
Abstract
Current mainstream deep learning optimization algorithms can be classified into two categories: non-adaptive optimization algorithms, such as Stochastic Gradient Descent with Momentum (SGDM), and adaptive optimization algorithms, like Adaptive Moment Estimation with Weight Decay (AdamW). Adaptive optimization algorithms for many deep neural network models typically enable faster initial training, whereas non-adaptive optimization algorithms often yield better final convergence. Our proposed Adaptive Learning Rate Burst (Adaburst) algorithm seeks to combine the strengths of both categories. The update mechanism of Adaburst incorporates elements from AdamW and SGDM, ensuring a seamless transition between the two. Adaburst modifies the learning rate of the SGDM algorithm based on a cosine learning rate schedule, particularly when the algorithm encounters an update bottleneck, which is called learning rate burst. This approach helps the model to escape current local optima more effectively.
The results of the Adaburst experiment underscore its enhanced performance in image classification and generation tasks when compared with alternative approaches, characterized by expedited convergence and elevated accuracy. Notably, on the MNIST, CIFAR-10, and CIFAR-100 datasets, Adaburst attained accuracies that matched or exceeded those achieved by SGDM. Furthermore, in training diffusion models on the DeepFashion dataset, Adaburst achieved convergence in fewer epochs than a meticulously calibrated AdamW optimizer while avoiding abrupt blurring or other training instabilities. Adaburst augmented the final training set accuracy on the MNIST, CIFAR-10, and CIFAR-100 datasets by 0.02%, 0.41%, and 4.18%, respectively. In addition, the generative model trained on the DeepFashion dataset demonstrated a 4.62-point improvement in the Frechet Inception Distance (FID) score, a metric for assessing generative model quality. Consequently, this evidence suggests that Adaburst introduces an innovative optimization algorithm that simultaneously updates AdamW and SGDM and incorporates a learning rate burst mechanism. This mechanism significantly enhances deep neural networks’ training speed and convergence accuracy.
Keywords
Introduction
Advancements in hardware technology and deep neural networks have led to the creation of increasingly complex and large-scale models. These models demand more training steps and substantial computational resources. A key element in this process is the optimization algorithm, which plays a crucial role in determining the convergence speed and final accuracy of the models. This is in addition to the quality of the dataset and the design of the model itself.
Current optimization algorithms [1–6] for deep neural networks [7–16], such as non-adaptive algorithms like Stochastic Gradient Descent (SGD) [17, 18] and adaptive algorithms like Adam [19], are fundamental to the training process. However, they often face a trade-off: adaptive algorithms typically enable faster convergence, whereas non-adaptive algorithms tend to ensure greater convergence precision. This trade-off poses a dilemma between training efficiency and effectiveness, especially in mainstream deep neural networks and generative models.
In practical training scenarios, especially for generative models where the end of training is not necessarily determined by a final convergence point but rather by a predefined number of training steps, both the quick convergence of adaptive optimization algorithms and the high convergence precision of nonadaptive optimization algorithms are vital. Consequently, it becomes imperative for adaptive optimization algorithms to demonstrate a faster rate of convergence.
The Adaburst algorithm, introduced in this paper, effectively addresses these challenges. It uniquely combines the updates of adaptive and non-adaptive algorithms, ensuring continuity in the update process. This integration achieves rapid convergence with precision. While newer versions of adaptive optimization algorithms like AdaDB [20] are available, mainstream deep neural networks—including discriminative models like ResNet [21] and Vision Transformer (ViT) [22], as well as generative models like VQGAN [23] and Stable Diffusion [24]—still predominantly use AdamW as their preferred training optimization algorithm. Hence, Adaburst integrates AdamW [25] and SGDM as its foundational algorithms. Additionally, drawing inspiration from the simulated annealing technique, Adaburst innovatively increases the learning rate during updates, aiding in overcoming local optima, a common issue in existing methods.
