
Abstract
Image segmentation is critical in medical image processing for lesion detection, localisation, and subsequent diagnosis. Currently, computer-aided diagnosis (CAD) has played a significant role in improving diagnostic efficiency and accuracy. The segmentation task is made more difficult by the hazy lesion boundaries and uneven forms. Because standard convolutional neural networks (CNNs) are incapable of capturing global contextual information, adequate segmentation results are impossible to achieve. We propose a multiscale feature fusion network (MTC-Net) in this paper that integrates deep separable convolution and self-attentive modules in the encoder to achieve better local continuity of images and feature maps. In the decoder, a multi-branch multi-scale feature fusion module (MSFB) is utilized to improve the network’s feature extraction capability, and it is integrated with a global cooperative aggregation module (GCAM) to learn more contextual information and adaptively fuse multi-scale features. To develop rich hierarchical representations of irregular forms, the suggested detail enhancement module (DEM) adaptively integrates local characteristics with their global dependencies. To validate the effectiveness of the proposed network, we conducted extensive experiments, evaluated on the public datasets of skin, breast, thyroid and gastrointestinal tract with ISIC2018, BUSI, TN3K and Kvasir-SEG. The comparison with the latest methods also verifies the superiority of our proposed MTC-Net in terms of accuracy. Our code on https://github.com/gih23/MTC-Net.
Introduction
Medical image segmentation is essential for assisting doctors with diagnosis. It can help with the analysis of dermoscopic images, polyp images, breast ultrasound images, and so forth. In comparison to traditional manual diagnosis methods, computer-aided diagnosis (CAD) automatically identifies diseases and segments lesion portions to achieve higher accuracy and assist doctors in making more objective and timely diagnoses.
With the ongoing development of deep learning, medical image segmentation methods based on convolutional neural networks (CNNs) have garnered a lot of attention in recent years. The limitations of the previous methods are avoided, and segmentation efficiency and accuracy are greatly improved. For example, the well-known fully convolutional networks (FCNs) [1] and UNet [2], an encoder-decoder network that has demonstrated significant advantages in image segmentation tasks, were proposed in [3] to improve the quality of segmentation of objects of varying sizes by mitigating the unknown network depth through efficient fusion of U-Net of varying depths. [4] proposes DoubleU-Net, which uses two stacked U-Net architectures to generate more accurate segmentation masks. and the ResU-Net proposed by [5], which uses residual units to simplify deep network training; and so on. All of these methods demonstrated the utility of encoder-decoder networks in image segmentation tasks. However, due to network structure limitations, successive downsampling results in the loss of global context information, which is abundant and important for accurate localization of skin lesion boundaries, and has a direct impact on the segmentation network’s accuracy. Furthermore, the underlying feature maps of images are frequently overlooked, despite the fact that low-level feature maps contain a large amount of spatial information that is critical for the localization and delineation of lesion regions. As a result, significant advancements are still required to improve the network’s ability to extract contextual information and learn remote dependencies between image pixels.
In this paper, we introduce MTC-Net, a unique multi-scale feature fusion network for medical picture segmentation. We merge convolutional and self-attentive methods in the encoder to build multi-scale feature maps while attaining global perceptual field for all images, unlike typical convolutional neural networks. To improve the network’s feature extraction capability, a multi-branch multi-scale feature fusion module (MSFB) is added to the decoder, which is integrated with a global cooperative aggregation module (GCAM) to train and fuse multi-scale features adaptively to accomplish feature fusion in space. We propose, on the other hand, a detail enhancement module (DEM) to improve the network’s ability to segment irregular boundaries. We experimented extensively on several medical image datasets and compared with the latest models. MTC-Net achieves 93.17% Dice on the ISIC2018 dataset; 96.53% segmentation accuracy on the BUSI dataset; 4.48% improvement in specificity (SP) of our network on the TN3K dataset compared to U-Net; and 81.45% recall on the Kvasir-SEG dataset, which is higher than the latest model.
The contributions of this paper can be summarized as follows: A detail enhancement module is proposed to capture the contextual information of local features through spatial attention module and channel attention module. The interdependence of channel mapping is utilized to enhance the contrast between class-related features. to improve the network’s ability to learn irregular boundary features of lesion regions. We include a multi-branch multi-scale feature fusion module in the decoder to extract richer hierarchical features through multi-branch convolutional layers, null convolution and hierarchical segmentation blocks to produce more detailed feature representations. And the global cooperative aggregation module is used to fully fuse the feature information at different levels of the decoder through bilinear interpolation transform and soft pooling operation to obtain more accurate segmentation results.
Related works
CNN-based methods
Convolutional neural networks are an important network framework in the field of deep learning, particularly in computer vision. CNN began with LeNet in the 1990s to solve the visual task of handwritten digit recognition, and the basic architecture includes convolutional, pooling, and fully-connected layers. Then came the AlexNet architecture, which has five convolutional layers and three fully-connected layers and uses ReLU instead of Sigmoid to accelerate SGD convergence. And GoogleNet replaces all of the later fully connected layers with simple global average pooling, propelling convolutional neural network research to new heights. ResNet, which was recently proposed in [6], implements a simple constant mapping by jumping connections and has demonstrated advanced performance in classification and segmentation tasks.
