
Abstract
Knowledge tracing (KT), which aims to trace human knowledge learning process by using machines, has widely applied in online learning systems. It dynamically models student’s knowledge states in relation to different learning factors through their learning interactions. Recently, KT has attracted many researches attention due to its good performance to using deep learning. Although most of KT models have shown outstanding results, they have limitations: either ignore the human cognitive law and learning behavior, or lack the ability to go deeper modeling to trace knowledge state. In this paper, we propose a deeper knowledge tracking model integrating cognitive theory and learning behavior (CLDKT). It united the advantages of memory network and recurrent neural network of the existing deep learning KT models for modeling student learning. To better implement CLDKT, we add the residual network (ResNet) to realize the deep modeling of learning behaviors. Extensive experiments on three open benchmark datasets to evaluate our model. Experimental results demonstrate that (I) CLDKT outperforms the state-of-the-art KT models on students’ performance prediction. (II) CLDKT can deeper modeling to trace knowledge state owing to the ResNet import. (III) CLDKT has better interpretability and predictability, which proves the effectiveness of the knowledge tracing model integrating cognitive law and learning behavior.
Introduction
One of the major characteristics of human intelligence is the ability to know one’s true knowledge, which means that humans can track the states of one’s knowledge in specific skills or concepts [3]. This enables human to identify gaps in their knowledge states to personalize their learning experience, then work in different industries. With the development of artificial intelligence (AI) in modeling various areas of human cognition [8, 9], human want to take advantage of the AI trace human knowledge state in online education. This has stimulated the research of knowledge tracing (KT), which is based on the learner’s performance on learning tasks in the learning process, the learner’s knowledge mastery state is modeled, the learner’s knowledge mastery level is traced and the probability of the learner answering the question correctly in the next moment is being predicted.
With the development of online education,the growths of online learning platforms such as massive open online courses (MOOCs) [19], intelligent tutoring systems, educational games, and learning management systems is experiencing rapid expansion. A vast amount of learning process datasets has been generated through these platforms, knowledge tracking can utilize these datasets to model students’ learning processes, providing personalized learning for individuals, teaching guidance for educators, and an evaluation basis for administrators. Nonetheless, it is a highly challenging task to employ artificial intelligence methods in modeling the human learning process for knowledge tracking, as human learning is influenced not only by cognitive factors [2] (e.g. memorizing, comprehension, attention, forgetting, and guessing, etc.) but also by individual learning ability (i.e. learning efficiency and interest).
Current mainstream knowledge tracing models can be categorized into two groups:traditional machine learning KT models and deep learning KT models. Bayesian knowledge tracing (BKT) [1] model is the representative model of the traditional machine learning KT. It utilizes the Hidden Markov Model (HMM) to separately model each knowledge skill, predicting learners’ mastery of specific points without considering correlations between them. While these models have made some progress, their oversimplification of the human learning process limits applications in real-world scenarios. Inspired by the impressive performance of deep leaning, several deep learning KT models have been developed in recent years. Deep knowledge tracing (DKT) [16] is a pioneering model was first proposed by Piech et al. in 2015, which based on Recurrent Neural Networks (RNN) to model the student knowledge states by a sequence of hidden states that implicit in historical learning record. Compared with BKT, the performance of DKT model has been greatly improved, but DKT represents a learner’s knowledge state of all knowledge concepts in one hidden state, which leads to it difficult to trace a learner’s level of mastery for a certain concept. To deal with the issue, Dynamic Key-Value Memory Networks (DKVMN) [23] was proposed, which uses dynamic key-value matrices to store knowledge skills and knowledge mastery state.
However, when implementing DKVMN models, it fails to take into consideration the impact of factors such as cognitive laws and learning behaviors on the predicted results.
In this paper, we propose a deeper knowledge tracking model integrating cognitive theory and learning behavior (CLDKT). The main innovations and contributions of this paper are: First, integrating cognitive theory and learning behavior, the CLDKT model accounts for both learning and forgetting behaviors in the process of knowledge acquisition. The model considers three factors that affect knowledge tracing results: the interval between learners’ repeated exposure to knowledge skills, the interval between sequential learning sessions, and the number of times a learner repeats studying a particular knowledge skill. Second, CLDKT designed a knowledge tracing model based on LSTM and DKVMN. The model includes attention layer, forgetting layer, learning layer, prediction layer and output layer. attention layer adopt a key-value memory of DKVMN model to trace knowledge states of learners, forgetting layers based on ResNet modelling a deeper neural network for feature extraction, and learning layer uses the LSTM to improve the problem of poor medium- and long-term dependence of DKVMN. Third, experiments conducted on three publicly available real-world datasets demonstrate that CLDKT is capable of effectively modeling learners’ learning and forgetting behavior, tracking their knowledge mastery level in real-time, and exhibiting superior interpretability and accuracy performance compared to existing models.
