
Abstract
In general, wireless sensor networks are used in various industries, including environmental monitoring, military applications, and queue tracking. To support vital applications, it is crucial to ensure effectiveness and security. To prolong the network lifetime, most current works either introduce energy-preserving and dynamic clustering strategies to maintain the optimal energy level or attempt to address intrusion detection to fix attacks. In addition, some strategies use routing algorithms to secure the network from one or two attacks to meet this requirement, but many fewer solutions can withstand multiple types of attacks. So, this paper proposes a secure deep learning-based energy-efficient routing (SDLEER) mechanism for WSNs that comes with an intrusion detection system for detecting attacks in the network. The proposed system overcomes the existing solutions’ drawbacks by including energy-efficient intrusion detection and prevention mechanisms in a single network. The system transfers the network’s data in an energy-aware manner and detects various kinds of network attacks in WSNs. The proposed system mainly comprises two phases, such as optimal cluster-based energy-aware routing and deep learning-based intrusion detection system. Initially, the cluster of sensor nodes is formed using the density peak k-mean clustering algorithm. After that, the proposed system applies an improved pelican optimization approach to select the cluster heads optimally. The data are transmitted to the base station via the chosen optimal cluster heads. Next, in the attack detection phase, the preprocessing operations, such as missing value imputation and normalization, are done on the gathered dataset. Next, the proposed system applies principal component analysis to reduce the dimensionality of the dataset. Finally, intrusion classification is performed by Smish activation included recurrent neural networks. The proposed system uses the NSL-KDD dataset to train and test it. The proposed one consumes a minimum energy of 49.67 mJ, achieves a better delivery rate of 99.92%, takes less lifetime of 5902 rounds, 0.057 s delay, and achieves a higher throughput of 0.99 Mbps when considering a maximum of 500 nodes in the network. Also, the proposed one achieves 99.76% accuracy for the intrusion detection. Thus, the simulation outcomes prove the superiority of the proposed SDLEER system over the existing schemes for routing and attack detection.
Keywords
Introduction
Wireless sensor networks (WSNs) are essential to today’s enormously dispersed infrastructures, such as the intelligent and cognitive environments, the internet of things, environmental monitoring networks, and vehicular and mobile ad hoc networks [1]. WSNs are currently used in various industries, including monitoring the ecological environment, military operations, medical care, transportation, and urban land use. WSNs have drawn the interest of numerous academics in recent years due to their extensive use [2]. To interpret, gather, and monitor events, WSNs comprises sensors and sink nodes operating in a network of ad hoc nodes. The nodes collectively communicate sensor data for variables like temperature and humidity [3] to a central point known as the sink or target node [4, 5] by sensing physical and physiological characteristics in the area where they are deployed. The limited power and processing capabilities of sensor nodes during transmission limit the applications and diminish the lifespan of WSNs [6]. Typically, once WSNs have been set up in the environment, their sensors have limited power and cannot be changed. As a result, energy is the most essential resource in WSNs, and energy-efficient methods can prolong their lifespan. Determining how to use limited resources effectively, perform load balancing across nodes, and prolong the network’s lifespan as much as feasible is a significant challenge in WSNs [7].
Clustering provides an energy-efficient method for prolonging the lifespan of WSNs and maximizing resource utilization [8, 9]. Clustering divides a sensing region into small sectors; it assists nodes in evenly distributing the workload among all server nodes, and one of the nodes is designated as the ‘Cluster Head’ (CH). The CH is responsible for collecting the information from the remaining cluster members, and the information gathered is sent to the base station or sink node via the chosen CH [10-12]. The sink node creates the schedules for time division multiple accesses and notifies the CH for communication. The CH node additionally generates time-division multiple access schedules for transmitting the data from the sensor node [13]. Existing methods for choosing the CH make this decision using a variety of factors, including topology information, maximum residual energy, CH area about alternative nodes, and SN’s previous movement as a CH [14]. Most of these CH selection techniques are designed to reduce nodes’ energy consumption. However, these techniques must consider the network’s necessity for full inclusion over long intervals [15]. As a result, the suggested system employs a practical clustering approach to group nodes into clusters, and an optimization algorithm is used to select the CH in the most energy-efficient manner that also prolongs the network’s lifespan.
However, the intrusion detection system (IDS) is the primary cause of WSNs security vulnerabilities. Attackers use a variety of methods to turn off WSNs capabilities. Because it is not always possible to prevent or lessen security concerns, IDS is crucial for detecting new attacks and alerting nodes [16]. With the increase in the database, efficiency is brutal to ensure. Therefore, implementing detection quickly and efficiently is a highly demanding task [17]. Deep learning (DL) and machine learning (ML) methods are now being utilized to detect intrusions in WSNs. ML and DL effectively extract essential features from network traffic data and identify regular and irregular actions based on discovered patterns [18]. ML techniques are mainly used to develop error-free models designed and constructed for classification and prediction. ML approaches such as logistic regression, support vector machine (SVM), and random forest (RF) are typically used to predict any malicious attack in WSNs [19]. However, due to their scattered nature, they have restricted access to data for analysis. As a result, ML models trained on certain parts of the network cannot detect intrusions throughout the entire network [20]. DL-based detection methods are suitable for mitigating these issues.
When it comes to working with large and complex data, handling non-linear relationships, working with unstructured and structured information, forecasting, handling missing data, interacting with sequential data, adaptability, and generalizing capacity, DL offers many advantages over ML. Additionally, DL models offer WSNs improved intrusion detection results with reduced errors and increased accuracy. These advantages spur us to create an efficient DL-based system for identifying network intrusions in WSNs. In recent years, more researchers have been focused on finding out the intrusions in the network and for energy-efficient data transmission [21-33]. However, the researchers either focus on energy-based routing or intrusion detection in the network. It is necessary to maintain the network’s security to prevent intruders while also considering the network’s lifetime and quality of service. Unfortunately, the existing models have failed to focus and develop a system which addresses both significant challenges of WSNs. So, the current study focuses on developing a system which focuses on quality of service and security of the WSNs. The suggested system uses classification, dimensionality reduction, cluster head selection, and efficient cluster formation techniques. Many strategies improve each of these approaches, which helps prolong the overall network lifetime of the network to a greater extent and minimizes energy consumption. The proposed configuration of WSNs fulfils the need for security and performance regarding detection metrics and energy preservation. The main objectives of the proposed work are as follows: We are employing density peak k-mean (DPKM) clustering to form the cluster of nodes that enhances the lifespan of WSNs by providing higher energy efficiency in sensor nodes. Utilizing pseudo-random chaotic sequence with a levy flight-based pelican optimization algorithm (PLPOA) for optimal selection of CH minimizes the network’s energy consumption and enhances the lifetime and reliability of the network. We are utilizing principle component analysis (PCA) to reduce the dimensionality and irrelevant features from the dataset. The dimensionality reduction process also avoids the problem of overfitting in the classification network and speeds up the prediction process. Employing Smish activation included recurrent neural networks (SARNN) for detecting several kinds of network intrusion with higher accuracy, in which the gradient vanishing problem of the classifier is solved using the Smish activation function for improving its performance.
The remaining section of the manuscript is arranged as follows: a survey of recently published works in our research domain is presented in section 2. Section 3 defines a brief explanation of the proposed system. Section 4 investigates the proposed work with existing methods based on evaluation indicators. Lastly, section 5 concludes the proposed work with future directions.
Literature survey
This section reviews the recent works related to the energy efficient data transmission and attack or IDS in WSNs.
N. M. Saravana Kumar et al. [21] recommended an energy-efficient secured data transmission in WSNs using an ML-based hybrid model. The sink node received the node’s data and transmitted it to the one-hop neighbor for node verification. It checked the sequence and sender identifier numbers of each node transmitted to the sink and updated them in a sequence table. Finally, the system performed packet redistribution of the reliable nodes using an ML model for sending the packets to the destination. The system attained an improved performance packet drop ratio of 90%, and the network’s lifetime was increased to 50%, with energy lower than 3% than the existing works. S. Muruganandam et al. [22] suggested IDS for WSNs using a feed-forward artificial neural network (FFANN). When the k-barriers were appropriately integrated, Monte Carlo simulations were used first to acquire the area, the node’s sensing range, the transmission area, and the many sensor node attributes. Using feature significance analysis, an ensemble of regression trees was used to determine the relevance of each feature. After feature preprocessing, the intrusions were detected using FFANN. The system discovered that the approach accurately predicted the number of barriers with an RMSE of 6.15, demonstrating that system was more effective than the other traditional methods.
