
Abstract
This paper investigates the detailed analysis of linear diophantine fuzzy Aczel-Alsina aggregation operators, enhancing their efficacy and computational efficiency while aggregating fuzzy data by using the fuzzy C-means (FCM) method. The primary goal is to look at the practical uses and theoretical foundations of these operators in the context of fuzzy systems. The aggregation process is optimised using the FCM algorithm, which divides data into clusters iteratively. This reduces computer complexity and enables more dependable aggregation. The mathematical underpinnings of Linear Diophantine Fuzzy Aczel-Alsina aggregation operators are thoroughly examined in this study, along with an explanation of their purpose in handling imprecise and uncertain data. It also investigates the integration of the FCM method, assessing its impact on simplifying the aggregation procedure, reducing algorithmic complexity, and improving the accuracy of aggregating fuzzy data sets. This work illuminates these operators performance and future directions through extensive computational experiments and empirical analysis. It provides an extensive framework that shows the recommended strategy’s effectiveness and use in a variety of real-world scenarios. We obtain our ultimate outcomes through experimental investigation, which we use to inform future work and research. The purpose of the study is to offer academics and practitioners insights on how to improve information fusion techniques and decision-making processes.
Keywords
Introduction
The methods typically employed in classical mathematics are not always satisfactory for handling real-world problems due to the uncertainties and ambiguity involved. In 1965, Zadeh [33] first proposed the concept of fuzzy sets, while Klir & Yuan [11] presented fuzzy logic in 1996 as an advancement over the traditional crisp set. In the unit closed interval [0, 1], the membership function assigns a real value to every item in the universe and creates a fuzzy set. It is an important mathematical tool for characterising a group of things whose borders are ill-defined. Fuzzy logic, distinguished by a membership function that has a range of 0 to 1, has replaced probability theory as a powerful tool for characterising obscurity, uncertainty, and imprecision in a variety of domains. The ability of fuzzy sets to handle imprecise, uncertain, or subjective information that frequently arises in real-life scenarios leads to a variety of applications across multiple domains. Fuzzy sets are used in control systems and engineering to model imprecise variables. This allows for more adaptable and flexible control mechanisms in processes like industrial automation and temperature regulation. Fuzzy sets help medical professionals make decisions by taking into account the uncertainty that may be present in patient data or symptoms, which helps in medical diagnosis. Fuzzy sets also help adaptive traffic management systems in the transportation and traffic control domains. These systems modify route guidance or signal timing in response to variable conditions, such as traffic density or meteorological forecasts. This has happened since Zadeh’s contribution to fuzzy sets [33]. In order to solve problems in a variety of disciplines, including robotics [44], environments [15], engineering [41], computer science [29], social science [40], and economics [6], researchers have looked into fuzzy sets. You can find studies of a few noteworthy works with fuzzy sets by Anoop, M. B., and Zadeh [32, 36]. Bustince [14] introduced the interval-valued fuzzy set (IVFS) in 2010. Modifications of FS theory [4, 55], application of FS theory in various fields [49] analysis of fuzzy systems [47, 57] are a few appropriate modifications that are listed in the shape. The membership function of this set is defined as denoting the collection of all subsets of [0, 1], for an explanation of the inadequate information. The idea of an intuitionistic fuzzy set (IFS) was created by Atanassov [28] in 1986. The hesitation degree is calculated, and the sum of the membership grade (ψ) and non-membership grade
An option where the sum of the membership and non-membership grades is higher than 1 and its total of squares, in some real-world situations, is more than 1 (e.g., 0.8 + 0.9 > 1) may satisfy a decision maker’s (DM) specified attribute. When this happens, both PFS and IFS malfunction. Changes have been made to the restrictions on membership and non-membership grades in order to address these worries. Models of decision-making must include control parameters. The lack of parameterizations in PFS, IFS, and q-ROFS is a disadvantage. LDFS provides the MADM with a multitude of applications for these kinds of real-world problems. This approach allows us to deal with the intuitionistic, Pythagorean, and qrung ortho-pair character of attributes under reference factor influence. For instance, if (0.8 + 0.5 > 1), we can insert reference parameters to make (0.8) (0.3) + (0.5) (0.2) <1, where (0.3, 0.2) are the standards by which membership and non-membership grades are measured, respectively. Due to its similarity to number theory’s well-known linear Diophantine equation ax + by = c, the linear Diophantine fuzzy set (LDFS) is the most appropriate word for the model that has been suggested. To describe how reference parameters work in LDFS since they can’t handle parameterizations in q-ROFSs, PFSs, or IFSs. The suggested model is an improvement over the existing methods, and choosing the grades is entirely up to the decision maker (DM). The physical attributes of the sense of reference are altered by this structure to provide further categorization. The q-linear Diophantine fuzzy set (q-LDFS) is a special combination of the Pythagorean fuzzy set and linear Diophantine fuzzy sets, as well as the q-rung ortho-pair fuzzy set. Almagrabi [1] introduced it and emphasised some of its most important features. Some operators were computed based on PFS, such as Archimedean operators [43], Einstein aggregation operators [60], and Schweizer-Sklar Muirhead mean operators [56] Additionally, in scenarios involving decision-making, for uncertainty to be aggregated effectively, aggregation operators are essential.
FCM clustering [26], also known as fuzzy C-means clustering, is a well-liked algorithm for cluster classification in data analysis and machine learning. Data points can be assigned to numerous clusters with different grades of membership using fuzzy C-means, reflecting the uncertainty or fuzziness in the data, in contrast to traditional crisp clustering methods. Web personalisation technologies that recognise and capitalise on user preferences to provide each user with dynamically tailored content have become increasingly crucial due to the internet’s continuous increase in available information. The logistics development in coastal regions was demonstrated by Xu et al. [34] through the usage of community division. In general, the program clearly encourages the growth of logistics in the regions along the coast. Xu et al. [35] proposed that the restrictions on the Sulfur content of marine fuels under the 1st round of ECA policy have only effectively reduced the SOx concentration in the Bohai Rim and the Yangtze River Delta region, whereas the impact on the Pearl River Delta region isn’t significant.
Using a real-world battery dataset, Zhang et al. [21] suggested the PF-BiGRU-TSAM method. The suggested strategy is superior to certain published techniques, according to experimental data. The idea of power routing was initially presented by Zhang et al. [22]. The dc-dc boost conversion system distributes power to the cells based on their cumulative damage, postponing the failure of cells with more cumulative damage. Conformal transformations, first proposed by J. Zheng and Hu [23], help non-linear kernels find difficult-to-identify minority class regions. These fractional methods proposed by [17, 18, 27, 50]. This helps the classifiers become more adaptive to unbalanced data with complicated distributions. Zheng [24] presented ideas that were better than what the rivals had learned.
