
Abstract
Recent advances in high-throughput electron microscopy (EM) have revolutionized the examination of microstructures by enabling fast EM image generation. However, accurately segmenting EM images remains challenging due to inherent characteristics, including low contrast and subtle grayscale variations. Moreover, as manually annotated EM images are limited, it is usually impractical to utilize deep learning techniques for EM image segmentation. To address these challenges, the pyramid multiscale channel attention network (PmcaNet) is specifically designed. PmcaNet employs a convolutional neural network-based architecture and a multiscale feature pyramid to effectively capture global context information, enhancing its ability to comprehend the intricate structures within EM images. To enable the rapid extraction of channel-wise dependencies, a novel attention module is introduced to enhance the representation of intricate nonlinear features within the images. The performance of PmcaNet is evaluated on two general EM image segmentation datasets as well as a homemade dataset of superalloy materials, regarding pixel-wise accuracy and mean intersection over union (mIoU) as evaluation metrics. Extensive experiments demonstrate that PmcaNet outperforms other models on the ISBI 2012 dataset, achieving 87.85% pixel-wise accuracy and 73.11% mean intersection over union (mIoU), while also advancing results on the Kathuri and SEM-material datasets.
Introduction
The preliminary material property evaluation phase entails a comprehensive analysis of the surface of materials. Optical microscopes have traditionally been the primary instruments used for visually examining microscopic objects. In contrast, Electron microscopy (EM) provides superior resolution compared to light-based imaging, as it uses an electron beam to capture high-resolution images, allowing observation of objects with wavelengths smaller than light. It is achieved by leveraging an electron beam to irradiate a solid substance and detecting scattered electrons to generate high-resolution EM images [1]. To bridge the gap between the microscopic and macroscopic scales, image segmentation algorithms are employed to analyze EM images and extract information about the material’s surface or near-surface structure. This research paradigm has found widespread application in various fields, including medicine [2], biology [3], and other relevant domains. It plays a crucial role in advancing fundamental disciplines.
With advancements in electron microscopy imaging technology, these techniques now generate high-resolution EM images with data volumes ranging from gigabytes to terabytes [4]. Figure 1 depicts our homemade SEM-material dataset alongside the corresponding ground truth, which was derived from an EM scanning result of a high-temperature alloy material. There is a significant difference in pixel distribution between EM images and natural images. EM images, in contrast to natural images, exhibit minimal color information, significant scale variations, and a pronounced class imbalance [5]. This observation implies that methods of segmentation designed primarily for natural images may struggle to produce promissing results when applied to EM images. Consequently, segmenting EM images with volumes up to terabytes presents a formidable challenge. Recently, several machine learning techniques, such as ilastik [6], TrakEM2 [7] and Microscopy Image Browser [8], have been proposed as potential solutions to this issue. While these methods have demonstrated satisfactory inference metrics, deep learning models offer further advancements through their enhanced feature extraction capabilities, enabling them to better fit the data.

An illustration of the EM image segmentation challenges, which shows the original image from our homemade SEM-material dataset (A) and the ground truth (B). The region of interest is annotated using a yellow dash box. The absence of color information and the presence of class imbalance are challenging issues.
Recently, various deep learning models have successfully been applied to segment EM images. An illustrative example is U-net [9], which enhances the architecture of fully convolutional networks (FCNs) [10] by incorporating upsampling in a reverse expansive path along with skip connections. This module facilitates improved mask output and fosters a comprehensive learning framework. Moreover, EM-net [11], a scalable deep convolutional neural network that extends the U-net [9] architecture, was specifically developed for segmenting EM images. This study demonstrates the ability to achieve effective learning outcomes with a limited set of ground truth samples in the context of 2D EM image segmentation tasks.
