
Abstract
Effective fire detection can identify the source of the fire faster, and reduce the risk of loss of life and property. Existing methods still fail to efficiently improve models’ multi-scale feature learning capabilities, which are significant to the detection of fire targets of various sizes. Besides, these methods often overlook the accumulation of interference information in the network. Therefore, this paper presents an efficient fire detection network with boosted multi-scale feature learning and interference immunity capabilities (MFII-FD). Specifically, a novel EPC-CSP module is designed to enhance backbone’s multi-scale feature learning capability with low computational consumption. Beyond that, a pre-fusion module is leveraged to avoid the accumulation of interference information. Further, we also construct a new fire dataset to make the trained model adaptive to more fire situations. Experimental results demonstrate that, our method obtains a better detection accuracy than all comparative models while achieving a high detection speed for video in fire detection task.
Introduction
Efficient fire detection is crucial for reducing the loss of human life and property caused by fire. In early research on fire detection, researchers [1–5] focus on employing traditional manual feature extraction in training neural networks for fire detection. Celik et al. [1] proposed a generic color model based on YCbCr color space to separate and detect fire regions, which is more effective than models based on RGB color space in fire detection. Phillips et al. [4] proposed a system using color and motion information to locate fire, which first detects fire pixels by a Gaussian-smoothed color histogram [6] and a temporal variation of pixels. Despite the positive performance of the above methods [1–5], they are susceptible to the subjective factors of researchers. So that these methods cannot adapt themselves to fire detection tasks in complex situations.
With the rapid development of the deep learning technique, deep neural networks [7–9] are demonstrated to achieve better performance than traditional machine learning in feature extraction. Ren et al. [10] introduced Faster R-CNN, a precise and generic two-stage approach for object detection. Many researches [11–15] proposed fire detection algorithms based on this framework [10]. Barmpoutis et al. [11] employed Faster R-CNN to generate candidate fire regions, which are then modelled by linear dynamical systems and classified by a vector representation approach. Zhang et al. [14] presented the MS-FRCNN model based on Faster R-CNN for a better detection performance of small target forest fires. These fire detection researches [11–15] based on two-stage object detection approaches like Faster R-CNN, despite their high accuracy, have the drawback of slow detection speed. Thus, they fail to satisfy the real-time demand of fire detection task.
In recent years, the You Only Look Once (YOLO) series [16–23], a kind of single-stage object detection framework, is proposed and sets it apart from the two-stage object detection frameworks like Faster R-CNN by offering real-time detection capability without sacrificing too much accuracy. The popularity of the YOLO series has prompted many researchers looking into utilizing YOLO frameworks for fire detection task.
Many previous researchers [24–33] often rely on integrating attention modules to the YOLO framework for better attention on fire features. Chen et al. [25] added CA attention [34] and CoT attention [35] modules to the backbone of YOLOv5s [17] for better focus on forest fire. Lin et al. [26] adopted the Transformer module [36] for global feature extraction of forest fires, CA attention [34] for better fusion of fire features. Wu et al. [28] employed SE attention [37] module into YOLOv4-tiny [16]’s neck to improve the precision of ship fire detection. However, these methods [24–33] based on YOLO framework overlook the importance of multi-scale feature learning capability of model to fire detection tasks.
Besides, some works [26, 38–40] have chosen to integrate the ASFF [41] module into YOLO framework as a post-fusion module for reducing interference information. They use this method to avoid interference information being sent to the head of the detection network. But, they all overlook the potential accumulation of interference information in the period of the fusion of features.
In this paper, to tackle the aforementioned issues, we present an efficient
In brief, this paper mainly makes three contributions: The novel EPC-CSP module is designed and replacing the original CSP module in the backbone, which improves the multi-scale feature learning capability of the backbone while remaining low computational consumption. An ASFF module is leveraged as a pre-fusion module to avoid the accumulation of the interference information. A new fire dataset labelled with three categories is built to make our model adapted to more fire scenarios while avoiding human-made noise in labeling.
The remainder of this this paper is organized as follows. Section 2 gives the details of our constructed fire dataset as well as methods used for data augmentation. Section 3 describes the proposed MFII-FD network for fire detection tasks. Section 4 reports the experimental results and ablation study. Finally, we provide a conclusion of this paper in Section 5.