S. Rameshkumar et al. [23] introduced a denial-of-service attack detection mechanism in WSNs using a transfer learning-based deep Q Network (DQN). Once the nodes were deployed in the network, their threshold round trip delay (RTD) was compared, which helped to attain reliable network communication. The malicious node’s detection time was affected by the secondary round trip path (RTP) and RTD numbers. The nodes displayed malicious behaviour by duplicating identities and generating fault data. Therefore, it was essential to reduce the detection time for RTP and RTD time measurement and evaluation, and the DQN approach was used to identify DDOS attacks in the network. The system attained a detection accuracy of 89% and a transmission ratio of 95%, which was better than existing ones. Mohit Mittal et al. [24] presented the levenberg-marquard neural network and gated recurrent unit (GRU) based low-energy adaptive clustering hierarchy (LEACH) protocol for secure end energy efficient routing in WSNs. Initially, the LEACH selected the CHs for transmitting the node’s data to the base station based on the node’s energy and distribution proximity. Once the chosen CHs formed clustering, the shortest route to the sink node for each CH was computed using the Dijkstra algorithm. The nodes’ data was aggregated and sent to the base station via the selected shortest paths. The GRU finally updated the list of remaining nodes for the next round. If the last node in the network died, there would be no more rounds; otherwise, it would continue until the previous node died. According to the findings, the system had the highest detection rate of 97.84%.
PoojaGulganwa and Saurabh Jain [25] presented an ML-based, energy-efficient, secure clustering scheme for WSNs. Initially, an energy-efficient weighted clustering algorithm was utilized to cluster the nodes in the network to minimize the network’s energy consumption. Then at the base station, the network traffic was analyzed using multilayer perceptron and SVM to identify the malicious nodes in the network. The method attained a 90% detection rate in malicious behaviour detection, which was satisfactory. V. Gowdhaman and R. Dhanapal [26] proffered deep neural network-based IDS for WSNs. The data of the collected intrusion dataset was preprocessed, and optimal features were selected using a cross-correlation approach to train the network. Finally, the optimal features were given to the deep neural network for detecting several attacks in the network. The system achieved the maximum accuracy of 95.5% for attack detection when testing on the NSL-KDD dataset. Gaurav Kumar Nigam and ChetnaDabas [27] presented an optimal cluster-based routing mechanism for WSNs. The system initially selected the optimal CH to gather the data from the nodes using particle swarm optimization. Then the LEACH was utilized to form the clusters in an energy-aware manner, and the sensor’s data was sent to the sink node. The simulation result of the system showed that the first hub’s total energy depletion occurred around the 650th round and that nearly all hubs lose all of their vitality when the network has completed around 1000 rounds, which was superior to the previous approaches.
Tanya Sood et al. [28] recommended an ensemble of DL frameworks for IDS in WSNs. The collected from the NSL-KDD and CICIDS2017 datasets initially underwent preprocessing to improve the data quality. The dimension of the preprocessed dataset was removed using the conditional generative adversarial network. Finally, the eXtreme gradient boosting classifier was utilized for ID. The method attains higher detection accuracy and lower false alarm rate for both tested datasets. Jeng-Shyang Pan et al. [29] developed smart IDS using a compact sine cosine algorithm and k-nearest neighbor (kNN) for WSNs. The system collected the data from NSL-KDD and UNSW-NB15 datasets. An optimal feature set was chosen from the collected dataset using CSCA, which improved the computational time and space of the classification. The sine cosine model was designed with a polymorphic mutation mechanism that helps to attain higher accuracy. Finally, the selected features were given to kNN to detect several network attacks. The method achieved better prediction accuracy with a lower false alarm rate of 0.5848% and 5.82% for both datasets.
S. V. N. Santhosh Kumar et al. [30] presented a secure and energy-efficient data transmission model for WSNs. Initially, the private and public keys were generated and installed in the nodes using the base station before their deployment in the network. Then clustering and CH selection were done using the intelligent fuzzy rule-based clustering scheme. The node’s data were transmitted from the CH to the sink via the optimal paths. During the packet transmission phase, CH constructed, signed, and sent packets to receptive cluster nodes. During the receiver verification step, the cluster nodes confirmed the received packet using their public key. The nodes were updated if the verification was successful; otherwise, the received packets were dropped from the network. The simulation outcomes revealed that the system employed less energy, with an average consumption of 58.21 j.
Gaoyuan Liu et al. [31] recommended an improved k-nearest neighbor (kNN) model for detecting intrusions in WSNs. Initially, an arithmetic optimization algorithm was utilized for detecting the intrusions, and then kNN was utilized to classify the detected intrusions. The system attained an accuracy of 99% in the Kaggle dataset, which was better than previous models. Abhilash Singh et al. [32] proposed IDS in WSNs using an automated machine learning (AutoML) model. The system’s potential predictors—the region’s area, the sensor’s sensing range, and the communication range were artificially extracted using Monte Carlo simulation. The regression tree ensemble approach was then used to assess the predictor sensitivity and importance. The system then detected the intrusion using AutoML on the training datasets. With a lower root mean square error (RMSE) of 30.59, the system outperformed the publicly accessible intrusion dataset, according to the findings. Robust node localization with intrusion detection was introduced by R. Punithavathi et al. [33] for WSNs. There were two main phases to the system. Initially, the manta ray foraging optimization (MRFO) algorithm was used to locate the nodes. Subsequently, the optimal Siamese neural network was utilized for intrusion detection, with the hyper parameters selected optimally through the application of the MRFO algorithm. The KDD Cup 99 dataset was used for experimentation, and the system’s maximum accuracy was 0.921%.
Problem statement
As seen from the research mentioned above, many existing research studies on WSN utilize clustering, CH selection and routing mechanisms to send the sensor data to the sink. They provide efficient results but also come with the following limitations. Initially, cluster formation is essential because clustering offers more advantages such as load balancing, lower energy usage, resource reusability, and increased network lifetime. Some research uses the conventional LEACH [24, 27] technique, a dual-layer system utilized for task allocation that allocates the load equitably across the nodes. This method performs the CH selection process arbitrarily, which minimizes the node’s remaining energy. So, the selected CH nodes might have the least energy and suffer to die quickly. It is not appropriate for use in a large network region. Furthermore, CH selection is an essential phase in clustering since it has a significant responsibility in WSNs for effectively transmitting and aggregating data. Some work chooses CH randomly from the cluster of nodes [30], but it predominantly affects WSN’s lifetime. The dimensionality reduction is an essential step in IDS. Dimensionality reduction helps in IDS by reducing features and removing redundant features. It reduces storage. It makes machine learning and deep learning algorithms computationally efficient. On the other hand, IDS plays a vital role in detecting and preventing security attacks on WSNs. The primary benefit of IDS is to notify when an attack or network intrusion occurs. Some of the algorithm mentioned above uses the ML approach for IDS [21, 32], which provides efficient results and reduces false positive rates of IDS. However, to deal with a vast amount of data, the traditional ML techniques take a long time to learn and classify data and the time requirement of IDS based on ML models is much higher. Most authors recently used DL approaches for IDS [22, 33]. However, it suffers from the vanishing gradient problem, which is a phenomenon that occurs during the training of DL, where the gradients that are used to update the network become extremely small or “vanish” as they are back propagated from the output layers to the earlier layers. The DL mentioned above did not focus on these problems, so the efficiency of these methods could be higher.
To mitigate these issues, this paper uses a DPKM algorithm to form the group. From that, optimal CH was chosen using PLPOA, which prolongs the network’s lifetime by considering the energy and distance of the nodes from base station. In addition, the proposed uses an efficient dimensionality reduction model called principal component analysis for removing irrelevant data from the dataset, which improves the prediction performance of the classifier by avoiding overfitting issues. Furthermore, the proposed system uses a novel DL approach with the Smith activation function to solve the vanishing gradient problem. These novelty algorithms, the proposed system, come with security and energy efficiency in network data transmission, which are explained in detail in the following section.
Proposed methodology
This paper proposes an SDLEER mechanism for WSNs. The proposed system involves two phases such as optimal cluster-based energy-aware routing (OCEAR) and DL-based IDS. In the OCEAR phase, the cluster of nodes is formed initially with the help of the DPKM clustering algorithm. After that, the CH selection is done using PLPOA. At last, the data are routed to the optimal CH to the sink. This OCEAR enhances the lifespan of the network by maintaining energy efficiency. Next, in the IDS phase, the data are gathered from the publicly available NSL-KDD dataset. Then, the preprocessing such as missing values imputation and normalization is carried out on the collected dataset. After that, the dimensionality reduction is performed using the PCA approach. Finally, the network attacks are detected using SARNN. The proposed method’s structural framework is shown in Fig. 1.
