
Abstract
In the entity extraction task, there are some complex extraction problems, such as nested entity, entity boundary recognition, context ambiguity, and multi-instance entity recognition. Entity nesting is an important challenge in relational extraction. The main reason of entity nesting problem is that the boundary information between entities is not clear. In order to solve the entity nesting problem at the fragment level, while preserving the relationship between fragments with the same characteristics and improving efficiency, we proposed a brand new fragment annotation method. On the basis of traditional fragment annotation method, combined with pointer annotation method, we designed an annotation method of "ergodic enumeration + group mapping". On the basis of this method, an entity extraction model is designed: Span-Extraction Based Entity Extraction Model (LMA). Our model underwent a series of validations in the English data sets New York Times(NYT) and WEBNLG, showing significant improvements over the baseline model F1. It can effectively alleviate the above problems.
Introduction
Relational Triple Extraction (RTE) [1], also known as entity relationship joint extraction, is a classic task in the field of information extraction. It aims to extract structured relational triples (Subjects, Relationships, Objects) from text to build knowledge maps. Entity relationship extraction can be divided into pipeline extraction and joint entity extraction. The pipeline model divides the entity relationship extraction task into two subtasks. First, entity recognition is carried out, and then the relationship classification task is completed in the case of a given entity and sentence. The advantage of the pipeline model is that it is easy to realize and has high flexibility, but it is easy to cause entity overlap and exposure bias. Exposure bias refers to the phenomenon where during training, each input is conditioned on the true label from the real sample, but during testing, the input is conditioned on the output from the previous step. Entity overlap refers to some identical entities between different relationship triples, as shown in Table 1. Joint entity and relationship extraction refers to the modeling and extraction of both entities and relationships in a single step, in contrast to the pipeline approach where entity recognition and relationship extraction are done separately. Joint extraction makes use of the potential relationship between the two tasks, which can alleviate the shortcomings of error accumulation to some extent. However, the problem of entity overlapped and exposure bias remains challenging to solve. To address the aforementioned issues, this paper proposes a joint relational extraction model that leverages partial segment tagging. Our model effectively deals with the challenges of entity overlapping and exposure bias.
Examples of entity overlap
Entity relationship extraction can be divided into two main categories based on the model structure: pipeline extraction and joint entity and relationship extraction. Pipeline extraction primarily leverages recurrent neural networks (RNN), convolutional neural networks (CNN), and other neural network structures. Socher [2] was the first to apply RNN to relational extraction models, effectively addressing the challenge of capturing the meaning of long phrases. Zeng [3] pioneered the use of CNN for extracting word and sentence-level features in the context of relationship extraction. Nguyen [4] proposed a convolutional neural network (CNN)-based model that employs multiple window-size convolution kernels to effectively capture implicit features in text. This approach reduces the reliance on external toolkits and sequence-to-sequence methods, potentially leading to better performance and increased efficiency. Wu [5] proposed a relationship extraction model based on the attention mechanism at the neuron block level. Greff [6] proposed an LSTM based method for relation extraction, which is based on the shortest path of the syntactic dependency analysis tree. It integrates word vectors, part of speech, syntax, and other features for relational classification. Zhang [7] used the BiLSTM model to extract relations by combining the information before and after the current word. Har [8] proposed a method for entity recognition and relationship classification, which leverages part-of-speech and syntactic dependency features in the input layer to extract relationships between entities.
