
Abstract
The detection of tomato leaf diseases is crucial for agricultural sustainability, impacting crop health, yield optimization, and global food supply. Despite the advancements in deep learning methods, a pressing challenge persists— achieving consistently high accuracy rates, particularly in the context of rigorous agricultural requirements. This study addresses this problem directly, introducing a novel approach by employing the Yolov8 architecture in a deep learning model for tomato leaf disease detection. The identified research challenge is precisely targeted, and the model is developed using a meticulously curated custom dataset. Through comprehensive training, validation, and testing phases, the study ensures the robust performance of the Yolov8 model. The novelty of this research lies in its focused solution to the specific accuracy challenge within deep learning-based tomato leaf disease detection. The proposed methodology is rigorously evaluated through extensive experimentation, showcasing its ability to surpass existing benchmarks and offering a highly effective solution. This innovative approach not only contributes a unique solution to the identified problem but also advances the field by providing a more accurate and reliable method for detecting tomato leaf diseases.
Introduction
The detection of leaf diseases in fruit-bearing plants holds immense significance within the agricultural sector, playing a pivotal role in maintaining crop health, optimizing yield, and ensuring global food security. As plants constitute a fundamental source of sustenance and economic stability, the early and accurate identification of leaf diseases emerges as a critical imperative for sustainable agricultural practices [1–3].
Among the diverse spectrum of fruit crops, tomatoes occupy a central place due to their widespread cultivation and dietary importance [4]. Detecting diseases in tomato leaves is of paramount importance, as it directly influences fruit production and quality [5]. Timely recognition of tomato leaf diseases aids in minimizing losses and implementing targeted strategies to mitigate disease spread [6]. By harnessing advanced technologies, such as automated disease detection, the agricultural sector can proactively manage and curtail the impact of tomato leaf diseases, ultimately fostering robust and prosperous crop cultivation [7]. Some sample of leaf tomato is depicted in Fig. 1.

Some samples of leaf tomato.
In recent years, technological advancements have ushered in a new era of innovation in the domain of tomato leaf disease detection. These strides encompass a range of techniques, from traditional image processing methodologies to cutting-edge machine learning algorithms [8–10]. The landscape of tomato disease detection has witnessed the emergence of intelligent systems, remote sensing technologies, and sophisticated image analysis tools. These tools empower growers, researchers, and stakeholders with the ability to swiftly and precisely identify diseases, facilitating informed decisions and enhancing overall crop vitality [11, 12].
Within this dynamic landscape, deep learning-based methods, notably involving Convolutional Neural Networks (CNNs), have gained significant traction. These approaches have demonstrated remarkable accuracy by automatically learning intricate features from raw image data [13, 14]. In contrast to conventional methods reliant on complex rule-based systems, deep learning can adeptly accommodate variations in disease patterns. The adaptability and potential for high accuracy have spurred researchers to investigate deep learning-based solutions extensively for tomato leaf disease detection [15, 16].
Nevertheless, deep learning-based tomato leaf disease detection approaches are not without limitations. The challenge of consistently achieving high accuracy across diverse disease scenarios persists, underscored by meticulous analysis of previous studies [12]. This challenge is particularly magnified given the demanding accuracy requirements inherent in agricultural applications. Moreover, computational resources and real-time processing capability are other concerns which are required to investigated [17]. To surmount this obstacle, further research is warranted to bolster the robustness and efficacy of deep learning techniques [18–20].
In this study, we propose a novel deep learning method employing Convolutional Neural Networks (CNNs) to address the research challenge of achieving high accuracy in tomato leaf disease detection. Adopting CNNs offers a potent solution, leveraging their capability to learn intricate patterns from image data. Our contributions encompass the curation of a bespoke dataset tailored to tomato leaf diseases, followed by rigorous training, validation, and testing phases.
Experimental results and comprehensive performance evaluations substantiate the proposed method’s effectiveness, underscoring its capability to achieve accurate tomato leaf disease detection. Through extensive experimentation and meticulous performance analysis, our study contributes to advancing the field of deep learning-based disease detection, offering a robust and accurate solution tailored to the nuanced challenges of tomato leaf diseases.
The research proposes a deep learning method, utilizing the CNN, to address the persistent challenge of achieving high accuracy in tomato leaf disease detection. Acknowledging the advancements in technology, particularly deep learning, the study justifies its focus by highlighting the persistent limitations in consistently achieving high accuracy across diverse disease scenarios. The research aims to fill these gaps by introducing a specialized dataset, an efficient deep-learning methodology tailored for tomato disease detection, and conducting extensive experiments with thorough performance evaluations.
