
Abstract
With explosive growth of industrial big data, workshop scheduling faces problems such as high complexity, multi-dimensionality and low stability. Recent years, the wide application of deep learning provides new idea for scheduling problem. In this paper, a hybrid deep convolution network and differential evolution algorithm is proposed to solve the non-permutation flow shop scheduling problem with the goal of minimizing total completion time. Mining relationship between job attributes and process priority by deep convolutional network is core idea of this method. In this paper, differential evolution algorithm is used to obtain the data set for deep learning, and neighborhood search algorithm is used to optimize scheduling solution. Additionally, a method combining k-means algorithm and data statistics is proposed, which provides a reasonable way for priority division. The experimental results show that this method can greatly improve scheduling efficiency.
Keywords
Introduction
Workshop scheduling is related to production efficiency and affects competitiveness of enterprises, flow shop as a common type of workshop has been widely studied for a long time [1, 2]. There are two types of flow shop: permutation and non-permutation. The jobs maintain the same processing order in all stages is permutation flow shop (PFS), relaxing the constraint of job processing order is non-permutation flow shop (NPFS) [3]. Non-permutation flow shop scheduling problem (NPFSSP) studies that n independent jobs are processed by m machines in turn, the processing order in different stages can be different, which makes general and practical [4–6].
NPFSSP has been proved to be NP-hard when the number of machines is larger than three [7]. At present, there are mainly three methods to solve NPFSSP: precise algorithm, heuristic algorithm and deep learning method. The precise algorithm can usually find the best solution accurately by searching all solutions according to certain rules. However, scheduling problem is usually complex, as the scale of problem expands, the solution space will increase exponentially [8], which makes solution time increase. Therefore, precise method is usually suitable for small-scale problems.
Heuristic algorithms abstract some phenomena from nature and biological populations into algorithms, and obtain an approximate optimal solution after several iterations [9]. This method can find a feasible solution for scheduling problem within acceptable solution time. However, with the expansion of problem scale, the heuristic algorithms have some randomness in search process, which may lead to unstable feasible solutions. Nevertheless, heuristic algorithms iterate according to specific rules, which makes optimal solutions have certain similarity, that is “survivor feature" [10]. Specifically, in different optimal solutions, one job may tend to be processed in front (or behand), further, if this job is replaced with a similar one and rescheduled, the processing positions of the two jobs in optimal solution are also similar. This phenomenon indicates that the processing order of jobs may be related to certain features. These job features may include processing time, processing cost, delivery time, etc. By mining these job features related to processing order, we can better understand optimization process of scheduling problems and improve performance of heuristicalgorithms.
As an intelligence algorithm, deep learning method can effectively mine hidden connections among data [11]. Convolutional neural network (CNN) are one of the representative algorithms of deep learning, with features of local perception, weight sharing, and pooling. They can reduce computational complexity, improve the generalization ability of model, and reduce overfitting risks. It is widely used in various applications. Additionally, the workshop will generate massive production data in manufacturing process, these production data provide abundant training datasets for deep learning. Therefore, deep learning has great application space in scheduling problem [12]. However, the scheduling data in actual workshop is numerous and miscellaneous, which makes it difficult to obtain high-quality dataset for deep learning.
Based on this, heuristic algorithms can be combined with deep learning. The heuristic algorithm can obtain optimal solutions quickly, these solutions can be used as original training dataset for deep learning. This method can instead of labelling jumbled production data in workshop. In optimal solutions, we select appropriate job features as inputs for deep learning, define processing order as priority, and use it as output of deep learning. The connection between job features and priority can be applied in workshop to quickly obtain approximate processing order of new jobs. In this way, this method can greatly improve production efficiency of workshop.
Therefore, this paper proposes a hybrid differential evolution algorithm, deep convolution neural network and neighborhood search algorithm (DEA-CNN-NS) method for NPFSSP. This method includes two parts: offline training and online scheduling. The offline training part mainly simulates actual production of workshop by generating scheduling task, and solves scheduling problem through DEA. The scheduling solutions from DEA are used as label data for training CNN. For the important attribute: priority, we propose a method combining K-means and data statistics (KM-DS) to obtain priority division method. The online scheduling part mainly solves scheduling problem of new jobs in workshop. Firstly, input new jobs’ attributes into the trained network to obtain corresponding priority, then arranging these new jobs according to their priorities to obtain an initial scheduling sequence. Finally, a neighborhood search algorithm is proposed to acquire higher quality solution. The experimental comparison proves that DEA-CNN-NS is more efficient than commonly used intelligent algorithm.
The rest of this paper is arranged as follows: Section 2 presents related research on NPFSSP. Section 3 describes the research problem through mathematical model. Section 4 introduces the main methods and algorithm framework. Section 5 represents each part of DEA-CNN-NS in detail. Section 6 carries out experimental comparison and reports computational results. Finally, Section 7 summarizes and prospects current research.
Literature review
Precise algorithm is often used to solve small-scale scheduling problems. Linear programming, branch and bound algorithm are commonly used precise algorithm. Mehravaran et al. [13] developed a linear mathematical model for NPFSSP, which comply with all of the operational constraints commonly encountered in industry. This method is designed to minimize work-in-process inventory for producer and to maximize the customers service level. Dhouib et al. [14] address the NPFSSP with minimal and maximal time lags between successive operations of each job, proposed a mixed integer linear programming model to minimize the number of tardy jobs and the makespan. Assia et al. [15] formulated a mixed binary integer programming model for NPFSSP with non-availability intervals, to minimize the total energy consumption and makespan. Meng et al. [16] considered two-stage NPFSSP with purpose of minimization of total completion time, presented a mixed integer programming model, and compared experiment results proving that it is more efficient than CPLEX. Gmys et al. [17] developed an efficient branch-and-bound algorithm, which contains a new node decomposition scheme that combines dynamic branching and lower bound refinement strategies in computationally efficient way. They applied this algorithm for the PFSSP with objective of minimizing total completion time. Chung et al. [18] developed a dominance theorem and a lower bound to accelerate branch-and-bound algorithm for minimizing the makespan in PFSSP with learning considerations. The experiment results showed that the branch-and-bound algorithm can solve problems of up to 18 jobs within a reasonable time.
Although precise algorithms can find the optimal solution, their workload increases exponentially with the expansion of problem scale [19]. However, meta heuristic algorithm can obtain the near optimal solution of the problem in a short time. In particular, a well-designed hybrid meta algorithm can achieve better performance than a single algorithm [20]. Aiming at permutation flow shop scheduling problem (PFSSP) with batch delivery to multiple customers, Wang et al. [21] developed a novel meta-heuristic (GA-TVNS) to minimize the total cost of tardiness and batch delivery. Li et al. [22] considered two-machine PFSPP with learning effects involving both experience and forgetting effects, proposed four heuristic algorithms combined with Branch and Bound algorithm (BB) to minimize makespan. Xiao et al. [23] focused on NPFSSP with order acceptance and weighted tardiness, presented a non-linear integer programming model and designed a two-phase genetic algorithm (GA) to solve this problem of medium and large sizes. Cui et al. [24] proposed a hybrid incremental genetic algorithm (HIGA) which combined population diversity super vision scheme and local refinement to solve the large-sized NPFSSP efficiently. Vahedi Nouri et al. [25] studied medium and large scale NPFSSP with learning effect, and proposed an improved meta-heuristic algorithm combining simulated annealing algorithm (SAA) and firefly algorithm (FA) to solve it. Zheng et al. [26] developed a novel quantum differential evolutionary algorithm (QDEA) based on the basic quantum-inspired evolutionary algorithm (QEA) for NPFSSP with the objective of minimizing the maximum completion time. Li et al. [27] developed a heuristic algorithm based on genetic algorithm (GA) to minimize the total weighted completion time in two-machine robotic non-permutation flow shop scheduling. Ying et al. [28] utilized ant colony system (ACS) to deal with NPFSSP with objective of minimizing the makespan. Benavides et al. [29] applied a constructive and an iterated local search heuristic in NPFSSP for minimizing the makespan.
With the continuous development of artificial intelligence technology, deep learning technology are increasingly being applied to the field of workshop scheduling. Olafsson et al. [30] proposed a method of using decision tree to learn scheduling rules from optimized scheduling data, and applied it to single machine scheduling problem. When two jobs are given, the decision tree can predict which job should be processed first. Wang et al. [31] used a branch and demarcation algorithm based on Petri nets to generate efficient solutions. The knowledge is extracted from the decision tree and combined with other heuristic methods to form a compound scheduling rule, which can further improve its performance on the basis of obtaining solution generated by Petri net-based branching algorithm. Shiue et al. [32] established a real-time scheduling knowledge base by combining Q-learning and multiple scheduling rules to solve the problem of dynamic workshop scheduling. Ren et al. [33] utilized reinforcement learning (RL) to solve FSSP, mapped different states in FSP and corresponding optimal scheduling rules to RL actions, and trained neural network to establish the relationship between states and actions, so as to select optimal rules for the states in workshop. To solve the dynamic flexible workshop scheduling problem, Liu et al. [34] set up specialized state and action representations, and used the dual deep Q-network algorithm to train the mapping relationship between variables, thereby achieving real-time scheduling of dynamic workshops. Sun et al. [35] proposed an architecture based on heterogeneous graph networks to capture the complex relationships between operations and machines for flexible JSP, and designed a new deep reinforcement learning (DRL) method to end-to-end learn high-quality priority dispatching rules (PDRs) to solve the problem. Lin et al. [36] studied a job shop scheduling problem (JSSP) under the intelligent manufacturing factory framework based on edge computing, proposed a deep Q network (DQN) combining deep learning and reinforcement learning, and adjusted it using edge computing framework to solve JSP.
It can be summarized that the application of deep learning is mainly to min useful scheduling knowledge from historical scheduling data to guide production. However, there are still some problems in previous research. For example, references [37, 38] directly divided priority according to the number of jobs or divided into three levels without theoretical basis. What’s more, it is not convenient to obtain excellent historical data in many workshops, and the complex potential relationship between job features and priority also increases the difficulty of data mining. Therefore, this paper uses KM-DS to get the priority of job. In addition, using DEA to solve scheduling problem, and generate label data for the training of CNN. Finally, a neighborhood search algorithm is used to remedy the error caused by deep learning.
Problem description and modeling
Problem description
The NPFSSP can be described as follows: a group of jobs N = {1, 2, 3,... , n} are processed on a group of machines M = {1, 2, 3, ... , m}. The processing paths of all jobs are the same, the processing order of jobs on different machines can be changed. The purpose of article is to arrange processing sequence of jobs on each machine, minimizing total process time.
In order to describe this mathematical model, relevant parameters and variables are listed as Table 1.
Summary of notations