While the pipeline method for entity and relationship extraction is straightforward, it has some inherent limitations. (1) Error accumulation: Errors in entity extraction will further affect the results of relationship extraction. (2) Entity redundancy: When performing relationship classification, it is necessary to match the pre-extracted entities in pairs. When a sentence has multiple entity pairs, multiple <sentence, e1, e2>, need to be constructed for multiple relationship classifications. (3) Lack of interaction: Ignoring the internal connections and dependencies between the two tasks can limit the performance of joint entity and relationship extraction. In recent studies on pipeline models, Qin [9] applied the idea of reinforcement learning to separately extract entities and relationships. Although the pipeline models eventually produced relatively good results, they ignored the interdependent relationship between entities and relationships. To address this issue, Zhong and Chen [10] proposed a novel pipeline method that combines entity information for entity and relationship extraction. However, this method still suffers from error propagation problems, and therefore, further exploration of better solutions is necessary. Early pipeline extraction work failed to capture the implicit correlation between these two independent subtasks, resulting in these methods being greatly susceptible to error propagation. To address these issues, recent research has primarily focused on joint entity and relationship extraction. Joint extraction models can be mainly classified into two categories: feature-based models and end-to-end joint extraction models. Feature-based models [11] introduce a relatively complex feature engineering process and heavily rely on natural language processing tools for feature extraction and laborious manual operations.Sequence-to-Sequence (Seq2Seq) is a general end-to-end sequence learning method, primarily based on the encoder-decoder architecture. Zheng [12] introduced a unified tagging scheme and transformed the relationship extraction problem into a sequence tagging problem.To address the issue of overlapping triplets, Zeng [13] applied a Seq2Seq model with a copying mechanism.Although these models have achieved certain effectiveness, most of them are still unable to handle complex application scenarios, where a sentence is composed of multiple overlapping relationship triplets. Ye [14] propose generative models that view triple as a token sequence. Wei [15], Yuan [16], Zheng [17] and Li [18] decomposes RTE into different subtasks. However, those methods learn the interaction between sub-tasks solely through input sharing, which can lead to cascade errors.
Model
LMA consists of both a coding layer and a decoding layer, as shown in Figure 1. We utilized a BERT pre-trained model [19] with single-character tokens for word unit encoding. The pre-trained model outputs word and sentence vectors that contain a large amount of external semantic information. For fragment encoding, we combined the word and sentence vectors generated by the pre-trained model with a fragment embedding method to generate initial fragment vectors. We then utilized two models, namely, a long short-term memory network and a multi-head self-attention mechanism [20], to extract fragment features, which enabled the direct construction of fragment semantic vectors. The encoding layer used fragment markers and different strategies to map the positional relationships between tokens and their corresponding fragments.The decoding layer used a multi-head selection mechanism and enumerate the relationships between fragment pairs to decode the entity relationship triplets, thereby avoiding exposure bias, relationship overlaps, and error accumulation.