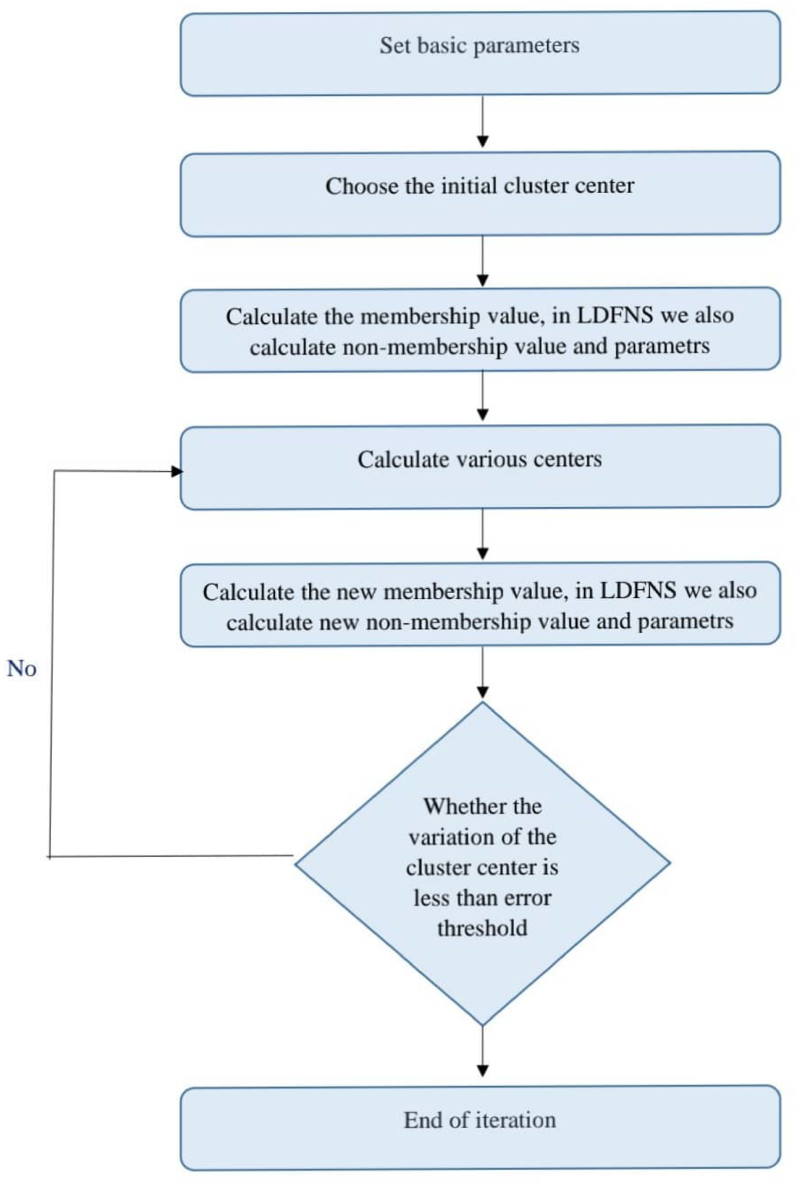
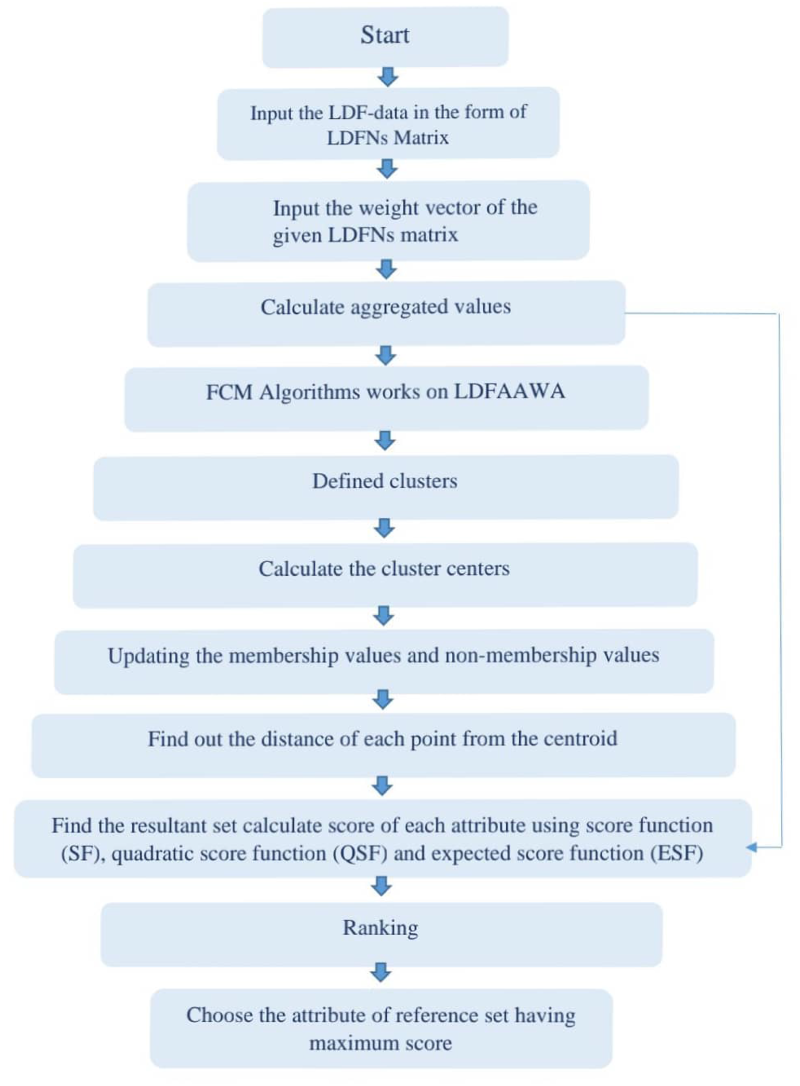
Flowchart of fuzzy-C means algorithm.
The contribution of the method proposed in this article is its practical applicability across several areas. The framework is adaptable and may be used for practical decision-making situations in several domains. The combination of FCM clustering and LDFAA operators allows for the control of ambiguities that are present in multi-attribute decision-making processes.
One special method for managing fuzzy data aggregation is to combine the Fuzzy-C Means clustering algorithm with linear Diophantine fuzzy aggregation operators. This new approach to data aggregation in fuzzy environments is made possible by the merging of ideas from fuzzy clustering techniques with a linear Diophantine fuzzy set. The formulation or modification of a methodology combining fuzzy clustering algorithms and a linear Diophantine fuzzy set is required by the research question. This raises a fresh question about the suitability and efficacy of using such an approach to aggregate fuzzy data. The combination of fuzzy clustering techniques like Fuzzy-C means with linear diophantine fuzzy aggregation operators may not be well covered in the literature as of yet. Therefore, by examining a relatively unexplored area in the realm of fuzzy logic and data analysis, this research issue has the potential to close a gap in the literature. The proposed research aims to shed light on the efficacy, efficiency, and practicality of fuzzy aggregation techniques by examining the Fuzzy-C Means clustering algorithm’s application in the context of linear Diophantine fuzzy aggregation operators. Therefore, the objectives and motivation of this article are as follows: To invent the Aczel-Alsina operational laws for LDF set based on the Aczel-Alsina t-norm and t-conorm. To expose the LDFAAWA operator, LDFAAOWA operator, and LDFAAHA operator, and evaluate their fundamental properties and results. To evaluate the problem of user profiling by fuzzy clustering to enhance the worth of the invented theory. To show the supremacy and accuracy of the proposed theory with the with the help of a comparative analysis between the proposed techniques and some existing techniques.
The overall scheme of this research paper is organised in this shape: In Section 2, we covered some basic LDFS concepts. In Section 3, it includes several possible Aczel-Alsina operational laws for LDFNs. In Section 4, it includes several possible Aczel-Alsina AOs for LDFNs. In Section 5, we discussed Fuzzy-C means clustering by user profiling. In Section 6, we solved a numerical example by using an algorithm. Some concluding remarks are stated in Section 7.
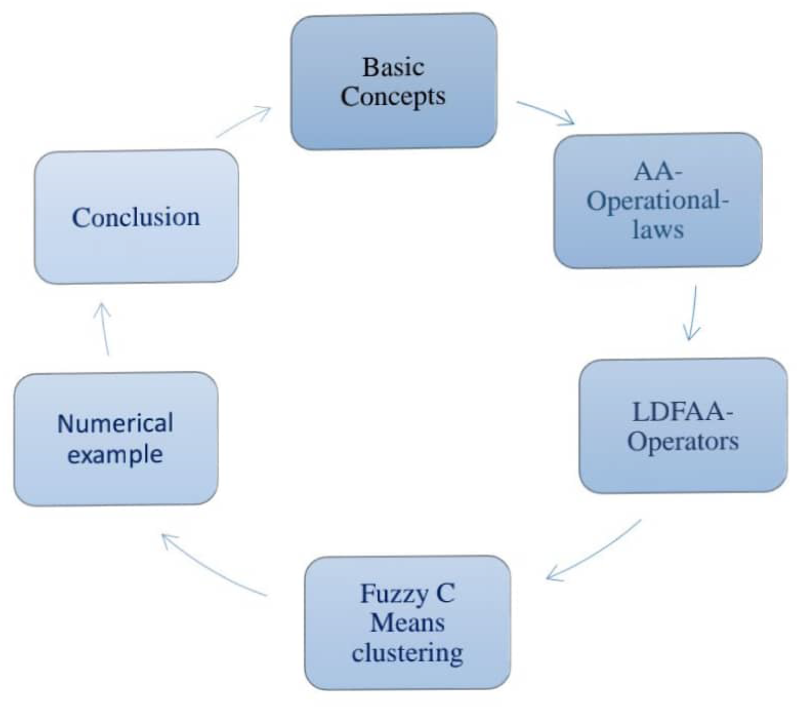
Graphical representation of paper scheme.
Explanation of symbols
In this section, we go over a few fundamental LDFS concepts, functions, and score functions.