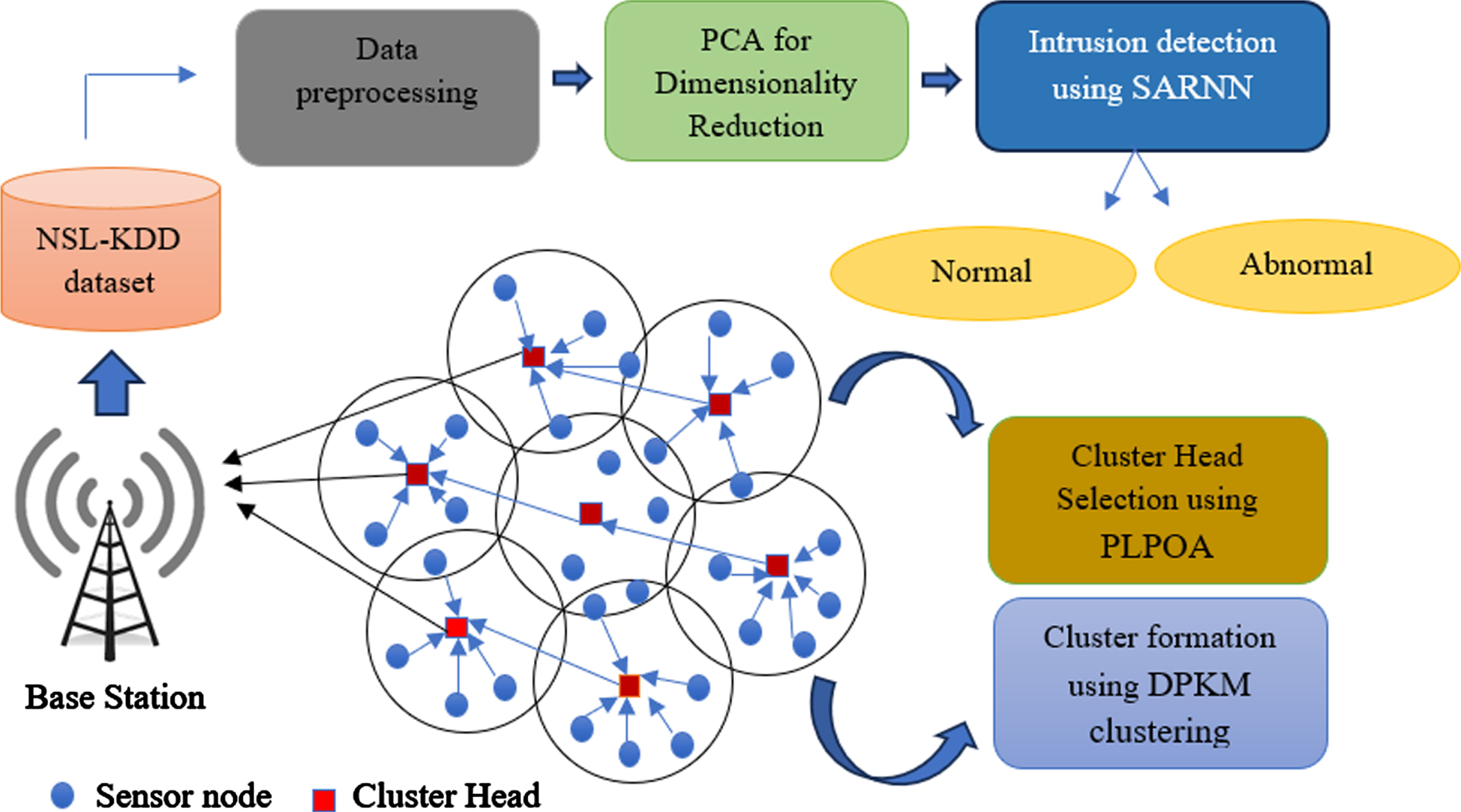
Structural design of the proposed methodology.
To begin, the nodes in the network are randomly distributed among various regions. The base station is aware of each node’s location as well as the coordinates of each area. After identifying the nodes in each area, sink notifies each node in every region to form a cluster. After optimal CH is selected, the data is sent to the sink from the optimal CH. This mainly involves two phases such as cluster formation and CH selection, and these are briefly explained as follows:
Cluster formation
Initially, the cluster formation is done using the DPKM to cluster the network of nodes energy-efficiently. The k-means clustering algorithm is presented as one of the simplest unsupervised learning algorithms that solve clustering problems. It is a heuristic and proved influential in determining clusters of spherical shapes. It was applied to partition a network into a number of groups. It classifies a given data into a predefined number of clusters, k and its main idea is to define k centroids, one for each cluster. It forms the clusters of the nodes in the network based on the Euclidean distances between them. The k-means algorithm is easy to use, interpret, and computationally efficient. K-means techniques, on the other hand, choose the initial centroid at random, and the final cluster is solely based on the initial centroid. This has an impact on the cluster’s computational time and accuracy. Finding the initial centroid is an essential problem in the k-means model for forming the network clusters. As a result, the suggested approach employs density peak to acquire the initial clustering centers to address the issue that k-means is sensitive to the initial centers. Thus, the density peak based initial cluster center selection in the conventional k-means is termed DPKM and the steps involved in the DPKM are explained as follows:
Where, ν
mn
indicates the distance between data point mand n, γ
m
refers to the minimum distance between point m and any point having higher local density, ν
cd
denotes the cutoff distance that are described as the top 1–2% value of all ν
mn
. When point mis the global density peak, γ
m
is the maximum value of allν
mn
. The decision graph is constructed using normalized
Where,
Where,
CH selection is an essential step in clustering because it transfers and aggregates data in WSNs. The proposed system uses PLPOA to select the optimal cluster leaders for aggregating the data from the clustered nodes. The pelican optimization algorithm is a new heuristic algorithm that mimics the pelican’s natural behaviour during the hunting phase. The world’s warm waterways are home to pelicans, which primarily inhabit lakes, rivers, beaches, and marshes. Pelicans typically live in groups and have excellent swimming and flying abilities. They mainly eat fish and have good observational skills and keen eyesight while flying. Once the pelicans have located their prey, they rush it from a height of 10 to 20 meters before diving headfirst into the ocean to begin their hunt. The two stages of a pelican’s hunting process are exploration and exploitation. It provides efficient solutions for complex optimization problems; the typical pelican optimization, on the other hand, has issues with early convergence, getting stuck in local optima, failing to maintain a good balance between local search and global search, and not always converging to the optimal global solution. To mitigate the limitations, the population evolution’s convergence speed is significantly accelerated in this study using the pseudo-random chaotic sequence (PRCS) initiation approach. In addition, the proposed system uses the Levy flight mechanism to update the pelican optimization position and avoid local optimal issues. These two incorporations in conventional pelican optimization are named PLPOA. The process involved in the BLPOA algorithm is explained as follows:
Where,
Where, β refers to the weighting variable, DT s and EN y indicates the distance and residual energy and they are calculated as follows:
In this distance calculation(DT
s
), two distances are computed, i.e., average distance between CH and sink and the average distance between the CH and nodes. It is shortly described as follows: Average distance between the CH and sensor nodes
This metric represents the distance betwixt all the sensor nodes (SN
j
) and each CH (CH
j
) in the formed cluster, which is computed as:
Where, J indicates the total number of nodes and h-refers to the number of CH. Average distance between CH and base station
This metric represents the average distance between the base station (BS) and each CH (CH
j
) in the clustered WSNs, which is computed as
The Equations (7) and (8) are merged to build Equation (9), indicated as the total distance DT
s
between the nodes and CH and CH and base station. The objective is to choose the node as the CH, which has a minimum distance with nodes and sink. So that only the amount of energy is reduced while performing data transmission.
The total amount of current energy the sensor node has is referred to as its energy level (EN
y
). Due to the fact that each node uses some energy when transmitting data, the goal is to minimize the energy utlization of the network while sending the data from one end to another end. So, choosing the CHs from nodes with higher energy than other nodes is crucial. It is expressed as follows:
During this stage, the pelican finds its prey and dives down to it from a high height. The prey’s random distribution enhances the capacity of pelicans to explore the search space, and the location of pelicans at each iteration is updated as follows:
Where, δ indicates a current iteration number,
Where, ϑ (0 < ϑ ≤ 2) refers to an index, σ indicates the step size,
When pelicans reach the water’s surface, they spread their wings to push the fish into shallower waters, which make it simpler for them to catch their meal. Equation (14) is a mathematical representation of this behaviour.
Where, M
δ
indicates a maximum number of iterations, δ refers to a current number of iterations, the neighborhood radius of

Pseudocode of the PLPOA.
The data is gathered from the remaining SNs via the optimal CHs and they route the data to the base station for attack detection purposes.
At the sink, the system performs the attack detection mechanism using a DL model to identify the kinds of intrusions in data transmission in the network. An attack detection model is required to detect known and unexpected threats and alert nodes about them. When an intrusion occurs, IDS can detect suspicious or abnormal activities and send a warning. Here, the system performs training using the NSL-KDD dataset to identify the network attacks in data transmission. The training process consists of ‘3’ steps such as preprocessing, dimensionality reduction, and classification, which are deeply explained as follows:
Preprocessing
In this initial stage, the dataset is preprocessed, which helps in reducing the time and effort required to preprocess data, thus increasing the efficiency of the IDS. Herein, the proposed system performs missing value imputation and normalization on the collected dataset to reduce the time complexity of the system and improve the data quality. It is shortly described as follows:
The common problem in the NSL-KDD dataset is the data of missing values, and imputation is the process of replacing these missing values with estimated values based on other available information. Herein, the proposed system uses mean imputation method to manage the dataset’s missing values. One of these strategies involves calculating the mean of the observed values for each variable and then using that mean to impute the missing values for that variable.