Summary of notations

The framework diagram.
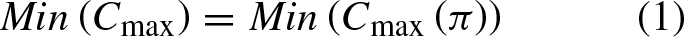
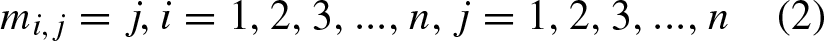
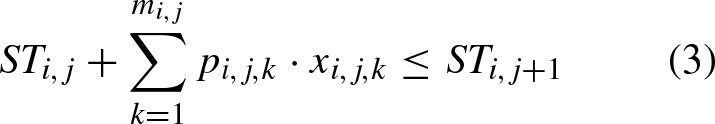
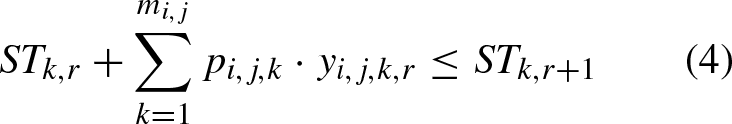

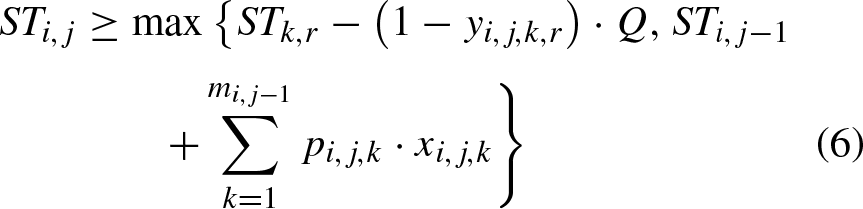
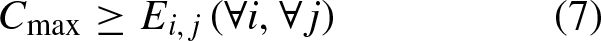