Existing research has explored automatic switching and combining the benefits of both types of algorithms through optimization techniques. Notable examples include SWATS [26] and ADABOUND [27]. SWATS switches to SGDM upon reaching a specific threshold, whereas ADABOUND progressively restricts the maximum updates. In comparison, the Adaburst algorithm features a continuous update process, circumventing the non-convergence issues associated with the SWAT transition. This instability during switching, particularly in large-scale neural networks such as diffusion models [28], can result in suboptimal outcomes. The learning rate burst mechanism in Adaburst specifically addresses the issue of becoming trapped in local optima in algorithms like ADABOUND. The paper’s contributions are outlined as follows: By overlaying the updates of AdamW and SGDM, the algorithm benefits from the speed of adaptive optimization and the generalization ability and convergence precision of non-adaptive optimization. Throughout the update process, by stacking the updates of SGDM and AdamW, the non-convergence issue caused by switching algorithms midway is solved. Inspired by the simulated annealing algorithm, a method to increase the learning rate during updates, enabling the model to achieve superior generalization capabilities and final accuracy, is designed.
This paper is organized as follows: The Related Work section introduces the two foundational algorithms of Adaburst, AdamW and SGDM, detailing their specific algorithmic processes. The Model Architecture section provides details of the learning rate burst method and specific update steps of the Adaburst algorithm. The Experiments section presents the specific hyperparameter settings and tests Adaburst on the MNIST, CIFAR-10, CIFAR-100, and DeepFashion datasets. The Limitations section discusses the remaining flaws of the algorithm.
This section delves into adaptive and non-adaptive optimization algorithms, particularly highlighting AdamW and SGDM, which form the foundation of Adaburst proposed in this paper through their integration.
SGDM (Stochastic Gradient Descent with Momentum) is a widely used algorithm in deep neural network training. Initially, gradient descent (GD) was the basic non-adaptive, gradient-based optimization method. However, GD had significant drawbacks, notably its inefficiency. In GD, all parameters are adjusted in each iteration based on the gradient, making the training process highly susceptible to local optima. Furthermore, its back-propagation process during training can be markedly slow. To address these issues, two advanced methods were developed: Batch Gradient Descent (BGD) and Stochastic Gradient Descent (SGD). BGD updates parameters after processing the entire training set once. However, this method has become impractical with the increasing size of training datasets. In contrast, SGD divides the training set into smaller batches and updates parameters after each batch, improving training efficiency. Subsequent enhancements, including the addition of momentum and weight decay, have evolved SGD into its current form, SGDM. This evolution reflects a continual effort to overcome the limitations of traditional optimization methods and enhance model training effectiveness.
1: m0 ← 0 ⊳ initialize moment vector
2: t ← 0 ⊳ initialize time step
3:
4: t ← t + 1
5: θ t ← θt-1 - θt-1 · D ⊳ weight decay
6: g t ← ∇ θ f t (θt-1) ⊳ Get gradients
7: m t ← M · mt-1 + g t
8: θ t ← θ t - lr · m t ⊳ Upgrade parameters
9:
10:
Most of the optimization algorithms that emerged during the preliminary development stage were based on smoothing of gradient and square of gradient. In this evolutionary line, Adagrad, which can be considered as the starting point, was based on the smoothing of the square of the gradient. The transition from Adagrad to RMSprop changed the way of gradient squared accumulation so that the update step did not decrease continuously with the time of updates. Adam combined SGDM with RMSprop, adding the accumulation of gradients and smoothing both gradients and gradient squares.
AdamW had a significant advantage over SGDM regarding model training speed and did not differ too much from SGDM regarding final accuracy. The proposers of AdamW found that the commonly used L2 regularization [29] for avoiding model divergence did not play the same role in AdamW as it did in SGDM. The effectiveness of the algorithm was significantly improved by using a functionally similar weight decay [30] instead of L2 regularization. Besides, AMSGrad is another algorithm to correct the possible learning rate increase of AdamW, whose performance is hardly demonstrated in practical applications. Thus, AdamW is still the mainstream choice for researchers.
1: m0 ← 0 ⊳ initialize 1st moment vector
2: v0 ← 0 ⊳ initialize 2nd moment vector
3: t ← 0 ⊳ initialize time step
4: ϵ ← 0.0001 ⊳ Prevent denominator from zero
5:
6: t ← t + 1
7: θ t ← θt-1 - θt-1 · D ⊳ weight decay
8: g t ← ∇ θ f t (θt-1) ⊳ Get gradients
9: m t ← β1 · mt-1 + g t ⊳ 1st moment
10:
11:
12:
13:
14:
15:
The approach of integrating adaptive and non-adaptive optimization algorithms is exemplified by the method known as SWAT [26]. The fundamental concept of SWATS involves initiating the training process with the adaptive learning rate features of AdamW. Subsequently, the method transitions to using Stochastic Gradient Descent with Momentum (SGDM) upon meeting predefined criteria.