Normalization is required when we have a massive dataset with thousands of rows in the training and testing files. In this study, the dataset is normalized using the min-max normalization approach. One of the most used techniques for normalizing data is min-max normalization. For each feature, the minimum value is converted to a 0, the maximum value is converted to a 1, and all other values are converted to a decimal between 0 and 1. The mathematical form of min-max normalization is given in Equation (15).
Where, Min
M
ax denotes the min-max normalized data,
The higher dimensions of the data have been reduced into lower dimensions for classification to increase the system’s computation efficiency while maintaining classification accuracy, which also avoids irrelevant features from the dataset. PCA is used in this study to convert higher-dimensional data into lower-dimensional ones. PCA is one of the most fundamental methods for dimensionality reduction, which may be used to extract useful features from input data vectors with large dimensions. It reduces many possibly associated variables to a smaller set of uncorrelated or principal components. The count of principal components is lower than that of initial dataset variables. The principal components, or design vectors, are attained by decomposing the data’s covariance matrix. The features are normalized before the process of decomposition of the covariance matrix’ Eigenvalues. The features are normalized before the process of decomposition of covariance matrix’ Eigenvalues. Let assume that a preprocessed dataset
Where, NT
s
refers to the number of samples in dataset and
Finally, the intrusion classification is performed from the dimensionality-reduced dataset using SARNN. Recurrent neural network (RNN) is a DL strategy that can extract features and long-term dependencies from time-series and sequential data. The model have input, hidden, and output units and consists of a one-way information flow from the input units to the hidden units and a synthesis of the one-way information flow from the previous temporal hidden unit to the current timing hidden unit. The primary and most crucial feature of the network is their hidden state, which preserves some information about a sequence. Memory state is another state that allows the network to recall prior input. It employs the same parameter settings for each input because it produces the output by carrying out the same procedures on all inputs or hidden layers.
Contrary to other neural networks, this decreases the complexity of the parameter set. However, the network has a problem called the vanishing gradient during backpropagation. Introducing an efficient activation function solves these issues. Still, the traditional activation functions are relatively time-consuming, increasing model complexity and making it hard to solve the gradient vanishing problem. Henceforth, the proposed system uses a Smish activation function that provides higher learning accuracy compared with other activation functions and solves the gradient vanishing problem efficiently. Thus, the Smish activation function included in the RNN is named SARNN and its architecture is shown in Fig. 3.
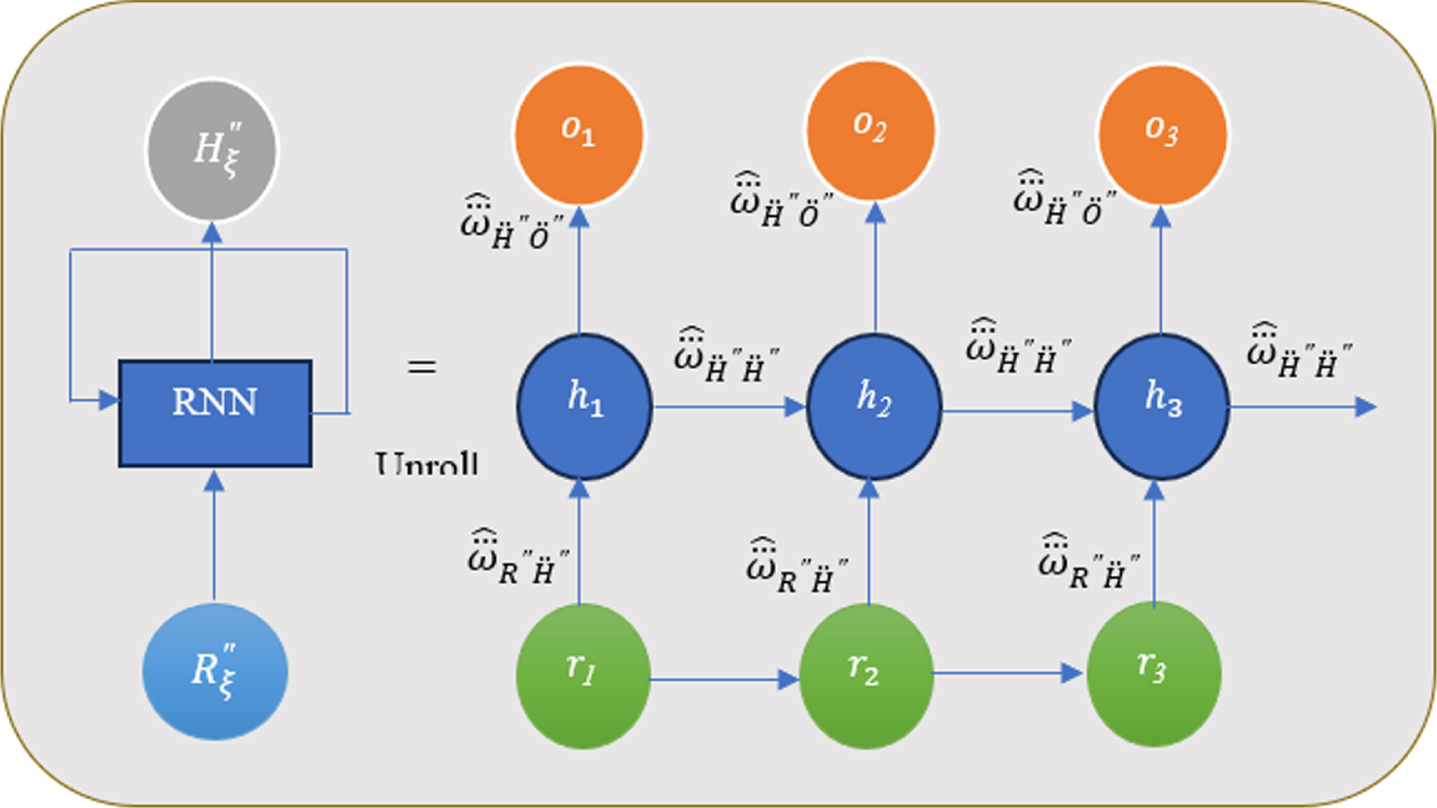
Architecture diagram of SARNN.
Figure 3 mainly includes three units such as input, hidden, and output units. Let us take the input dimensionality reduced data as R″ ={ r″1 , r″2 , r″3 , . . . . . . r″
ξ
} for time ξ. Then, the inputs are passed to the hidden units. The past knowledge of the network at a given time step is indicated using the hidden unit. So, for each time step, the hidden unit is updated to signify the network’s knowledge change about the past. The calculation of hidden units is defined in Equation (19).
Where,
Where, κ and ϖ refers to the values of 1. Finally, the output is detected by using the following equation.
Where,
This section discusses the simulation outcomes of the proposed SDLEER mechanism and existing methods in terms of network evaluation indicators. The proposed system is implemented in the network simulation (NS2) tool and prepared with random mobility to demonstrate the sensor nodes, which is shown in Fig. 4(a) and (b) shows the clustering and CH selection outcomes attained by our proposed system. The simulation parameters of the current study are given in Table 1. The sensor data of the clustering nodes are sent to the sink in an energy ware and secure manner. Then at the sink, the network attacks during data transmission are identified via the DL-based IDS. The dataset used by the proposed system to train and test the IDS is given in Section 4.1, and the outcome analysis of the proposed and existing works is given in Section 4.2.
