
Abstract
The Student-Project Allocation with preferences over Projects problem is a many-to-one stable matching problem that aims to assign students to projects in project-based courses so that students and lecturers meet their preference and capacity constraints. In this paper, we propose an efficient two-heuristic algorithm to solve this problem. Our algorithm starts from an empty matching and iteratively constructs a maximum stable matching of students to projects. At each iteration, our algorithm finds an unassigned student and assigns her/his most preferred project to her/him to form a student-project pair in the matching. If the project or the lecturer who offered the project is over-subscribed, our algorithm uses two heuristic functions, one for the over-subscribed project and the other for the over-subscribed lecturer, to remove a student-project pair in the matching. To reach a stable matching of a maximum size, our two heuristics are designed such that the removed student has the most opportunities to be assigned to some project in the next iterations. Experimental results show that our algorithm is efficient in execution time and solution quality for solving the problem.
Introduction
In project-based courses, students must be assigned to projects to build projects together. To do this, either lecturers can propose a list of students for their projects or departments can assign students to lecturers for doing projects. If doing so, it is evident that there exist conflicts not only among lecturers but also among students since lecturers usually choose good academic students for their projects, while students typically choose projects based on their preferences. The question for this problem is how to allocate students to projects to meet the preference requirements of both students and lecturers. To solve this problem, Abraham et al. introduced the Student-Project Allocation problem (SPA) in 2003 [1]. In particular, an instance of SPA involves three non-empty sets of students, projects, and lecturers. Each lecturer offers a set of projects and ranks a subset of students in strict order of preference in their lists to whom they intend to supervise, while each student ranks a subset of the available projects in a strict order of preference in their lists that they find acceptable. Moreover, each project is offered by a unique lecturer, both projects and lecturers have capacity constraints to indicate the maximum number of students assigned to projects and lecturers. In this context, a stable matching refers to an assignment of students to projects such that there exist no student-project unstable pairs, i.e., the student and project are not matched together in the matching, but they prefer each other to their current assigned partners in the matching. Then, they proposed a student-oriented algorithm running in a linear time to find a student-optimal stable matching for a given instance of SPA, in which each student is assigned to the most preferred project they could get in any stable matching. In 2007, Abraham et al. [2] extended their work and introduced two algorithms for SPA. The first one is a student-oriented algorithm described in their previous work [1], while the second one is a lecturer-oriented algorithm running in a linear time to find a lecturer-optimal stable matching for a given instance of SPA, in which each lecturer is assigned to the most preferred students to whom they could get in any stable matching.
In practical applications, requiring each lecturer to rank a subset of students in a strict order as in SPA is unfair for both lecturers and students. For example, lecturers often strongly prefer to supervise students with good academic results rather than students with poor academic results. This sometimes leads to conflicts among lecturers and students. Moreover, if there are many students in SPA, it is difficult for lecturers to rank students in their lists. For these reasons, in 2008, Manlove and O’Malley [12] proposed a variant of SPA, called SPA with preferences over Projects (SPA-P), where lecturers rank a subset of projects in strict order rather than a subset of students in their lists. Given an instance of SPA-P, Manlove and O’Malley [12] showed that stable matchings could have different sizes, and the problem of finding a maximum stable matching is NP-hard even if each project and lecturer has a capacity 1.
In the last few years, several researchers have proposed efficient approximation algorithms and provided the lower and upper bounds for SPA-P. An algorithm is said to be an r-approximation algorithm for SPA-P if it results in a stable matching M with |M
opt
|/|M| ≤ r for all SPA-P instances, where M
opt
is the stable matching of maximum size. In 2008, Manlove and O’Malley [12] extended the well-known Gale-Shapley algorithm [5] to propose a 2-approximation algorithm with linear time complexity, namely SPA-P-approx. This algorithm consists of a sequence of proposals, in which an unassigned student with a non-empty list proposes the most preferred project on her/his list to form student-project pairs of a matching such that the lecturers and projects satisfy their capacity constraints. The algorithm returns a stable matching in a finite number of iterations. In 2012, Iwama et al. [6] extended the SPA-P-approx [12] using Király’,s idea [8] and proposed a
So far, both SPA and SPA-P have received significant attention from the research community for their roles in developing automated systems for student project allocation. Several examples can be found at various institutions, such as the School of Computing Science at the University of Glasgow [9], the Faculty of Science at the University of Southern Denmark [3], and the Department of Computing Science at the University of York [7].
The remainder of this paper is structured as follows. Section gives a formal definition of SPA-P, Section algorithm presents our proposed algorithm, Section experiments discusses the experiments, and Section conclusions concludes our work.
SPA-P problem
In this section, we remind the SPA-P problem given in [6, 12]. An instance I of the SPA-P problem comprises a set S = {s1, s2, ⋯ , s
n
} of students, a set P = {p1, p2, ⋯ , p
q
} of projects, and a set L = {l1, l2, ⋯ , l
m
} of lecturers, where (i) Each lecturer l
k
∈ L offers a non-empty set P
k
of projects in strict order of preference in their lists, subject to P1 ∪ P2 ∪ ⋯ ∪ P
m
= P and P
k
1
∩ P
k
2
= ∅ , ∀ k1 ≠ k2; (ii) Each student s
i
∈ S ranks a non-empty set A
i
⊆ P of projects in strict order of preference in their lists; (iii) Each lecturer l
k
∈ L has a capacity
For ∀s i ∈ S, ∀l k ∈ L, and ∀p j ∈ P, we denote rank (s i , p j ) and rank (l k , p j ) by the rank of p j in s i ’s and l k ’s lists, respectively. If s i and l k prefer p j as the α th and β th choices in their lists (1 ≤ α, β ≤ q), then rank (s i , p j ) = α and rank (l k , p j ) = β, respectively. For ∀p j ∈ A i and ∀p t ∈ A i , if s i prefers p j to p t , we denote by rank (s i , p j ) < rank (s i , p t ). For ∀p j ∈ P k and ∀p t ∈ P k , if l k prefers p j to p t , we denote by rank (l k , p j ) < rank (l k , p t ). Moreover, we denote rank (s i , p j ) =0 for ∀p j ∈ P \ A i and rank (l k , p j ) =0 for ∀p j ∈ P \ P k .
An assignmentM in I is a subset of S × P such that if (s i , p j ) ∈ M, then p j ∈ A i . If l k offers p j and (s i , p j ) ∈ M, then we say that s i is assigned to p j and l k in M, p j is assigned to s i in M, and l k is assigned to s i in M.
