
Abstract
Deep Hashing is a technique used for retrieving images on a large-scale, encoding the latent code of images into binary codes, which significantly reduces computational and storage costs in image retrieval. This enables fast similarity comparison and search. However, this technique encounters two significant challenges: the extraction of discriminating category-specific image features and the conflict between metric learning and quantization learning. The latter challenge often results in the binary representation of latent codes being considerably ambiguous. To tackle these challenges, this paper proposes a novel Cross-Scale Fusion Deep Hash Network. The model is built upon a dual-branch framework, aiming to capture the most representative retrieval features. One branch employs Spatial Pyramid Pooling layers and a self-attention mechanism for local information extraction, whereas the other branch uses a sliding window methodology for capturing global information. Upon obtaining the local and global information, the Cross Feature Synergy Module proposed in this paper integrates these data points to form a comprehensive feature vector, ultimately generating a complete representation of the image. In order to address the conflict between metric learning and quantization learning, as well as improve the binary codes further, this paper introduces a meticulously designed, threshold-dependent Hash-Guided Metric Loss (HGM-Loss). The novel network proposed in this paper demonstrates superior retrieval performance in standard benchmark tests on multiple datasets, including CIFAR-10, CIFAR-100, ImageNet, and MS-COCO, outperforming the existing hash methods.
Introduction
In recent years, large-scale image retrieval has become a highly researched area in the fields of computer vision and multimedia computing [1–4]. With the widespread use of social media platforms and search engines, billions of images are constantly uploaded to the internet. Therefore, retrieving images similar to the query image from these massive libraries quickly and accurately has become a research topic of great practical value. Image descriptors [5, 6] play a critical role in encoding and measuring the similarity of image content in image retrieval. Due to the subtle and potentially overlapping feature differences among various categories of images, precise classification becomes challenging. Furthermore, the internal changes within the same category, such as variations in lighting, angle, or scale, also increase the difficulty of distinguishing features between different categories of images. Therefore, extracting discriminative features from images to achieve highly detailed visual understanding is a significant challenge. Given the excellent performance of deep neural networks (DNNs) in feature extraction, deep hashing [7, 8] has become an important research branch in recent years. It aims to map the high-dimensional feature vectors extracted by DNNs to low-dimensional vectors through specific hash functions. The encoded binary hash codes can minimize storage costs while preserving distinguishable features of images [7, 9–11].
Most existing deep hashing algorithms first extract continuous floating-point features from the last fully connected layer of a deep network before the classification layer, and then use a simple sign function as a post-processing step to calculate binary codes. Consequently, the network can be optimized through pair-based or triplet-based loss, either as a classification task, or using cosine similarity loss as a metric learning task. However, these methods ignore the issue of semantic information loss during the binarization process of continuous floating-point features. Therefore, a challenge that needs to be addressed is how to preserve the most important semantic information in the floating-point features in order to ensure retrieval quality. Previous works [12–16] have made significant efforts to address the issue of inevitable information loss during the binarization process. However, they have not resolved the incompatible conflict between metric loss and quantization loss. Metric loss is usually based on continuous space metric methods, such as euclidean distance or cosine similarity, to measure the similarity between images. It requires preserving as much semantic information as possible to accurately express image similarity in low-dimensional space. On the other hand, quantization loss maps continuous semantic information to binary codes, which inevitably introduces information loss and distortion, leading to severe distortion of image similarity in low-dimensional space. As shown in Fig. 1(a), the gradient direction of metric loss for the red cluster is opposite to that of quantization loss, and this common conflict causes clustering to deviate from the ideal hashing position during convergence, leading to the problem of erroneous hashing and a decrease in retrieval quality. To tackle these challenges, we propose a Hash-guided Metric Loss (HGM-Loss) that addresses the conflicting objectives of preserving semantic information and generating compact binary codes. HGM-Loss uses a threshold ν, which is determined by the number of hash bits and the number of classes, to prevent the distance between different classes from becoming infinitely distant. As shown in Fig. 1(b), this threshold ensures that negative samples are only penalized when their distance is less than ν, thereby preventing clustering from deviating from the ideal hashing position during convergence and maintaining the stability of the hashing position.

(a) The opposite gradient direction from the metric loss and the quantization loss balances the red cluster, leading to a higher likelihood of error hashing during binarization. (b) The red clusters are only affected by the quantization loss until they reach the hash position with the help of HGM-loss.
