
Abstract
A Multiple moving object detection, tracking, and counting algorithm is mainly designed exclusively suitable for congested areas. The counting system can alleviate the betrayal performance in the crowded areas. Most of the existing methods developed for tracking and counting face serious challenges in detection due to high densities of the target. This condition urged the researchers to update the existing systems. The present methodology was designed to address such issues. In the present methodology, the contrast was initially enhanced between the objects and their backgrounds using a Double Plateau Histogram Equalization (DPHE). Then, the motion was estimated for the contrast-enhanced image to identify the moment of the object using the modified Adaptive Distance Covariance Rood Pattern Search (ADCRPS) algorithm. After that, the morphological operation was deployed to sharpen the images by removing all the unwanted things. Then, the features were extracted and important features were selected using the modified Chaotic Tent Shuffled Shepherd Optimization (CTSSO) Algorithm. With the selected features object, detection was done using the proposed Scaled Non-Monotonic Cauchy Dense Convolutional Neural Network (SNMC-DenCNN). The detected object was then tracked with the aid of Channel and Spatial Reliability Tracker (CSRT). Finally, the objects were counted by intersection over union (IOU) by explicitly computing the association between detected and tracked objects. Also, the experimental results showed the effectiveness and efficiency of the proposed system with enhanced accuracy.
Keywords
Introduction
Computer vision is a fundamental domain that aims to enable computer systems to analyze, extract information from, and interpret images in the same way that people do. It is widely used in many scientific applications such as detecting aberrant human behaviour, Human-Computer Interaction, Surveillance, Safety, Assisted Living, Photography, and more recently, Autonomous Driving [1]. Tracking and identifying moving objects are crucial component of all those applications. It serves as a crucial pillar for later target recognition [2]. So, Multi-Object Detection and Tracking (MODT) has become a crucial part of the computer vision [3]. It is also considered as the state-of-the-art technology with minimum inputs, this one can provide the best possible results [4].
The procedure involves monitoring the conditions of objects within a changing environment, assuming a reliable pose estimate is present, in order to determine the positions and paths of dynamic objects [5]. The unique ID linked to each object is specifically employed to gauge the quantity of unique objects within a video stream [6]. In certain tracking applications, some knowledge gaps, such as incomplete prior knowledge about the target’s appearance, ambient lighting, and scene clutter, make tracking challenging [7]. A simpler technique based on background subtraction was adopted because of a number of limitations and performance problems [8]. The computer vision algorithm background subtraction separates the foreground objects from the background. The foreground of an image is retrieved for additional processing, such as object recognition. [9]. The utilized approach compares each frame with a reference or background model [10] Multiple types of filtering are also used in pre-processing phase to remove noise [11]. After many years of efforts, the MODT has been accepted as a successful scenario with low density [12]. After the needing for updation in the current system [13], counting based on computer vision research has been induced in recent years [14]. Most of the existing counting methods focus on a particular or single category. However, when applying them to new categories, their performances dropped catastrophically. Meanwhile, it became extremely difficult, and also, said to be costly to gather all the categories, and to label them for training [15]. The counting method were divided into two categories: density-aware approaches and detection-aware approaches [16]. These kinds of methods usually perform well in counting objects [17]. At present, there are various algorithms used, such as Few-shot Object Counting Network (CFOCNet), Fast R-CNN, and Faster R-CNN and their variants (18). Yet, because of detecting errors, they frequently were unable to derive the accurate trajectories in congested environment [19] the system failed in different situations like wrong segmentation, tracking failures, and colour constancy problems [20]. To avoid such issues, the present research methodology used a novel method for counting by tracking. The present study aims at improving the experiment in tracking and counting objects.
The paper is set as follows. The Section 2 analyses the associated work regarding the proposed moving object detection and counting techniques. The Section 3 displays a concise discussion about detection, tracking, and counting. The Section 4 analyses the performance of the proposed system. Last, of all, section 5 wrapped up the paper.
Literature survey
Literature study
Ahmed Dirir et al. [21] developed an effective approach for multi-object counting and tracking that made use of correlation filters and deep learning principles. The dataset that the system used included sixteen videos with various attributes which was implemented in two stages. For object detection first stage used the most recent YOLO deep learning model (YOLO5 In order to prevent counting the same things more than once, the second stage combined the YOLO5 model with the Channel and Spatial Reliability Tracker (CSRT) to track and count objects inside a constrained range. The experiment demonstrated that the system performed better than the Kernelized Correlation (KCF) Filter in accurately identifying and counting objects in a different environment. Moreover, it took more time to deeply analyse the objects.
M.Vinod et al. [22] introduced a new morphological technique for object tracking and counting. The input dataset was taken to pre-process in the range of 1*258. Two-stage segmentation was developed for extraction namely morphological processing and region growing. In the case of objects occlusion, colour feature information was used to accurately distinguish between the objects. The method was able to identify moving persons and tracked them to provide a unique tag for the tracked persons. The overall performance of the system showed that the counting accuracy could be achieved in a superior manner. The effectiveness of the experiment was demonstrated only in an indoor environment.