For ∀s i ∈ S, we denote M (s i ) by the set of projects assigned to s i in M and |M (s i ) | by the number of projects in M (s i ). If M (s i ) =∅, then we say that s i is unassigned in M. For ∀p j ∈ P, we denote M (p j ) by the set of students assigned to p j in M and |M (p j ) | by the number of students in M (p j ). If |M (p j ) | > c j , |M (p j ) | < c j , or |M (p j ) | = c j , then we say that p j is over-subscribed, under-subscribed, or full, respectively. For ∀l k ∈ L, we denote M (l k ) by the set of students assigned to l k in M and |M (l k ) | by the number of students in M (l k ). If |M (l k ) | > d k , |M (l k ) | < d k , or |M (l k ) | = d k , then we say that l k is over-subscribed, under-subscribed, or full, respectively.
List of some notations

List of some notations
A matchingM in I is an assignment such that |M (s i ) |≤1, |M (p j ) | ≤ c j , and |M (l k ) | ≤ d k for ∀s i ∈ S, ∀p j ∈ P, and ∀l k ∈ L. If |M (s i ) |=1, we denote M (s i ) by the project assigned to s i in M.
A pair (s
i
, p
j
) ∈ (S × P) \ M is a blocking pair for a matching M if all the following conditions are met, where p
t
= M (s
i
): p
j
∈ A
i
, i.e., s
i
finds p
j
acceptable; either p
t
=∅ or rank (s
i
, p
j
) < rank (s
i
, p
t
), i.e., s
i
prefers p
j
to p
t
; |M (p
j
) | < c
j
and either \\ (a)s
i
∈ M (l
k
) and rank (l
k
, p
j
) < rank (l
k
, p
t
), or\\ (b)s
i
∉ M (l
k
) and |M (l
k
) | < d
k
, or\\ (c)s
i
∉ M (l
k
), |M (l
k
) | = d
k
, and rank (l
k
, p
j
) < rank (l
k
, p
z
), where p
z
is l
k
’s worst non-empty project, i.e., l
k
ranks p
z
with the lowest priority in M (l
k
), where M (p
z
)≠ ∅.
The concept of blocking pair refers to a situation where a student s
i
finds a project p
j
acceptable and s
i
prefers p
j
to her/his currently assigned project, then s
i
and p
j
have the potential to form a better matching than the current matching by replacing their current assigned partners.
An instance of the

A matching M in I is called stable if no blocking pair exists for M; otherwise, M is called unstable. Given a stable matching M, we denote |M| by the number of students assigned in M, i.e., the size of M. If |M| = n, then M is called perfect; otherwise, M is called non-perfect. The SPA-P problem aims to find a stable matching with maximum size, known as MAX-SPA-P [12].
An instance I of the SPA-P problem is given in Table \ref tab:SPA-P-Example, where S = {s1, s2, s3, s4, s5, s6}, P = {p1, p2, p3, p4, p5}, L = {l1, l2}. The students’ and lecturers’ lists columns show the preference lists of students and lecturers over projects, respectively, i.e., A1 = {p1, p2, p5}, A2 = {p1, p4}, A3 = {p2, p1, p4}, A4 = {p3}, A5 = {p3, p4}, A6 = {p5, p3, p4}, P1 = {p3, p1, p2}, and P2 = {p4, p5}. The students’ and lecturers’ ranks columns show the rank of projects in the students’ and lecturers’ lists, respectively, where if s i and l k prefer p j as the α th and β th choices in their lists, then rank (s i , p j ) = α and rank (l k , p j ) = β. For example, in the students’ lists, we write “s1: p1p2p5”, meaning that s1 prefers p1 as the first choice, p2 as the second choice, and p5 as the third choice and therefore, rank (s1, p1) =1, rank (s1, p2) =2, and rank (s1, p5) =3 in the students’ ranks. We use similar notations in the lecturers’ lists. The matching M = {(s1, p5), (s2, p1), (s3, p2), (s4, p3), (s5, p4)} is unstable because there exist two blocking pairs consisting of (s1, p1) and (s6, p5) for M. Specifically, (s1, p1) ∉ M and s1 prefers p1 to p5, so s1 should be assigned to p1. Meanwhile, (s6, ∅) ∉ M, s6 prefers the most p5, and |M (p5) | < c5, so s6 should be assigned to p5. The matching M = {(s1, p1), (s2, p1), (s3, p4), (s4, p3), (s6, p5)} is a stable matching of size |M|=5. On the contrary, the matching M = {(s1, p5), (s2, p1), (s3, p1), (s4, p3), (s5, p4), (s6, p5)} is a maximum stable matching and it is also perfect since its size is |M|=6.
\label sec:algorithm
In this section, we first propose two heuristic functions used in our algorithm. Then, we propose an algorithm to find stable matchings of maximum size for the SPA-P problem. Finally, we give an execution of our algorithm for the SPA-P instance given in Table \ref tab:SPA-P-Example.
Heuristic definitions
\label sec:heuristic-definition
We consider the SPA-P-approx [12] and SPA-P-approx-promotion [6] algorithms for finding maximum stable matchings of SPA-P instances. The main principle of SPA-P-approx is as follows. At the beginning, the algorithm initializes a matching M to be empty, meaning that every student is unassigned to any project offered by lecturers. At each iteration, the algorithm finds the first project p j of an unassigned student s i with a non-empty list. If p j is full, meaning that p j does not have a slot for s i , then the algorithm deletes p j from s i ’s list so that it does not choose p j for s i in the next iterations. Otherwise, the algorithm provisionally assigns p j to s i to form a stable pair (s i , p j ) ∈ M. When p j is assigned to s i , the lecturer l k who offered p j is assigned to s i . If l k is over-subscribed, the algorithm removes an arbitrary student s r from M (p z ), where p z is l k ’s worst non-empty project, and deletes p z in s r ’s list. Meanwhile, SPA-P-approx-promotion [6] algorithm runs as follows. At the beginning, the algorithm marks all students as unpromoted. At each iteration, the algorithm chooses the first project p j of an unassigned student s i with a non-empty list at each iteration. If p j is full, the algorithm removes an arbitrary student s r from M (p j ) and adds (s i , p j ) to M. If l k is over-subscribed, the algorithm removes an arbitrary student s r from M (p z ) such that l k is full, where l k is the lecturer who offered p j and p z is l k ’s worst non-empty project in M (l k ).
We found that removing an arbitrary student s r in M (p j ) or M (p z ) is a weak point of both SPA-P-approx and SPA-P-approx-promotion algorithms. For example, we consider a specific case where the three following conditions are met: (i) M (p z ) consists of at least two students s r and s w ; (ii) s r ranks only one project; and (iii) s w ranks more than one project. If we remove s r from M, then s r is unassigned in M forever, while if we remove s w from M, then s w can be assigned to some project in her/his list at the next iterations.