Among them, Equation (1) defines the objective of this problem, Equation (2) ensures that each operation can only be processed on corresponding machine, Equation (3) ensures that the next operation of one job can only be started after its previous operation is completed, Equation (4) ensures that the next operation on one machine can only be started after previous operation on this machine is completed, Equation (5) stipulates that completion time of job must be non-negative, Equation (6) ensures that one operation can only be started after its previous operation is completed and previous job on current machine is finished, Equation (7) defines overall completion time, Equations (8) and (9) define value range of decision variables.
The framework of DEA-CNN-NS is shown in Fig. 1. It includes offline training part and online scheduling part. The offline training part includes generating scheduling sequence dataset, obtaining training label data, training network. The online scheduling part includes extracting attributes of new jobs, obtaining priorities of new jobs, and NSA. The specific implementation steps of this method are as follows.
Step 1: Using DEA to solve NPFSSP and obtain excellent scheduling sequence for training [39]. Run DEA several times to solve a case of NPFSSP, and retain the optimal solution for each run. These optimal solutions can better reflect the relationship between job attributes and processing priority, and can be used as training dataset for CNN.
Step 2: Obtaining label data from scheduling solutions dataset. In the training of CNN, we select several attributes related to processing as input data. For output data - job priority, we design a reasonable division method, which utilizes K-means algorithm and data statistics to process the dataset and obtain priority from the rules of dataset.
Step 3: Training deep convolution network. This paper uses CNN to mine relationship between job attributes and priority. The trained network is equivalent to a scheduler which can reflect relationship between job attributes and priority. When new jobs arrive, obtain their attributes as input, the output is priority of new job. Arranging new jobs according to their priorities can get an excellent initial scheduling sequence
Step 4: Apply neighborhood search algorithm to improve solution quality. Since a priority may contain more than one job, when generating scheduling sequence code, the jobs in the same priority are automatically arranged, which leads to the quality of solution cannot achieve desired effect. Moreover, there are a little error in training results of network. In order to improve scheduling solution, the solution obtained by network needs to be further optimized. Based on initial scheduling sequence, the neighborhood search is carried out, after several simple iterations, a satisfactory solution can be obtained.
Algorithm design
Offline training framework
This paper proposes an offline training framework based on DEA to driven deep learning. Compared with previous research on job priority, we use KM-DS to get priority division method, which makes result more rigorous. There are three main parts: generating scheduling sequence database by DEA, obtaining training label data, training network.
The DEA
The core idea of DEA is described as follows: select three individuals s1, s2, s3 in population randomly, adding vector difference between s1and s2 to s3 can obtain v t , then cross s1 and v t to obtain u t , compare s t with u t and retain the better one to enter the next iteration. The general process of the algorithm is shown in Fig. 2.
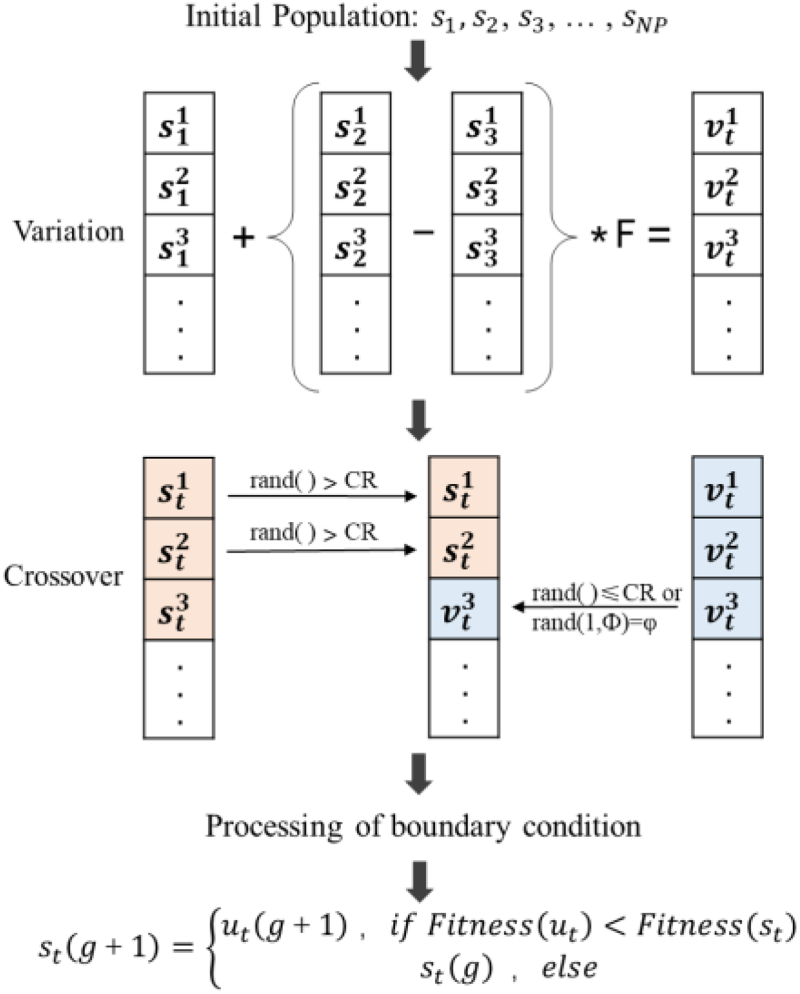
The framework diagram of DEA.
When generating scheduling sequence, the code is operated by stages, and then connect each stage in turn to form a complete scheduling code, as shown in Fig. 3. In scheduling sequence, the number represents job id, and the m-th occurrence of the number represents the m-th processing stage of this job. When the code is transformed into a specific scheduling scheme, also operated by stages. When a machine is idle, the jobs of corresponding stage are placed on machine in order.

Chromosome coding.
Since the number of scheduling code represents different job, the scheduling code must be an integer within a certain range. However, the DEA will generate irregular number during mutation, which requires boundary condition processing for non-integer and out-of-range numbers in scheduling sequence code. If the decimals are rounded directly, it may appear out of range numbers or repeated numbers, which is also unreasonable. So, the boundary condition processing is designed as follows: the numbers in sequence code are sorted by size, and their ranking in sequence code is used to replace this number, as shown in Fig. 4. In this way, it not only ensures that numbers are within a reasonable range, but also ensures that the number of job is not repeated in sequence code.
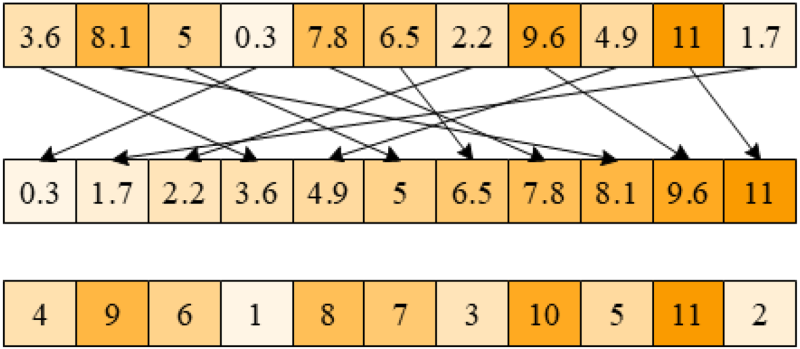
Processing of boundary condition.
In scheduling sequence, the more front the position of job, the higher the priority is. In NPFSSP, the optimal solution is often not unique, one job may have different positions in different scheduling sequences. This leads to different priorities for the same job in training data. Therefore, this paper uses KM-DS to obtain a reasonable way of priority division, the specific implementation ideas are as follows:
Due to the potential relevance of excellent scheduling sequences, although the position of a job in different scheduling sequences is not unique, it is mostly fixed in a few positions. Counting the number of occurrences of the job at each position, get a set of numbers {c1, c2, c3, ·· · , c n }, the large number in array reflects that the job often appears at that position, several larger numbers are position interval where this job often appears, the length of position interval is the length of priority determined by this job, denoted as L Jobi . However, it is not rigorous to directly select larger numbers from the array based on subjective judgment. In order to ensure the accuracy of experiment, K-means algorithm is used to cluster the numbers in array into two groups. The K-means algorithm is a commonly used clustering method. It can divide the dataset into K clusters, and the mean of all samples in each cluster is called “centroid". The basic process of the K-means algorithm includes: first, randomly selecting K nodes as initial centroids; then, determining the category of each node based on the distance from each centroid; finally, recalculating the mean of all samples in cluster as the new centroid. Based on statistical data obtained, K-means algorithm can cluster them and obtain the L Jobi of each job.
As shown in Fig. 5, Job1often appears in first four positions, so the best priority division determined by Job1 is that four positions form a priority, while Job2 is suitable for three positions to form a priority. Perform the same processing on all jobs, get an array {LJob1, LJob2, LJob3, … , L Jobn }, the highest frequency number is the length of priority.
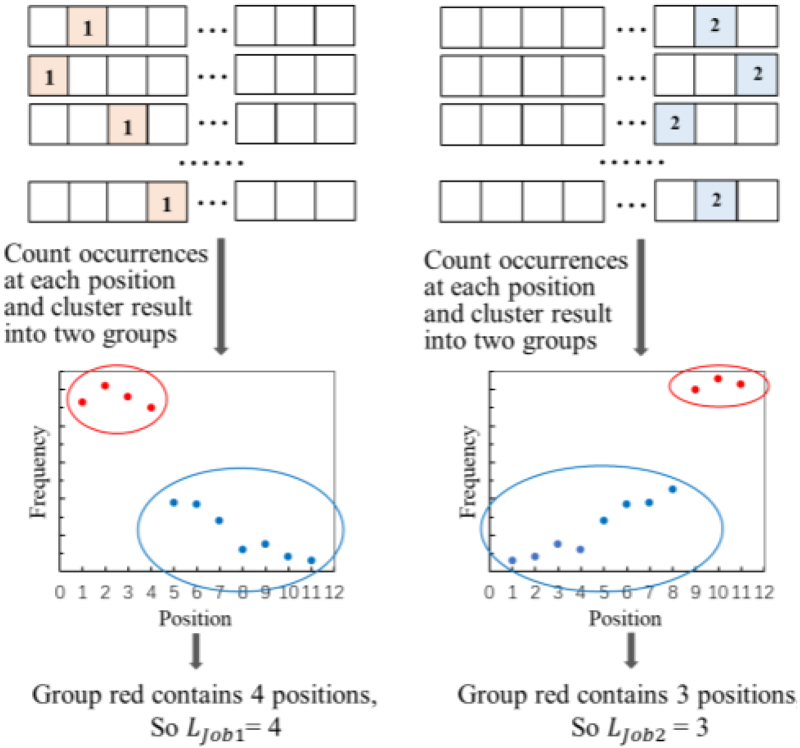
Priority division method.
The processing attributes of job refer to some hidden features in job processing. According to the characteristics of flow shop scheduling problem and the attribute-oriented induction method [10], this article extract following attributes.
Training neural network
The relationship between job attributes and its priority is complex, so this paper proposed a convolution two-dimensional transformation (CTDT) based on Cartesian product to process job attributes data[12]. Using this transformation, one-dimensional feature data can be transformed into two-dimensional feature data, which are used as the input of CNN. The two one-dimensional vectors used in transformation are related to job attributes, which are defined as follows: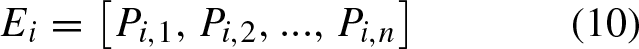
In Equation (10), Pi,n is the proportion of total processing time of Job
i
to Job
n
, which are represented Equation (11)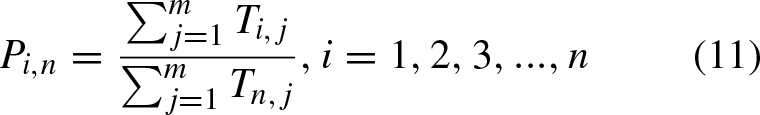

