
Abstract
Model lightweight is a challenging topic in the field of computer vision, aimed at reducing the computational demands and size of models, with widespread research needs in both industrial and academic sectors. However, in fire detection tasks, fluctuating environmental factors often lead to decreased detection accuracy. Considering the challenges of feature extraction, low detection accuracy, and prolonged inference times in current fire detection networks, this paper proposes a YOLOv5s-RBC fire detection algorithm. Initially, a lightweight convolutional neural network module, RepVGG, is introduced during the feature extraction stage, which enhances deep feature extraction of input images while reducing the model's inference time. Subsequently, a weighted bidirectional feature pyramid network, BiFPN, serves as the feature fusion network for the YOLOv5 s model, merging features extracted from various dimensions in a layered approach, thus optimizing the feature fusion structure of the YOLOv5 s model. Lastly, the backbone network incorporates a spatial and channel attention mechanism, CBAM, enhancing focus on target area features and reducing the computational load of the network model. Experimental results indicate that, the YOLOv5s-RBC network model proposed in this paper detects fire images faster and with higher accuracy, meets the requirements for real-time detection, and to some extent reduces the computational load of the network model, thereby increasing inference speed and detection precision.
Introduction
Fires can easily generate toxic smoke, hazardous gases, or chemical leaks, among other disasters, which result in significant financial losses and human casualties (Rehman et al., 2023). According to statistics from the Emergency Management Department Fire Rescue Bureau of the People's Republic of China, in 2021, there were a total of 748,000 fire incidents nationwide, resulting in 1,987 deaths, 2,225 injuries, and direct property damage amounting to 6.75 billion yuan. Fire is one of the major hazards to human life safety. Fire warnings have always been a critical issue in the field of fire safety (Luo et al., 2019). Fires are characterized by their suddenness, destructiveness, and uncontrollability, often resulting in substantial economic losses and severe environmental damage (Gaur et al., 2020), with the affected areas typically unable to regenerate and recover. Common fire detection and identification methods are mainly divided into two categories: one is based on the principle of sensor-based fire detectors, and the other is based on video image processing technology for fire recognition (Zhang et al., 2015). Fire detection technologies based on sensor principles include contact-type fire detectors such as temperature and smoke detectors. This detection method is not suitable for outdoor environments and has limitations such as restricted detection range and delayed alarm times (Wang et al., 2022). Fire detection technology based on video images is highly regarded by researchers due to its fast response speed, wide detection range, and high real-time performance, and has been widely applied (Liu et al., 2014).
The fire detection problem has been widely concerned and researched by scholars from various countries, and many previous researches are listed below in Table 1. This paper summarizes many classical fire detection methods and innovative application scenarios, including convolutional networks and many machine learning algorithms in combination and innovation. However, there are some shortcomings in the research of these scholars, most of the early scholars research algorithms are based on the analysis of the physical characteristics of the flame, through algorithmic improvement and refinement of the prediction function to improve the model performance network structure is relatively complex, the computational cost of training models is high, and it is difficult to meet the real-time requirements. Although with the rapid development of machine vision, combining deep learning (DL) and image processing fire detection technology is also more and more mature, deep learning-based fire detection technology can overcome the limitations of traditional fire detection methods. However, they are not considered in the direction of model lightweighting and reducing the computational cost for the time being. To solve the above problems, this paper proposes a lightweight target detection model.Based on the YOLOv5 algorithm (Glenn et al., 2020), a lightweight convolutional neural network module, RepVGG (Ding et al., 2021), was introduced during the feature extraction phase. 2) A weighted bi-directional feature pyramid network (BiFPN) (Tan et al., 2020) was used as the feature fusion network for the YOLOv5 s model, optimizing the original network model's feature fusion structure. 3) A lightweight convolutional block attention module (CBAM) (Woo et al., 2018) was inserted into the backbone network.
Research on Fire Detection by Previous Scholars.

Research on Fire Detection by Previous Scholars.
The YOLOv5s-RBC network model was trained, tested, and analyzed using a fire dataset, leading to enhanced detection speeds and accuracy of the improved YOLOv5 s model, satisfying real-time detection needs, and reducing the computational demand of the network, thus improving inference speed and detection accuracy. Superior to current mainstream object detection algorithms, it offers a novel solution for addressing public safety issues and accelerates the development of intelligent fire detection.
Methods
In 2021, Ding et al. introduced the lightweight convolutional neural network model, RepVGG, which utilizes structural re-parameterization to separate the training and inference stages of the model (Geng et al., 2022). Initially, the RepVGG network is based on the original VGG model, incorporating structures from the Residual Network (ResNet). Additionally, multiple residual identity branches are added to the branch channels. Ultimately, this forms the network structure of the RepVGG model during the training phase. As shown in Figure 1, during the training phase, the main channel is composed of 3 × 3 convolution modules and Rectified Linear Unit (ReLU) activation functions. The branch channel combines 1 × 1 convolution modules with residual identity branches, enhancing the model's feature extraction capabilities and acquiring more feature information. During the inference phase, the model utilizes a stacked arrangement of 3 × 3 convolution modules and ReLU activation functions, thereby improving inference speed.

