
Abstract
Hypernym discovery aims to distinguish potential hypernyms for a query term. However, existing methods for hypernym discovery suffer from the following problems: (1) traditional unsupervised pattern-based methods suffer from low recall; (2) recent supervised box embedding methods are deficient in identifying specific hypernyms. To cope with the above problems, this paper presents a method for hypernym discovery based on
Introduction
In the field of linguistics, hypernymy represents a basic semantic relationship that is an asymmetrical relationship between a superordinate and a subordinate term [1]. Hypernymy is not only an important part of classification system construction and other intensive systems but is also widely used in various downstream tasks of natural language processing (NLP), including knowledge graphs and question-answering systems [2, 3], etc. Due to the wide application value of hypernymy, the accurate prediction of hypernymy relation becomes an important task in NLP research. In this article, we address the problem of hypernym discovery rather than hypernym detection. Usually, for hypernym detection, which is common to transform the task into a binary classification problem. Hypernym detection classifier often learns which words are typical hypernyms, rather than directly determining whether there is a hypernymy relationship between the two concepts. Hypernym detection employs this experimental configuration and is prone to encounter the problem of “lexical memorization” [4]. To alleviate the “lexical memorization” problem, Luis et al. [5] introduced the task of hypernym discovery. When provided with a query term and a domain-specific vocabulary, the objective is to identify potential hypernyms for the given term. Hypernym discovery alleviates the “lexical memorization” problem and facilitates its use with other downstream tasks, including semantic retrieval, question-answering systems, etc. Inspired by this, the coordinators of SemEval Task9 released a public dataset for hypernym discovery tasks, encompassing various languages and domains of knowledge [6]. In this paper, we assess the effectiveness of our method on the English sub-tasks of SemEval 2018 Task 9.
In the existing research, the methods for hypernym discovery are primarily classified into two main categories: unsupervised pattern-based method and supervised distributed learning method. The pattern-based method was originally introduced by Hearst [7], where the author focused on particular lexical and syntactic patterns, and used text-matching to automatically extract entity pairs with hypernymy relationships from the corpus. For example, in the sentence “
This paper proposes a new method for hypernym discovery: EP-BoxE, which combines a pattern-based method and a distributed learning method. For the pattern-based method, with a view to improving the recall and robustness of the pattern-based method and discovering more hypernymy relationships, we extend and improve it by using the extended pattern-based hypernym discovery method. For the distributed learning method, we employ the newly introduced box embedding method [8] to identify hypernyms within the corpus, which represents entities as points in an n-dimensional Euclidean space and relations as regions in an n-dimensional Euclidean space, that is, for hypernymy relation, box embedding method represents it as two boxes in an n-dimensional Euclidean space. Finally, we perform experiments on two publicly available datasets, and the outcomes demonstrate that EP-BoxE outperforms the popular methods. In summary, the key contributions of this paper are as follows: An extended pattern-based hypernym discovery method is proposed, which effectively improves the recall of the pattern-based method. By utilizing the linguistic patterns of the concepts themselves, some specific hypernyms are discovered, which solves the deficiency of the box embedding method in identifying specific hypernyms. Thorough experiments are carried out on two publicly available datasets to verify the efficacy of the EP-BoxE method, which has better performance than other existing methods.
The rest of this paper is organized as follows: Section 2 reviews the related work; Section 3 presents our proposed method in detail; Section 4 introduces and analyzes the experimental results; Finally, Section 5 concludes this paper.
Related work
Hypernym detection and discovery
In existing studies, the methods for hypernym detection and discovery can be broadly classified into two main groups: pattern-based methods and distributed learning methods [9].
The pattern-based method is a widely adopted unsupervised method, and almost all pattern-based approaches can be traced back to the Hearst pattern [7]. Even in recent years, these patterns continue to be extensively employed in constructing expansive taxonomies, such as Probase [2], WebIsADB [10], etc. Since Hearst patterns have a high degree of rigidity, most of the subsequent research work focus on enhancing the coverage of Hearst patterns. One prevalent technique is referred to as “pattern generalization”, which employs more generalized language patterns to substitute the fixed Hearst patterns. Navigli et al. [11] introduced the notion of “Star pattern”, which employs placeholders to replace the most common words in the pattern. Nakashole et al. [12] introduced the PATTY system, which added more additional information to achieve pattern generalization, including knowledge ontology categories, part-of-speech tagging, etc. Arshia Z.Hassan et al. [13] uses hearst patterns to extract hypernymy relation pairs and ranks candidate hypernyms based on co-occurrence frequency of the pairs. Yun et al. [14] introduce Hypert, which is further pretrained using masked language modeling with Hearst pattern sentences. The primary problem of the pattern-based approach lies in its inability to extract the hypernymy relation between two entities unless they co-occur within the same sentence. Our extended pattern-based method enhances the co-occurrence frequency between entities, thereby enabling the extraction of a greater number of hypernymy entity pairs.
