
Abstract
Recently, huge progress has been achieved in the field of single image super resolution which augments the resolution of images. The idea behind super resolution is to convert low-resolution images into high-resolution images. SRCNN (Single Resolution Convolutional Neural Network) was a huge improvement over the existing methods of single-image super resolution. However, video super-resolution, despite being an active field of research, is yet to benefit from deep learning. Using still images and videos downloaded from various sources, we explore the possibility of using SRCNN along with image fusion techniques (minima, maxima, average, PCA, DWT) to improve over existing video super resolution methods. Video Super-Resolution has inherent difficulties such as unexpected motion, blur and noise. We propose Video Super Resolution – Image Fusion (VSR-IF) architecture which utilizes information from multiple frames to produce a single high- resolution frame for a video. We use SRCNN as a reference model to obtain high resolution adjacent frames and use a concatenation layer to group those frames into a single frame. Since, our method is data-driven and requires only minimal initial training, it is faster than other video super resolution methods. After testing our program, we find that our technique shows a significant improvement over SCRNN and other single image and frame super resolution techniques.
Keywords
SRCNN uses a single LR image as input to produce the final HR image. f1, f2, f3 are the filter sizes for the respective convolutional flayers. C is the number of channels in the image (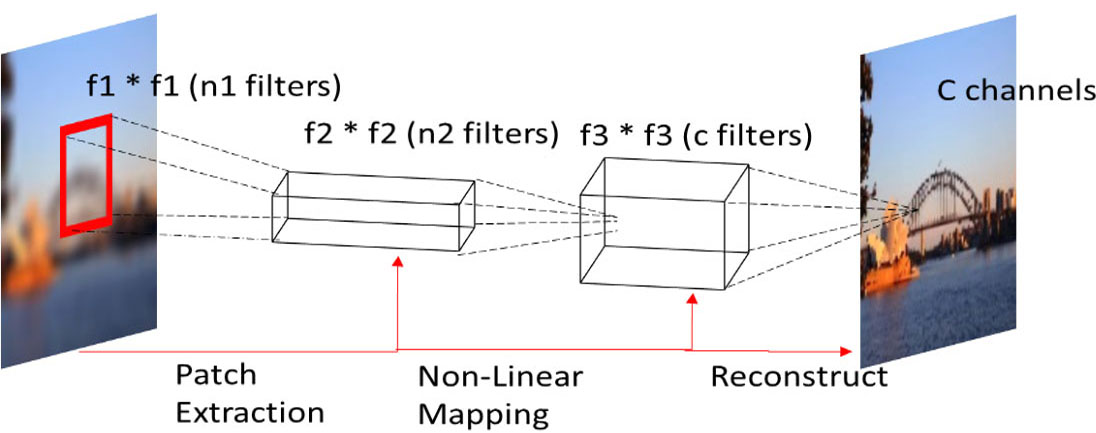
Super Resolution (SR) is a subset of image processing problems where High Resolution images are expected to be reconstructed based on downscaled Low resolution images. Image Super-Resolution is a technique where a low-resolution image is converted into a high resolution image. Before 2014, it was done using Bayesian methods or sparse coding methods [1, 2]. The Bayesian marginalization resulted in the reduction of the degree of entropy found in determining imaging parameters like point spread function, warping and lighting conditions. The process resulted in the better estimation of a high resolution image. However, convolution neural networks (CNN) have proven to be effective in single-image super resolution [3, 4, 5, 7]. The idea behind using CNN is to train it using low resolution (LR) and high resolution (HR) image pairs. In the training, phase CNN learns how to map multiple LR pixel information into a single HR pixel. Using the same idea, we propose a video super-resolution technique. Instead of using multiple pixels to obtain a single HR pixel, we use multiple LR video frames to obtain a single HR frame. Similarly, videos can be depicted as a series of frame where each frame may be defined as an image, thus creating the potential for video super resolution. Video resolution, however poses to be more complex in nature due to the additional parameters which need to be considered, like motion transitions, rapid change in lighting, blur and frame rate.
SRCNN (Super Resolution Convolution Neural Network) is used for augmenting the resolution of single images. However, SRCNN proves to be mildly ineffective when used for videos. In videos, we come across problems such as quick motion, blur and noise. Since, SRCNN is trained on single images, it cannot perform motion estimation.