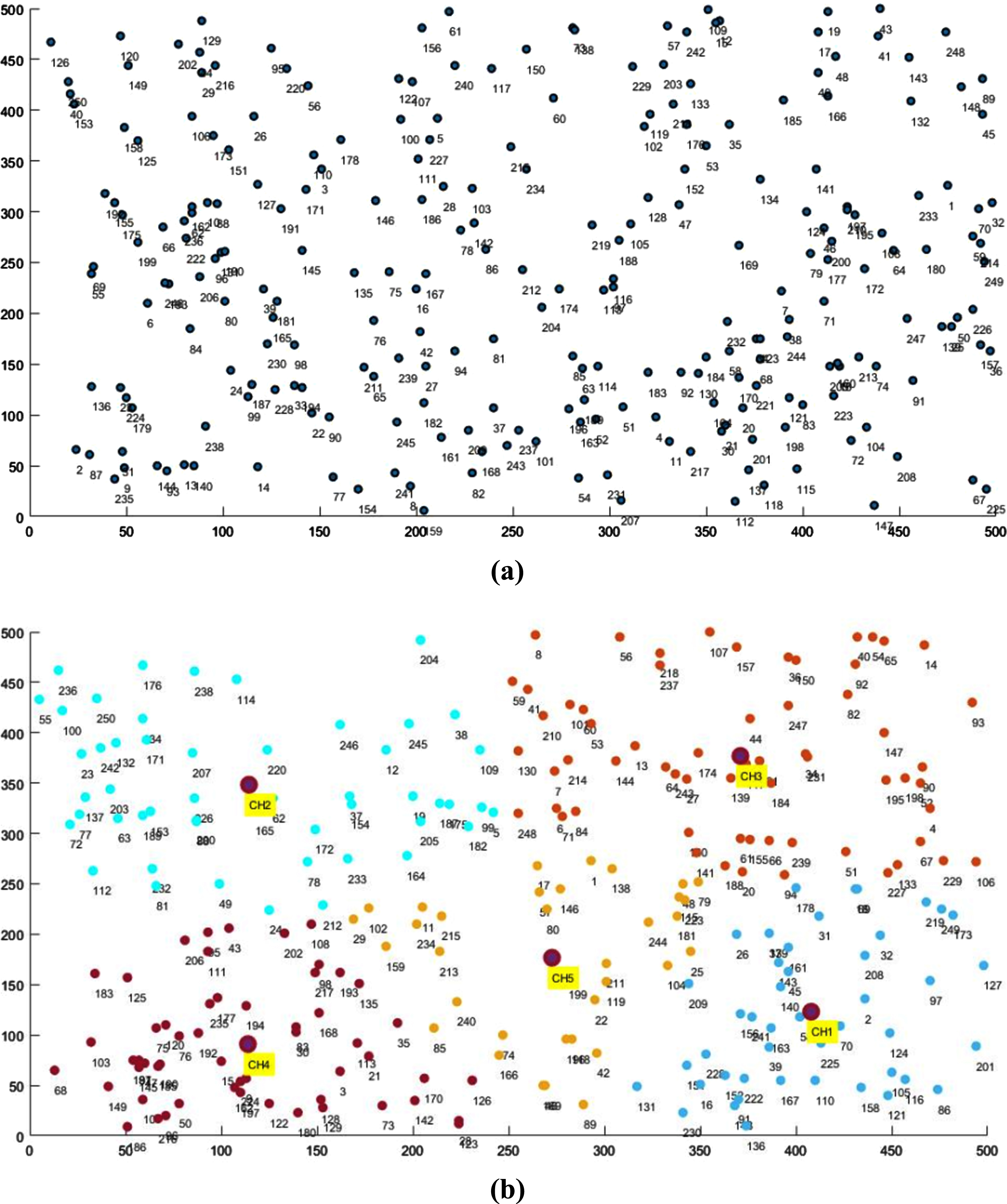
Network model of the proposed system.
Simulation parameters of the proposed system
The performance of the proposed work is examined using the NSL-KDD dataset. Researchers can use this benchmark data set to compare various ID strategies effectively. The NSL-KDD dataset is sufficient to make it possible to use the entire dataset without the need for random sampling. The dataset’s attack types can be divided into four main categories: DoS, U2 R, Probe, and R2 L. Apart from the four categories, the remaining data is labeled normal. The four categories are used to organize 39 attacks, and rather than detailing each attack individually, each attack is mapped into the corresponding group. Attacks are classified as “1” for probe categories, “2” for DoS categories, “3” for U2 R categories, “4” for R2 L categories, and “5” for the remainder of the normal data. Among the many attacks, 41 features—including basic features, content features, and traffic features—are gathered into three distinct groups. There are 33 continuous features and seven discrete features among the obtained features, which are classified into discrete and continuous attributes. The training and testing samples of the system is shown in Table 2.
Training and testing samples of the NSL-KDD
Training and testing samples of the NSL-KDD
In this section, the outcomes of the OCEAR are contrasted to the existing well-known optimization schemes such as whale optimization algorithm (WOA), grey wolf optimization (GWO), particle swarm optimization (PSO), and LEACH methods to analyze its routing capability in WSNs. The evaluation uses energy consumption, packet delivery ratio, lifetime, delay, and throughput by ranging the nodes from 100 to 500.
Table 3 demonstrates the outcomes of the proposed and existing WOA, GWO, PSO, and LEACH methods regarding energy usage, delivery rate, and lifetime metrics for 100 to 500 nodes. First, considering the energy consumption, the proposed one consumes lower energy for all nodes ranging from 100 to 500 than the existing algorithms. It is noted that the amount of energy consumed by the proposed OCEAR and the existing WOA, GWO, PSO, and LEACH is 22.78mJ, 29.71mJ, 43.01mJ, 56.42mJ, and 64.85mJ for 100 numbers of the sensor node. Here, the proposed one consumes less energy. When the node count increases, the energy usage of the network also increases. However, energy consumption could be much higher in the proposed OCEAR than in existing algorithms.
Results analysis of the proposed methods
Results analysis of the proposed methods
Next, considering packet delivery ratio, the OCEAR methodology illustrates superior outcomes under all nodes. For example, with 100 nodes, the OCEAR model achieved a higher delivery ratio of 96.86%, whereas the WOA, GWO, PSO, and LEACH techniques achieved lower throughputs of 93.87%, 89.08%, 87.35%, and 84.41%, respectively. Eventually, with 500 nodes, the OCEAR approach reached a higher delivery rate of 99.92%, while the WOA, GWO, PSO, and LEACH techniques resulted in lower throughput of 96.85%, 92.48%, 90.54%, and 87.79%, respectively. Similarly, considering the lifespan of the network, the proposed one has a maximum lifetime for the nodes 100 to 500. Herein also, the proposed OCEAR has 5924 rounds 100 nodes which are high when analogized with the prevailing methods. Similarly, for the remaining number of SNs (200 to 500), the proposed one has a higher lifespan than the existing methods. Thus, the proposed OCEAR performs better for cluster-based energy-aware routing in WSNs than the existing methods. The graphical representation of the Table 3 is shown in Fig. 5.
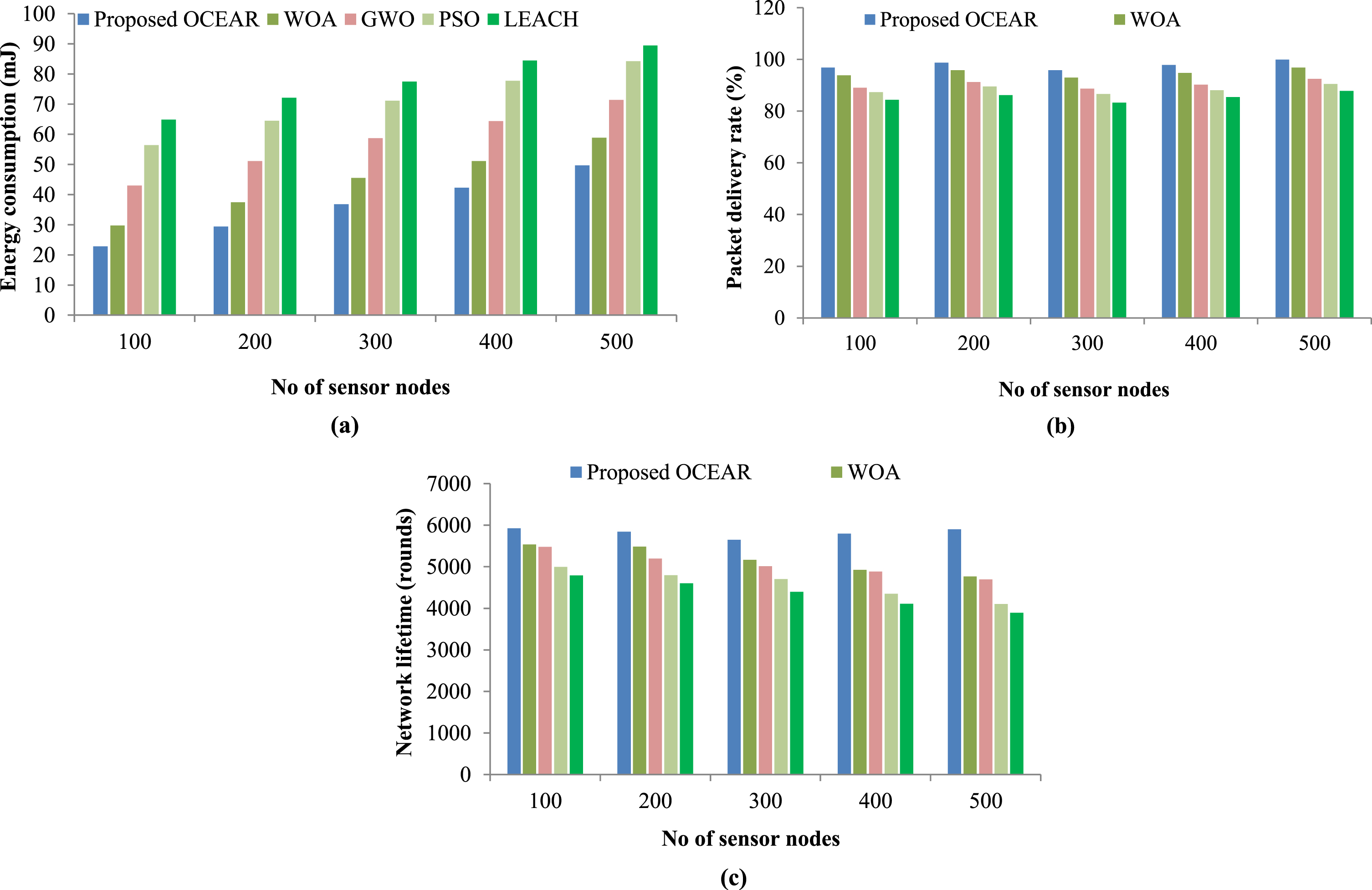
(a) Energy consumption, (b) packet delivery rate, and (c) network’s lifespan.
