
Abstract
Contrastive learning is a powerful technique for learning feature representations without manual annotation. The K-nearest neighbor (KNN) method is commonly used to construct positive sample pairs to calculate the contrastive loss. However, it is challenging to distinguish positive sample pairs, reducing clustering performance. We propose a novel
Keywords
Introduction
Image clustering is an unsupervised learning method that groups images into different clusters based on a predefined similarity measure without manual annotation. The goal is to maximize the similarity between samples in a cluster and the difference between samples in different semantic clusters [1, 2]. The representation capability of an unsupervised deep learning model is crucial for image clustering tasks. The quality of the learned representations directly affects the clustering performance.
Self-supervised learning (SSL) has shown significant performance improvements for predictive coding [3], multi-task learning [4], contrastive learning [5], and other tasks in related fields [6]. The goal of SSL is to train a model for learning useful representations by leveraging self-supervision tasks. These learned representations can be used for downstream tasks, such as classification and object detection. Pseudo-labels are a useful tool but not a necessary component of the SSL framework. Contrastive learning-based deep clustering models utilize positive and negative sample pairs to minimize the normalized temperature-scaled cross-entropy loss function (NT-Xent) [7]. These approaches have generated discriminative and general features in the latent space, resulting in higher clustering performance.
Information on the neighborhood, i.e., spatial information surrounding the pixel of interest, guides the learning tasks. In the Semantic Clustering by Adopting Nearest Neighbors (SCAN) method [8], high-level semantic features are obtained by accurately matching nearest neighbors. The clustering loss is obtained by maximizing the similarity between a sample and the k-nearest neighbors. In graph contrastive clustering (GCC) [9], the number of positive sample pairs in the sample’s nearest neighbors is maximized to improve the clustering performance.
However, a sample and its nearest neighbors may not belong to the same semantic cluster, i.e., they are false positive sample pairs. As shown in Fig. 1, the first sample represents a query, and the following five samples represent its nearest neighbors. Three of the five neighbors are correctly identified (green circles), while two are incorrectly identified (red circles). When false positive pairs are used as semantically similar samples and are assigned to a cluster, the representation capability of the network decreases, and the solution uncertainty increases.

The semantic inconsistency between a sample and its nearest neighbors (STL-10 dataset).
To reduce the semantic inconsistency between a sample and its neighbors, we select k-nearest neighbors with high similarity. Next, a two-layer graph convolutional network (GCN) instead of a multilayer perceptron (MLP) is utilized. The connected nodes share the same semantic cluster in network-based classification when the adjacency matrix and Laplacian matrix are constructed [10].
Inspired by the MixUp algorithm [11], we use two different augmented views of an image to create a new image, increasing sample diversity and the number of positive samples. The contrastive loss is used to increase the similarity between positive sample pairs, which is consistent with the goal of feature learning, i.e., to learn the inherent feature representation of the augmented views. The main contributions of this paper are as follows:
(1) A new contrastive clustering method is proposed by leveraging an instance-level contrastive loss with mean square error (MSE) regularization and a cluster-level contrastive loss with cross-entropy regularization.
(2) A GCN is utilized as a feature projector to improve the semantic consistency of features. Samples whose similarity exceeds a predefined threshold are selected to reduce the potential for false positive sample pairs while constructing the adjacency matrix.
(3) Linear interpolation data augmentation is employed to increase sample diversity, reduce training difficulty, and improve the representation ability of the model.
The experimental results demonstrate that the GHDCC is an efficient deep contrastive clustering method.
Self-supervised representation and clustering
The earlier work of contrastive concept was proposed by Hadsell et al. in 2006 [12] to optimize the contrastive loss over pairs of samples. The classic contrastive learning method SimCLR [5] (a simple framework for contrastive learning of visual representation) was proposed by Hinton’s team. The two augmented views are considered a positive pair and are assumed to have a highly similar feature space, resulting in the same semantic cluster. The SimCLR learns the discriminative features by minimizing the normalized temperature-scaled cross-entropy loss (NT-Xent) to identify positive pairs across the dataset. This approach represented a breakthrough in self-supervised feature representation. Contrastive-based methods [13, 14] became popular after the introduction of the SimCLR method. Contrastive clustering (CC) [15] uses dual contrastive learning for deep clustering. It is an improved version of the SimCLR method and uses contrastive learning at the instance and cluster levels. The CC model jointly learns representations and cluster assignments in an end-to-end fashion. However, the CC performance is significantly influenced by the sample size. The model has a long runtime, and 8 threads are required for 160 GPU hours on the STL-10 dataset.