To solve the problem of co-occurrence sparsity between entities, distributed learning approach directly uses the distributed representation of two entities (also called word vectors, word embeddings, etc.) to infer whether they have a hypernymy relation [15–17]. According to the different learning approaches, distributed learning approaches can be divided into unsupervised hypernymy relation measures and supervised hypernymy relation classifiers. For any pair of concepts, an unsupervised hypernymy relation measure calculates a score, which is used to measure the likelihood of them having a hypernymy relation. Classic hypernymy relation measures include WeedsPrec [18], SLQS [19], and so on. However, experimental results indicate that among these classic measures, none outperforms all other methods on every dataset. The common method for supervised hypernymy relation classifiers is to use the distributed representation of two entities as the input of the classification model and train a binary relation classifier. Classical algorithms directly use the word vectors of two entities or perform simple arithmetic operations on their word vectors as the features of the classifier. In recent years, Roller et al. proposed the asym model [20], which uses both the difference and squared difference of word vectors as the features of the classifier, better utilizing the anti-symmetry of hypernymy relations. Turney and Mohammad et al. proposed the simDiff model [21], which calculates the semantic similarity between two concepts and other words separately and then uses the difference of two semantic similarity vectors as features. Yu et al. [22] utilized a vast amount of hypernymy relationship data from Probase [2] to separately learn distinct distributed representations for a concept when it serves as a hypernym and a hyponym. They also introduced a maximum-margin neural network model for hypernymy relation classification. However, these methods often suffer from “lexical memorization” problem, which affect the accuracy of practical predictions. The underlying reason for this problem is that hypernymy relation classifiers frequently learn the weights of word embeddings in various dimensions. They are more inclined to learn which words serve as typical hypernyms rather than determining whether there exists a hypernymy relationship between two entities. The box embedding method we utilize explicitly models the hypernymy relationships between entities, effectively resolving the “lexical memorization” problem.
Embeddings
In the supervised methods, we use an embedding-based method. Yu et al. [23] proposed a distance-margin neural network to learn word vectors based on some pre-extracted hypernymy attributes, which utilizes the word vectors as input for an SVM classifier for hypernym prediction. However, a major drawback of this method is that it learns hypernymy pairs without taking the context into account, resulting in poor generalization ability of term embeddings. Hyperbolic embeddings represent entities as points on a hyperbolic surface, such as on a Poincare ball, and can be viewed as a continuous extension of hierarchical structures [24, 25]. However, the mentioned graph-based approaches usually demand training data with a hierarchical structure, and can’t use unstructured noisy data to learn taxonomy. Abboud et al. proposed BoxE [8], a method that treats entities as points and relations as a group of boxes that spatially capture basic logical properties, and our supervised method also relies on BoxE.
Methodology
In this part, we will introduce the proposed EP-BoxE, which combines two methods: the extended pattern-based method and the box embedding method.
Hypernym discovery employing pattern-based
In this subpart, we illustrate the pattern-based method we use, which has the biggest drawback of low recall, because it considers that the hypernym and hyponym appear in the same sentence, which is often not the case in reality. To improve the recall, we enhance the pattern-based method from two aspects. We look for the co-hyponyms of each term and take the hypernyms of these co-hyponyms as the candidate hypernyms of that term. We mainly identify these co-hyponyms by pattern matching and filter them using the distributed similarity of the trained word embeddings. The linguistic patterns of the terms themselves also provide additional information for hypernymy relation identification. We find that most terms are composed of multiple words, and the headwords of compound terms often have hypernymy relations with the terms.
We use enumeration patterns to find co-hyponyms (e.g. X1, X2 and X3), and use Hearst patterns to find hypernyms, as shown in Table 1 for the Hearst patterns we adopt.
Hearst patterns
Hearst patterns
The extended pattern-based hypernym discovery algorithm we use can be described as follows: Given a query term q to find its hypernyms, create an empty set Q to store the set of co-hyponyms of the query term q. Use the co-hyponym patterns to search for the co-hyponyms q′ of the query term q, store q′ and its frequency f (q′) in the set Q. Score each co-hyponym q′ ∈ Q by multiplying f (q′) with the cosine similarity of the embeddings of q and q′. Rank the co-hyponyms in Q according to this score, keep the TopN, and discard the rest, we set TopN = 5 empirically. Add the original term q to Q and create an empty hypernym set Hq. For each q′ ∈ Q, find its hypernyms according to the Hearst patterns, and add these hypernyms to Hq. Add the head of q′ ∈ Q to Hq, as well as the head of the original term q. For each c ∈ Hq, remove c from Hq if it is not in the vocabulary because we have not learned its embedding in the corpus. Score each candidate hypernym c ∈ Hq by multiplying its normalized frequency Softmax (f (c)) by the cosine similarity between the embeddings of c and q. Rank all candidate hypernyms in Hq according to the score, the normalized frequency Softmax (f (c)) is set to [0.05,1.0].
In the above process, the calculation method of cosine similarity is shown as follows:
Where E q represents the embedding vector of the target query term q, Eq′ represents the embedding vector of the co-hyponym q′ ∈ Q. The cosine similarity between the hypernym c ∈ Hq and the query term q is calculated similarly to this.
Finally, we conducted a statistical analysis of the number of hypernymy pairs extracted using the extended pattern-based method and the pattern-based method, as shown in Figs. 1 and 2. In the figures, P1-P6 correspond to the six patterns in Table 1. From the experimental results, it is evident that the extended pattern-based method extracted a significantly higher number of hypernymy pairs compared to the pattern-based method. By using the extended pattern-based hypernym discovery method, the coverage of the pattern-based method is improved, which also solves the deficiency of the box embedding method in identifying specific hypernyms.