The reminder of this paper is organized as follows. The related work is presented in Section 2. Section 3 detailed our proposed KT model CLDKT. Sections 4 discusses the experimental design and results. We conclude the paper in Section 5.
Related work
Knowledge tracing
Current mainstream knowledge tracing models can be categorized into two groups: traditional machine learning KT models and deep learning KT models [10]. Bayesian knowledge tracing (BKT) model is the representative model of the traditional machine learning KT. It utilizes the Hidden Markov Model (HMM) to separately model each knowledge skill, predicting learners’ mastery of specific points without considering correlations between them. While these models have made some progress, their oversimplification of the human learning process limits applications in real-world scenarios. Inspired by the impressive performance of deep leaning, several deep learning KT models have been developed in recent years. Deep knowledge tracing (DKT) is a pioneering model was first proposed by Piech et al. in 2015, which based on Recurrent Neural Networks (RNN) with Long Short-Term Memory (LSTM) units to model the student knowledge states by a sequence of hidden states that implicit in historical learning record. Compared with the knowledge tracing model based on traditional machine learning, the performance of the deep knowledge tracing model has been greatly improved. In recent years, scholars at home and abroad have been innovating in the field of in-depth knowledge tracing. Jian Zhang et al. proposed DKVMN, which uses dynamic key-value matrices to store knowledge skills and knowledge mastery status. Chun-Kit Yeung et al. on the basis of the DKVMN model, proposed a deep-knowledge tracing model (Deep Learning Based on knowledge Tracing Explainable Using Item Response Theory, Deep-IRT) that combines project response theory, enhancing the interpretability of in-depth knowledge tracing [21]; Nakagawa et al. applied graph neural network (GNN) to the field of knowledge tracing for the first time, and proposed Graph-based Knowledge tracing (GKT) [7]. This model complicates the knowledge skills of traditional linear relationships and makes it closer to the knowledge skill relationships in the real teaching environment. Convert this complex knowledge skill relationship into a graph structure, and then combine the knowledge tracing task with GNN, and improve the interpretability of the model through this knowledge skill modeling. Subsequently, Exercise-aware Knowledge Tracing for Student Performance Prediction(EKT) [12] is improved the problem of loss of semantic information of the topic during the training process. The model uses the BiLSTM network to mine text-level information and integrate it into the modeling process of changes in students’ knowledge level, further improving the interpretability of the model. However, EKT directly inputs the information of the text into the feature extractor, without taking into account the potential hierarchical nature of the topics, so it brings additional noise to the text. In order to solve this problem, Tong et al. used a hierarchical graph neural network to infer and aggregate the exercise text [18], which more completely characterized the exercise itself in the hierarchical structure, and effectively solved the problem of semantic loss of the topic.
Although many models have certain effects in terms of accuracy and interpretability, most of these models fail to consider cognitive theory and learning behavior influence on learning processing. According to the German psychologist Heathcote [11] and the forgetting curve proposed by Ebbinghaus [6], the degree of knowledge mastery and forgetting behavior in the learning process are closely related. Over time, the degree of knowledge mastery decreases, and repeated learning of the same knowledge skills can reduce the degree of forgetting. Qiu et al. considered the forgetting behavior in the knowledge tracing model and added a date label to the BKT model to represent the forgetting behavior of a certain day after the exercise interaction [17], but the model cannot achieve forgetting on a smaller time scale. Subsequently, Khajah et al. further expanded the BKT model, using the exercise interaction sequence to estimate the probability of forgetting, but failed to take into account the forgetting time after answering the question. Koki Nagatani et al. expanded the DKT model for the first time, using three forgetting factors [15], but the model did not establish a deep forgetting model, and the modeling of forgetting behavior was not sound enough.
LSTM network
LSTM is proposed to solve the problems of gradient explosion and gradient disappearance in recurrent neural networks (RNN) [22], and is generally used to process sequential data. As shown in Fig. 1, it is the internal structure of a single node cell in the LSTM network. Compared with the general RNN unit node, the state value C t is added to the LSTM node. The internal node is implemented by three gate mechanisms. f t determines which parts of C t are retained to realize the forgetting gate; i t implements the memory gate to determine the new information stored in C t ; o t implements the output gate to determine the output value of the cell based on C t .