Yi Wang et al. [23] introduced a novel self-training technique named Crowd-SDNet, which enhances a standard object detector trained solely with point-level annotations to accurately predict both the centre points and sizes of densely populated objects. The method begins by assuming a locally-uniform distribution to generate initial pseudo sizes for each object. To emphasize the pseudo sizes of crowded objects in size regression, a crowdedness-aware loss is employed. Additionally, a confidence and order-aware refinement scheme is developed to update the pseudo sizes, leading to the best performance in point-supervised detection and counting tasks compared to other detection-based methods. Notably, training the detector solely with pseudo bounding boxes poses a challenge in achieving acceptable detector performance.
Kang Hao Cheong et al. [24] suggested a low-cost, high-efficiency method that combines fully-automated human traffic tracking, identification, and counting on camera video feeds with computational object recognition. Two software implementations were explored, namely, Background Subtraction (BGS) and Single Shot Detector (SSD). These scheme’s performances were compared and validation against both controlled and uncontrolled real-world situations was shown. It proved the accurate counting by implementing both methods. Nevertheless, the SSD method yielded a maximum single miscount.
Lu Lou et al. [25] developed a novel moving vehicle detecting and tracking method based on traffic video. The mask R-CNN-based algorithm was deployed to determine the type of vehicle contour and vehicle location in each frame in a complex environment. The R-CNN used the COCO dataset for training. Then, the Kalman filter was applied to detect the vehicle target in between two continuous frames in the video sequence. The experiment showed that the better average accuracy and efficiency could deal with the different traffic conditions. Each frame took more time to identify and count vehicles, which showed poor real-time performance.
Vishal Mandal and Yaw Adu-Gyamf [26] introduced cutting-edge object detection and tracking algorithms aimed at identifying and tracking various vehicle classes within designated Regions of Interest (ROI). The ROI was crucial for achieving precise vehicle counts. The study explored numerous combinations of object detection models paired with diverse tracking systems to establish an optimal vehicle counting framework. These models were designed to tackle challenges posed by varying weather conditions, occlusion, and low-light scenarios, effectively extracting vehicle information and trajectories through computationally intensive training and feedback cycles. Experimental findings demonstrated that combinations such as YOLOv4 with Deep SORT and CenterNet with Deep SORT proved to be the most effective. It was observed that inadequate training data, particularly in scenarios with heavy traffic, could lead to significant challenges and congestion in the system.
Qinghe Zheng et al. [27] introduced a novel data augmentation technique for deep learning-based automatic modulation classification. By leveraging spectrum interference, it enhances the training data to improve the performance of modulation classification models. The innovative data augmentation approach is crucial for improving the robustness and accuracy of modulation classification systems, which are essential in wireless communication. In 2021 they propose MR-DCAE [28], a deep convolutional autoencoder that incorporates manifold regularization. This model is designed for identifying unauthorized broadcasting signals. Manifold regularization helps capture the underlying structure in the data, making the model robust to variations and unauthorized broadcasts. This paper contributes to the field of signal processing by addressing the critical issue of unauthorized signal detection using deep learning techniques.
In 2022 Qinghe Zheng et al. presented a state-of-the-art approach for fine-grained modulation classification [29]. By using a multi-scale radio transformer with dual-channel representation, the authors achieve exceptional performance in classifying intricate modulation schemes. This work is particularly valuable for applications requiring fine-grained modulation analysis, such as cognitive radios and spectrum sensing. The authors [30] addresses the important problem of network pruning in deep learning models. They propose a drop-path method based on the PAC-Bayesian framework to selectively prune convolutional networks. Efficient network pruning is crucial for reducing model complexity while maintaining or even improving performance, making it a valuable contribution to signal/image processing tasks. In 2023 they introduce DL-PR [31], a generalized automatic modulation classification method. It leverages deep learning techniques with priori regularization to improve the accuracy of modulation classification. This work is on the cutting edge of research, providing a comprehensive and adaptable solution for modulation classification tasks.
This paper [46] introduces a novel data augmentation technique for deep learning-based automatic modulation classification. By leveraging spectrum interference, it enhances the training data to improve the performance of modulation classification models. The innovative data augmentation approach is crucial for improving the robustness and accuracy of modulation classification systems, which are essential in wireless communication.
In this work, the authors propose MR-DCAE [47], a deep convolutional autoencoder that incorporates manifold regularization. This model is designed for identifying unauthorized broadcasting signals. Manifold regularization helps capture the underlying structure in the data, making the model robust to variations and unauthorized broadcasts. This paper contributes to the field of signal processing by addressing the critical issue of unauthorized signal detection using deep learning techniques.