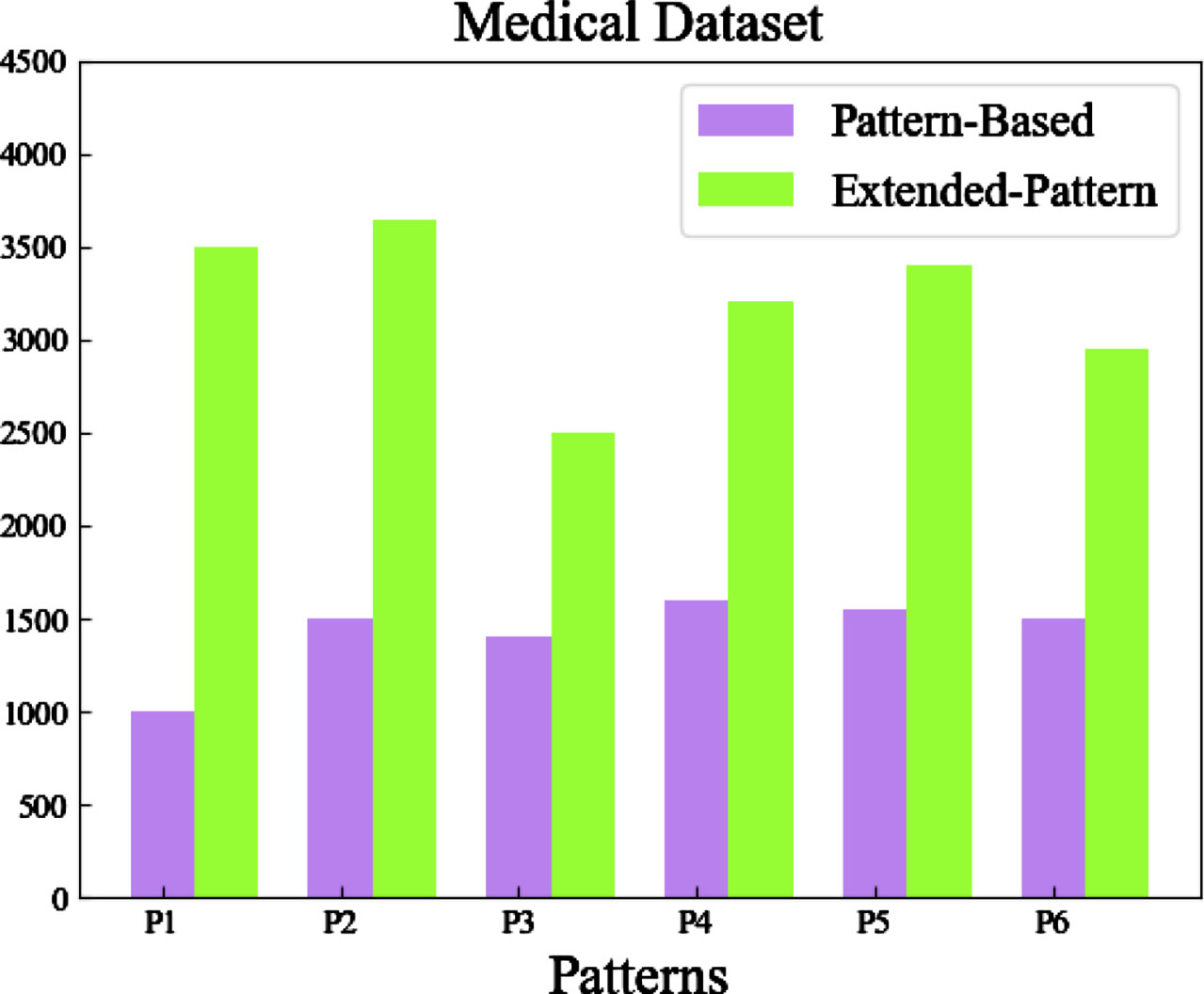
Statistics for hypernymy pairs extracted from Medical dataset.
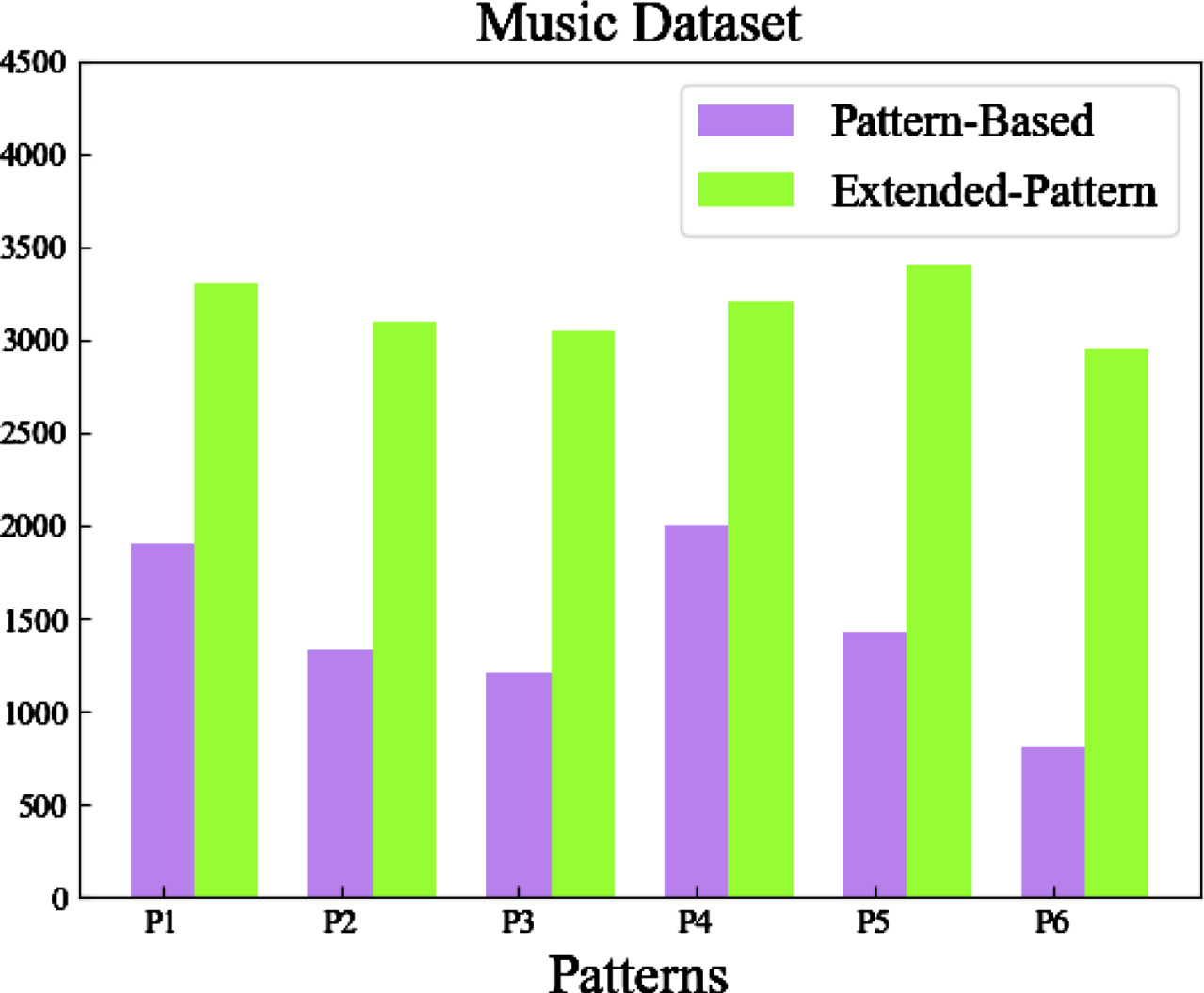
Statistics for hypernymy pairs extracted from Music dataset.