Model Structure of RepVGG Network in the Training and Inference Phases.
The Channel Attention Module (CAM) is set at the input end with a group of input feature maps. Initially, the feature maps undergo Global Average Pooling (GAP) and Global Max Pooling (GMP), resulting in two groups of pooled feature maps. Subsequently, these one-dimensional feature vectors from both pooling processes are input into a shared-parameter neural network. The neural network outputs a summed weighted feature vector after sigmoid activation, producing the channel attention feature vector. The computational method for the channel attention module is shown in equation (1).
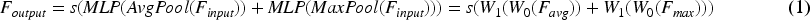
Where
The Spatial Attention Module (SAM) also starts with a group of input feature maps. These feature maps are similarly processed through Global Average Pooling and Global Max Pooling. Then, the pooled feature vectors are concatenated at the channel level and reduced in dimension through convolution. A sigmoid activation function generates the spatial attention feature. The computational method for the spatial attention module is shown in equation (2).
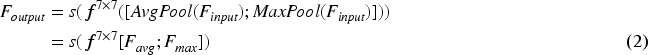
Where
The YOLOv5 s network model employs the Path Aggregation Network (PANet) (Liu et al., 2018) as a feature fusion network, as depicted in Figure 2(a). This network aggregates features extracted at different dimensions using both top-down and bottom-up approaches, though it overlooks the attention and importance of feature fusion at various scales. In 2019, the Google team proposed the EfficientDet algorithm, which introduced a weighted bidirectional feature pyramid network, BiFPN, as shown in Figure 2(b).
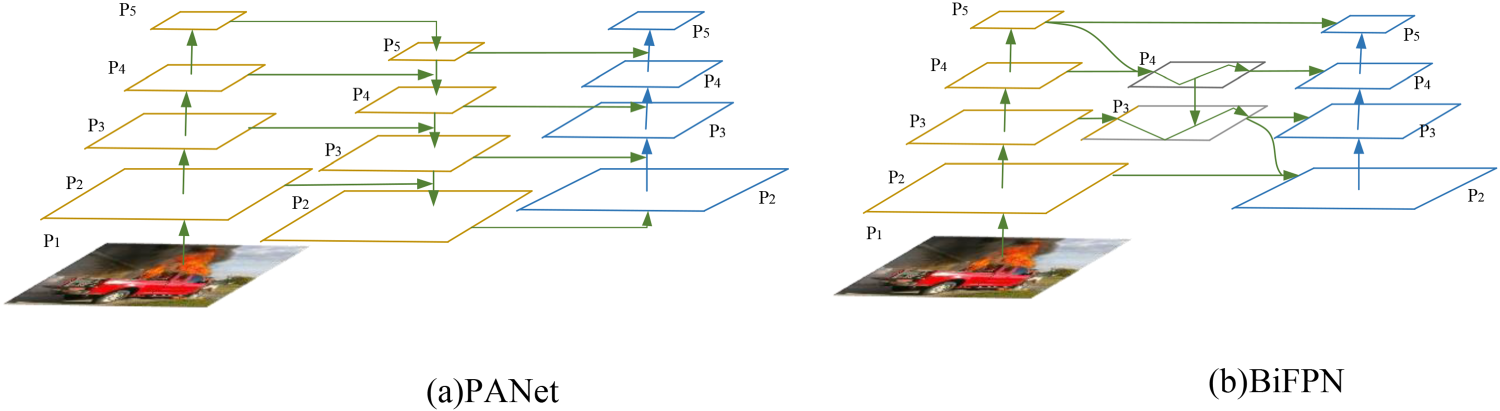
Structure of Two Feature Fusion Networks.
To address the issues of low inference speed and challenging feature extraction in the original network models, this study enhances the YOLOv5 object detection algorithm by incorporating the RepVGG lightweight convolutional network into the backbone convolutional layers of the YOLOv5 s model. RepVGGBlock modules replace the original network's basic convolution modules (Conv), while retaining the Focus module and Spatial Pyramid Pooling (SPP) structure. The backbone network structure of the YOLOv5 s model with the RepVGG module is presented in Table 2.
Introduce the YOLOv5 s Backbone Network Structure of the RepVGG Module.
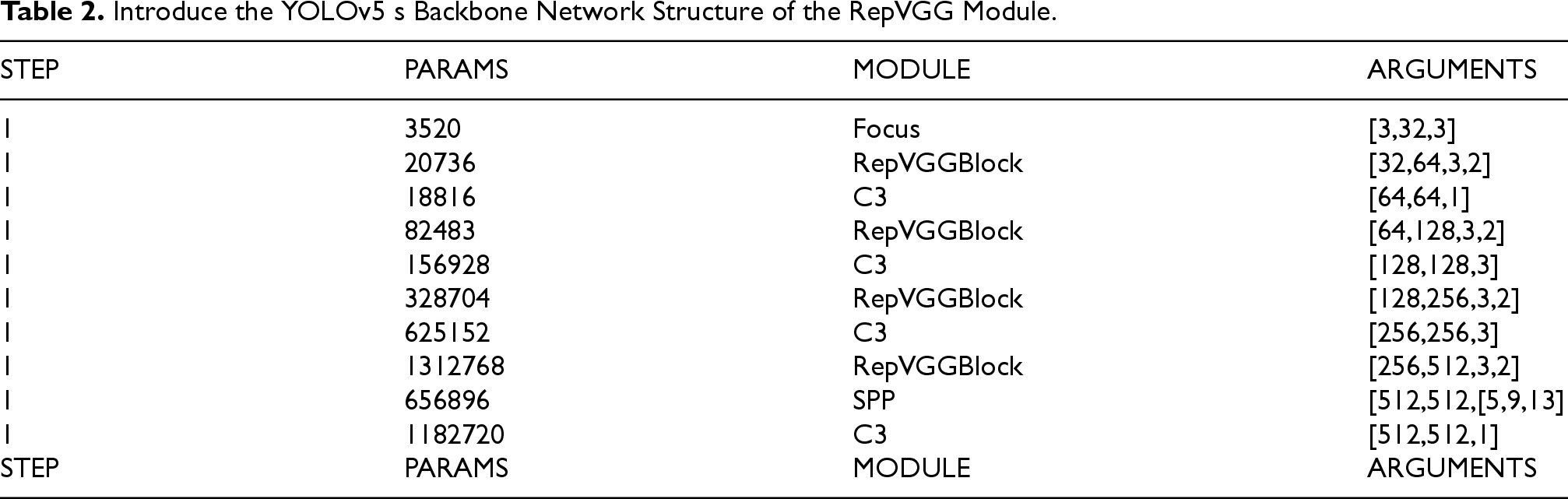
Introduce the YOLOv5 s Backbone Network Structure of the RepVGG Module.
The advantages of using the RepVGG model for the backbone convolutional layers include: 1) The model's design utilizes structural re-parameterization to better balance detection accuracy and speed; 2) The use of stacked 3 × 3 convolution modules with ReLU activation functions reduces computational costs, facilitating embedding and deployment on mobile devices; 3) The single-channel inference process significantly reduces the model's inference time, thereby enhancing the model's inference speed.
However, the network model with the RepVGG module still faces challenges with background interference and insufficient effective feature extraction, lacking an appropriate attention mechanism to focus more on important features in the target area (Dong et al., 2023). Consequently, this study integrates the CBAM attention mechanism into the backbone network part.
As illustrated in Figure 3, the CBAM attention mechanism applies convolution and weighting operations to the extracted feature maps across both channel and spatial dimensions. This enhances the network model's ability to focus on features in the target area while suppressing irrelevant background interference, and it also reduces the computational load of the network model.