Through this manuscript we have proposed a method VSR-IF (Video Super-Resolution – Image Fusion) which uses adjacent frames of video to estimate motion and reduce noise in the output image. Image Fusion Techniques (PCA, DWT, Average, Minimum, Maximum) are used to perform a fusion between multiple images. While using VSR-IF, we observe an increase in PSNR (Peak Signal Noise ratio) when compared to SRCNN or Draft-CNN.
The rest of the manuscript has been arranged as follows: Section 2 includes a comprehensive survey on the existing work in image and video SR (Super-Resolution). Section 3 includes the description of the reference model (SRCNN). Section 4 includes the description of the proposed architecture (VSR-IR). Section 5 includes the results of different combinations of hyper-parameters for VSR-IR. Section 6 includes result comparison with different video and image SR techniques.
A shows sample high-resolution image and the resulting image after down-sampling using bicubic interpolation (2x, 3x and 4x). B shows the result of down-sampling in adjacent video frames from VidData.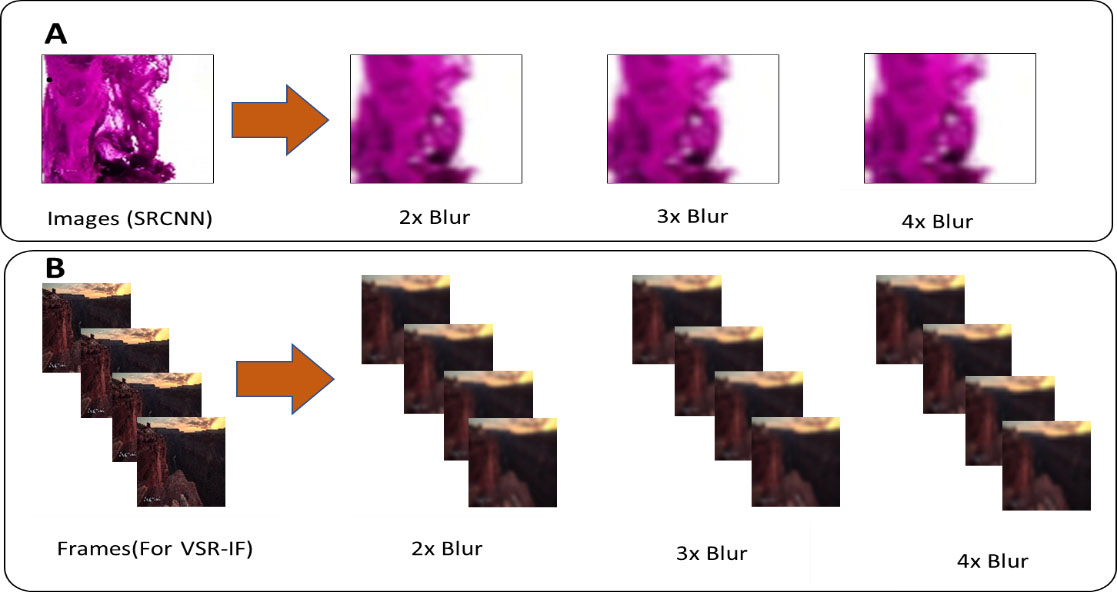
The first major breakthrough in single-image super resolution was sparse-coding SR [1, 2]. Super Resolution (SR) methods utilize information from image priors (Bayesian inference) in sparse-coding methods. However, sparse coding or other Bayesian methods do not utilize information from LR/HR pairs. SRCNN [3] uses a convolutional neural network to imitate sparse-coding technique. The idea behind SRCNN is to use information from neighboring low-resolution pixel to create a HR pixel. SRCNN is effective in learning the non-linear mapping between an LR image and respective HR image. We use SRCNN as a reference model in our proposed method (Section 3).
Multi-Frame Convolutional Neural Network (MFCNN) [4] is a leaning model which utilizes information from multiple frames. MFCNN is an extension of SRCNN, in which multiple frames are used as an input to produce a single high-resolution image. We also observe the fluctuation of PSNR (Peak Signal to Noise Ratio) while tweaking the hyper-parameters of the MFCNN model. Similarly, we use different combinations of hyper-parameters for optimal training (Fig. 2).