To capture the most critical semantic information from an image, it is essential for the network to extract both global and local features to generate better image descriptors. Global features, which can be designed to be invariant or robust to certain viewpoints and lighting conditions, are used as advanced semantic image signatures. Local features, on the other hand, provide geometric discriminative information about specific regions of the image and are more sensitive to local geometry and texture [17–19]. Therefore, fusing local and global features can effectively enhance the representation ability of the image descriptor. Our Cross-Scale Fusion Deep Hashing Network incorporates a global branch and a local branch, enabling the seamless integration of high-level semantics and fine-grained details. In addition, the local branch of our proposed Cross-Scale Fusion Deep Hashing Network is equipped with spatial pyramid pooling and self-attention mechanisms inspired by previous research [29], which are focused on extracting representative local features. A Cross-Feature Synergy (CFS) module is introduced to enhance the mutual influence between global and local features. Inspired by the orthogonalization idea, the module aims to orthogonalize global and local features to extract the critical local information and eliminate redundant components of global information. This enables the local and global components to mutually reinforce each other, thus generating final representative descriptors. By doing so, the discriminability and retrieval quality of the hash code can be improved. Our contributions can be summarized as follows:
Based on the expressive power of binary coding, we propose a novel network architecture called CSF-Net to achieve efficient image retrieval The Cross-Feature Synergy module (CFS) aims to utilize global semantics to extract discriminative local features, and fuse both global and local features to enhance the representation ability of the descriptors. The proposed Hash-Guided Metric loss(HGM-Loss) aims to mitigate the conflict between metric learning and quantization learning by restricting the learning scope of the metric term through meticulously designed thresholds. A large number of experiments demonstrate that our proposed CSF-Net outperforms existing hashing methods and achieves significant performance improvements in four public benchmark tests.
The remaining sections of this paper are structured as follows: first, Section II briefly reviews previous work related to deep hashing; second, Section III presents in detail our proposed Cross-Scale Fusion Deep Hashing Network, which fully utilizes both global and local features to enhance the representation ability of image descriptors, and employs the HGM-Loss to alleviate the conflict between metric learning and quantization learning; third, Section IV validates the effectiveness and flexibility of our proposed method through four benchmark experiments; finally, Section V concludes our work.
With the rapid expansion of image datasets in recent years, efficient image retrieval has become a hot topic in the field of image processing. Among numerous retrieval methods, due to its high computational efficiency and low storage cost advantages, the hash method [1–3, 9] has become one of the most popular methods for retrieval in large-scale image datasets. However, before the advent of deep learning, the accuracy of traditional hash methods in generating binary codes from handcrafted features was limited,since the inability of these features to optimally represent the content of images while maintaining semantic similarity. With the emergence of Deep Neural Networks (DNN), the method of image hashing has greatly benefited from the excellent performance of DNN in feature extraction from two-dimensional images. Deep learning methods have achieved significant success in this field, making deep hashing the mainstream of image retrieval. Examples of such methods include Convolutional Neural Network Hashing (CNNH) [9], Network in Network Hashing (NINH) [20], Bit-scalable Deep Hashing (BS-DRSCH) [21], and Hashnet [13]. The workflow of CNNH consisted of two phases: hash code learning and hash function learning. In the hash code learning phase, it decomposed the similarity matrix of samples into binary codes, and in the hash function learning phase, it fitted these binary codes using a CNN. Unlike CNNH, which follows a two-stage approach, both NINH and BS-DRSCH adopt a single-stage deep hashing framework. NINH utilizes a triplet ranking loss to maintain relative similarity and integrates image representation learning and hash code learning into a single framework. This framework consists of a shared subnetwork and multiple stacked convolutional layers for image feature extraction, and a segmentation coding module that utilizes a sigmoid activation function and a piecewise threshold function to output binary hash codes. BS-DRSCH constructed an end-to-end architecture to learn the hash function and could flexibly control the length of the hash code by weighting each bit of the hash code as needed. In addition, BS-DRSCH also defined weighted Hamming similarity to measure the dissimilarity between two hash codes. HashNet solved the gradient difficulty in optimization by optimizing a non-smooth weighted pairwise cross-entropy loss function with a sign activation function sign (.). This method could generate binary hash codes and cluster similar samples in feature space. Unlike traditional methods, HashNet avoided the problem of Tanh gradient approaching 0 in the domain, which led to small penalties for potential encoding between similar samples with relatively large relativedistances.
However, existing deep hashing learning frameworks based on contrastive loss and triplet loss often suffer from slow convergence, partly because they only use one negative sample per update and do not interact with other negative classes. To address this issue, [22] proposed a novel metric learning objective function called Multi-class N-pair Loss, based on triplet loss, which interacts with multiple negative samples per update. The objective function first generalizes triplet loss by allowing joint comparisons of N - 1 negative samples. Then, it reduces the computational burden of evaluating deep embedding vectors by using an efficient batch construction strategy that only contains N pairs ofexamples.