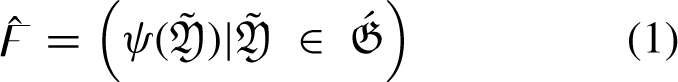
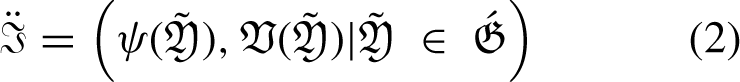
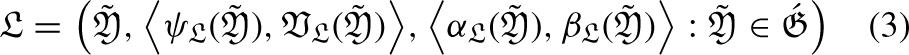
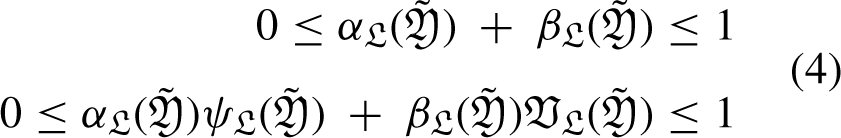
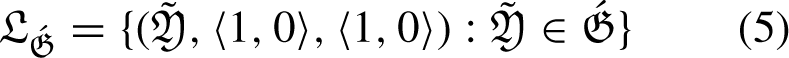
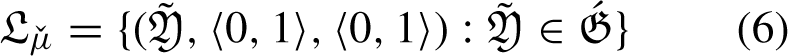
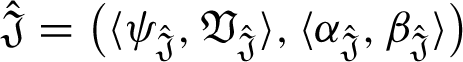
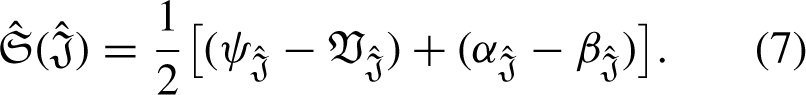
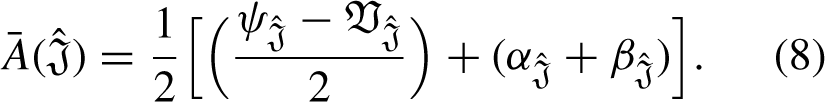
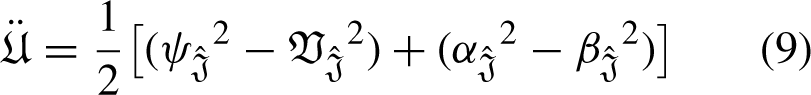
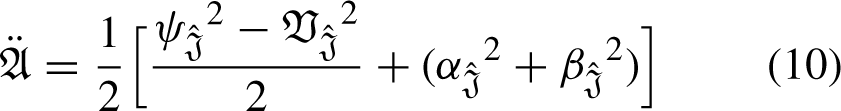
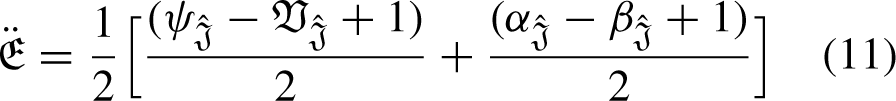
If If If If If If
Aczel-Alsina Operational laws pertaining to linear Diophantine fuzzy numbers are particular guidelines and precepts that control how aggregation operators behave when dealing with these fuzzy numbers. Diophantine equations are extended to fuzzy numbers with linear Diophantine fuzzy numbers, allowing uncertainty or imprecision in numerical values to be represented. Within this framework, definition and comprehension of t-norms and t-conorms are central to the discussion of Aczel-Alsina operational laws for linear Diophantine fuzzy numbers.