However, due to the high resolution of EM images, it is necessary to divide them into smaller patches during model training. Unfortunately, this partitioning inevitably results in a reduction in available contextual information [12]. Additionally, the limited spatial range of convolutional filters restricts the incorporation of comprehensive global information from the image. This limitation is particularly significant for image segmentation tasks that heavily rely on the utilization of global context. Furthermore, the process of providing ground truth samples for electron microscopy datasets presents considerable challenges due to the low contrast exhibited by these samples. According to a study [13], manual data segmentation or annotation costs an average of $10 per μm3, which might amount to thousands of dollars for a relatively large data volume. The absence of annotated data poses a significant obstacle for EM image segmentation tasks.
To address these limitations, a pyramid multiscale channel attention network (PmcaNet) is proposed for enhancing EM image segmentation. In contrast to other methods, PmcaNet distinguishes itself by leveraging pyramid multiscale feature extraction and attention mechanisms to capture contextual relationships spanning various feature scales. This approach enables effective learning from a limited number of ground truth samples and concurrently enhances the accuracy of 2D EM image segmentation. Furthermore, the paper introduces the lightweight adaptive channel attention (LACA) module to reduce computational complexity while ensuring performance. By extracting attention vector of each channel, the LACA module captures intricate nonlinear structures present in EM images with fewer computations. The incorporation of multiscale contextual information in PmcaNet, achieved by harnessing multiscale attention information to enhance features, contributes to an improved accuracy in segmenting larger objects within EM images.
In summary, the following four contributions are offered by this work: (i) A novel EM dataset named SEM-material is proposed, focusing specifically on superalloy materials. (ii) A new architecture named PmcaNet is specifically developed to enhance the utilization of multiscale attention value and context information. (iii) A lightweight adaptive channel attention (LACA) module is designed to improve the understanding of the complex structures present in EM images and reduce computational complexity while ensuring efficient learning. (iv) The effectiveness of PmcaNet is extensively evaluated on our homemade SEM-material dataset as well as two general EM datasets, ISBI 2012 [14] and Kathuri [15]. Extensive experiments reveal that PmcaNet achieves competitive results in EM image segmentation.
The subsequent sections are organized as follows. In Section 2, related work concerning natural image segmentation and electron microscopy image segmentation is explored. Section 3, describes each module of our approach. The experiments and analysis are presented in Section 4. Section 5 introduces the examination of the individual roles of each module and an assessment of the model’s convergence. Finally, Section 6 concludes this paper.
Natural image segmentation
Computer vision researchers have predominantly focused on natural images, which capture ordinary scenes from the natural environment and exhibit abundant and high-quality content. In this domain, deep learning models based on encoder-decoder architectures have emerged as the prevailing approach, with particular prominence given to fully convolutional networks (FCNs) [10]. Several methods have been proposed to enhance the receptive field of convolutional networks, including the use of dilated or atrous convolutions [16]. Initial approaches [17–20] involved a sequence of consecutive convolutions followed by spatial pooling to generate dense predictions. For instance, PSPNet [21] employed spatial pyramid pooling to capture contextual information at multiple scales, while DeepLabv3+ [22] integrated atrous spatial pyramid pooling to achieve an efficient encoder-decoder architecture. OneFormer [23] employs a backbone and pixel decoder to extract multi-scale features from the input image, yielding a more densely packed feature representation. Recently, many studies have explored the integration of attention mechanisms into encoder feature maps to replace coarse pooling. Sophisticated techniques have been proposed to enhance channel-wise dependencies [24–26], and spatial attention mechanisms [27–29] have been integrated with other techniques to improve long-range dependency acquisition. SegViT [30] introduces an Attention-to-Mask (ATM) decoder module, which harnesses the spatial information within the attention map to generate mask predictions for each category. However, due to the substantial disparities in grayscale distribution and other characteristics between electron microscopy images and natural images, achieving satisfactory results on EM images through the application of natural image segmentation methods is challenging.