The SCAN method [8] is a two-stage method combining feature representation and cluster assignment. An image and its nearest neighbors are assumed to belong to the same semantic cluster. High-confidence samples are selected by thresholding the probability output provided by clustering. Pseudo-supervised learning is used to fine-tune the clustering parameters and the cluster assignments. The unsupervised visual representation algorithm (CoKe) [16] learns the relationship between instances based on the online constrained K-means. This online clustering method enables representation learning without interrupting encoder training. Another novel semantic clustering by partition confidence maximization (PICA) [17] was proposed. It learns representation features during training and the one-hot encoded cluster indices during testing by maximizing the global partition confidence of the clustering solution.
A nearest neighbor matching (NNM) clustering method [18] similar to SCAN was proposed to obtain semantic sample pairs with high confidence by optimizing the global and local consistent losses and class contrastive loss. This approach assesses the semantic sample relationships between local and global features, resulting in high clustering performance and low solution uncertainty. Neighborhood contrastive learning (NCL) learns discriminative features from the labeled data and has been used for novel class discovery (NCD) [19] using an unlabeled dataset. Semi-supervised NCL performs well and assumes that similar samples belong to the same class.
The Semantic Pseudo-labeling framework for Image ClustEring (SPICE) [1] divides the clustering network into a feature backbone and a cluster projector. Training is performed using contrastive learning and a pseudo-label algorithm, respectively. SPICE significantly reduces the gap between unsupervised and fully supervised classifications.
This paper proposed a self-supervised method, leveraging the pairwise similarity of positive/negative samples and analyzing the neighborhood using GCNs for unlabeled data. The method minimizes the occurrence of false positive pairs and has the benefits of neighborhood aggregation.
Data augmentation
Fan et al. [20] proposed a novel self-expert cloning technique to decouple robust representation learning using weak and strong augmentations. Random cropping is a type of weak augmentation. Strong augmentation refers to images with heavy distortion. The MixUp [11] method is a simple learning principle utilizing vicinal risk minimization (VRM). It trains a neural network on convex combinations of example pairs and their labels to reduce the risk of memorization and sensitivity to adversarial examples. Manifold MixUp [21], a variant of MixUp, uses semantic interpolations as additional training information to regularize the network for smoother decisions. The Co-Mixup method [22] maximizes saliency measurements to ensure super-modular diversity, significantly improving the cropping result.
The CutMix [23] method randomly crops a rectangular area and exchanges two rectangular patches to generate two augmented feature maps. The labels are mixed proportionally to the area of the patches. The network trained by the CutMix augmentations has a higher generalization ability and better object localization capability than the Cutout method. PatchUp [24] is another data augmentation method that crops patches to obtain the outputs in the hidden layer. Experimental results have shown that replacement-based methods provide higher recognition accuracy, and interpolation-based methods have higher robustness against attacks.
Graph convolutional network
A multilayer GCN was first proposed by Kipf and Welling [25] to classify graph-structured data with a few labels. The GCN is a variant of convolutional neural networks (CNNs) [26] with layer-wise propagation and contains a Laplacian matrix:
GCN-based classification [27] and face clustering [28] methods have made significant progress because the edges of the GCN encode the nodes’ similarities, providing additional information to improve model performance. Xie et al. [29] proposed an active and semi-supervised graph neural network (ASGNN) to deal with the scarcity of labeled graphs in graph classification. It is a semi-supervised active learning method that increases the number of pseudo-labeled graphs.
Another GCN-based semi-supervised method, GCN and semantic feature guidance for deep clustering (GFDC) [30] was used for deep clustering. A GCN with a Softmax output layer enables the discrimination of visual features for clustering. However, when the categories of two different datasets do not match completely, the clustering error increases significantly. Thus, we use positive and negative pair-based dual contrastive learning with GCN projectors for deep clustering in this study. It is an unsupervised method without any predefined annotations.