Next, the performance of the proposed methods is analyzed based on delay and throughput, shown in Figs. 6 and 7.
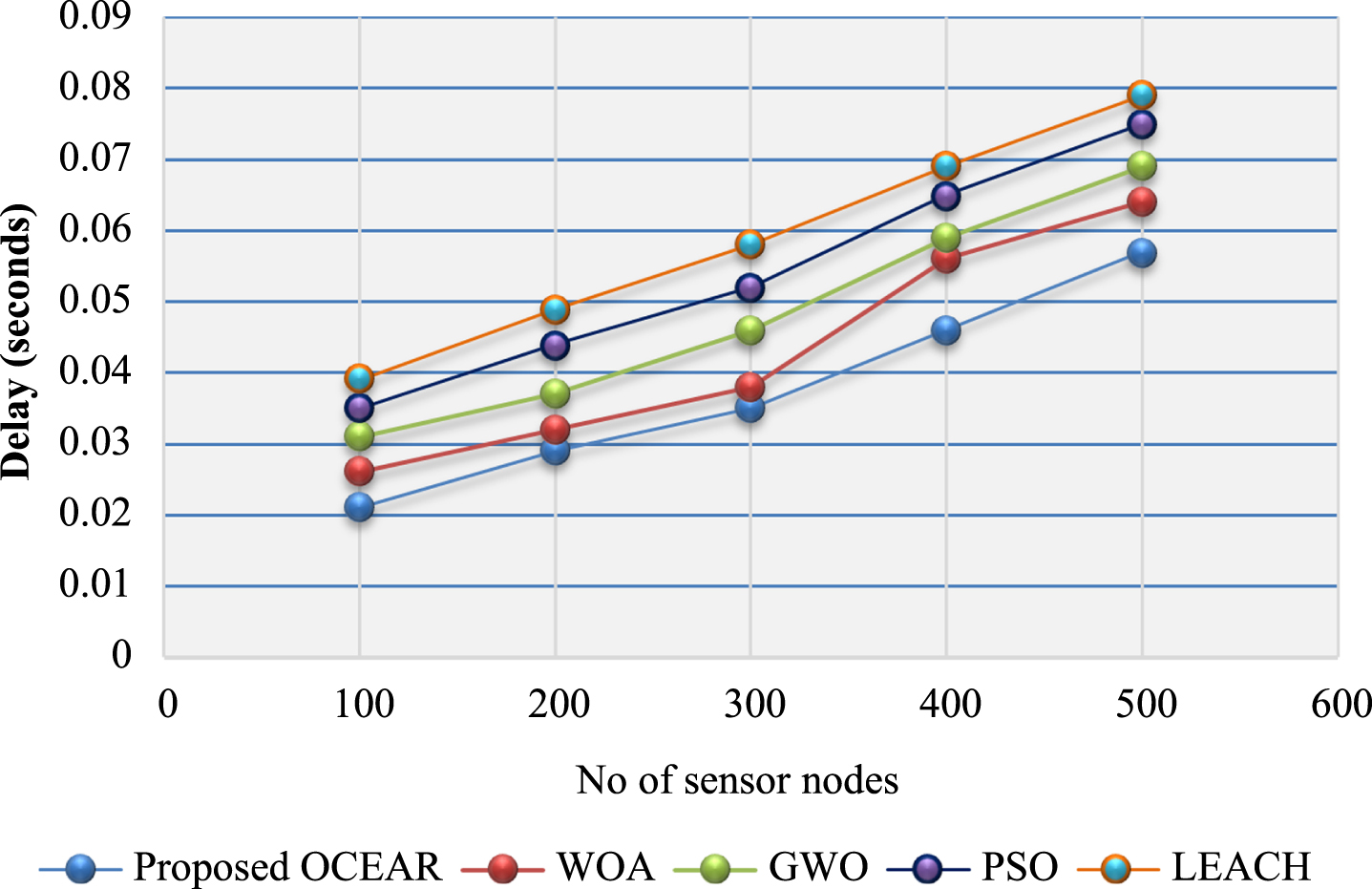
Analysis based on delay.
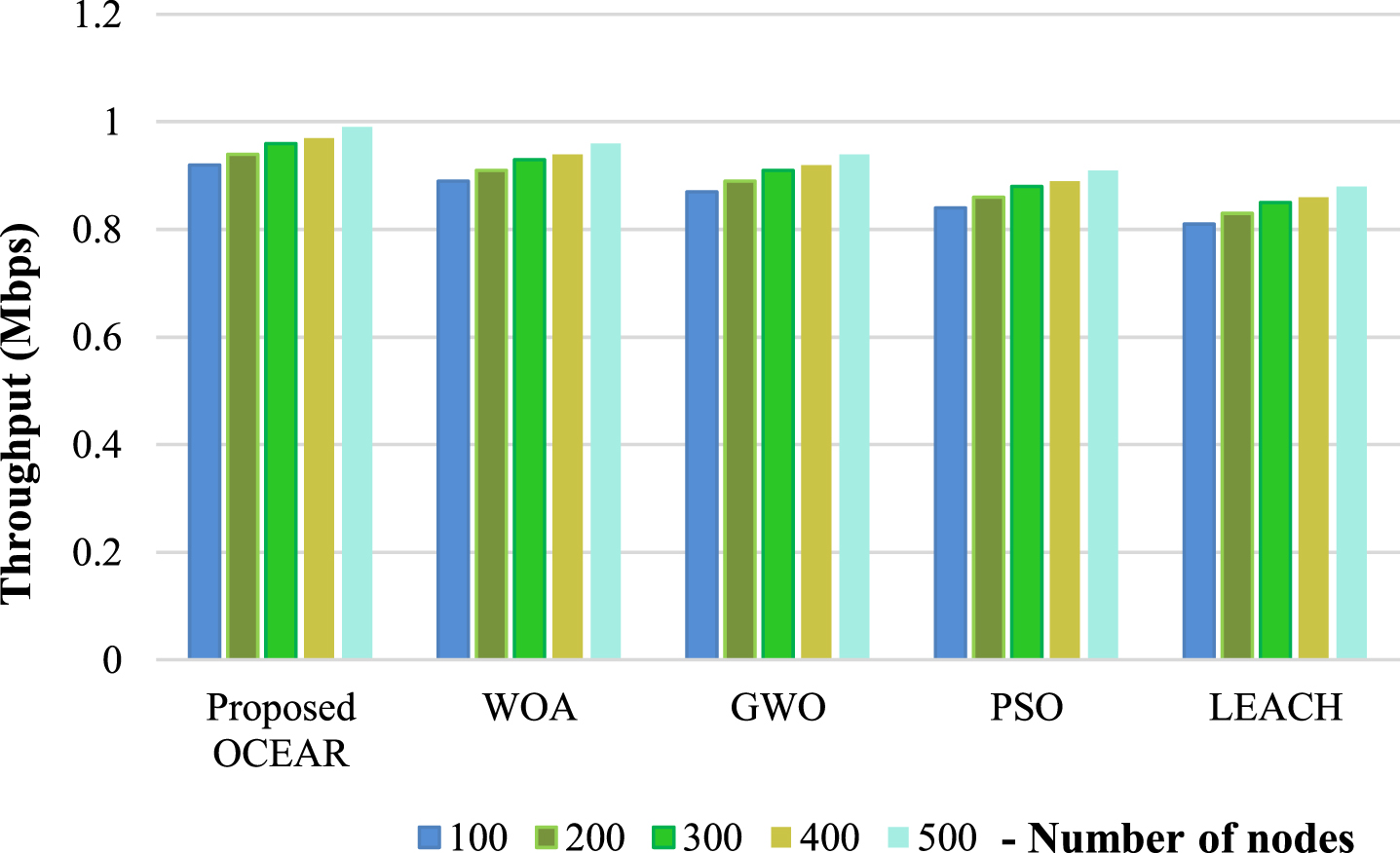
Analysis in terms of throughput.