The designed architecture is motivated by the persistent challenges in accurately detecting diverse tomato leaf diseases. Conventional methods struggle with consistency, prompting the utilization of Convolutional Neural Networks (CNNs). The motivation lies in CNNs’ ability to autonomously learn intricate features from raw image data, offering adaptability to varied disease patterns. This approach departs from rule-based systems, aiming to provide a robust and efficient solution, contributing innovatively to the field of tomato leaf disease detection through deep learning technologies.
Three significant research contributions of the study are as follows, Generating a specialized dataset designed to address the challenges of tomato leaf disease detection. Conducting extensive experiments and perform thorough performance evaluations to affirm the method’s efficacy in detecting tomato leaf diseases with precision and reliability.
The rest of this paper is as, section 2 reviews the related works. Section 3 discuss the research methodology. Section 4 presents experimental results and discussion. Finally, conclusion presents in section 5.
Machine learning and deep learning methodologies have significantly contributed to the advancement of agricultural domains, particularly in forecasting, categorization, and identification of plant diseases. These techniques offer a non-invasive, cost-effective, rapid, and dependable approach to detect plant diseases. A multitude of researchers have dedicated their efforts to investigating the diagnosis and detection of plant diseases, particularly those afflicting tomato leaves. Noteworthy researchers in this area include:
The authors in [21] presented a Tomato Leaf Disease Detection System utilizing a novel approach called FC-SNDPN. This method combines Fully Connected (FC) layers with a Symmetric Neuron-based Deep Pyramid Network (SNDPN) for accurate disease classification. The FC-SNDPN model extracts hierarchical features from tomato leaf images, enabling effective disease diagnosis. However, the approach has limitations. It might struggle with generalization to unseen disease types due to potential overfitting on the specific dataset. Additionally, the model’s performance could be influenced by variations in lighting conditions and image quality. Despite these limitations, FC-SNDPN shows promise in automating tomato disease detection and could benefit from further testing on diverse datasets.
The paper [22] introduced a precise method for detecting tomato leaf diseases through images, employing a technique called PLPNet. This approach involves the use of a specially designed network architecture to capture and process image features related to disease symptoms effectively. However, the method’s performance is constrained by the availability of extensive and diverse training data. Also, the reliance on image quality and environmental conditions might affect its accuracy in real-world scenarios. Nonetheless, PLPNet demonstrates potential in advancing automated tomato disease detection, warranting further evaluation on broader datasets.
The authors [23] presented a method for tomato leaf disease detection using Machine Learning-based Parallel Convolutional Neural Networks (CNNs). The approach involves training multiple CNNs in parallel to extract features from images of tomato leaves, enabling accurate disease classification. However, the method’s effectiveness heavily relies on the quality and size of the training dataset, potentially leading to reduced performance on less represented diseases. Additionally, the computational resources required for training and deploying multiple CNNs might limit its practicality. Despite these limitations, the proposed parallel CNN approach shows promise in enhancing automated tomato disease detection systems.
The authors in [24] introduced a method for detecting tomato leaf diseases employing Deep Convolutional Neural Networks (CNNs). The method entails training CNNs on a dataset of tomato leaf images to learn distinctive disease-related features, enabling accurate disease identification. However, the model’s performance might be constrained by the availability of comprehensive and diverse training data, potentially leading to difficulties in recognizing less common diseases. Moreover, the approach’s success could be influenced by variations in imaging conditions and disease stages. Nevertheless, the deep CNN-based approach offers promise in advancing automated tomato disease detection systems.
The paper [25] presented a novel PCA DeepNet method for detecting tomato leaf diseases to aid agro-based industries. This approach combines Principal Component Analysis (PCA) with a Deep Neural Network (DeepNet) to extract relevant features from tomato leaf images, facilitating accurate disease classification. However, the success of the method hinges on the availability of a substantial and diverse training dataset, potentially leading to challenges when dealing with rare or newly emerging diseases. Additionally, the model’s performance might be influenced by variations in lighting and image quality. Despite these limitations, the PCA DeepNet approach holds promise for enhancing disease detection in the agricultural sector.