The criterion for transitioning in SWATS is specified as follows:
λ
k
is the dynamically estimated learning rate for SGD, updated as: λ
k
= β2λk-1 + (1 - β2) γ
k
. γ
k
measures the difference between the update direction p
k
and the current gradient g
k
, computed as: β2 is the decay factor for the second moment estimation in AdamW and k is the iteration number. ϵ is a small positive threshold.
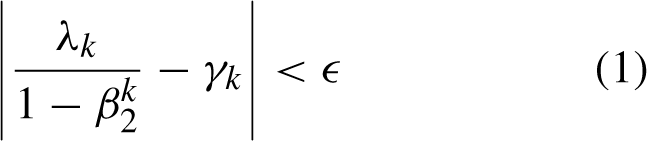
Once the switching condition is satisfied, SWATS transitions to SGDM with the learning rate Λ set as:

It’s worth noting that during the switching process of SWAT, the accumulation of the first and second moments from the previous AdamW iterations is completely discarded, which might lead to non-convergence issues.
Previous experiments have demonstrated that employing SWAT [26] to alternate between SGDM and AdamW in the training of large-scale models, such as diffusion models, often failed to converge. Additionally, in the context of training discriminative models, executing the switch too late in the training process fails to yield significant improvements in the outcomes. These observations lead to the formulation of several hypotheses: the divergence in update paths between SGDM and AdamW renders mid-training switching impractical, and AdamW’s limited efficacy in escaping local optima hampers further optimization of the model towards the latter stages of the update process.
The analysis underscores the necessity for an algorithm that not only concurrently updates both SGDM and AdamW but also possesses the capability to escape local optima towards the end of the training process. The proposed Adaburst algorithm addresses this requirement. Adaburst calculates and merges updates from SGDM and AdamW through summation during its update cycle.
1: Tcur ⊳ current step
2: φ ⊳ final result
3: if ς = = True
4: Tcur = 1
5:
7: Tcur ← Tcur + 1
8:
Require Lrburst (): learning rate burst algorithm
1: m0 ← 0 ⊳ initialize 1st moment vector
2: v0 ← 0 ⊳ initialize 2nd moment vector
3: t ← 0 ⊳ initialize time step
4: A ← 0 ⊳ initialize AdamW’s update
5: S ← 0 ⊳ initialize SGDM’s update
6: ϵ ← 0.0001 ⊳ Prevent denominator from zero
7:
8: t ← t + 1
9: θ t ← θt-1 - θt-1 · D ⊳ weight decay
10: g t ← ∇ θ f t (θt-1) ⊳ Get gradients
11: m t ← β1 · mt-1 + g t ⊳ 1st moment
12:
13:
14:
15:
16: lr2 ← lr · Lrburst ()
17: S ← m t ⊳ SGDM’s update
18: θ t ← θ t - lr1 · A - lr2 · S ⊳ Upgrade parameters
19:
20:
In our method, a distinctive burst mechanism is implemented to enhance the learning rate when a particular model metric reaches a plateau. This approach is inspired by the principles of simulated annealing, incorporating a cosine annealing scheme. The efficacy of the model is evaluated using the accuracy of the training set. If there is no improvement in the model’s accuracy during recent epochs, the current step of reducing the learning rate to zero through cosine annealing is restarted. It is important to note that the selection of model metrics is adaptable and may differ according to the specific requirements of the task. The details of this learning rate scheduling method are outlined in Algorithm 3.
Integrating the aforementioned Lrburst algorithm to merge AdamW and SGDM, we obtain the proposed Adaburst algorithm, as shown in Algorithm 4. Adaburst reuses the first-order moment accumulation of AdamW, avoiding resource wastage due to redundant calculations.