Electron microscopy image segmentation
Electron microscopy involves collecting electrons that reflect from the imaged specimen surface, resulting in EM images [11]. The pixel distribution observed in EM images differs significantly from that of natural images. In recent years, deep learning models have made notable advancements in addressing the challenges of semantic segmentation in EM images, surpassing traditional approaches that relied on manually engineered features [31–33]. Previous research [34, 35] on scanning electron microscopy (SEM) images of sandstone and transmission electron microscopy (TEM) images of mouse brain slices has provided evidence supporting this phenomenon. Oztel et al. [36] introduce a deep convolutional neural network that incorporates a sliding window strategy and subsequent postprocessing steps to enhance its performance. MitoNet [37] introduced a generalizable model for segmenting individual mitochondria across volume electron microscopy datasets. Nonetheless, these methods have not effectively tackled the challenges associated with the absence of edge information and incomplete object segmentation in EM images. We contend that the acquisition of supplementary global contextual information is imperative for addressing these issues.
Method
Overview
Figure 2 provides an overview of the proposed model. The backbone network of PmcaNet is based on the ResNet-50 model, which incorporates dilated convolutions to expand the receptive field. The choice of the ResNet-50 model as the backbone network for PmcaNet was made to strike a balance between model capacity and computational efficiency, which is particularly well-suited for our segmentation task. The final feature map from the backbone network is then fed into the multiscale channel attention pyramid module. This module captures global contextual dependencies across different geographical dimensions. Distinguished from alternative approaches, within the multiscale channel attention pyramid module, the lightweight adaptive channel attention (LACA) module is utilized to compute channel attention on feature maps at multiple scales. The channel attention vector is then produced by the multiscale attention fusion module, which incorporates attention values from different dimensions. Finally, the low-level features collected from the backbone network are fused with the enhanced high-level features, generating the final features used for pixel-level mask prediction.
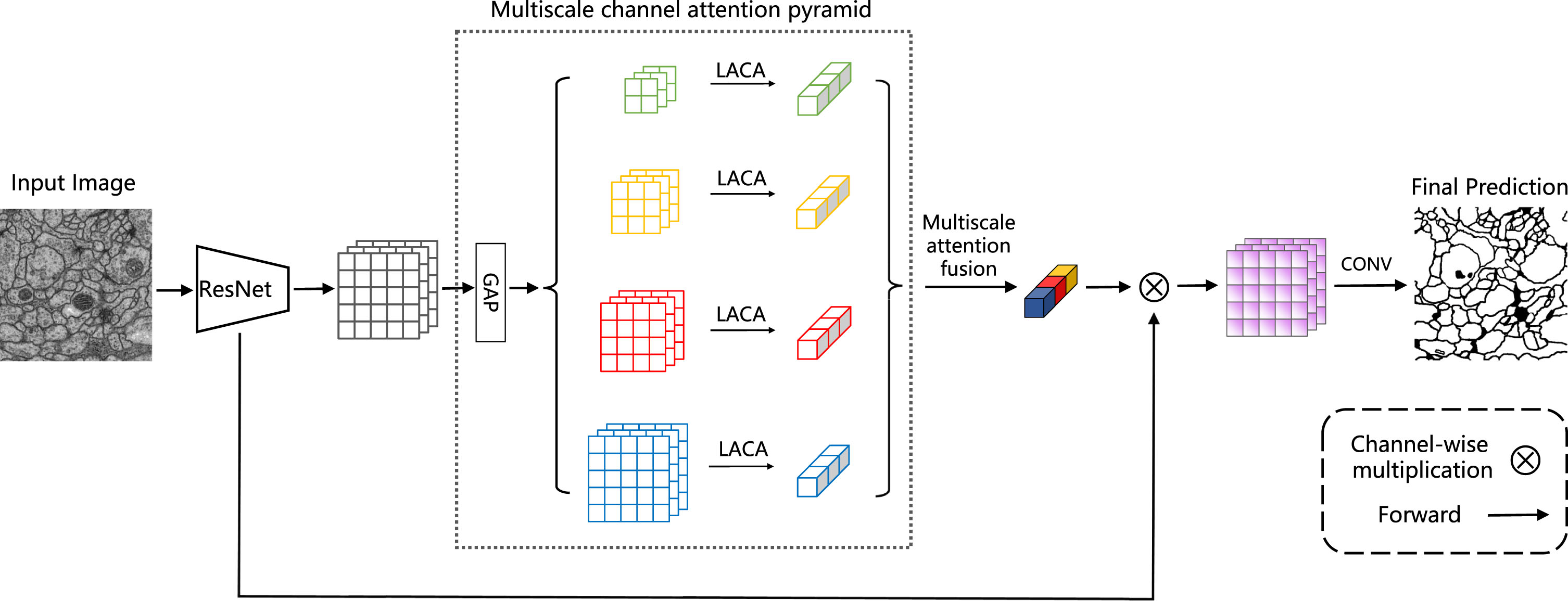
An overview of the proposed PmcaNet. The flow of information is indicated by the black arrows. Within the architecture, "GAP" denotes a global average pooling layer, and "LACA" signifies lightweight adaptive channel attention.