The mentioned papers propose various approaches for automating tomato leaf disease detection. The [21] introduces FC-SNDPN, a technique that combines Fully Connected (FC) layers with a Symmetric Neuron-based Deep Pyramid Network (SNDPN) for hierarchical feature extraction from images. The method exhibits promise but might face challenges with generalization and lighting variations. The [22] presents the PLPNet method, a network architecture for accurate disease identification. However, its performance relies on diverse training data and can be influenced by image quality. The [23] employs parallel CNNs for feature extraction, which is effective but resource-intensive. The [24] focuses on CNNs, offering accurate classification contingent on data diversity and imaging conditions. Lastly, [25] combines PCA and DeepNet for disease detection, but its success depends on a substantial and varied training dataset and might be affected by image variations.
In summary, these papers propose innovative methods for automated tomato leaf disease detection. While FC-SNDPN and PLPNet aim to enhance accuracy through distinct architectural strategies, parallel CNNs, deep CNNs, and PCA DeepNet explore the use of neural networks and PCA for feature extraction. Despite their potential, these methods encounter limitations such as data diversity, lighting variability, resource intensity, and image quality. Successful implementation of these approaches necessitates addressing these challenges for reliable and robust disease detection in agriculture.
Methodology
Data collection
We begin by curating a custom dataset consisting of images of tomato leaves with varying disease instances. In our study, we employ the YOLOv8 model to address the challenge of tomato leaf disease detection on a custom dataset. To generate the YOLOv8 model, we follow a series of steps to ensure accurate and effective detection. Firstly, our custom dataset is meticulously annotated, with each image labeled to indicate the location and class of tomato leaf diseases present. This annotation process enhances the model’s ability to identify and classify disease instances accurately.
Data pre-processing
Preprocessing plays a crucial role in preparing a dataset for subsequent processing steps, enhancing the quality of data, and aiding the effectiveness of algorithms. In the context of tomato leaf disease detection, preprocessing involves various techniques to improve the quality and relevance of the images before feeding them into the disease detection model.
Histogram equalization
One such preprocessing technique is histogram equalization. Histogram equalization is applied to enhance the contrast of images, making the different regions and features within the images more distinct in the context of tomato leaf disease detection. By applying histogram equalization as a preprocessing step in tomato leaf disease detection, the aim is to normalize the lighting conditions and enhance the visibility of disease symptoms. This contributes to more accurate and effective disease classification by the detection model. However, it’s important to note that while histogram equalization can be beneficial, it might also introduce some artifacts in extreme cases and needs to be used judiciously.
Noise removal
Noise removal is an essential preprocessing step in tomato leaf disease detection that helps improve the quality of images by reducing unwanted variations and artifacts caused by factors such as sensor noise, compression, or other imperfections. In this study with a custom dataset, noise removal techniques can be applied to enhance the accuracy and reliability of disease detection algorithms. Using Gaussian blur or other noise removal techniques, it effectively preprocesses the images to reduce unwanted variations and improve the overall quality of the dataset. This leads to more accurate and reliable disease detection results since the detection model can focus on actual disease-related features without being affected by irrelevant noise. However, it’s important to strike a balance, as excessive blurring can lead to the loss of important details and affect the detection algorithm’s ability to classify diseases accurately.
Data augmentation
To extend the variety and size of our dataset, data augmentation techniques are employed. This augmentation process involves applying a range of transformations to the original images, such as rotations, flips, and changes in lighting conditions. By incorporating these augmented images into the dataset, we aim to capture a broader spectrum of scenarios, including various lighting conditions and transformations that can occur in real-world settings. This augmentation strategy improves the model’s robustness and adaptability to diverse appearances of tomato leaf diseases.
Subsequently, the annotated and augmented dataset is split into three distinct subsets: training, validation, and testing. The training set, comprising 90% of the dataset, is utilized to train the YOLOv8 model. During the training phase, the model learns to identify unique features and patterns associated with different types of tomato leaf diseases. The validation set, constituting 8% of the dataset, plays a crucial role in fine-tuning the model’s hyperparameters, ensuring optimal performance without overfitting. Finally, the remaining 2% of the dataset forms the testing set, which is held separately throughout the training process. This independent testing set is used to evaluate the YOLOv8 model’s performance, measuring its accuracy and generalization capabilities on previously unseen data. In conclusion, our study leverages the YOLOv8 model for tomato leaf disease detection on a custom dataset. Through meticulous annotation, data augmentation, and a well-structured dataset split, we aim to develop a robust and accurate model capable of detecting a wide range of tomato leaf diseases under various appearances and scenarios.
Yolov8 base model generation
The Yolov8 model in this study is generated using a meticulously curated Tomato Leaf Disease dataset. The dataset is split into three subsets: 70% for training, 20% for validation, and 10% for testing. This division ensures that the model is trained on a substantial portion of the data while having separate datasets for validation and testing to evaluate its performance accurately.
