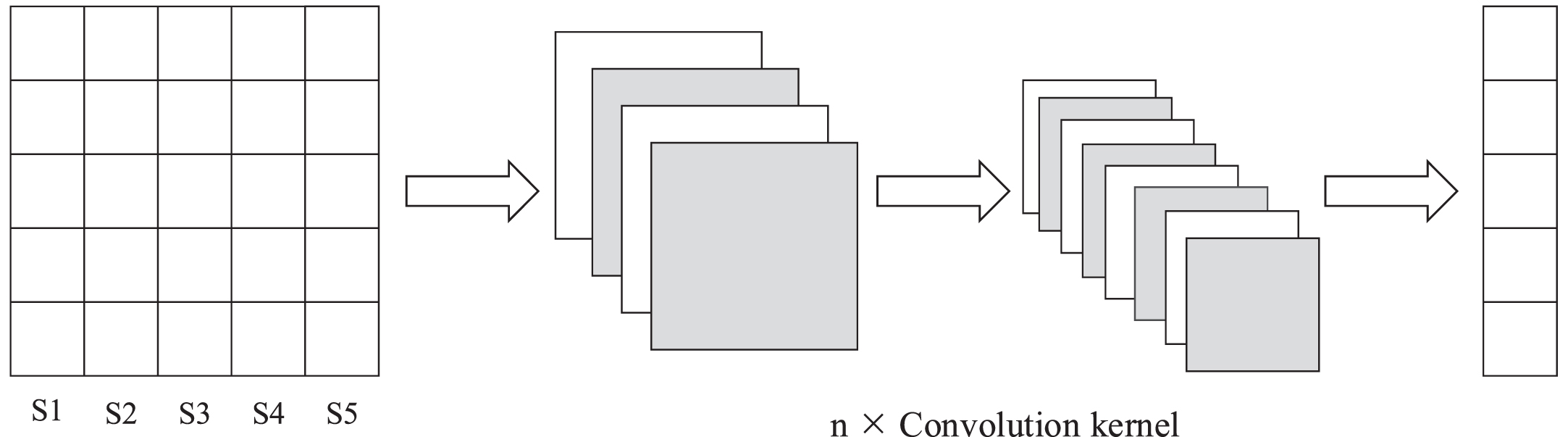
Extracting span sequences feature information. We use convolutional neural network to extract entities from span sequences.
The model extracts entity features through convolutional neural networks in span sequences, as shown in formula (4):
The main task of this layer is to identify entities between the span sequences. A reference to an entity below may be expressed as: ‘The Beatles’ is hereinafter referred to as’ The famous band’. Before extracting entities information between span sequence, reference resolution is used to form a mentions cluster. multi-sentence learning [34] were used to learn information features between sentence. The model uses inter span learning to learn the entities information, which obtained in the Entity recognition with span sequence layer to obtain entity features between span sequences, which can combine textual information to effectively solve long-distance dependencies between entities. We set the maximum length of the span sequence at 11. After extracting entity information from different span sequences, the entity information representation is shown in formula (5):
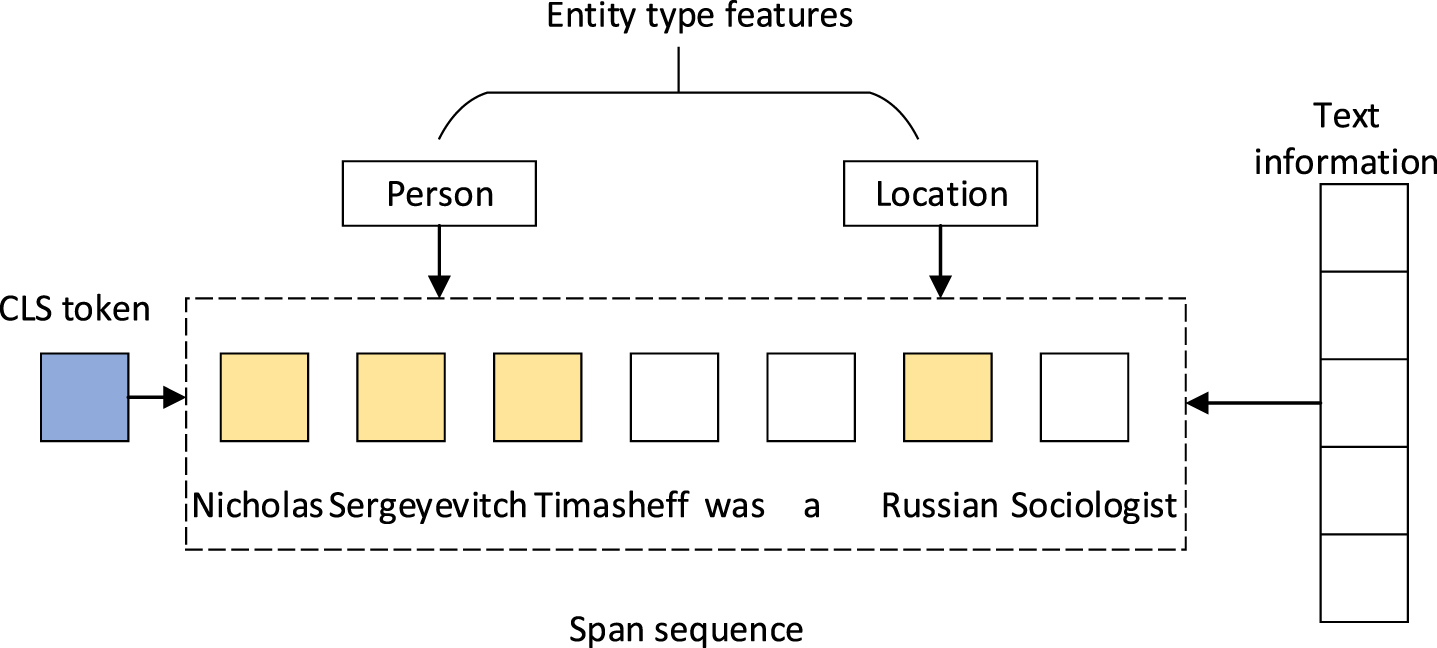
Fusion of entity type feature information.
Then use Softmax regression for entity classification, as shown in formula (7):
The main task of the relation classification layer is to classify the relations in the span sequences. The entity recognition with span sequence layer and the entity recognition between span sequence layer obtain the entity information in the document and embed it into the text information to form a new relationship classification sequence. Our model uses the Linear layer to calculate the score of the relationship classification sequence. We set the relationship filtering threshold to 0.6 (Section 4.5 of this article describes how to set the value of the relationship filtering threshold.) If the score is bigger than the relationship filtering threshold, it is considered to be an effective relationship in the classification sequence, otherwise it is considered an invalid relationship in classification sequence. The relationship type features are represented by Cr, and the text information and relationship type feature information are integrated into the relationship classification sequence, as shown in formula (8):
Since both entity classification and relation classification are multiclassification problems, the cross-entropy loss function is used in the ISLM model. The loss function of the entity recognition with span sequence layer, the loss function of the entity recognition between the span sequence layer and the loss function of the relationship classification layer are shown in formulas (10), (11), and (12), respectively.
Where c1 represents the weight of the entity recognition with span sequence layer, and c2 represents the weight of the entity recognition between span sequence layer, and c3 represents the weight of the relation classification layer; The length of c1, c2 and c3 are equal to the length of the real relation type vector respectively; j1, j2 and j3 represents the length of the predicted vectors; y b represents the prediction vector of the entity recognition with span sequence layer; y e represents the prediction vector of the entity recognition between span sequence layer; Y represents the prediction vector of the relation classification layer.
The loss function of the whole model is the sum of the loss functions of the entity recognition with span sequence layer, entity recognition between span sequence layer and the relation classification layer, as shown in formula (13).