Structural of the CBAM Attention Mechanism.
In order to compare the difference between the YOLOv5 model and the addition of the CBAM attention mechanism, this paper separately visualizes the two models, as shown in Figure 4 below, the first line shows the visualization results of the original YOLO model, and the second line shows the visualization of the CBAM model with the addition of CBAM, which shows that the attention area of interest of the CBAM is larger than that of the original YOLOv5 model on the visual heat map, and the hotspot region of interest is larger than the original YOLOv5 model, which makes it easier to enhance the sensitivity of the model for fire detection.
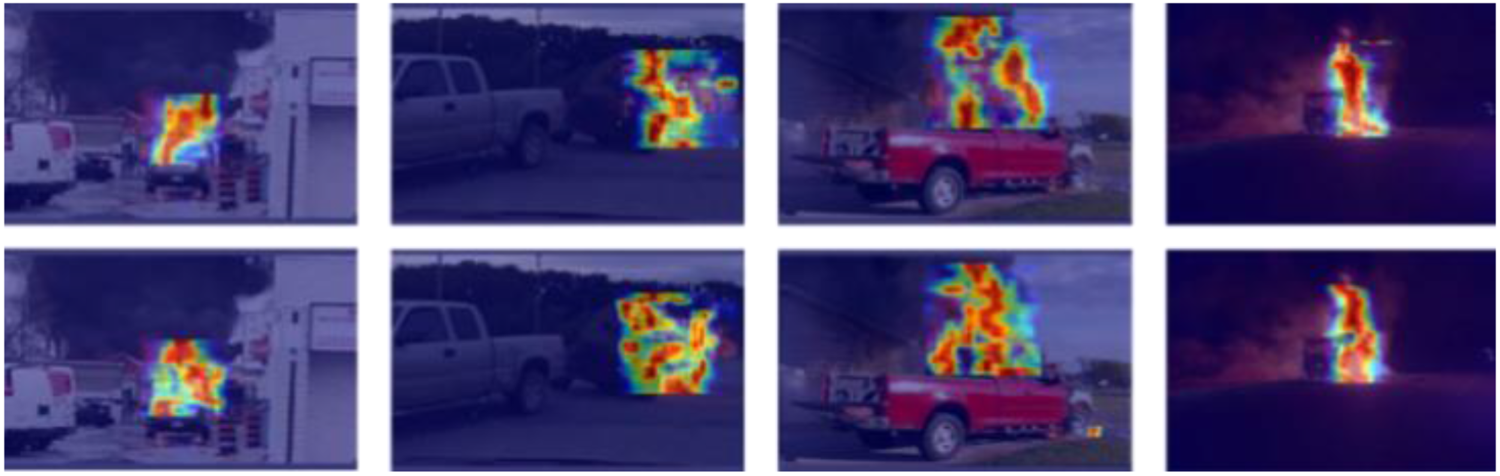
Comparison of CBAM Attention Mechanism Visualization.
Incorporating the RepVGG module and the CBAM attention mechanism into the YOLOv5 s network model improves the model's feature extraction capability and attention to features in the target area. Additionally, it optimizes the model's size and computational load.
To facilitate the weighted fusion of feature information across different scales, the BiFPN structure is employed as the feature fusion network of the YOLOv5 s model. The specific structure is depicted in Figure 5, which strengthens the features extracted from layers A3 to A5 and passes them to multi-scale feature layers, resulting in three outputs at different scales: P3, P4, and P5. The BiFPN network not only retains the top-down and bottom-up fusion methods but also incorporates multi-scale cross-connect weighting operations. At various resolutions, adaptive learnable weights are set for each input node, balancing feature information across different scales. The final output is a superposition of the weighted feature vectors, delivering enhanced feature information.
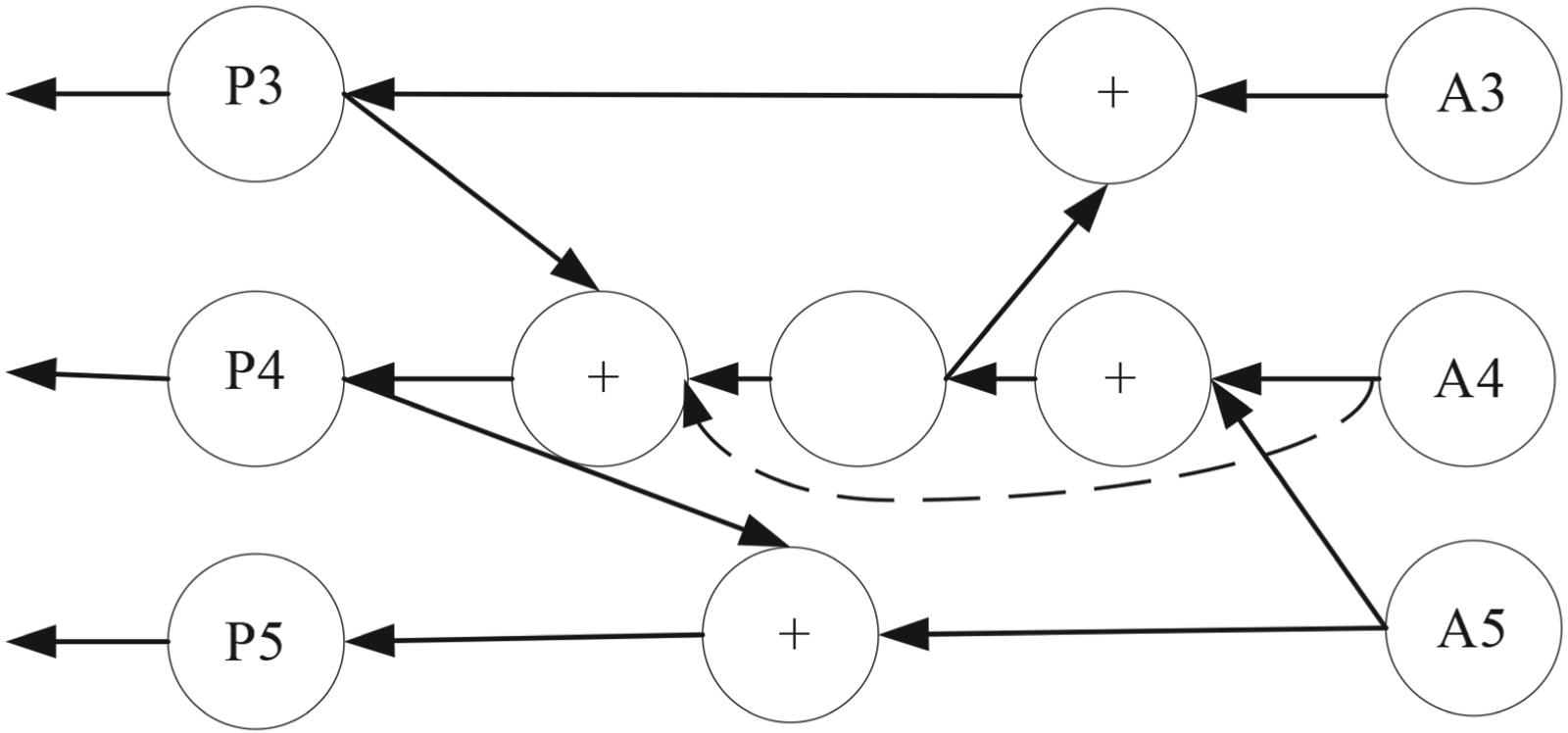
BiFPN Network Structure in YOLOv5s-RBC.
Therefore, the model framework of the YOLOv5 algorithm before and after improvement is shown in Figure 6. The Backbone and Neck parts of the algorithm are mainly improved, and the RepVGG, CBAM and BiFPN modules are respectively integrated into the main framework of the algorithm.