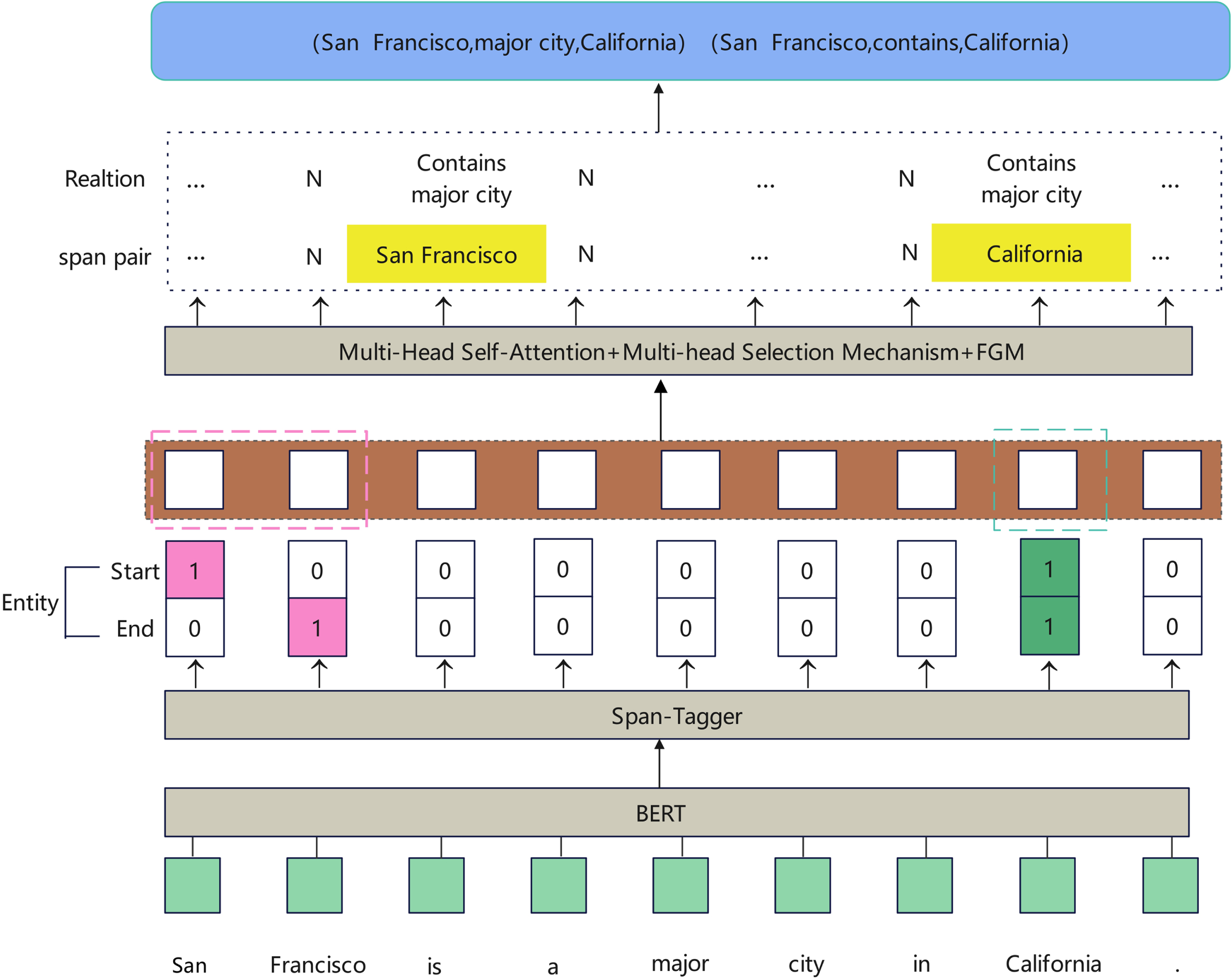
The framework of LMA.
At present, the mainstream pre-training models are based on word elements to sentence. As a result, all kinds of labeling models based on word markers can only predict the label of a single word element. During recognition, it is necessary to combine the recognition results of multiple words, which can lead to error accumulation and difficulty in resolving nested entities. In this paper, we address the nesting problem by enumerating fragments, which ensures that all candidate entities appear in the enumerated fragments. At the same time, the fragment marking method is designed, which combines the position index of the first and last lexical elements that make up the fragment into an index tuple to mark the fragment.The main idea of fragment tagging is to annotate fragments with their corresponding location indices in a fragment embedding matrix, using a meta-location index. For instance, consider the sentence "San Francisco is a major city in California". Assuming that tokens are set based on terms and the maximum length of the sliding window is 7, tokens in the text are sequentially read as a starting point. The token "San" is marked as (0, 0), "San Francisco" is marked as (0, 1), "San Francisco is" is marked as (0, 2), and so on. When the fragment length meets the maximum window length, This round of iteration for the extraction task has been completed. Before next round of operations, the "group mapping" task for the corresponding group will be performed first, followed by the next round of parameter settings.Meanwhile, the tagging order of fragments is mapped using three different strategies: fragment same start mapping strategy, fragment same end mapping policy, and fragment same length mapping policy. The fragment marker diagram is shown in Figure 2.

Span Marking Diagram
The location index of the fragment in the fragment embedding matrix varies according to the different fragment mapping strategies. The mapping strategy for the same start point of a fragment(SSF): Fix the starting point of the text fragment, change the length of the fragment by changing the endpoint of the fragment, that is the right border of the sliding window until the maximum length of the window is reached, and centralize the fragments from the same starting point. The mapping strategy for the same length of a fragment(SLF): The window length is fixed and the text is traversed, then the window length is adjusted and the text is re-traversed until the maximum window length is reached. Fragments with identical lengths are extracted and sorted together. The mapping strategy for the same end point of a fragment(SEF): Fix the end point of the text fragment, change the length of the fragment by changing the startpoint of the fragment, that is the left border of the sliding window until the maximum length of the window is reached, and centralize the fragments from the same starting point.
