
Abstract
In the process of production, the label on the product provides the basic product information. Due to the complex text contained on the product labels, the high accuracy recognition for online production labels has always been a challenging problem. To address this issue, a more effective method for complex text detection by improving the convolutional recurrent neural network has been proposed to enhance the recognition accuracy of complex text. Firstly, the SE-DenseNet feature extraction network has been introduced for feature extraction, aiming to improve the model’s depth and feature extraction capacity. Then, the Bi-GRU network is utilized to learn and model the hidden states and spatial features extracted by SE-DenseNet, anticipate preliminary sequence results, reduce model parameters, and improve the model’s calculation performance. Finally, the CTC network is employed for transcription to convert each feature sequence prediction output by Bi-GRU into a label sequence, achieving complex text recognition. Experimental results on the SVT, IIIT-5K, ICDAR2013 public dataset, and a self-built dataset demonstrate that the proposed model achieves superior outcomes on both public and self-built datasets. Remarkably, the model exhibits the highest recognition accuracy of 93.2% on the ICDAR2013 public dataset, demonstrating its potential to support complex text recognition for online production labels.
Introduction
Product labeling plays a crucial role in modern production by serving as a marker in the product processing process and as an information record and traceability of product quality [1]. With the advent of information technology, enterprises can now improve their production efficiency and quality through digitalization and intelligence. In order to facilitate the identification of label information, more and more companies are using 2D codes, bar codes, RFID ray codes [2], and even electronic tags as information carriers [3]. However, in the field of cash crop-tobacco redrying, the gradual increase in the spectrum of tobacco raw materials in redrying units has made cross-production areas and modular processing commonplace. To date, complex text labels, shown in Fig. 1. containing Chinese characters, numbers, English letters, etc., are still used as information carriers on tobacco boxes during transfer and storage. So, online recognition with higher accuracy has long been a difficult subject because the environment is influenced by uneven illumination, complex backgrounds, and other issues. To improve the level of threshing and redrying production, it is crucial to design a system that can rapidly and reliably identify the information contained on the complex labels.
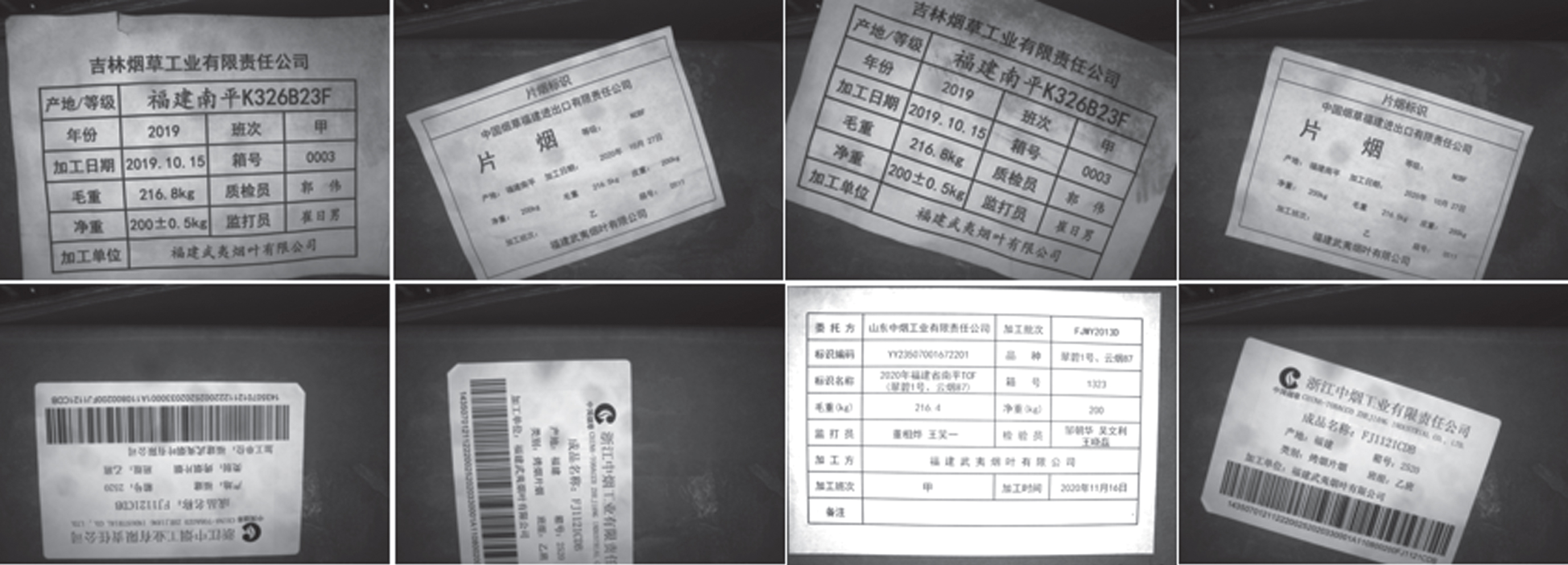
The labels on the tobacco boxes.
Currently, with the rapid development of deep learning, text recognition algorithms can be broadly classified into two types: character-level text recognition methods [4] and sequence label-based text recognition methods [5]. Character-level text recognition methods, exemplifi ed by Jaderberg et al. [6], involve positioning and cutting character images before feeding them into a deep convolutional neural network model for feature training. The output is then compared with a fixed dictionary to obtain the final text recognition result. To ensure recognition accuracy, character recognition requires the arduous learning of different character features without any learning omissions. On the other hand, sequence recognition algorithms can directly learn semantic features from the image and are divided into two types: temporal feature classification-based algorithms [7] and decoder-encoder-based algorithms [8]. Inspired by Vision Transformer [9, 10], Du et al. [11] completely abandoned the text sequence modeling stage and proposed a single visual text recognition (SVTR) based on a single visual model, aiming to enhance text recognition ability by augmenting the visual model. The network extracts features of different scales of text images in stages to form multi-granularity feature descriptions, so that the recognition task can be completed by a single visual model. Based on the encoder-decoder autoregressive method, Sheng et al. [12] and Zheng et al. [13] transformed recognition into the process of iterative decoding, considering contextual information and improving accuracy. However, the inference is slow due to verbatim transcription. Chandio et al. [14] proposed a segmentation-free method based on deep convolutional recurrent neural network to solve the problem of cursive text recognition, without pre-segmenting into a single character, taking the entire word image as input, and then converting it into a sequence of related features. In the existing research, text recognition is mainly for the recognition of a type of character, and the research in this paper focuses on the identification of re-cured cigarettes, which contain Chinese characters, letters and numbers. At present, there are few studies on complex text recognition containing Chinese characters, letters, and numbers.
In order to increase the recognition speed and enhances accuracy for complex text, a new algorithm based on a convolutional recurrent neural network is proposed. The improved model incorporates SE-DenseNet during the feature extraction phase aiming to increase the model depth and improve feature extraction capabilities. Bi-directional Gate Recurrent Unit (Bi-GRU) with lower parameters is adopted to generate feature sequences, which can be predicted by the CTC networks and that will be turned into a label sequence.
Network architecture
The proposed structural design for the recognition model based on the convolutional recurrent neural network is shown in Fig. 2. The model comprises three modules: the convolutional layers (SE-DenseNet) [15], the recurrent layers (Bi-GRU) [16], and the transcription layers (CTC) [17]. the specific network architectures are shown in Table 1.