In semantic segmentation tasks with complex scenes, integrating multiscale information has shown significant performance improvement. Incorporating attention mechanisms allows the model to selectively focus on important regions, enhancing the segmentation results for objects of varying dimensions. Hence, it is necessary to independently derive attention of different scales and utilize it to enhance features. This methodology optimizes the use of contextual information from lower-level feature maps, improving segmentation performance.
The multiscale channel attention pyramid module extracts feature maps applying the same pyramid pooling parameters as PSPNet [21]. By performing pooling operations with kernel sizes of 1×1, 2×2, 3×3, and 6×6, feature maps at different scales are generated, capturing information at various scales. The lightweight adaptive channel attention (LACA) module is then applied to collect the global priors for each layer to gather attention values covering the entire image and those covering half of the image and small portions. Finally, the adaptive fusion of attention maps yields contextual information that encompasses a broader range of semantic details.
Lightweight adaptive channel attention (LACA)
Channel attention mechanisms, leveraging squeeze and activation operations, play a crucial role in facilitating feature integration and recalibration. The lightweight adaptive channel attention (LACA) module is designed to obtain channel attention values, enabling the capture of channel dependencies and enhancing the feature representation capability. Figure 3 provides an overview of the zooming process, while the LACA module can be represented as follows:

The specifics of our lightweight adaptive channel attention (LACA) module. In the diagram, "GAP" corresponds to global average pooling, "CONV" represents 1D convolution, and "BN" stands for batch normalization.
Recently, Qilong Wang et al. [25] have proposed a mapping relationship between the number of feature map channels C and the convolution kernel size k to better represent the correlation between high-dimensional and low-dimensional channels:
The linear relationship is acknowledged as the most fundamental mapping function. However, the presence of sparse feature relationships can pose challenges in representing the interconnections between channels. Hence, the employment of nonlinear functions to facilitate the mapping process is taken into consideration. Exponential functions are particularly favored for their effectiveness in integrating information across multiple channel dimensions. Therefore, exponential functions are used as the mapping function:
Then, the size of the convolution kernel can be adaptively determined by the channels C:
After obtaining attention information at multiple spatial scales, a straightforward additive fusion technique can be used to derive multiscale attention weights. However, it is important to note that the relative importance of different hierarchical attention modules may vary and should not be presumed to be equal. Determining the weights experimentally can be computationally expensive and may not guarantee generalization. Weizhen Wang et al. [38] have suggested employing an adaptive learning strategy to determine the magnitudes of the weights. Similarly, in this study, the weight vector is derived by applying a 1×1 convolution operation to the various hierarchical level outputs:
Finally, the attention information is fused with the low-level feature F as follows:
The sample imbalance issue in EM images is considered during the model training process. To address this bottleneck, Dice loss [39] is utilized as the loss function. The Dice loss encourages the model to allocate more attention to foreground regions that may have sparse features, effectively addressing the challenge posed by class imbalance:
Additionally, the multiclass cross-entropy (CE) loss [40] is employed to evaluate the pixel-wise classification error:
Consequently, PmcaNet is trained by minimizing the overall loss objective:
Datasets and metrics
Figure 4 illustrates some samples from the three datasets ISBI 2012 [14], Kathuri [15], and SEM-material used in the experiments, with details as follows:

Some examples of ISBI 2012, Kathuri, and SEM-material datasets. ‘Source’ indicates the original images, while ‘GT’ represents the corresponding ground truth.