In Equation (12), fij,1 ∼ fij,6 are six job attributes mentioned in the previous section. The specific calculation formula is shown as Table 2.
Job attributes in one-dimensional vector

Cartesian product operation can combine linear characteristics of data to convert it from one dimension to two dimensions, can excavate more comprehensive and deeper information in convolution operation. The conversion in this article described as Equation (13).
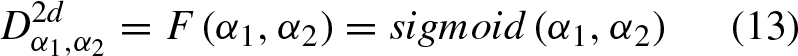


In Equations (13) and (14), α1 and α2 are one-dimensional feature data, × is the sign of Cartesian product operation, mathematical operation is in Equation (14). After Cartesian product, the result is processed by activation function, which is shown in Equation (15). The sigmoid function can convert data between 0 and 1, and convert some very large or very small values into two endpoints of 0 and 1, so as to avoid some extreme outlying value causing over-fitting in the subsequent network. In this paper, α1 = P i , α2 = Fi,j.
The structure of CNN is shown in Fig. 6. At the beginning, convolution layer uses a 5 * 2convolution kernel to preliminarily mine two-dimensional features. The output of convolutional layer is nonlinearly calculated through excitation function Relu. Then the feature data is compressed by maxpooling layer to extract main features and simplify complexity of network computational. In fully connected layer, two-dimensional features are transformed into one-dimensional form. Finally, through softmax layer, the data is converted into output, and the number of output neurons is the number of priority. A trained network is equivalent to a complex function structure that can reflect the relationship between input and output. When new job attributes are input, the network can quickly get corresponding output, that is, the priority of this new job.
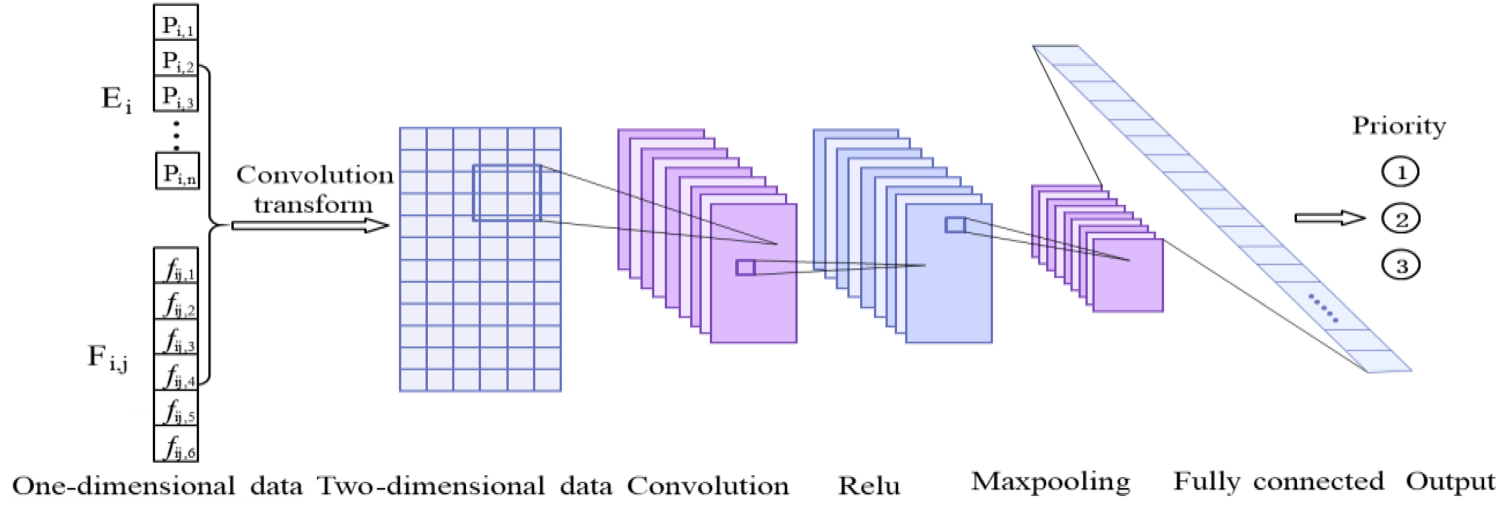
Structure of deep convolution neural network.
The online scheduling part solves the scheduling problem of new jobs in workshop, the specific framework is shown in Fig. 7. In online scheduling part, when a new set of jobs arrives, six attributes of new jobs are extracted, then put them into the trained network, the output is their priorities. Arrange new jobs according to their priorities to get an initial scheduling sequence. However, the different arrangement of jobs within the same priority lead to different scheduling solutions. Additionally, in tons of training scheduling data, the same job in different sequences may have different positions, resulting in its priority is not unique, which bring about some errors in network. These problems mean that initial scheduling sequence cannot be directly used for production. This paper designs a neighborhood search algorithm (NSA), starting from initial solution, after simple iterations, the final satisfactory solution is obtained for actual production.
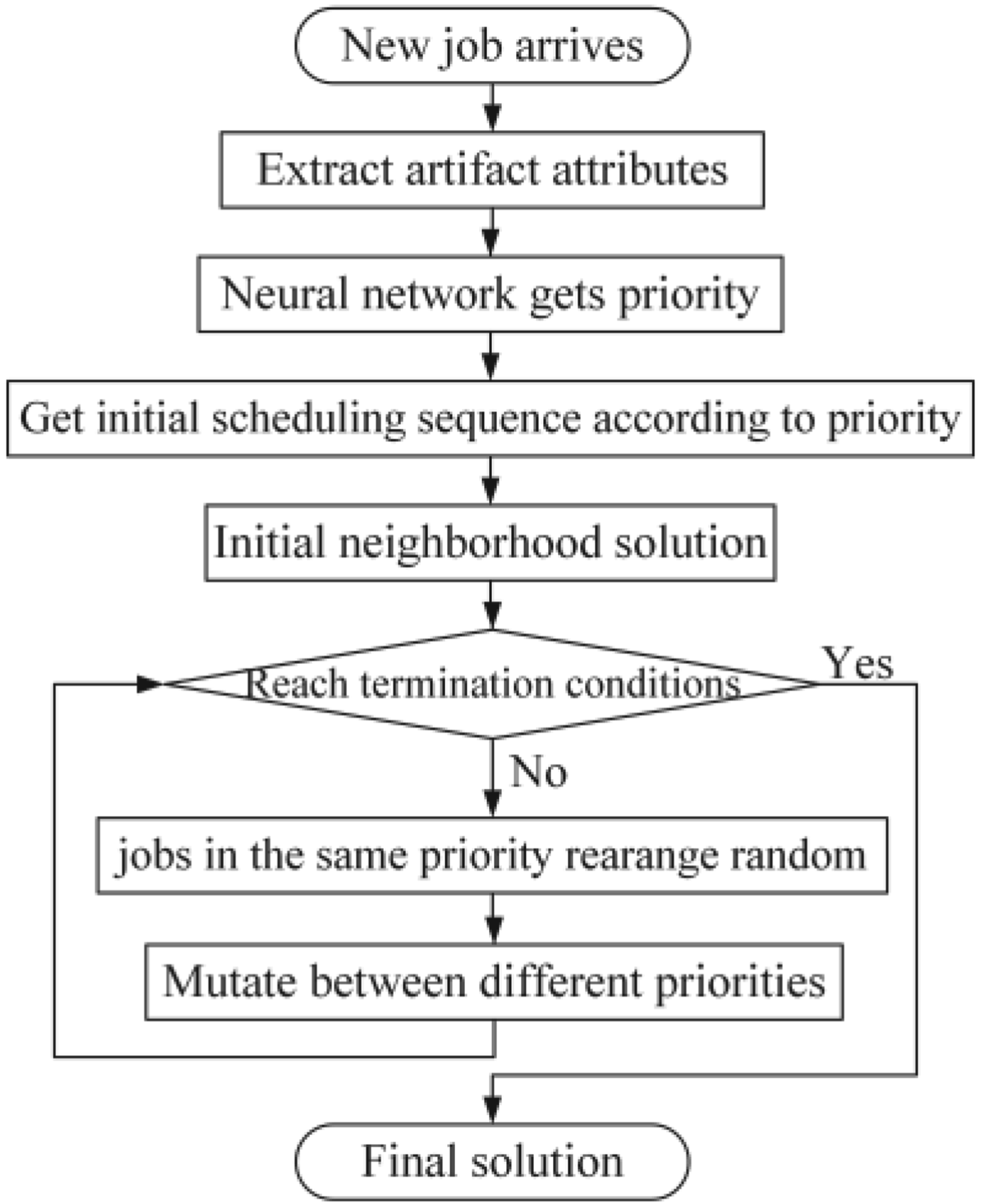
Framework of online scheduling.
The NSA uses greedy strategy, and (S, F, f) is used to represent this combinatorial optimization problem. S represents space of all solutions, F is the evaluation function, f is neighborhood search function. In neighborhood of initial solution s, a neighborhood solution s’ is generated according to neighborhood search function f. If the result F(s’) is better than F(s), replace s=s’, then starts a new round of neighborhood search, repeat above steps until iteration termination condition is reached. The neighborhood search function f processes the jobs in the same priority, and sets a certain mutation probability to operate jobs with different priorities, that can make neighborhood solution jump to a larger range without departing from initial solution, which can find a better solution and improve search efficiency. The specific process of NSA is as follows:

In order to prove the effectiveness of DEA-CNN-NS, an experimental study is carried out in a non-permutation flow shop problem. This case includes 5 processing stages and 11 jobs. The processing sequence of jobs are the same.
Experimental design
The experiment obtains training dataset by DEA, then obtains job attributes and priorities as input and output labels for CNN training, and finally uses NSA to optimize scheduling solution. The specific implementation steps and parameter settings are as follows:
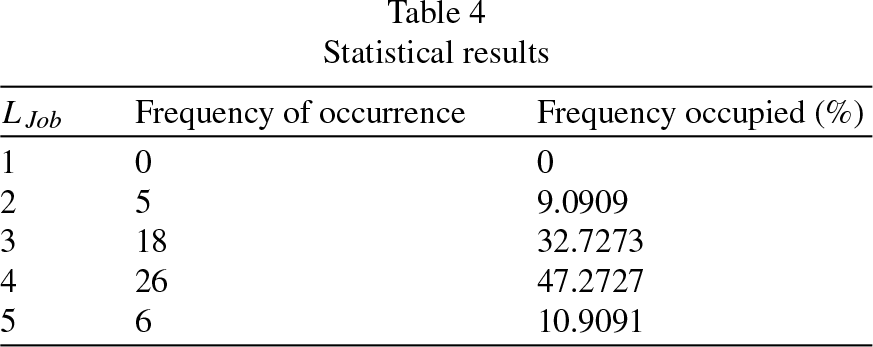
Step 1: Run DEA for many times, retain excellent scheduling sequence in each run, then use KM-DS to get priority division method. In this 11 * 5 flow shop case, at each stage, count the number of times that the job appears in each position, each job will get an array {c1, c2, c3, ·· · , c11 }. So each stage will get an 11 * 11 matrix, each row represents number of occurrences of the job in each position. Table 3 shows statistical results of one stage. K-means algorithm clusters each row into two categories. For the first row, the clustering results are (35, 42, 47, 36, 37) and (9, 24, 26, 19, 14, 9), the smaller category is where this job often appears, and length of this category is recorded as the number of positions within a priority, that is, LJob1 = 5. Similarly, LJob2 = 4, LJob3 = 4. Finally get an array {LJob1, LJob2, … , L Jobn } from this matrix. Doing the same operation for 5 stages to get 55 numbers, perform frequency statistics on 55 numbers, the results are shown in Table 4. According to experimental results, every four positions divide into one priority is the most reasonable.
Statistical results of one processing stages

Statistical results of one processing stages
Statistical results
Step 2: According to statistical results of previous step, the first 4 positions are divided into the first priority, the middle 4 positions are the second priority, and the last three positions are the third priority. Then the input and output label data of CNN can be obtained. Figure 8 shows training process of deep convolution network and a partial enlarged view of loss process. Table 5 shows the training results of CNN, reflecting the accuracy of network for each classification and the overall classification accuracy. Values on diagonal indicate the times that network predicts correctly for each class data.
Confusion matrix of CNN