Schematic Diagram of the Main Framework Before and After Algorithm Improvement.
The specific network improvement work in this paper is as follows, replace the original Conv module of the first, third, fifth, and seventh layers in the Backbone network with the RepVGGBlock module, add the Conv_CBAM module in the middle of the C3 module of the second layer and the improved module of the third layer, and the module to strengthen the detection ability of the model. In the Head section, replace the original layer 19's layer 14 and layer 18 Concat operations with layer 6, layer 13 and the previous layer's Concat operations, and the original layer 22's Layer 10 and the previous layer's Concat operations with layer 9 and the previous layer's Concat operations.
By collecting and capturing real fire scenes, each image contains at least one fire source, with a small number of images having smoke obscuring fire source types including: indoor fires, forest fires, automobile combustion, kitchen fires, candle lamps, and farmland waste burning. A total of 5889 common fire scenes were collected. All valid samples were labeled with labeling software and divided into training, validation and test sets in the ratio of 8:1:1. Figure 7 shows some fire scenes in the dataset.

Example Plot of the Fire Dataset Used for Training.
This study was conducted on a computer equipped with the Windows 10 operating system and a GeForce GTX 1650 GPU.
Model Evaluation Index
The mean Average Precision (mAP) and Average Precision (AP) are used as indicators to evaluate the model's recognition performance. Precision and Recall, which calculate mAP and AP, are demonstrated through Equations (3) and (4). where TP (True Positives) represents the count of correctly classified positive targets, FP (False Positives) represents the count of incorrectly classified positive targets, and FN (False Negatives) represents the count of incorrectly classified negative targets. AP is represented by the area under the curve formed by the Precision-Recall curve, and mAP is the ratio of the average precision of all target categories to the total number of target categories, as shown in Equations (5) and (6). where P represents Precision, the y-coordinate on the P-R curve, and R represents Recall, the x-coordinate on the P-R curve. n represents the total number of target categories, and i denotes the current target category's sequence. Frames Per Second (FPS) is used as an indicator to evaluate the detection speed of the model, testing its real-time performance as shown in Equation (7). where t represents the time required to process an image. Also in this paper we introduce the F1-Score metric which is an evaluation metric for binary classification problems that combines Precision and Recall. The F1-Score is a single numerical value used to synthesize the performance of the classifier, especially in the case of class imbalance. The F1-Score is calculated as follows Equation (8). The F1 score takes values between 0 and 1, where 1 indicates a perfect classifier and 0 indicates the worst classifier. It takes into account false positive and false negative cases, not just accuracy. In some cases, there is a trade-off between precision and recall, which can be helped by the F1 score to find a balance that allows the classifier to achieve good performance between precision and recall.






To select a more appropriate pretrained model for optimization, comparative experiments were conducted on the proposed dataset, with results shown in Table 3. Based on the YOLOv5 algorithm, iterations and tests were performed on four models: YOLOv5 s, YOLOv5 m, YOLOv5 l, and YOLOv5x.
Performance Metrics of Four Pre-trained Network Models.

Performance Metrics of Four Pre-trained Network Models.
From Table 3, it is evident that the YOLOv5 s network model's AP value outperformed the other three pretrained models by 1.9%, 2.8%, and 3.7%, respectively, achieving 85% while having the smallest model size. As shown in Figure 8, the YOLOv5 s network model requires less computational power and inference time compared to the other three pretrained models. Therefore, this study optimizes the algorithm using the YOLOv5 s network model combined with the proposed dataset.

Computational Volume and Inference Time Results of Four Pre-Trained Models.
In order to verify the effectiveness of the lightweight convolutional neural network RepVGG module in the algorithm, this study compared other lightweight modules, including MobileNetV2, MobileNetV3 and EfficientNet. The results are shown in Table 4.
Comparison of Parameters of Different Lightweight Models.