In the general case, we find in each iteration of the above algorithms that when a project p j ∈ A i is assigned to a student s i ∈ S, if p j is over-subscribed, we need to remove a student from M (p j ) so that p j is full. We recognize that the student removed from M (p j ) should have the most remaining projects in her/his list since she/he has the most opportunity to be assigned to some project at the next iterations. Moreover, when a project p j is assigned to a student s i , the lecturer l k who offered p j can be over-subscribed. If l k is over-subscribed, we need to remove a student from M (l k ) so that l k is full. To keep M stable, the student removed from M (l k ) must be a student assigned to a project p z , which is l k ’s worst non-empty project, so that condition (3c) in the definition of a blocking pair is not violated. Similar to the case where p j is over-subscribed, the student removed from M (p z ) should have the most remaining projects in her/his list since she/he has the most opportunity to be assigned to some project at the next iterations. To solve these two issues, we propose two heuristic functions as follows:
Case 1: When a project p
j
is over-subscribed, we propose a heuristic function for every student s
r
∈ M (p
j
) as follows: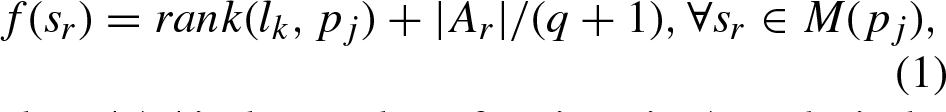
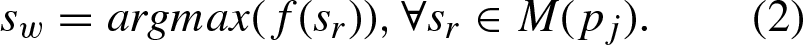
Case 2: When a lecturer l
k
is over-subscribed, we propose a heuristic function for every student s
r
∈ M (l
k
) as follows: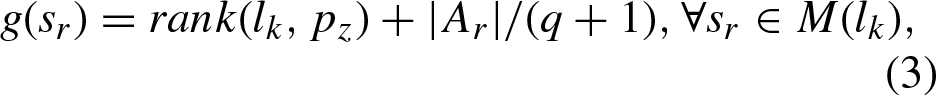
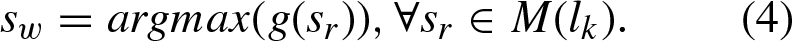
Since the student s w removed from M (p j ) and M (l k ) corresponds to the maximum f (s w ) and g (s w ) values given in Equations \eqref eq:fsw and \eqref eq:gsw, we call such a student s w the worst student removed from either M (p j ) or M (l k ).
\label sec:SPA-heuristic
Our heuristic algorithm for finding maximum stable matchings of SPA-P instances, namely SPA-P-heuristic, is shown in Algorithm 1. During the execution of the algorithm, each student is marked active (i.e., a (s i ) =1) or inactive (i.e., a (s i ) =0). At the beginning, every student s i ∈ S is active and unassigned in M. At each iteration, if there exists an active student s i with an empty list, then she/he becomes inactive forever (i.e., a (s i ) =0). Therefore, she/he is unassigned in M and the algorithm runs the next iteration (lines 5–8). Otherwise, she/he is assigned to her/his most preferred project p j to form a pair (s i , p j ) in M, and she/he becomes inactive (lines 9–12). If p j is over-subscribed, then the worst student s w in M (p j ) determined by Equation \eqref eq:fsw is removed from M (lines 14–15), s w deletes p j in her/his list (line 16), and she/he becomes active again (line 17). If l k is over-subscribed, then the worst student s w in M (l k ) determined by Equation \eqref eq:gsw is removed from M (lines 20–22). If so, s w deletes p z in her/his list, where p z is offered by l k and assigned to s w (line 23), and she/he becomes active again (line 24). The algorithm repeats until all students are inactive and returns a stable matching.
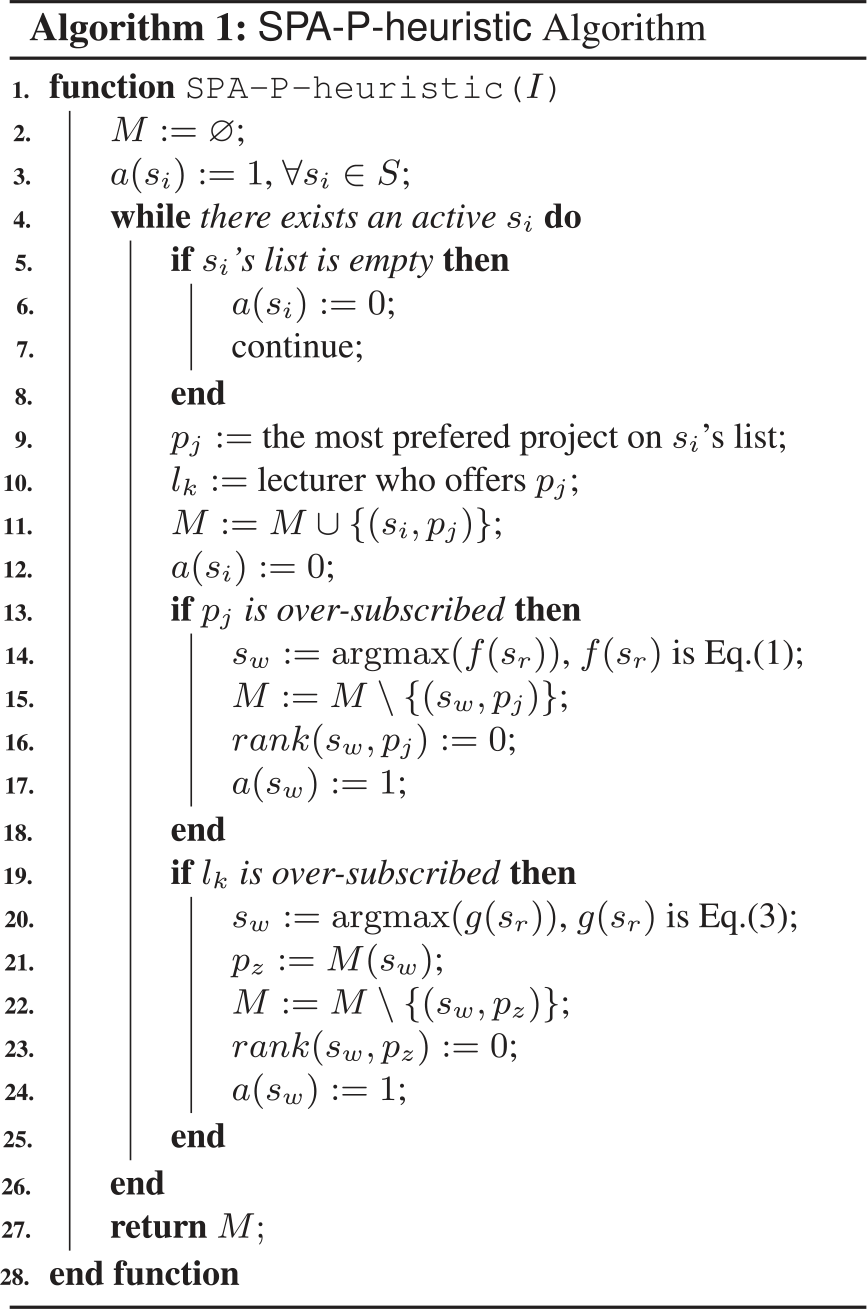
S = S1 ∪ S2, where S1 is a set of students assigned to projects and S2 is a set of students not assigned to any project. If so, we have (i) S1∩ S2 = ∅; (ii) every s i ∈ S1 is inactive since s i is assigned to some project in her/his list; and (iii) every s r ∈ S2 is inactive since s r ’s list is empty after deleting |A r | projects in her/his list. This shows that all students are inactive after a finite number of iterations and therefore, the algorithm terminates since it runs when there exists an active student s i ∈ S. \myend
Case 1: If p t is not deleted from s r ’s list, then s r ’s list is not empty. If s r is unassigned in M, then s r is marked active. If so, the while loop would not have terminated and we get a contradiction with Lemma 3.1. Hence, s r is assigned in M. Since we assume that (s r , p t ) blocks M, i.e., s r prefers p t to p z = M (s r ). However, when s r proposes p z , p z was the first project on s r ’s list and we get a contradiction. Hence, M is stable.