Experiments
In this section, the effectiveness of the proposed Adaburst optimization algorithm is evaluated across a range of datasets. Initially, the algorithm undergoes a dimensionality reduction analysis, which includes scrutinizing the update quantities during training. The algorithm’s performance is then assessed by training Convolutional Neural Networks (CNNs) on the MNIST and CIFAR-10 datasets. This assessment involves a comparative analysis with the AdamW and SGDM algorithms. Following this, analogous comparative experiments are conducted on the CIFAR-100 dataset, employing the same algorithms. For these experiments, the more advanced Vision Transformer (ViT) [22] model is utilized, to better gauge the algorithm’s efficacy in diverse contexts. In addition to tests on discriminative models, the Adaburst algorithm is further evaluated using complex generative diffusion models with the Deepfashion dataset.
The hyperparameters for the Adaburst algorithm, which hold practical implications similar to those for AdamW and SGDM, are deliberately aligned with the latter to underscore Adaburst’s unique attributes. The hyperparameters employed in these experiments are detailed in Table 1. These hyperparameters are chosen following the conventional settings of the PyTorch deep learning framework, as cited in [31]. Furthermore, Table 2 delineates the specific conditions under which learning rate burst is triggered for various tasks.
Hyperparameters
Hyperparameters
Timing to trigger lr burst
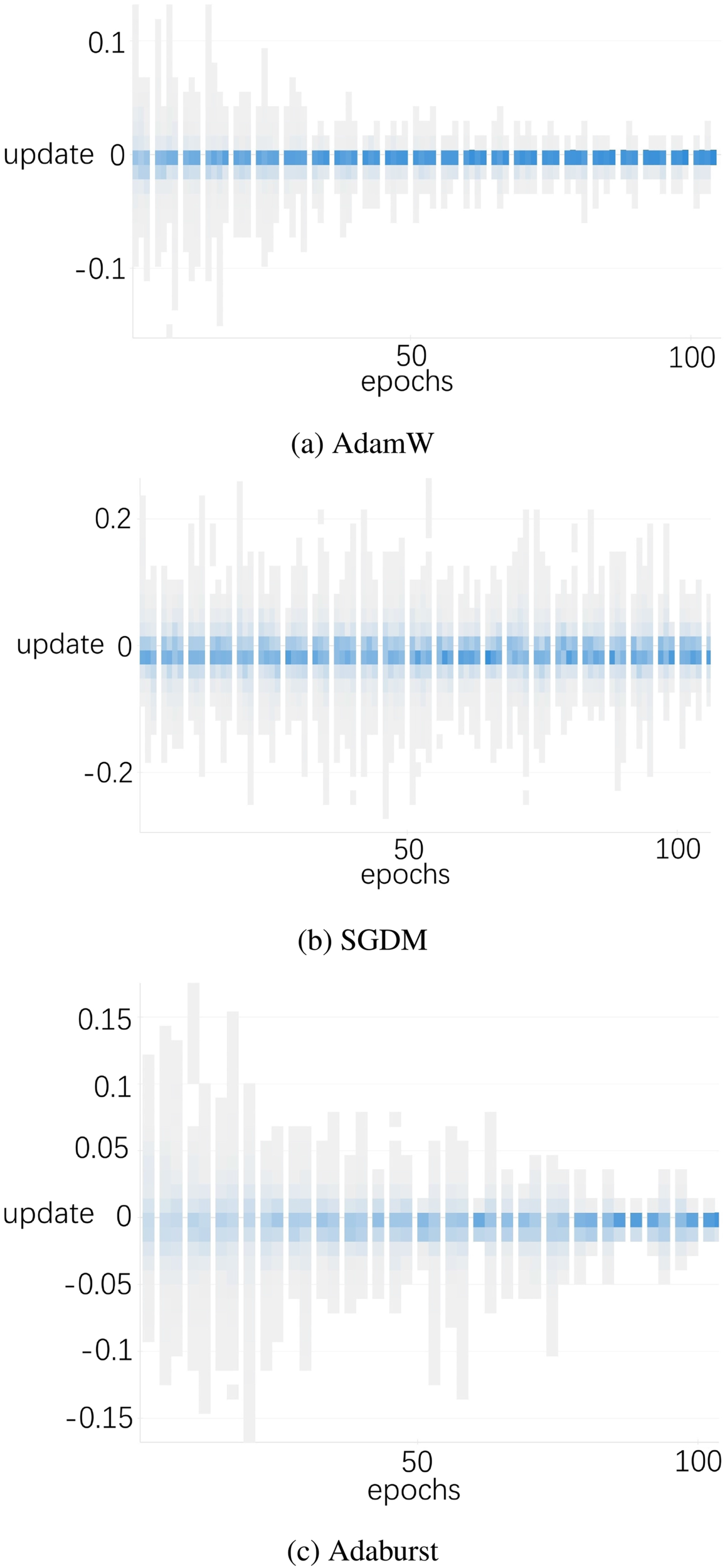
Dimensionality reduction analysis.