As shown in Table 4, the RepVGG module achieves the highest average precision (AP) value, demonstrating excellent detection accuracy when integrated with the YOLOv5 algorithm, while reaching 0.847 in the composite metric F1 score, outperforming the other modules. Notably, the module has a computational complexity of 12.2 GFLOPS and a model size of 8.3 MB, reflecting an effective balance between performance and resource requirements. In contrast, the MobileNetV2 module has the lowest computational complexity but obtains a significantly lower AP of 80.81%, which indicates a much lower accuracy. Although the EfficientNet module is second only to the RepVGG module in terms of average precision (AP) as well as F1 score, the EfficientNet module performs poorly in terms of both model size and computational complexity, making it less suitable for lightweight applications. In this case, the goal of lightweight design is to optimize the computational complexity and model parameters while maintaining the detection accuracy, thus achieving an effective trade-off. Based on these conclusions, this study adopts the RepVGG module as the preferred lightweight solution for fire detection algorithms.
In terms of the attention mechanism, several common attention mechanism methods such as EMA, SimAm, CPCA, MPCA, MLCA, CAFM are selected to verify the effectiveness of the attention mechanism selected in this paper, and CBAM as the attention mechanism of augmented CNN network can be well embedded into the fire data detection studied in this paper, and has a good generalization effect on the fire data at different scales. generalization, the specific results of the experiment are shown in Table 5.
Comparison of Parameters of Different Attention Mechanisms.
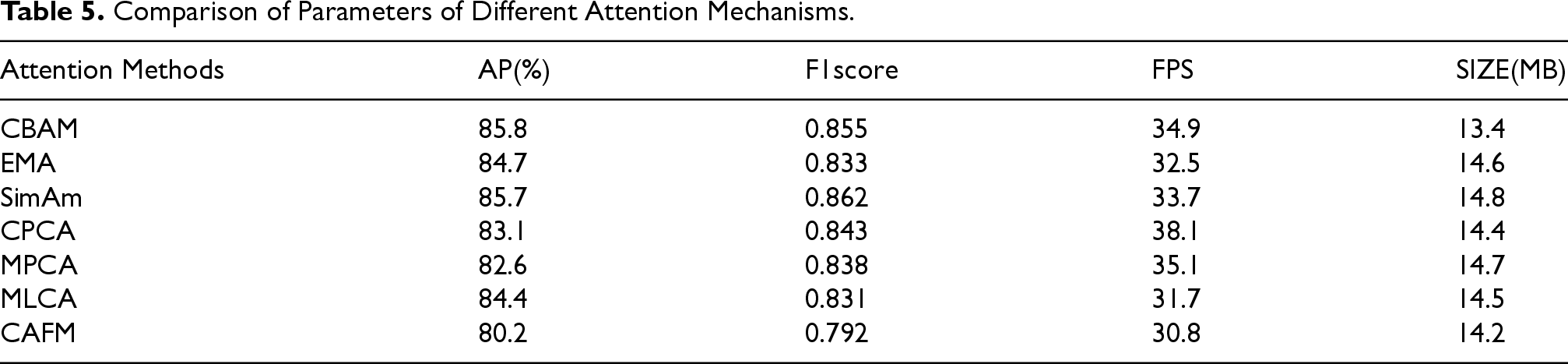
As can be seen from Table 5, among the seven mainstream attention mechanisms, the CBAM attention mechanism takes the lead with 85.8% in average precision (AP), and although it is slightly lower than the SimAm module in F1 scores, it has the advantage in both FPS and model size, so by combining all the evaluation metrics, this paper chooses the CBAM attention mechanism as the preferred choice for the subsequent improvement method.
To verify the effectiveness of the proposed improved algorithm, comparisons were made with nine other mainstream detection algorithms, and the results are shown in Table 6.
Comparison with Mainstream Detection Algorithms.
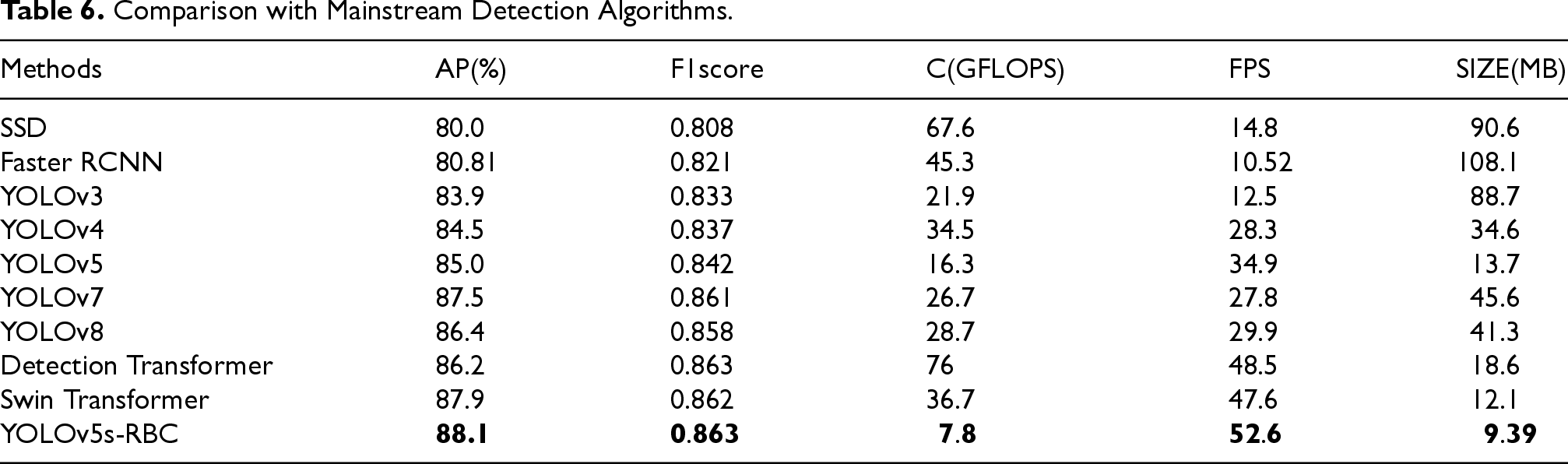
From Table 6, the YOLOv5s-RBC algorithm proposed in this study reached the highest AP performance index at 88.1%. Compared with SSD (Liu et al., 2016), Faster RCNN (Ren et al., 2017), YOLOv3 (Redmon & Farhadi, 2018), YOLOv4 (Bochkovskiy et al., 2020), YOLOv5, YOLOv7, YOLOv8, Detection Transformer and Swin Transformer the proposed algorithm improved average detection accuracy by 8.1%, 7.29%, 4.2%, 3.6%, 3.1%, 0.6%, 1.7%, 1.9% and 0.4%, respectively, showing excellent performance in detection accuracy. From Table 6, the YOLOv5s-RBC algorithm proposed in this study reached the highest AP performance index at 88.1%. Compared with SSD (Liu et al., 2016), Faster RCNN (Ren