Case 2: If p t is deleted from s r ’s list, then this occurs when (i) p t is over-subscribed. If so, p t becomes full and (s r , p t ) cannot block M; or (ii) l k is over-subscribed, where l k is the lecturer who offered p t . If so, g (s r ) is maximum as shown in Equation \eqref eq:gsw, i.e., rank (l k , p t ) is maximum and |A r | is maximum. Since rank (l k , p t ) is a positive integer number and 0 < |A r |/(q + 1) <1, meaning that p t is l k ’s worst non-empty project in M (l k ). Now l k becomes full in M and l k ’s worst non-empty project in M (l k ) is better than p t . Hence, (s r , p t ) cannot block M. Since we assume that (s r , p t ) blocks M, we get a contradiction. Hence, M is stable.\myend
Example
An execution of SPA-P-heuristic for the instance given in Table \ref tab:SPA-P-Example
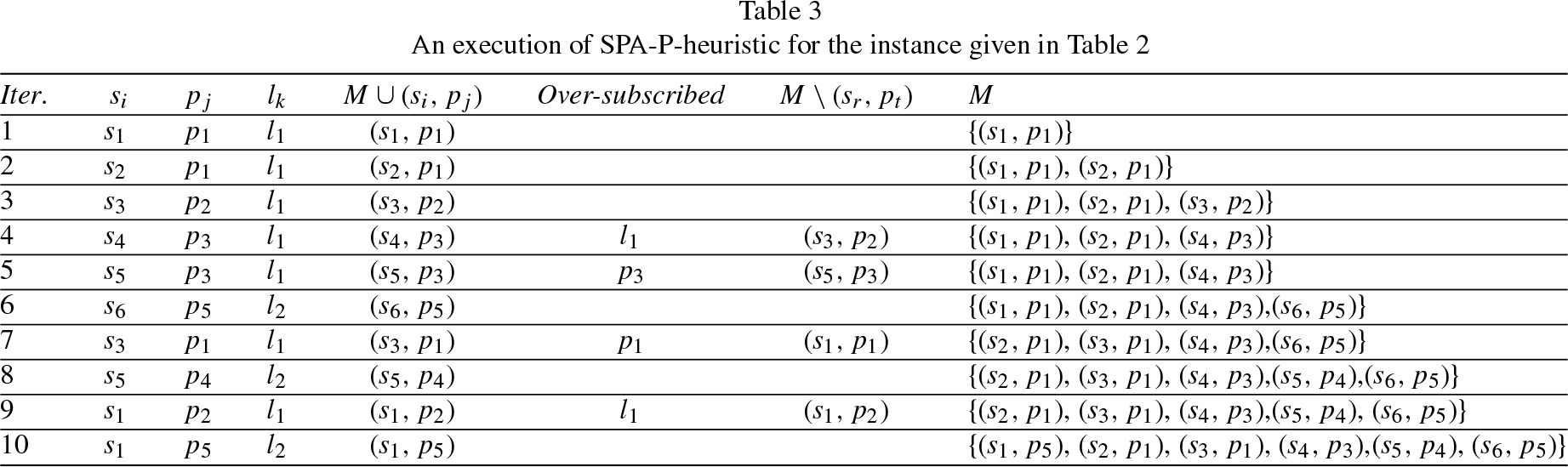
An execution of SPA-P-heuristic for the instance given in Table \ref tab:SPA-P-Example
In this section, we consider the execution of our algorithm for the SPA-P instance given in Table \ref tab:SPA-P-Example. First, our algorithm sets all students to be active and unassigned in a matching M, i.e., M = {}. Then, it runs the iterations shown in Table \ref tab:SPA-P-Heuristic-excution, where p
t
= M (s
r
). Specifically, the iterations are as follows: At the 1st, 2nd, and 3rd iterations, s1, s2, and s3 are assigned to their most preferred project p1, p1, and p2, respectively, offered by l1. Therefore, we have M = {(s1, p1), (s2, p1), (s3, p2)} and s1, s2, and s3 are marked inactive. At the 4th iteration, s4 is assigned to her/his most preferred project p3 offered by l1. Therefore, we have M = {(s1, p1), (s2, p1), (s3, p2), (s4, p3)} and s4 is marked inactive. Since l1 is over-subscribed, from Equation \eqref eq:gx, we have M (l1) = {s1, s2, s3, s4}, g (s1) =2.50, g (s2) =2.33, g (s3) =3.50, and g (s4) =1.17, i.e., g (s3) is maximum. From Equation \eqref eq:gsw, (s3, p2) is removed from M. So, we have M = {(s1, p1), (s2, p1), (s4, p3)}, s3 deletes p2 from her/his list and she/he is active again. At the 5th iteration, s5 is assigned to her/his most preferred project p3 offered by l1. Therefore, we have M = {(s1, p1), (s2, p1), (s4, p3), (s5, p3)} and s5 is marked inactive. Since p3 is over-subscribed, from Equation \eqref eq:fx, we have M (p3) = {s4, s5}, f (s4) =1.17, and f (s5) =1.33, i.e., f (s5) is maximum. From Equation \eqref eq:fsw, (s5, p3) is removed from M. So, we have M = {(s1, p1), (s2, p1), (s4, p3)}, s5 deletes p3 from her/his list and she/he is active again. At the 6th iteration, s6 is assigned to her/his most preferred project p5 offered by l2. Therefore, we have M = {(s1, p1), (s2, p1), (s4, p3), (s6, p5)} and s6 is marked inactive. At the 7th iteration, s3 is assigned to her/his most preferred project p1 offered by l1. Therefore, we have M = {(s1, p1), (s2, p1), (s3, p1), (s4, p3), (s6, p5)} and s3 is marked inactive. Since p1 is over-subscribed, from Equation \eqref eq:fx, we have M (p1) = {s1, s2, s3}, f (s1) =2.50, f (s2) =2.33, and f (s3) =2.33, i.e., f (s1) is maximum. From Equation \eqref eq:fsw, (s1, p1) is removed from M. So, we have M = {(s2, p1), (s3, p1), (s4, p3), (s6, p5)}, s1 deletes p1 from her/his list and she/he is active again. At the 8th iteration, s5 is assigned to her/his most preferred project p4 offered by l2. Therefore, we have M = {(s2, p1), (s3, p1), (s4, p3), (s5, p4), (s6, p5)} and s5 is marked inactive. At the 9th iteration, s1 is assigned to her/his most preferred project p2 offered by l1. Therefore, we have M = {(s1, p2), (s2, p1), (s3, p1), (s4, p3), (s5, p4), (s6, p5)} and s1 is marked inactive. Since l1 is over-subscribed, from Equation \eqref eq:gx, we have M (l1) = {s1, s2, s3, s4}, g (s1) =3.33, g (s2) =2.33, g (s3) =2.33, and g (s4) =1.17, i.e., g (s1) is maximum. From Equation \eqref eq:gsw, (s1, p2) is removed from M. So, we have M = {(s2, p1), (s3, p1), (s4, p3), (s5, p4), (s6, p5)}, s1 deletes p2 from her/his list and she/he is active again. At the 10th iteration, s1 is assigned to her/his most preferred project p5 offered by l2. Therefore, we have M = {(s1, p5), (s2, p1), (s3, p1), (s4, p3), (s5, p4), (s6, p5)} and s1 is marked inactive.