Group mapping method
Before proceeding to the next round of the enumeration task, we first need to perform the "group mapping" task for the group. The purpose of this task is to build an index in the matrix for the extracted fragments in accordance with the previously extracted grouping order and to preserve common features of a group of fragments through mapping logic. We take SSF as an example. Specifically, we first package all the fragments extracted in this round that have the feature starting coordinate of "0" into a group and then fill them into the matrix sequentially. For example, As shown in Figure 3, the first fragment "San" in the first group has a fragment coordinate of (0,0), which is mapped to the matrix grid where the fragment starting coordinate is 0 and the fragment ending coordinate is 0 in the two-dimensional matrix. Similarly, all indices of the first group are filled in horizontally. After the mapping is completed, the next round of parameter settings begins, moving the left side of the window (Start) one position to the right, while the right side of the window (End) moves back to the same coordinate point as the left side of the window, and the next round of operations begins. After one round of operations is completed, the next round will be mapped in a new row in the matrix, using the "line wrapping" logical structure as a separator between different groups. When the last fragment with a coordinate of (6,6) is extracted, the fragment starting coordinate and the fragment ending coordinate are equal, and the end of the text is reached, and the group is packaged and mapped. Once all groups have completed mapping, all rounds end, and the fragment extraction task also ends. Through this logical structure where each row in the matrix represents a group, we can preserve the shared characteristics of fragments with the same starting point. Finally, we flatten the two-dimensional matrix into a one-dimensional list according to the index order, and this one-dimensional list is the output of the fragment extraction, which will serve as the input for the entity classification task.
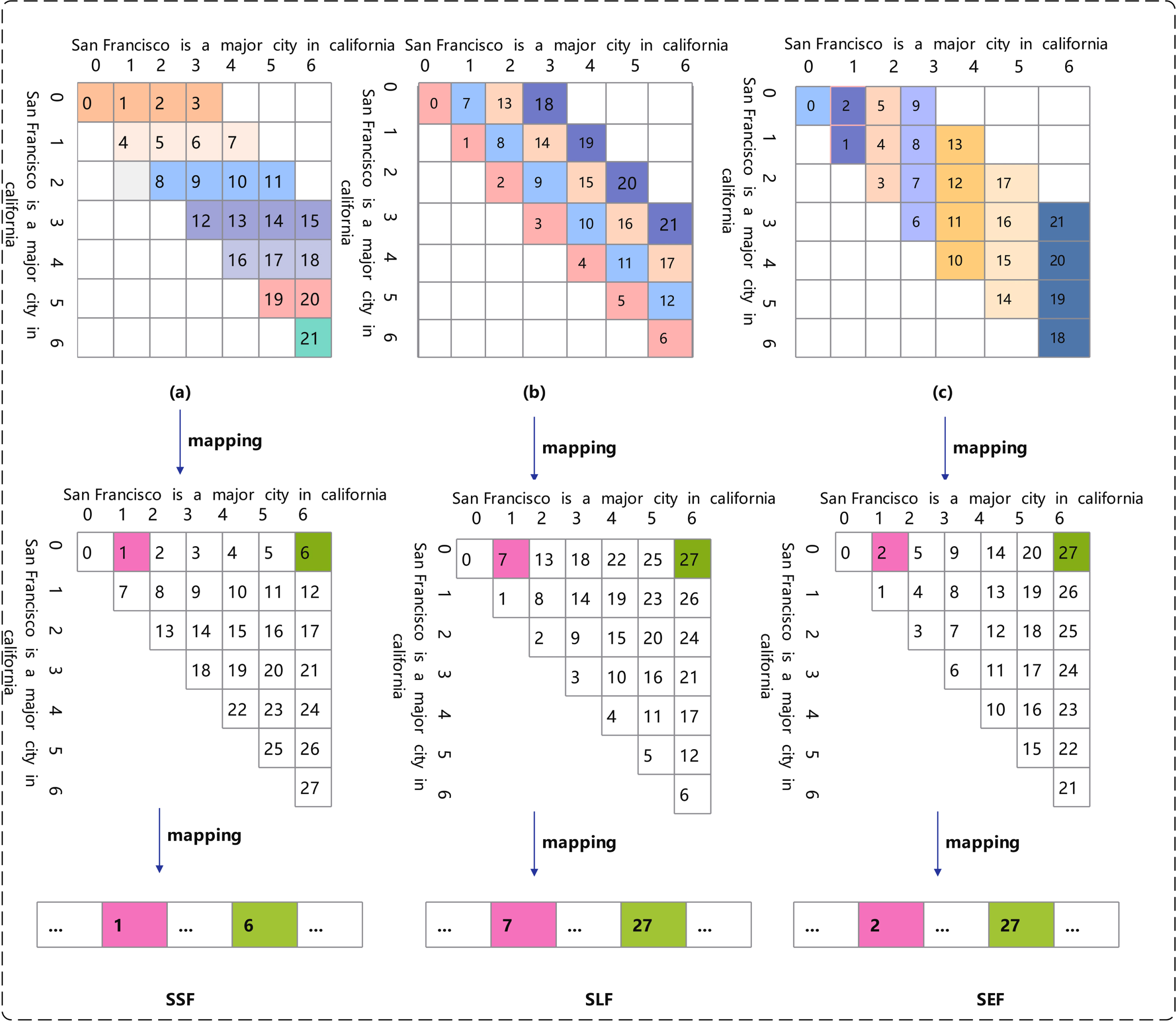
Three different mapping strategies
First, the one-dimensional list outputted by the group mapping method is imported into the entity classification layer. As shown in Figure 4, the same fragment will have different index values depending on the mapping strategy used. Then, we process the input fragment list using LSTM and a multi-head self-attention mechanism. The resulting list is then passed through a sigmoid activation function to perform a multi-classification task on each fragment, constructing a two-dimensional matrix of "entity fragment-entity type", which can accurately classify each fragment according to each type. The fragment feature matrix calculation method for SLF and SEF is the same as that for SSF. However, due to the different feature mapping strategies, the feature matrices will also differ, which allows for different perspectives to be used to focus on different fragment features and adapt to different semantic information needs.