This part includes 6 subsections, which describes the dataset of the experiment in this paper, the experimental software and hardware environment, the experimental parameter settings, the comparative experiment and the comparison of the model performance under different parameters.
Dataset
The DocRED dataset is a human-annotated relation extraction dataset at document-level from Wikipedia, including more than 5,000 Wikipedia documents. In this experiment, the training set contains 3008 documents, the evaluation set contains 300 documents and the test set contains 700 documents. The dataset division is shown in Table 2.
Data set split
Data set split
The model in this paper uses the PyTorch framework to implement the ISLM proposed in this paper. Where the PyTorch version is 1.8.0. The experimental software and hardware environment is shown in Table 3.
Software and hardware environment
Software and hardware environment
The experiment in this paper uses the BERT-BASE-CASED pre-training model, the maximum length of the span sequence is set at 11, and the relation filtering threshold is set at 0.6. The main hyperparameter settings of this experiment are shown in Table 4.
Parameter settings
Parameter settings
The evaluation used in this experiment are Precision (P) [35, 36], Recall (R) [37, 38] and F1-score(F1) [39, 40], and their representations are shown in formulas (14), (15) and (16):
The model proposed in this paper is compared with the state-of-the-art relation extraction models in recent years. The comparison model is as follows: CNN [24], LSTM [24], Ctx-Aware [24] and Bi-LSTM [24] are the results of training the DocRED dataset using CNN, LSTM, Ctx-Aware and Bi LSTM neural networks, respectively. It provides a baseline model. Two-Step [25] introduced the use of two-step entity relationship extraction. The first step is to predict whether there is a relationship between two entities, and the second step is to predict the specific relationship between the two entities. HIN [41] Introduced a Hierarchy Inference Network (HIN) model to obtain information from the entity, sentence, and document levels. LSR [42] introduced a method of enhancing the inference relationship between sentences by automatically analyzing latent document-level texts. CorefRo [43] Introduced a model that can effectively represent coreferential relationships, achieving good extraction performance on DocRED dataset. JEREX [30] introduced the first document-level entity relationship extraction at the entity level, which uses multi-sentence learning to extract entity and relationship information within a document. DocRE-SD [44] introduced a document-level entity relationship extraction model with inference module, which is based on the multi-head self-attention mechanism.
Table 5 shows the results of comparing the performance of the ISLM with the baseline model on the DocRED dataset. The data show that the F1-score of the ISLM on the DocRED dataset is 63.14%, an increase of 2.74%. This improvement comes from the fact that the span division of the token sequence can effectively utilize the overlapping relationship information in the text and improve the information utilization rate. Using inter span learning to extract entity information in different span sequences can effectively solve the problem of long-distance dependencies between entities. Adding entity type features to the entity recognition and relationship type features to the relationship classification can better combine the semantics of the whole text information, which also lifts the performance of model entity relation extraction.
Compared with the baseline model
Compared with the baseline model
When the span is too large or too small, the long-distance entity-relationship information in the overlapping relationship cannot be used well. The size of the span division will affect the entity pairs contained in the span sequence. At times, the setting of the span size will also affect the division of entities within the document.
ISLM sets the relationship filtering threshold when classifying the relationship. Only when the relationship classification sequence score is greater than the set relationship filtering threshold, the relationship between entities is considered to be valid. In order to find the most suitable maximum span value and relation filtering threshold, this part verifies the extraction performance of the model on the DocRED dataset by adjusting the parameter values. At the same time, the change of the training loss function, during the parameter changing, is also compared. When the model selects the optimal parameter value of the maximum span value and the relationship filtering threshold, only these two parameters are changed, and the other parameters of the experiment remain unchanged. The F1-score are shown in Table 6.
Performance of the model with different parameter values
Performance of the model with different parameter values
According to Table 6, when the maximum span value of the model is 11 and the relationship filtering threshold value is 0.6, the F1-score of the model achieves the maximum value of 63.14. Therefore, the maximum span value of the model in this paper is 11, and the relationship filtering threshold value is 0.6.