In this subsection, we illustrate the box embedding method we use, which represents entities as points in an n-dimensional Euclidean space, and relations as regions in an n-dimensional Euclidean space.
For a corpus composed of a limited set of words E, obtain the vocabulary C from the corpus, given a word w
i
and the dimension m of word embedding, the model finds the word embedding vector e
i
corresponding to the word w
i
from the word vector set
In the box embedding method, hypernymy relation h is represented as two boxes
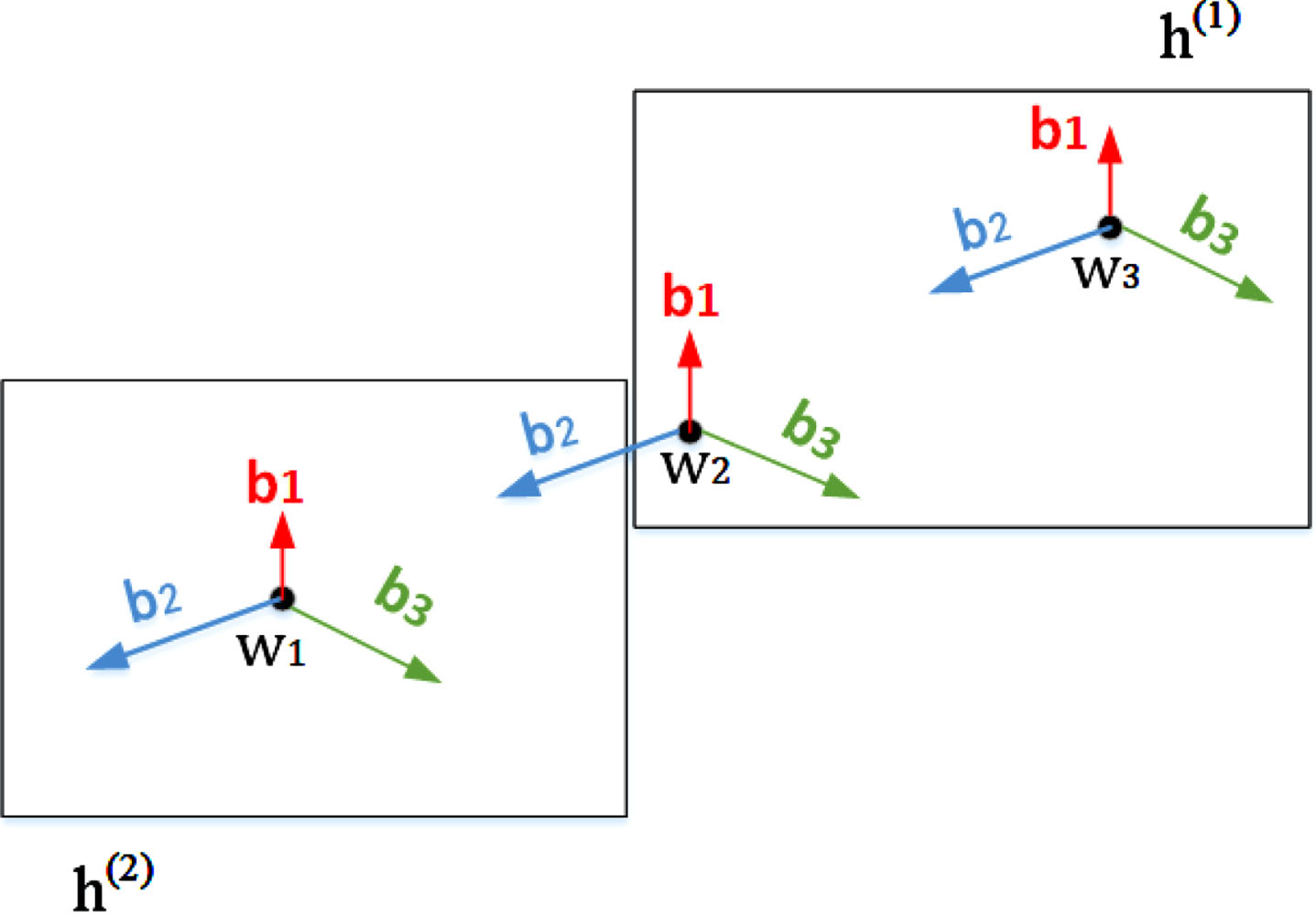
The example of box embedding method.