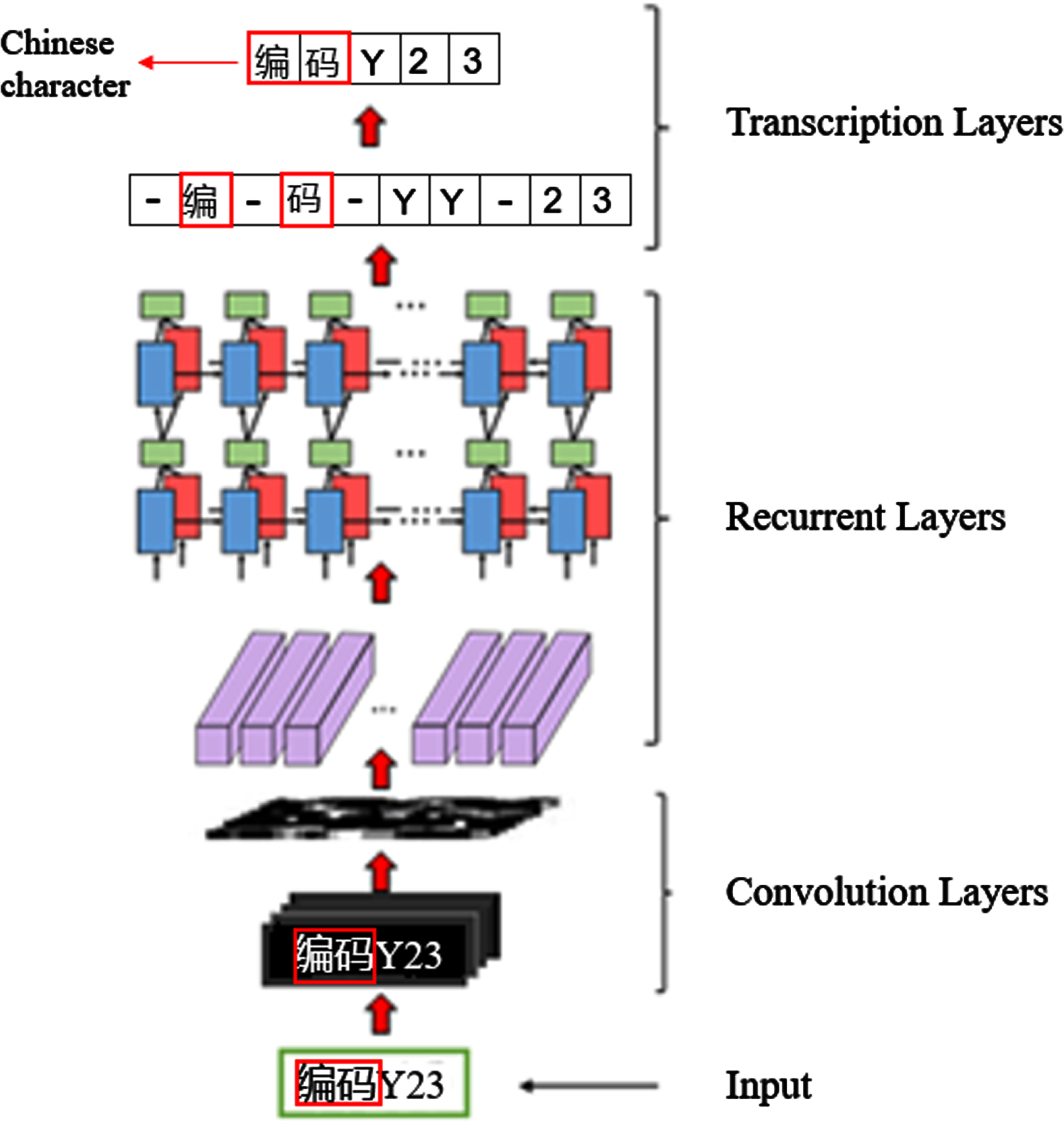
Schematic diagram of the text recognition model of tobacco marking.
Network architecture table
The process of deep feature extraction using Convolutional Neural Networks (CNN) is highly adaptive and effective. To extract features in target detection models, a pre-trained image classification model can be used as the backbone network, with the fully connected layer removed. However, as the depth of the model increases, the gradient at the front progressively diminishes, making it difficult to update during gradient return and leading to the problem of gradient disappearance. This issue becomes more pronounced as the depth of the model increases and the number of parameters expands. To address this challenge, Huang et al. [18] proposed DenseNet, which restructures each concatenation of all network outputs in front of each convolutional layer into network input. This not only increases feature utilization at each layer but also reduces the number of parameters in the model. This approach enhances gradient propagation and improves the overall training efficiency of deep network models.
As illustrated in Fig. 3. a dense architecture block Dense-Block is utilized in the DenseNet model for feature extraction. Assume that Dense-Block has l convolutional layers, its output expression can be expressed as:
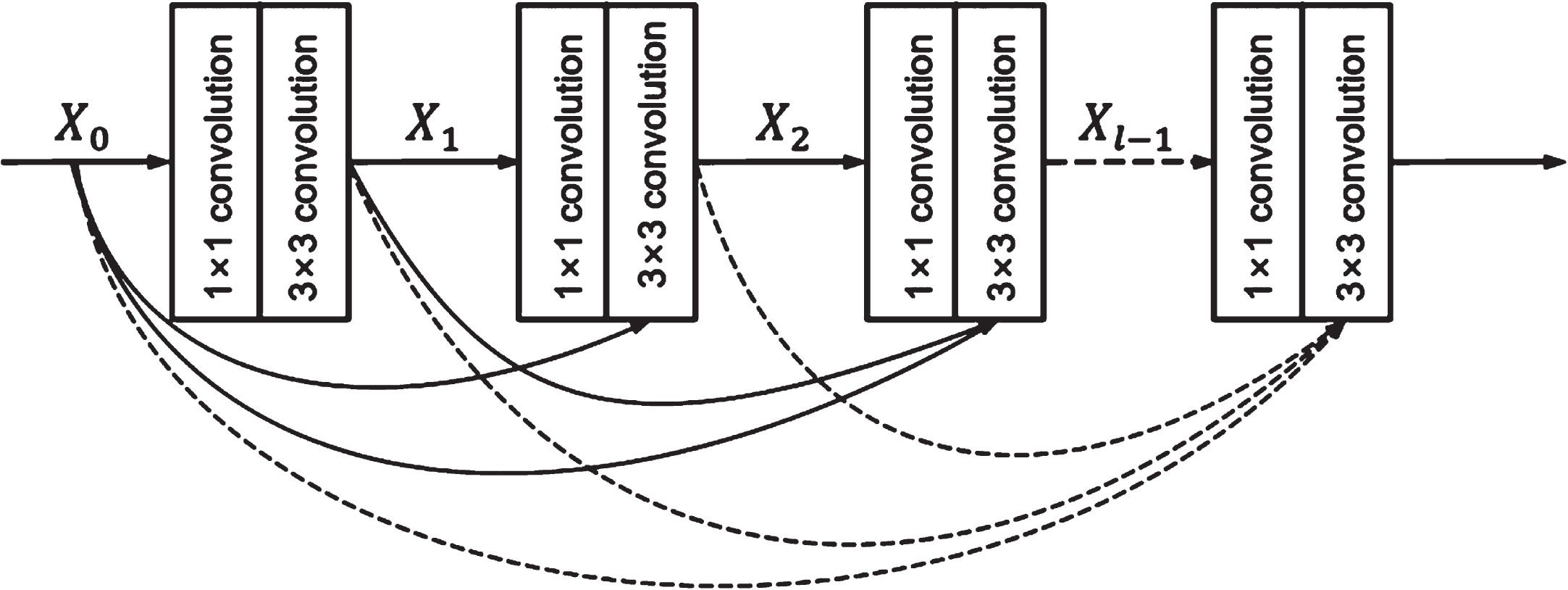
Dense-Block module.
