
Abstract
As the theory of picture fuzzy sets has been developed, more information in life can be expressed in mathematical terms. Similarity measure is a special tool for quantifying the similarity between two sets, so studying similarity measure on picture fuzzy sets has become a trending topic. This new research direction has drawn a great deal of attention from experts and has led to a number of important results which have led to significant results in a number of practical applications. By examining these new findings, we discovered that there are many studies on similarity measure of picture fuzzy sets, some of them are deficient in solving certain problems, and such similarity measures can lead to the calculation of unreasonable data in practical applications, affecting the final results. Secondly, there is still room for research similarity measures on exponential functions. Considering these two aspects, we propose two new similarity measures based on exponential function, which not only satisfy the axiomatic definition of similarity measures, but also show reasonable computational results in practical applications.
Introduction
Zadeh [15] proposed fuzzy sets, which can represent information with fuzziness. Later, Atanassov [1] proposed intuitionistic fuzzy sets. It can represent more types of information, such as fuzziness and uncertainty than fuzzy sets. Cuong [2] proposed picture fuzzy sets (PFSs), which brought a new direction for representing different types of information, such as fuzziness, uncertainty and inconsistency. Since PFSs are more outstanding in representing information, many studies based on PFSs have been generated ([4, 13]).
Pattern recognition is a problem of processing and classifying information, therefore it has a wide range of applications in real life, for example the selection of candidates for companies, the selection of building materials, etc. The representation of information can be done with the help of PFSs, while other tools are needed to process information. Similarity measures can quantify the degree of similarity between different sets, and it has never ceased to be studied on PFSs. Gupta and Kumar ([4]) proposed two similarity metrics using fractional functions which are used to solve pattern recognition and cluster analysis. Khan et al ([6]) proposed similarity measures with parameters and applied them to pattern recognition and medical diagnosis. Li et al ([7]) proposed a similarity measure that combines Hamming distance and transformed tetrahedral centroid distance and applied it to pattern recognition. Verma and Rohtag ([13]) proposed Chi-square and Canberra picture fuzzy similarity measures and then applied them to pattern recognition and medical diagnosis.
However, when applying these similarity measures, we find that in some cases some existing similarity measures are not reasonable, which is an obstacle to solving practical problems. Secondly, similarity measures based on exponential functions have not been fully investigated. Considering the above two aspects, we propose two exponential function-based similarity measures, and they can deal with some problems that cannot be solved by some existing similarity measures in practical applications, or even better.
The rest of this paper is organized as follows: in Section 2, we review the basic definitions and properties for PFSs. In Section 3, we give two new similarity measures based on exponential function between PFSs. In Section 4, we apply the proposed similarity measures to pattern recognition. The conclusions are given in Section 5.
Preliminaries
In this section, we review some common concepts of picture fuzzy sets, which will be used in this paper.
(1) G ⊆ H iff τ G (γ i ) ≤ τ H (γ i ), σ G (γ i ) ≤ σ H (γ i ) and θ G (γ i ) ≥ θ H (γ i );
(2) G = H iff G ⊆ H and H ⊆ G;
Let D* = {〈τ, σ, θ〉 ∈ [0, 1] 3, τ + σ + θ ≤ 1} is the set of picture fuzzy numbers. Let φ = 〈τ φ , σ φ , θ φ 〉 and ψ = 〈τ ψ , σ ψ , θ ψ 〉 ∈D*, the ordering ≤ D * is defined as φ ≤ D * ψ iff τ φ ≤ τ ψ , and σ φ ≤ σ ψ , and θ φ ≥ θ ψ ([2]).
(1) 0 ≤ S (G, H) ≤1;
(2) S (G, H) = S (H, G);
(3) S (G, H) =1 if and only if G = H;
(4) If G ⊆ H ⊆ J, then S (G, J) ≤ S (G, H) and S (G, J) ≤ S (H, J).
Let
Dinh and Thao’s similarity measures ([2]):
Liu and Zeng’s similarity measure ([8]):
Thao’s similarity measure ([12]):
Wei’s similarity measures ([14]) Equations (5), (6) and (7):
Singh and Mishra’s similarity measures ([11]) Equations (8), (9), (10) and (11):
In this section, based on exponential function, we propose two new similarity measures on PFSs.