Where each row of the table represents the change in the maximum span value, and each column represents the change in the relationship filtering threshold value. The two-dimensional table represents the F1-score of the model in different maximum span values and relational filtering threshold values.
It can be seen from Table 6 that the ISLM model has the best performance when the maximum span value is 11 and the relation filtering threshold is 0.6. Since different parameter values also have an impact on the model training loss, it is found from Table 6 that when the maximum span value is 11 and the relationship filtering threshold is 0.6, the model extraction effect is the best. So, we draw the model training loss when the maximum span value is 11 and the relation filtering threshold changes. When the relation filtering threshold is 0.6, the maximum span changes. Specifically, as shown in Figs. 6 and 7.
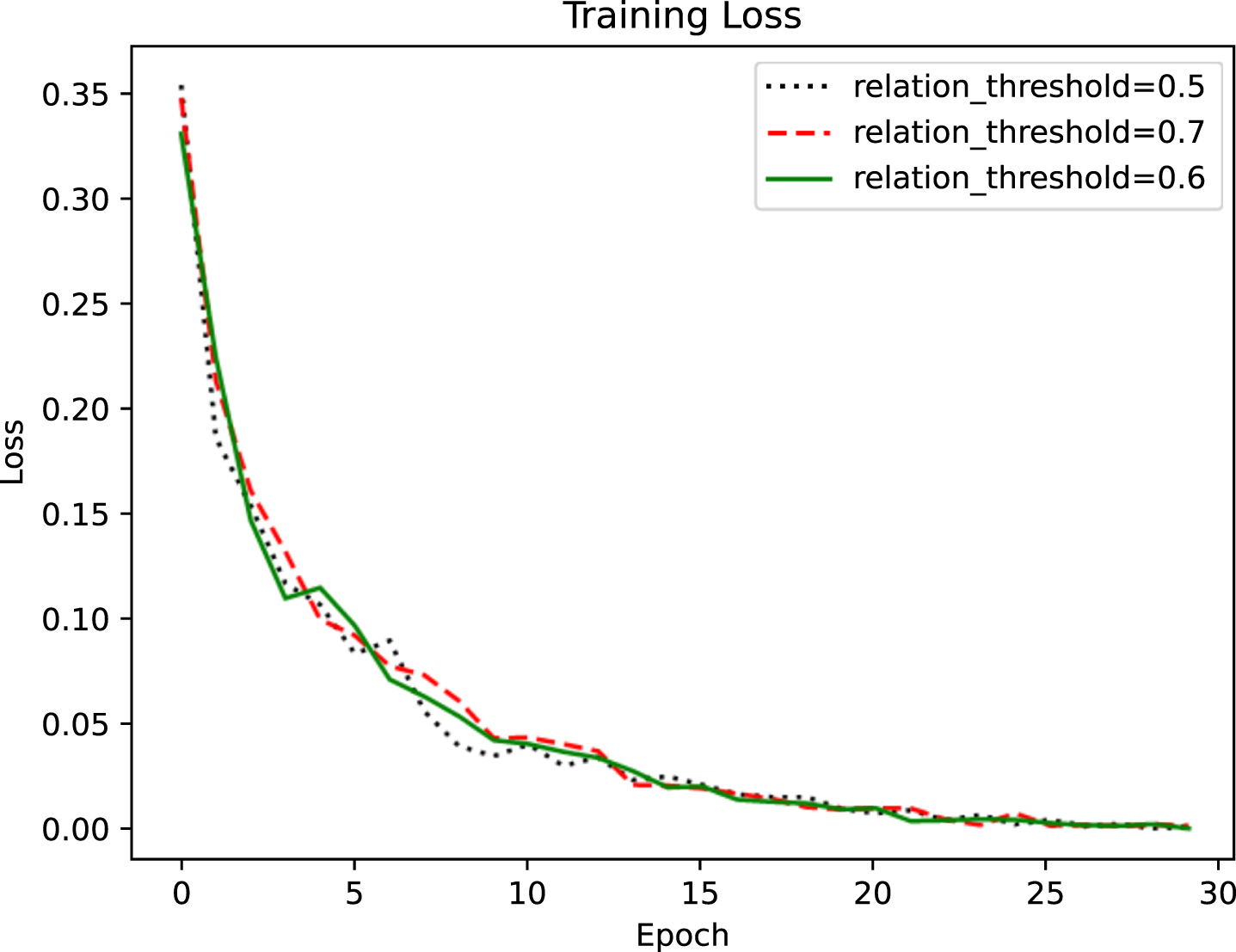
Training loss when the threshold of relational filtering change.