Training process of network.
There is some error in prediction results. Firstly, due to the non-reproducibility of heuristic algorithm, there are diversities between different scheduling solutions, which lead to the same job may correspond to different priorities in different sequences. Additionally, the selected job attributes are limited, which may not fully reflect hidden information related to processing. These problems bring about errors in network training.
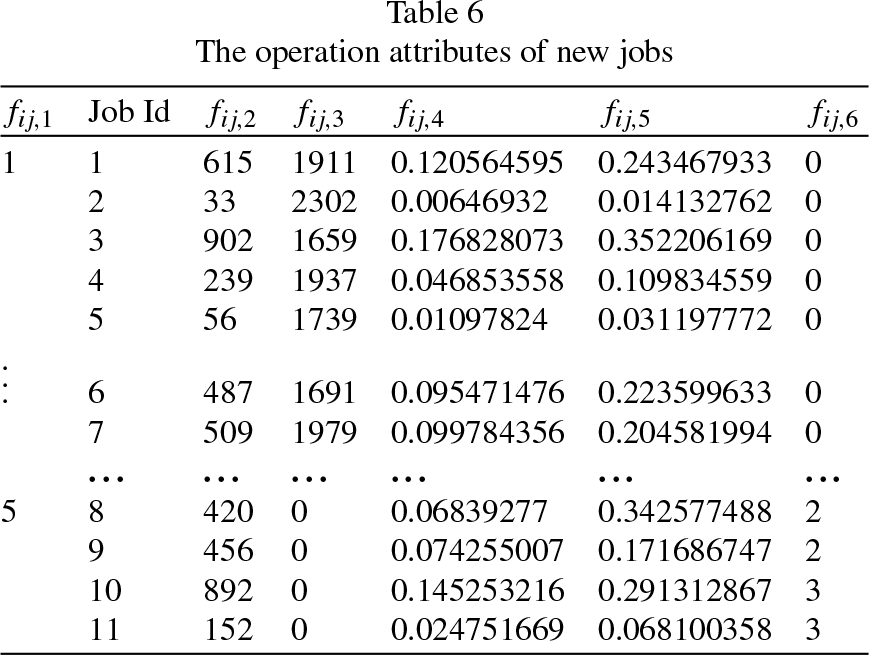
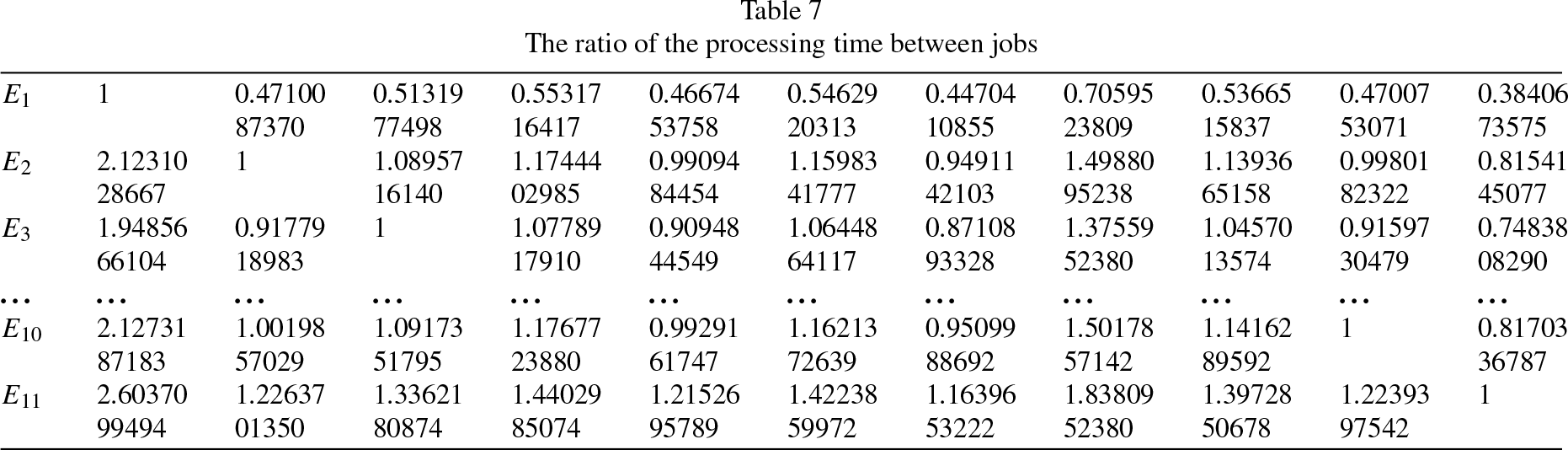
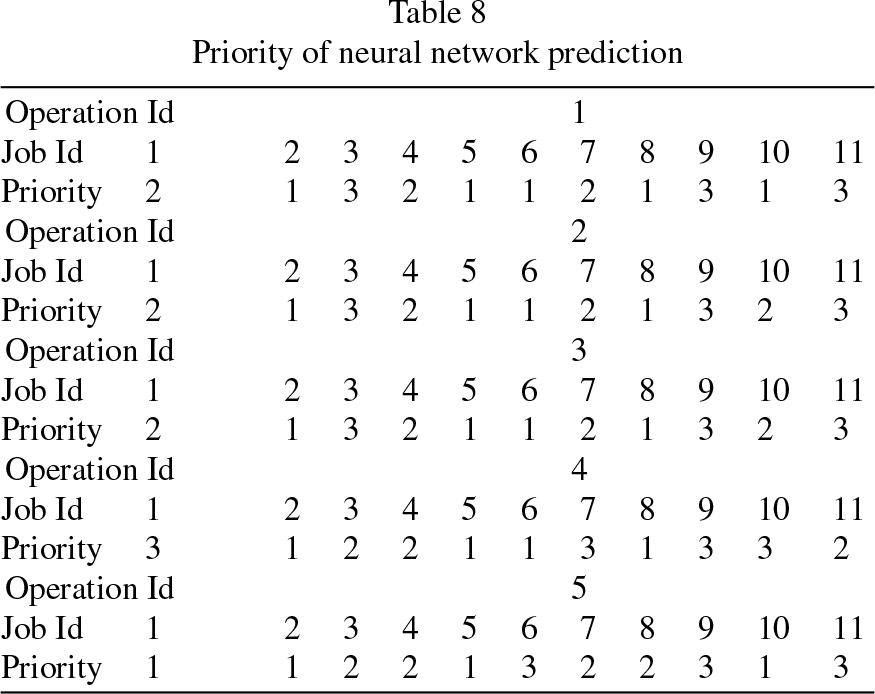
Step 3: For new jobs in this flow shop, extract their job attributes, part of data is shown in Table 6, these data are components of parameter Fi,j. The data related to parameter E i are shown in Table 7. These job attributes data are converted into vectors and input into trained network, the output of network is corresponding priority, as shown in Table 8. Due to some errors in network, the priority obtained may not be accurate. So the initial scheduling sequence obtained by priority need furtherprocessing.
The operation attributes of new jobs
The ratio of the processing time between jobs
Priority of neural network prediction
Step 4: Starting from initial sequence, the neighborhood search is carried out. In each iteration, two priorities are selected, as shown in Fig. 9, P1, P3 are selected, the jobs within the two priorities are rearranged to obtain a neighborhood solution. The mutation is shown in Fig. 10, P1, P3 are selected, the last two jobs of P1 are exchanged with the first two jobs in P3. This operation avoids solution falling into local optimum.