(3) If S1 (G, H) =1, then
If τ G (γ i ) = τ H (γ i ), σ G (γ i ) = σ H (γ i ), θ G (γ i ) = θ H (γ i ), (i = 1, 2, …, n), then S1 (G, H) =1 is obvious.
(4) Let G, H, J be three PFSs. If G ⊆ H ⊆ J i.e. τ
G
≤ τ
H
≤ τ
J
, σ
G
≤ σ
H
≤ σ
J
, θ
G
≥ θ
H
≥ θ
J
. Because |τ
G
(γ
i
) - τ
H
(γ
i
) | ≤ |τ
G
(γ
i
) - τ
J
(γ
i
) |, |σ
G
(γ
i
) - σ
H
(γ
i
) | ≤ |σ
G
(γ
i
) - σ
J
(γ
i
) |, |θ
G
(γ
i
) - θ
H
(γ
i
) | ≤ |θ
G
(γ
i
) - θ
J
(γ
i
) |, then
(2) Obviously.
(3) If S2 (G, H) =1, i.e.,
If τ G (γ i ) = τ H (γ i ), σ G (γ i ) = σ H (γ i ), θ G (γ i ) = θ H (γ i ), (i = 1, 2, …, n), S2 (G, H) =1 is obvious.
(4) Let G, H, J be three PFSs. If G ⊆ H ⊆ J i.e. τ
G
≤ τ
H
≤ τ
J
, σ
G
≤ σ
H
≤ σ
J
, θ
G
≥ θ
H
≥ θ
J
. Because |τ
G
(γ
i
) - τ
H
(γ
i
) | ≤ |τ
G
(γ
i
) - τ
J
(γ
i
) |, |σ
G
(γ
i
) - σ
H
(γ
i
) | ≤ |σ
G
(γ
i
) - σ
J
(γ
i
) |, |θ
G
(γ
i
) - θ
H
(γ
i
) | ≤ |θ
G
(γ
i
) - θ
J
(γ
i
) |, then,
In this section, we first give a numerical example to illustrate the rationale for new similarity measures. Then, new similarity measures are used to solve pattern recognition problems. Finally, we compare the results of new similarity measures with some existing similarity measures to illustrate the validity of new similarity measures.
Consequences derived from different similarity measures (Example 4.1)
Consequences derived from different similarity measures (Example 4.1)
According to Table 1, we find that G1 = G2, H1 ≠ H2. The similarity measures S (G1, H1) and S (G2, H2) are not supposed to be equal. However S t , S z , S g 3 , S p 1 obtain that the similarity measures between G1, H1 and G2, H2 are equal, this is unreasonable; S d 1 , S d 2 , S g 1 , S g 2 , S p 2 , S p 3 have a similar case: the similarity measures between G1, H1 are higher than G2, H2. Similarly, G3 = G4, H3 ≠ H4, the similarity measures S (G3, H3) and S (G4, H4) are not supposed to be equal. However, S d 1 , S d 2 , S g 1 , S g 2 , S p 2 , S p 3 obtain that the similarity measures between G3, H3 and G4, H4 are equal, this is unreasonable; S t , S z , S g 3 , S p 1 have the same situation: the between G4, H4 are higher than G3, H3, S p 4 appears to have a denominator of 0, so the result cannot be calculated.
Algorithm for pattern recognition
Let
The recognition steps are as follows:
Step 1. Calculate the similarity measure S (G k , H) (k = 1, 2, ⋯ , m) between G k and H.
Step 2. Choose the maximum one S (G k 0 , H) from S (G k , H) (k = 1, 2, ⋯ , m). Then the unknown pattern H is belongs to G k 0 according to the maximum principle of similarity measures.
Step 3. Calculate the degree of confidence Doc,
Applications for pattern recognition
Patterns and unknown pattern (Example 4.2)
Patterns and unknown pattern (Example 4.2)
To solve this problem, we calculate S (G1, H), S (G2, H), S (G3, H) using the proposed similarity measures S1, S2. The results are shown in Table 3.