Taking the experiment on the CIFAR-10 dataset as an example, a dimensionality reduction is conducted. The analysis of the training process on the CIFAR-10 dataset involves collecting the parameter update quantities for all convolutional layers. The quantities of different layers in the same epoch are then averaged, with the results presented in Fig. 1. The horizontal axis in this figure denotes the number of epochs, while the vertical axis represents the updated amount. It is revealed that during the initial phase, the Adaburst algorithm exhibits a wider search range. Furthermore, it effectively mitigates oscillations post-convergence in the later stages of training.
MNIST
This section presents a comparative analysis of the Adaburst algorithm against the well-established SGDM and AdamW. The experiments are conducted on the ResNet framework, a prominent CNN model, using the MNIST dataset [32]. The dataset consists of 70,000 handwritten digit images, divided into 60,000 training images and 10,000 testing images. As an image classification dataset, the MNIST dataset exclusively comprises black and white images, thereby offering reduced input dimensionality. ResNet, recognized as the most prevalent CNN model [21], is the primary network used for a vast array of image processing tasks. The experiments conducted in this study span 200 epochs.
The experimental procedure for each epoch is structured as follows: Firstly, the dataset was segmented into small batches, each containing 128 samples. Secondly, after completing the training for each epoch, the resulting CNN model was evaluated on the testing set concurrently with the training process. It is important to note that no training method correlating precision increase with update necessity was utilized.
In this experimental study, the performance of the proposed Adaburst algorithm is juxtaposed with that of SGDM and AdamW. Additionally, RMSProp and Adam were initially included in the experiments. However, their performance markedly lagged behind the other two algorithms, leading to their exclusion to maintain clarity in the visual representation of results in figures and tables.
The comparative analysis of test results from the training set is depicted in Fig. 2. For a more direct assessment of model training speed and final convergence accuracy, refer to Table 3. The analysis reveals that on simpler datasets like MNIST, Adaburst demonstrates enhanced stability in the final stages of convergence, compared to SGDM and AdamW. Notably, surpassing the training set accuracy of SGDM suggests that the model retains its generalization capabilities, avoiding entrapment in local optima.
Experimental data on MNIST
Experimental data on MNIST

Comparison experiments on MNIST.
This segment highlights the performance of the proposed Adaburst algorithm compared to other optimization algorithms, utilizing the ResNet model. The CIFAR-10 dataset, employed for this evaluation, consists of 60,000 images (32 × 32 RGB), divided into 50,000 for training and 10,000 for testing, across 10 classes with 6,000 images each [33].
The ResNet model underwent training over 200 epochs, with its performance assessed against the testing set after each epoch. The differences between the three optimization algorithms, including Adaburst, are illustrated in Fig. 3, which depicts results from the training process. Notably, Adaburst exhibited an enhanced rate of accuracy improvement for the training set at the onset of training, as well as a higher final accuracy at the end of the training period, as shown in Table 4. The results indicate that Adaburst’s more aggressive initial update strategy led to quicker initial training speeds. This approach also facilitated reaching a more effective extremum, thereby improving both training and testing accuracy.