Methodology
We aim to group a set of images into several disjoint clusters without semantic labels. We propose the deep clustering method GHDCC, which consists of a feature extractor and a clustering projector. The parameters of the GHDCC are learned using the contrastive loss of sample discrimination as a pretext task. The goal of contrastive learning is to obtain the optimal feature representation by maximizing the similarity between positive sample pairs and minimizing the similarity between negative sample pairs. The proposed GHDCC can improve clustering performance and reduce the risk of generating degenerate solutions. The framework of the proposed GHDCC is shown in Fig. 2.

The framework of the GHDCC model.
For the given image dataset X = {x1, x2, . . . , x
N
}, the goal of clustering is to allocate all samples into several disjoint clusters C = {C1, C2, ⋯ , C
K
}, where N is the number of samples, and K is the number of predefined clusters. Contrastive clustering has two preprocessing steps. First, two of the five augmentation methods (random cropping, color jittering, grayscale, horizontal flip, and Gaussian blur) are randomly selected and are denoted as T
a
and T
b
. The original sample x
i
generates two augmented samples
The GHDCC model consists of two GCNs that perform feature extraction. Each node contains information on itself and its neighbors in the latent space H [31]. The GCN, instead of a two-layer perceptron, guides the backbone network to learn the semantically discriminative features. The outputs of GCNs are allocated into several disjoint groups using the K-means algorithm.
Contrastive loss of GCN projectors
Matrix A is a normalized adjacency matrix representing the semantic affinity between the nodes and their nearest neighbors using the cosine distance. The fine-tuned features Z
a
and Z
b
are expected to be more representative and useful for clustering. For a given feature
The instance-level contrastive loss is defined as:
The similarity of the positive pair is maximized, and those of the negative pairs are minimized while minimizing L
ins
. In addition, the MSE between
Its output is the K-dimensional features YN×K, and K is the predefined number of clusters. Hard label clustering means that a sample is classified into a cluster. The row vector
The cluster-level total contrastive loss is defined as:
The linear interpolation (
To this end, we optimize the Kullback-Leibler (KL) divergence between the two probability distributions to refine the representative ability of the backbone network. Thus, KL divergence loss is:
Minimizing Equation (7) is equal to minimizing the cross-entropy (Equation (8)):