CNNs are widely used in medical image classification and segmentation tasks due to their efficient and accurate performance. By fusing all layer he features with an edge-guided module and modifying the jump-join part of the traditional UNet, DEA-UNet solves the problem of blurred lesion edges [7]. To better deal with complex images, [8] proposed CA-Unet++, which solved the loss of eigenvalues in the long jump connection process and upsampling process, respectively, using the channel module and attention module to achieve better image segmentation efficiency and accuracy. The proposed MR-UNet model of [9] uses bilinear interpolation instead of deconvolution in the UNet model, and the encoder includes residual blocks to improve segmentation capability. [10] proposed an attention-based residual dense depth network that can better preserve image details by combining the attention mechanism and residual connectivity. Multiple downsampling is prone to information redundancy in the encoder-decoder framework, and [11] proposed a remote image change detection network based on a multi-feature self-attention fusion mechanism, which can well avoid this drawback by adding a multi-functional self-attention mechanism to obtain richer contextual information. Among the skin lesion segmentation tasks, [12] proposed a new semi-automatic skin lesion segmentation method that overcomes the problem of low contrast between the lesion region and the surrounding healthy skin by combining a full convolutional network with multi-scale integration. Similarly, [13] proposed a new dense pooling layer for accurate skin lesion boundary identification and improved segmentation accuracy. FCN (fully connected network) and U-Net, two neural networks, are prone to parameter redundancy. [14] proposed an improved skin lesion segmentation model based on deformable 3D convolution and ResU-NeXt++, which improves the Jaccard index of skin lesion segmentation by standard reverse propagation for efficient training and improved Jaccard index for skin lesion image segmentation. Ms RED [15] improved the network’s learning capability by replacing the traditional convolutional layer in the encoder and decoder networks with a multi-channel feature fusion module. FAT-Net [16] included a novel functional adaptive transformer network based on the classical encoder-decoder architecture that can effectively capture remote dependencies and global contextual information, as well as improve feature fusion between adjacent level features by activating effective channels and suppressing irrelevant background noise. However, the traditional convolutional neural network-based approach has limitations in capturing rich global contextual information, and more progress is required.
Transformer
Since its introduction, the Transformer model has been widely used in natural language processing, computer vision, and many other fields. It is essentially an Encoder-Decoder architecture, with the encoding component consisting of multiple layers of encoders (Encoder), each of which is composed of two sub-layers: the self attention layer and a feedforward network layer. The Decoder, on the other hand, is made up of three sub-layers: a multi-headed self-attentive layer, an additional layer capable of multi-headed self-attentive of the encoder output, and a fully connected layer. Many improved models have been developed in recent years as a result of Transformer’s satisfactory results in the field of image processing. The VIT model divides the image into multiple patches, each of which is mapped into a fixed dimension using a NN network and input to a subsequent Transformer Encoder; when the image is classified, an identity token is added at the beginning of the sequence. When pre-trained on a large amount of sufficient data, VIT can achieve good results. The TNT model [17] further subdivides the patches in the original VIT into sub-patches, treating each patch as a sentence and the elements obtained by further subdivision of the patches as words. The model can find more similar sub-patch groups in the data, improving the model’s learning ability and generalization on the data. [18] proposed a Transformer model for pixel-level image tasks, incorporating the Pyramid CNN concept into Transformer and capturing finer-grained information by increasing the initial resolution and decreasing the resolution layer by layer, while reducing the running overhead. Swin Transformer [19] uses local attention to divide patches into windows, and attention between patches is only performed within the windows to improve operational efficiency. Swin Transformer also proposes the Shifted Window method, which uses different window configurations in different layers, and the window positions in the next layer will be shifted horizontally and vertically by 2 patches in order to make the patches within different windows in the previous layer interact with information. Transformer’s application in the field of computer vision has gradually matured, making a significant contribution to the field of computer vision and multimodality.
Proposed method
Network architectures
Figure 1 depicts the network’s overall design. For precise and dependable segmentation of lesion locations in medical imaging, we present a multi-scale feature fusion network (MTC-Net). To improve MTC-Net’s ability to segment lesions and deal with common issues like blurred lesion boundaries, low contrast, and irregular shapes, we built a network with four key components: a fusion encoder, a global cooperative aggregation module (GCAM), a detail enhancement module (DEM), and a multi-branch multiscale feature fusion module (MSFB). The fusion encoder, in particular, is used to extract multi-scale distant dependent features from the input image while keeping rich global context information. The first two layers of the encoder extract high-resolution low-level features with a considerable quantity of boundary information, which serves as a vital guide for the network’s boundary learning. The latter two levels can extract extensive global contextual information. The decoder’s multi-branch multi-scale feature fusion module builds multi-scale feature representations by separating blocks into layers, and GCAM fuses the features learned in each layer of the decoding stage to increase segmentation accuracy even further. DEM accepts encoder features and improves interclass discrimination and intraclass response via two parallel attention modules. The output is subsequently sent to the decoder for improved segmentation performance. Our network can efficiently fulfill the task of segmenting medical image lesions using the approaches described above.