T-norms in the context of linear Diophantine fuzzy numbers represent mathematical operations that model the intersection or conjunction (AND) operation between fuzzy numbers. These functions combine two fuzzy numbers and produce an output that represents the intersection of their fuzzy sets. T-norms maintain certain properties, such as commutativity, associativity, and boundary conditions within the context of T-conorms are mathematical operations that model the union or dis-junction (OR) operation between fuzzy numbers in the context of linear Diophantine fuzzy numbers. T-conorms are similar to t-norms in that they take two fuzzy numbers and output the union of their fuzzy sets. Additionally, T-conorms have particular properties and guidelines when it comes to linear Diophantine fuzzy numbers.
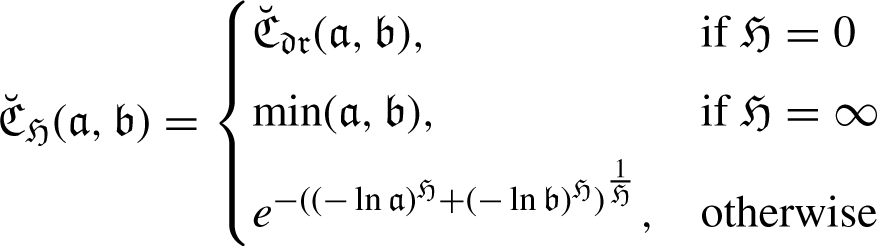
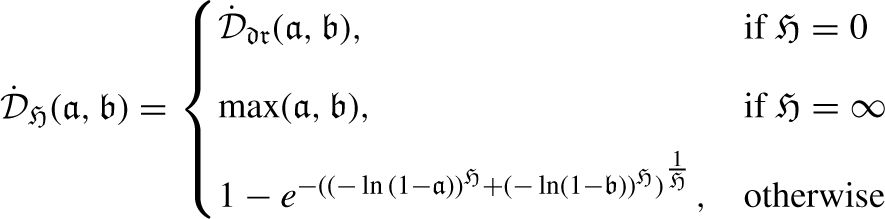
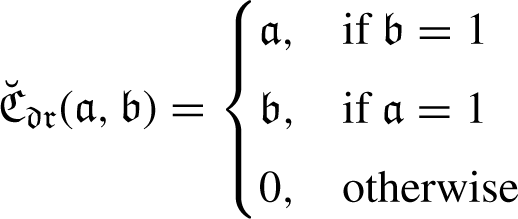
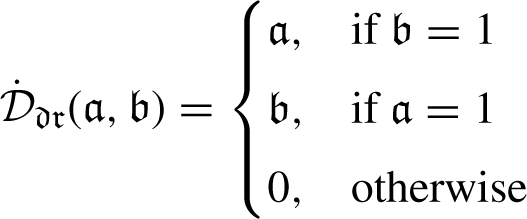