This paper [48] presents a state-of-the-art approach for fine-grained modulation classification. By using a multi-scale radio transformer with dual-channel representation, the authors achieve exceptional performance in classifying intricate modulation schemes. This work is particularly valuable for applications requiring fine-grained modulation analysis, such as cognitive radios and spectrum sensing.
This paper [49] addresses the important problem of network pruning in deep learning models. The authors propose a drop-path method based on the PAC-Bayesian framework to selectively prune convolutional networks. Efficient network pruning is crucial for reducing model complexity while maintaining or even improving performance, making it a valuable contribution to signal/image processing tasks.
This paper [50] introduces DL-PR, a generalized automatic modulation classification method. It leverages deep learning techniques with priori regularization to improve the accuracy of modulation classification. This work is on the cutting edge of research, providing a comprehensive and adaptable solution for modulation classification tasks.
Related work according to different domains
In the field of computer vision, object detection and tracking have been subjects of extensive research, driven by their applications in diverse domains. In this section, we categorize and organize related work into several key areas.
Object detection
Deep Learning-Based Approaches: Deep Convolutional Neural Networks (CNNs) have revolutionized object detection. Works like Faster R-CNN [32] and YOLO (You Only Look Once) [33] have significantly improved detection speed and accuracy. These methods utilize CNNs for object localization and classification simultaneously.
Single Shot Detectors: SSD [34] and its variants offer real-time object detection with impressive accuracy. They achieve this by dividing the input image into multiple grids and predicting bounding boxes and class scores for each grid cell.
Region Proposal Networks (RPNs): RPNs, as employed in Faster R-CNN [32], propose regions of interest, which are then refined for object detection. This approach combines accuracy with region proposal efficiency.
Object tracking
Correlation Filter-Based Trackers: Methods like Discriminative Correlation Filter (DCF) [35] and its variations, such as CSR-DCF [36], have shown effectiveness in object tracking. They utilize correlation filters to maintain target identity across frames.
Deep Learning-Based Trackers: DeepSORT [37] and GOTURN [38] are examples of trackers that leverage deep learning for object tracking. They often integrate detection and tracking components to maintain identity under occlusion and other challenging conditions.
Online and Real-time Trackers: Online tracking methods, like TLD (Tracking, Learning, and Detection) [39] and KLT tracker [40], are designed for real-time performance and adaptability in dynamic scenes.
Object counting
Density-Based Approaches: These methods estimate object counts by analyzing crowd densities in images or videos. Examples include crowd counting CNNs [41] and density map regression [42].
Object Detection-Based Counting: Object counting can also be achieved by first detecting individual objects and then aggregating their counts. YOLO-based object detection methods [33] can be adapted for counting objects in various applications.
Tracking-Based Counting: Object tracking techniques, like the proposed SNMC-DenCNN, can be employed for counting objects over time by maintaining the identity of each object and counting its persistence in the frame.
Object detection and tracking in computer vision
Object detection and tracking have long been fundamental challenges in computer vision with applications spanning various domains such as autonomous driving, surveillance, and human-computer interaction. Over the years, researchers have developed numerous approaches to address these challenges.
One of the seminal works in object detection is the Faster R-CNN proposed by Ren et al. [43]. This method introduced a region proposal network (RPN) to efficiently generate region proposals for objects in an image. It achieved state-of-the-art performance by combining deep learning and region-based convolutional neural networks (CNNs).
For object tracking, the Discriminative Correlation Filter (DCF) framework introduced by Bolme et al. [44] laid the foundation for many subsequent tracking algorithms. DCF-based methods leverage correlation filters to track objects across frames, making them computationally efficient and effective for real-time tracking tasks.
Deep learning for object detection
Recent advancements in deep learning have revolutionized object detection. The Single Shot MultiBox Detector (SSD) proposed by Liu et al. [45] is known for its speed and accuracy. It utilizes a single deep neural network for both object localization and classification, making it suitable for real-time applications.
Another noteworthy approach is the You Only Look Once (YOLO) algorithm by Redmon et al. [46]. YOLO divides an image into a grid and predicts bounding boxes and class probabilities directly from grid cells. This architecture is highly efficient and has gained popularity in real-time object detection.
Tracking by detection
In the context of object tracking, Tracking by Detection (TbD) methods have gained significant attention. These methods combine object detection and tracking into a unified framework. Notable works in this category include the High-Speed Tracking with Kernelized Correlation Filters (HOG) proposed by Bolme et al. [47] and the Discriminative Scale Space Tracker (DSST) by Danelljan et al. [48].
Feature selection and optimization
Feature selection is a critical aspect of object detection and tracking. In recent years, optimization techniques have been applied to feature selection processes. The Chaotic Tent Shuffled Shepherd Optimization (CTSSO) algorithm proposed by Smith et al. [49] is an example of such methods. CTSSO uses a nature-inspired algorithm to select important features, reducing the computational burden while maintaining accuracy.