The proposed MTC-Net network framework.
As shown in Fig. 1, we use a fusion encoder that combines translational invariance, input adaptive weighting, and a global perceptual field based on MBConv blocks and self-focus. Since shallow features mainly include some broad object feature patterns such as texture, color, and orientation, these features are usually not global, but deep features represent object-specific information, which usually requires global information. Therefore, we build a four-stage encoder structure that uses MBConv to capture spatial interactions in the first two stages and then performs deep convolution with inverted residuals. In addition to this, both depth-separated convolution and self-attention can be described as the sum of the weighted values of each dimension in the pre-defined perceptual field. The self-attention module(Multi-head attention module and feedforward network) is used in the latter two stages to provide additional contextual information through the broader perceptual field.
Multi-branch and multi-scale feature fusion module
To enhance the ability of the network to extract richer hierarchical features, combining the ideas from [20] and [21], we propose the multi-branch multi-scale feature fusion module (MSFB) shown in Fig. 2, whose internal structure consists of three components: multi-branch convolutional layer, null convolution and hierarchical segmentation block. The multi-branch structure is composed of convolutional layers of convolution kernels of different sizes. The feature graph is divided into s groups by adding segmentation blocks, and each group has w channels. Only the first set of filters can be connected directly to the next layer. The second set of feature maps is sent to a 3×3 void convolution to extract features, and then the output feature maps are divided into two subgroups on the channel dimension. One subgroup of feature maps is connected directly to the next level, while another subgroup is connected in series to the next set of input feature maps in the channel dimension. The series feature map consists of a set of 3×3 void convolution operations. This method is repeated until all of the input feature maps have been processed. Finally, all input group feature maps are cascaded and delivered to another layer of 1×1 convolution to reconstruct the features. The reconstructed feature maps produce a more detailed feature representation.

Multi-branch and multi-scale feature fusion module structure.
We propose GCAM in order to fully fuse the feature information of different levels of the decoder and obtain more accurate segmentation results (as in Fig. 1). The features at layer l in the decoder are denoted as D
l
(l ∈ {1, 2, 3, 4}), and they are unified to D1 size using a bilinear interpolation transform and 3×3 convolution, before being connected and denoted as feature F. Soft pooling with multilayer perception (MLP) is used to obtain the coefficients of each channel of F, and the channel coefficient attention vector is denoted as a ∈ [0, 1], in addition to using a 3×3 null convolution and a 1×1 convolution layer to generate spatial attention coefficients b ∈ [0, 1]. GCAM’s output is represented as:
We introduce a detail enhancement module to improve the network’s ability to learn irregular boundary features in the lesion region (e.g., Fig. 1). The DEM is made up of two modules: spatial attention and channel attention. The spatial attention module is used to capture the broader contextual information of local features, and the generated features are represented as Q
y
and K
x
by two convolutional layers, 1×3 and 3×1, to extract edge information in the vertical and horizontal directions, respectively. 1×1 convolution is also applied to the input features to obtain a new feature map V. The transpose of Q is matrix multiplied with K, which can promote each other in similar spatial points and suppress each other for different spatial points suppress each other; after that, the softmax layer is applied to obtain the similarity note map of each position with the others. Then matrix multiplication is performed with the features V to obtain the enhanced features, and finally the final output features F
s
of the spatial attention module are obtained by summing with the initial input features F. The channel attention module exploits the interdependence of channel mapping to enhance the contrast between class-dependent features. By matrix multiplying the input features F with their transpose, similar channels will promote each other and different channels will suppress each other. The channel dependency matrix is then Softmaxed so that the network can enhance the ability to recognize curve structure and background. The output features F
c
are then obtained by multiplying and then summing with the features F. Finally, the attentional feature map information generated in both dimensions is integrated by matrix multiplication and convolution layer operations to produce the output of the DEM module. The final feature map looks like this:
Lesion segmentation is a binary classification task, and in this work we use a combination of the binary cross-entropy (BCE) loss function and dice coefficient (Dice) loss in a way that the BCE loss and dice loss are defined as:
Datasets
We conducted extensive experiments on four public medical image segmentation datasets to validate the effectiveness of our method, including the skin lesion image dataset ISIC 2018 [22], the breast ultrasound image dataset BUSI [23], the gastrointestinal polyp image dataset Kvasir-SEG [24], and the thyroid nodule dataset TN3K [25]. Among them, the ISIC 2018 dataset is a challenge dataset for "Skin lesion analysis for melanoma detection" sponsored by the International Symposium on Biomedical Imaging (ISBI) 2018.The ISIC 2018 dataset consists of 2594 color RGB images, which we resampled to 224 × 224 pixels and randomly divided into training set (70%), validation set (10%) and test set (20%). The BUSI dataset consists of 780 images in PNG format (133 normal images, 437 benign images, 210 malignant images), which we randomly divided into training set, validation set and test set by 7:2:1. the Kvasir-seg dataset contains 1000 polyps images from the Kvasir dataset v2 and their corresponding ground The resolution of the images contained in the Kvasir-SEG ranged from 332×487 to 1920×1072 pixels, and we resampled the dataset to 224 × 224 pixels and randomly divided it into training set (70%), validation set (10%), and test set (20%). The TN3K dataset contains 3493 ultrasound images, which are also resampled to 224 × 224 pixels and randomly divided into a training set, a validation set and a test set according to 7:2:1.