Where H l (·) is a nonlinear transformation function, [x l-1, x l-2, ·· · , x 2, x 1] is the output splicing of 0 to l - 1 layer. The Dense-Block architecture, according to analysis, makes it possible to get global knowledge by reusing features, decreases computational demands, broadens the variety of input data, and enhances model feature extraction abilities. This feature reuse strategy, however, does not successfully assess the significance of feature information in the feature layer or suitably increase the weight of such information. The SE-Block module developed by the SENet network [19] has proven its capacity to execute feature weighting on significant images during the 2017 ILSVRC classification competition.
The schematic diagram of the SE-Block module architecture is shown in Fig. 4. It can be seen that the SE-Block module obtains the feature map C × W × H by performing serialized convolution operations on each output. It then completes the recalibration of feature weights by performing the Squeeze, Excitation, and Reweigh operations.
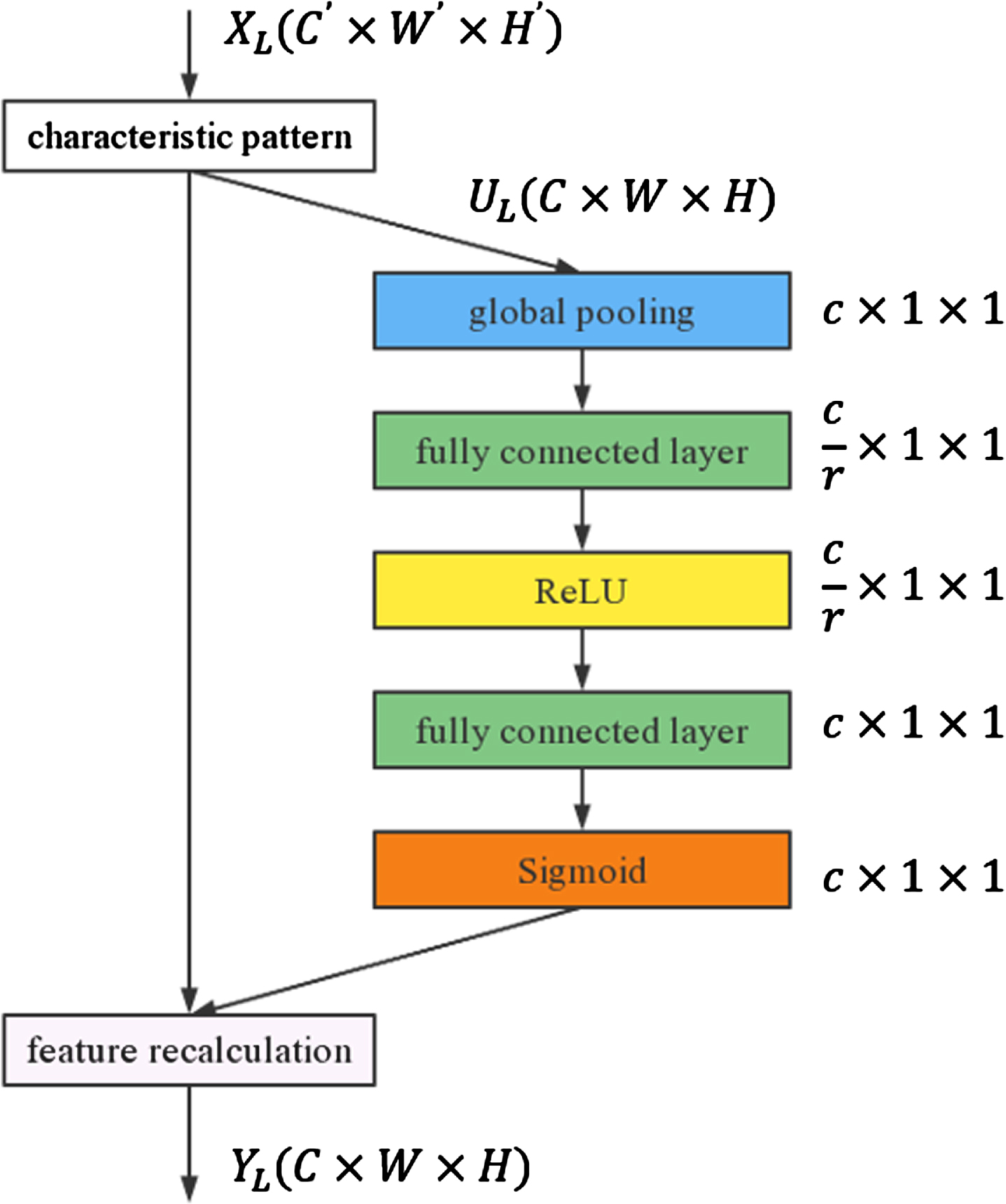
SE-Block module.
By conducting global average pooling on the C × W × H feature map U, the Squeeze module compresses the feature map on the spatial dimension into a 1 × 1 × C feature map, effectively getting the global receptive field, which can be written as:
To acquire the relevant feature weights between each feature channel, the excitation module runs the outcomes of the squeeze operation through a two-layer fully connected neural network, which can be calculated as follows:
Where δ and σ denote the activation functions for ReLU and sigmoid, respectively.
The reweigh module undertakes the pivotal task of recalibrating the feature weights. This is achieved by multiplying the original features with the corresponding feature weights between the feature channels, which were determined by the excitation module. The process can be described as:
DenseNet is used as the backbone network in this paper to develop a more effective feature extraction network, with the attention mechanism network SENet introduced in each 3×3 convolutional layer of the DenseNet network. The weights of the feature output channels of each layer of the Dense-Block module are predicted in this manner to achieve adaptive calibration of the weights in the feature extraction process and to improve the network’s feature information extraction capability. Weighting is also used to obtain the interdependencies between the convolutional feature channels. The diagram of the SE-DenseNet dense block architecture is shown in Fig. 5.
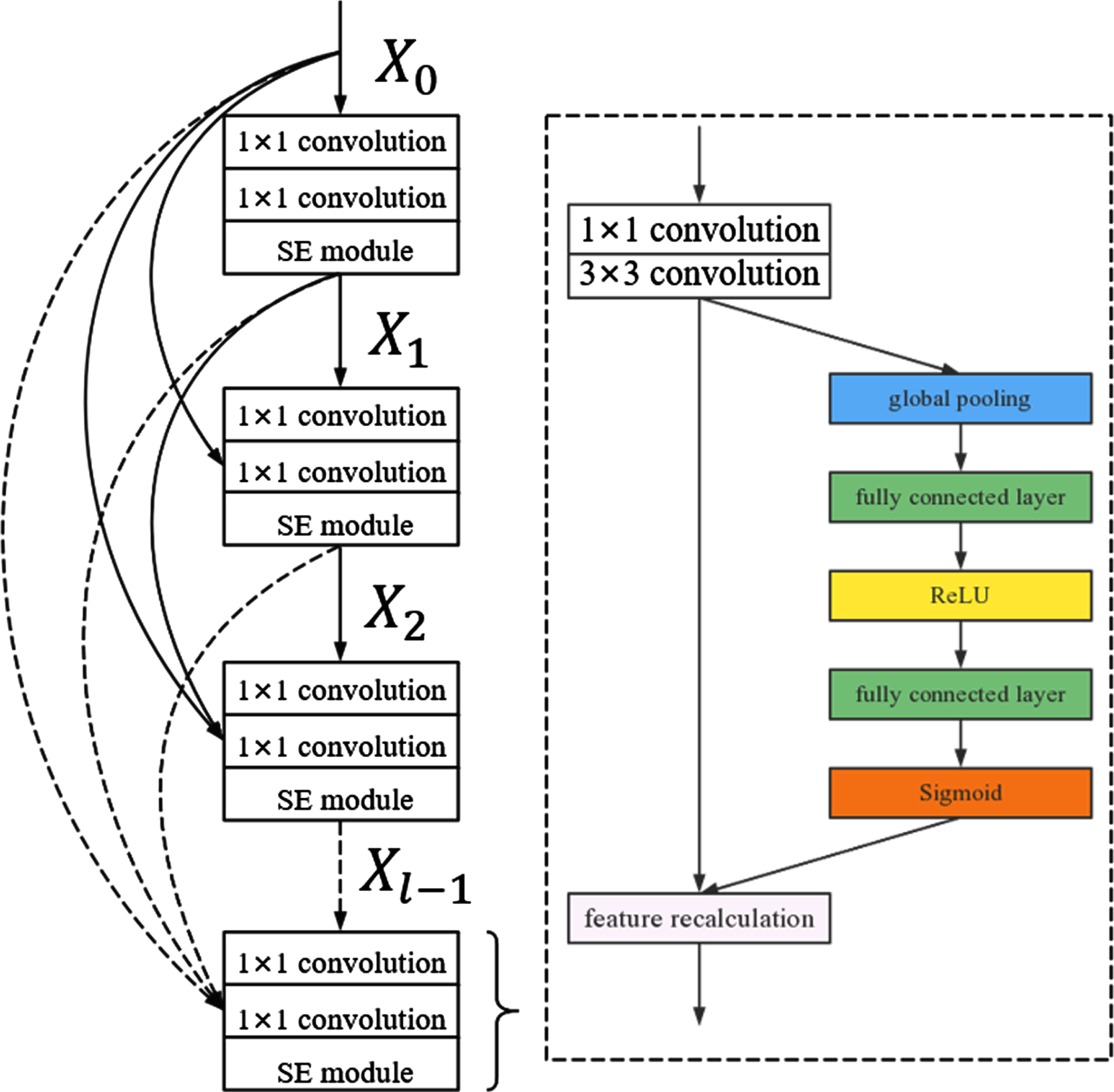
Schematic diagram of SE-DenseNet dense block architecture.