New approaches to LDFNs with some notable features, based on Aczel-Alsina operators are presented in this section: LDFAAWA, LDFAAOWA and LDFAAHA.
LDFAAWA Operator
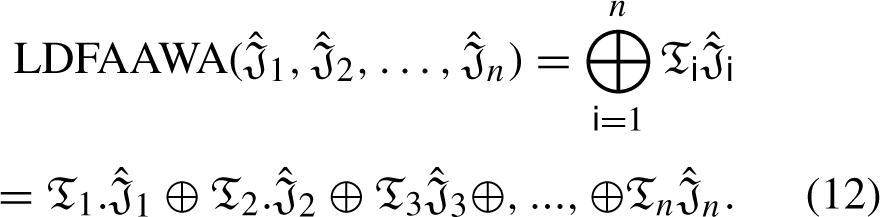
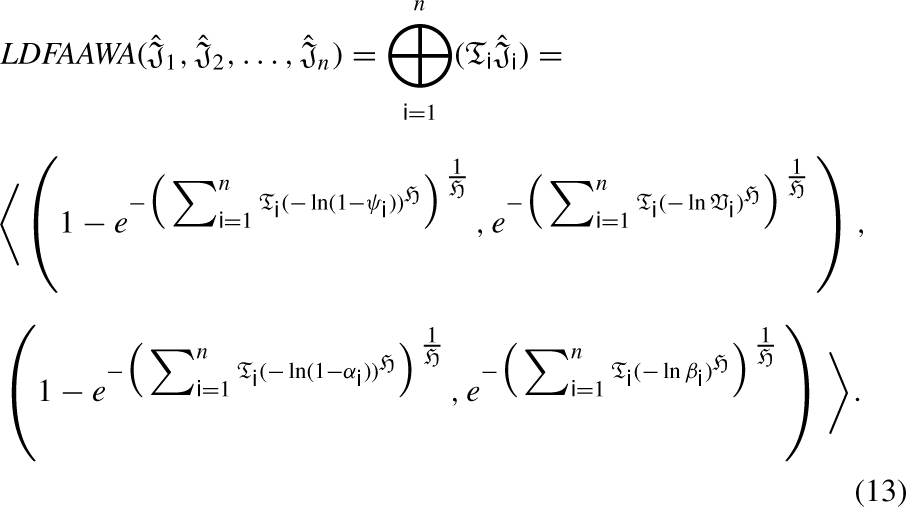
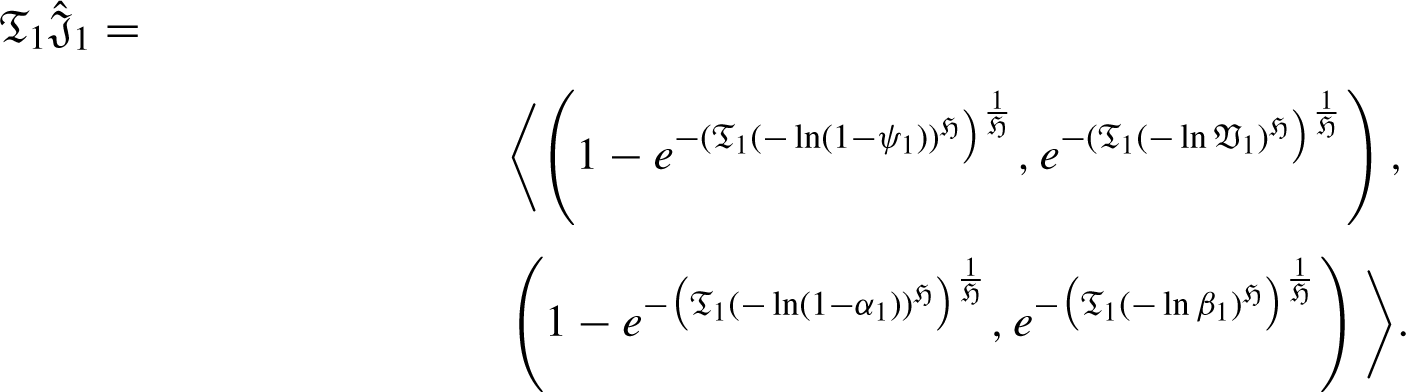
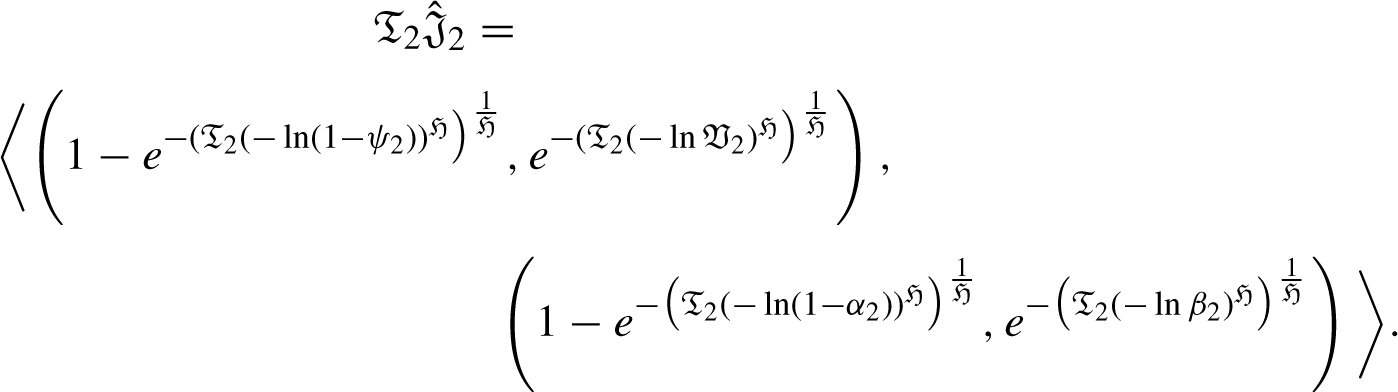
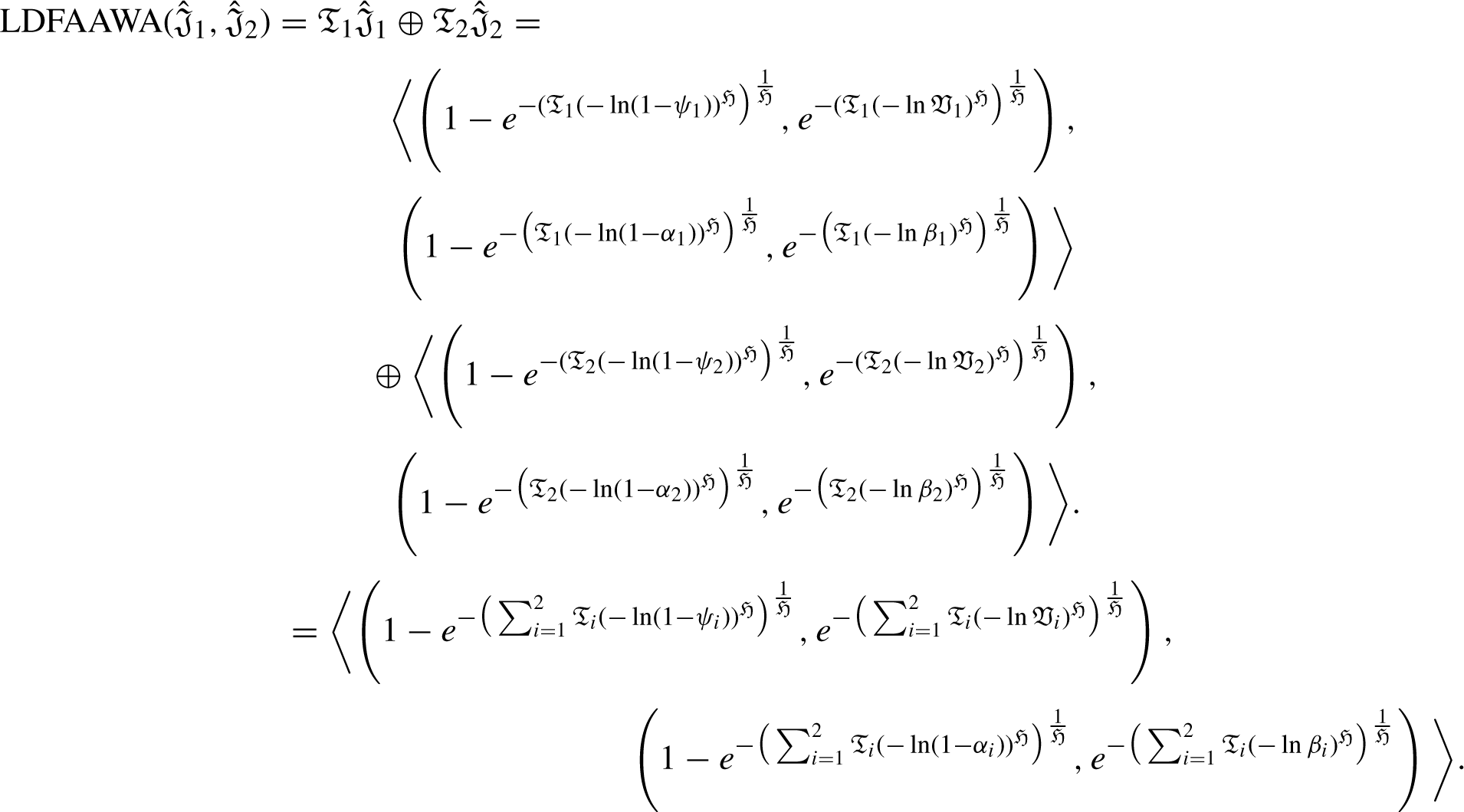
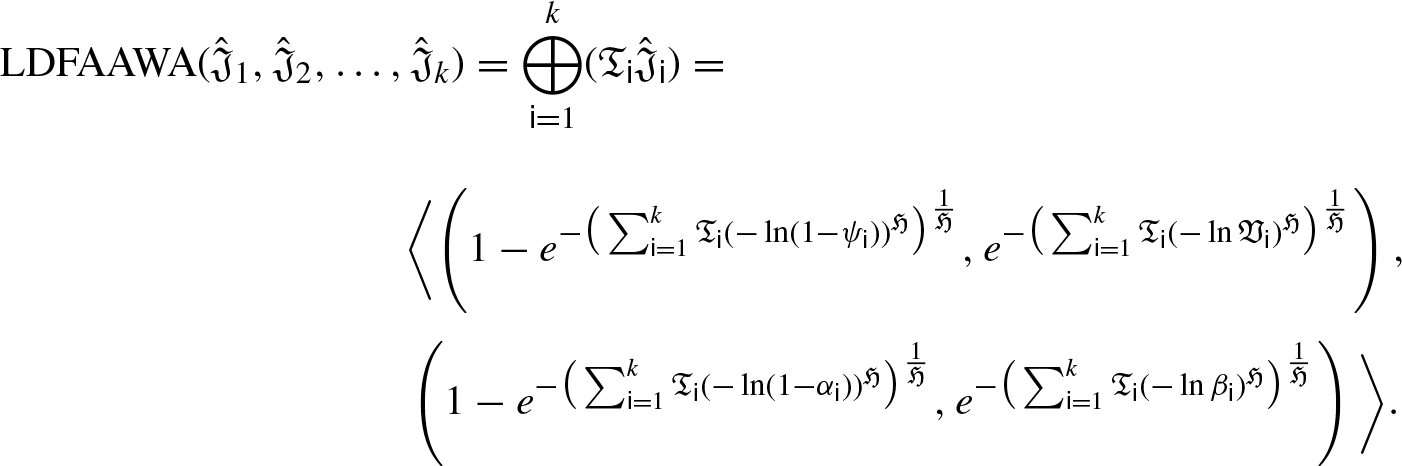
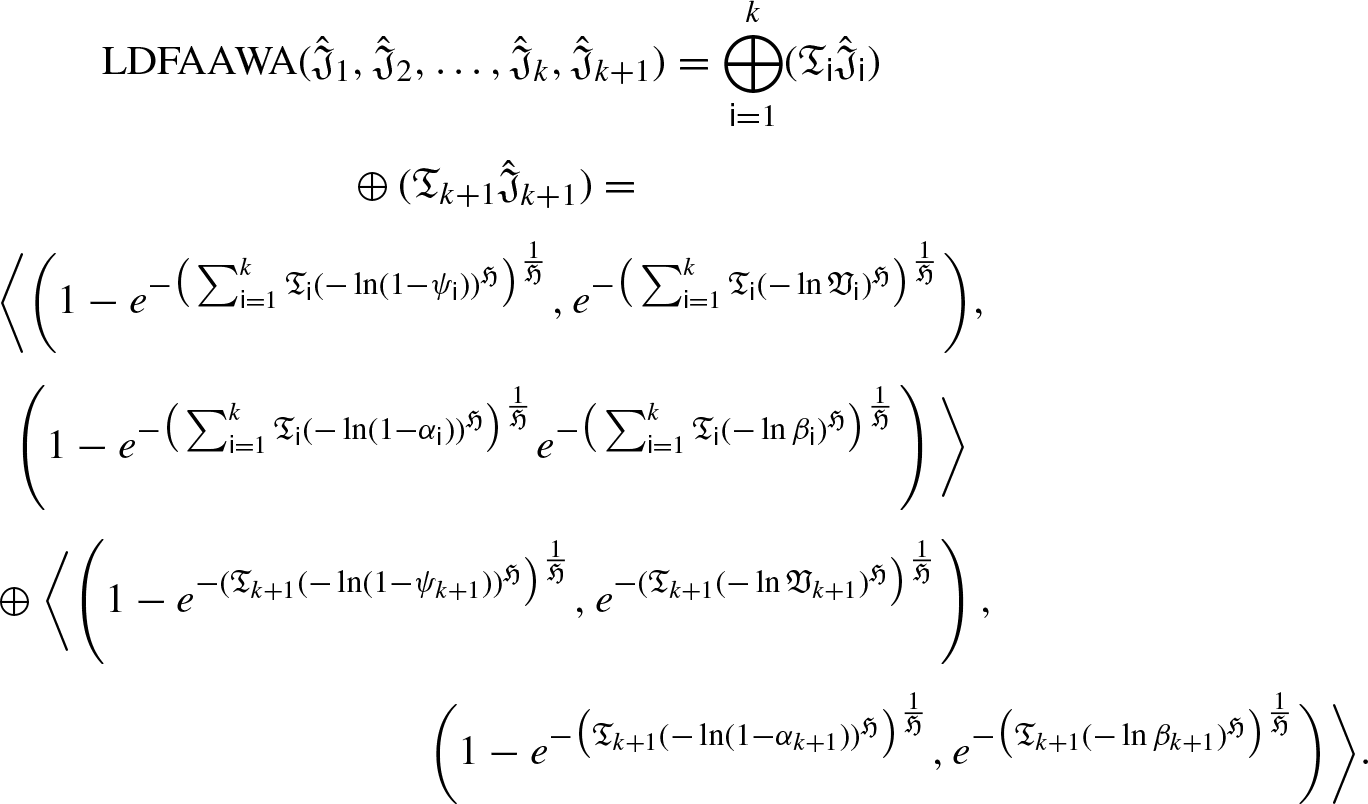
Now, we are to prove that it is also true for n = k + 1, such that:
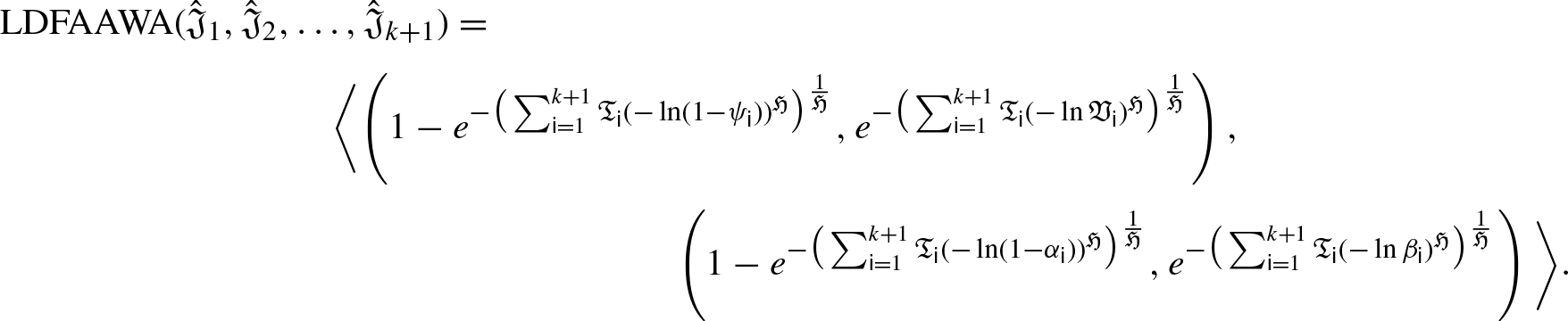
A few of the advantageous characteristics of an LDFAAWA operator will be covered in the next few paragraphs.

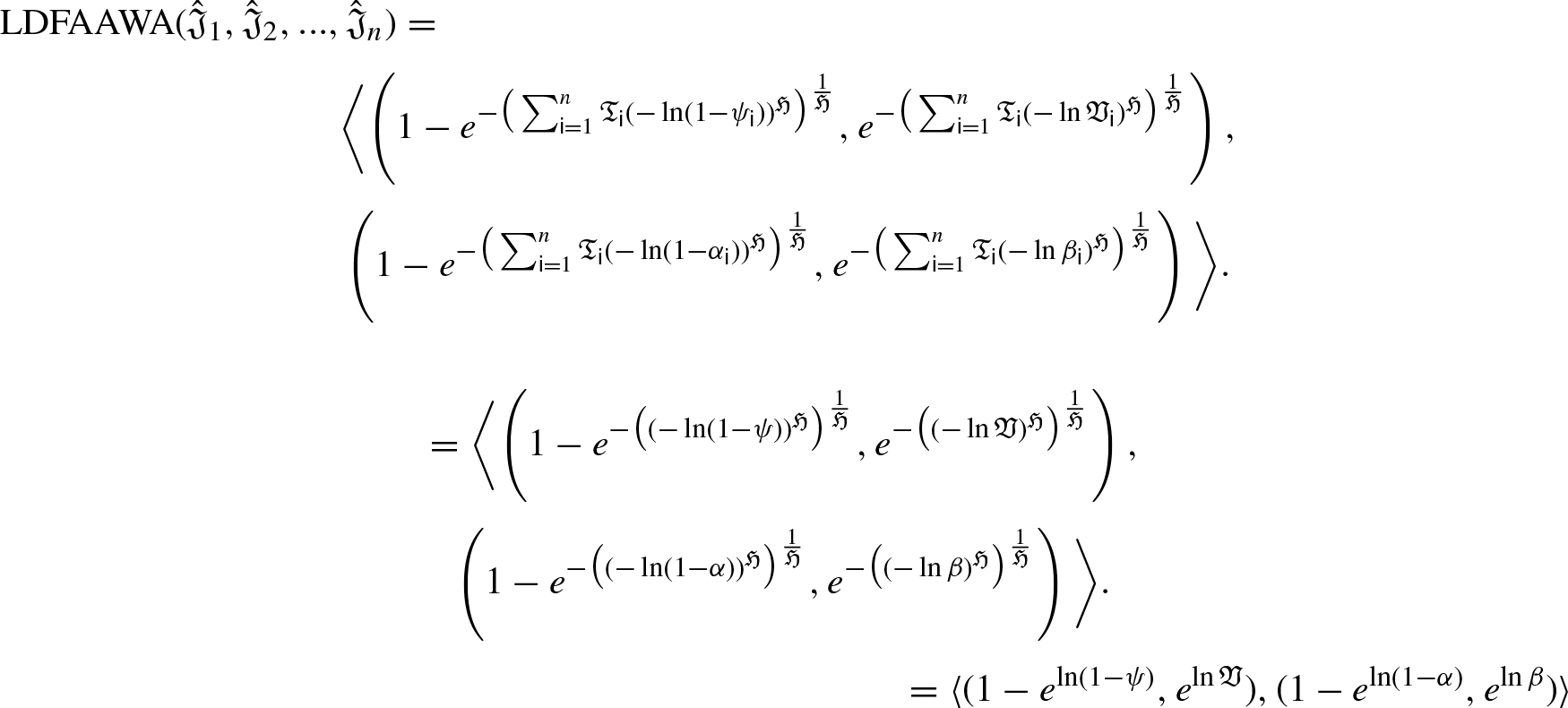
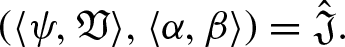
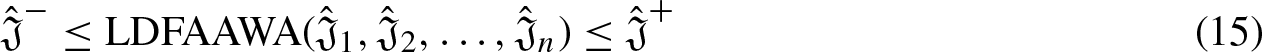
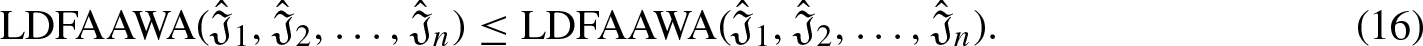
We will now address LDFAA ordered weighted averaging (LDFAAOWA) AO using a few fundamental operations that are defined in Definition 15 in order to maintain the arrangement of the options in order of preference throughout the aggregation process.