Experimental settings and evaluation criteria
For the ISIC 2018 dataset, we compared with 10 methods, among which there are three general-purpose segmentation networks, U-Net [2], AttU-Net [26], and DeepLabv3+ [27], and seven networks dedicated to skin lesion segmentation, CE-Net [28], BCDU-Net [29], CPF- Net [30], CA-Net [31], BA-Transformer [32], MFS-Net [33], and FAT-Net [16]. All experiments were done under the same computational environment conditions, and none of them performed data enhancement on the dataset. Table 1 depicts the statistical experimental results of skin damage segmentation on the ISIC 2018 dataset for different methods, it is obvious that our method on the four evaluation metrics of Dice coefficient (Dice), Accuracy (ACC), Sensitivity (SE) and Specificity (SP) all showed better results with 93.17%, 96.60%, 91.78% and 97.40%, respectively. Figure 3 compares the segmentation results of different networks on the ISIC 2018 dataset, and our networks all show better processing capabilities.
Performance of different networks for skin lesion segmentation on the ISIC 2018 dataset, with the best results shown in bold
Performance of different networks for skin lesion segmentation on the ISIC 2018 dataset, with the best results shown in bold
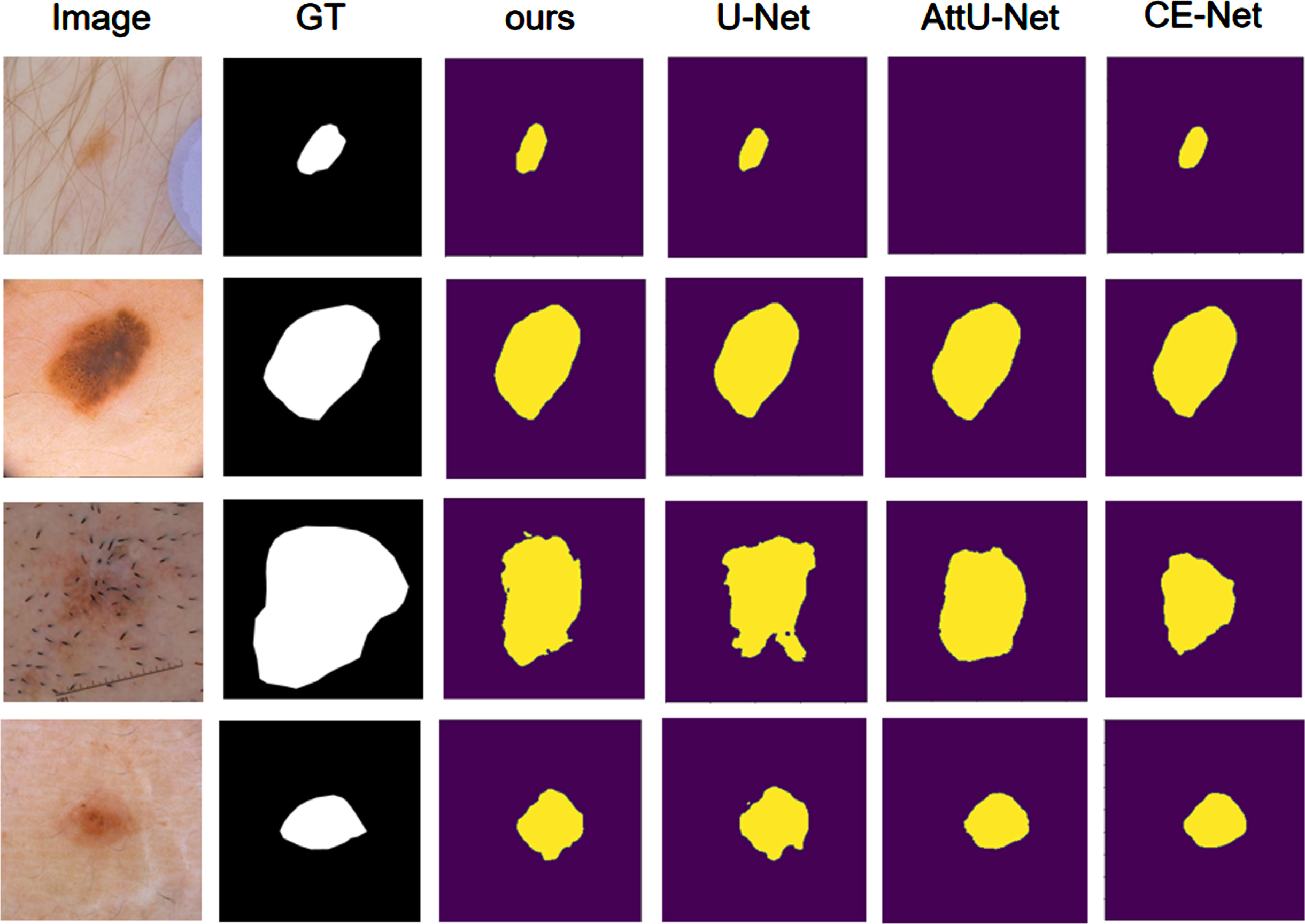
Comparison visualization on the ISIC2018 dataset.