Our backbone network ResNet34 is followed by a GCN; however, it is not an MLP as in CC [15] and SimCLR [5]. The feature and structural information is fed into the GCNs, resulting in high semantic similarity. Thus, our deep clustering method has the advantages of contrastive learning and a local neighborhood.
Two types of graphs are used. We concatenate three group features into
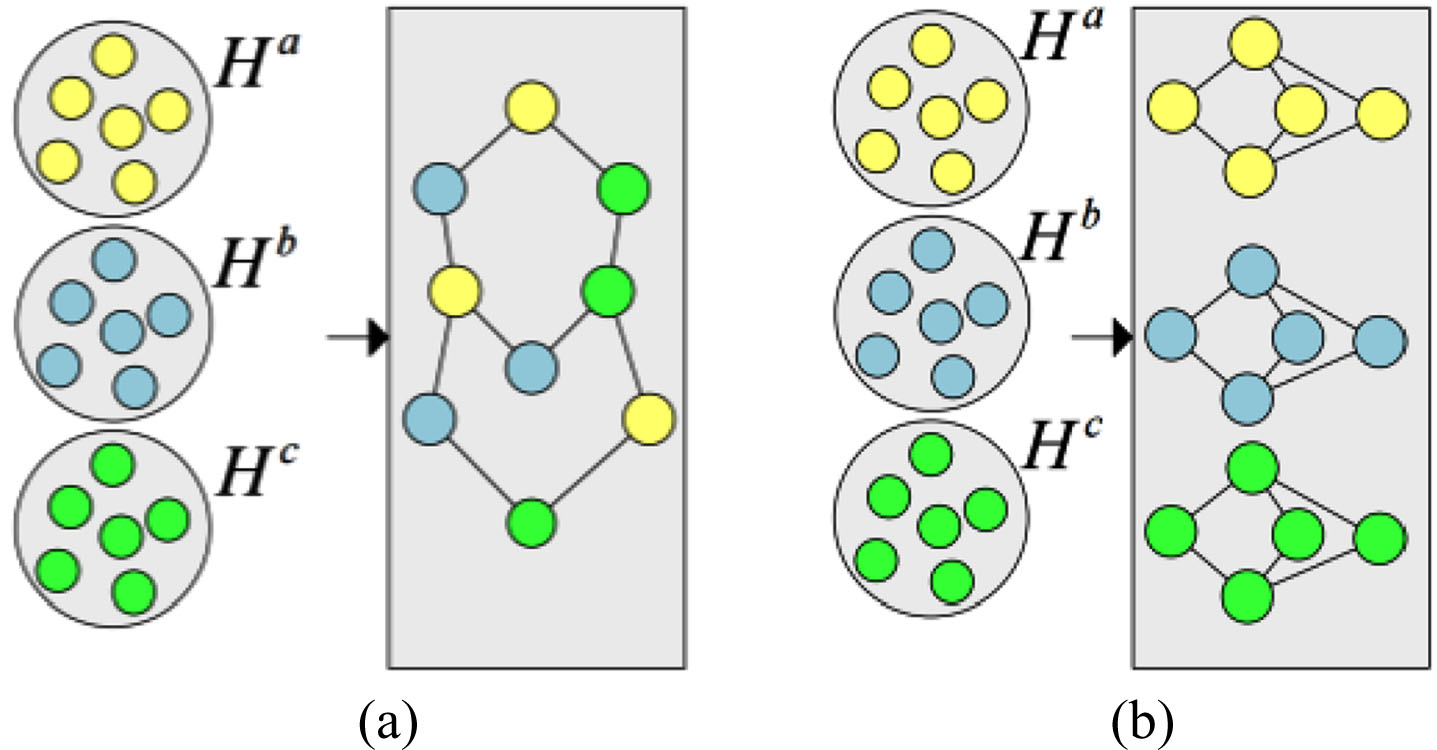
Two types of topological graphs.
The other is called a concatenated graph in Fig. 3(b). Three smaller topological graphs and adjacency matrices are constructed according to {H a , H b , H c } and concatenated to obtain a larger adjacency matrix. The mixed graph provides better clustering than the concatenated graph.
Equations (2), (3), (5), and (8) are combined. The total loss of the proposed GHDCC method is defined as:
The training process of the clustering model GHDCC is summarized in Algorithm 1.
Complexity of the GHDCC algorithm is evaluated by the number of parameters and floating point operations(FLOPs). FLOPs can measure the computation complexity of a deep algorithm/model.
The GHDCC model is composed of ResNet34, two GCNs and K-means clustering. First, standard ResNet34 network has 34 convolutional layers without pooling and one fully-connected layer. Second, the parameters of two fully-connected networks are 2 * f in * f out that is far fewer than those of ResNet34. Third, time and space complexity of K-means clustering algorithm can be reduced to O(N), where N is the number of samples. Overall, the complexity of GHDCC algorithm is mainly the training of ResNet34.
Thus, the total number of parameters is about 200 w that is amount to 83MB. FLOPs is amount to about 3.4 G.
Implementation details
The six image datasets used in the experiments are briefly described in Table 1.
Information on the datasets used in this paper
Information on the datasets used in this paper
We resize all input images to 64×64; the batch size is 128, and the learning rate is 2e - 4. The GHDCC framework contains a ResNet34 and two GCNs. ResNet34 reduces the inputs to 128-dimensional features. GCN1 and GCN2 perform feature extraction, and the outputs are 128-dimensional and K-dimensional. Adaptive moment estimation (Adam) [35] is used as the optimizer. The GHDCC model is trained using 500 epochs. The linear interpolation parameter is λ = 0.7. The trade-off parameters are λ1 = λ2 = 0.5, and the temperature parameters are τ1 = 0.5 and τ1 = 1. The GHDCC model is built using Python 3.7 under the Pytorch framework; and the experiments are carried out on Nvidia RTX 3060 GPU.