Although the idea of the above methods is to learn high-level semantic features of images through deep networks and then generate compact binary codes using hash networks, the global representations obtained by deep learning alone may not be sufficient to accurately retrieve similar samples with a large amount of redundant background. Thus, recognizing the need for more refined local features, our proposed method adopts a dual-branch feature extraction architecture with different scales to jointly consider both local and global features. Furthermore, while the existing methods aim to generate compact binary codes using hash networks, they fail to tackle the problem of losing a significant amount of continuous semantic information during the quantization process of floating-point features. DHN [7] combines quantization loss with metric loss based on pairwise loss to restrict potential codes and control quantization error to improve hash quality. Recent studies [23–27] have added quantization loss to reduce information loss in the binarization process and have demonstrated potential performance improvements. Although recent works have shown the potential of adding quantization loss to improve the performance of deep hashing techniques, the combination of metric loss with quantization loss can lead to information loss during binarization. To address this issue, we propose HGM-loss, a carefully designed approach that reconciles these two losses, resulting in significant performance improvements across various deep hashing techniques.
Method
In this paper, we propose a deep hash network for cross-scale feature fusion to optimize binary coding. The network consists of a dual-branch module and a cross-feature synergy module.
Problem Definition
As mentioned above, deep hash networks can learn a compact high-dimensional feature representation and transform it into binary hash codes through a hash function, enabling fast image retrieval. Given N images
Overview of CSF-Net
The CSF-Net framework proposed by us is shown in Fig. 2. Building upon the state-of-the-art image recognition model ResNet50, as in [1, 28], we introduce a dual-branch architecture, CSF-Net, to address the issue of insufficient representation of ambiguous objects in image encoding by deep learning networks. As is well-known, shallow layers of deep neural networks tend to capture fine-grained details such as edges and corners, while deeper layers are more sensitive to global and semantic information. Inspired by this, the dual-branch design of CSF-Net aims to leverage semantic context in Res4 to align and filter better local features, thus suppressing noise interference. The approach showcases a sophisticated fusion of deep learning and image retrieval techniques, resulting in a coherent and elegant solution for improving the representation of non-obvious targets in image encoding.
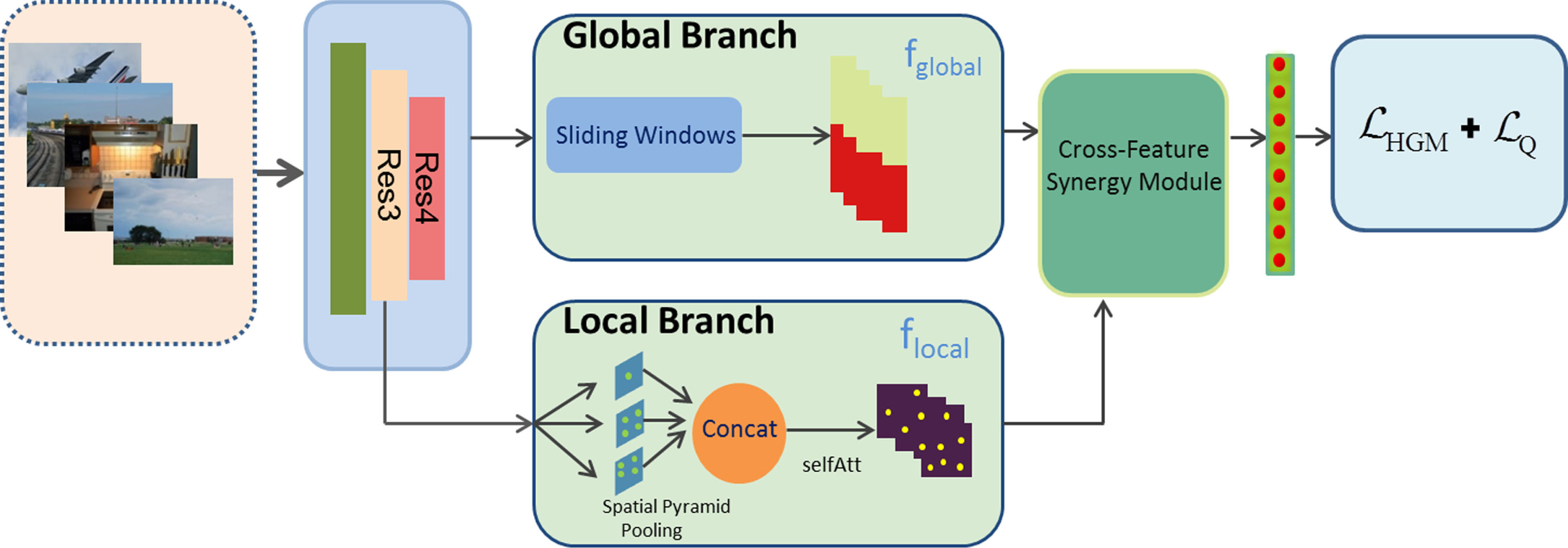
Overall structure of proposed CSF-Net, built upon ResNet50. The multi-scale features f
global
are obtained by the global branch which takes the output of Res4 block as input. The local branch, which models more local details f
local
after Res3 block, uses spatial pyramid pooling (SPP) and self-attention. The CFS module takes both f
global
and f
local
as inputs to generate the final representation. The metric loss(
As shown in Fig. 2, our global branch remains the same as the original ResNet50, but all pooling and fully connected layers after the Res4 block are removed to preserve spatial information in the feature maps. In addition, a multi-scale sliding window is introduced to capture multi-scale spatial global information by applying sliding windows of different sizes to the feature map. This allows the network to capture contextual information at multiple scales and helps to improve the overall performance of the model. The global features, abbreviated as f
g
, can be expressed as:
In Equation (1), the feature maps f41 and f42 are obtained by processing the output of the Res4 layer with Conv2d, but they have different sizes. We use 3 × 3 and 5 × 5 as the window size (denoted as s w 1 and s w 2 , respectively) to apply multi-scale sliding windows on them. To enhance the ability of neural networks to extract detailed information from images and jointly extract local descriptors, we also introduced a local branch after the Res3 block, which consists of spatial pyramid pooling layers and a self-attention module. Specifically, we perform max pooling on the output feature f3 of the Res3 block at different spatial scales to obtain multiple feature maps with different spatial receptive fields. Each feature map is then flattened into a one-dimensional vector, and these vectors are concatenated along the channel dimension. By performing pooling operations at different scales on the image, a fixed-size feature representation is generated, allowing the model to capture multi-scale information of the target. This enables the model to extract relevant information from features at different scales, even when the position and size of the target vary in the image, thus maintaining effective recognition capabilities. Therefore, the spatial pyramid pooling layer contributes to enhancing the performance and robustness of the model, enabling it to adapt to targets of different scales and positions [29]. Finally, the concatenated feature map is passed to the self-attention module to further model the importance of each local feature point. The self-attention mechanism computes the similarity between input features and allocates weights accordingly. This allows the model to focus more on the areas that have the greatest impact on the results, reducing the influence of other distracting information. Since it takes into account and emphasizes the importance of meaningful information areas, it can better capture representative, distinguishable local features. This mechanism enhances the model’s ability to extract local features and contributes to improving the accuracy of the model’s prediction [16].
The global feature component f g and the local feature tensor f l , as two important feature sources, undergo feature fusion and elaborately designed processing through the Cross-Feature Synergy module, resulting in a compact descriptor that effectively preserves spatial information from both branches and achieves adaptive context alignment, which will be discussed in detail later. The design of the Cross-Feature Synergy module aims to fully leverage the strengths of global and local features, achieve complementarity and synergy, and better capture semantic information from images.
Our Cross-Feature Synergy (CFS) module operates as illustrated in Fig. 3. The input to CFS includes two components: the multi-scale global feature f
g
based on sliding windows and the local feature f
l
based on self-attention. To start, we align the local feature tensor and global feature tensor by calculating the contextual repetition of each local feature point

Framework of our proposed Cross-Feature Synergy Module(CFS).
Due to the fact that global feature tensor contains more semantic contextual information, while local feature tensor contains more detailed local contextual information, redundant context in complex backgrounds may contain unnecessary semantic information. Therefore, to better extract fine-grained local features with multi-scale spatial context, we adopted a strategy of eliminating redundant features. Specifically, when extracting local information from global features, we use subtraction operation to cancel out the duplicated information with local features, thus retaining information that only appears in the global scope. This effectively separates global and local features, and extracts more valuable features. The whole process can be expressed as follows:
By following this procedure, we obtain a tensor of size C × H × W, where each element is orthogonal to the global feature f g . We then concatenate the C×1 vector f gc to each element of this tensor, resulting in a new tensor of size C0 × H × W. Finally, we aggregate this tensor into a C0 × 1 vector. Finally, a K×1 descriptor is generated using a fully connected layer. Here, we choose to use pooling to aggregate the cascaded tensors. Through our Cross-Feature Synergistic (CFS) module processing, the extracted features align detailed local features with global spatial context, thus focusing on the key instance regions.