For the box embedding method, we refer to the scoring function proposed by Abboud et al. [8]. They define a distance function to constrain the position of the entities and their corresponding boxes. If the point corresponding to the entity’s embedding is inside the box, the distance function increases slowly, but if the point corresponding to the entity’s embedding is outside the box, the distance function increases rapidly. This drives the points corresponding to the entity’s embeddings to enter their target boxes more effectively and ensures that the points inside the boxes have smaller changes.
Let
Finally, the scoring function is defined as:
Given the terms and their hypernyms in the training set, we effectively optimize the distance-based model by minimizing the negative sampling loss:
In formula (9), γ denotes a constant scalar margin, f ∈ C
q
is a positive entity,
The proposed EP-BoxE combines unsupervised extended pattern-based method and supervised box embedding method. We select the TopN candidate hypernyms output by each method, normalize their scores and add them together, then re-rank the candidate hypernyms according to the obtained scores. EP-BoxE can effectively utilize the computational capabilities and advantages of both methods, greatly reduce the errors that may exist in a single method, help to find more suitable hypernyms, and enhance the overall recognition ability of the proposed method. Through preliminary experiments, more than 100 candidate hypernyms do not improve the accuracy of the model, so we set TopN=100.
Experimental analysis
Datasets and evaluation metrics
We have assessed the performance of our method using the SemEval-2018 Task 9 [6] benchmark, which focuses on hypernym discovery. This shared task encompasses five different subtasks, encompassing both general-purpose (across multiple languages, including English, Italian, and Spanish) and domain-specific tasks in the fields of Music and Medical. For each subtask, participants are provided with a substantial textual corpus, a vocabulary containing valid hypernyms, and both training and testing sets consisting of hyponyms and their corresponding gold hypernyms. In this paper, we specifically address the two English subtasks:2A(medical), and 2B(music). In Table 2, we summarize their statistics. In this dataset, there are 500 terms in both the training set and the testing set, and 15 terms in the validation set. In most cases, each term has one or more hypernyms. After statistics, in the test sets of the medical and music domains, there are 4116 and 5223 hypernymy relation entity pairs, respectively.
Statistics of the experiment data
Statistics of the experiment data
For all experiments, we evaluate our method and baselines using three metrics: Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), and Precision at k (P@k).
We evaluate our proposed method with the following methods in this paper:
Parameter settings
We train word embeddings on the original corpora provided by the organizers of SemEval2018 Task9, with an embedding dimension set to 300. The original corpora consist of two domains: medical and music. For the Box Embedding method, we utilize the Adam optimizer for training in order to optimize the negative sampling loss. The choice of Adam optimizer is motivated by its effectiveness in handling the complexity of our neural network model. Adam’s adaptive learning rate, momentum, and second-moment estimation capabilities make it well-suited for optimizing the high-dimensional embeddings we are working with. After examining the results on the validation set, we determined the following hyperparameters: a learning rate of 0.001, 100 negative samples, and γ set to 2.
Performance comparison
Tables 3 and 4 present the overall performance comparison of our method with all the baseline methods in terms of MRR, MAP, and P@5. This paper and all baseline methods used the same dataset. From the experimental results, we can draw the following conclusions: The unsupervised pattern-based method we employed ensures higher accuracy by providing contextual constraints. Simultaneously, the supervised box embedding method we utilized effectively learns the anti-symmetry and hierarchy relationships.
Results on the Medical dataset
Results on the Medical dataset
Results on the Music dataset
To investigate the impact of the extended pattern-based method, box embedding method, and their combination on performance, we conducted an ablation study on the proposed method, as shown in Table 5. From the results, we observed that: EP-BoxE integrates the extended pattern-based method and the box embedding method, and the two have slightly different contributions to the model performance. The contribution of the extended pattern-based method to the model is less than that of the box embedding method; In the process of identifying hypernyms, the extended pattern-based method performs poorly, although it performs well on the MRR, but it is lower than the box embedding method in terms of overall accuracy, especially on the Music dataset.
Ablation results
Ablation results
The extended pattern-based method can solve the limitation of the box embedding method in identifying specific hypernyms, as shown in Table 6 (The bold font is the correct hypernym). For instance, the term “vocal jazz” is closely related to the hypernym “jazz”, and their vector representations are in close proximity in the embedding space. Consequently, the final embedding representation of “jazz” may not fall within the hypernym box, resulting in a relatively lower score from the box embedding method. However, the extended pattern-based method solves the deficiency of the box embedding method.
Predict example in Music dataset
As shown in Table 7, the terms in the Medical dataset are all composed of concepts, while the terms in the Music dataset are composed of concepts and entities. Therefore, EP-BoxE is more suitable for finding the hypernyms of concepts in practical applications.
Distribution in test dataset
To investigate the impact of the parameter TopN on the performance of the EP-BoxE method, we conducted a series of experiments. Specifically, we set the values of TopN to [20, 40, 60, 80, 100, 120] to study their effect on the performance of the EP-BoxE method. From the experimental results, it can be observed that when the value of TopN = 100, the performance of EP-BoxE remains essentially unchanged. Therefore, we selected TopN = 100. Figures 4 and 5 displays the experimental results on two datasets. To explore the impact of the constant scalar margin γ on the performance of the BoxE method, we conducted a series of experiments. Specifically, we set the values of γ to [1, 2, 3, 4] to study their effect on the performance of the BoxE method. From the experimental results, it can be observed that when γ is set to 2, the performance of the BoxE method reaches its optimum. Therefore, we set γ to 2. Figures 6 and 7 display the experimental results on two datasets. To investigate the impact of the negative samples k on the performance of the BoxE method, we conducted a series of experiments. Specifically, we set the values to [20, 40, 60, 80, 100, 120] while keeping γ fixed at 2, and studied their effect on the performance of the BoxE method. From the experimental results, it can be observed that when k is set to 100, the precision at 5 (P@5) reaches its optimum value. Therefore, we set the negative sample quantity k to 100. Figure 8 display the experimental results on two datasets.