We compared our network to seven other approaches on the BUSI dataset: U-Net [2], AttU-Net [26], DeepLabv3+ [27], CE-Net [28], BCDU-Net [29], DA-Net [34], and MCF-Net [35]. Table 2 displays the experimental outcomes. Our network MTC-Net outperforms the state-of-the-art breast nodule segmentation network, and our network performs better in all four evaluation metrics. MTC-Net outperformed DeepLabv3+ by 7.8%, 1.4%, and 0.35% in Dice coefficient (Dice), Accuracy (ACC), and Specificity (SP), respectively. Our MTC-Net performs better in terms of segmentation. Figure 4 compares the segmentation results of various networks on the BUSI dataset, and all of our networks outperform.
Breast nodule segmentation performance of different networks on the BUSI dataset, the best results are shown in bold
Breast nodule segmentation performance of different networks on the BUSI dataset, the best results are shown in bold
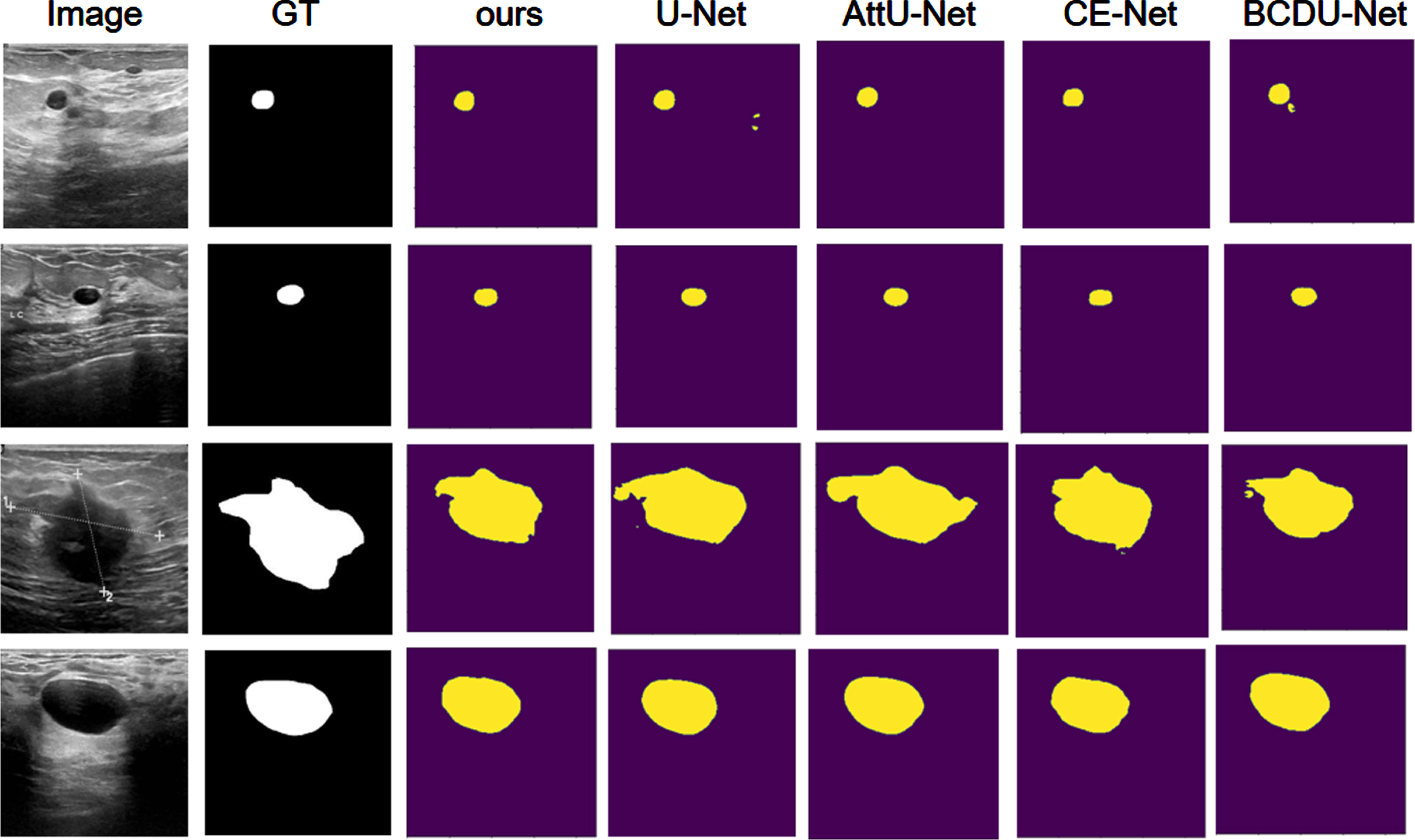
Comparison visualization on BUSI datasets.