The training process involves feeding the Yolov8 model with the training subset, where the model learns to identify intricate features and patterns associated with various tomato leaf diseases. During training, the model iteratively adjusts its parameters to minimize the difference between predicted and actual disease labels.
The validation process assesses the model’s performance on the validation subset, helping to fine-tune hyperparameters and prevent overfitting. This step ensures that the model generalizes well to new, unseen data.
Finally, the testing process evaluates the Yolov8 model on the reserved testing subset, assessing its ability to accurately detect tomato leaf diseases on previously unseen data. The experimental results obtained through extensive testing affirm the efficacy of the proposed methodology, highlighting the model’s capability to achieve accurate and reliable tomato leaf disease detection.
Model evaluation techniques
Precision, recall, F1 score, and mean Average Precision (mAP) are commonly used metrics to assess the performance of object detection models. In the context of tomato leaf disease detection using YOLOv8 and YOLOv5, this is how these metrics are employed to assess the performance:
Model evaluation and discussion
In this segment, we elaborate on the various tests conducted to assess the model. Within this context, we carried out distinct experiments and juxtaposed the outcomes using diverse evaluation metrics, including mAP, precision, recall, and F1-score.
Evaluation of convolutional neural network (YOLOv5) model
In our research, we have meticulously crafted a YOLOv5 model tailored for the detection of tomato leaf diseases on a bespoke dataset. This endeavor follows a structured approach that encompasses several key steps. We initiated by assembling a diverse collection of tomato leaf images and meticulously annotating them to facilitate model training. Subsequently, we subjected these images to preprocessing procedures involving resizing and normalization, ensuring they aligned with YOLOv5’s input requirements. Our model’s architecture was thoughtfully configured to accommodate the specific number of disease classes we aimed to detect. Leveraging transfer learning with pre-trained weights expedited the training process, and we meticulously fine-tuned hyperparameters, employing techniques like data augmentation. Throughout the training phase, we closely monitored the model’s performance on a validation set. Upon completion, we assessed the model’s accuracy using comprehensive metrics, which yielded impressive results with an F1 score of 0.98, precision of 0.93, recall of 0.99, and mAP of 0.97. The performance of our YOLOv5 model is visually depicted in Fig. 2. This culmination results in a highly capable YOLOv5 model, proficient in accurately detecting and localizing diverse tomato leaf diseases within previously unseen images from our custom dataset. Such an achievement holds immense promise for advancing disease management in the realm of agriculture.

F1 score, precision, recall, and mAP carve.
The evaluation of the performance of a generated YOLOv5 model involves a close examination of its training and validation losses, which provide critical insights into its training dynamics and generalization capabilities. The training loss is a fundamental metric that quantifies the disparity between the model’s predictions and the actual ground truth during the training process. As the model trains, the training loss should ideally decrease over time, indicating that the model is learning to make more accurate predictions on the training data. However, it’s important to monitor for signs of overfitting, where the training loss continues to decrease while the validation loss starts to increase. This divergence implies that the model may be fitting the training data too closely and might not generalize well to unseen data. By tracking the trends of training and validation losses, we gain valuable insights into the model’s performance during training and its potential for effective object detection on new images.
The validation loss plays a crucial role as it measures the model’s performance on data that it hasn’t encountered during training. A decreasing validation loss implies that the model is learning features that are generalizable and successfully capturing the patterns of the target objects. Conversely, an increasing validation loss may suggest that the model is struggling to generalize, indicating potential issues like overfitting. By comparing the training and validation losses, we can identify the optimal training point where the model achieves a balance between accuracy on the training set and the ability to generalize to new, unseen data. This iterative evaluation based on training and validation losses allows us to fine-tune the model’s hyperparameters, architecture, and training strategies to achieve the best possible performance in object detection with YOLOv5. The training and validation losses of YOLOv5 are depicted in Fig. 3. Finally, the results of the YOLOv5 model are shown in Fig. 4.