The GHDCC model is evaluated using the clustering accuracy (ACC) [36], normalized mutual information (NMI) [37], and the adjusted Rand index (ARI) [38]. The larger the value of these indicators, the better the clustering performance of the model is.
Comparison experiments were conducted. CC and GCC are two competitive comparators. The comparison results with other clustering methods are listed in Table 2. The accuracies are obtained by running the original codes in our experimental environment. The best results are shown in bold, and the second-best results are underlined. The clustering results indicate that the GHDCC algorithm provides good performance. The SPICE method provides the highest clustering accuracy of 0.959, 0.926, and 0.938 on the ImageNet-10, CIFAR-10, and STL-10 datasets, respectively, outperforming the proposed GHDCC algorithm by a large margin. The reason is maybe the limited hardware and the smaller image size.
Comparison of the accuracies of the GHDCC and several baseline methods
Comparison of the accuracies of the GHDCC and several baseline methods
Note: “*” denotes the clustering accuracy obtained in a previous study, “-” denotes no value available. The best results of the last two rows are shown in bold, and the second-best results are underlined.
We assessed the training cost of the backbone network and the hardware requirements of CC (the input image is 224×224, the batch size is 256, and there are 1000 training epochs. The shortest running time on the GPU is 20 hours, and the longest is 160 hours). The similar situation is for the GCC. Due to the limitation of hardware, we retrained the ResNet34 using 64×64 input images and the other default training parameters of CC. We report the clustering accuracy in 500 training epochs (CC (500)) and then train the GHDCC model. The results are listed in Table 2.
The GCC and GHDCC are two variants of the CC method. They both use the k-nearest neighbors to increase the number of positive sample pairs and improve clustering performance. As shown in Table 2, our method outperforms the GCC and CC (1000) by 1.2% and 2% on ImageNet-10 and by 10.2% and 10% on Image-dogs, respectively. However, it performs the worst on the other four datasets. The reason is that the batch size and input image size of the GHDCC are significantly smaller than those of the GCC and CC (1000).
The GHDCC significantly outperforms CC (500) by a large margin, except on CIFAR-10. The clustering accuracy of GHDCC is 10.5% higher than that of CC (500) on Tiny-ImageNet. Furthermore, the GHDCC shows comparable performance to most state-of-the-art methods.
As shown in Table 3, the three evaluation indicators are consistent, indicating reliable clustering results. The GCN1 uses t-distributed stochastic neighbor embedding (t-SNE) [42] (Fig. 4). Different colors represent different clusters. It is observed that the distance between the clusters increases during iterative optimization.
Clustering performances of the GHDCC on six datasets

Visualization of the GCN1 features after training GHDCC on ImageNet-10.
Three ablation studies were conducted to verify the performance of the components of the proposed method.
First, the impact of the adjacency matrix (Section 3.3) on the clustering results was tested on ImageNet-10. The mixed graph pattern provides 0.913 clustering accuracy, and the concatenated graph has an accuracy of 0.812. The comparison indicates that the mixed graph can extract higher discriminative features.
Second, the two-layer MLP was compared with the GCN; both were implemented as projectors after ResNet34. The features are visualized in Fig. 5. The first column in Fig. 5 shows the features extracted by ResNet34 and ResNet34 + MLP. The second column shows the features extracted by ResNet34 and ResNet34 + GCN.