On the Kvasir-SEG dataset, we compared with six methods, namely U-Net [2], AttU-Net [26], CE-Net [28], BCDU-Net [29], DA-Net [34], and MCF-Net [35]. The detailed comparison results are shown in Table 3. Our network achieves superior results in all four evaluation metrics, and it can be seen that the best result among the state-of-the-art segmentation networks is DA-Net [34], while our network compares with it in terms of Dice coefficient (Dice), Accuracy (ACC), Sensitivity (SE) and Specificity (SP) by 13.72%, 1.95%, 7.16% and 0.87%, respectively. The segmentation performance of the above networks with our MTC-Net network on the Kvasir-SEG dataset is shown in Fig. 5.
Polyp segmentation performance of different networks on the Kvasir-SEG dataset, with the best results shown in bold
Polyp segmentation performance of different networks on the Kvasir-SEG dataset, with the best results shown in bold
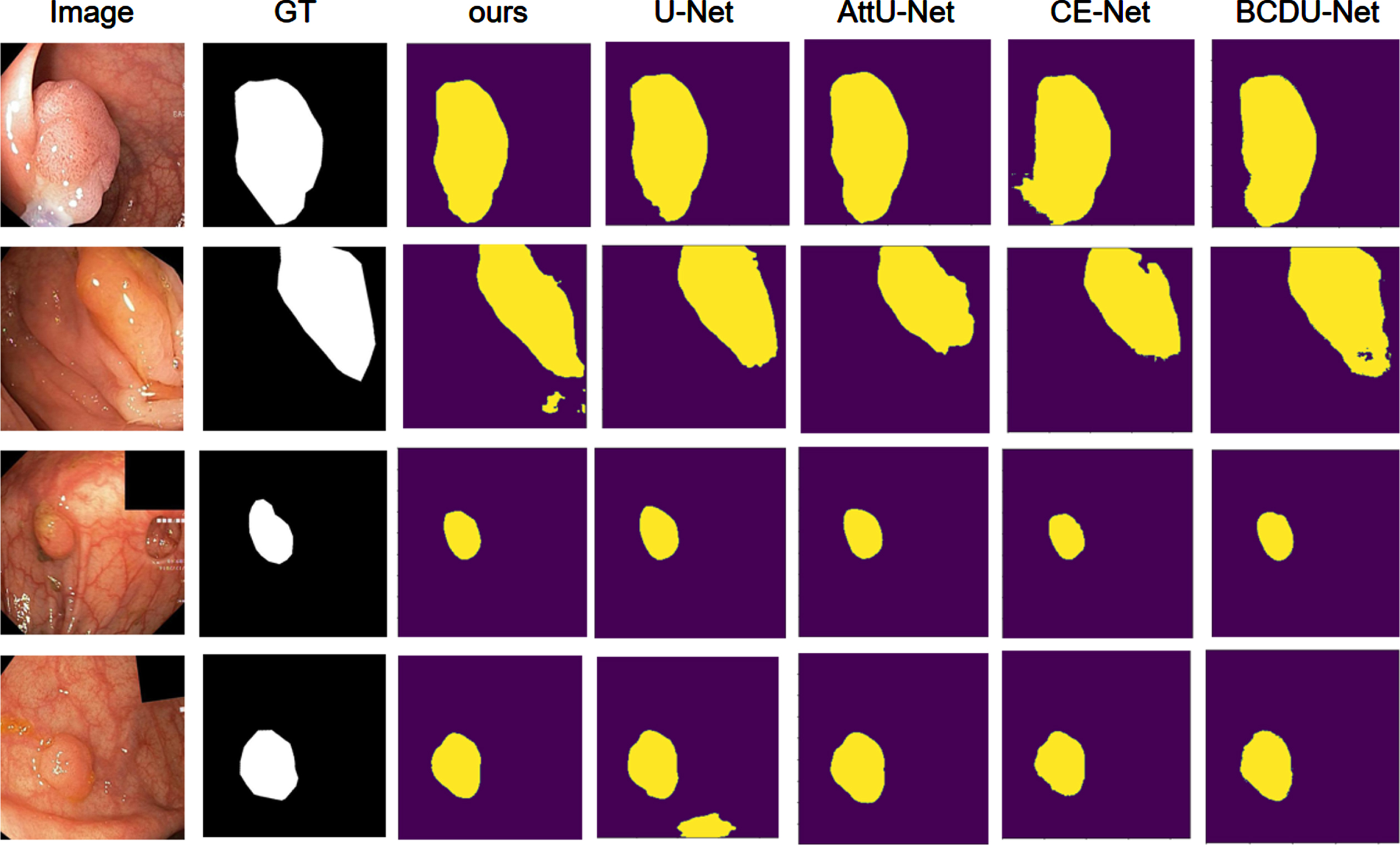
Comparison visualization on the Kvasir-SEG dataset.