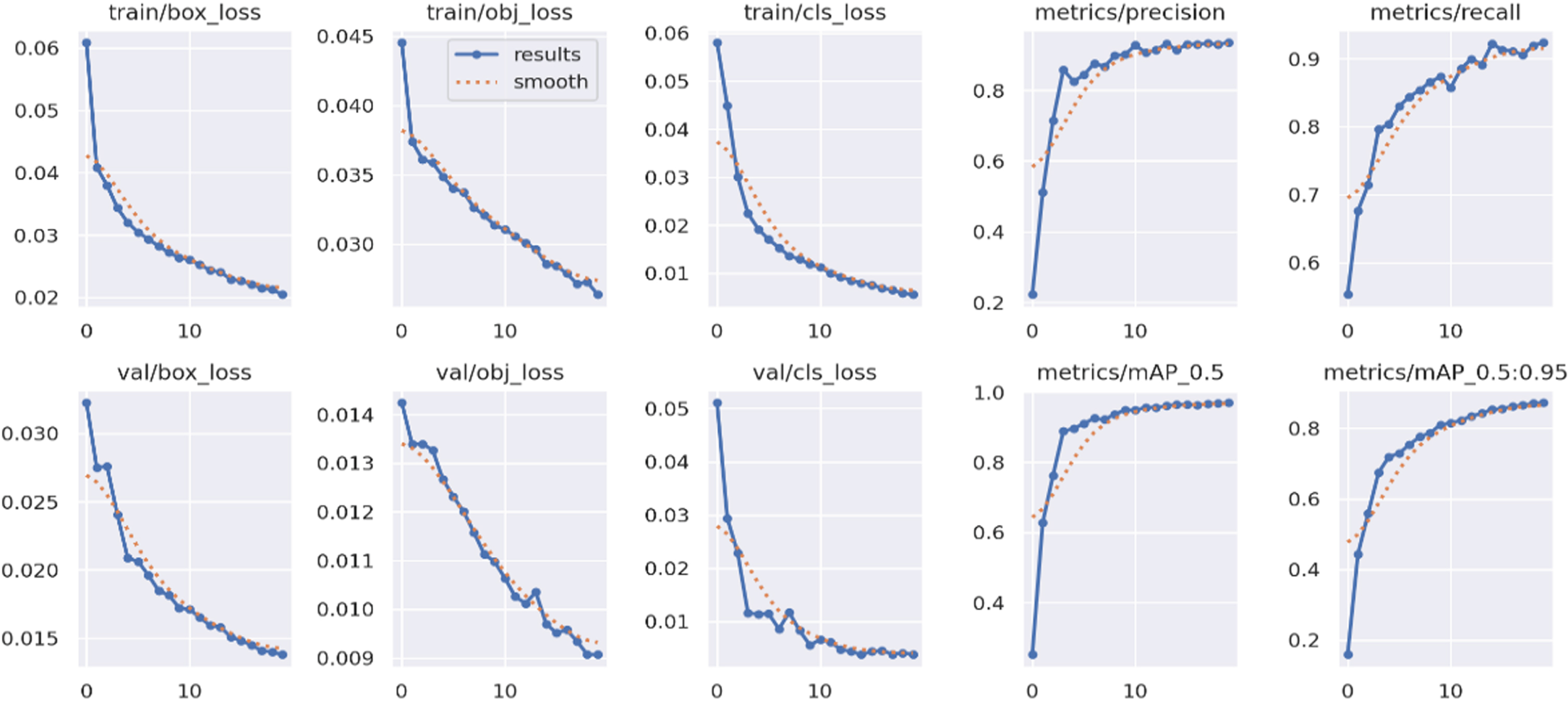
Training and validation losses of YOLOv5.

Result of YOLOv5 model.
In our study, a YOLOv8 model for tomato leaf disease detection on a custom dataset is generated through a systematic process. The procedure involves collecting and annotating a diverse set of tomato leaf images, preprocessing them by resizing and normalizing, configuring the YOLOv8 architecture to accommodate the number of disease classes, and utilizing transfer learning with pre-trained weights for efficient training. With careful hyperparameter tuning, the model is trained on the annotated dataset, leveraging techniques such as data augmentation and monitoring its performance on a validation set. After training, the model’s accuracy is evaluated using metrics

F1 score, precision, recall, and mAP carve.
The performance evaluation of the generated YOLOv8 model is conducted by analyzing its training and validation losses, providing insights into the model’s training progress and generalization capabilities. The training loss is a crucial metric that quantifies the disparity between the model’s predictions and the ground truth during the training process. As the model trains, the training loss should ideally decrease, indicating that the model is learning to make more accurate predictions. However, it’s essential to monitor for signs of overfitting, where the training loss continues to decrease while the validation loss starts to increase. This divergence suggests that the model is fitting the training data too closely and might not generalize well to new, unseen data. By tracking the trend of training and validation losses, we gain valuable information about the model’s performance during training and its potential for effective disease detection on novel images. Figure 4 shows the result of the YOLOv8 model.