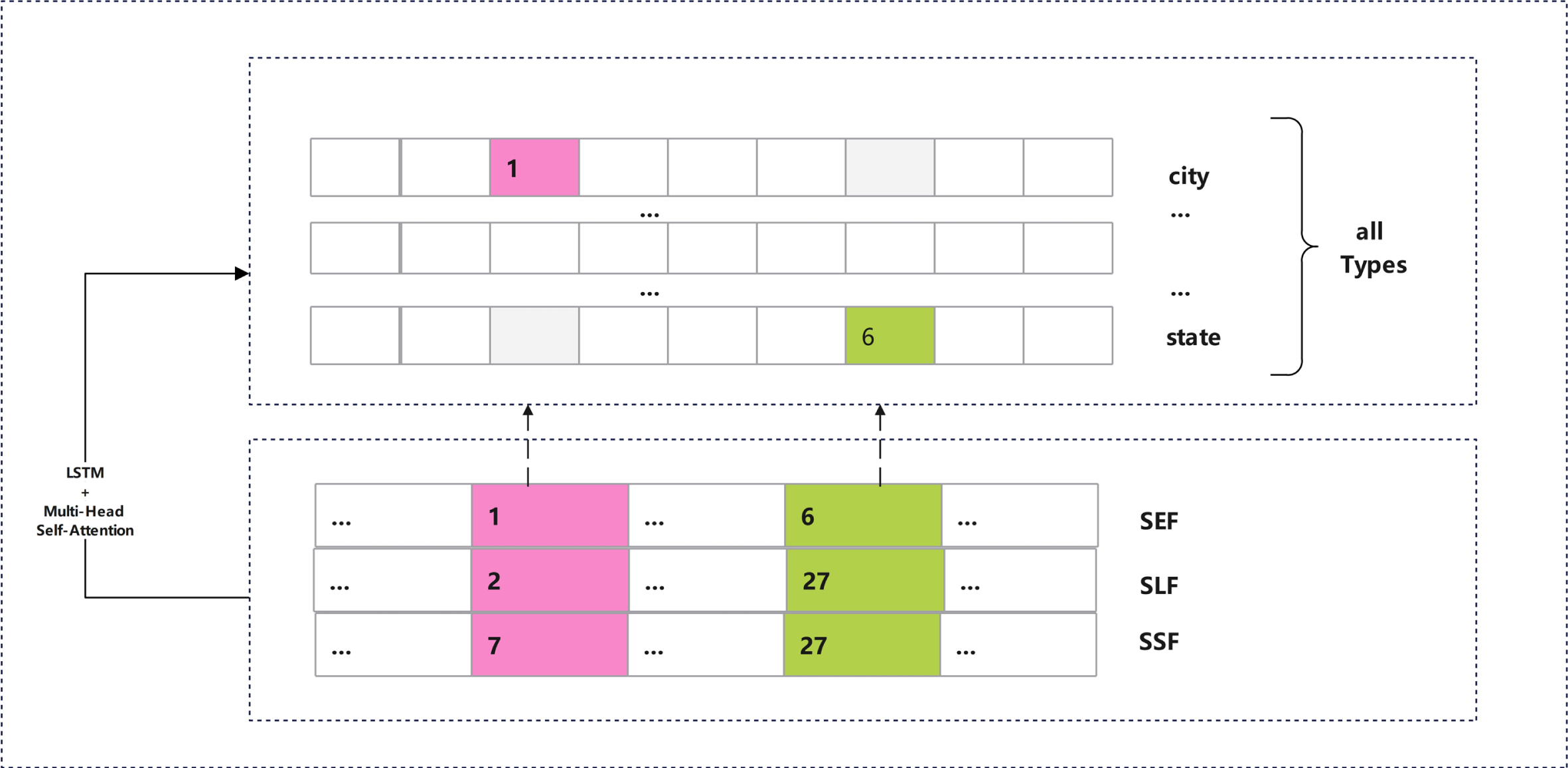
Example entity classification layer
Token representation
First, the words are encoded based on the vocabulary of the selected BERT model. Then, the combined fragment’s index in the fragment sequence is determined using the designed fragment marker and corresponding fragment mapping strategy. The word units are then inputted, and the contextual semantic information of each word unit and the overall semantic information of the sentence are extracted. The text input is expressed as
Where
Fragment vectors are constructed by averaging and pooling each word unit vector that constitutes a fragment, and then splicing them with sentence vectors. Assuming that
Among
To enhance the extraction of deep segment features and promote interaction among segment information, the LMA model proposed in this paper incorporates both LSTM [21] and multi-head self-attention mechanisms. By controlling the input content and memory unit content through the input gate, output gate, and forgetting gate, LSTM creates a memory of past input information. This enables LSTM to effectively capture context and dependencies between segments, leading to improved overall model performance. which can effectively alleviate the problems such as gradient disappearance and gradient explosion. The attention mechanism can selectively focus on important information in the text. Multi-head self-attention mechanism is a variation of the attention mechanism, in which Q (query), K (key), and V (value) are equal. Multiple queries are utilized to extract distinct sets of information from the input in parallel for concatenation, and shared attention is applied to information from different feature subspaces at various positions. This enables the model to capture a more comprehensive range of fragment feature information.
At the decoding layer, we use the multi-head selection mechanism, which aims to carry out single-step multi-head relationship extraction, so as to extract all existing entity relationships and overcome problems such as relationship overlap and exposure bias.
Antagonistic training