The backbone network used for PmcaNet is ResNet-50, pre-trained on the ImageNet-1k dataset. During training, the data augmentation pipeline from the MMSegmentation [41] library is applied. This pipeline includes random horizontal flipping, random cropping, and random resizing with a scale between 0.5 and 2.0. Stochastic gradient descent (SGD) [42] is employed for training the models with a fixed momentum of 0.9. Additionally, the ’poly’ learning rate schedule is utilized, defined as
a) ISBI 2012: By default, the initial learning rate is set to 0.01, the weight decay is set to 0.9, the crop size is set to 128×128, and the batch size is set to 16. If not supplied, the training iterations default at 40K.
b) Kathuri: By default, the initial learning rate is set to 0.005, the weight decay is set to 0.9, the crop size is set to 512×512, and the batch size is set to 8. If not supplied, the training iterations default at 20K.
c) SEM-material: By default, the initial learning rate is set to 0.005, the weight decay is set to 0.9, the crop size is set to 512×512, and the batch size is set to 8. If not supplied, the training iterations default at 40K.
All experiments are conducted on a workstation equipped with 8 NVIDIA A40 48G GPU cards.
Results analysis
A comprehensive evaluation is conducted to compare the performance of PmcaNet with the latest models on three distinct datasets: ISBI 2012, Kathuri, and SEM-material. The objective of this evaluation is to assess the effectiveness of PmcaNet in electron microscopy image segmentation. Table 1 presents the results, demonstrating the efficacy of the proposed approach in accomplishing the segmentation tasks.
Comparison with state-of-the-art methods. ‘pixel acc.’ refers to pixel-wise accuracy, while ‘mIoU’ stands for mean intersection over union
Comparison with state-of-the-art methods. ‘pixel acc.’ refers to pixel-wise accuracy, while ‘mIoU’ stands for mean intersection over union
On the ISBI 2012 dataset, PmcaNet achieves a pixel-wise accuracy (pixel accuracy) of 87.85% and a mean intersection over union (mIoU) of 73.11%, outperforming the other models. Similarly, on the Kathuri dataset, PmcaNet performs the best with a pixel accuracy of 98.97% and a mIoU of 83.99%. These outcomes illustrate the comparable segmentation performance of the proposed method for electron microscopy images.
Furthermore, when evaluated on the homemade SEM-material dataset, which presents challenges such as larger image sizes, cluttered backgrounds, and sparser foreground information, PmcaNet demonstrates exceptional performance. It achieves a pixel accuracy of 99.66% and a mIoU of 68.39%, surpassing other models evaluated in this study. Regarding the number of parameters, it is worth noting that while PIDNet [43] has fewer parameters, its performance is relatively lower. This accomplishment can be ascribed to the integration of a multiscale attention network within the primary decoder. This integration allows for the utilization of diverse information at various resolutions, aiding in the capture of comprehensive contextual details and enhancing feature representation.
This section presents the comparative results of PmcaNet on various datasets. The test results from the SEM-material dataset and the Kasthuri dataset are visualized in Figs. 5 and 6, respectively. Figure 5 shows the results of PmcaNet, which indicate improved precision and greater object completeness on the SEM-material dataset. Notably, segmenting the primary phase (highlighted in red) and hole structures inside the primary phase (highlighted in black) indicates some improvement. In contrast, DeepLabv3+ [22] and PIDNet [43] encounter difficulties that result in gaps, causing misclassification of pixels.

Visual improvements on the SEM-material dataset. PmcaNet produces more accurate and detailed results.

Qualitative results of the proposed PmcaNet and other methods on the Kathuri dataset.
In Fig. 6, a selection of results from the Kasthuri dataset’s test set is shown. The results obtained by PmcaNet exhibit more complete objects and demonstrate superior performance in terms of contours and details, as compared to both EM-net [11] and PIDNet [43]. This improvement can be attributed to PmcaNet’s effective incorporation of rich contextual information and comprehensive global information. The utilization of such information enables PmcaNet to effectively handle category boundaries, which is crucial for EM image segmentation tasks that lack color information and heavily rely on texture information.