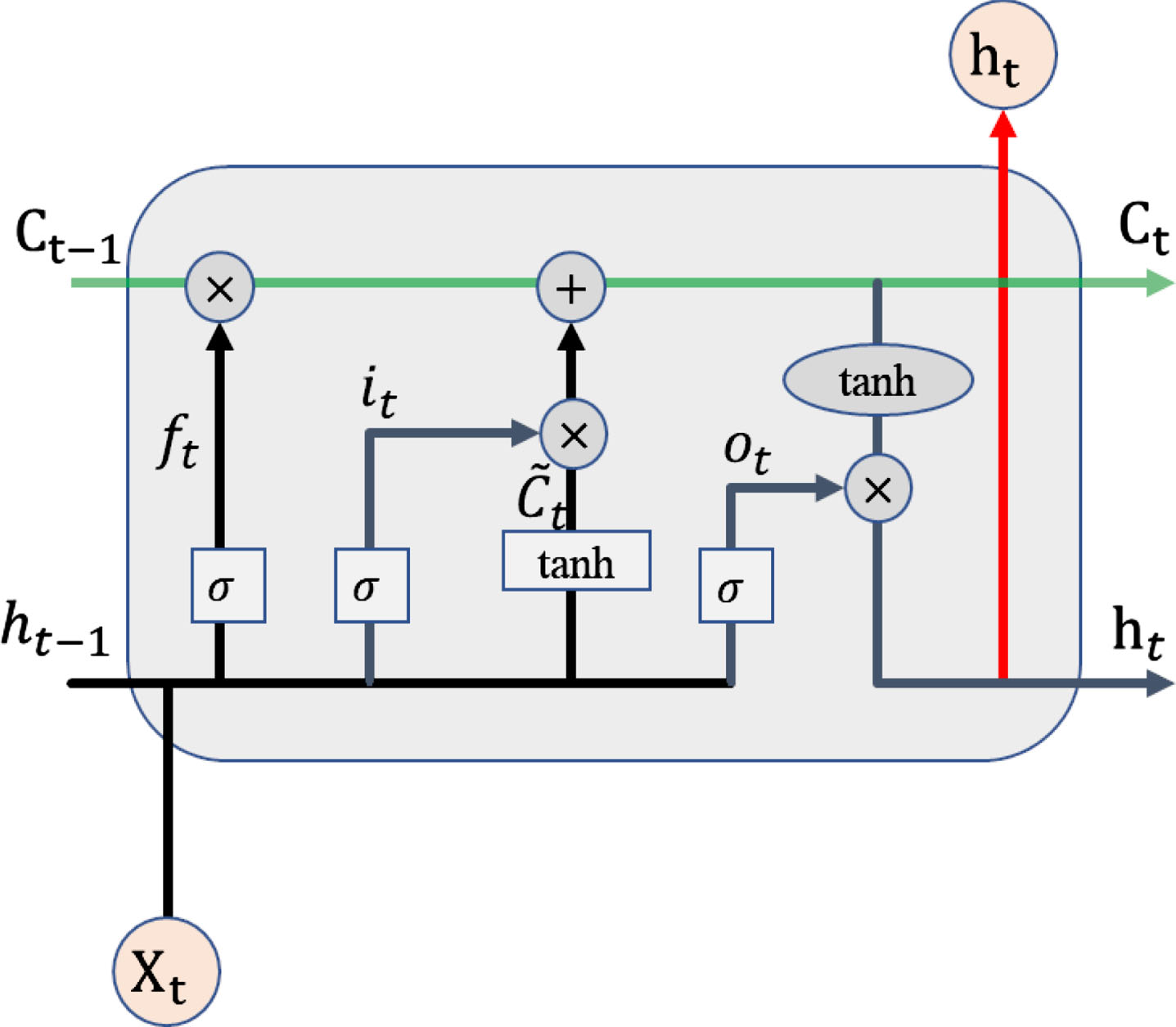
LSTM network.
In a Convolutional Neural Network (CNN), network depth has a greater impact on network performance. When the number of layers of the CNN network reaches a certain depth, network degradation will occur. Studies indicate that this type of network degradation is not attributable to overfitting, but rather to issues with network optimization. He Kaiming et al. designed ResNet and introduced a residual learning framework to solve this problem [5].
Set the objective function of CNN to H (x), and the objective function of ResNet is F (x).As shown in Fig. 2, relu is the activation function and identity is the jump function. Through this jump link method, ResNet transforms the problem of CNN finding the objective function H (x) into finding the residual mapping function F (x) of the network. Therefore, in the event of network degradation during deep network training, updating only the partial weight of F (x) is sufficient to achieve better learning features.