Effect of parameter TopN on the performance of EP-BoxE.
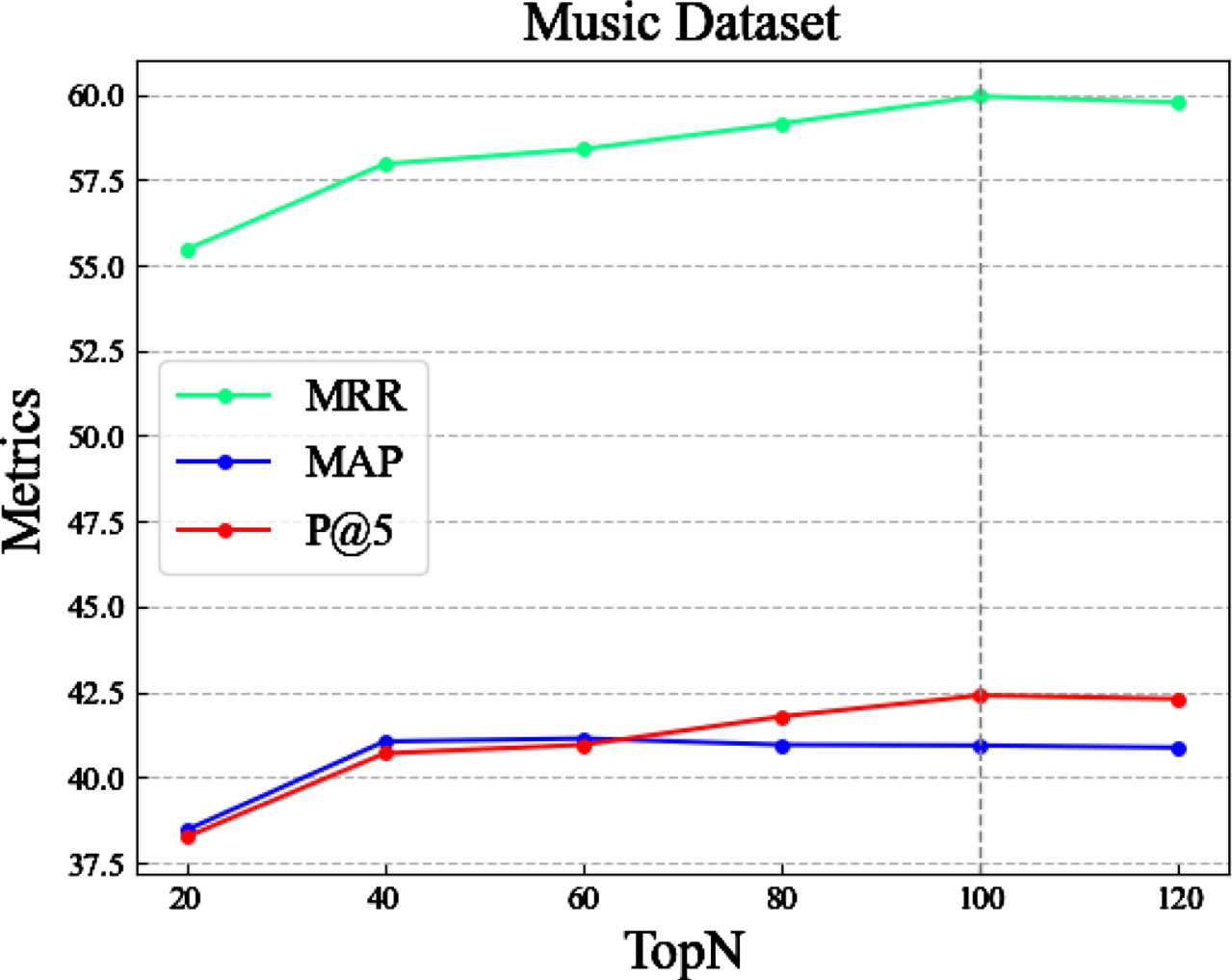
Effect of parameter TopN on the performance of EP-BoxE.