et al., 2017), YOLOv3 (Redmon & Farhadi, 2018), YOLOv4 (Bochkovskiy et al., 2020), YOLOv5, YOLOv7, YOLOv8, Detection Transformer and Swin Transformer the proposed algorithm improved average detection accuracy by 8.1%, 7.29%, 4.2%, 3.6%, 3.1%, 0.6%, 1.7%, 1.9% and 0.4%, respectively, showing excellent performance in detection accuracy. In addition, the improved algorithm YOLOv5s-RBC and Detection Transformer proposed in this paper have a combined evaluation index F1 score of 0.863, which is ranked the highest among all the models and 0.055 higher than the lowest SSD module. From the real-time perspective, the average detection speed of the improved algorithm YOLOv5s-RBC reaches 52.6 frames/sec, which is 17.7 frames/sec higher than the original algorithm, and meets the requirement of real-time detection. The network model of YOLOv5s-RBC has the smallest size of only 9.39MB, which is lightweight, and is easy to be embedded and deployed on mobile devices and development boards.
In order to verify the effect of the proposed modules and structures on the YOLOv5 s network model, ablation experiments were conducted in the test set to enhance the comparison between the improved methods and further analyze the effectiveness of the proposed method, and the results are shown in Table 7. From Table 7, it can be seen that using the RepVGG module as the convolutional layer of the backbone network can reduce the computational load and inference time of the model, but the improvement of the detection accuracy is not obvious. After adding the CBAM attention mechanism to the RepVGG module, the computational load and inference time of the model reach the lowest, which are 6.1 GFLOPS and 8.7 ms, respectively, and the AP value is also improved by 1.3%. However, the detection accuracy still needs to be improved, and the weighted fusion of features extracted from different dimensions can improve the attention to the features of the target region. Meanwhile, this study introduces the F1 score to verify the effectiveness of the improved model in this paper, and from the comparison, it can be seen that the optimized model consisting of RepVGG module and BIFPN feature fusion mechanism reaches the highest value of 0.864 in the F1 score of the comprehensive evaluation index, while the YOLOv5s-RBC algorithm proposed in this paper is almost the same with this model in terms of the model computational load and inference time far exceeds that model, especially in the computational load of the model, which is only 51% of that model. Therefore, using the BiFPN structure can effectively optimize the feature fusion structure and improve the detection accuracy. However, it also adds extra computational load, which increases the inference time of the model to 20.5 ms. The proposed YOLOv5s-RBC algorithm enhances the model's focus on the features of the target region, suppresses the interference of the complex background, reduces the computational load and inference time of the model, effectively improves the detection accuracy, and meets the real-time requirements (See Figure 9).
Experimental Performance Index Study of Different Network Models for Ablation.