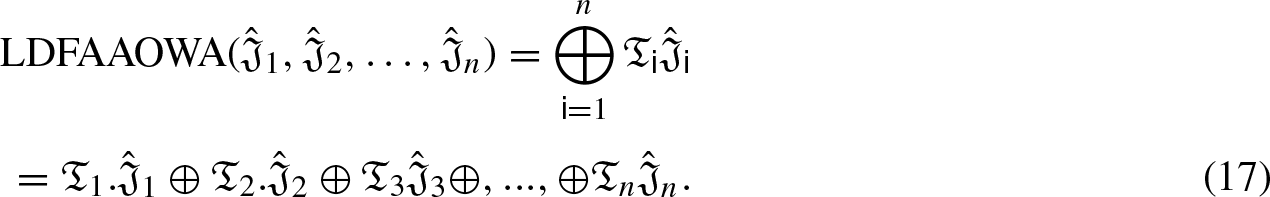
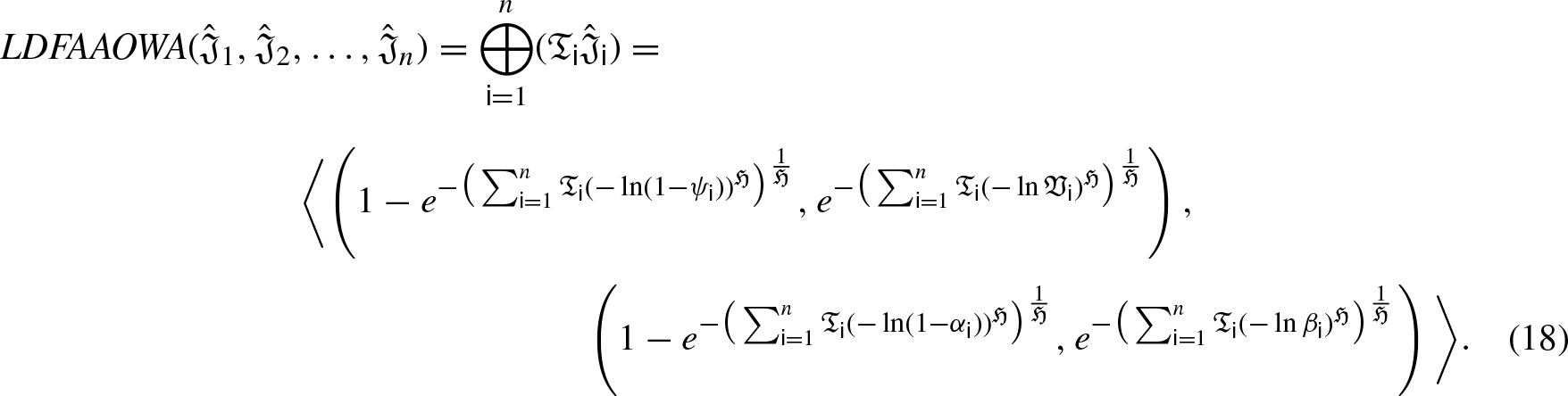
The properties mentioned in Proposition 1, 2, and 3 are analogously satisfied by the LDFAAOWA operator.

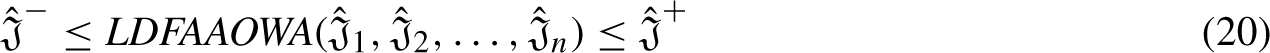

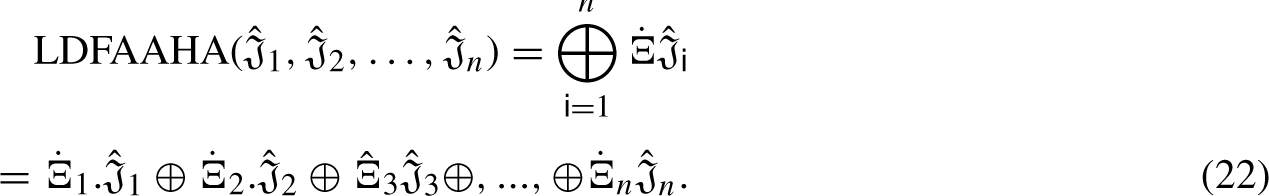
The theorem for the LDFAAHA operator can now be obtained in the manner shown below.
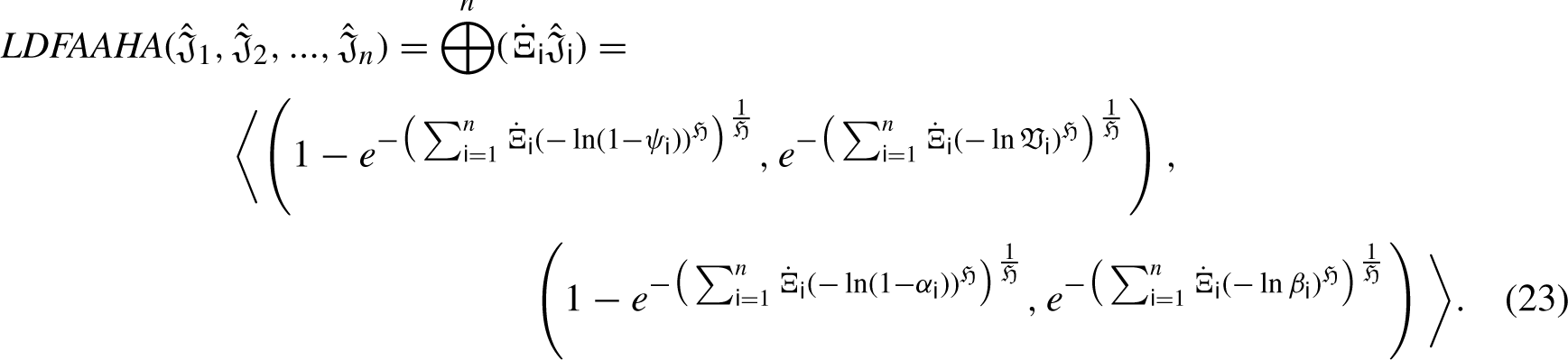

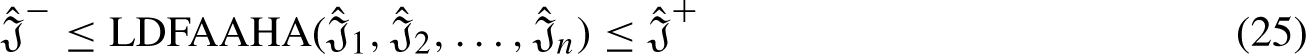
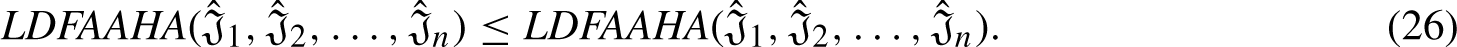


In this paper, Fuzzy clustering algorithms are used in user profiling to group users according to their traits, behaviors, or preferences in a way that permits them to have overlapping memberships in several user groups. Conventional clustering methods allocate each data point (user) to exactly one cluster, but fuzzy clustering, such as fuzzy C-means, allows for partial memberships. This allows users to be part of multiple profiles at once in user profiling, capturing the subtleties and ambiguities in their choices or actions. Fuzzy clustering,
for example, could be used in an e-commerce environment to classify users according to their buying patterns. Instead of strictly fitting into one buyer personal, users may display traits from several buyer personal (such as "luxury seeker," "frequent shopper," or "budget-conscious") to varying degrees. This method recognizes the complexity of user preferences, which allows for tailored recommendations, focused marketing campaigns, or unique user experiences. Businesses can more effectively customize their services and user interactions by using fuzzy clustering for user profiling, taking into account the varied and dynamic nature of consumer behavior. In linear Diophantine equations, the integer variables have linear relationships with one another. Using linear diophantine equations to create mathematical models that represent user characteristics or behaviors could be one way to apply these equations to user profiling. In data-driven user profiling scenarios, however, the traditional method may not be to directly use Linear Diophantine equations for user profiling.
Linear Diophantine equations may not always be used directly in user profiling to cluster or profile users. Alternatively, methods for aggregating or summarizing user preferences or behavior patterns, such as Linear Diophantine Fuzzy Sets or Linear Diophantine Aczel-Alsina aggregation operators, might be taken into consideration. User profiles are located through a clustering procedure following the derivation of the matrix of interest degrees. Every user profile will feature users with comparable interests and browsing patterns. This work used the well recognised Fuzzy C-Means (FCM) clustering approach to arrange vectors bTDSFTDi into overlapping clusters that correspond to user profiles [16].