Job exchange in the same priority.
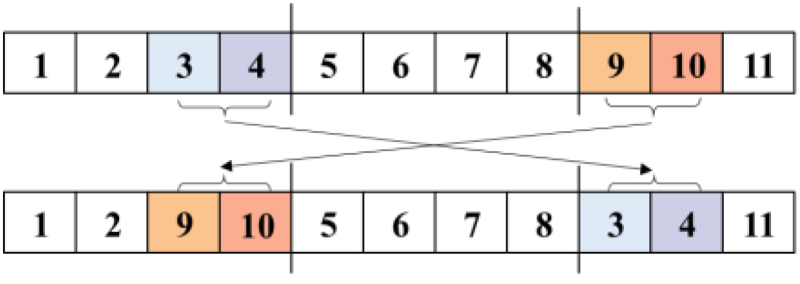
Job exchange in different priority.
In order to compare ability of different neural networks in mining job attributes, this paper selects CNN, Back Propagation Network (BP), and Long Short-Term Memory Network (LSTM) for comparison, and uses the same data for training. The comparison of accuracy in training process of three networks is shown in Fig. 11. It can be seen that BP has achieved high accuracy with little train, premature convergence may lead to poor generalization ability of network model, while LSTM has weak ability to mine job attributes, the training result is poor. After training, use the same data to test classification ability of three network models, the forecast results and confusion matrices are shown in Figs. 12–14. Although BP network performs well in training process, it may be because the selected training data are relatively typical and sample, so when it faces new data, its prediction ability is poor. LSTM excels in time series prediction, but is not ideal for mining prioritier. CNN performs well in mining deep relationship of data. Compared with experimental results, CNN is more suitable for mining job attributes data.

Training process of three network.

Forecast result and confusion matrix bar graph of CNN.
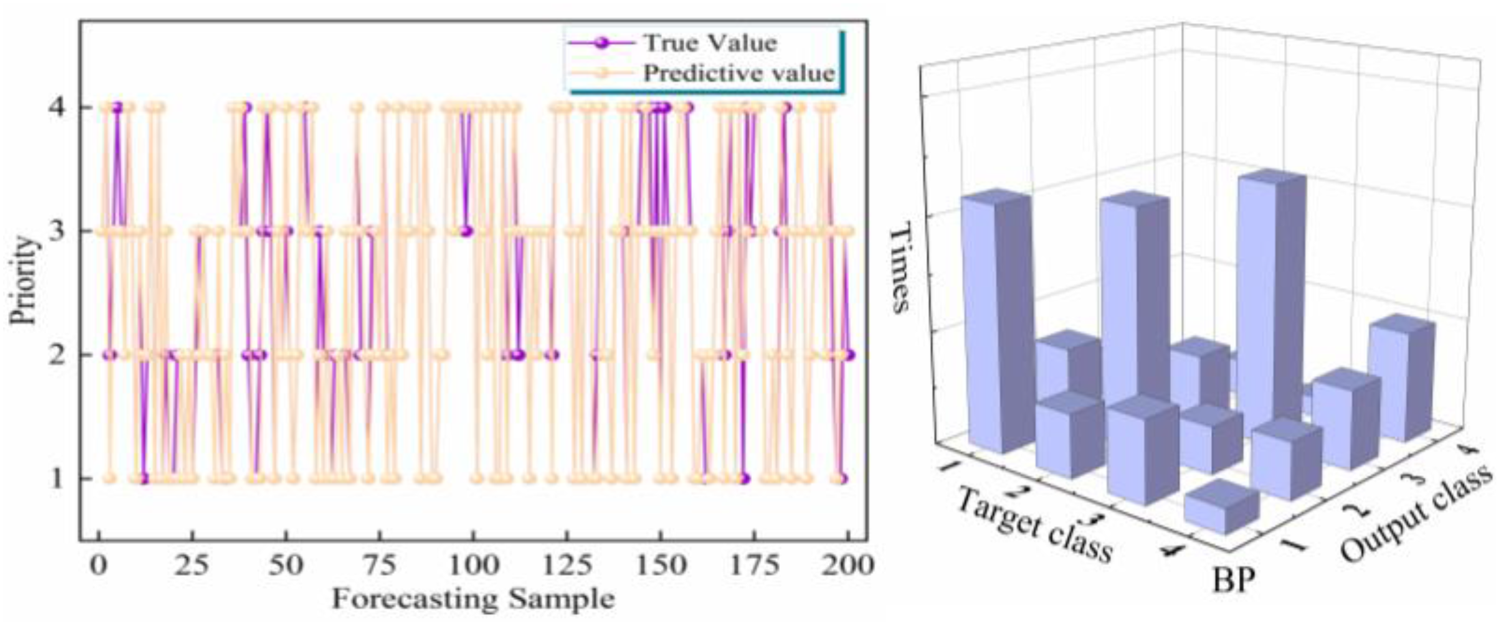
Forecast result and confusion matrix bar graph of BP.
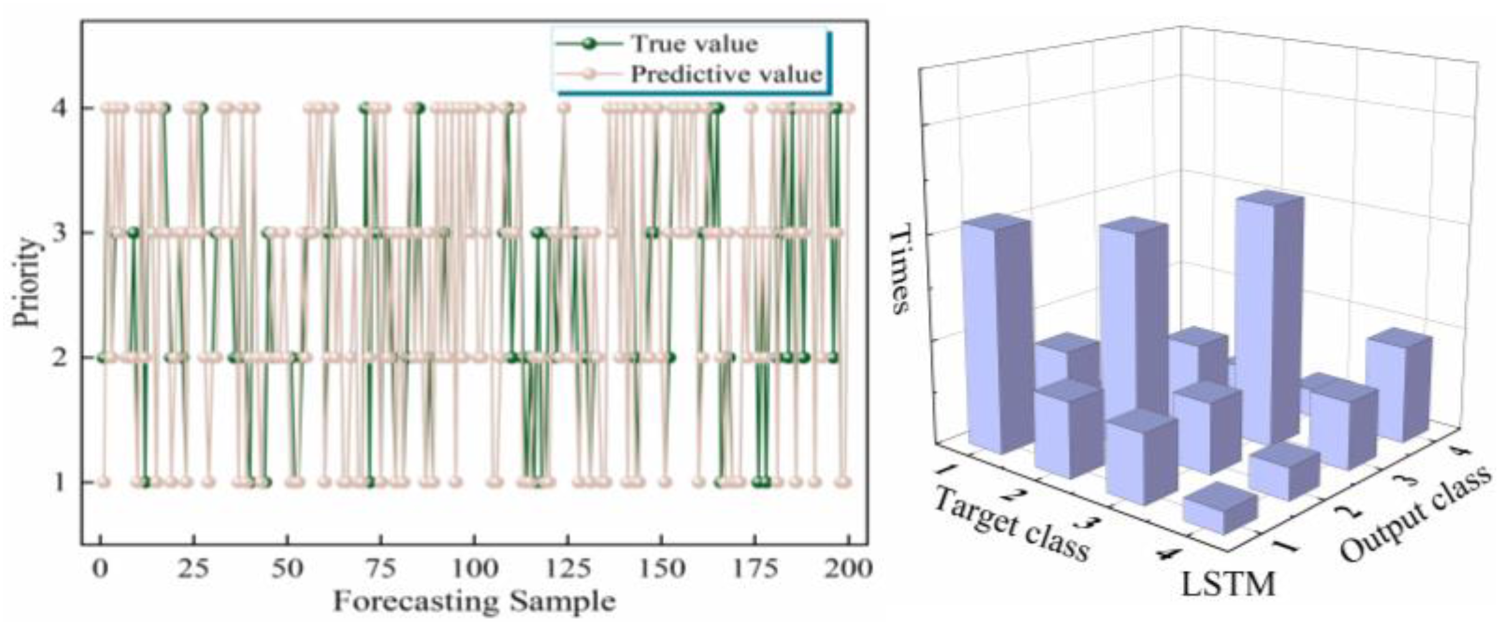
Forecast result and confusion matrix bar graph of LSTM.
In order to verify the superiority of DEA-CNN-NS in this paper, a comparison experiment was performed between DEA, GA, Gray Wolf Algorithm(GWA) and DEA-CNN-NS.
The number of individuals in population is set to 100. Figure 15 shows comparison of four algorithms’ convergence at 150 generations. Then compare performance of four algorithms at 150 generations and 500 generations in Table 9. Run each algorithm 5 times, take medium value from 5 results, the CPU time and makespan are recorded in Table 9. In addition, three network and heuristic algorithms were applied to solve several cases of different scales, the experimental results are recorded in Table 10.
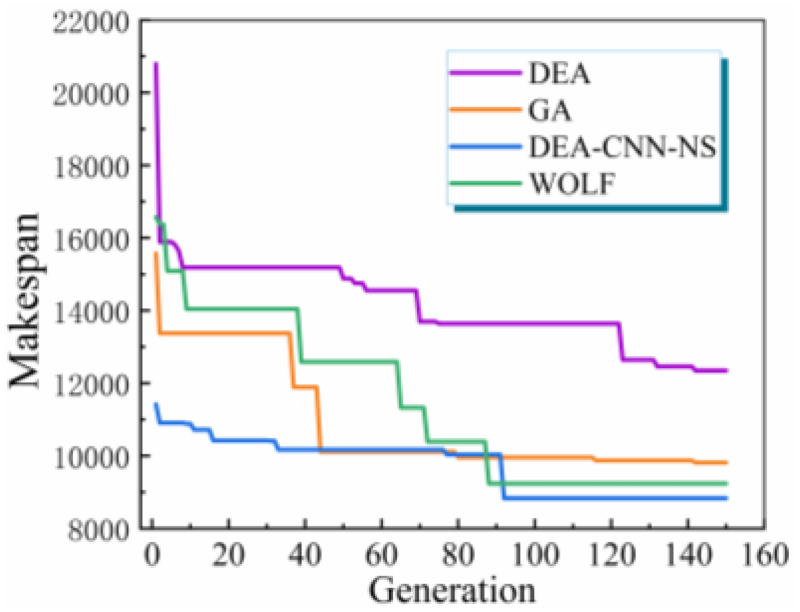
Compare of four algorithms when iterating 150 times.
Experimental results of different algorithms