Experimental data on CIFAR-10
Experimental data on CIFAR-10
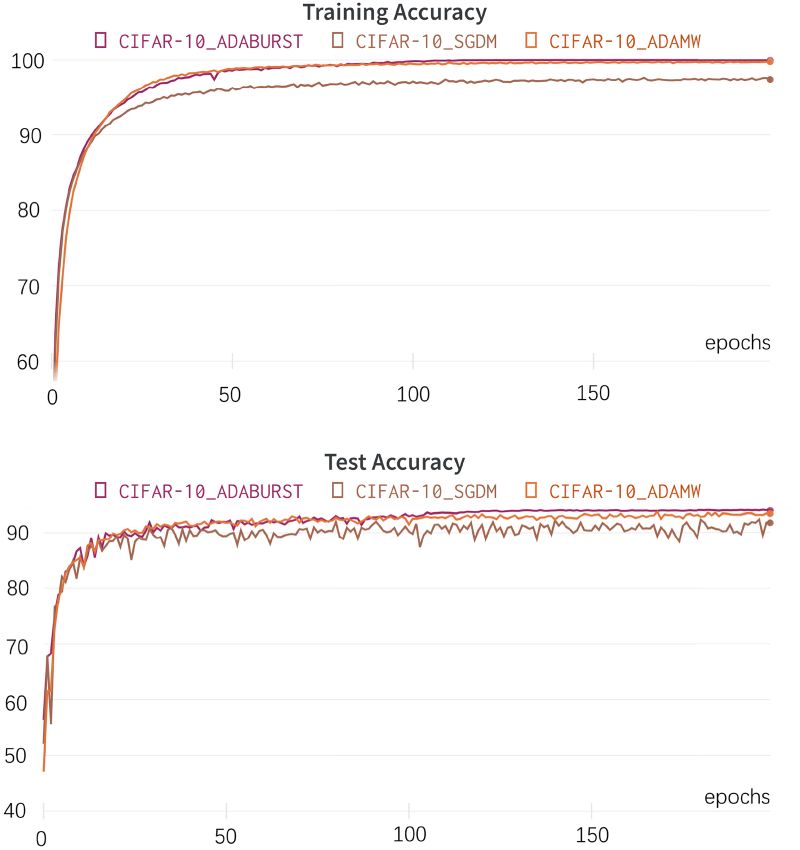
Comparison experiments on CIFAR-10.
This segment outlines a comparative analysis of our Adaburst algorithm against SGDM and AdamW, using the challenging CIFAR-100 dataset. CIFAR-100 comprises 50,000 training and 10,000 testing images, distributed across 100 subclasses. Each subclass contains 600 RGB images of 32 × 32 size. Compared to the previously discussed datasets, CIFAR-100 poses a greater challenge due to its increased number of classifications without a corresponding increase in sample size, resulting in fewer samples per classification [34].
To address this challenge, the VIT-Tiny model was utilized. This model is a scaled-down version of the standard Vision Transformer (ViT) with a parameter count comparable to ResNet-34. VIT-Tiny, built entirely on the Transformer architecture without convolutional operations, relies solely on attention mechanisms. This design offers improved stability and proves particularly effective for classification tasks like CIFAR-100, where each class has a limited number of samples.
The performance disparities among the optimization algorithms are more pronounced in the CIFAR-100 dataset, as shown in Fig. 4. These findings suggest that Adaburst surpasses SGDM and AdamW, especially as dataset complexity increases. Table 5 presents specific evaluation metrics for this experiment. The advantages of Adaburst were particularly notable in this context. With the CIFAR-100 dataset’s increased complexity and the model’s sophisticated structure, the optimization process encounters more challenges, such as a greater number of local optima due to more categories with fewer images per category. While AdamW led in training set accuracy over SGDM, it demonstrated poorer performance on the test set, indicating susceptibility to local optima and overfitting. In contrast, Adaburst effectively circumvented these issues, achieving superior final convergence accuracy.