Proposed method based on LDFAA operators Fuzzy C-Means (FCM) clustering Algorithm
The FCM clustering based on LDFAA algorithm works as follows: Input the LDF data in the form of LDFNs Matrix. Take two matrices of LDFNs in the form of Input the weight vector of the given LDFNs matrix, where, Calculate aggregated values by using LDFAAWA operator. The FCM Algorithms works on LDFAAWA When using fuzzy K-means clustering, a sample’s membership and non-membership can be graded or fuzzy, depending on the cluster’s parameters α, β. Membership and non-membership of LDFAA sample Calculate the cluster centers to find the centroid Find out the distance of each point from the centroid. Updating the membership values and non-membership values and also their parameters. Utilising the anticipated score function (ESF), quadratic score function (QSF), and score function (SF), calculate the score for each characteristic after identifying the resultant set we have Find ranking by using score function, quadratic score function and expected score function. Select the reference set attribute that has the highest score. Flowchart for the Proposed Algorithm. LDF-decision matrix LDF-decision matrix LDFAAWA-decision matrix Membership clusters of visitor ( Non-membership clusters of visitor ( Centroid of the FCM of LDFAAWA Distance of each point from the centroid
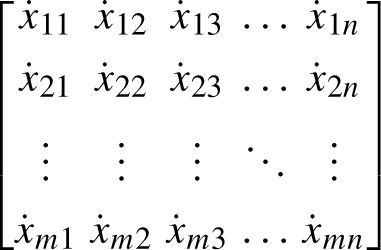
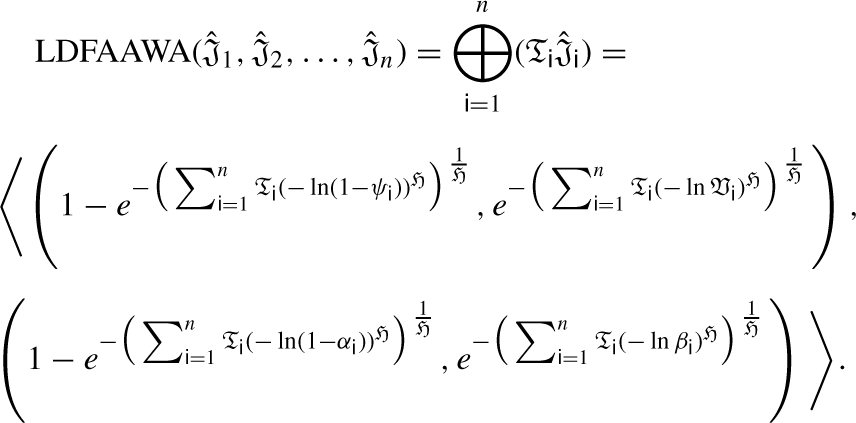
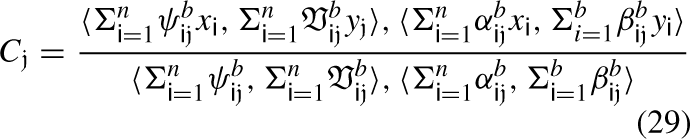
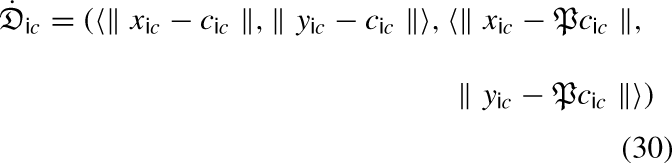
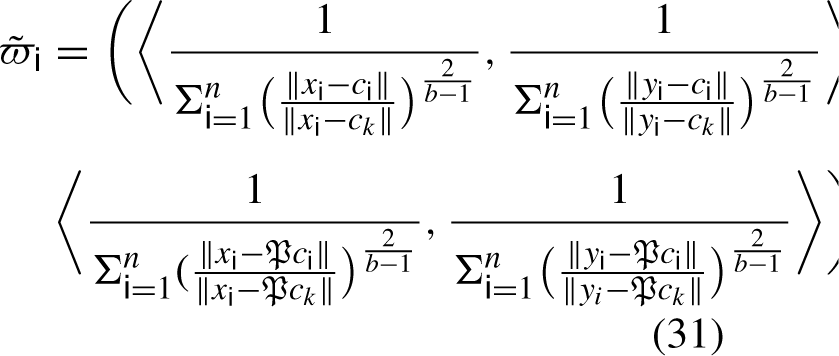
Update membership and non-membership clusters of visitor behaviour
Update membership and non-membership clusters of visitor behaviour
Obtain matrix of LDFNS
Assume that the following values make up the weight vector:
Aggregate the LDF values using LDFAAWA operator given in Table 4.
Using the aggregate matrix of LDFAAWA, Table 4 illustrates how the FCM algorithms operate. The values in Table 4 correspond to the values of website visitors.
We maintained the interest of visitors in the matches, home page, entertainment, and picture in this step. We thus take membership clusters and non-membership clusters, which correspond to the website pages’ descriptions. Because of these clusters, we are able to classify the data in a way that makes sense and shows us which visitors are most interested in each of these different web-page groups. A parameter that in some manner, balances the data and aids in data classification.
Centroid of the clusters vectors are given in Table 7. By using formula of the centroid
We can determine the distance between each cluster point and our internet web-page by utilizing the distance formula Eq (5.2). This step leads us to the profile that has received the most views. Table 8 presents the outcome of utilizing the distance formula for the given data. In this step, we go through user profiling and the child’s interest through the data center
The profile in Table 9 has been updated with the membership and non-membership cluster values.
This step involves computing the score function (SF), quadratic score function, and expected score function. To find these score values, we first developed the proposed method to find the score values of several operators. Next, we proceed to the updated cluster values listed in Table 13. Table 10 provides predicted score values; Table 11 provides operators for quadratic score values; and Table 12 provides expected score values. These score values are highly helpful in determining the final result of any proposed method. In order to determine which profile is most interested, we also use these three scoring functions in our FCM algorithm. This aids in our determination of the most viewed profile.
The score detail under LDFAAWA operator
The score detail under LDFAAOWA operator
The score detail under LDFAAHA operator
Page has the highest level of interest across all four clusters
Determine which score function (SF), quadratic score function (QSF), and expected score function are ranked highest in Table 14. We used our created operators to rank the values. However, Table 15 shows the clusters where visitors view the most profiles after computing the ranking of the interest degree using score values in Table 15. Ranking
Ranking
The Table 14 above that the
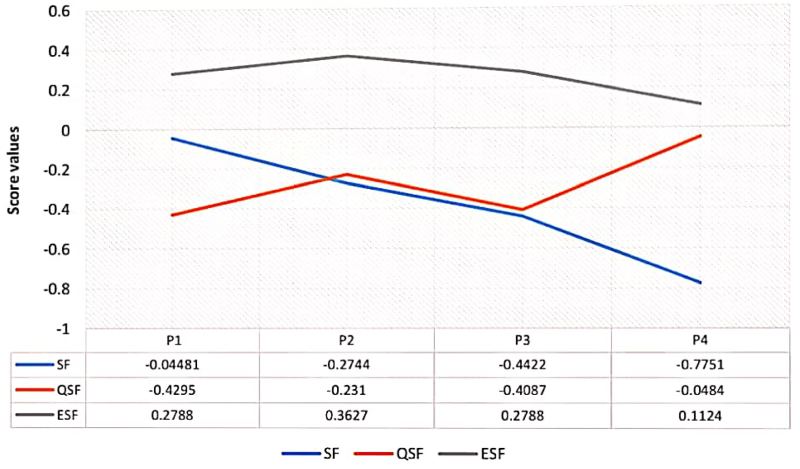
The visual depiction of Table 10.
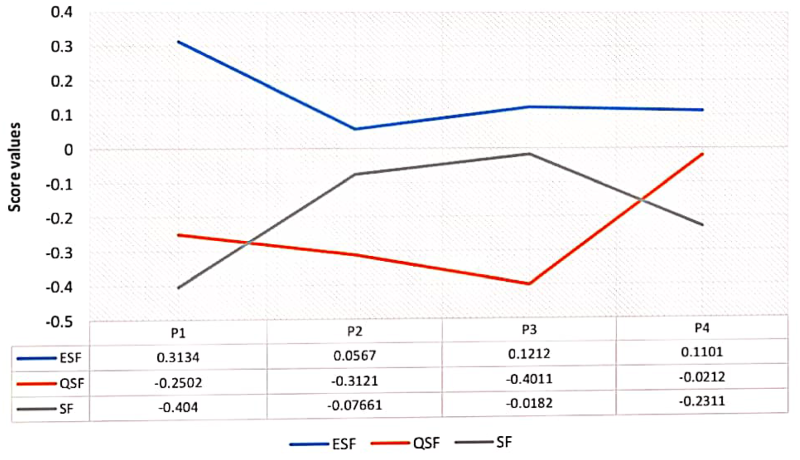
The visual depiction of Table 11.
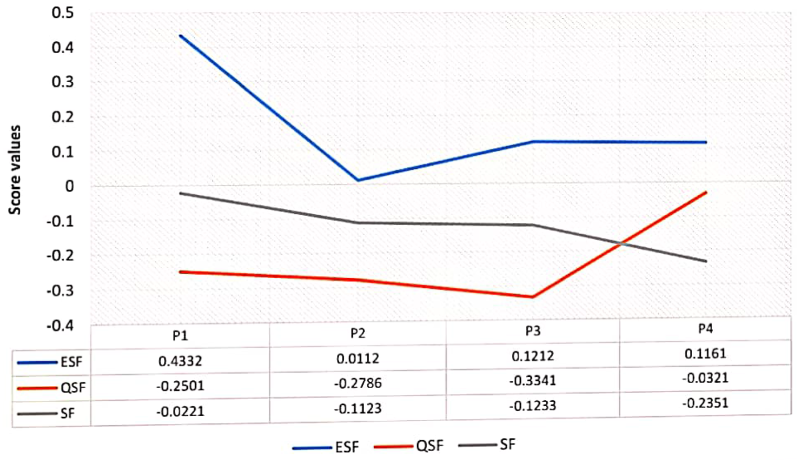
The visual depiction of Table 12.