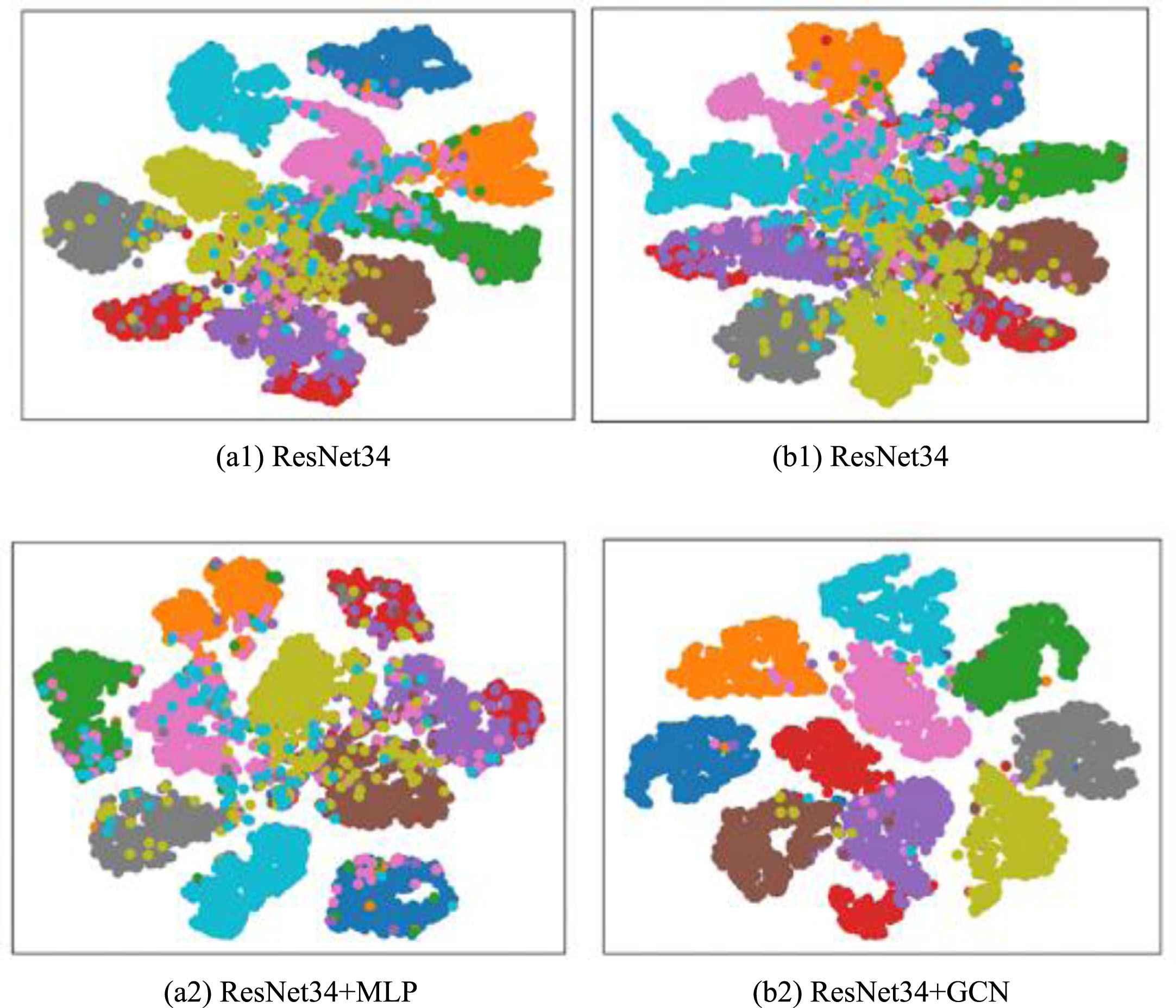
Visualization of the features obtained from projectors MLP and GCN on ImageNet-10.
The results indicate that the boundary between the clusters is better defined in Fig. 5 (b2) than in Fig. 5 (a2), and the samples in the clusters are more compact. In addition, the clusters in Fig. 5 (b1) are not as well defined as those in Fig. 5 (a1). Thus, the GCN better describes the relationship between the samples and minimizes solution uncertainty.
Third, linear interpolation data augmentation was used to increase the sample size. The parameter λ in the linear interpolation substantially influences the quality of the data set and the experimental results. Therefore, we tested different λ values on several datasets. The results of ImageNet-Dogs are shown in Fig. 6. The optimal clustering accuracy is λ = 0.7.