Consequences derived from different similarity measures for pattern recognition (Example 4.2)
In Table 3, we find S d 1 , S d 2 , S g 1 , S g 2 , S g 3 , S p 1 , S p 2 , S p 3 , S p 4 have a similar case: S (G1, H) = S (G2, H); S t , S z classify pattern H into pattern G2, the results of proposed similarity measures S1, S2 are same. The Doc results comparison about S1, S2 and some existing similarity measures are shown in Fig. 1. We could notice that the Doc of S1, S2 are higher than most other similarity measures. Therefore, the proposed similarity measures S1, S2 are effective.
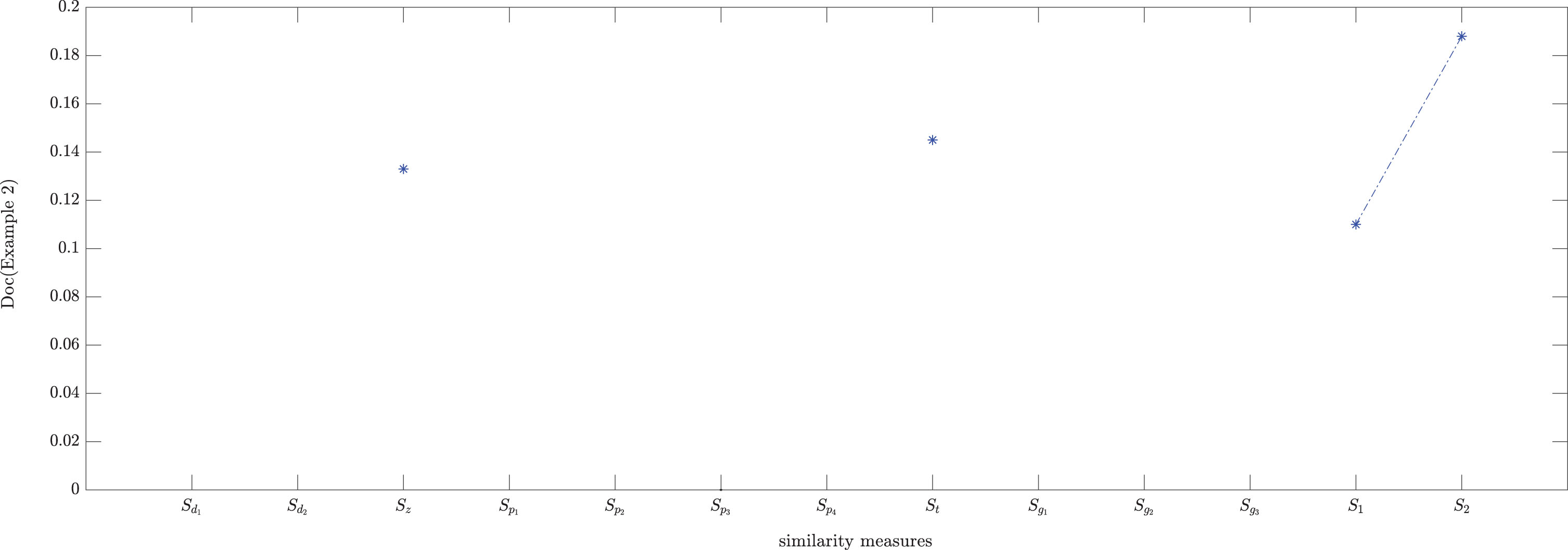
The Doc results comparison about S1, S2 and some existing similarity measures (Example 4.2).
Patterns and unknown pattern (Example 4.3)
To solve this problem, we calculate S (Q1, J), S (Q2, J), S (Q3, J) using the proposed similarity measures S1, S2. The results are shown in Table 5.
Consequences derived from different similarity measures for pattern recognition (Example 4.3)
In Table 5, we find S d 1 , S d 2 , S t , S z , S g 1 , S g 2 , S g 3 , S p 1 , S p 2 , S p 3 , S p 4 classify the sample J into pattern Q3, the results of proposed similarity measures S1, S2 are same. The Doc results comparison about S1, S2 and some existing similarity measures are shown in Fig. 2. We could notice that the Doc of S1, S2 are higher than most other similarity measures. Therefore, the proposed similarity measures are effective.