Armin et al. [5] proposed three different architectures for video-super resolution. For each architecture, SRCNN was used as the reference model. The proposed architecture used a concatenation layer in SRCNN model to obtain a single LR frame from multiple LR frames. Similar to their approach, we use SRCNN as our reference model. However, in VSR-IF (proposed method), the concatenation layer is not a part of CNN, but uses image fusion techniques after high-resolution outputs are obtained using image fusion.
JohnsonSuthakar et al. [6] have performed a comprehensive survey on the techniques of image fusion. One way of image fusion is to find the minimum/maximum of each pixel for a given set of input images to obtain the resultant pixels in the output image. Another method is to find the average of pixels in the given set of input images. A more sophisticated way is to obtain the output image by applying PCA [7] on the given input images. We also use DWT (Discrete Wavelet Transform) as an image fusion technique in VSR-IF.
Sajjadi et al. have managed to solve a unique problem with problems like Video Super Resolution. The paper presents an approach which is recursive in regard to using the last iterative HR frame to produce the next one in order to reduce the computational demand of the entire system. The system is also able to handle larger inputs. With more emphasis on environmental computing being realized in the modern world, the paper lays the groundwork for further work in this field leaving room for consideration for external factors while successfully outperforming other approaches, proving there is always room for improvements in all domains of a problem [14].
A show the MSE observed during training of SRCNN model. B shows the PSNR curve during training. As expected, LR images with least noise (2x down-sampling) showed the best results.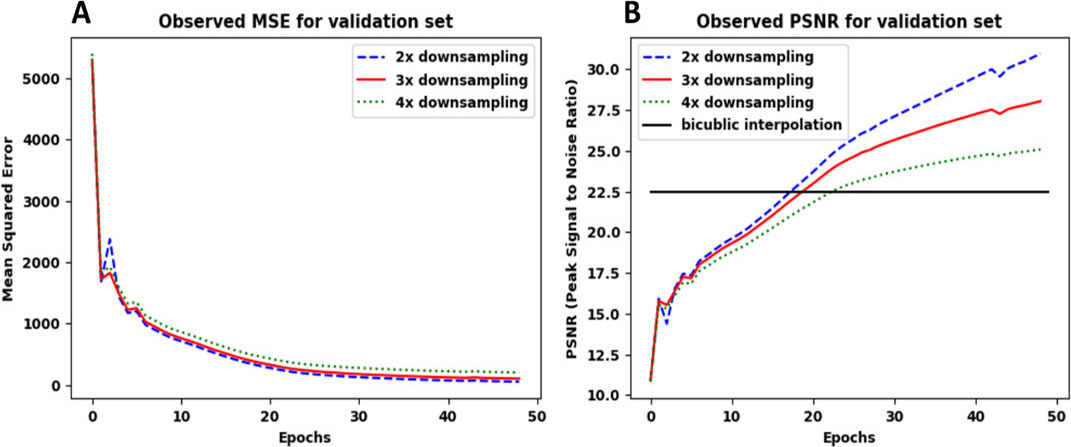
Lopez-Tapia et al. [15] propose an approach to super resolution using CNN and Generative Adversarial Network (GAN). The presented approach is not expected to have the utility of motion compensation. The model proposes two new models which produce excellent results in terms of PSNR and SSIM. The methodology used in unique in nature and presents two additional loss features which are being used to produce the required Super Resolution output.
Hung et al. [16] present an approach which is applicable to both images and videos. They present a system in which an object is considered in its global capacity. All the parameters of an object are considered at all times which are then evaluated to produce one single high resolution object. The process may be termed as the objects being aware of themselves. Each global position provide some additional detail towards the overall resolution of the object which can be added to other frames thus producing a higher resolution. The paper proposes the use of a global aware network and self attention blocks to achieve a global evaluation of an object at all possible intervals of time. The degree of the network is shallow, thus reducing the computational complexity when compared to other methods although this may result in loss in performance and the overall system is still very demanding. The experimental results do not draw comparison between computational parameters when compared to other methods.
Video SR has also been tried using sophisticated methods for motion estimation [8]. However, motion estimation is a computationally expensive procedure. Furthermore, if there is an abrupt change such as a video-cut, motion estimation becomes difficult.