In our evaluation, the validation loss is equally significant as it measures the model’s performance on data it hasn’t encountered during training. A decreasing validation loss implies that the model is learning generalizable features and successfully capturing disease-related patterns. On the other hand, an increasing validation loss might indicate that the model is struggling to generalize, suggesting potential issues like overfitting. By comparing the training and validation losses, we can identify the optimal training point where the model achieves a balance between accuracy on the training set and the ability to generalize to unseen data. This iterative evaluation based on training and validation losses allows us to fine-tune the model’s parameters, architecture, and training strategies to achieve the best possible performance in tomato leaf disease detection on our custom dataset. The training and validation losses are depicted in Fig. 6, and the results of the YOLOv8 model are shown in Fig. 7.
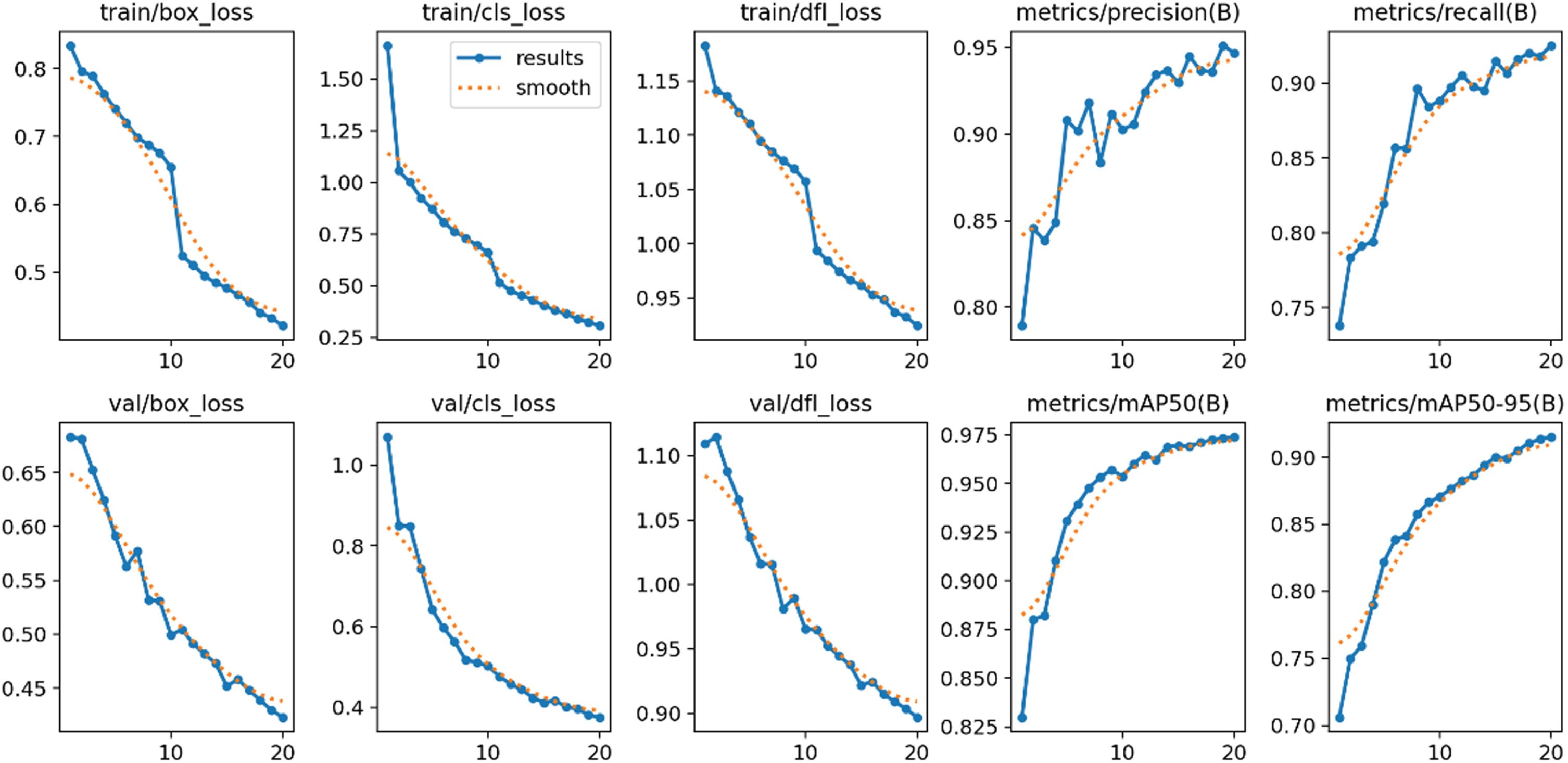
Training and validation losses of YOLOv8.