Figure 6 shows the results of the proposed OCEAR and traditional WOA, GWO, PSO, and LEACH algorithms based on the delay metric. For 100 nodes, the existing WOA, GWO, PSO, and LEACH have higher delays of 0.026 s, 0.031 s, 0.035 s, and 0.039 s, respectively, but the proposed one has lower delay of 0.021 s, which is less than the existing methodologies. Also, for 500 nodes, the OCEAR has a low delay of 0.057 s, which is lesser than the current approaches. Similarly, for the remaining number of nodes (200-500), the proposed one has low delay. It is seen from the simulation results that OCEAR decreases the delay as compared to other solutions at varying numbers of nodes.
Figure 7 shows the throughput outcomes of the proposed OCEAR and existing algorithms. For 500 nodes, the proposed OCEAR has higher throughput of 0.99Mbps, but the prevailing WOA, GWO, PSO, and LEACH have throughputs of 0.96Mbps, 0.94Mbps, 0.91Mbps, and 0.88Mbps, respectively that, are minimal compared to the OCEAR. One achieved higher throughput for the remaining number of nodes also proposed than the previous approaches. Thus, the results prove that the proposed system performs better than the traditional methodologies fewer than 100 to 500 nodes.
Here, the average classification results of the proposed SARNN are contrasted to the existing RNN, artificial neural network (ANN), RF, and SVM approaches in terms of accuracy, precision, recall, f-measure, area under curve (AUC), and detection time. The detection performance of the classifier is determined using the relationship between actual class and the predicted class of the system which is estimated based on true positive, false positive, true negative and false negative values. The confusion matrix of the proposed system is shown in Fig. 8, where the actual and predicted classes of the dataset are plotted with correctly and incorrectly identified data samples. The diagonal cells of the matrix represent the correctly classified observations and the off-diagonal cells indicate the incorrectly classified observations. It was clear that the proposed system accurately identifies the attacks in the network with higher prediction ratio with lowest classification loss.
Table 4 illustrates the proposed and existing models’ outcomes regarding accuracy, precision, recall, and f-measure using the NSL-KDD dataset. The percentage of data that is accurately categorized as both true positives and true negatives is called accuracy. The precision measure describes the number of features in the solution that are accurate according to the data. Recall measures how many correct class predictions have been generated using all of the successful instances in the dataset. F-Measure addresses both recall and precision concerns with a single number.
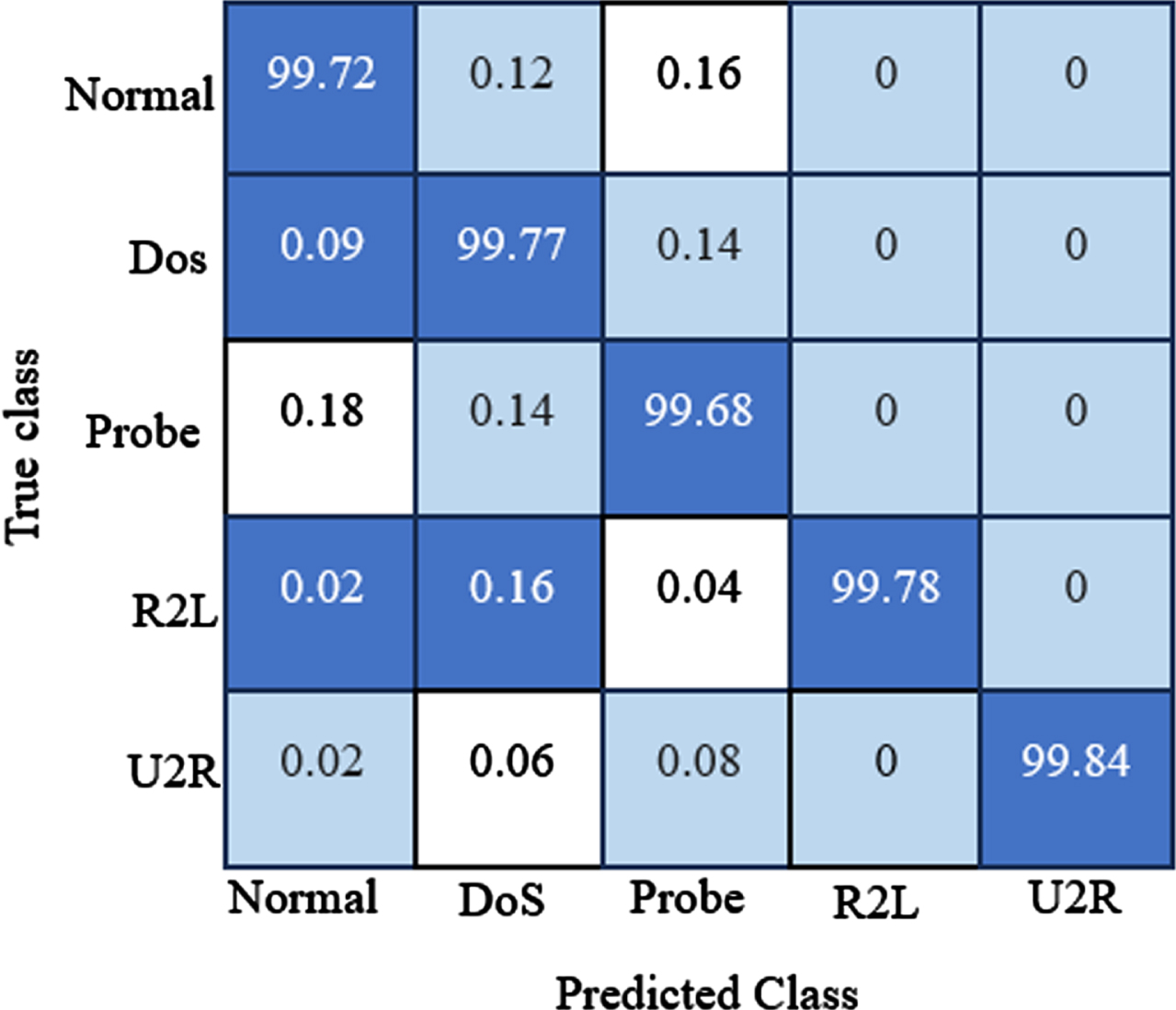
Confusion matrix.
Outcomes analysis of the proposed model with existing methods
The outcomes showed that the existing SVM delivers the poorest performance for ID compared to other classifiers. Also, the RF, ANN, and RNN offer low-level performance. But, the proposed SARNN attains more accurate and higher ID results than the previous technique. For example, the proposed SARNN achieves accuracy, precision, recall, and f-measures of 99.76%, 99.67%, 99.97%, and 99.89%, respectively, a higher outcome than the conventional existing classifiers. Thus, it concludes that the proposed one achieves high-level performance than the traditional methodologies. Figure 9 portrays the diagrammatic representation of Table 2.
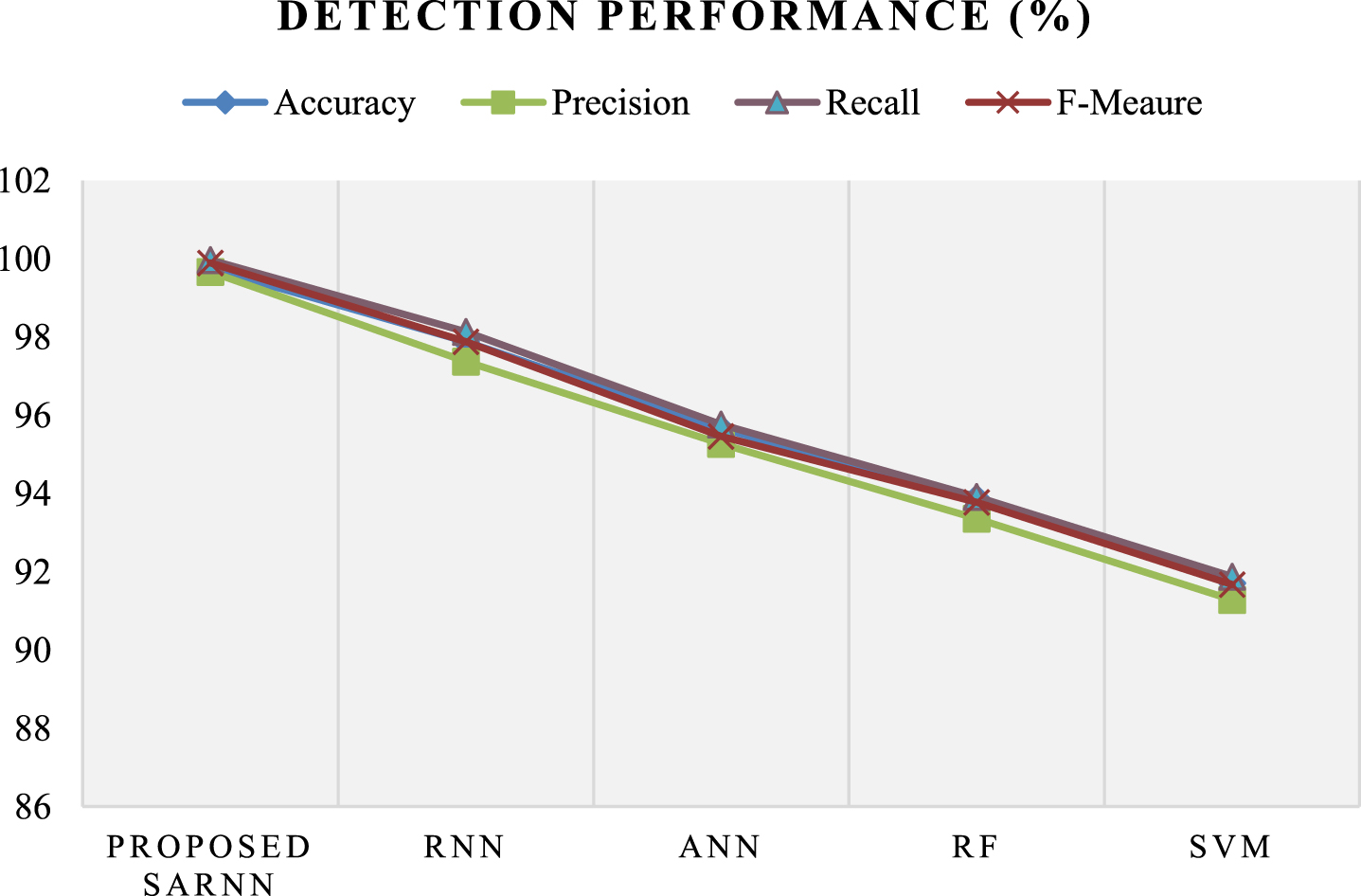
Detection performance of the classifier.