The image is passed through the convolutional network to generate a feature sequence{X 1, X 2, ⋯ , X t }into the recurrent layer, recurrent neural network (LSTM) [20] can process sequence-type data to predict the label distribution of each frame, but its complex network architecture and a large number of calculation parameters deepen the difficulty of model training to a certain extent. To reduce the calculation of model training parameters without reducing the recognition accuracy, this paper introduces a Gated Recurrent Unit (GRU) similar to SLTM [21], which achieves a good balance between reducing the computational power of the model and improving the accuracy.
The convolutional network generates a feature sequence for the input image, denoted as {X 1, X 2, ⋯ , X t }, which is then fed into the recurrent neural network (LSTM) to predict the label distribution of each frame. However, due to its complex network architecture and numerous calculation parameters, it is challenging to train the model effectively. In order to address this issue, a Gated Recurrent Unit (GRU) is introduced in this study with a network structure similar to LSTM. GRU strikes a fine balance between reducing the computational burden of the model and maintaining high accuracy levels, thereby improving model training efficiency while preserving recognition accuracy. The GRU network architecture is shown in Fig. 6.
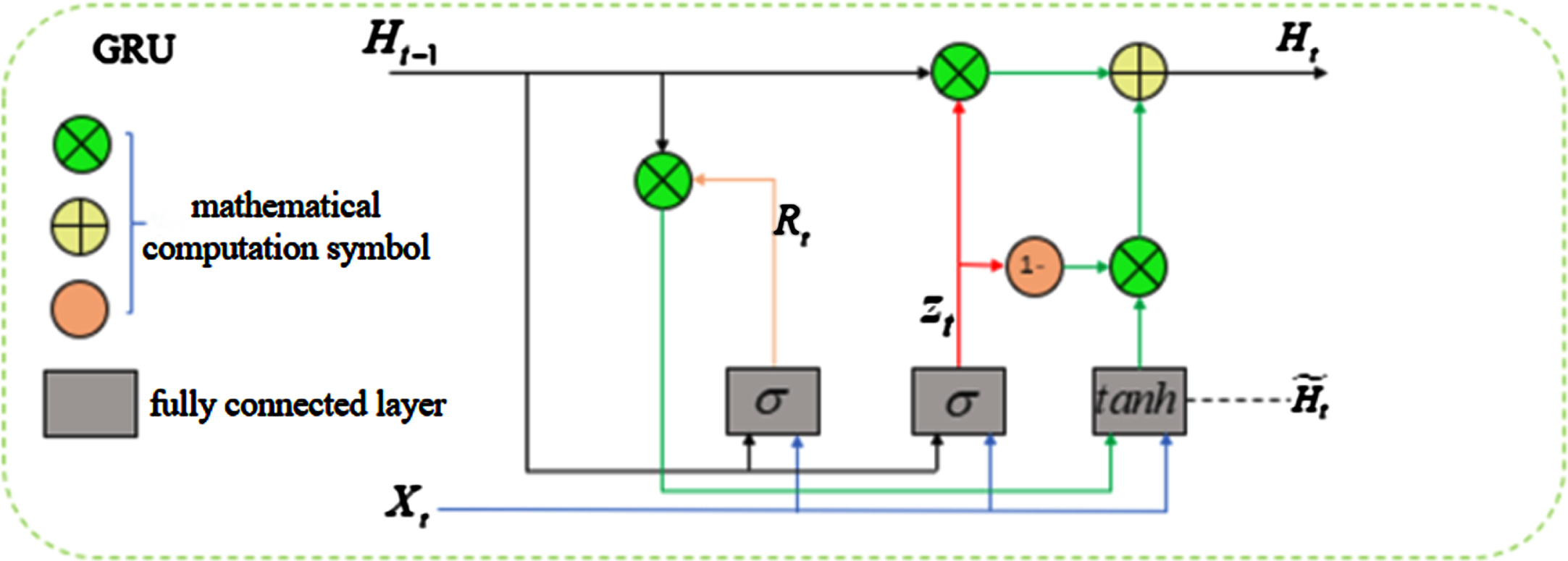
Schematic of GRU network architecture.
The GRU network mainly comprises the current time step input X t , the previous time step hidden state H t-1, the candidate hidden state H, the reset gate R t and the update gate Z t . Firstly, the hidden state in the recurrent neural network is modified through the control of the reset and update gates in GRU. Then the candidate’s hidden state is employed to further refine the internal state and eliminate irrelevant temporal information. Finally, the output is generated by combining the current hidden state and the last time step information. The corresponding formula is given below:
Where W xr , W hr , W xz , and W hz are weight parameters, b is deviation and σ is the sigmoid function to map the element value to [0,1], so that each element value in the reset gate and the update gate is between [0,1]. The output range of the tanh function is [–1,1].