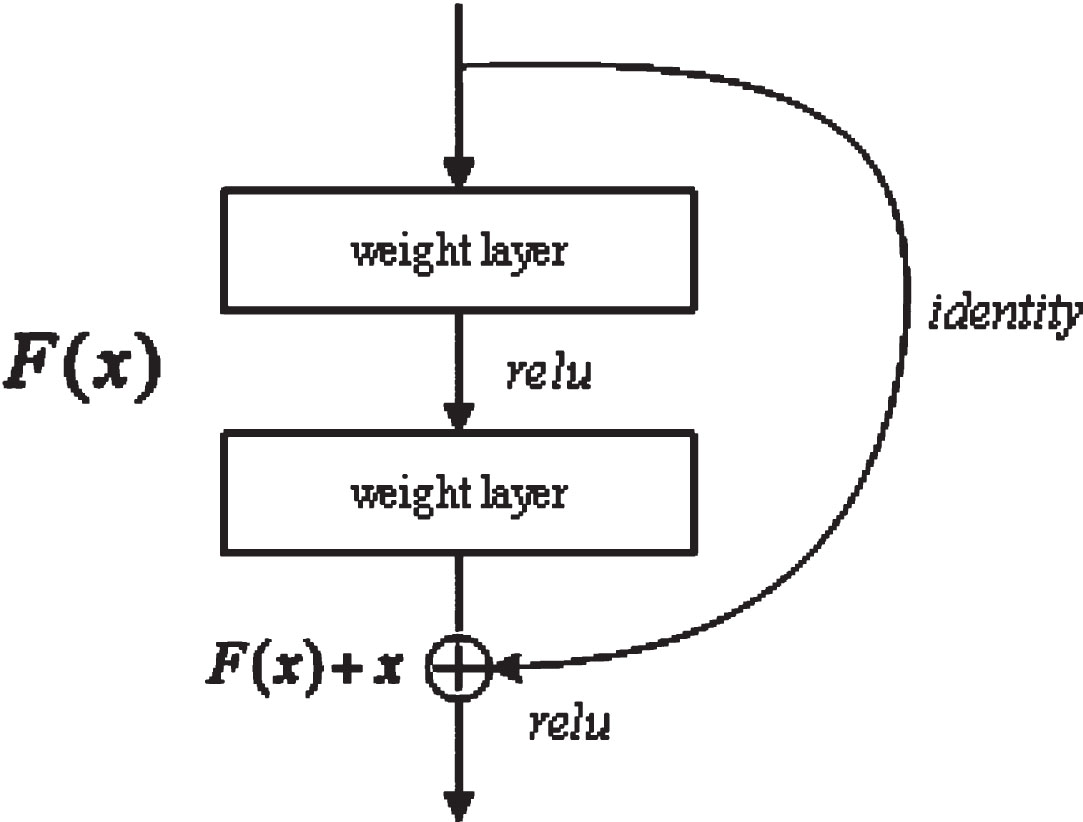
A residual learning framework.
Cognitive theory is a learning theory that explores learning rules by studying people’s cognitive process. The main perspectives encompassed are: the human as the subject of learning, active learning; The process by which humans acquire information is an exchange involving perception, attention, memory, comprehension and problem-solving. People’s perception, attention and understanding of external information are selective. Learning quality hinges on outcomes. The learning curve theory and the forgetting curve theory are two important theories in education studies, which provide the basic ideas for modeling the knowledge mastery of students. The learning curve theory argues that students can gain the knowledge with constant trails or exercises [13], the forgetting curve theory suggests that students have a decreasing memory on things they have learned so that their knowledge proficiency follows a declining curve. These theories show that knowledge proficiency has a great relationship with the individual learning behavior (repeated time interval, repeated learn times, the time interval between any two learning moments, and so on)of students.
The CLDKT model
Problem formulation
In an intelligent tutoring system, supposing the set of students
CLDKT framework
In this section, the CLDKT model is detailed. As shown in Fig. 3, the CLDKT model include five layers, attention layer, deep forgetting layer, LSTM learning layer, prediction layer and output layer. In CLDKT model, we use cognitive theory and learning behavior to model forgetting layer, import ReNet framework to deeper extract the feature of forgetting factors and LSTM is used train the model and update learner’s knowledge state.