Since all students are inactive, the algorithm returns a stable matching M = {(s1, p5), (s2, p1), (s3, p1), (s4, p3), (s5, p4), (s6, p5)} of size |M|=6, which is a perfect matching.
In this section, we present some experiments to evaluate the performance of our SPA-P-heuristic algorithm. We chose the SPA-P-approx [12] and SPA-P-approx-promotion [6] (for short, we call it SPA-P-promotion) algorithms to compare their solution quality and execution time with those of our SPA-P-heuristic algorithm since both SPA-P-approx and SPA-P-promotion are approximation algorithms with a linear time complexity. We implemented three algorithms by Matlab R2019a software on a laptop computer with Core i7-8550U CPU 1.8 GHz and 16 GB RAM, running on Windows 11.
Generate a set S = {1, 2, ⋯ , n} of students, a set P = {1, 2, ⋯ , q} of projects, and a set L = {1, 2, ⋯ , m} of lecturers. Generate randomly non-empty sets P1, P2, ⋯ , P
m
of projects such that P1 ∪ P2 ∪ ⋯ ∪ P
m
= P and P
i
∩ P
j
= ∅ for i = 1, 2, ⋯ m, j = 1, 2, ⋯ m, and i ≠ j. We consider P
k
as a set of projects offered by lecturer l
k
∈ L (l
k
= 1, 2, ⋯ , m). Iterate for each l
k
∈ L and each p
j
∈ P, if p
j
is at the position β
th
in P
k
, then we set rank (l
k
, p
j
) = β; otherwise, we set rank (l
k
, p
j
) =0. By doing so, we have a rank matrix of all the lecturers. Distribute the total capacity σ of all the projects randomly to the capacity c
j
of each project p
j
∈ P (j = 1, 2, ⋯ , q) such that 0 < c
j
< σ and Calculate the total capacity ρ
k
of all the projects p
j
∈ P
k
and generate the capacity d
k
of each lecturer l
k
∈ L by setting d
k
to be some percentage of ρ
k
(e.g., d
k
= 100 % ρ
k
, or d
k
is a random integer number such that 80 % ρ
k
≤ d
k
≤ 100 % ρ
k
). Generate randomly non-empty sets A1, A2, ⋯, A
n
of projects such that A
i
⊆ P. We consider A
i
as a set of projects proposed by student s
i
∈ S (i = 1, 2, ⋯ , n). Iterate for each s
i
∈ S and each p
j
∈ P, if p
j
is at the position α
th
in A
i
, then we set rank (s
i
, p
j
) = α; otherwise, we set rank (s
i
, p
j
) =0. By doing so, we have a rank matrix of all the students.
As a result, our method represents an instance of SPA-P by a rank matrix of students, a rank matrix of lecturers, a capacity list of projects, and a capacity list of lecturers, which are inputs for our algorithm.
In our experiments, we generated 100 instances of SPA-P for each value of n. In each instance, we chose the values of m and q to make the student-to-lecturer ratio and the student-to-project ratio suitable for real applications. Besides, σ is chosen based on the value of n. To compare the performance of our SPA-P-heuristic algorithm with that of SPA-P-approx and SPA-P-promotion algorithms for SPA-P instances, we ran SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms for each instance to find their solution and execution time. Then, we determined the percentage of perfect matchings, the average of unassigned students, and the average execution time found by each algorithm run on 100 instances of SPA-P to compare their performance.
Parameter values for datasets in Experiments 1 and 2
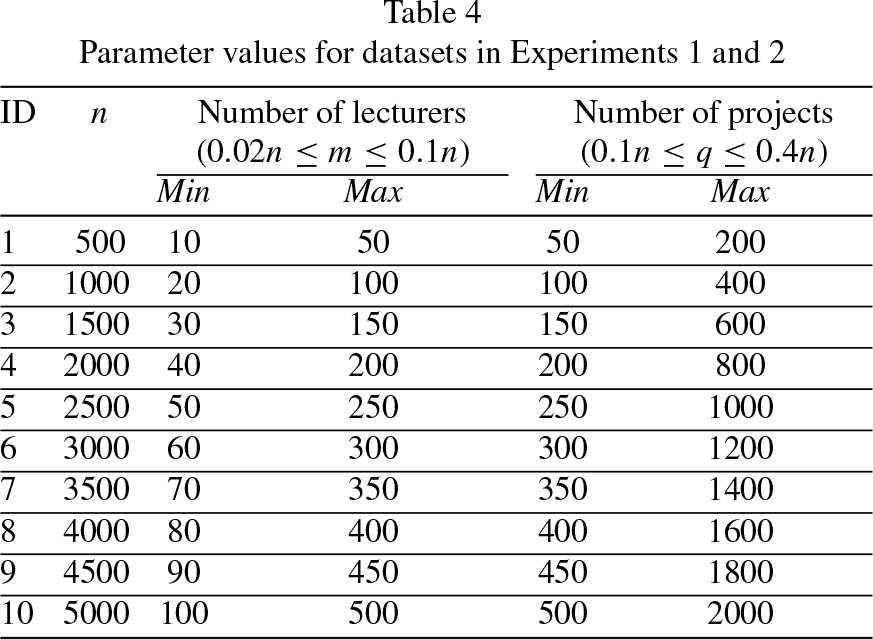
Parameter values for datasets in Experiments 1 and 2
Comparing solution quality and execution time of SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms.