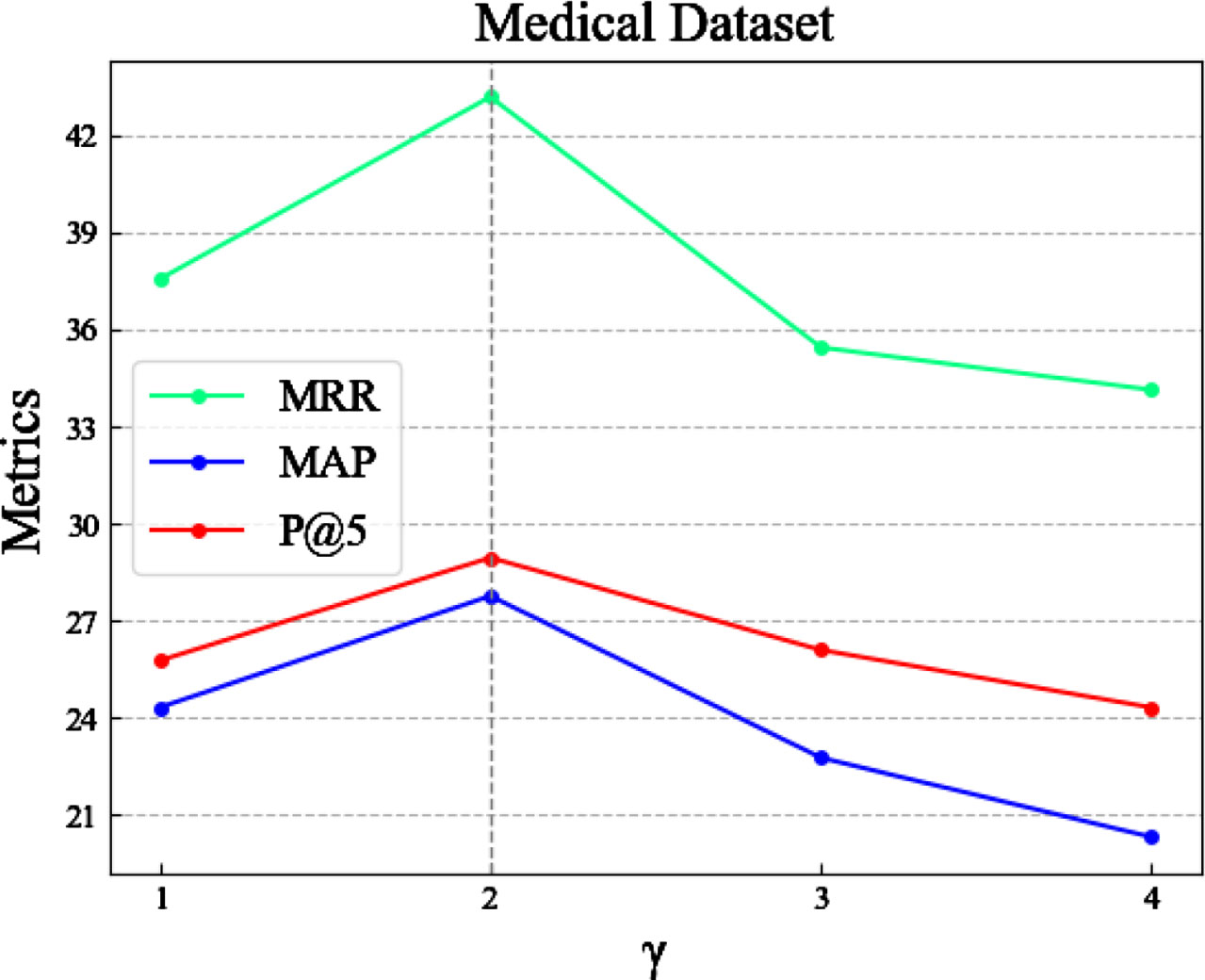
Effect of hyper-parameter γ on the performance of BoxE.
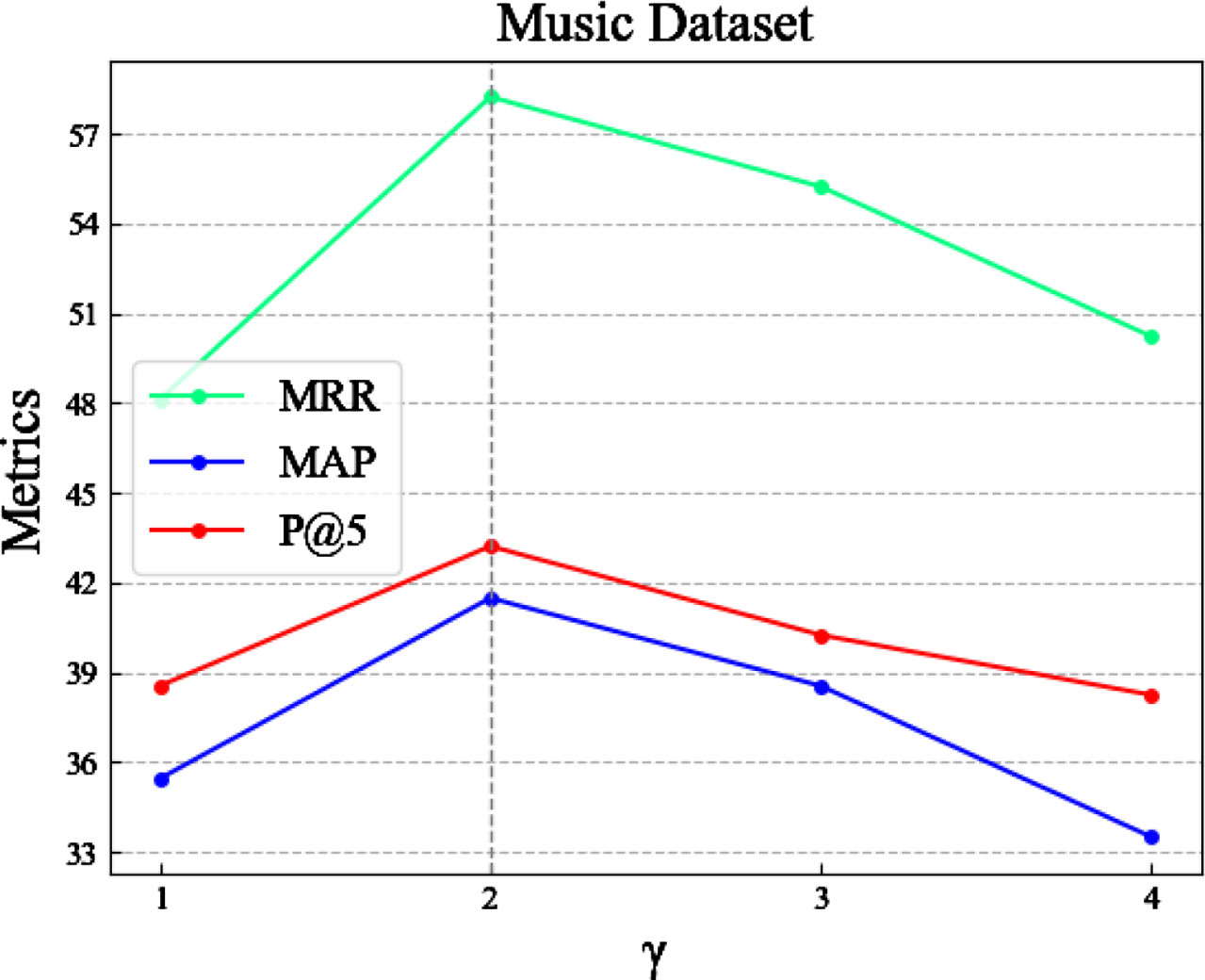
Effect of hyper-parameter γ on the performance of BoxE.