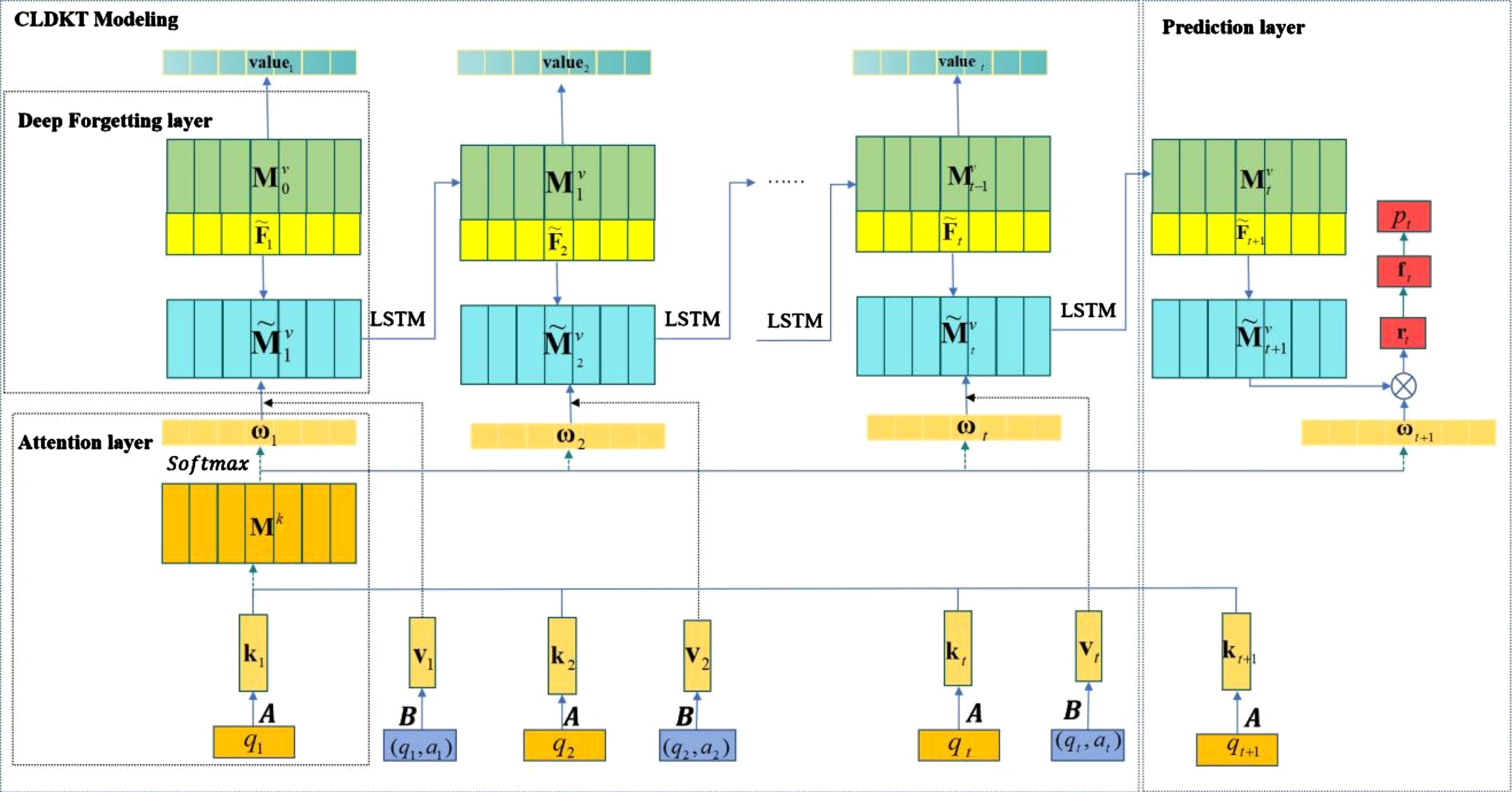
CLDKT model framework.
At any timestamp t, we define the embedding matrix
Studies have shown that learning and forgetting behaviors in the learning process depend on the number of times the learner learns and the time interval of the last learning. Therefore, three factors that affect knowledge tracing results are selected in this article,namely: RT (Repeated time interval): For the same knowledge skill, the time interval between the two studies before and after. ST (Sequence time interval): Do not pay attention to the knowledge skills learned, the time interval between any two learning moments. LT (Repeated learn times): In the historical learning record, the number of times learners used the same knowledge skills to answer questions.
Combine the three scalar RT, ST and LT to obtain the forgetting vector
As one of the branches of the CNN model, the ResNet model can build a deeper network level and perform multi-level abstraction, which has more advantages when learning complex inputs and outputs. In order to improve the modeling of forgetting behavior, the ResNet-12 network is selected to further process the forgetting vector, embed the forgetting feature vector into the ResNet-12 network for training, and perform feature extraction on the forgetting vector. The network structure of ResNet-12 is shown in Fig. 4.

The ResNet-12 network.