In our proposed method, we do not utilize explicit motion estimation methods. However, motion estimation is implicit because we use LR frames to produce a single HR frame. Due to the data oriented approach of our methodology, the amount of training required is relatively less when compared to the above described literature, thus resulting in a lightweight model. The light weight approach in training proves to be an effective methodology for producing a faster model.
The primary problem that this paper attempts to tackle may be described in two phases, both being related to each other. The first is the amount of data sent to the training network to produce the HR frame to be used and finally the entire SR Video. The second being the overall speed being delivered by the system. The data driven approach results in a low amount of training thus it directly impacts speed. The model also uses concatenation of frames to increase performance metrics and reduce training time.
Results for different hyperparameters of SRCNN model. Increasing the number of layers and filter size leads to increase in the quality of image restoration
Results for different hyperparameters of SRCNN model. Increasing the number of layers and filter size leads to increase in the quality of image restoration
Architecture of VSR-If model. The three LR frames are adjacent frames (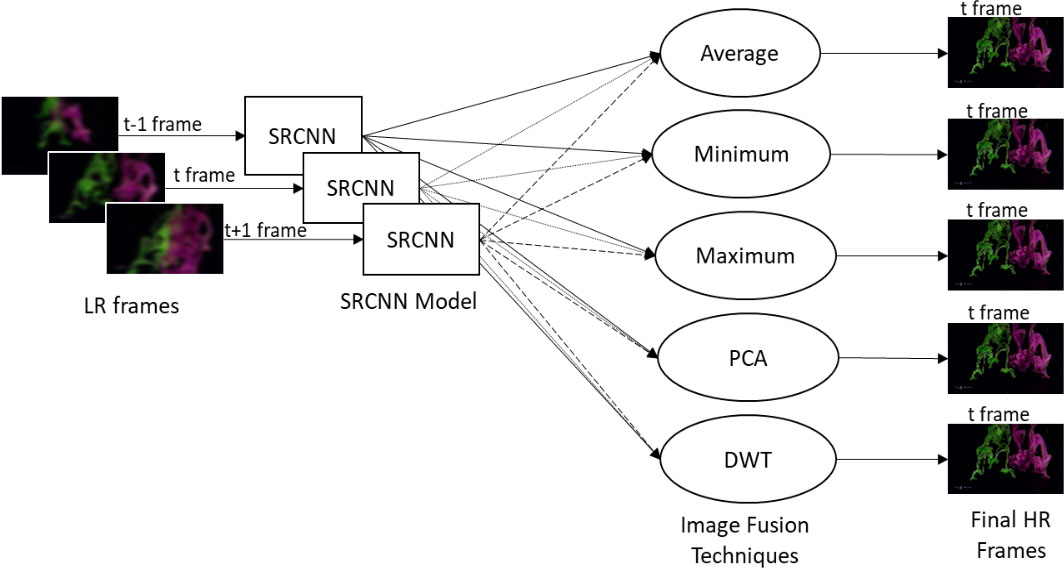
For training and testing of SRCNN, we obtained multiple HR images (720p, 1080p, 4k) from Flicker Creative Commons [9] 100M Dataset to form a still-images dataset (ImgData). For testing of VSR-IF, we obtained high-resolution videos (4k videos from YouTube and Vimeo) to form a video dataset (VidData).
For training and testing with ImgData and VidData, we convert the high-resolution images and frames into low resolution images and frames using down-sampling and upscaling. For down-sampling the dataset, we apply Gaussian Blur (sigma is 1.5) and use bicubic interpolation [11] (2x, 3x and 4x) to reduce the size of image. Then, we resize the image to their original size to obtain high-resolution dataset. Figure 2 shows a sample LR and HR image and adjacent LR and HR video frames. The average PSNR between LR/HR pairs for ImgData was 26.31 after 2x bicubic interpolation and 23.32 after 4x bicubic interpolation.
Before building the video SR model (VSR-IF), we pretrain a reference model. There are three convolutional layers in the SRCNN model. The first layer is used for patch extraction (extracts overlapping small patches
Each of the three operations described form a convolutional layer. We use MSE as our loss function for the convolutional layer (Eq. (4)).