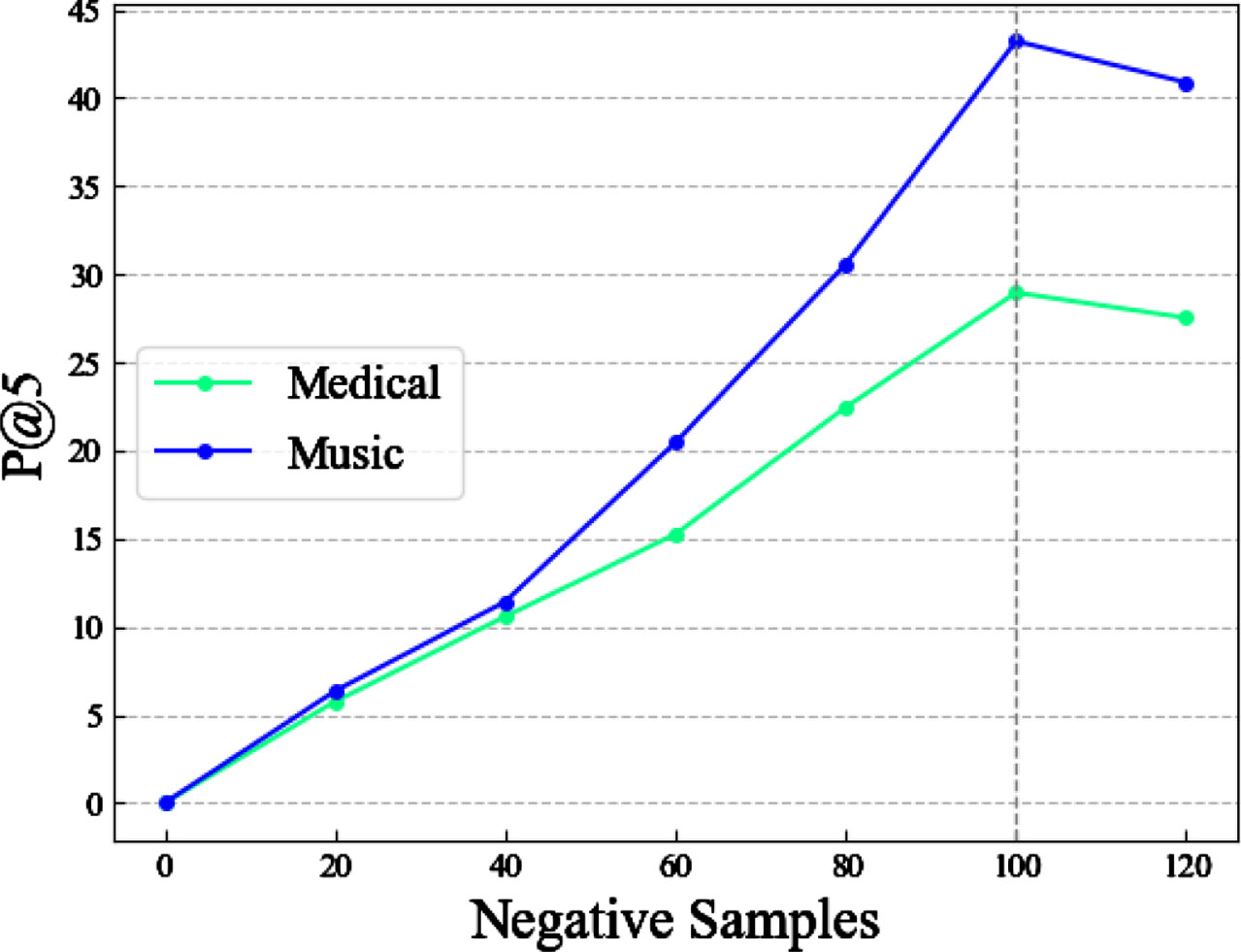
Effect of Negative Samples k on the performance of BoxE.
EP-BoxE provides an effective method for solving the problem of hypernym discovery. EP-BoxE combines an extended Patterns method and a box embedding method. Specifically, in the pattern-based method, we use an extended pattern-based hypernymy discovery method, which effectively improves the coverage of the pattern-based method; meanwhile, by utilizing the linguistic patterns of the terms themselves, we discover some specific hypernyms, which solves the deficiency of the box embedding method in identifying specific hypernyms. we compare the performance of our method on two domain-specific datasets and conduct extensive experiments, and the results demonstrate that our method outperforms the baseline method on most metrics, and we also prove the effectiveness of each component in the ablation tests. However, our approach still has certain limitations. Our study solely concentrated on a specific domain dataset and did not encompass research on datasets in the general domain. Additionally, Our study focused on identifying hypernyms for the term, without exploring the hierarchal relation between hypernyms. At present, in the study of the hypernym discovery domain, Bai et al. [31] are exploring the hierarchical relationship among hypernyms. These issues are deserving of further research in the future.
Footnotes
Acknowledgments
This work was supported by the Science Fund for Outstanding Youth of Xinjiang Uygur Autonomous Region under Grant No. 2021D01E14.