After the ResNet-12 network training, get the extracted forgetting feature vector
Figure 5 is the deep forgetting layer model,we use
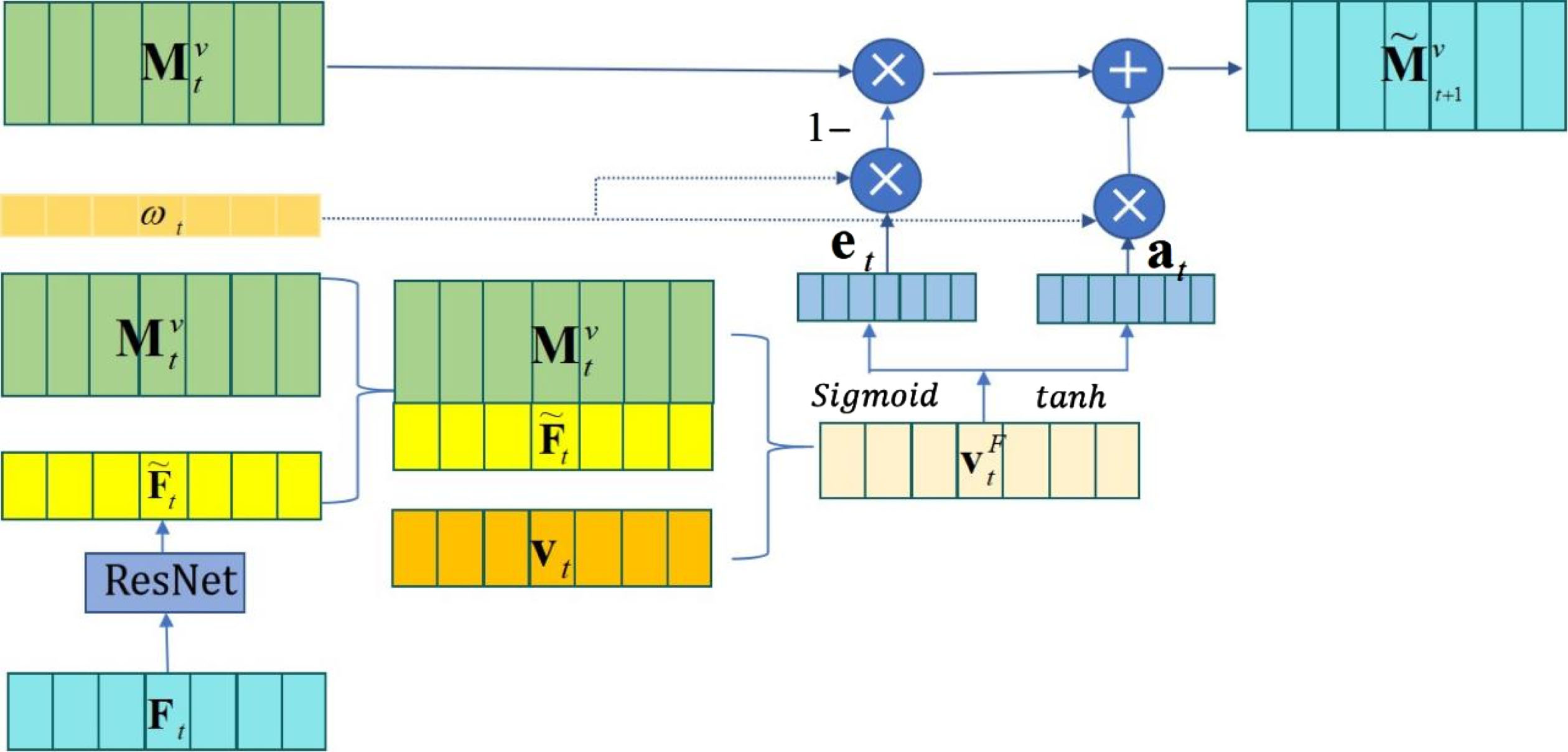
The deep forgetting layer.
The answer embedding vector
Then the memory erasure
Since the knowledge mastery state of the DKVMN model is obtained from the recent interactive training of exercises, the long-term dependence is poor. In order to deal with this problem, LSTM is introduced to improve the original model. Use
The reading correlation vector
The output layer aims to computer the students’ knowledge mastery state. After LSTM learning layer output
To learn all parameters in CLDKT, we choose the cross-entropy loss between the prediction p
t
and actual answer r
t
as the object function:
Experiment setting
Benchmark datesets
The experiment was conducted on three public real datasets: ASSIST2009, ASSIST2015, Statics2011. The data sets information are shown in Table 1, which list the number of users, the number of knowledge points and the number of interaction records of the data set used. The ASSIST2009 data set is collected from the online tutoring system Assists created in 2004. Users need to master these problem sets through similar exercises. The ASSIST2015 data set is the same as the ASSIST2009 data set, collected from the Assists online coaching system. The Statics2011 data set comes from a university’s engineering statics course, which combines exercise names and step names as knowledge concepts.
Experimental datasets statistics
Experimental datasets statistics
The experiment uses a 50% off cross-verification method to evaluate the training of the knowledge tracing model. 80% of the data is used as the training set and verification set in each data set, and the other 20% of the data is used for testing. The upper limit of the length of the data input is set to 200 items. Delete users with less than 5 interaction records in each data set.
For ease of calculation, the state matrix dimensions d
k
and d
v
are set to the same value. In the model,
The experiments use AUC as the measure of the model. The higher the AUC value, the higher the prediction accuracy of the model. Five benchmark models were selected for comparative experiments.
DKT model: The model obtained by using a recurrent neural network to train the interactive sequence of exercises introduces deep learning ideas into knowledge tracing for the first time.
DKVMN model: Use a key-value pair network to store knowledge concepts and knowledge mastery status, and then predict the learner’s answer based on the learner’s knowledge mastery status.
DKT-Forgetful model: Based on the DKT model, three forgetting factors are embedded in the input data, and hidden states are used to represent the learner’s knowledge mastery state.