Dataset and data augmentation
Fire dataset
In recent years, studies [43–45] have trained detectors by labelling their fire datasets with only one category ‘fire’ (as illustrated in Fig. 1(a)(d)). However, in many actual fire incidents, the surveillance camera may only capture smoke without any visible flames (as displayed in Fig. 1(b)). Consequently, the aforementioned fire detector may erroneously assume that everything is normal and fail to alert the fire department, missing the optimal time to rescue individuals in the fire.
In studies [46–48], their fire datasets was labelled with two categories: ‘fire’ and ‘smoke’. Although these datasets can cover more fire scenarios, it can be difficult to distinguish the boundaries between the flame and smoke in certain fire scenarios (as depicted in Fig. 1(c)). This will hinder the determination of bounding boxes and create hand-made noise in labeling, further impacting the converge of fire detection networks.
In summary, the fire datasets used in existing methods contain two problems: single and inadequate detection category (e.g. Fire) and potential hand-made noise. Thus, these methods can not applicable to various fire situations. To address these issues, this paper builds the fire dataset labelled with three categories: ‘fire with only flame’ (Fire), ‘fire with only smoke’ (Smoke) and ‘fire with both flame and smoke’ (FireSmoke). The labelled samples in the fire dataset are visible in Fig. 1(d)(e)(f).
As shown in Fig. 1(a)(b)(c), the fire dataset constructed in this paper contains about 5,500 high-definition images of various types of fire scenarios. The dataset’s main sources comprise publicly available datasets like MIVIA [49, 50], NIST [51], BoWFire [52] and FireDataSet [53], along with images crawled from Google [54], Baidu [55] and Bing [56].

Illustration of the fire dataset.
After labeling the dataset, we divide it into training set, validation set and testing set in the ratio of 8:1:1, as shown in Fig. 2(a). In the dataset, the distribution of each category is balanced, as illustrated in Fig. 2(b).
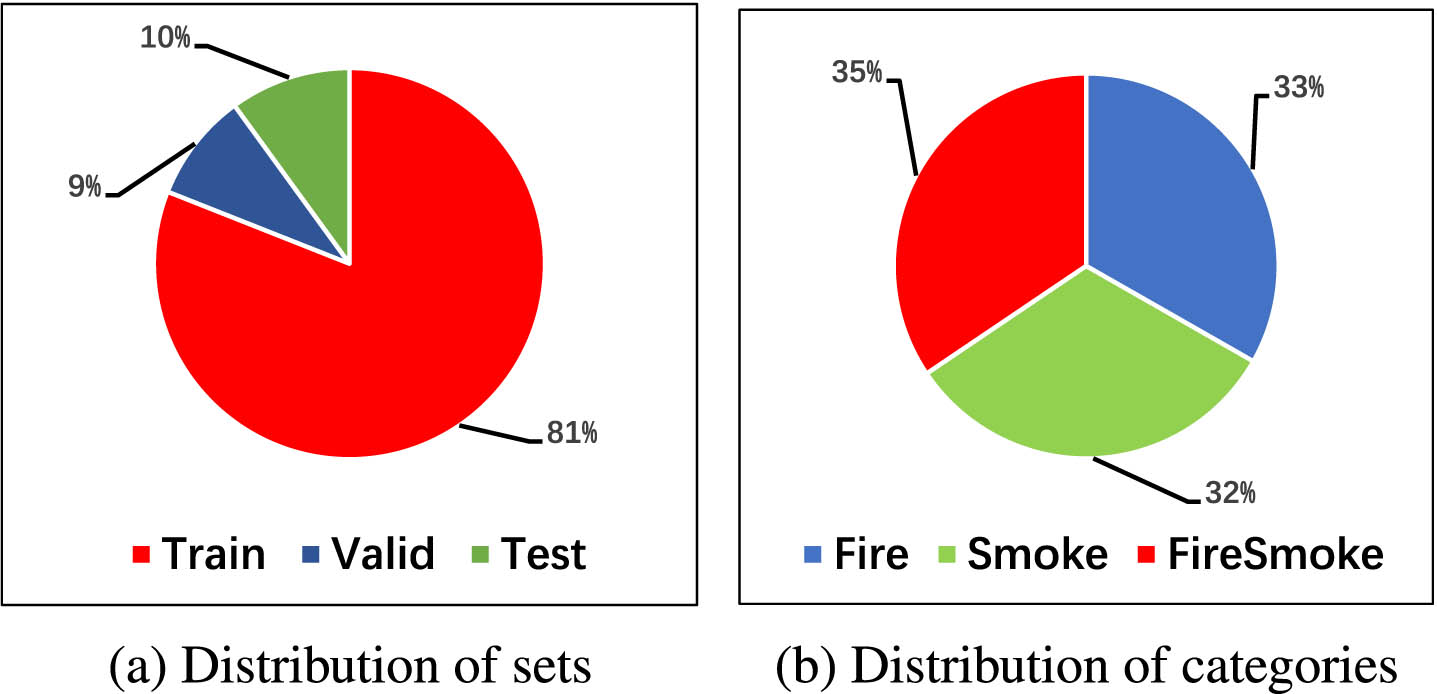
Illustration of the fire dataset.