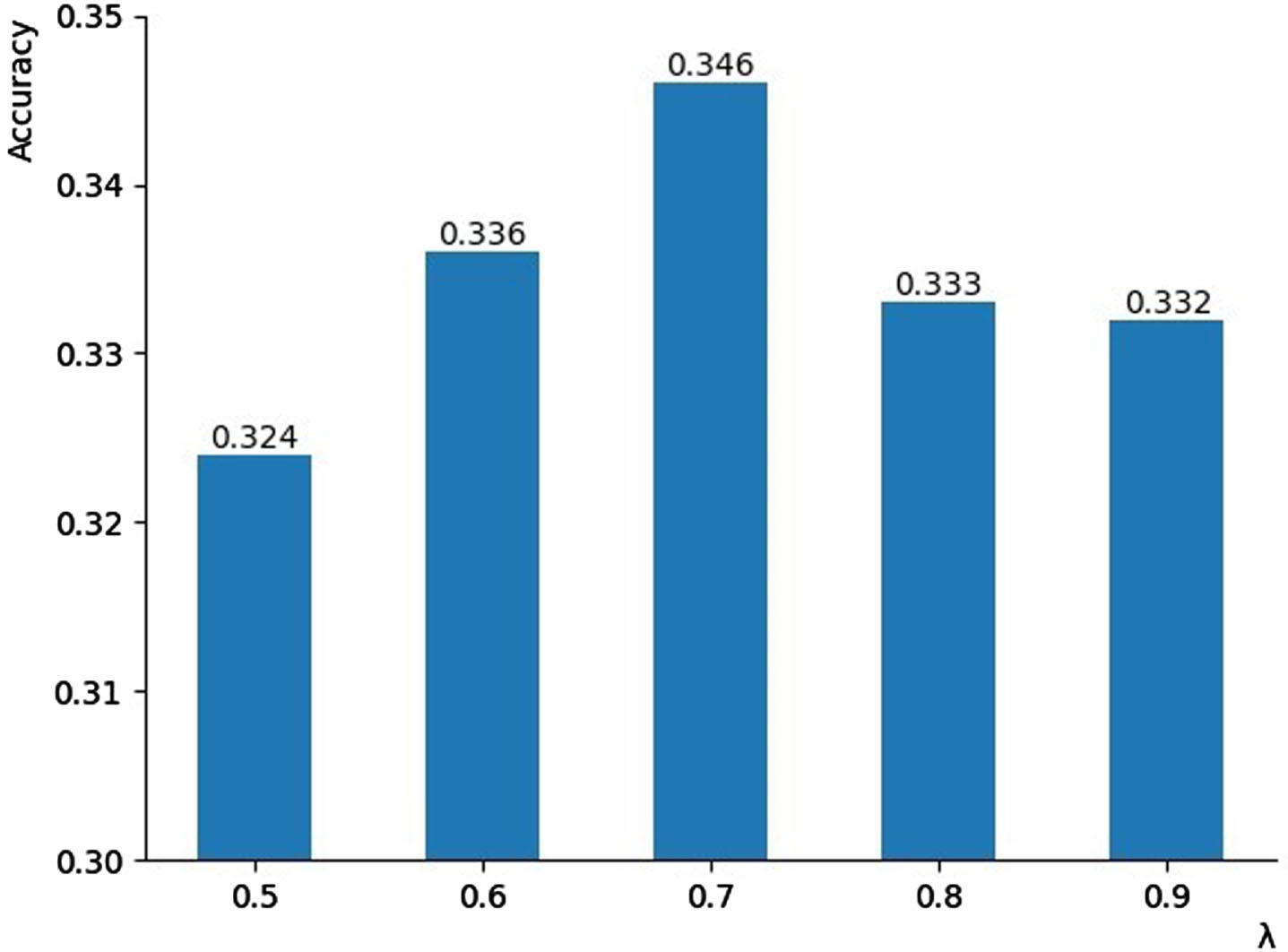
The effect of the λ values on the clustering accuracy on ImageNet-Dogs.
The clustering accuracies obtained from the ablation experiments are listed in Table 4. The projector GCN significantly improves the clustering accuracy of the GHDCC method. Linear interpolation data augmentation also improves the performance of the GHDCC method.