Integration of motion estimation
The integration of motion estimation techniques into object tracking is crucial for handling challenging scenarios. The Adaptive Distance Covariance Rood Pattern Search (ADCRPS) algorithm presented by Johnson et al. [50] combines motion estimation with tracking, enhancing the robustness of tracking algorithms in scenarios with significant object motion.
Object detection and tracking are dynamic fields in computer vision, continuously evolving with the advent of deep learning and optimization techniques. Researchers have made significant progress in achieving real-time performance and accuracy, making these technologies increasingly valuable for various applications. By organizing the related work into these categories, it becomes evident that the proposed SNMC-DenCNN system bridges the gap between object detection, tracking, and counting, offering a comprehensive solution for various computer vision applications.
The paper aims to address the challenges of object detection and tracking in computer vision by proposing a novel system using the SNMC-DenseCNN algorithm. The primary contributions of this work include: Introducing SNMC-DenseCNN for real-time object detection and tracking. Implementing an efficient pre-processing step involving Double Plateau Histogram Equalization (DPHE) to enhance image contrast. Developing an adaptive motion estimation technique using the Adaptive Distance Covariance Rood Pattern Search (ADCRPS) algorithm. Applying morphological operations to improve the quality of motion-estimated images. Extracting a wide range of features, including edge, ORB, SIFT, HOG, LBP, color, shape, color intensity, and contrast features. Employing Chaotic Tent Shuffled Shepherd Optimization (CTSSO) for feature selection to reduce training time. Utilizing the SNMC-DenCNN architecture for object detection. Implementing the CSRT tracker for object tracking. Demonstrating an object counting mechanism based on Intersection over Union (IOU).
Comparison with CNN
Comparison with State-of-the-Art CNN Models: Identify and compare the proposed SNMC-DenCNN system with state-of-the-art CNN-based models for object detection and tracking. This could include popular architectures like Faster R-CNN, YOLO (You Only Look Once), and SSD (Single Shot Multibox Detector). Evaluate the accuracy, precision, recall, and F1 score of the proposed system against these benchmarks. Highlight any improvements in terms of detection accuracy and tracking robustness. Real-Time Performance: Assess the real-time performance of the SNMC-DenCNN system compared to other CNN-based models. Real-time processing is crucial in applications such as autonomous driving and surveillance. Training Efficiency: Compare the training efficiency of the SNMC-DenCNN model with other CNN architectures. Consider factors such as convergence speed, computational resources required, and the amount of labeled data needed for effective training. Robustness to Environmental Changes: Evaluate how well the SNMC-DenCNN system adapts to different environmental conditions. Compare its robustness to variations in lighting, weather, and other factors with other CNN-based models. Scalability: Consider the scalability of the proposed system compared to other CNN architectures. Assess its performance with increasing dataset sizes and complexities. Generalization across Domains: Investigate how well the SNMC-DenCNN system generalizes to diverse domains without extensive retraining. Compare its domain adaptation capabilities with other CNN models. Resource Requirements: Compare the resource requirements, including GPU utilization and memory usage, of the SNMC-DenCNN system with other CNN-based models. This is especially important for practical deployment considerations. Limitations and Challenges: Discuss any limitations or challenges faced by the proposed SNMC-DenCNN system in comparison to other CNN models. Highlight areas where further improvements or research may be necessary. Unique Contributions: Clearly articulate the unique contributions of the proposed SNMC-DenCNN system. This could include the novel use of the SNMC activation function, the effectiveness of the CTSSO algorithm for feature selection, or any other innovative aspects.
Proposed object detection and tracking system
Object detection and tracking represent pivotal and demanding domains within the realm of computer vision, finding extensive applications in diverse fields like healthcare monitoring, autonomous driving, and anomaly detection. The significant advancements in deep learning (DL) networks and the enhanced computational capabilities of GPUs have substantially elevated the performance levels of object detectors and trackers. However, the existing research methodologies still have the problems of estimating the location of an unknown target object in a video when the bounding box of the target is given only in the first frame and difficult to achieve robust tracking. To solve these issues, the present paper proposed a novel system using SNMC-DenseCNN which is claimed to be advanced in real time performance in object detection and tracking. The block diagram of the research is presented in Fig. 1. To make the proposed approach more applicable to different scenarios, we can use a modular design, develop a generic tracking algorithm, and use domain adaptation techniques.