As is well known, the goal of metric loss is clustering, which is a distance-based learning method designed to learn a mapping function that maps input data from a high-dimensional feature space to a low-dimensional embedding space, and makes samples of the same class more compact in the embedding space, while making the distance between different class samples more distinct. This technique is widely used in the field of image retrieval and is used to optimize the performance of models. Existing techniques [30–33] typically use cosine similarity estimated in mini-batches to design the metric loss term, which can be represented as:
In image retrieval, deep learning models are commonly used to learn feature representations, which are then subjected to distance measurement to enable matching of similar images. The purpose of metric loss is to optimize this feature representation so that similar images are closer to each other in feature space, while dissimilar images are further apart. On the other hand, quantization loss aims to quantize continuous feature vectors into discrete binary codes for more efficient storage and retrieval. However, the learning objectives of metric loss and quantization loss are contradictory, since metric loss requires the feature representation to be more compact and continuous in feature space, while quantization loss requires the feature representation to be more discrete in the binary code space.
To illustrate this contradiction more clearly, we use an example of a two-dimensional feature space shown in Fig. 4, which contains three different categories. To better demonstrate their distribution in the two-dimensional feature space, all samples are scaled to a feature circle with a radius of r =

(a) The objective of metric loss is to maximize the inter-class distance while minimizing the intra-class distance in the feature space. (b) Once the quantization loss is incorporated, the class centroids tend to shift towards the binary points. However, the metric loss that repels the classes from one another prevents the centroids from aligning with the optimal hashing positions. (c) Upon integrating hash-guided metric loss, the solution obtained is the global optimum for this problem.
Figure 4(a) illustrates the goal of metric learning by showing samples of three different classes in a 2D feature space, where the centers of these classes are pushed as far apart from each other as possible to form an equilateral triangle, representing the best solution where each cluster is separated as much as possible from each other. In contrast, in Fig. 4 (b), the goal of quantization learning is to pull the class centers to one of the four binary points as closely as possible to minimize information loss during the binarization process, resulting in the optimal quantized solution (i.e., minimizing information loss as much as possible). It is visually clear that in metric learning, we want the center points of different classes to be separated as much as possible, while in quantization learning, we want the center points of different classes to be pulled towards one of the four binary points, to minimize information loss in the hashing process. Therefore, there is no solution that simultaneously satisfies the best metric and the best quantization goals. In fact, the ideal solution is to have the three class centers strictly located at the three of the four binary points, which is the optimal global solution with the least information loss during the binarization process (as shown in Fig. 4 (c)). When both metric loss and quantization loss are integrated into a method, an intermediate state is obtained (as shown in Fig. 4 (b)), which lies between the optimal metric solution and the optimal global solution. This integration leads to more information loss during the binarization process, thus reducing retrieval accuracy. Specifically, samples that are further away from the cluster center are more likely to be misclassified into other binary points.
The Proxy-Anchor [37] was previously the state-of-the-art method, which used the cosine similarity estimated in small batches to design the metric loss term. Our proposed HGM-loss modifies the linear computation part of the cosine similarity in the Proxy-Anchor metric loss to restrict the learning scope of the metric term. The metric loss of Proxy-Anchor is calculated as Equation 8:
In Equation 8, the exponential term is linearly related to the cosine similarity of all samples, which contradicts the principles of quantization learning discussed earlier. Therefore, our proposed HGM-loss uses a specific threshold value ν to correct this part of the equation. The HGM-loss is shown in Equation 9:
where F(a,b) = max(0,a + b), δ is a margin hyperparameter to prevent the model from fitting too closely to the training data. The proposed HGM-loss modifies the error component calculation part in the Proxy-Anchor metric loss with a specific threshold value to alleviate the conflict between metric loss and quantization loss. The value of threshold ν depends on the binary code length and the number of categories, which indicates the minimum distance d min of the optimal global solution. The goal of HGM-loss is not to have an infinite metric distance between different classes, but to push them apart until they reach a specific distance ν derived from the minimum distance d min . When the distance between different classes satisfies ν, the optimal metric solution is considered to have been achieved. Overall, the HGM-loss aims to balance the separation of different class clusters and the minimization of information loss in the quantization process.