Experimental Performance Index Study of Different Network Models for Ablation.

Model Detection Results, the First Row is the Original Fire Image, the Second Row is the Detection Results Output by YOLOv5 Algorithm, and the Third Row is the Detection Results Output by YOLOv5s-RBC Algorithm.
In order to verify the generalizability of the YOLO-RBC model proposed in this paper, we validated the model using the video fire dataset (Foggia et al., 2015). The validation process was carried out on a local computer without using any program, where the model averages the detection time output at the time of detection of each video, and finally calculates the results based on the FPS formula, which gains the final results as shown in Table 8 below.
Experimental Performance Index Study of Different Network Models for Ablation Video Dataset Information and Average FPS Values.

As seen above, the YOLO-RBC model proposed in this paper has a stable FPS value higher than 70 in different sizes of video data, which is capable of handling most of the dynamic fire detection scenarios, and also shows good model stability on untrained video datasets, and the results of some video datasets are shown in the following Figure 10.

Selected Video Dataset Results are Shown.
We also used the above video dataset for the detection comparison between the nine mainstream algorithm models in Table 6 and the YOLO-RBC model proposed in this paper, and the comparison results are shown in the figure below, which shows that most of the models have an obvious disadvantage in the detection of early fire embers in the same video dataset, while the detection effect of the YOLO-RBC model proposed in this paper is also better than the others, which reflects the robustness of the proposed model (See Figure 11).