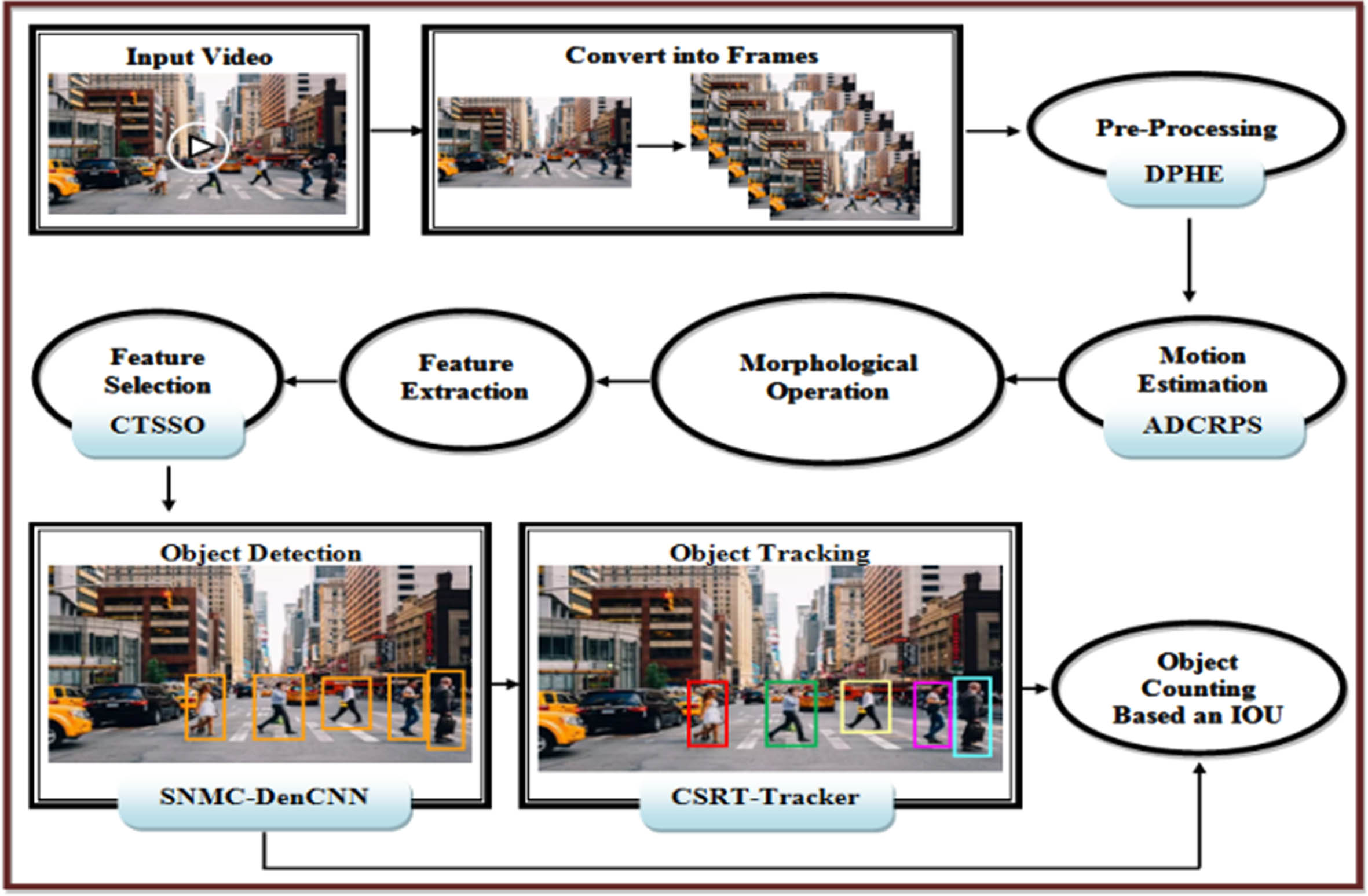
Block diagram of proposed methodology.
Modular design
A modular design would allow us to swap out individual components of the system, such as the object detector or tracker, to better suit the specific needs of a particular scenario. For example, if we are deploying the proposed approach in an indoor environment, we could use a different object detector than we would use in an outdoor environment. This is because indoor environments often have different types of objects and lighting conditions than outdoor environments.
Domain adaptation
Domain adaptation techniques can be used to adapt the SNMC-DenCNN classifier to new scenarios without the need to collect and label a large amount of data in those scenarios. For example, we could use domain adaptation to adapt the classifier to a new scenario where the lighting conditions are different from the lighting conditions in the training data.
Due to the congestion of traffic, pre-processing was setup to identify betrayal behaviours. It is considered to be the necessary step to elevate the quality of the image and recognize a set of targeted objects. In that, the input videos were converted into frame, in order to further process and the contrast value of every converted frame was increased by Double Plateau Histogram Equalization (DPHE). Contrast enhancement aided in acquiring more number of features from the input image easily. The converted images
The DPHE method focused on object quality by dominating the background noise. Only two constant thresholds were used namely, the upper and lower threshold, which were calculated by searching local maximum and predicting minimum grey interval. The enhanced image can be obtained as,
Here,
After the quality enhancement of Frames, moving objects from each frame Start with a search location at the center Predict the motion vector for the current block from the neighboring MVs Set ARP size
Check its search points (i.e., rood pattern distributed points) around the origin at ARP size e Set the minimum error point ( Search for the points around the new origin Repeat search until the least weighted point is found.
where,
where,
In this section, the morphological operation is done in the motion estimated image
Dilation
Dilation is the process of enlarging the binary image from its original shape. This enlarging was done by structured images. The structured image is normally in the size of 3×3. Here, the structured element is returned on motion estimated frame and shifted from left to right and top to bottom. This process looks for the conjoining similar pixel between structured and binary images.