Ablation study
To conduct a comprehensive analysis of the methodology, a series of ablation experiments are devised to evaluate the efficacy of the network modules.
Ablation study of multiscale channel attention pyramid
Ablation study of multiscale channel attention pyramid
Evaluating the effectiveness of different channel attention modules
Ablation study with different attention fusion modules. ‘Addition’ represents that the fusion method is the form of addition, ‘Multiplication’ stands for bitwise multiplication and ‘MAF’ represents multiscale attention fusion
Performance comparison with or without diversity loss. λ1 and λ2 represent the weight of cross-entropy loss and Dice loss, respectively
Moving forward, the complexity and convergence time of different methods will be analyzed to highlight the advantages of PmcaNet in terms of model complexity and convergence speed.
Figure 7 compares the parameter count and mIoU performance of various methodologies used for the SEM-material dataset analysis. Among them, PIDNet requires the fewest parameters, while segmentor [27] requires the greatest number. PmcaNet, with 11.65 million parameters, has a slightly higher count than PIDNet [43] but significantly fewer than segmentor [27] and SegViT [30], which utilizes a ViT-based encoder with 102 million parameters. Furthermore, PmcaNet has a comparable number of parameters to other convolutional neural network-based models, such as EM-net [11] and DeepLabv3+ [22]. Despite this, it should be noted that PmcaNet does not necessitate significantly more computational resources during a single forward pass when compared to other methods. This allows PmcaNet to achieve superior performance without incurring a significant increase in the parameter count.

Comparison of model performance and number of parameters on SEM-material. PmcaNet achieves improved performance with minimal additional parameters.
To assess the training progress of all models, the mean intersection over union (mIoU) and loss metrics on a validation set are depicted graphically in Fig. 8. Notably, the validation results indicate that PmcaNet exhibited the lowest validation loss and the highest mIoU score, thus emphasizing its superior performance and faster convergence speed. These advantages enable PmcaNet to deliver outstanding results in a shorter training time compared to more complex models.

An illustration of the tendency of the loss (A) and mIoU (B) for different methods during training for mitochondria segmentation on the Kathuri dataset.
In this paper, the problem of challenging the segmentation of electron microscopy (EM) images due to inadequate contrast and grayscale approximation is examined. To enhance the precision of EM image segmentation and address the issue of insufficient data sets, a novel multi-scale channel attention pyramid is employed. Diverging from other techniques, this structure comprehensively extracts local and global information from EM images by capturing attention values at various scales. This approach is pivotal for representing intricate nonlinear characteristics within the images. Additionally, an electron microscopy (EM) image data set of high-temperature alloy materials, known as SEM-material, is presented. The provision of more datasets is imperative for the advancement of the field.
Conclusion
This paper introduces PmcaNet, a novel model aimed at enhancing the utilization of contextual information across multiple scales in low-contrast electron microscopy images. The key contribution of this research lies in the proposal of a multiscale channel attention pyramid, which effectively integrates semantic context from various scales. Furthermore, a lightweight adaptive channel attention module is introduced to capture channel dependencies and enhance the representation capacity of features. Ablation studies were carried out to determine the effectiveness of the proposed modules, which were designed to address the challenge of identifying approximate grayscale pixels under low contrast conditions in electron microscopy image segmentation. These advancements have significantly reduced the difficulty of this task by improving the use of multi-scale information. According to the results, it is evident that PmcaNet produces promising results for electron microscopy image segmentation.
Additionally, the issue of lacking available data for electron microscopy (EM) image segmentation is addressed in this study by introducing a novel dataset named SEM-material, which may contribute to alleviating data scarcity in the EM image segmentation domain. In the future, to achieve better performance and further reduce computing complexity, more efficient self-attention methods will be employed.
Footnotes
Acknowledgement
The research was supported by the National Science Foundation of China (No. U22B2048).