Result of YOLOv8 model.
This paper utilizes a dataset comprising 10,000 images of tomato leaf diseases for training and model development. The collected data undergoes a series of preprocessing steps, including data annotation and data augmentation, aimed at enhancing image quality by noise reduction and dataset expansion. After these enhancements, two distinct experiments are conducted to compare the effectiveness of models created using YOLOv5 and YOLOv8 approach. All models are created using augmented datasets. To determine the optimal model, performance evaluation metrics such as mAP, precision, recall, and F1-score are employed. The subsequent table illustrates a comparison of the developed models based on their training and test accuracies. The comparison of YOLOv5 and YOLOv8 model results is depicted in Table 1 and Fig. 8.
The comparison of YOLOv5 and YOLOv8 models results
The comparison of YOLOv5 and YOLOv8 models results
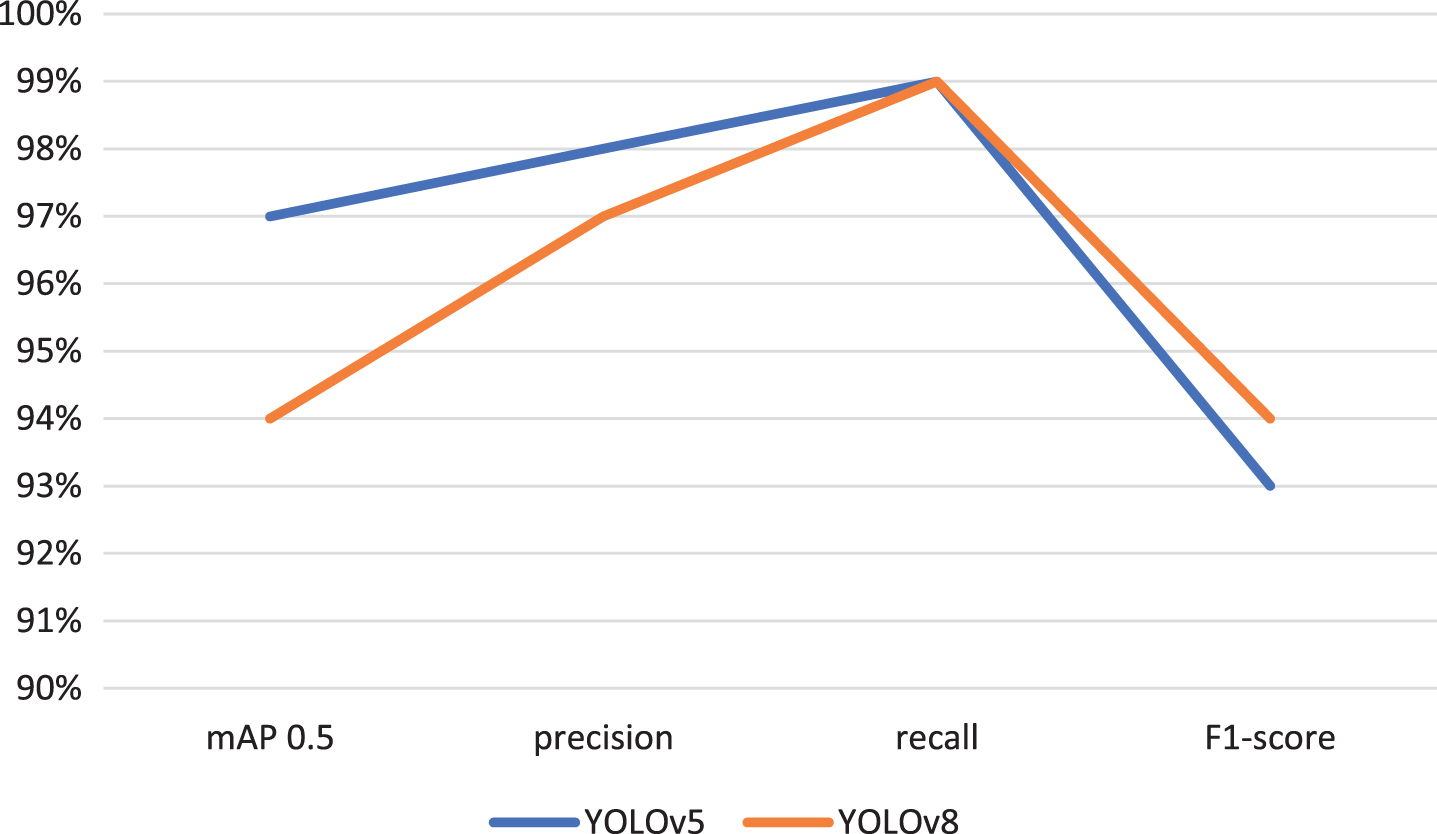
The comparison of YOLOv5 and YOLOv8 models.