On the TN3K dataset, we compared with seven methods, namely U-Net [2], AttU-Net [26], BCDU-Net [29], SGUNet [36], TRFE [37], TRFE+ [38], and CPF- Net [30]. The detailed comparison results are shown in Table 4. Our network has improved 9.92% and 4.48% in Dice coefficient (Dice) and Specificity (SP), respectively, compared to U-Net. The segmentation performance of our MTC-Net network on the TN3K dataset is shown in Fig. 6.
The performance of different networks for thyroid nodule segmentation on the TN3K dataset, with the best results shown in bold
The performance of different networks for thyroid nodule segmentation on the TN3K dataset, with the best results shown in bold
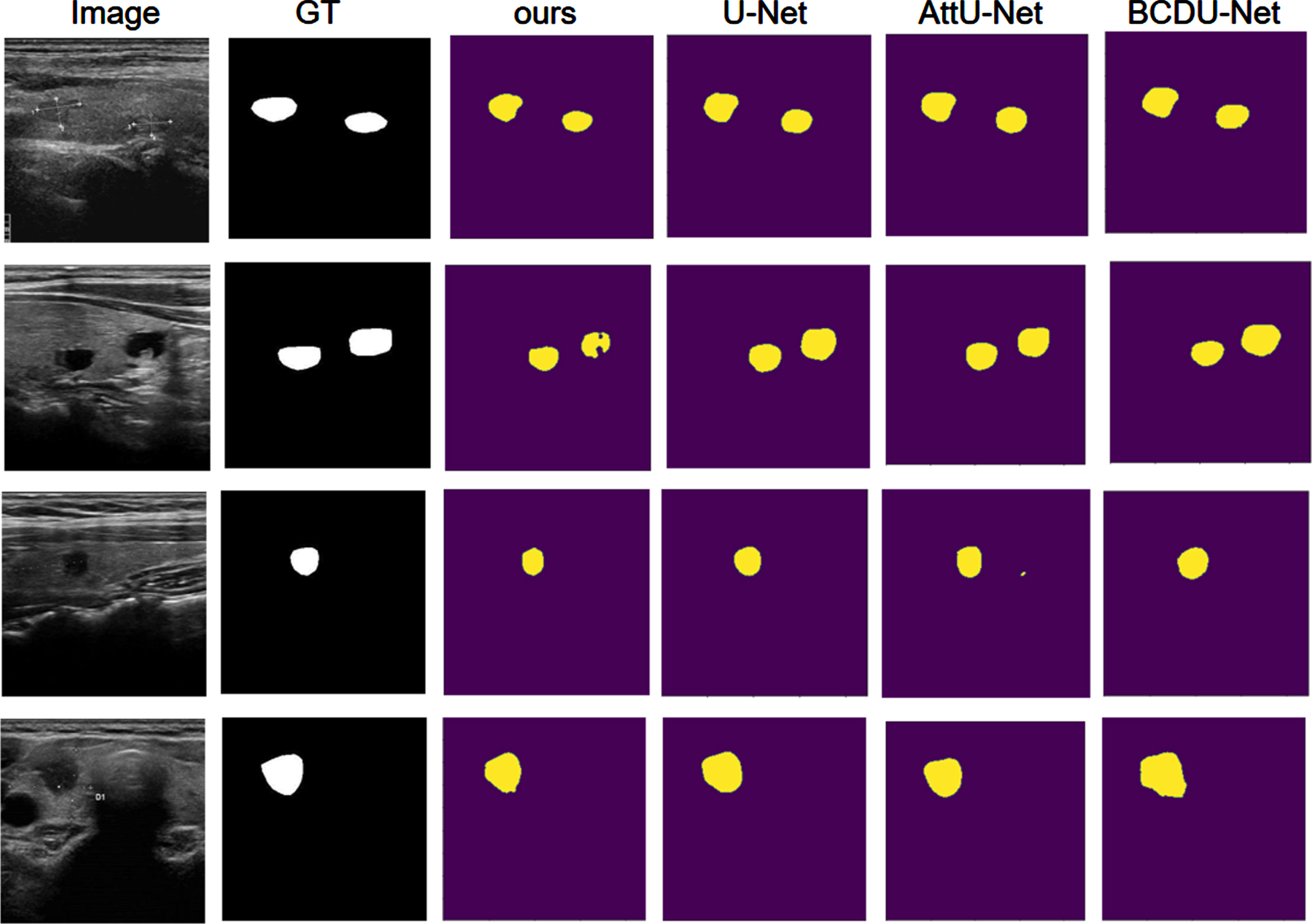
Comparative visualization on TN3K datasets.
To demonstrate the effectiveness of our proposed module, we conducted ablation experiments on the ISIC2018 dataset. We compare the following models and present the results in Table 5:
Ablation experiments for different parts of the proposed model on the ISIC2018 dataset
Ablation experiments for different parts of the proposed model on the ISIC2018 dataset
The graphs of experimental results before and after adding the detail enhancement module are shown in Fig. 7, which proves the contribution of the module to the fuzzy boundary of network segmentation.