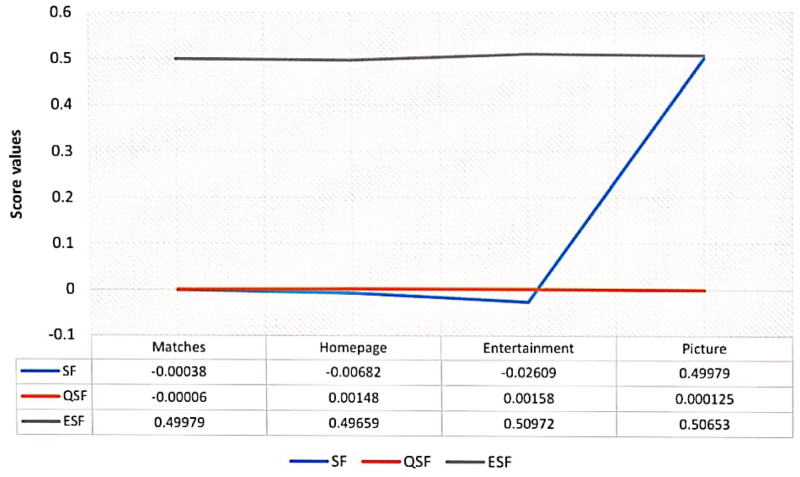
The visual depiction of Table 13.
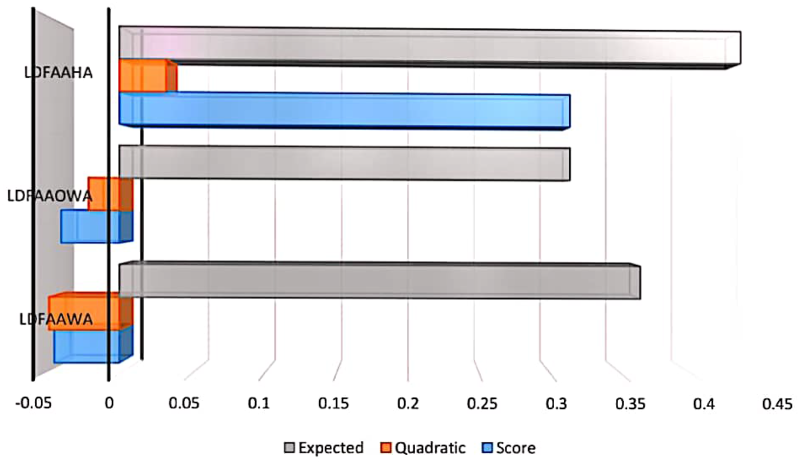
The visual depiction of Table 14.
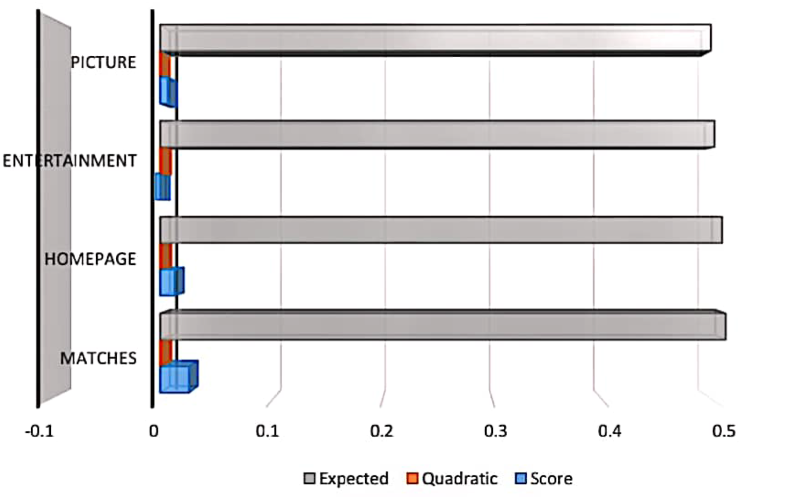
The visual depiction of Table 15.
Comparison analysis
By comparing the performances of the Linear Diophantine Aczel-Alsina aggregation operators with alternative aggregation approaches, comprehensive insights into their individual performances have been achieved. Comparing the outcomes with the particular aggregation operators, we find that there are some significant differences in how we handle vague and unknown data sets. The effusiveness of the Linear Diophantine Aczel-Alsina aggregation operators was demonstrated in certain data types or scenarios, exhibiting specific special features or strengths such as computational efficiency, accuracy, adaptability, etc. On the other hand, other operators demonstrated this in specific contexts. The lovely thing about this structure is that it establishes criteria for categorization based on characterizations and fosters independence between grades that are membership and non-membership. Table 16 compares the aggregation operators that are offered with a few operators that are already in place.
A comparative analysis between the suggested operators and a few legacy operators
A comparative analysis between the suggested operators and a few legacy operators
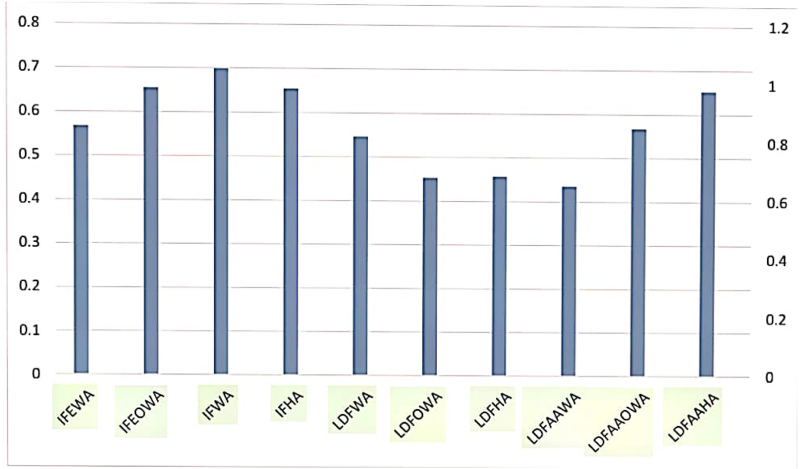
The visual depiction of Table 16.
This is an overview of the experimental settings in which online users are clustered according to their interests using access logs and Fuzzy C-Means (FCM). Access logs from a 15-year-old website intended for younger users. The attributes of each user’s interactions with various website pages (matches, homepages, entertainment, and picture pages) are represented as data points. Choose between random initialization and smart seeding strategies for cluster centroids’ initialization. Dividing the dataset into groups for testing and training in order to assess it. Using the dataset to run the Fuzzy C-Means method, which updates the cluster centroids iteratively and determines membership values, non-membership, and parameters. Adding non-membership values to the FCM process in order to represent user apathy or decreased affiliation with particular clusters, as found in the LDFNS data table. Regulating elements, including pre-processing stages, dataset selection, and algorithm parameters, to ensure consistency. Examining the FCM-obtained clusters for analysis, analysing trends, and determining user groups with specific interests. Using tables and visualisations to present the outcomes of the experiment. FCM may have played a larger part in the creation of more resilient and flexible clustering models by expanding its function in machine learning algorithms, particularly in clustering tasks.
Conclusion
Conclusively, this research has explored the domain of Linear Diophantine Fuzzy sets in relation to Aczel-Alsina aggregation operators, utilising the novel integration with the Fuzzy C-means algorithm. With thorough analysis and empirical experimentation, this work has demonstrated the feasibility and effectiveness of this combination in managing ambiguous and imprecise data in a range of fuzzy systems. We invented the Aczel-Alsina operational laws for the LDF set based on the Aczel-Alsina t-norm and t-conorm. We exposed the LDFAAWA operator, LDFAAO-WA operator and LDFAAHA operator and evaluated their fundamental properties and results. After the evaluation of these operators, we evaluate the problem of user profiling by fuzzy clustering to enhance the worth of the invention. theory. We used a comparative study between the suggested procedures and a few current techniques to demonstrate the superiority and accuracy of the suggested theory.
Adding the Fuzzy C-means algorithm to these aggregating operators improves their accuracy and computational efficiency, offering a practical solution with potential applications in a variety of industries. In the near future, we will employ artificial intelligence in the context of suggested techniques through the use of robots and automation, virtual assistants and chat bots, decision-making and data analysis, individualised learning and training, and neural networks. In order to increase the value of the developed theory, we also intend to alter the suggested methods for a few extensions, such as Generalised linear diophantine fuzzy Aczel-Alsina aggregation operators and Linear diophantine fuzzy Aczel-Alsina Geometric aggregation operators, to improve the worth of the invented theory. On the other hand, to handle ambiguity in the decision-making technique, the described approach can be extended to various kinds of imprecise and ambiguous contexts in future studies. The approach is also applicable to a broad range of research domains, including financial analytics [2], environmental monitoring and sustainability [48], advanced supply chain modelling methods [25] and Internet of Things services [42].
Conflict of interest
About the publishing of the study article, there are no conflicts of interest, according to the authors.
Acknowledgments
Aziz Khan and Thabet Abdeljawad would like to thank Prince Sultan University for paying the APC and support through TAS research lab.