In general, the GRU network is unidirectional and its output relies only on past context information. However, the modules before and after the image feature sequence prediction in the text are highly related. The current output not only depends on the previous hidden state but also on the subsequent hidden state. As a result, the unidirectional recurrent neural network fails to capture effective semantic relationships between the two directions, leading to low text recognition accuracy. To address this issue, we propose the Bi-directional GRU (Bi-GRU) network, as depicted in Fig. 7. Bi-GRU combines two opposite LSTM network connections to form a hidden layer that transmits information bi-directionally, thereby enhancing the model’s ability to extract semantic information and improving recognition accuracy. At time t, the hid state (H t ) of the Bi-GRU unit is computed as follows:
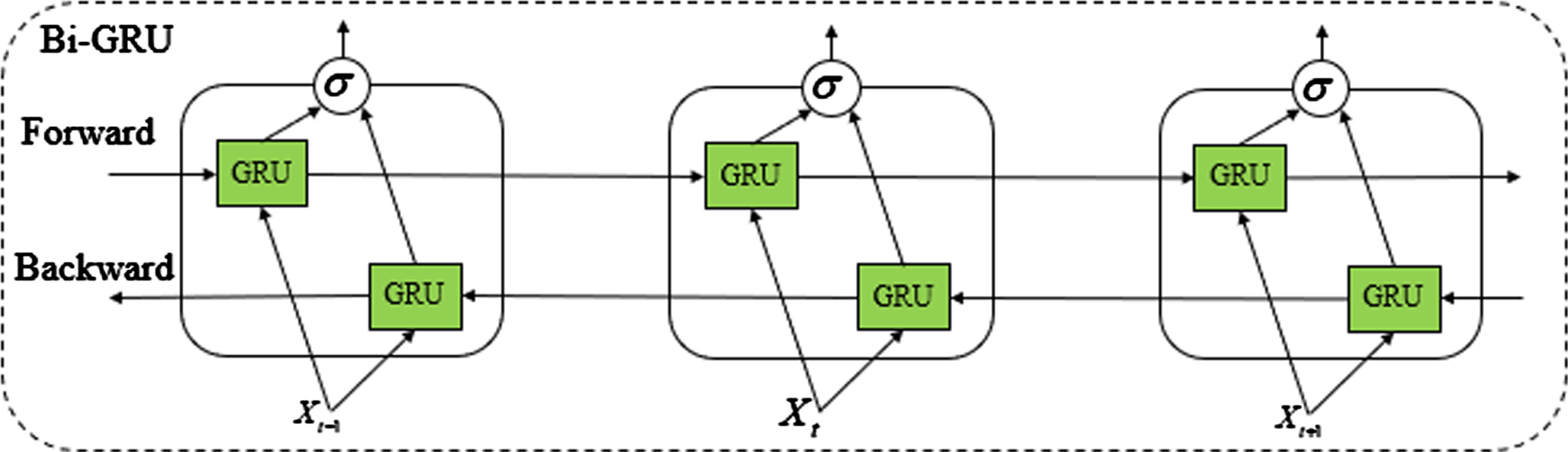
Schematic of Bi-GRU network architecture.
Where
As a crucial module in text recognition, the transcription layer is responsible for converting the predicted feature vectors of each Bi-GRU output into a label sequence. Thus, it is also commonly referred to as the sequence recognition layer. However, traditional time series classification and recognition methods pose a challenge for the sequence recognition layer, as the input sequence X = [x
1, x
2, ·· · , x
t
] and corresponding output label sequence Y = [y
1, y
2, ·· · , y
u
] are of varying lengths and not aligned properly, leading to redundancy issues. For instance, the input image text label in Fig. 2. is ‘ Y23’, and after passing through the Bi-GRU network, it may generate output sequences such as’
Y23’, and after passing through the Bi-GRU network, it may generate output sequences such as’  YY23’, ‘
YY23’, ‘ Y233’, or ‘
Y233’, or ‘ Y223’, resulting in an inability to output the final sequence recognition result due to repeated sequence labels. In order to effectively tackle the redundancy issue in sequence recognition, this paper proposes the adoption of Connectionist Temporal Classification (CTC) in the convolutional recurrent neural network model. CTC introduces a blank character to enable the Bi-GRU network to identify interruptions. Meanwhile, a multi-to-one mapping technique is employed to combine identical continuous characters and remove the blank character ‘_’ such as _
Y223’, resulting in an inability to output the final sequence recognition result due to repeated sequence labels. In order to effectively tackle the redundancy issue in sequence recognition, this paper proposes the adoption of Connectionist Temporal Classification (CTC) in the convolutional recurrent neural network model. CTC introduces a blank character to enable the Bi-GRU network to identify interruptions. Meanwhile, a multi-to-one mapping technique is employed to combine identical continuous characters and remove the blank character ‘_’ such as _  _YY_2_3 ->
_YY_2_3 ->  Y23,
Y23,  _
_ Y_2_33 ->
Y_2_33 ->  Y23, and
Y23, and  _Y_22_3 ->
_Y_22_3 ->  Y23. In other words, multiple paths are available to generate the final label sequence. Figure 8. illustrates three legitimate paths at a time step of 10.
Y23. In other words, multiple paths are available to generate the final label sequence. Figure 8. illustrates three legitimate paths at a time step of 10.
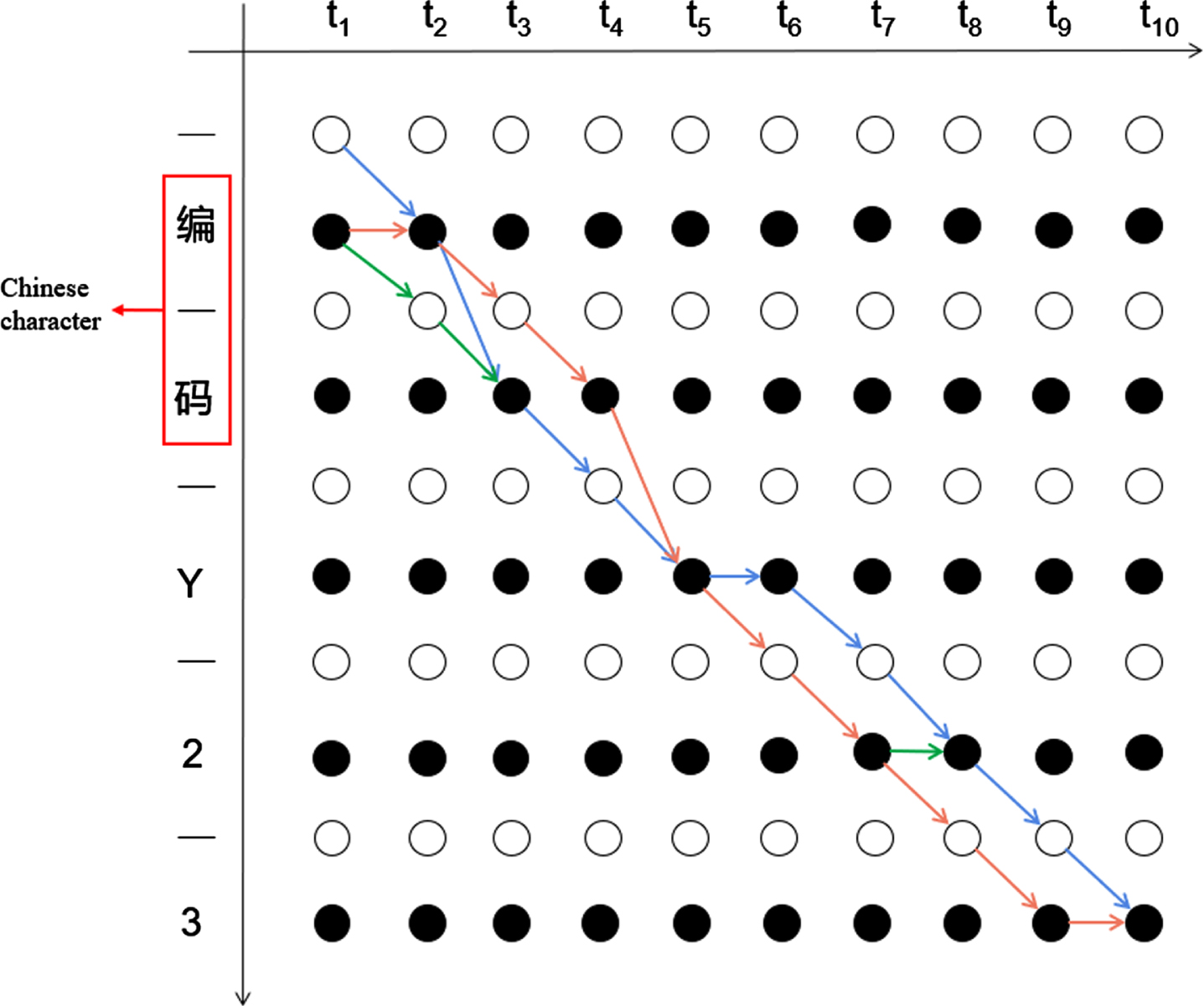
CTC legal paths.