As shown in Fig. 8, based on the provided performance metrics for both YOLOv5 and YOLOv8 models, we can observe that YOLOv5 outperforms YOLOv8 in terms of mAP at a threshold of 0.5, precision, and F1-score. YOLOv5 achieves an impressive mAP of 97%, indicating its effectiveness in accurately detecting objects. In contrast, YOLOv8 lags slightly behind with a still respectable mAP of 94%. Additionally, YOLOv5 demonstrates higher precision at 98% compared to YOLOv8’s 97%, suggesting that YOLOv5 is better at minimizing false positive detections. The recall metric, indicating the model’s ability to capture all relevant objects, is nearly identical at 99% for both models. However, when considering the F1-score, which balances precision and recall, YOLOv5’s score of 93% surpasses YOLOv8’s score of 94%. This indicates that YOLOv5 offers a more balanced performance in terms of precision and recall, making it the better choice for this specific detection task.
In summary, based on the provided performance metrics, YOLOv5 appears to be the superior model for the task of object detection when compared to YOLOv8. It achieves a higher mAP, precision, and F1-score, signifying its ability to detect objects accurately while maintaining a good balance between minimizing false positives and capturing all relevant objects. However, it’s essential to consider the specific requirements and constraints of the application when choosing between these models, as the choice may also depend on factors like computational resources and real-time processing capabilities.
The accurate detection of tomato leaf diseases has become indispensable within the agricultural sector, playing a pivotal role in safeguarding crop yield, quality, and global food security. Numerous methodologies have been explored in the literature to address this challenge, reflecting the urgency to curb losses caused by these diseases. In particular, deep learning methods have emerged as a prominent choice, consistently demonstrating superior accuracy when compared to alternative techniques. This preference for deep learning-based approaches is grounded in their remarkable ability to autonomously learn intricate patterns from raw data, yielding enhanced accuracy and predictive capabilities. However, a prevailing challenge in deep learning-based tomato leaf disease detection pertains to consistently achieving high accuracy rates across diverse disease scenarios. This challenge is compounded by the demanding accuracy requirements critical for effective agricultural interventions. To address this hurdle, our study proposes a novel deep-learning model utilizing the Yolov8 architecture tailored to overcome the specified research challenge. Our approach encompasses the creation of a specialized dataset for tomato leaf disease detection, followed by rigorous model training, validation, and testing procedures. Experimental results and comprehensive performance evaluations substantiate the proposed method’s efficacy, illustrating its proficiency in achieving accurate tomato leaf disease detection. Through meticulous experimentation and thorough performance analysis, our study contributes to advancing the field of deep.
learning-based disease detection, offering a potent solution attuned to the complex nuances of tomato leaf diseases. To address concerns about insufficient detail for replication, our research methodology is meticulously outlined, encompassing each stage from dataset curation to the rigorous training, validation, and testing phases of the proposed deep learning method. Furthermore, the used dataset, tailored for tomato leaf diseases, is made available, promoting transparency and facilitating replication. By prioritizing clarity in methodology and sharing our dataset, we ensure that fellow researchers can accurately replicate and validate our findings, fostering a robust and collaborative scientific environment. Despite the advancements in deep learning-based tomato leaf disease detection, two primary limitations warrant consideration. Firstly, the challenge of achieving consistent accuracy across diverse disease types and environmental conditions persists, potentially leading to misclassifications and false negatives. Secondly, the reliance on large and well-annotated datasets poses a constraint, as collecting representative samples encompassing varying disease stages and environmental variations remains resource-intensive. Addressing these limitations, directions for future works could focus on developing ensemble methods that combine diverse models to enhance robustness and accuracy across various disease scenarios. Additionally, the exploration of transfer learning techniques could alleviate data scarcity concerns, enabling models to leverage knowledge from related plant disease datasets and adapt to new disease instances more effectively.