It is worth mentioning that to improve the robustness and generalization ability of the model, we have added confrontation training to the model. The purpose of confrontation training is to impose disturbances on the original input samples and then use them for training after obtaining the confrontation samples. In general, based on traditional training, the addition of confrontation training can further improve the effect. When we carried out the contrast experiment, the result was higher than the F1 value without the contrast experiment. The calculation process of the fragment vector is shown in Formula (7) [23] - (8) [24].
Multi category cross entropy loss function is adopted in this paper [25], and the formula is shown in Formula(9), The definition of the loss function for fragment multi-head selection is shown in Formula (10).
Dataset
English datasets NYT [26] and WebNLG [27] were used in the experiment. The NYT dataset contains 24 predefined relations, was generated through distant supervision from articles in the New York Post. Meanwhile, WebNLG, initially created for natural language generation tasks, was utilized by Zeng et al. To perform triple extraction of relations, resulting in the definition of 171 relations. The calculation formula is shown in Table 2.
Datasets basic information table
Datasets basic information table
Text can be divided into three categories according to entity overlap types: normal, entity pair overlay (EPO), and single entity overlay (SEO).The specific classification quantity is shown in Table 3.
Table of the number of relationship overlapping types of text
Table of the number of relationship overlapping types of text
In this study, we utilized a single NVIDIA TITAN XP graphics card with CentOS 7.9 operating system and 12G running memory for our deep learning experiments. The programming language used was Python 3.7, and the deep learning framework employed was Pytorch 1.7. During the model training phase, we set the maximum window length to 16, the maximum word element length to 128, and the word element vector dimension to 768. The batch size was set to 4, the learning rate to 0.00001, and the epoch to 100. These parameters were chosen after careful experimentation to achieve optimal results.
Evaluation
In this paper, we adopt accuracy rate(The ratio of true positive samples to the total number of samples predicted as positive by the model), recall rate(The ratio of true positive samples to the total number of actual positive samples), and F1(The F1 score is the harmonic mean of precision and recall) value as metrics for evaluating the experimental results, and adopt strict criteria.. The evaluation formula is shown in Formula(11)- Formula(13).