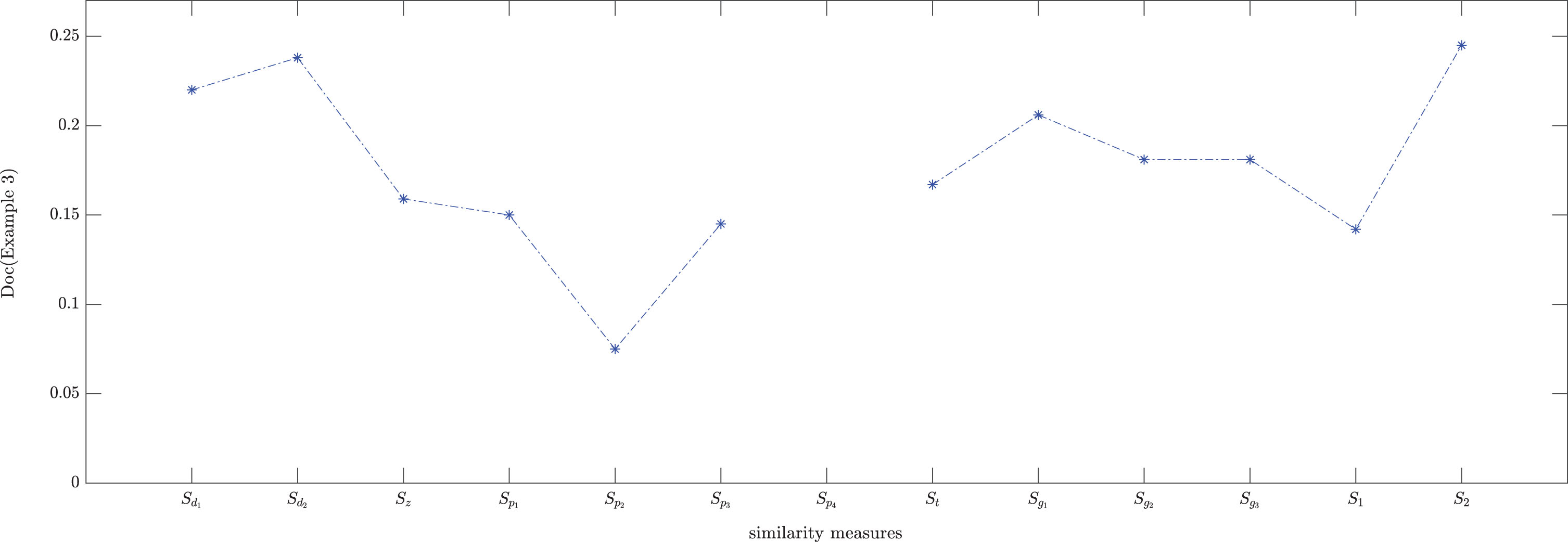
The Doc results comparison about S1, S2 and some existing similarity measures (Example 4.3).
First, we give a numerical example, and it shows that the new similarity measures S1 and S2 give the accurate results in the face of small gaps between PFSs, overcoming shortcoming of some existing similarity measures. Secondly, two applications of pattern recognition illustrate that new similarity measures S1 and S2 can still compute reasonable results in the face of more complex situations. By comparing the degree of confidence with some existing similarity measures, the similarity measure S2 has the higher degree of confidence than other similarity masures in pattern recognition example 4.2 and 4.3. Although the new similarity measure S1 has lower degree of confidence than similarity measure S2, they have the same pattern recognition results. The results of pattern recognition show that new similarity measures S1 and S2 can give more accurate computational results, and therefore the proposed new similarity measures are reasonable andvalid.
Conclusions
Recently, the study of similarity measures on PFSs has received a lot of attention, and different types of similarity measures have been proposed in large numbers. After research, we find that there is still room for research on similarity measures based on exponential functions, so we proposed two new similarity measures based on exponential functions. Then new similarity measures are used to solve the problem of pattern recognition. The results show that the proposed new similarity measures are reasonable and effective. In the next work, we will consider parameterizing new similarity measures, and construct a formula by introducing other functions to include some existing exponential similarity measures, so as to solve practical problems more effectively.
Footnotes
Acknowledgment
The authors would like to thank Editor-in-Chief, Area Editor and anonymous reviewers for their valuable comments and suggestions.