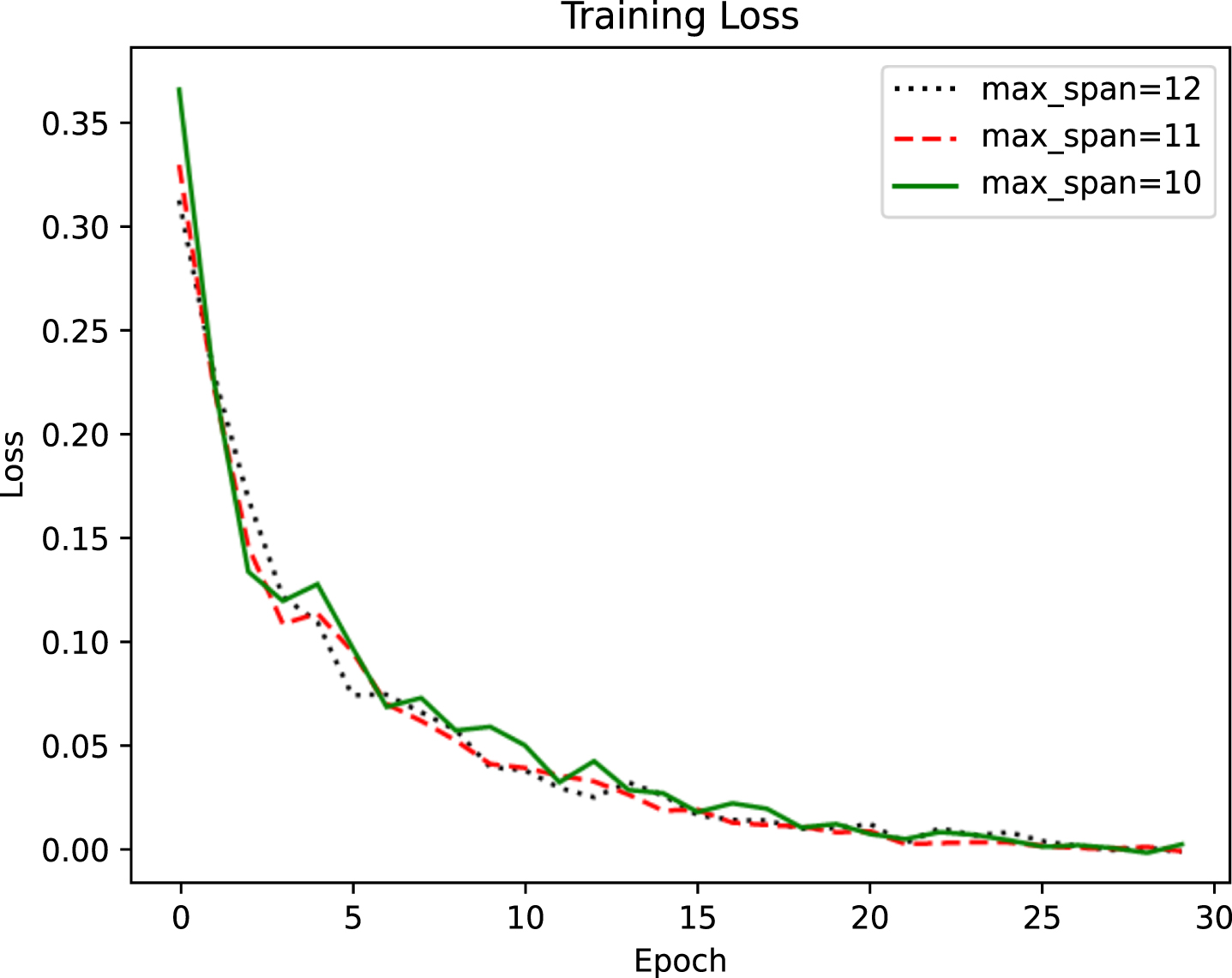
Training loss when the maximum span value changes.