To verify the effectiveness of the model, we compared the mapping strategy for the same starting point of a fragment with other seven baseline models. In this paper, we designed three groups of experiments: a validation experiment,a hyperparameter experiment and a set of ablation experiments.
Validation Experiment
To validate the experiment, we selected two datasets and compared them with seven baseline models: (a) Novel-Tagging [12], a model that transforms the two tasks of relation extraction and entity extraction into a unified sequence annotation. (b)CasRel [15] employs a cascade binary tagging framework;(c) TP-Linker [28], a single-stage joint extraction model by linking token and token annotations. (d) PRGC [17], Proposed a joint relationship extraction framework based on predictive relationships and global correspondences.(e)TDEER [29], proposed a joint entity relationship extraction model based on translation decoding mechanism.(f) GRTE [30], proposes an iterative model to enhance the model’s learning of global features, which include two parts: the correlation between token pairs and the correlation between relationships.(g)EmRel [31], propose the integration of relational representations into the model for display.We reproduced the original paper and obtained experimental results in our experimental environment.The experimental results are shown in Table 4. The LMA method proposed in this paper has achieved a high level of accuracy, recall rate, and F1 score. In comparison, the Novel Tagging method fails to overcome the challenges of overlapping and nested entities, resulting in a lower recall rate. On the other hand, CasRel suffers from the issues of error transmission and exposure bias due to its pipeline-based extraction mode, where errors and omissions in subject extraction can directly affect the subsequent relationship prediction and object extraction. The TP-Linker method has a high annotation complexity, involves numerous redundant operations and information, and has low decoding efficiency. Similarly, PRGC belongs to the pipeline extraction mode, and its accuracy of final triplet extraction can be influenced by the relationship judgment and entity extraction parts.In contrast, LMA is a one-step decoding of entities and relationships, which fundamentally avoids the problem of exposure bias from the model mechanism. Moreover, the model’s accuracy rate and recall rate are almost the same, which proves its robustness. The LMA method performs well on WebNLG, which has a large number of relationships and a small amount of data, indicating that the model has strong generalization and migration ability, and is suitable for various application scenarios. The experimental results demonstrate that the LMA method proposed in this paper can effectively solve the problems of entity nesting and exposure bias.
Comparative experimental results table
Comparative experimental results table
Experimental Results of Different Window Lengths under Three Strategies
In order to investigate the effect of selecting different maximum window lengths under different segment index mapping strategies on experimental results, we used three different mapping strategies, namely "start" representing mapping strategy for segments with the same starting point, "end" representing mapping strategy for segments with the same ending point, and "length" representing mapping strategy for segments with the same length. We conducted experiments using different maximum window lengths, and the experimental results are shown in Table 5.
Table of experimental results of different window lengths under three strategies
Table of experimental results of different window lengths under three strategies
Discussion the ability of the multi-head selection mechanism
This section focuses on investigating the impact of removing the multi-head selection mechanism, and the experimental results are presented in Table 6. The removal of the multi-head selection mechanism led to a 2.7 and 1.2 decrease in the F1 score of the model on the NYT and WEBNLG datasets, respectively. This indicates that the multi-head attention mechanism’s fragment feature extraction is effective for the model. The main reason for this is that using LSTM for fragment encoding can only reinforce the interaction and dependency relationships between fragments, whereas it cannot extract deep fragment feature information. Overall, our findings demonstrate the importance of the multi-head attention mechanism in enhancing model performance.
Ablation experimental results table
Ablation experimental results table
This article proposes a new method for text annotation and mapping, and on this basis, establishes a joint extraction model. The model uses fragment tagging and fragment embedding methods to construct fragment vector representations; extracts fragment features through long short-term memory networks and multi-head self-attention mechanisms, and implements single-step relationship extraction through fragment label classification. This model aims to solve complex extraction problems such as nested entities, entity boundary recognition, context ambiguity, and multi-instance entity recognition in entity recognition tasks. Compared with various baseline models, the F1 value has obvious advantages in the English relation extraction dataset NYT and WebNLG. but there is still room for exploration. For example, the construction of fragment vector representations is somewhat rough. The next focus is on how to construct fragment vectors more accurately and efficiently. How to better match the subjects and objects of the same relationship and solve the problem of entity overlap is also a future research direction.