As indicated in Fig. 3, compared with other existing fire datasets, our three-categories fire dataset can provide unambiguous bounding boxes with corresponding categories in a wide range of fire scenarios. Consequently, our fire detection network trained on this dataset will be adaptable to many fire scenarios and converge well.
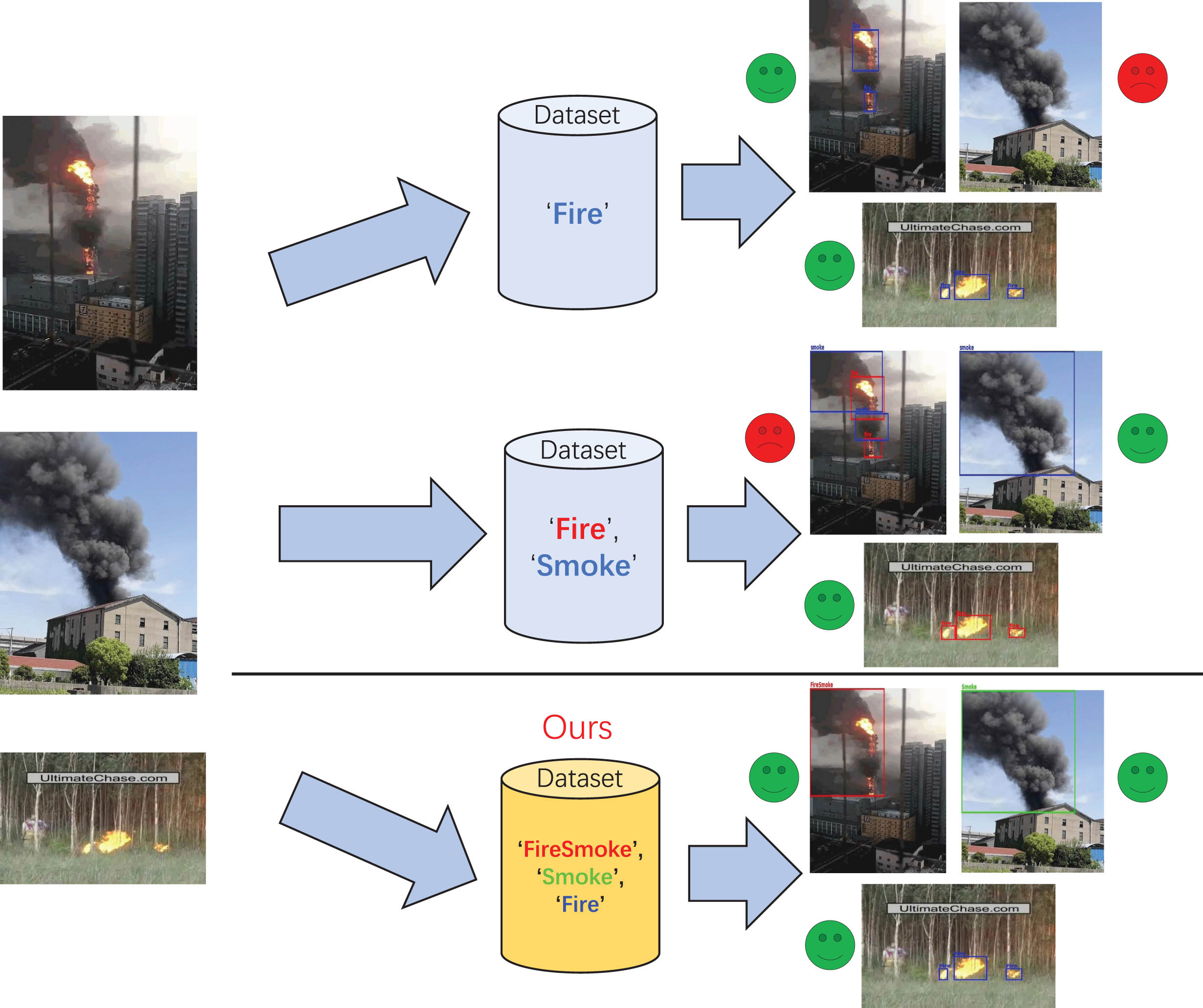
Comparison of different fire datasets.