Clustering accuracies of the GHDCC components in the ablation experiments
The confusion matrices on ImageNet-10 are shown in Fig. 7. The diagonal elements represent the number of correctly classified samples. A brighter yellow color indicates that more samples are correctly classified. Replacing the MLP with the GCN, i.e., Fig. 7(b) vs. Fig. 7(a) significantly improves the clustering accuracy. The accuracy of the GHDCC algorithm is 0.913 when linear interpolation data augmentation is used (Fig. 7(c)).
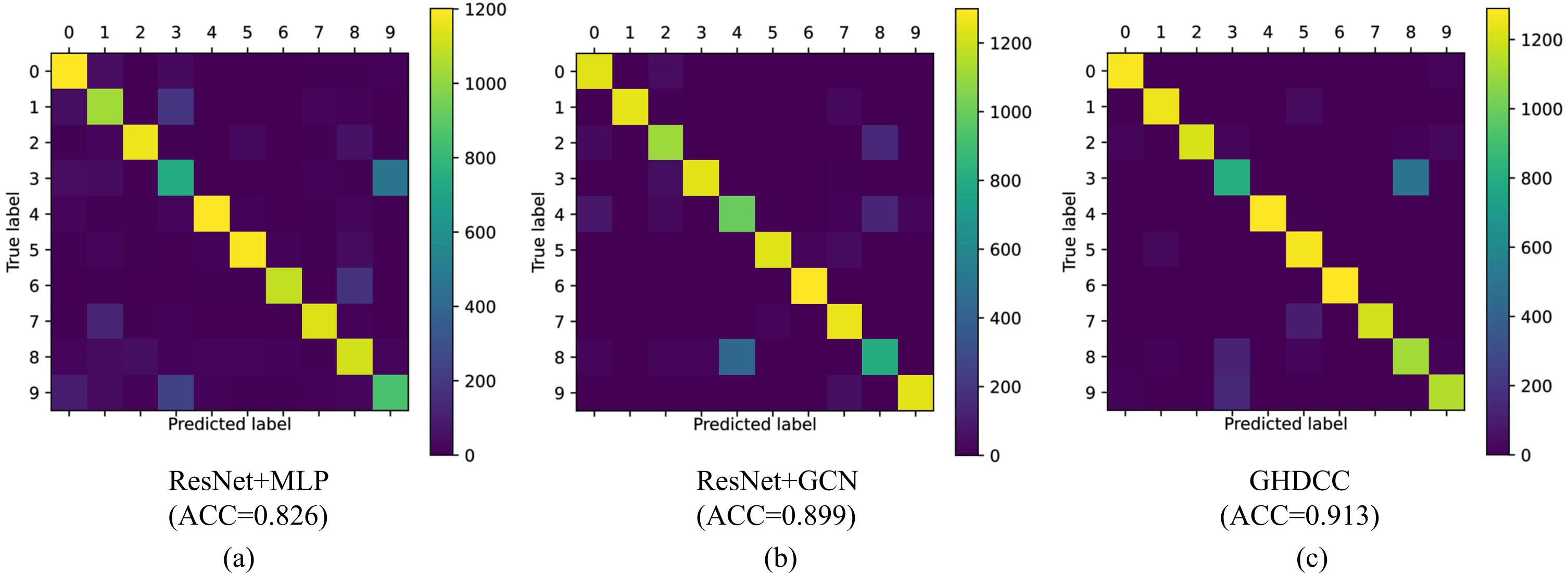
Confusion matrix of the GHDCC on ImageNet-10.
The paper proposed a self-supervised learning approach called GHDCC for image clustering. It uses contrastive clustering to learn more discriminative features. GHDCC utilizes a GCN and a convex combination of data to prevent false positive samples and improve the extraction of semantic features. The experimental results demonstrated that GHDCC achieved improved clustering performance on six baseline datasets and outperformed most state-of-the-art clustering methods evaluated in this study. The ablation study results indicated that every component of the GHDCC model contributed to improving the clustering performance.
However, the clustering performance of GHDCC was limited by the small image size, affecting the pixel-level information. We plan to improve the GHDCC’s performance by using a larger image size and a higher-capacity GPU. Another objective is to use the GHDCC model for image inpainting via Features Fusion and Two-steps Inpainting algorithm (FFTI) [43] in the Expectation-Maximization (EM) framework.