Experimental data on CIFAR-100
Experimental data on CIFAR-100
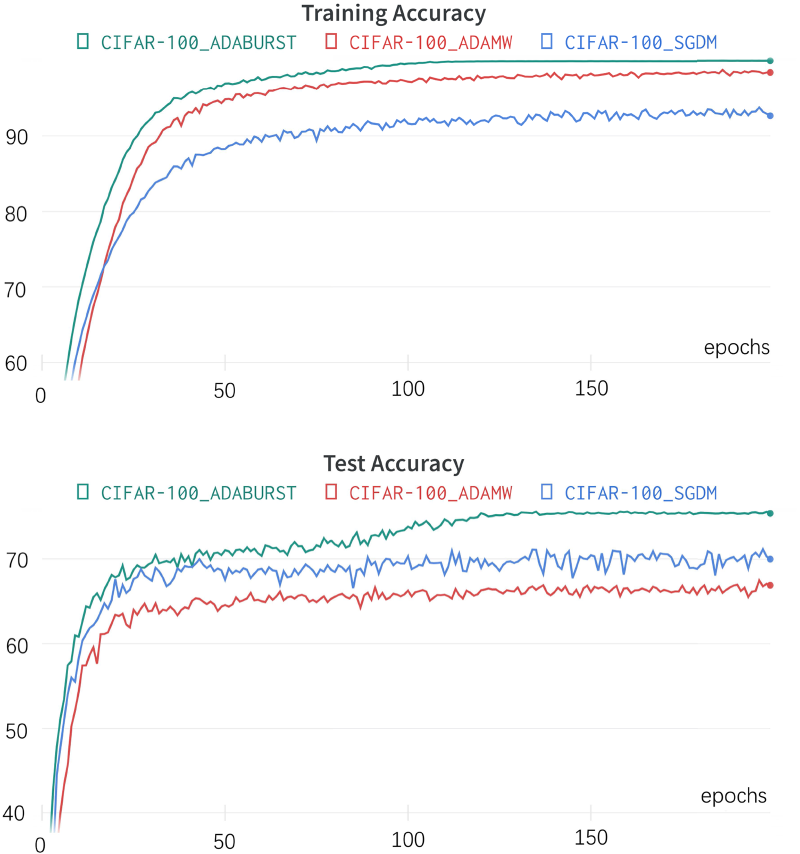
Comparison experiments on CIFAR-100.

Experiments on DeepFashion.
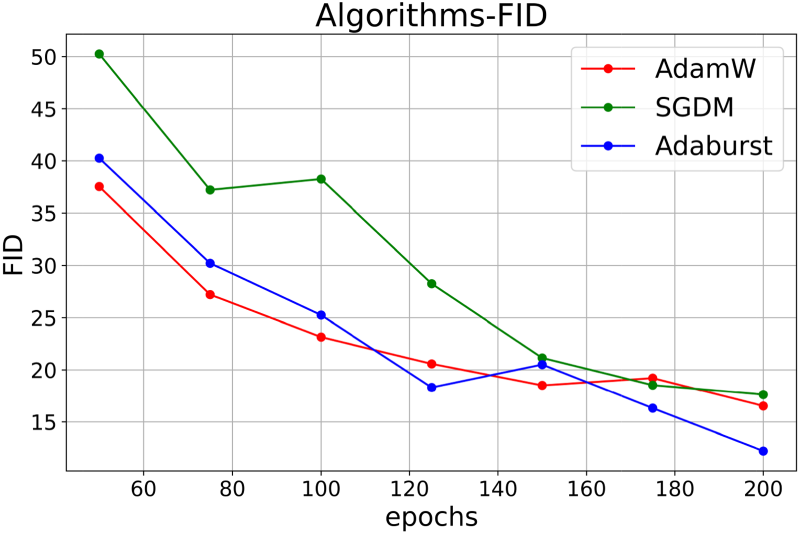
Changes in FID During the Training Process with Different Optimization Algorithms.
The DeepFashion dataset [35] is a comprehensive collection of images featuring individuals in various clothing styles, making it a valuable resource for research in human image generation. It includes a total of 289,222 images, categorized into 50 clothing categories and 1,000 clothing attributes. The unique aspect of this dataset is the presence of images of the same individual in different styles, which is particularly useful for generation tasks.
Diffusion models [28], which represent the latest advancements in image generation, transform the conventional one-step generation process into a multi-step denoising procedure. This approach significantly enhances the quality of generated images compared with GANs [36] and VAEs [37]. Utilizing these diffusion model principles, human image generation is conducted on the DeepFashion dataset. This application serves to demonstrate the stability of our algorithm when applied to larger models [38].
The experimental results are depicted in Fig. 5. Given the distinctive characteristics of generative models, it is necessary to selectively choose epochs to assess the effectiveness of the training accurately. The Frechet Inception Distance (FID) [39], a standard image quality assessment metric, is used for this purpose, where a lower FID value indicates higher image quality. The outcomes are shown in Fig. 6.