In this paper, Mosaic [16] and Mixup [57] techniques are utilized within the process of data augmentation. As demonstrated in Fig. 4(a), Mosaic data augmentation involves splicing four images onto one image as training data after random cropping. This technique can improve the diversity of the training data, in other words, increase the training batch size, which can save VRAM. In Fig. 4(b), Mixup data augmentation randomly mixes and superimposes training images with other images, thereby extending the training dataset. In this paper, besides the typical random rotation, cropping, and hue data augmentation, Mosaic and Mixup data augmentation techniques are included with a probability of 50%. The training data with augmentation is displayed in Fig. 4(c).

Illustration of data augmentation.
The proposed fire detection network, MFII-FD
As presented in Fig. 5, this paper introduces MFII-FD, a fire detection network with enhanced multi-scale feature learning and interference immunity capabilities. This network is based on the YOLOv5s network and has two enhancements: (i) We first design the novel EPC-CSP module with Elastic [58], Partial Convolution (PConv) [59] and Cascade Fusion Network (CFNet) [60]. Then, we replace all the CSP modules with our proposed EPC-CSP modules in the backbone. (ii) We adopt the ASFF module as a pre-fusion module and place it between the backbone and the neck of the detection network.

The architecture diagram of MFII-FD.
In the following Subsection (3.2,3.3,3.4), we will describe the design process of the EPC-CSP module. In Subsection 3.5, the pre-fusion module will be described.
Each CSP module of YOLOv5s only learns a single scale of feature information, which hinders the network’s ability to handle fire detection tasks that contain targets of varying sizes. Wang et al. [58] introduced the Elastic module, which adds extra branches into each residual block of the network, enabling the network to efficiently learn multiple different scales of feature information from the images. In the Elastic branch, the input will first get 2× downsampling, and followed by operations like convolution, normalization, activation, and so on. Finally, the output of the previous step will get 2× upsampling and summed with the remaining branches to obtain the final output. The network with Elastic module can flexibly adjust weights at original branches and Elastic branches in response to different instances. For example, the original residual branches will be favored for large targets, while the Elastic branches will be favored for small targets.
The process of Elastic module can be expressed as Equation (1)colon
e and c are the count of Elastic branches and original residual branches respectively. U ri (x) and D ri (x) represent the upsampling and downsampling respectively. τ i (x) denotes any combination of functions like convolution, normalization, activation and so on. σ is a non-linear activation function.
As shown in Fig. 6, in this paper, we first add an extra Elastic branch to the BottleNeck in the backbone’s CSP module, enabling the network to learn feature information with different scales within each CSP module. This helps improve the detection of fire targets of different sizes.