AKT model: A context-aware knowledge tracing model that represents the performance of learners in the learning process through a monotonic attention mechanism, and can capture the individual differences in the learning process of different learners [4].
GIKT model: A graph-based neural interaction knowledge tracing model that uses embedded communication to represent the correlation between knowledge points and exercises [20].
Experimental results and analysis
Experimental results
The experimental results are shown in Table 2. They are the AUC obtained by different models trained on each data set. The best results are highlighted in bold. It is known from Table 2:
Prediction results of different models on knowledge tracing
Prediction results of different models on knowledge tracing
(1) On the datasets used in the three experiments, the knowledge tracing model of deep oblivion modeling is better than other comparative models. Compared with the DKVMN model, the AUC values of the CLDKT model on the ASSIST2009, ASSIST2015 and Static2011 datasets have improved by 3.7%, 3.1% and 4.7%, respectively. Indicating the effectiveness of deep oblivion modeling and the introduction of LSTM to improve the network model.
(2) In the comparative model, the AUC value of the DKT-forgetful model has improved on all three datasets compared to the DKT model, indicating the effectiveness of forgetting behavior modeling in in-depth knowledge tracing to improve the accuracy of the model.
(3) On the three datasets, the AUC value of the CLDKT model compared to DKT-forgetful has increased, while in the comparison between the DKVMN model and DKT-forgetful, the AUC value of the DKVMN model is only higher than that of DKT-forgetful on the ASSIST2009 dataset, indicating the effectiveness of forgetting behavior modeling to improve the accuracy of the model.
In order to further verify the performance of the CLDKT model, the DKT model was selected as the comparison model, and the AUC change values of the CLDKT model and the DKT model were visualized during the training process on the experimental datasets ASSIST2009, ASSIST2015, and Statics2011 as shown in Fig. 6.
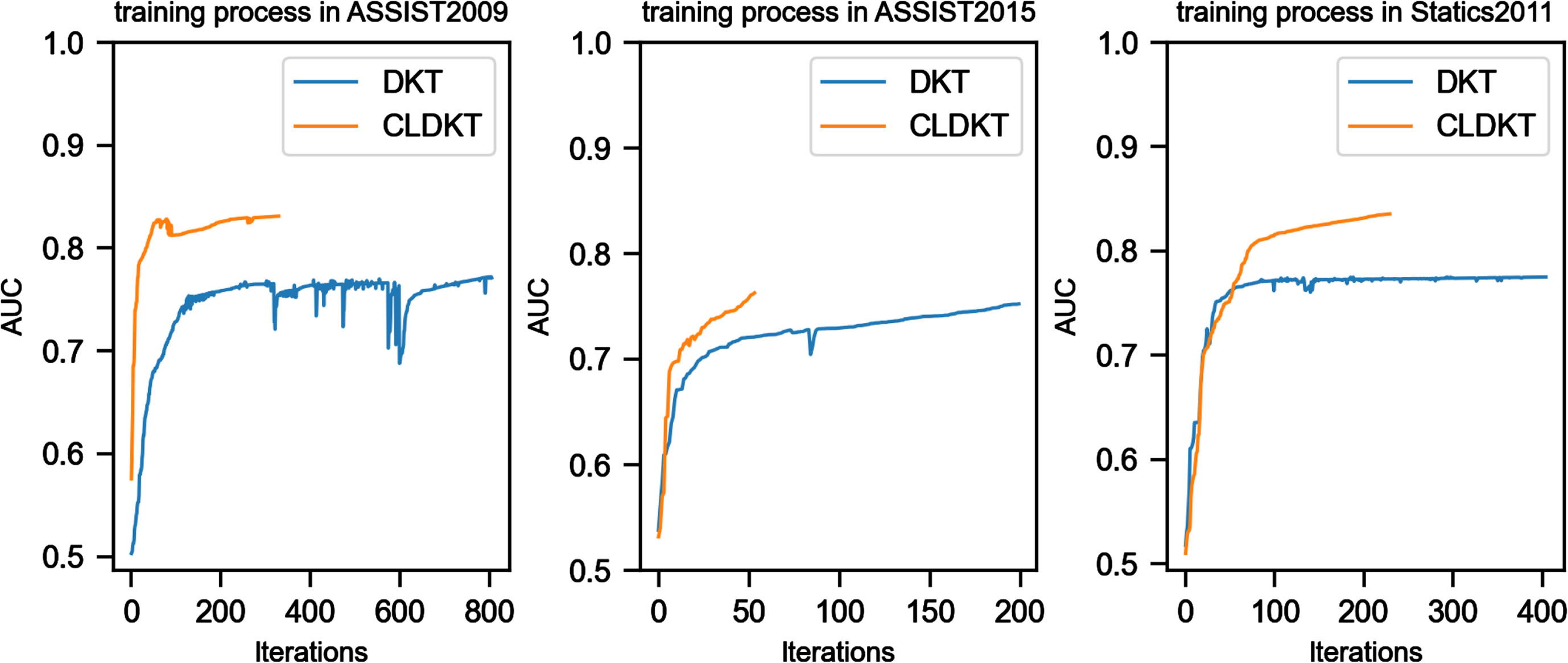
The training AUC of DKT and CLDKT on all datasets.