In this experiment, we chose the values of parameters n, m, and q as shown in Table \ref SPA-P-experiments. For each value of n varying from 500 to 5000 with steps 500, we generated 100 instances of SPA-P of parameters n, m, and q, where m and q are random numbers constrained by 0.02n ≤ m ≤ 0.1n and 0.1n ≤ q ≤ 0.4n, respectively. The constraints of m and q mean that the student-to-lecturer ratio is from 10 to 50 and each lecturer offers from 1 to 20 projects. In each instance, we let each student randomly rank from 1 to 20 projects in the set of projects offered by all lecturers. We set the total capacity σ of projects offered by all lecturers as n, i.e., σ = n. Then, we distributed σ randomly to the capacity c
j
of each project p
j
∈ P to ensure that
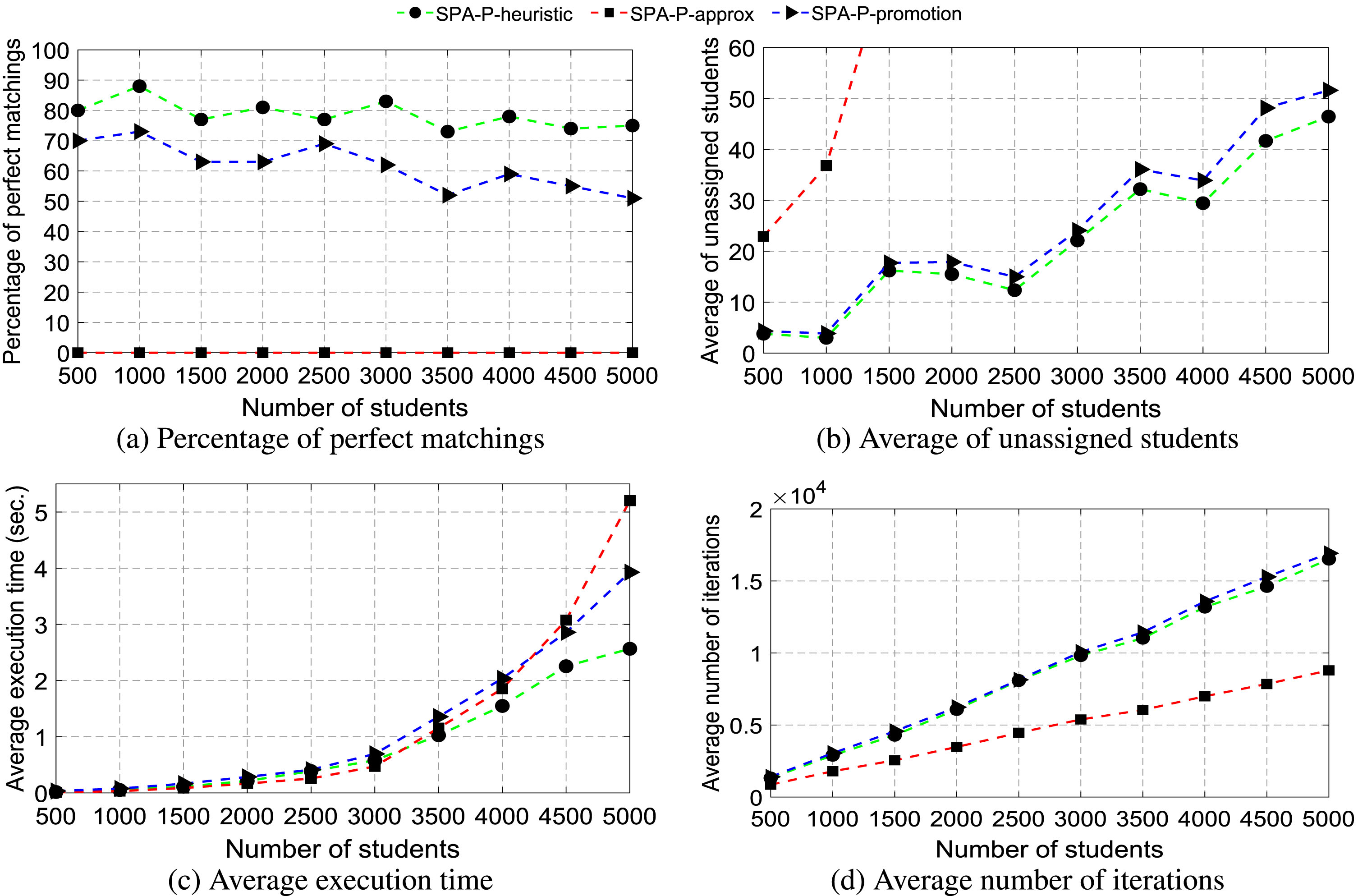
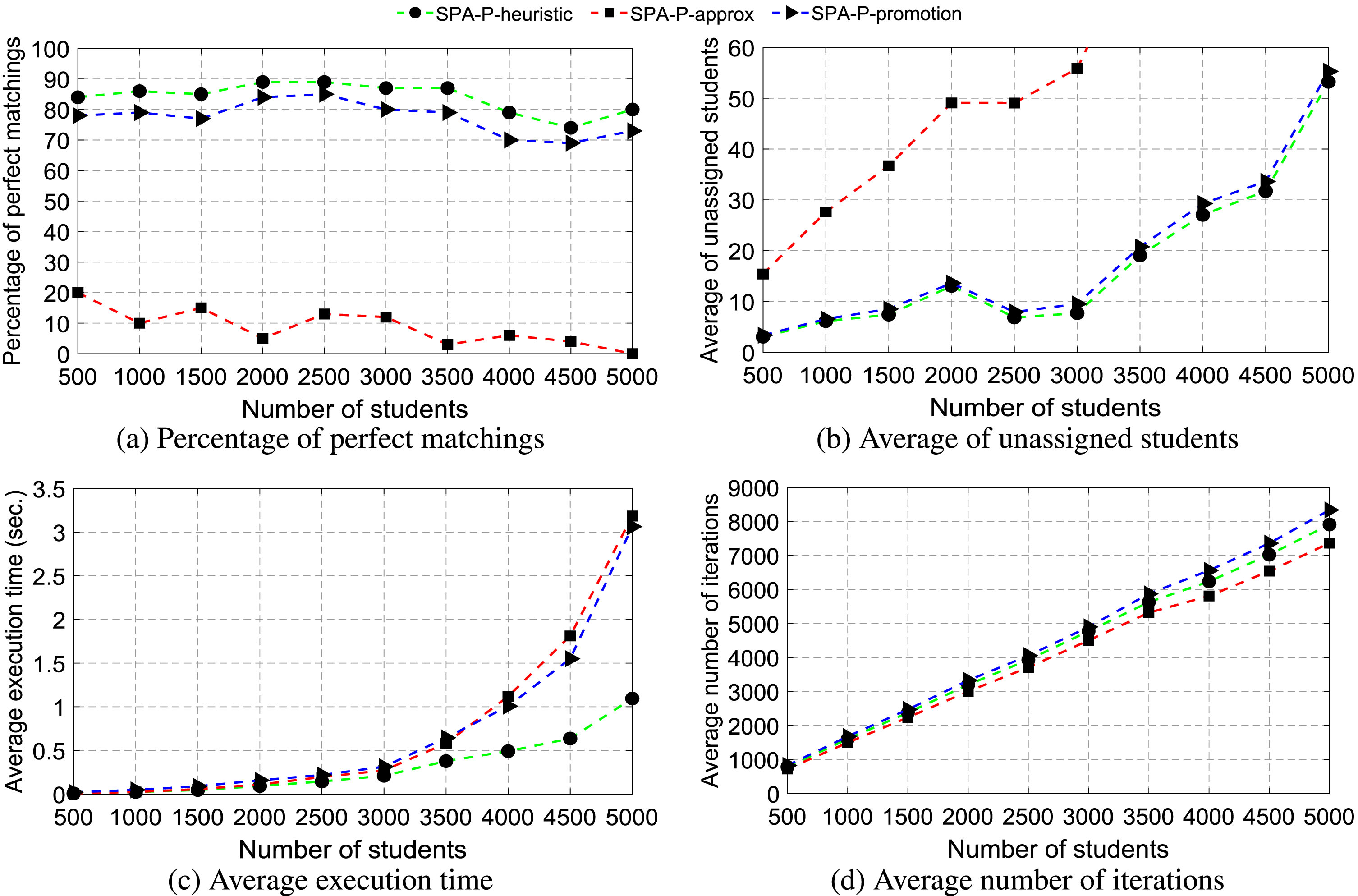
Figure 1(a) shows the percentage of perfect matchings found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When n increases from 500 to 5000 with steps 500, SPA-P-heuristic finds a much higher percentage of perfect matchings than SPA-P-promotion and SPA-P-approx. Specifically, SPA-P-heuristic finds from 73% to 88% of perfect matchings, SPA-P-promotion finds from 51% to 73% of perfect matchings, while SPA-P-approx fails to find any perfect matchings of SPA-P instances.
Figure 1(b) shows the average number of unassigned students found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When n increases from 500 to 5000 with steps 500, SPA-P-approx finds stable matchings with more than 22 unassigned students. Meanwhile, SPA-P-heuristic finds fewer unassigned students in stable matchings than SPA-P-promotion. This means that the stable matchings found by SPA-P-heuristic are larger than those found by SPA-P-promotion in terms of size.
Comparing solution quality and execution time of SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms.
Figure 1(c) shows the average execution time of SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When n increases from 500 to 5000 with steps 500, the average execution time of SPA-P-approx increases from 0.0097 seconds to 5.2027 seconds, the average execution time of SPA-P-promotion increases from 0.0327 seconds to 3.9276 seconds, and the average execution time of SPA-P-heuristic increases from 0.0150 seconds to 2.5655 seconds. We see that when n ≥ 4000, SPA-P-heuristic runs about two times faster than SPA-P-promotion and SPA-P-approx.
Figure 1(d) shows the average number of iterations found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. We see that the average number of iterations found by SPA-P-heuristic is slightly smaller than that found by SPA-P-promotion, but larger than that found by SPA-P-approx. However, the average execution time of SPA-P-heuristic is much smaller than that found by SPA-P-promotion and SPA-P-approx, meaning that at each iteration, SPA-P-heuristic needs a smaller computation than SPA-P-promotion and SPA-P-approx.