Comparison of 10 Mainstream Algorithms on Video Datasets.
Meanwhile, in the non-fire scenario test, we used 2 sets of self-developed UAV flights to photograph the plantation forest samples, and the sample display images are shown in Figure 12.

UAV Planted Forest Sample Plot Dataset.
428 UAV images were collected in sample plot A and 647 UAV images were collected in sample plot B. The misdetection rate of the model and the degree of detection function in multiple scenarios were quantified by model detection validation in multiple scenarios, and the final experiments found that, in sample plot A, there were 8 misdetections in the 428 datasets with a misdetection rate of 1.86% for the YOLO-RBC model proposed in this paper, and in sample plot B the 647 data sets, there are 56 misdetections with a misdetection rate of 8.66%. From the experiment, it can be found that the model has stronger detection performance in the forest area with dense canopy, and the false detection rate increases in the area with sparse forest and relatively dry land (See Figure 13).

Demonstration of UAV Dataset Misdetection Results for Sample Plots A and B.
Fires pose a significant and unavoidable challenge in human life. With the continuous advancement of science and technology, particularly the iterative development of image detection techniques and deep learning algorithms, the pursuit of precise and rapid-response detection methods has emerged as a critical breakthrough direction in contemporary fire detection research. The YOLOv5s-RBC network proposed in this paper achieves notable progress in both responsiveness and accuracy. With a model size of only 9.39 MB and a computational complexity (GFLOPS) of 7.8—the lowest among all compared models—this approach is highly amenable to integration into hardware devices. Furthermore, its detection speed of 52.6 frames per second (FPS) enhances its suitability for applications such as unmanned aerial vehicle (UAV)-based fire detection and high-altitude mechanical operations, where real-time performance is paramount.
As a pervasive and severe issue in human society, fires are characterized by their sudden onset, destructive potential, and uncontrollability, often resulting in substantial economic losses and human casualties. The ongoing evolution of scientific technologies, especially in the domains of image detection and deep learning algorithms, has made the development of accurate and swift fire detection methods a focal point of current research efforts and a key to overcoming the limitations of traditional fire detection systems. The YOLOv5s-RBC network model introduced in this study demonstrates remarkable innovation and practical potential in this field. It achieves significant improvements in both detection speed and accuracy, with an AP of 88.1%, underscoring its effectiveness in fire recognition tasks. Notably, the model's compact size of 9.39 MB provides a clear lightweight advantage over other mainstream detection algorithms, while its computational complexity of 7.8 GFLOPS—the lowest among evaluated models—substantially reduces resource demands, facilitating its deployment on hardware platforms. Additionally, the model's detection speed of 52.6 FPS not only meets the requirements for real-time detection but also renders it particularly well-suited for specific scenarios. In applications such as UAV-based fire detection and high-altitude mechanical operations, which demand rapid mobility and real-time analysis, the YOLOv5s-RBC model leverages its lightweight design and high efficiency to provide reliable support for fire monitoring in dynamic environments.
However, this study is not without its limitations, particularly with respect to the model's real-time detection capabilities, where further optimization is warranted. First, the research does not adequately address the classification training of scenarios that closely resemble fire events. For instance, in practical settings, the visual characteristics of fires may bear a striking similarity to certain non-fire phenomena, such as the reddish glow of a sunset, artificial lighting, or smoke from industrial emissions. This similarity could lead to misclassifications or missed detections in complex environments. Since the training dataset may not comprehensively encompass these edge cases, the model's generalization capability may be constrained when encountering such atypical conditions, thereby compromising its reliability and accuracy. Second, while the study achieves breakthroughs in lightweight design and real-time performance, the model's effectiveness under extreme conditions—such as dense smoke occlusion, low-light settings, or scenes with multiple overlapping objects—remains insufficiently validated. These scenarios may impose greater demands on feature extraction and attention mechanisms, potentially exposing performance bottlenecks in the current YOLOv5s-RBC model when addressing such complexities. Addressing these shortcomings in future work will be essential to enhancing the model's robustness and applicability in real-world fire detection tasks.
Conclusion
This paper draws on the YOLOv5 algorithm, optimizing the model based on the YOLOv5 s network model integrated with the RepVGG module, CBAM attention mechanism, and BiFPN network. The RepVGG module enhances the network's feature extraction capabilities during the training phase and also increases the model's inference speed during the inference phase. The CBAM attention mechanism allows the network model to focus more on the features of the target area, suppress irrelevant background interference outside the target area, and reduce the computational load of the network model. The BiFPN network assigns different weights to the feature vectors to balance the acquired feature information, thereby achieving the purpose of weighted fusion of feature information at different scales. The experimental results show that the proposed YOLOv5s-RBC network model outperforms many current mainstream fire image detection advanced algorithms and can meet the requirements of being lightweight, real-time, and accurate.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work in this paper has been supported by National Natural Science Foundation of China (62462029, 62062006, 62362029, 62262018), Hainan Provincial Natural Science Foundation of China (625RC758) and Higher Education Teaching Reform Project in Hainan (Program No. Hnjg2024-59).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.