During the model training, the conditional probability of generating each path can be stated as:
Where x denotes the input sequence, l denotes the legal path, and
Where y denotes the output text label, and B denotes the deduplication operation. If we rewrite the above equation into a negative log-likelihood function, we obtain what is known as the CTC loss:
Laboratory equipment
Image acquisition is a crucial prerequisite for visual positioning and module recognition. The proper functioning of the image acquisition system for tobacco boxes labeling is essential for the overall workflow of the system. The labeling positions on both sides of the tobacco boxes are not fixed and vary among different outsourcing companies. Therefore, this article proposes a dual-zone binocular structure design to address the issue of inconsistent labeling positions. By selecting appropriate cameras, the system enables image acquisition for labeling at any position. The specific structure is illustrated in Fig. 9.
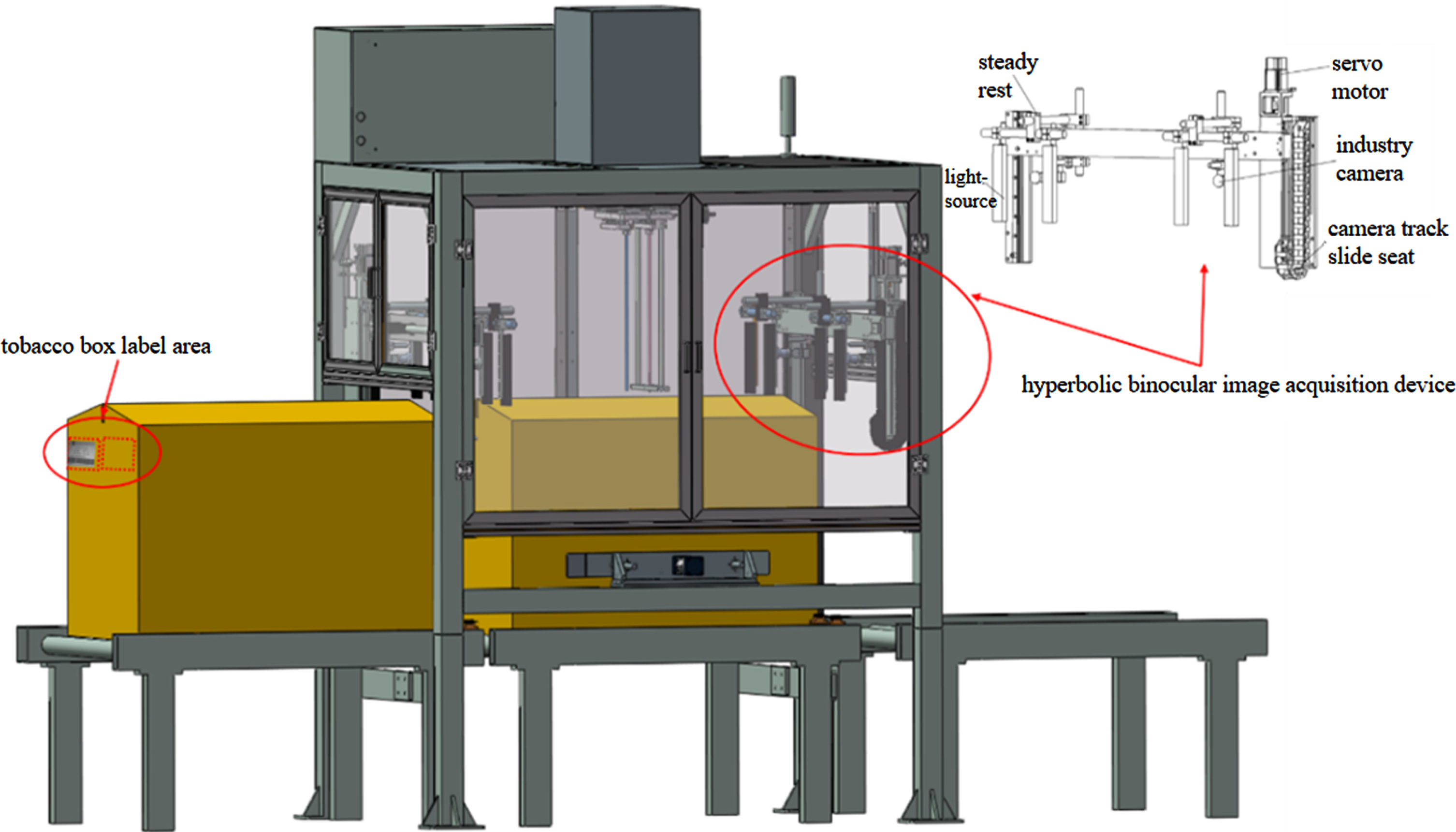
Tobacco box label recognition system complete machine structure diagram.
During the process of camera selection, the best camera type should be determined according to the precision requirements of the detection target, field of view, target state (static or dynamic), and other conditions in order to obtain the best cost-performance ratio. In this paper, the tobacco boxes identification characters to be detected are in 16 pounds KaiTi, which has a more prominent feature size compared to the 0.16mm × 0.16mm feature size of handwritten fonts. Therefore, the camera needs to be set to capture the feature size of 0.16mm. During the process of camera sampling and imaging, the photodetector converts analog signals to digital signals, which complies with the Nyquist sampling theorem [22]. According to the resolution formula, the required sampling accuracy can be calculated as 0.08mm.
Where Z i represents the length and width of the tobacco boxes label, and Urepresents the required sampling accuracy.
Considering that the actual size of tobacco box identification may vary, resulting in different required sampling resolutions, this paper provides an example of the identification of Shandong Tobacco, which has a larger field of view. Figure 10. shows the identification of Shandong Tobacco.

Shandong tobacco boxes label diagram.
The tobacco boxes identification has a size of 180mm × 120mm. Due to the manual pasting process, the position of the identification may fluctuate within a certain range. To account for this variation during the image acquisition process, a redundant field of view of 300mm × 200mm is set. According to formula (13), the longitudinal and lateral resolutions of the camera are approximately 37,500mm × 2,500mm, with a pixel count of around 9.4 million.
Based on the selection analysis above, we have chosen a MER2-1220-9GM GMOS industrial camera from Daheng as the image acquisition device for tobacco boxes identification. The camera parameters are shown in Table 2.
MER2-1220-9GM camera parameter table
When selecting a lens, parameters that determine optical performance such as focal length, the field of view, and aperture ratio should be considered. Additionally, to be compatible with the MER2-1220-9GM GMOS industrial camera, the lens should have a C mount, a pixel resolution of at least 12 million, and a sensor size larger than 1/1 .7′′ inch to ensure the accuracy and clarity of the image acquisition.
Based on the method of pasting identification labels on tobacco boxes and the design of the “hyperbolic binocular” visual image acquisition structure, the camera is positioned at a distance of 200mm from the tobacco boxes label. Therefore, the required focal length of the lens can be calculated using formula (14) based on the size of the field of view, the working distance, and the size of the camera’s photosensitive sensor.
Where H FOV represents the size of the field of view, WD represents working distance, and H CCD represents the size of the camera photosensitive sensor. The conversion table of industrial camera target surface size is shown in Table 3.
Camera target surface size unit conversion table
Based on the analysis of lens compatibility and the calculation of field of view and focal length for the industrial camera selection, we have chosen the Hikvision MVL-KF0618M-12MPE industrial lens, whose main parameters are shown in Table 4.