In the ASSIST2009 dataset, the DKT model reached the optimal value at 803 iterations, and the CLDKT model reached the optimal value at 330 iterations. In the ASSIST2005 data set, the DKT model reached the optimal value at 204 iterations, and the CLDKT model reached the optimal value at 54 iterations. In the Static2011 dataset, the DKT model reached the optimal value at 405 iterations, and the CLDKT model reached the optimal value at 230 iterations. Compared with the DKT model, the CLDKT model takes less iterations to train to reach the optimal iterative value on the same data set, and the AUC result is higher, indicating that the training speed of the model is faster than that of the DKT model, and the optimal AUC value of the model can be trained with fewer iterations.
In order to further analyze the effectiveness of the model and modeling, this paper conducted an ablation experiment to compare the model with the variant model. The variant model is as follows.
CLDKT-F model: In order to verify the effectiveness of the deep forgetting modeling of the model, the feature part of the forgetting factor extracted by ResNet is removed, and the forgetting feature vector
CLDKT-L model: In order to verify the effectiveness of forgetting modeling, the forgetting modeling part is removed, and the model degenerates into an improved model after the DKVMN model is added to the LSTM network.
The experimental results are shown in Table 3.
The following conclusions can be obtained from the analysis of Table 3.
Results of ablation experiment
Results of ablation experiment
(1) Compared with the DKVMN model, the training accuracy of CLDKT-L has improved on all three data sets, proving the effectiveness of adding LSTM to improve the model.
(2) Compared with the CLDKT-L model, the CLDKT-F model has improved its training accuracy on all three data sets, indicating the effectiveness of forgetting behavior modeling to improve the accuracy of the knowledge tracing model.
(3) Compared with the CLDKT-L model, the CLDKT model has a higher accuracy rate on the three data sets, which verifies the effectiveness of deep forgetting modeling.
In order to further verify the performance of the model, a learner’s 4 knowledge points and 21 answer records in the data set ASSIST2009 were selected. As shown in the Fig. 7, it is a diagram of the change in the student’s knowledge mastery state on the DKT model and the CLDKT model. The abscissa is (q t , a t ), which represents the sequence of answers, and the ordinate is the sequence number of knowledge points.

An example of a student’s knowledge level output on 5 concepts using DKT and CLDKT in ASSISTments2009.
Analyzing Fig. 7, it can be seen that taking knowledge point 1 as an example, in the DKT model, only at the sequence related to the serial number of the knowledge point, and at other timestamps, the state of knowledge hardly changes, which is obviously inconsistent with the laws of memory and forgetting in reality, indicating that the DKT model does not have the ability to forget. In the CLDKT model, in the learning process, the state of knowledge mastery will decrease over time, which is more in line with the forgetting behavior in reality, proving the effectiveness of the CLDKT model for modeling forgetting behavior.
In this paper, we explored a new model for knowledge tracing named deeper knowledge tracking model integrating cognitive theory and learning behavior (CLDKT). Specifically, we first integrate cognitive theory and learning behavior to model forgetting layer that considers three factors in the process of knowledge acquisition. Then based on LSTM and DKVMN, we designed five layers deep learning model, which includes attention layer, forgetting layer, learning layer, prediction layer and output layer. With experiments on three public datasets, we proved that the CLDKT model based on ResNet deep forgetting modeling has good performance in knowledge tracing ability. Through the analysis of the knowledge state of the CLDKT model, our model is capable of effectively modeling learners’ learning and forgetting behavior, tracking their knowledge mastery level in real-time, and exhibiting superior interpretability and accuracy performance compared to existing models.
The CLDKT model improves the performance of knowledge tracing. However, we find that the relationship between different forgetting factors and the weight of each type of forgetting factor are not considered. In the future, we will research the characteristics of forgetting behavior data, study the relationship between different forgetting behavior data and forgetting laws, and further realize a knowledge tracing model that includes multiple forgetting characteristic data, incorporates information of the exercises into the students learning ability and learning behavior to further improve the representations. So that knowledge tracing can accommodate complex learning situations in reality.
Footnotes
Acknowledgment
This work is supported by Gansu Youth Science and Technology Fund Program under Grant No. 21JR11RA217 and 22JR11RA208. The Outstanding Youth Fund Project of Gansu Academy of Sciences No. 2023 YQ-03. Innovation Group Project of basic research in Gansu under Grant No. 23JRRA1348.