The calculation method of threshold ν is equivalent to minimizing the distance between given binary codes, however, previous work [34] has proven that computing the ideal minimum distance requires exponential time complexity, which is an NP-hard problem. However, researchers [35] proposed a method to estimate the minimum distance of binary linear codes and provided a table of lower bounds for the minimum distance of binary linear codes, denoted as
Dataset
We conduct extensive experiments on four representative benchmarks (CIFAR-10 [38], CIFAR-100 [38], MS-COCO [39], and ImageNet [40]) to validate the performance of our proposed method and to demonstrate the effectiveness of the proposed CSF-Net.
Evaluation protocols and implementation details
The CSF-Net is implemented in the PyTorch framework. We use pre-trained ResNet-50 on ImageNet as the backbone to show the superiority of our solution. The convolutional layers with the proposed CFS module and HGM-loss are optimized using backpropagation. We use stochastic gradient descent (SGD) as the optimizer with a momentum of 0.9 and weight decay of 1e-5. The initial learning rate is set to 0.01. As for hyperparameters, we set δ to 0.2 based on empirical experience. All experiments use batch size of 128 trained on a NVIDIA TITAN X (Pascal) GPU for 150 epochs. We employ the widely used metric of mean average precision (mAP) to evaluate the retrieval performance, which is a metric ranging between 0 and 1, used to measure the accuracy and reliability of a retrieval system.
Table 1 details the comparisons of mean average precision (mAP) across various hash bit lengths, allowing us to juxtapose the performance of our proposed CSF-Net method with that of alternative leading-edge methods. Intriguingly, CSF-Net exhibits superior performance when compared to other techniques, particularly when we consider the 32-bit and 48-bit hash codes within the CIFAR-10 and CIFAR-100 datasets. While the breadth of categories present in the CIFAR-100 dataset makes image identification a more demanding task, and results in a more notable performance decline for all methods when compared to CIFAR-10, CSF-Net remains robust. It’s worth noting the stark performance drop exhibited by the DPSH and DSDH methods when transitioning from CIFAR-10 to CIFAR-100, yet our CSF-Net shows resilience amid these challenges. This highlights our solution’s capability to mitigate observed conflict between metric learning and quantization learning, thereby demonstrating the robustness of our approach.
The map performance by Hamming Ranking for various hash bits configurations was evaluated on CIFAR-10, CIFAR-100, ImageNet, and MS-COCO datasets
The map performance by Hamming Ranking for various hash bits configurations was evaluated on CIFAR-10, CIFAR-100, ImageNet, and MS-COCO datasets
When discussing the large-scale ImageNet and MS-COCO datasets, CSF-Net consistently outshines. With a 64-bit hash code on ImageNet, an uptick of 0.5%, 0.6%, and 1.5% is observed over the next best performing method—CSCE-Net for 16-bit, 32-bit, and 64-bit hash bits respectively. Our CSF-Net implementation on the MS-COCO dataset also outperforms CSCE-Net, barring a minor exception where the performance dips with 32-bit hash bits. Amid varying datasets and variable hash bit lengths, CSF-Net remains steady and impressive. It confirms the algorithm’s inherent strength for extracting and isolating crucial granular fine-grained information. We also recognize the role of our newly proposed HGM-Loss, which plays a significant part in minimizing informational loss during the binarization process to the farthest extent.
In Fig 5, we demonstrate the comparative results between our method and others in terms of precision when employing 64-bit binary codes. Our method stands out with a significant advantage in precision among all compared. This advantage is attributed to the effective use of 64-bit binary codes in our method to acquire and retain information, as well as the exceptional stability and accuracy of our algorithm while handling high-dimensional data and complex scenarios.