In this experiment, we chose the values of parameters n, m, and q as those constraints in Experiment 1. In each randomly generated instance of SPA-P, we set each student to rank randomly from 1 to 20 projects in the set of projects offered by all lecturers. Moreover, we set the total capacity σ of projects offered by all lecturers as 1.1n, i.e., σ = 1.1n, and distributed σ randomly to the capacity c
j
of each project p
j
∈ P such that
Figure 2(a) shows the percentage of perfect matchings found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When n varies from 500 to 5000 with steps 500, SPA-P-heuristic finds from 74% to 89% of perfect matchings, SPA-P-promotion finds from 69% to 85% of perfect matchings, while SPA-P-approx finds only from 0% to 20% of perfect matchings. It is obvious that SPA-P-heuristic finds a higher percentage of perfect matchings than SPA-P-promotion and SPA-P-approx. Compared to Experiment 1, we can see that when the total capacity of projects increases, i.e., the capacity of each project increases, it is easy for these algorithms to find perfect matchings in SPA-P instances.
Figure 2(b) shows the average number of unassigned students found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When n increases from 500 to 5000 with steps 500, SPA-P-approx results in stable matchings with more than 15 unassigned students. In contrast, SPA-P-heuristic yields stable matchings with fewer unassigned students than SPA-P-promotion. This means that the stable matchings found by SPA-P-heuristic are larger than those generated by SPA-P-promotion in terms of size.
Figure 2(c) shows the average execution time of SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When n varies from 500 to 5000 in increments of 500, the average execution time of SPA-P-approx increases from 0.0083 seconds to 3.1844 seconds, the average execution time of SPA-P-promotion increases from 0.0220 seconds to 3.0629 seconds, and the average execution time of SPA-P-heuristic increases from 0.0083 seconds to 1.0946 seconds. This shows that SPA-P-promotion and SPA-P-approx exhibit similar execution time, while SPA-P-heuristic runs approximately three times faster than both SPA-P-promotion and SPA-P-approx.
Figure 2(d) shows the average number of iterations used by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. As in Experiment 1, we can see that SPA-P-heuristic used a smaller number of iterations than SPA-P-promotion, but a larger number of iterations than SPA-P-approx. Moreover, we can see that when the total capacity of projects increases, all these three algorithms not only find stable matchings faster than those, but also use a smaller number of iterations compared to those in Experiment 1.
Experiment 3

Comparing solution quality and execution time of SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms.