Figure 6 shows the model training loss for different values of the relation filtering threshold when the maximum span value is 11. Through the Fig. 6, when we set the relation filtering threshold to 0.6, the initial value of the training loss of the model is the smallest and the final value is the smallest. Therefore, we set the relationship filtering threshold to 0.6.
Figure 7 shows the model training loss with different maximum span values when the relation filtering threshold is 0.6. When the maximum span value is 11, although the model training loss is not the smallest at the beginning, the training loss converges the fastest and the final loss value is the smallest. Therefore, we set the maximum span value to 0.6.
This article proposes a model that uses span and inter span learning to extract entity relationships. In order to verify the effectiveness of using random span to partition word vectors, inter span learning, and fuse relationship type features, this paper designs ablation experiments as shown in Table 7.
Comparison of ablation experiment results
Comparison of ablation experiment results
ISLM’ Indicates that the model proposed in this paper removes the use of spans to divide word vectors, and learns between different spans and fuses relationship type features.
ISLM’ + S represents that only the span is used to divide the word vector. ISLM’ + S + ISL represents not only using spans to divide word vectors, but also using inter-span learning to obtain information between different spans.
ISLM’ + S + ISL + F represents the use of spans to divide word vectors, and the use of inter-span learning to obtain information between different spans and integrate the relationship type features that exist in the text, that is, the model we proposed in this paper.
Test the Precision, Recall and F1-Score of different models for comparison.
From Table 7, it can be seen that using spans to divide the word vectors, learning between spans and integrating relationship type features can gradually increase the F1-score of the model, from 43.62% to 63.14%, an increase of 19.88%. Compared with ISLM’ + S, the F1-score of the model after adding inter-span learning increased from 60.99% to 62.85%, an increase of 1.86%. That is because using inter-span learning can effectively acquire information within span sequences of different span sequences and improve the utilization of textual information.
In order to study the impact of relations between relatively distant entities on relation classification, a comparative experiment is carried out in this section. The results are shown in Table 8.
The impact of long-distance relationships on relationship classification
The impact of long-distance relationships on relationship classification
Among them, -Long-distance relationship indicates the result of removing the relatively long-distance relationship. From Table 8, we can conclude that after removing the relatively long-distance relationship, the result of relationship classification dropped from 63.14% to 61.78%, a drop of 1.36%. This proves that the acquisition of relatively distant entity relationships is helpful to the relationship classification results, which shows that the problem of long-distance dependence between entities has been partially solved.
On the basis of analyzing the existing entity-relation extraction methods, this paper proposes an Inter Span learning for document-level relation extraction (ISLM). The model first divides the word vector based on the span to form a span sequence after the BERT pre-training model, and then based on the span the word vector is divided to form a span sequence. Second, the convolutional neural network is used to extract the entity information in the span sequence. Third, the entity information located in different span sequences is extracted, and the entity type features are fused, and Softmax regression is used to classify entities. Finally, the text information and relation type features are fused, and the relation is classified using Linear Layer. The experimental results show that the model has achieved certain effects.
The next step is to study the span sequence formed after division, and deconstruct the entity relationship contained in the span sequence, so as to achieve the purpose of better extraction when the text contains complex overlapping relationships and long-distance dependencies between entities.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China: [Grant Number 62076006]; 2019 Anhui Provincial Natural Science Foundation Project: [Grant Number 1908085MF189]; University Synergy Innovation Program of Anhui Province: [Grant Number GXXT-2021-008].