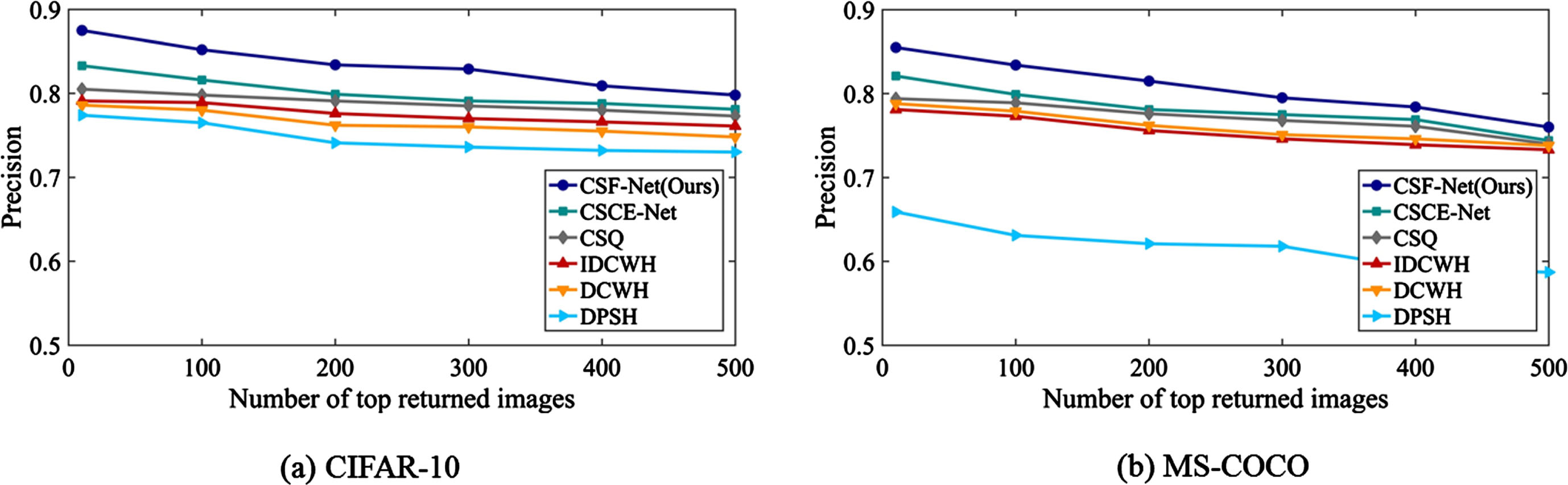
Precision@top-500 curves on CIFAR-10 and MS-COCO datasets with binary codes @ 64-bits.
We also observed that although our algorithm performs well under the settings of 64-bit binary coding, there might be minimal precision drop under certain circumstances, such as complexity in the image patterns or in cases of high noise. This indicates that there is room for improvements in our method to handle these challenges.
On the other hand, in Fig 6, we present the retrieval results of our CSF-Net on the CIFAR-10 dataset, using only 12-bit hash codes. The graph suggests that our method can execute accurate image retrievals even when only applying 12-bit hash codes. This further emphasizes the strong capability of our method in dealing with the issue of information loss during the binarization process.

Shown here are the top 7 images retrieved with our proposed method using 12 bits on the CIFAR-10 dataset
Outcomes obtained from conducting experiments with diverse architectures of the CSF-Net
Outcomes obtained from conducting experiments with diverse architectures of the CSF-Net
Comparison of mAP using different loss variants
We adopted various loss settings in the experiment represented in Table 4. “Proxy-NCA” introduced a set of class centers that can be learnt using proxy-based loss. “Proxy-Anchor” is also a proxy-based loss, which amalgamates the advantages of proxy-based methods and pair-based methods. “Qua” stands for Quantization loss. “CE” refers to the Cross Entropy loss utilized, and “CF” represents the CosFace loss implemented.
mAP performance with different margin hyperparameters δ for a 32-bit hash code on three datasets using the same model and loss function
From Table 4, it is evident that our proposed HGM-Loss+Qua algorithm displays remarkable performance on the Imagenet100 dataset, with average mAP highest performances of 0.874, 0.906, and 0.912 respectively. This substantiates the robustness and effectiveness of our HGM-Loss, even when the increase in the number of categories within the dataset exacerbates the conflict issues between metric learning and quantization learning. Our method effectively ameliorates these conflicts and manifests its resilience.
“CE+Qua” and “CF+Qua” represent the combined results of Cross-Entropy loss and CosFace loss. Their respective mAP performances for 16bits, 32bits, and 64bits stand at 0.862, 0.886, 0.893 and 0.863, 0.887, 0.894. Although these scores are slightly lower than when we utilize our proposed HGM-Loss, they still verify that implementing Quantization loss can help improve the precision of image retrieval.
In conclusion, these experimental outcomes validate the superiority of our proposed HGM-Loss in achieving an effective balance between metric learning and quantization learning and thereby facilitating efficient and precise image retrieval.
In HGM-Loss, the alpha value has a direct impact on the model’s performance. The alpha value controls the weight of the two parts of the loss in HGM-Loss, namely, the metric loss and the quantization loss. Proper adjustment of the alpha value can affect the model’s performance in two aspects: 1. Metric learning of the data, that is, how to separate the distance between different categories in the feature space; 2. Quantization learning of the hash code, that is, how to map the continuous feature vectors to the discrete binary code. By adjusting the alpha value, the impact of these two aspects can be balanced, thereby optimizing the overall model performance. Therefore, choosing the appropriate alpha value is a key factor in optimizing the performance of HGM-Loss. As shown in Table 6, we conducted experiments on the model on three standard datasets (CIFAR-10, CIFAR-100, and ImageNet), with the hash code length set to 32 bits, and the scaling factor α ranging from 0.15 to 0.6. The experimental results show that the optimal performance for each dataset occurs at a specific value of α. Specifically, for CIFAR-10, the optimal α value is 0.15; for CIFAR-100, the optimal α value is 0.25; for ImageNet, the optimal α value is 0.45.