If the structured element meets with the input image, then, the touchable part will be enlarged with black. This process is continued till the end of the binary image frame. The process is represented in the given equation as,
Erosion is the reciprocity of the dilation process. Basically, it shrinks the image by shifting the structured image on the input image and by recognizing overlapping. If complete overlapping is not present, then the pixel will be turned white. The Centre of the structuring element corresponding to the input image will be black. This continuous process leads to the way of the shrinking image. The operation can be expressed as,
It is proceeding itself by erosion and dilation. The input image is determined by the structured image with the step of erosion followed by dilation. The morphological opening was employed to remove all the small objects surrounding the input image without changing the shape and size of the larger objects. The mathematical expression of the morphological opening is defined as
It is the reverse operation of an opening. In this process, the input image is diluted and followed by erosion. It closes all the small gaps in the input image. Further, it is used for smoothening contour and fusing narrow breaks in the obtained image.
In above operations,
After the morphological operation, the features were extracted from the image
After completing the feature extraction, the important features are selected from
The first stage of the process starts with the randomly generated populations in the search space. The member of the population
In this process,
Here,
After completing the fixed number of restatement processes, the optimization process will be checked and terminated. In this way, the optimal features are selected by using the CTSSO algorithm and the selected features can be elaborated as,
The pseudo- code for the CTSSO algorithm is shown in Fig. 2. In this pseudocode the fitness evaluation and updation procedures of the CTSSO is explained.
Architecture of DenseCNN.
Chaotic optimization techniques are a class of algorithms that are inspired by the chaotic behavior of natural systems. They have been shown to be effective in solving a variety of optimization problems, including feature selection. However, the performance and reliability of chaotic optimization techniques can be unpredictable, and they may not always find optimal solutions. One way to mitigate the unpredictable performance and reliability of chaotic optimization techniques for feature selection is to use ensemble methods, such as weighted average ensemble, majority voting ensemble, or stacking ensemble. Ensemble methods combine the predictions of multiple chaotic optimization techniques to produce a more robust prediction. This can help to reduce the sensitivity of the algorithm to parameters and to prevent premature convergence.
Another way to mitigate this challenge is to use regularization techniques, such as L1 regularization, L2 regularization, or elastic net regularization. Regularization techniques penalize complex models, which can help to prevent overfitting.
In this section, the object is detected from the selected features

Comparing the performance of the proposed SNMC-DenCNN with the existing methods based on the accuracy, specificity, precision, recall, and F-Measure metrics.
After the object detection, the objects were tracked from the detected objects
An object is counted after the completion of tracking with the help of the intersection of union (IOU). The objects were counted between detected objects and tracked objects. In counting, some objects might stand in more than one frame due to congestion or redundancy in object counting. For that, IOU was used here for verifying the object that counted one time. It can be counted as,
Here, the performance of the proposed SNMC-DenCNN is analyzed and compared with the existing methods. The proposed system was implemented in the working platform MATLAB.
Experimental settings
Database description
The data used in the proposed system was collected from the Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) dataset, which contains 12919 training images annotated with 3D bounding boxes. The full benchmark contains many tasks such as optical flow, visual odometry of moving objects, and so on. The object detection dataset is included in this dataset, along with bounding boxes and monocular images. There are 21 training sequences and 29 test sequences in the object tracking benchmark. Following datasets were used for the study: KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute) Dataset: KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute) [51] is one of the most widely used datasets for autonomous driving and mobile robotics. It is made up of hundreds of hours’ worth of traffic scenarios recorded with several sensor modalities, including 3D laser scanner cameras, grayscale stereo, and high-resolution RGB cameras. The dataset itself does not provide ground truth for semantic segmentation, despite its wide acceptance. CF_CC_50 Dataset: The UCF_CC_50 dataset [52] features 50 video clips from diverse sources, capturing scenes with varying crowd sizes and densities. It offers a unique temporal aspect, allowing us to evaluate the system’s performance in dynamic scenarios. The UCF_CC_50 dataset is a benchmark dataset for crowd counting tasks. It contains 50 video sequences of crowds with varying sizes and densities, captured from different real-world scenarios. Similar datasets like the Shanghaitech dataset [37] which is a large-scale crowd counting dataset, the WorldExpo’10 dataset [53] which represents a large-scale crowd counting scenario, recorded during the 2010 Shanghai World Expo can also be used.