Next, the efficiency of the proposed method is analyzed with the existing methods in terms of AUC and detection time, shown in Fig. 10. AUC provides an overall measure of performance across every possible classification criterion. The higher AUC indicates the system achieved excellent outcomes at distinguishing between normal and attack. An AUC score of 1 means the classifier can perfectly distinguish between the entire normal and attack classes. In this figure, the proposed one achieves a higher AUC of 0.994% than the existing methods because the existing RNN, ANN, RF, and SVM attained AUCs of 0.974%, 0.941%, 0.916%, and 0.892%, which are lower when compared to the existing methods. Moreover, the system outcomes are better whenever the detection time is lacking. Herein, the existing RNN, ANN, RF, and SVM take 1.03 min, 1.85 min, 2.38 min, and 3.13 min to classify the classes as normal and attack types, which is higher than the proposed one because the proposed one takes just 0.74 min to complete the classification process.
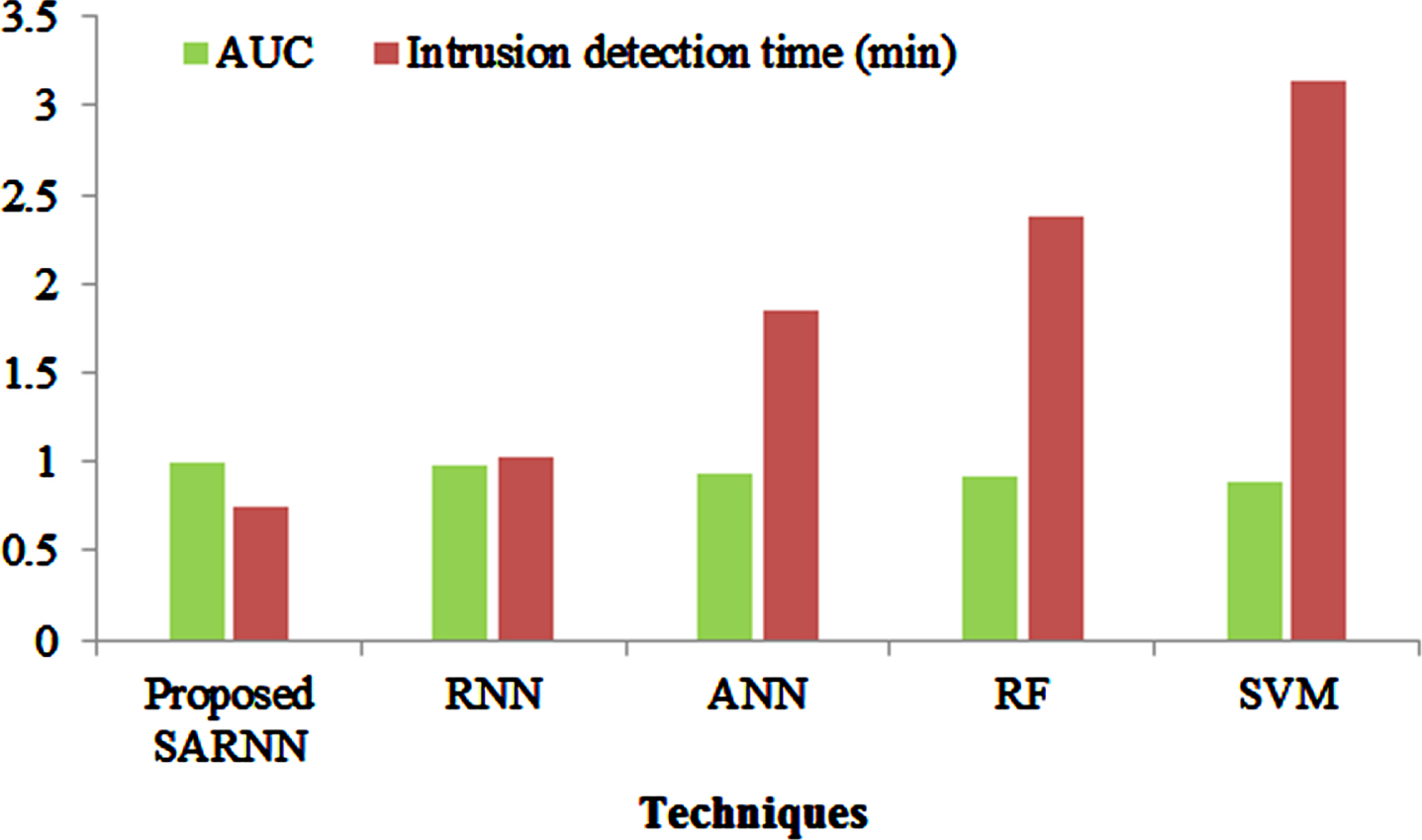
AUC and detection time analysis.
Thus, the overall outcomes indicate that the proposed method achieves more outstanding results than the existing methods. The reason is that the proposed one does not directly use the data from the dataset; it performs the preprocessing first to yield better accuracy. Also, the proposed system uses the PCA approach to reduce the dimensionality of the dataset, increasing the detection rate and reducing the complexity. Finally, the attack detection is done with the help of an efficient DL approach, namely, the SARNN approach, and the activation function of the RNN is computed using the Smish activation. These novelties and improvisations increase the prediction rate and reduce the time complexity.
This paper proposes an SDLEER mechanism for WSNs to achieve a better quality of service in the network. The proposed system comprises two phases: OCEAR and IDS. The OCEAR includes cluster formation and CH selection. The IDS phase includes preprocessing, dimensionality reduction, and classification. The training of the proposed system is done using the NSL-KDD dataset. Initially, the proposed OCEAR are investigated against the WOA, GWO, PSO, and LEACH algorithms regarding ENC, delivery rate, lifetime of the network, delay, and throughput metrics for 100 to 500 nodes. In this regard, the proposed one achieves better outcomes than the existing methodologies. Herein also, the proposed one consumes less energy of 49.67 mJ, achieves a better delivery ratio of 99.92%, takes less lifetime of 5902 rounds, 0.057 s delay, and achieves a higher throughput of 0.99 Mbps for 500 nodes, which is superior compared to the previous routing methods. Then the outcomes of the proposed SARNN are weighted against the conventional RNN, ANN, RF, and SVM approaches concerning accuracy, precision, recall, f-measure, AUC, and detection time. Herein also, the proposed one achieves 99.76% accuracy, 99.67% precision, 99.97% recall, 99.89% f-measure, 0.994% AUC, and a shorter detection time of 0.74 minutes, which is also more significant than the existing methods. Thus, the overall experimental analysis showed that the proposed one achieves higher accuracy and performance than the existing methodologies. Though the detection accuracy obtained by the proposed model is 99%, it is reduced if many attacks are performed in the network, which is a minor limitation of the proposed work. The system will focus on implementing a cryptographic mechanism for encoding the data before sending it into the base station, which will prevent the network from many kinds of network attacks. Also, this research work can be improved by introducing a nature-inspired optimization model for feature selection that will reduce the computational complexity and increase the classification accuracy of the DL-based IDS.
Statements and declarations
Funding
Not applicable,
Competing interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Availability of data and materials
The experimentations are accomplished over the NSL-KDD dataset and is collected from Kaggle through https://www.kaggle.com/datasets/hassan06/nslkdd.