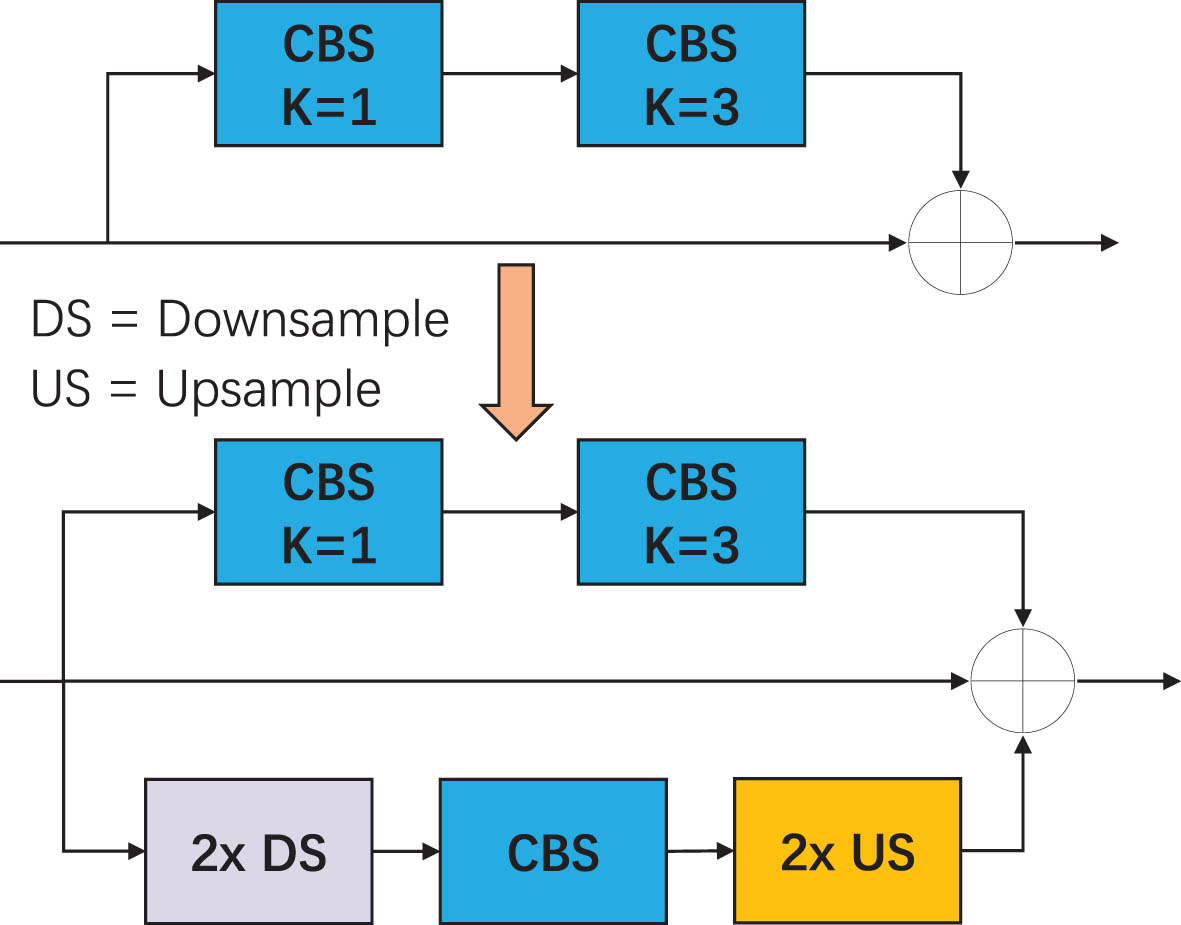
Schematic of BottleNeck adding elastic.
Since this paper introduces an Elastic branch to BottleNeck of CSP module of YOLOv5s, the floating point operations (FLOPs) of the network will significantly increase if we use regular convolution in the Elastic branch, leading to a considerable decrease in network throughput. Therefore, we need to seek lightweight and efficient convolution operator.
In current research, Depthwise convolution [61] (DWConv) is the most commonly used lightweight convolution operator. However, despite achieving low FLOPs compared to regular convolution, numerous experiments [62–64] have demonstrated that DWConv often suffers from high memory accesses (MAC). Eventually, DWConv provides a limited improvement in computational efficiency compared with regular convolution.
Recently, Chen et al. [59] proposed a new convolution operator: PConv. Its purpose is to address the inefficiency issue of DWConv. Chen et al. [59] stated that deep neural networks often contain redundant and repetitive feature maps within their channels. Thus, they proposed PConv to perform the convolution only on a part of the input channels (e.g.
Meanwhile, Chen et al. [59] also proposed a FasterNet module based on PConv. Specifically, as is shown in Fig. 7, each FasterNet module has a PConv layer followed by two 1 × 1 convolutions. Two 1 × 1 convolutions will expand and recover the number of channels to fully and efficiently leverage the information from all channels.

Architecture of PConv and FasterNet.
As depicted in Fig. 8, following with modification of network in the last Subsection, we further replace the convolution operators with FasterNet module in the Elastic branch. This substitution allows the network to learn feature information at multiple scales while maintaining low computational expense.