MVL-KF0618M-12MPE industrial lens basic parameters
To expedite the training and verification process, the experiments were conducted on a 64-bit Windows system. The hardware and environment configurations are shown in Table 5. The model was trained using Ada as the optimizer, with a learning rate of 0.001, and with 16 images per iteration. The model was trained over a period of 300 iterations (epochs).
Deep learning environment configuration table
Deep learning environment configuration table
To test and compare the effectiveness of the proposed text recognition model based on a convolutional recurrent neural network for tobacco marking, three public datasets are used in this paper: SVT [23], IIIT-5K [24], and ICDAR2013 [25], as well as an actual threshing and redrying dataset for tobacco marking. SVT contains 350 images, 100 of which are used for training and 250 for testing. Some of the images in this dataset are heavily corrupted by blur, noise, and low resolution. IIIT-5k is obtained from Google Image Search and contains 5000 cropped word images from scene text images and digital images, of which 2000 images are used for training and the remaining 3000 images are used for testing. ICDAR2013 is cropped from 288 real scene images. Following previous work, the version with 857 images is chosen for testing, which deletes non-alphanumeric characters and text instances shorter than 3 characters. The re-roasting tobacco identification dataset is a screenshot of the pictures collected by the image acquisition system through the image acquisition system of the tobacco leaf re-roasting unit - Fujian Wuyi Tobacco Co., Ltd., a tobacco leaf re-roasting unit in Shaowu City, Fujian Province, through text detection, including a total of 15,000 pictures, 13,000 training set pictures, and 2,000 test data sets, as shown in Fig. 11. for some dataset examples.

Re-roasting tobacco identification dataset.
In order to verify the effectiveness of the text recognition model based on convolutional recurrent neural network proposed in this chapter, this section compares and analyzes the text detection algorithms that have emerged in recent years on SVT, IIIT-5K, and ICDAR2013 datasets. The state-of-the-art (SOTA) algorithms considered include CRNN [7], AON [26], RARE [27], R2AM [28], Rosetta [29], and MORAN [30]. Model performance is evaluated based on the Accuracy index, defined by the following formula:
Among them, Mdenotes the number of text images correctly identified by the data set, and N denotes the total number of all text images in the data set.
Table 6 presents a performance comparison of various algorithm models on the SVT, IIIT-5K, and ICDAR2013 datasets, while Fig. 12. shows the visualization attempts. Notably, the R2AM, MORAN, and the improved model using CRNN demonstrated the highest accuracy rates on the SVT, IIIT-5K, and ICDAR2013 datasets, with 96.3%, 91.2%, and 93.2% respectively. These findings effectively highlight the competitiveness of the improved CRNN-based model. Moreover, to test the practical application of the improved model, it was compared to the SOTA method on the tobacco identification dataset. The test data performance results are shown in Table 7 and the corresponding visual comparison diagram is displayed in Fig. 13. The AON model demonstrated the lowest accuracy on this dataset, while the MORAN model achieved the highest test accuracy of 92.3% through the use of text correction and pixel-level weakly supervised learning. While models incorporating an attention mechanism or serial decoding based on the attention method limit prediction speed, their prediction times can be longer, such as the RARE and R2AM models, with prediction times extending up to 20ms.

The performance comparison of different algorithm models on SVT, IIIT-5K, and ICDAR2013 datasets.

Performance comparison diagram of different algorithm models on tobacco boxes label data set.
Performance results of different algorithm models on SVT, IIIT-5K, and ICDAR2013 datasets
Performance results of different algorithm models on tobacco boxes label data set
The model’s performance is also compared with detection accuracy as illustrated in Fig. 14. along with detection time. Although MORAN has achieved slightly higher accuracy than the improved model by 0.5%, it has a detection time that is 5.4ms longer. Furthermore, during the initial stages of model training, the improved model demonstrated better performance in terms of convergence and stability when compared to other models.
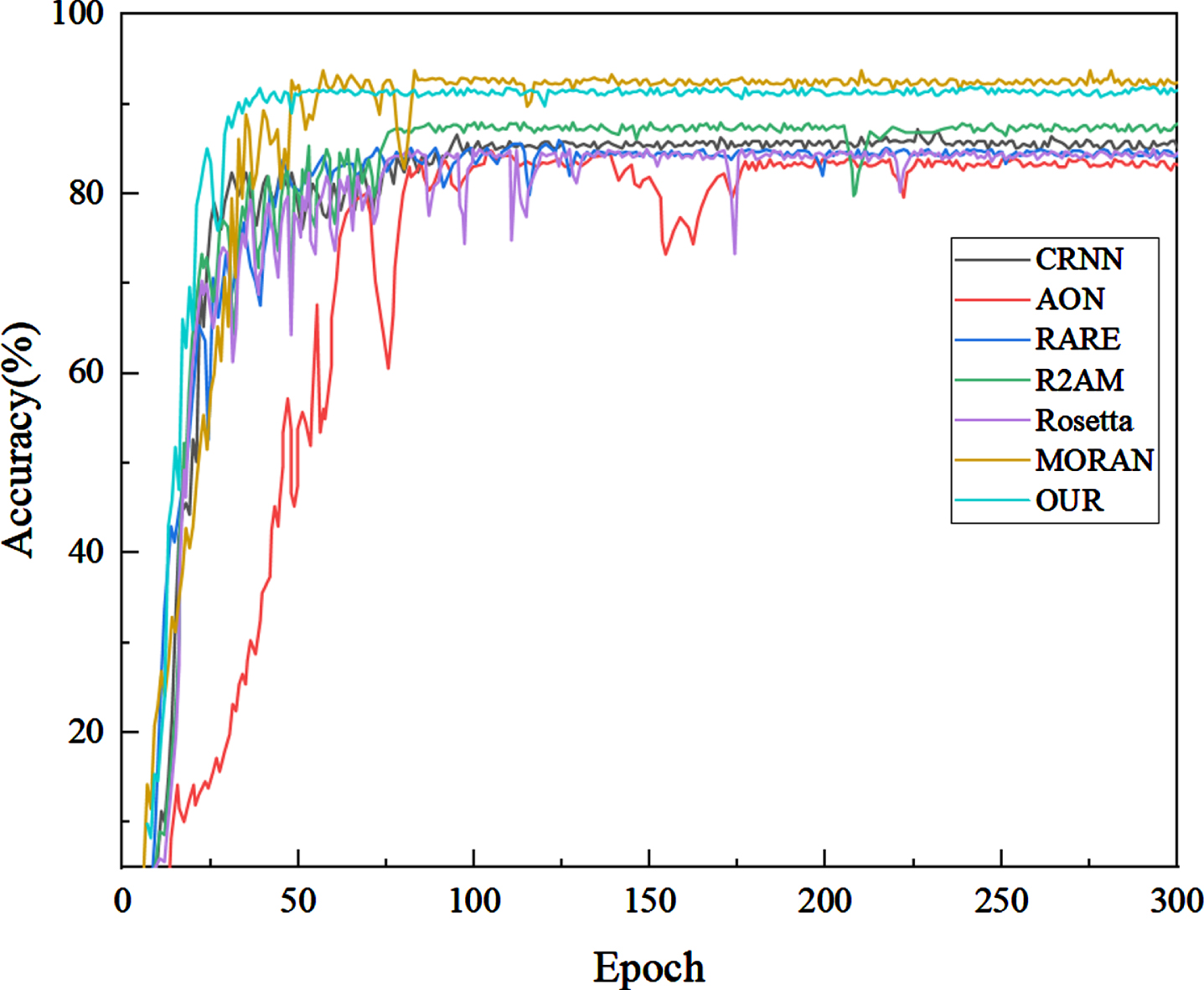
Detection accuracy diagram.