In comparison with the other two algorithms, Adaburst shows a significant improvement in training speed. By the 125th epoch, the model achieves high-quality generative effects. This acceleration means that in experiments conducted on four RTX 4090 graphics cards, the training duration can be reduced by approximately 30 hours from a total of 120 hours.
Ablation study
Experiments utilizing the SWAT [26] training methodology were initially performed on diffusion models to assess the feasibility of direct switching. The learning rate and other hyperparameters applied in these experiments were derived from parameters commonly used in SGDM-related studies. The decision on when to implement the switch adhered to the schedule specified in the foundational paper, selecting the variant alternating between AdamW and SGDM. The outcomes, as depicted in Fig. 7, unequivocally reveal a pronounced occurrence of blurring, thereby substantiating the impracticality of direct switching between these optimization algorithms in the context of training diffusion models.

Experiments of SWAT Algorithm on DeepFashion.
Ablation study of Adaburst
Additionally, to further validate the effectiveness of the algorithm’s various components, ablation studies were conducted. These studies focused on key elements of the algorithm: the learning rate burst and the integration of SGDM with AdamW. For comparison, three baseline groups were established: (1) Integration of SGDM and AdamW only; (2) Combination of SGDM with learning rate burst; (3) Combination of AdamW with learning rate burst. All experiments adhered to the hyperparameters detailed in previous sections and underwent training over 200 epochs. The evaluation criterion was the final convergence test set accuracy. Results, as presented in Table 6, demonstrate the individual contributions of each component to the algorithm’s performance. The experiment shows that the combination of AdamW and the learning rate burst mechanism does not produce a significant effect, confirming the rationale of using this mechanism exclusively with SGDM.
Adaburst has achieved better results than SGDM and AdamW across multiple datasets, but it still has some shortcomings. One notable drawback is the complexity of the hyperparameter setting. Adaburst necessitates not only the configuration of standard hyperparameters but also the determination of appropriate timing for the learning rate burst trigger. This additional requirement complicates the process of hyperparameter tuning, presenting a challenge in its practical application.
Furthermore, the learning rate burst mechanism in Adaburst encounters inefficiencies in specific contexts. This inefficiency arises primarily because the initial phases of elevated learning rates can lead to suboptimal training outcomes. Terminating training during these phases could potentially diminish the model’s final accuracy.
Conclusion
The manuscript concentrates on the evaluation of optimization algorithms, specifically AdamW and SGDM, aiming to improve both convergence speed and final accuracy. It presents computational comparisons of these algorithms, demonstrating accelerated training speeds in the initial phases. The introduction of a new technique, termed ’learning rate burst,’ draws inspiration from simulated annealing. This approach is designed to overcome the challenge of stagnation in updates following a switch between algorithms. The paper introduces ‘Adaburst,’ an algorithm developed by amalgamating these strategies.
Moreover, by reutilizing AdamW’s parameters for a combined update with SGDM, Adaburst avoids the need for additional storage space. This integration entails no extra computations beyond those in AdamW, except for the incorporation of weight planning for both algorithms. Consequently, there is no escalation in space complexity, and the rise in time complexity remains negligible.
Finally, Adaburst is compared with SGDM and AdamW across MNIST, CIFAR-10, and CIFAR-100 datasets using ResNet and VIT architectures. Results suggest Adaburst’s superiority over SGDM and AdamW in terms of both convergence speed and final accuracy. Further experiments with the Deepfashion dataset using diffusion models validate Adaburst’s efficacy in more complex scenarios.
The Adaburst algorithm, which incorporates a fundamental learning rate burst mechanism, effectively combines elements of two distinct algorithms. This feature unveils the potential for performance enhancement via algorithmic substitutions, underscoring the algorithm’s versatility. Moreover, the simplicity of its learning rate burst mechanism, along with its easily definable activation conditions, offers promising avenues for future research. These include optimizing the timing, form and recovery process of the burst mechanism.
Footnotes
Acknowledgement
This research was funded by the Key Research and Development Project of China State Railway Group Company Ltd., under Grant Number [N2021G004].