Schematic of BottleNeck adding FasterNet module.
In YOLOv5s, multi-scale feature fusion is mainly done by neck’s PANet [59]. However, in a recent study, Zhang et al. [60] argued that it may not be sufficient to fuse the multi-scale features only depending on the neck’s fusion module. Thus, they presented CFNet, an architecture designed to enhance the multi-scale feature learning and fusion capabilities for the backbone network.
The main process of CFNet is as follows. For the input I ∈ RC×H×W, 2× downsampling and operators (e.g. convolution, normalization, activation et al.) are performed twice to obtain feature
As shown in Fig. 9, following with the last two Subsections’ modification, we adopt CFNet’s architecture in the Elastic branch, forming the novel EPC-BottleNeck as well as EPC-CSP module. This enables each stage of the backbone network to learn and fuse up to three different scales of feature information, resulting in improved recognition of fire targets of varying sizes.

Architecture of EPC-BottleNeck.
Liu et al. [41] proposed the ASFF module. In this module, three different scale output features of YOLO can be adaptively fused with each other. This helps each feature obtain meaningful information and reduce interference information.
Let’s denote Level-1, Level-2 and Level-3 are the feature map outputs of the YOLOv5s at three different scales, respectively. As the number of channels and spatial sizes vary among diferent Levels, a 1 × 1 convolution is applied to allign the number of channels, followed by a 2/4× up/downsampling to align the spatial sizes. Let
In recent years, fire detection studies [26,38,39,40, 26,38,39,40] have chosen to place the ASFF module between the neck and the head of YOLO network for reducing the interference information. However, they overlook a potential issue, that is interference information may be extracted by the backbone and accumulated in the neck. The accumulated interference information may become difficult to be reduced. Thus, we suggest that the ASFF module be placed between the backbone and the neck of the detection network to avoid the accumulation of interference information in the neck’s fusion network. This helps maximize the fusion capability of neck and improve the detection of fire targets. The experimental results in Table 1 prove our suggestion. Therefore, as shown in Fig. 10, this paper places the ASFF module between the backbone and the neck of the detection network.
Comparison of ASFF module’s placement
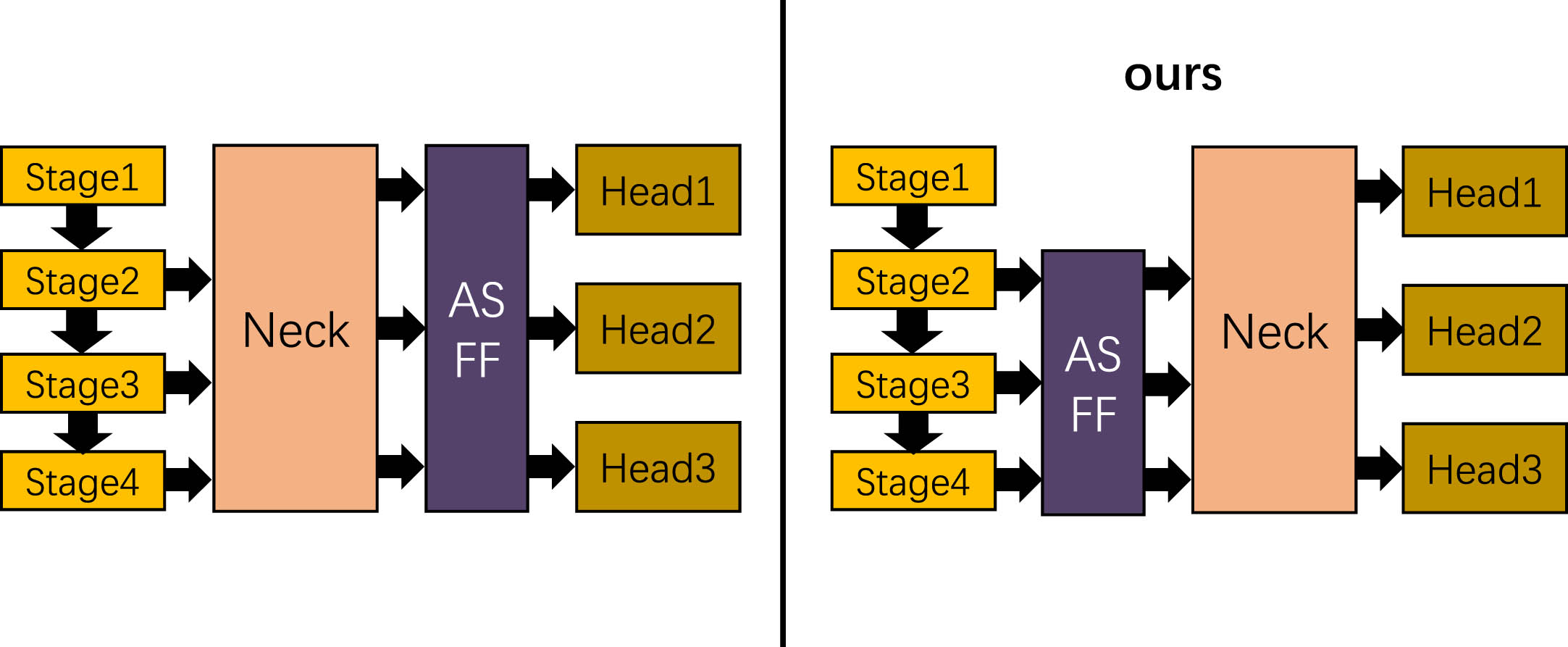
Schematic of adding ASFF to the detection network.