mAP performance with different feature fusion methods on ImageNet datasets
mAP performance with different scaling factor α for a 32-bit hash code on three datasets using the same model and loss function
In the CIFAR-10 dataset, with the increase in the value of α, the model’s mAP performance exhibited a significant decrease. When α is set at 0.15, the mAP reaches the maximum value of 0.889. This suggests that for this dataset, a smaller α value can help the model achieve higher performance. This result may be due to the greater tolerance of error as a result of a smaller α, which allows the model to better learn the underlying patterns of the data and to avoid over-concentrating on noise and outliers. However, in the CIFAR-100 dataset, the model’s performance reaches its highest value when α is 0.25. This may be due to the fact that for datasets with more categories, a slightly higher α value can be beneficial in distinguishing more classifications, thereby improving the model’s performance. On the ImageNet dataset, with the increase in α, the model’s performance initially shows an upward trend and achieves its peak when α is 0.45. Afterward, as α continues to increase, the model’s performance starts to decline. This may be related to ImageNet’s higher image complexity and the number of categories, which allows the model to improve performance within a certain range of increased α, but an overly large α may cause the model to overfit, leading to performance degradation.
In summary, this ablation study reveals the impact of the α value on the model’s classification performance, and indicates that the selection of α needs to take into account the characteristics and complexity of the dataset. A specific α value cannot adapt to all datasets, thus it needs to be chosen and adjusted according to the specific dataset and task at hand.
Firstly, it can be observed that our CFS method achieves competitive performance across all hash bit lengths. Particularly, at 64-bit hash bit length, our CFS method achieves the highest performance with an mAP@1000 of 0.912, surpassing all other methods. This indicates a significant advantage of our CFS module in cross-scale feature fusion, enabling better capture of both global and local feature information in images at 64-bit hash length. Secondly, although in some cases, such as at 32-bit hash length, our CFS method slightly trails behind CFNet, it still demonstrates high mAP@1000 (0.906). This suggests that while CFNet may excel in capturing global feature information at 32-bit hash length, our CFS method remains competitive in local feature fusion.
Compared to other feature fusion methods, our CFS method exhibits stable performance across different hash bit lengths. In particular, our CFS method outperforms CFP in terms of mAP@1000, further confirming the superiority of our CFS module in extracting key fine-grained information. Overall, the results of the ablation study validate the effectiveness and competitive performance of our CFS module across different hash bit lengths. While in some cases, other feature fusion methods may demonstrate better performance, our CFS module’s advantage in cross-scale feature fusion is more pronounced, providing a more flexible and robust feature representation for image retrieval tasks.
In this paper,we consider the representational power of feature fusion and proposes a cross feature synergy module for deep hashing. The proposed CSF-Net can extract fine-grained local information by utilizing global contextual information, thereby improving the recall rate for difficult samples. In addition, to alleviate the challenging conflict between metric learning and quantization learning in deep hashing, we proposes a new loss function called Hash-Guided Metric loss (HGM-Loss), which achieves a balance between metric and quantization terms by limiting the learning range of metric terms and alleviating the problem of semantic information loss. Extensive experiments on four standard datasets verify the superiority of our method, and the results show that our method achieves significant performance improvements in mAP evaluation metric. Visualization results demonstrate that CSF-Net can achieve better retrieval performance and visual consistency.
Looking forward, there are several promising avenues to further evolve our work. Firstly, we believe there is room to expand our study of feature fusion, potentially integrating varying image feature types to provide a more comprehensive image representation. Secondly, our future research paths will include a deeper exploration into different hash coding techniques, such as investigating the impact of hash length on retrieval accuracy and speed, as well as accommodating a wider array of data types and scenarios through multi-hash coding techniques. We assert that these exploratory directions may not only improve the method proposed herein but can also broaden its application potential.
Our ongoing commitment to this line of enquiry, prompted by our findings in this paper, will continue to drive the improvement and innovation in deep hashing methods.
Footnotes
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China (No. 62173285 and 62103345), the Fujian Provincial Natural Science Foundation of China (No. 2021J011181, 2020J02160 and 2022J011234) and Xiamen Youth Innovation Fund Project (No. 3502Z20206072 and 3502Z20206076).