Experimental results of different algorithms
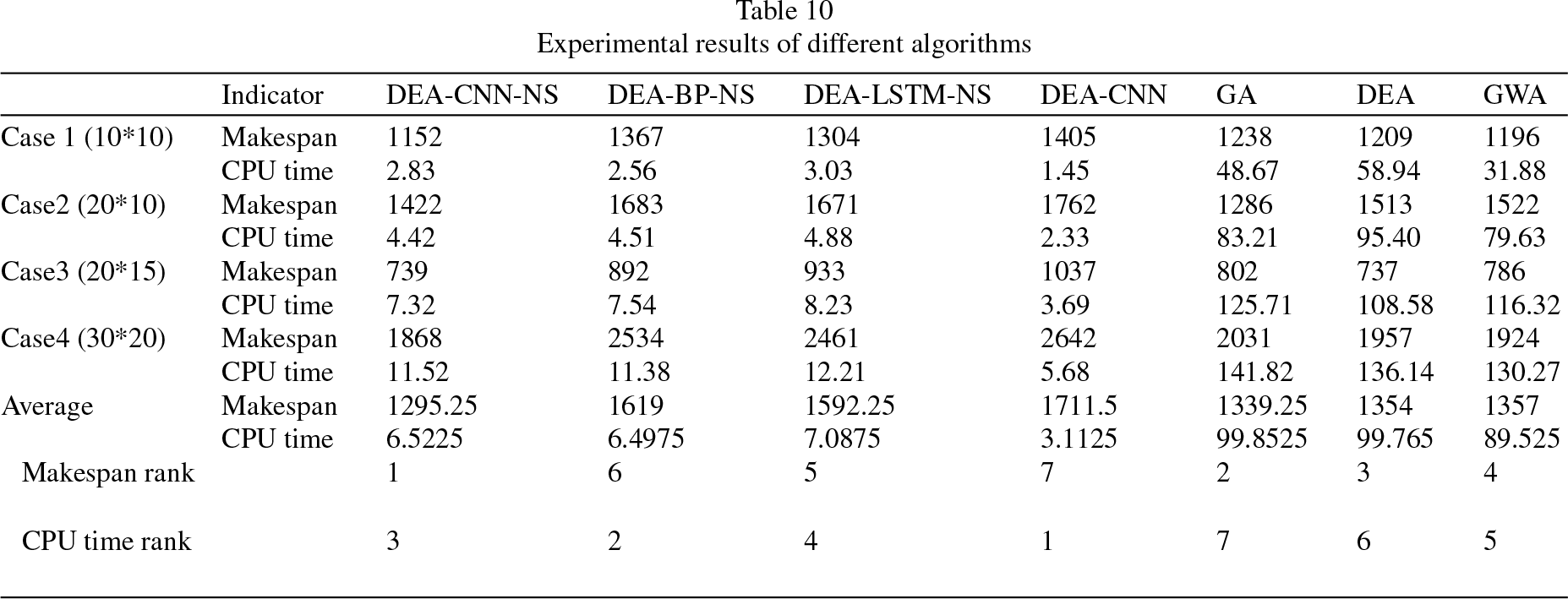
The performance of these algorithms can be described as follows: Meta heuristic algorithm takes long time to solve large-scale problems. With number of iterations increases, the optimal solution does not improve much, but the time is greatly increased. The algorithm converges too early and the global search ability is poor in later stage. DEA-CNN-NS needs a certain amount of time in offline training part, but the trained model can be applied to similar new jobs in the same NPFS, so it can quickly schedule and get excellent scheduling sequence in short time. In general, DEA-CNN-NS is easier to find excellent solutions because of its better initial scheduling sequence, and because the neighborhood search function runs faster, its time cost will not increase greatly with the increase of iterations. The superiority of this method is more obvious when dealing with larger scale problems.
It can be seen that the overall performance of DEA-CNN-NS is better, which provides a feasible solution for scheduling problem of similar type jobs in NPFSSP.
The jobs processed in the same workshop often have certain similarities, and the historical data in workshop contains many job information related to scheduling results. Mining the potential information for new scheduling problem can greatly improve production efficiency. Therefore, aiming at non-permutation flow shop scheduling problem, a hybrid differential evolution algorithm, deep convolution network and neighborhood search method is proposed. This method takes some time in training part. The trained neural network can greatly improve processing efficiency of similar jobs in this workshop. In addition, DEA, K-means algorithm and neighborhood search algorithm also improve integrity and rationality of this method. Experimental results show that the performance of this method is better than traditional intelligent heuristic algorithm. In addition, there are still some problems. Is there any advantage when the similarity of new jobs is low? What job attributes remain to be mined? Future research will focus on these questions, and will also focus on more complicated scheduling problem, such as hybrid flow shop scheduling problem, distributed job shop scheduling problem, etc.