Implementation details
In this paper, the hardware used in all experiments is Intel i7 11700 CPU, 32 GB of RAM, and NVIDIA GeForce RTX3090 GPU with 24 GB VRAM. Environment is Ubuntu 22.04 64bit, Pytorch 1.13, Python 3.9.13 and CUDA 11.7.
The input size of this paper is 640*640, the batch size is 24, the optimiser is Stochastic Gradient Descent (SGD), the initial learning rate is 0.002, the momentum is 0.937, the weight decay is 0.0005, cosine annealing is used for the learning rate decay, and the epoch for training is 300. Note that all experiment models were trained and tested in the fire dataset built in this paper, using the same configuration.
Evaluation metrics
In this paper, the effectiveness of the fire detection network is evaluated by the mean average precision (mAP), and the detection speed of the network is assessed by the frames per second (FPS).
The mAP value is calculated as shown in Equation (4), which is obtained by averaging the average precision (AP) values under all categories. The FPS, which evaluates the network’s detection speed, is the reciprocal of the inference latency (Latency) of the fire detection network, as shown in Equation (5).
Note that in this paper, the metric of the fire detection network’s effectiveness uses the mAP value when the intersection over union (IoU) threshold is 0.5: mAP@50. Here, the IoU, which measures the ratio of overlap between the predicted boxes (Pred) and the ground true boxes (GT), as shown in Equation (6).
Ablation study on modifications of EPC-CSP
Before investigating the effectiveness of modules made in this paper based on YOLOv5s, we first verify the validity concerning the proposed EPC-CSP module. We examined each modification in the CSP module independently. When the Elastic is integrated in the CSP module solely, the model’s mAP@50 increases by 0.74% compared to model with original CSP module. However, due to the inefficient regular convolution, the model’s FPS have a notably decrease in FPS by 28. When the PConv is used in the CSP module with Elastic, the model achieves mainly the same mAP@50 as the model mentioned above, but with a higher FPS. Surprisingly, when the Elastic is added in the CSP module only with the CFNet, there is a significant decrease in both mAP@50 and FPS of the model compared with the original model. When the Elastic, PConv and CFNet are integrated in the CSP module, forming the proposed EPC-CSP module, the model achieves the best mAP@50 among all modifications in the CSP module with a slightly decrease on FPS compared with the original model. This indicates that the EPC-CSP module can boost network’s multi-scale feature learning capability with low computational cost. The experimental results on EPC-CSP module are displayed in Table 2.
Results of ablation experiments on EPC-CSP
Results of ablation experiments on EPC-CSP
In this ablation study, to further investigate the effectiveness of the modules made in this paper based on YOLOv5s, we will perform experiments on each of the proposed modules and their combinations.
As shown in Table 3, when the EPC-CSP and ASFF module are respectively integrated into the detection model, the model’s mAP@50 increases by 1.42% and 1.64%. Then, when the above-mentioned modules are added to the model together, the model’s mAP@50 increases by 3.41%, achieving an additional improvement of about 0.40% compared to total improvement brought by these modules. This indicates that boosted multi-scale feature learning and interference immunity capabilities achieved by EPC-CSP module and ASFF module can improve the detection performance of fire detection tasks respectively. And the combination of these modules can bring additional improvement of detection performance.