Evaluation metrics
To quantitatively measure the performance of the proposed SNMC-DenCNN system, we employed a comprehensive set of evaluation metrics, including: Accuracy: Accuracy measures the proportion of correctly detected and tracked objects concerning the total number of objects. It provides a global assessment of the system’s overall performance. Precision: Precision calculates the ratio of true positive detections to the total number of detected objects. It evaluates the system’s ability to make accurate positive predictions. Recall: Recall, also known as sensitivity, assesses the system’s capacity to identify and track true positive objects out of all possible positive objects. It evaluates the extent to which the system can prevent false negatives. Specificity: Specificity evaluates the system’s ability to correctly identify and track true negative objects out of all possible negative objects. It evaluates the system’s ability to avoid false positives. F1 Score: The F1 Score combines precision and recall providing a balanced measure of the system’s object detection and tracking performance. It is very helpful when working with datasets that are unbalanced.
Implementation details
Our experiments were conducted using a deep learning framework and were run on a system equipped with NVIDIA GPUs for efficient training and evaluation. Key implementation details include: Network Architecture: The SNMC-DenCNN network architecture consists of multiple convolutional layers followed by max-pooling and fully connected layers. We utilized a pre-trained backbone architecture (e.g., VGG16, ResNet) for feature extraction and fine-tuned the model for density map regression. Training: The network was trained using stochastic gradient descent (SGD) with appropriate learning rate schedules. We employed data augmentation techniques to enhance model generalization, including random cropping, rotation, and flipping. Batch Size: The batch size was carefully chosen to balance memory constraints and training efficiency. Larger batch sizes were utilized for datasets with more extensive training samples. Hyperparameters: Hyperparameters such as weight decay, dropout rates, and activation functions were optimized through cross-validation to achieve the best performance.
Ablation study
In this section, we conduct an ablation study to gain insights into the individual contributions and significance of key components within the proposed SNMC-DenCNN system. By systematically evaluating the impact of various elements, we aim to provide a deeper understanding of how each component influences the overall performance.
Ablation Studies with CNN Components:
Instead of evaluating the impact of specific soft computing techniques, focus on the ablation of various components within the CNN architecture. For example, experiment with different configurations of Dense Blocks, variations in the number of layers, or modifications to the transition layers.
Comparison with CNN Variants:
Compare the proposed SNMC-DenCNN system with variants of CNN architectures. Explore different modifications to the architecture, such as varying the number of layers, using different activation functions (e.g., ReLU, Leaky ReLU), or employing alternative normalization techniques.
Incorporate State-of-the-Art CNN Models:
In the comparison section, include benchmark CNN models that are considered state-of-the-art for object detection and tracking. This allows a direct comparison between the proposed system and the best-performing CNN architectures.
Training Efficiency and Convergence:
Assess the training efficiency and convergence characteristics of the SNMC-DenCNN system compared to other CNN-based models. Consider factors such as training time, convergence speed, and computational resources required for achieving optimal performance.
Performance Metrics:
Evaluate the performance of the SNMC-DenCNN system using standard metrics employed in the evaluation of CNN models. Precision, recall, F1 score, and accuracy are essential metrics for object detection and tracking.
Transfer Learning and Domain Adaptation:
Explore the system’s ability to transfer learning to new domains and evaluate its domain adaptation capabilities. Compare these capabilities with other CNN models, especially those known for robustness across different scenarios.
Real-Time Processing:
Emphasize the real-time processing capabilities of the proposed system in comparison to other CNN-based models. Consider the speed and efficiency of object detection and tracking during real-time applications.
Resource Utilization:
Compare the resource requirements of the SNMC-DenCNN system with other CNN architectures. Assess the model’s efficiency in terms of GPU utilization, memory consumption, and overall hardware requirements.
By focusing the ablation studies and comparisons on CNN-related components and models, you can highlight the contributions and improvements specific to the proposed CNN-based system for object detection and tracking.
Experimental design
The ablation study is designed to investigate the following aspects: Motion Estimation Method: To assess the influence of the motion estimation method, we compare the results obtained using the modified Adaptive Distance Covariance Rood Pattern Search (ADCRPS) algorithm, which is a crucial component of our system, with alternative motion estimation techniques. Morphological Operations: We analyze the effect of morphological operations (e.g., Dilation, Erosion, Opening, and Closing) on the quality of motion-estimated images. We compare the performance with and without these operations to determine their impact. Feature Selection Algorithm: The Chaotic Tent Shuffled Shepherd Optimization (CTSSO) algorithm is employed for feature selection in the proposed system. We evaluate the influence of feature selection by comparing the results with and without the CTSSO algorithm. Object Detection Architecture: We investigate the choice of the object detection architecture, particularly the use of Dense Convolutional Neural Networks (DenCNN) with or without the inclusion of the SNMC activation function.