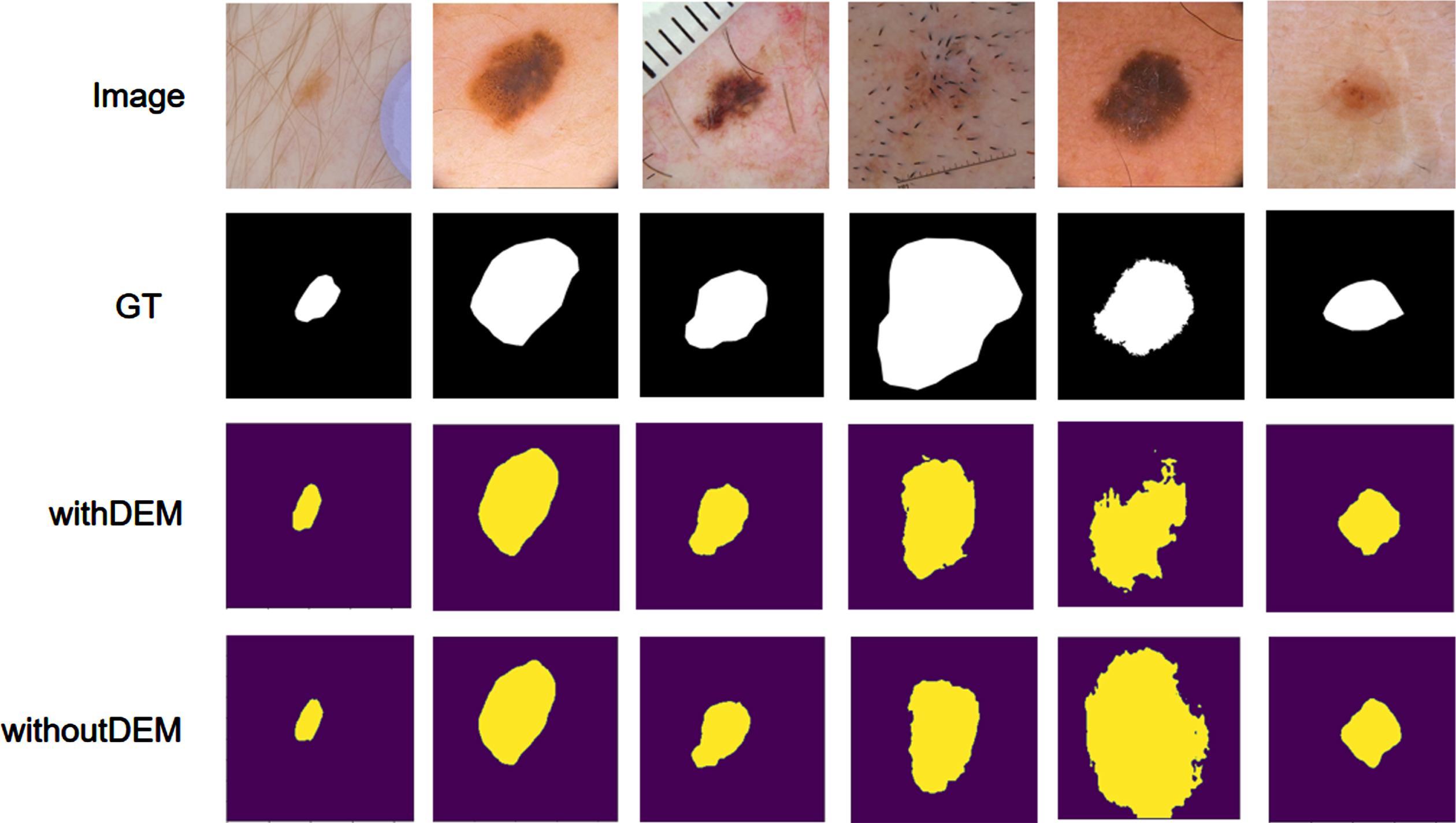
Effect comparison of DEM on ISIC2018 dataset.
In this paper, we propose a multiscale feature fusion network (MTC-Net) for solving medical image segmentation problems. Unlike traditional convolutional neural networks, we use a fusion encoder to extract multiscale remotely dependent features from the input image, preserving rich global contextual information. In addition, we use a multi-branch multi-scale feature fusion module (MSFB) to enhance the feature extraction capability of the network. And, the Global Cooperative Aggregation Module (GCAM), adaptively fuses features from different scales to fully learn contextual information. Further detailed features are extracted using the Detail Enhancement Module (DEM). To validate the effectiveness of our network, we conducted extensive experiments on four public medical image segmentation datasets (ISIC2018, BUSI, Kvasir-SEG, and TN3K) to verify the superiority of the performance of our proposed MTC-Net compared with state-of-the-art segmentation methods.
Footnotes
Acknowledgment
This work was supported by the National Natural Science Foundation of China (Grant No. 61976126).