Results of ablation experiments
Results of ablation experiments
In this subsection, we evaluate the performance of the proposed MFII-FD fire detection network against several commonly used network such as YOLOv5s (baseline), YOLOv5m, YOLOv6s, YOLOv7tiny, YOLOXs and FasterRCNN-ResNet50.
As shown in Table 4, the experimental results indicate that the proposed MFII-FD fire detection network outperforms all compared models in mAP@50. In detail, the proposed network shows a notably increase of 3.41% /3.29% in mAP@50 compared to YOLOv5s baseline and YOLOv7tiny network, respectively, while remaining a relatively high FPS. When compared to YOLOXs, our proposed model achieves an improvement of 0.75% in mAP@50, while offering comparable FPS. Moreover, MFII-FD even gets an improvement of 0.89% /1.27% /1.95% in mAP@50 when compared to YOLOv5m, YOLOv6s and FasterRCNN-ResNet50, respectively, while achieving operating at a faster speed of 31/26/75 FPS. These three models are more than double the proposed network’s size. These results clearly show that our proposed MFII-FD fire detection network can have high detection performance while remaining low computational cost.
Comparison with commonly used network
Comparison with commonly used network
Furthermore, we believe that a simple numerical comparison does not prove the superiority of our network. Several visual comparative analyses of the detection results of our proposed MFII-FD fire detection network and the baseline YOLOv5s network are as follows.
As shown in Fig. 11, the baseline network YOLOv5s incorrectly detects the white willow flakes as smoke and detects the firefighter’s yellow shoes and black trousers as a mixture of fire and smoke. That’s because these interference information are extracted by the backbone wrongly and accumulated in the neck’s fusion network, leading to incorrect detection. In contrast, the ASFF module integrated in our proposed MFII-FD detection network can reduce interference information of the backbone’s output features by adaptively fusing them. In this way, the detection network can avoid the accumulation of interference information in neck and provide correct as well as precise detection. Consequently, the proposed network can accurately locate the flame with the complex background.

Visual comparison of anti-interference capability.
As illustrated in Fig. 12, the baseline network YOLOv5s cannot fully extract the global information of the smoke target. Only half of the smoke target is detected. In comparison, our proposed MFII-FD network, which is integrated with EPC-CSP module, has enhanced multi-scale feature learning capability. Therefore, the proposed network can fully detect the whole smoke target.

Visual comparison of global information localization capability.
In Fig. 13, the baseline network YOLOv5s misses the small smoke target on the right side of the image. That’s because the multi-scale feature learning capability of the baseline network is not enough to detect fire targets of various sizes. On the contrary, our proposed MFII-FD network, owning the boosted multi-scale feature capability, can detect fire targets of various sizes effectively. Thus, the proposed network can not only detect the normal size smoke target, but also detect the small smoke target.

Visual comparison of missed detection.
In this paper, we proposed an efficient fire detection network with boosted multi-scale feature learning and interference immunity capabilities based on YOLOv5s: MFII-FD. In detail, we first proposed the novel EPC-CSP module in the backbone to boost network’s multi-scale feature learning capability with low computational cost. Then, an ASFF module was adopted as a pre-fusion module to reduce and avoid the accumulation of interference information. Notably, we also constructed a new fire dataset with three categories to cover more fire scenarios with less human-made noise in labeling. Extensive experiments demonstrated the effectiveness as well as efficiency of our proposed fire detection network.
Despite effective improvements, we acknowledge that the MFII-FD fire detection network still has room for improvement in terms of FLOPs and FPS. This requires further research and fine-tuning. We will focus on further reducing model’s FLOPs and FPS while remaining high detection accuracy to improve model’s performance. Furthermore, we will expand our fire dataset to include fire objects in more conditions. These improvements improve the applicability and utility of our proposed model.
We hope that our proposed MFII-FD can be integrated in a practical surveillance system to provide timely fire detection and warnings. In this way, we can reduce the loss of human life and their property.
Footnotes
Acknowledgment
This work was supported by the Shenzhen Science and Technology Innovation Commission (Grant No. KCXFZ20211020163402004).