In this experiment, we chose n = 5000 and varied the total capacity σ of projects offered by all lecturers from 0.8n to 1.5n with steps 0.1n, i.e., σ varied from 4000 to 7500 with steps 500. For each combination of parameter values n and σ, we generated 100 instances of SPA-P, in which other parameters were set as follows: (i) m and q were random integer numbers constrained by 0.02 ≤ m ≤ 0.1n and 0.1n ≤ q ≤ 0.4n, i.e., 100 ≤ m ≤ 500 and 500 ≤ q ≤ 2000; (ii) σ was distributed randomly to the capacity c
j
of each project p
j
∈ P such that
Figure 3(a) shows the percentage of perfect matchings found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. We see that when the total capacity σ ∈ {4000, 4500}, all these three algorithms cannot find any perfect matching since we have σ < n, i.e., the total capacity σ of projects is not enough slots for n students. However, when σ = 5000, i.e., each project has only a slot for each student, all these three algorithms cannot find any perfect matching. When σ increases, the percentage of perfect matchings found by these algorithms increases since the capacity of projects and lecturers increases. However, SPA-P-heuristic finds a higher percentage of perfect matchings than SPA-P-approx and SPA-P-promotion.
Figure 3(b) shows the average of unassigned students found by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When σ increases, the average of unassigned students found by these algorithms decreases, meaning that the sizes of stable matchings increase. Moreover, we see that SPA-P-heuristic finds stable matchings whose sizes approximate those of SPA-P-promotion (i.e., the green line overlaps the blue line) but are larger than those of SPA-P-approx.
Figure 3(c) shows the average execution time of SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. When σ increases, the average execution time found by these algorithms decreases since the capacity of projects and lecturers increases, making these algorithms find stable matchings easier. When σ increases from 4000 to 7500, the average execution time of SPA-P-heuristic decreases from 7.66 seconds to 0.36 seconds, the average execution time of SPA-P-approx decreases from 53.28 seconds to 0.75 seconds, and the average execution time of SPA-P-promotion decreases from 113.82 seconds to 0.78 seconds. When σ = 4000, SPA-P-heuristic runs about 15 times faster than SPA-P-promotion and about 7 times faster than SPA - P - approx. When σ ≥ 5500, SPA-P-heuristic runs about 2 times faster than SPA-P-promotion and SPA-P-approx. In particular, when σ decreases from 5000 to 4000, the execution time of SPA-P-approx and SPA-P-promotion significantly increases, while that of SPA-P-heuristic almost remains unchanged.
Figure 3(d) shows the average number of iterations used by SPA-P-heuristic, SPA-P-approx, and SPA-P-promotion algorithms. As in Experiments 1 and 2, we see that SPA-P-heuristic used a smaller number of iterations than SPA-P-promotion, but a larger number of iterations than SPA-P-approx.
In summary, we see from the three experiments above that SPA-P-heuristic outperforms SPA-P-approx and SPA-P-promotion in solution quality and execution time. This can be explained as follows: In SPA-P-approx, there are two main reasons to show that this algorithm performed poorly in finding maximum matchings for SPA-P instances. Firstly, when an unassigned student s
i
with a non-empty list chooses the first project p
j
in her/his list, if p
j
is full, then p
j
is not assigned to s
i
. However, if s
i
has only a project p
j
in her/his list and if the algorithm does not assign p
j
to s
i
, then s
i
is single. Since M (p
j
) is a set of students assigned to p
j
, if the algorithm removes some student from M (p
j
) and assigns p
j
to s
i
, then s
i
is not single. Secondly, when a student s
i
is assigned to a project p
j
in her/his list, meaning that s
i
is assigned to a lecturer l
k
who offered p
j
. If l
k
is over-subscribed, the algorithm removes an arbitrary student s
r
from M (p
z
), where p
z
is l
k
’s worst non-empty project, and deletes p
z
in s
r
’s list. If s
r
remains only a project p
z
in her/his list, then s
r
becomes single. Since M (p
z
) is a set of students assigned to p
z
and in this case, the algorithm should remove another student from M (p
z
) rather than s
r
. Moreover, removing an arbitrary student s
r
from M (p
z
) makes the algorithm find a stable matching difficult, leading to inefficient execution time. In SPA-P-approx-promotion, If a project p
j
is full, the algorithm removes an arbitrary student s
r
from M (p
j
) and adds (s
i
, p
j
) to M. If a lecturer l
k
is over-subscribed, the algorithm removes an arbitrary student s
r
from M (p
z
), where l
k
is the lecturer who offered p
j
and p
z
is l
k
’s worst non-empty project in M (l
k
). Similar to SPA-P-approx, removing an arbitrary student s
r
in M (p
j
) or M (p
z
) is a weak point of SPA-P-approx-promotion. Moreover, when a student s
i
with a non-empty list is unpromoted, she/he is allowed to recover her/his original list once again to find a project again in her/his list. This makes the algorithm inefficient in execution time. In SPA-P-heuristic, our heuristic functions f (x) and g (x) given in Equations \eqref eq:fx and \eqref eq:gx are used to keep the students in M who have the least opportunity to be reassigned to projects in their lists and remove the students in M who have the most opportunity to be reassigned to projects in their lists. Therefore, our SPA-P-heuristic solves the weaknesses of SPA-P-approx and SPA-P-promotion algorithms.
Finally, the scenarios of our experiments, where n = 5000, m ranges from 100 to 500, and q ranges from 500 to 2000, show that our SPA-P-heuristic results in maximum stable matchings in approximately 1.0 to 7.0 seconds. This underscores the remarkable efficiency of SPA-P-heuristic for dealing with large SPA-P instances.
In this paper, we propose a SPA-P-heuristic algorithm to find maximum stable matchings of SPA-P instances. At the beginning, our algorithm initializes a matching to be empty and sets all the students to be active. At each iteration, our algorithm finds an active student with a non-empty list. If such a student exists, our algorithm assigns to her/him the most preferred project in her/his list to form a student-project pair in the matching. If the assigned project overcomes its capacity, our algorithm uses a heuristic function to remove the worst student among students assigned to the project in the matching. If the lecturer who offered the project overcomes her/his capacity, our algorithm uses another heuristic function to remove the worst student among students assigned to the lecturer in the matching. When a student is assigned to a project, she/he becomes inactive. When a student removes a project assigned to her/him, she/he deletes the project from her/his list and becomes active again. Our algorithm repeats until all the students are inactive. We show that our algorithm returns a stable matching after a finite number of iterations. Our experimental results over all the tested scenarios show that our SPA-P-heuristic algorithm outperforms SPA-P-approx and SPA-P-promotion algorithms regarding solution quality and execution time for SPA-P instances of large sizes.
The SPA-P problem consists of variants such as the Student-Project Allocation with preferences over Projects with Ties (SPA-PT), the Student-Project Allocation problem with lecturer preferences over Students (SPA-S) [2], or the Student-Project Allocation problem with lecturer preferences over Students with Ties (SPA-ST) [4, 14]. Therefore, our approach can be extended by defining suitable heuristic functions to solve these problems efficiently.