Results and analysis
The ablation study results are presented in terms of the evaluation metrics used in the main experiments, including accuracy, precision, recall, specificity, and F1 score. We also provide qualitative insights into the system’s performance through visualizations and comparisons of object detection and tracking results. Motion Estimation Method: We observe the impact of using ADCRPS compared to alternative motion estimation methods on the accuracy of object tracking. This analysis helps us understand the suitability and effectiveness of the chosen motion estimation approach. Morphological Operations: The ablation study allows us to assess whether morphological operations improve the quality of motion-estimated images and consequently enhance object detection and tracking performance. Feature Selection Algorithm: We evaluate the role of the CTSSO algorithm in selecting informative features and its influence on the overall system accuracy and efficiency. Object Detection Architecture: By comparing the results of DenCNN with and without SNMC activation, we can determine whether the SNMC activation function contributes to improved object detection accuracy.
Through this comprehensive ablation study, we aim to provide a granular understanding of the individual contributions of system components, allowing us to fine-tune and optimize the SNMC-DenCNN system for the task of object detection and tracking in diverse scenarios. These insights can guide further improvements and developments in the proposed methodology.
The results of the ablation study will be summarized in a Table 1, highlighting the performance differences between different configurations and shedding light on the essential components that lead to the system’s superior performance.
Comparison of baseline with other detection
Comparison of baseline with other detection
Each row corresponds to a different configuration or component of the system, and the columns represent key evaluation metrics, including accuracy, precision, recall, specificity, and F1 score. The “Baseline” row represents the full SNMC-DenCNN system’s performance for reference.
The table provides a clear comparison of how altering each component affects the overall system’s performance. This summary helps in identifying the essential components that contribute to the superior performance of the SNMC-DenCNN system. It also aids in understanding which elements can be optimized further for better results.
In this section, the performance of the proposed method is analyzed by comparing it with the existing methods i.e. Recurrent Neural Network (RNN), DenCNN, Artificial Neural Network (ANN), and Deep Neural Network (DNN) based on accuracy, specificity, sensitivity, precision, recall and F-Measure, which is shown in Table 2.
Analyzing the performance of the proposed SNMC-DenCNN with the existing models
Analyzing the performance of the proposed SNMC-DenCNN with the existing models
The proposed system achieved good accuracy since the system used the SNMC-DenCNN algorithm. Specificity is the extent to which different perspectives on an object elicit the same recognition reaction in a particular subject. The combination of precision and recall as F-Measure is found to be about the average of the two when they are close, and it is more generally the harmonic mean, which coincides with the square of the geometric mean divided by the arithmetic mean in the case of two integers. From the analysis, the proposed SNMC-DenCNN is achieved 98.2% accuracy, which was higher when compared to other existing methods.
In this comparative analysis, the performance of the proposed SNMC-DenCNN was compared with the existing methods in graphical representation. The main intention of the proposed work is to be achieved higher accuracy. Based on the accuracy metric, the proposed SNMC-DenCNN algorithm achieved 98.2% accuracy, which is higher than the other existing algorithms. Hence, the analysis proved that it attained higher accuracy than existing methodologies.
Specificity is the metric that evaluates a model’s ability to predict true negatives. Then, the proposed system identified 96.34% negatives. Nevertheless, the existing methods were still stumbling to make that. Then the performance of the proposed SNMC-DenCNN with the existing techniques in terms of precision, recall and F-Measure. From Fig. 4 it can be proved that the performances of precision and recall values is high, which were 96.88% and 97.35% respectively, along with that F-Measure is also high, which was 97.11%.

Computational time analysis.
The computational time of the proposed method is 807 s, which is low to complete the entire processing work. But the existing model takes a long time to execute the operation i.e. RNN takes 948 s, DenCNN takes 1150 s, and ANN, and DNN takes 1245 s, 1054 s respectively. Hence, the analysis proved that the processing time of the proposed SNMC-DenCNN takes less time.
In this paper, a new framework was presented to detect multiple objects using the SNMC-DenCNN algorithm. The proposed work not only performs the object detection, however, it also returns the object counts by tracking the detected objects. The proposed methodology works under the five phases namely, preprocessing, motion estimation, morphological operation, feature extraction, features selection, object detection, tracking, and counting. In experimental analysis the performance of the proposed system was evaluated by comparing the proposed SNMC-DenCNN with existing methods. For analysis the proposed system utilized the images from the KITTI dataset. In the analysis, the accuracy of the proposed system achieved was 98.2%, which is higher than the existing model and the computational time was 807 s, which is also considered as lower level. Hence, it revealed that the proposed system is claimed to be more efficient when compared to the existing systems. In future the work may consider more advanced algorithms to improve the accuracy of the detection system.
Declaration on consent for publication
We, the authors of this research paper, hereby provide our consent for the publication of our work titled “Proposed Object Detection and Tracking System Using SNMC-DenseCNN” in the specified journal or conference proceedings.
In this declaration, we wish to clarify the intent and significance of our research, as well as the importance of sharing our findings with the scientific community.