The effectiveness of SE-DenseNet feature extraction network
To investigate the impact of the SE-DenseNet feature extraction network on tobacco box marking characters, this study has developed three experimental comparison strategies. The first approach involved using the original CRNN feature extraction network - VGG. The second approach employed the Dense-Net, which is a dense residual network. Lastly, the third approach adopted the SE-DenseNet network, which incorporates a feature-weighted attention mechanism on top of the DenseNet network. This study then applied these three strategies to test and compare their effectiveness on the tobacco boxes label dataset using analytical evaluation.
Table 8 presents the performance of different feature extraction networks under various schemes. By comparing the results of experiment schemes 1 and 2, it can be observed that the recognition accuracy of the DenseNet network is 2.6% higher than that of the VGG network. This effectively demonstrates that simply stacking neural networks for feature extraction can only enhance performance to a certain degree. DenseNet network, which employs a deep residual architecture, can use the intensive connection to extract meaningful features and improve the recognition accuracy of the model. Furthermore, by comparing the performance of experimental schemes 2 and 3, it is evident that the SE-DenseNet network, which leverages a feature-weighted attention network mechanism, exhibits even better performance and provides a 3% increase in accuracy. This observation further emphasizes the role of a robust feature extraction weighting mechanism in promoting model performance.
The influence of feature extraction network performance
The influence of feature extraction network performance
Figure 15 displays the losses in three different scenarios. It can be seen that the model’s loss function converges more easily when a feature-weighted attention network is introduced instead of replacing the feature extraction network. This observation further confirms the enhanced performance of the model.
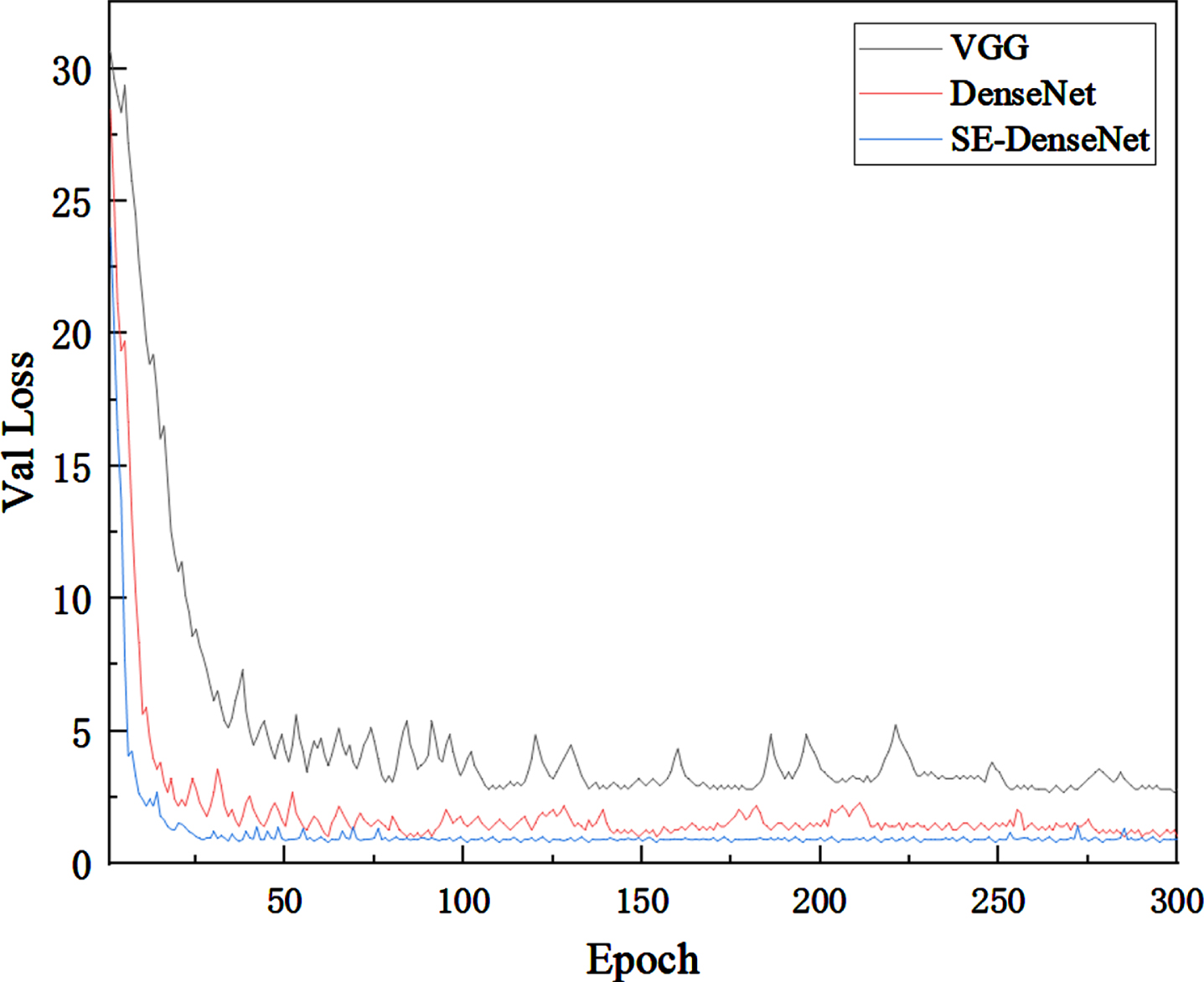
Loss diagram.
This paper utilizes the Bi-GRU network to replace the original Bi-LSTM network in the convolutional recurrent neural network. To investigate its effect on tobacco boxes, we designed two control experiments: 1) utilizing the original Bi-LSTM recurrent network; 2) replacing the recurrent network with Bi-GRU. Both experiments were evaluated analytically on the tobacco boxes label dataset and compared.
According to Table 9, the experimental results of Bi-LSTM and Bi-GRU networks indicate that after replacing Bi-LSTM with Bi-GRU, the recognition accuracy of the network increased by 0.6%. This suggests that Bi-GRU has a simpler architecture than Bi-LSTM and is more effective in complex text character recognition performance.
The impact of loop layer network performance
The impact of loop layer network performance
Targeting the problem of speed and accuracy in recognizing complex text on online product labels, this study used tobacco strip marking as a case study and addressed the difficulty of recognizing tobacco boxes labels by improving the convolutional recurrent neural network approach. Initially, SE-DenseNet was utilized as the feature extraction network, followed by Bi-GRU, which learned feature vectors in sequences and outputted predicted label distributions. Finally, the CTC loss function was employed to convert the series of label distributions obtained from the recurrent layer into the final label sequence, constructing the model for identifying the text of tobacco strip marks in the production of sliced and toasted tobacco leaves.
The real-time and efficient performance of the improved model in this paper is verified by comparing and analyzing the text recognition algorithms in recent years on three public datasets and self-built datasets. The improved model has excellent performance on the self-built dataset, and the recognition accuracy reaches 91.8% under the condition of ensuring fast prediction speed. At the same time, the ablation experiments were carried out on the self-built dataset under the same experiment, and the recognition accuracy of the improved model for the feature extraction network and the recurrent layer network was increased by 5.6% and 0.6%, respectively, which verified the effectiveness of the improved module in this paper. These findings provide valuable support for the recognition of complex text in tobacco strip marking.
Footnotes
Acknowledgments
This project has been supported by: the Natural Science Foundation of Fujian Province (grant no. 2023J01342), the Program for Innovative Research Team in Science and Technology in Fujian Province University (2020No. grant: no.12). Fujian Provincial Key Project of Science and Technology Innovation (2022G02007) and High-level talents foundation of Fuzhou Polytechnic. National Natural Science Foundation (52275413).