PSNR is widely accepted as a metric for image quality enhancement procedures. PSNR (Peak Signal Noise Ratio) is used to find the relative noise between an output image of SRCNN and its ground truth (Eq. (5)).
Figure 3 shows the PSNR and MSE curves for training of SRCNN model. Table 1 shows average PSNR (test images) for different combinations of hyper-parameters.
VSR-IF uses SRCNN as a reference model. VSR-IF uses information from multiple adjacent frames to produce the final frame. Figure 4 represents the flowchart for Video Super-Resolution using Image Fusion. SRCNN is used on multiple frames to produce multiple HR frames. Then HR frames are fused to form a single HR frame. Due to the fusion process, the noise of the resultant HR frame is reduced further, and we see a significant improvement over SRCNN. While, we used ImgData for training and testing of SRCNN, we will use VidData for testing of VSR-IF.
Image fusion techniques
The values are PSNR score for different combinations of number of neurons and filter size in the reference model along with different fusion techniques. The models are an improvement on the reference models present in Table 1. In this table, we only consider PSNR score for 3x down-sampling. The value of
(number of frames on either side) is 56
The values are PSNR score for different combinations of number of neurons and filter size in the reference model along with different fusion techniques. The models are an improvement on the reference models present in Table 1. In this table, we only consider PSNR score for 3x down-sampling. The value of
Suppose we have three adjacent frames from a video. A simple procedure is to find the average of Red, Blue and Green components of the image for each pixel for the given input frames. Consequently, the final image will be the average of all the input frames. The average fusion technique is summarized in Eq. (6) (for one channel).
The minimum and maximum fusion techniques are similar to the average technique. The difference is that we find the minimum/maximum of each pixel for a given set of input frames to find the resultant output frame. The equation for minimum fusion technique is Eq. (7). The technique for maximum fusion technique is Eq. (8).
InputInput OutputOutput OutputOutput ForForEnd For ForEachFor eachEnd For [h] Image fusion using PCA
LFrame
Initialize 2D zero matrices R, G and B of size (S * S)
HFrame
J
Use PCA algorithm on
eigenvector
Red component for HR
Repeat steps 12 to 16 on matrix G and B to obtain green and blue components of HR
Combine Red, Green and Blue component to obtain HR
END
Average PSNR for VSR-IF5 model. The value of d number of LR frames on either side of the frame at 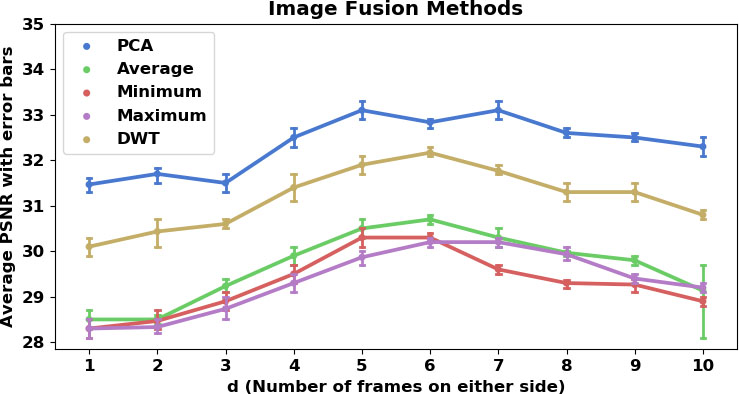
PCA algorithm used for image fusion is described using Algorithm 4.1.2. We assume that the multiple frames used in the image are different dimensions (
From Table 2, it is clear that PCA performs better in most cases compared to other Image Fusion techniques. We compare the models VSR-IF1, VSR-IF2, VSR-IF3, VSR-IF4 and VSR-IF5 which are based on the models defined in Table 1. Again, we find that increasing the number of neurons and filters in the reference model is helpful in increasing the PSNR score of the obtained images.
In Fig. 5, we see that most of the image fusion methods had maximum efficiency when

This section is aimed at producing a detailed comparison between the results produced using the model suggested in this paper and other techniques which have been implemented in recent literature works.
The comparative analysis is depicted through images to provide a better visual depiction of the results. The analysis of each parameter considered for comparison is followed after each image. The parameters have been chosen due to their common nature with most literature and also the used parameters are accepted as comparison metrics in this particular field of study. They also provide a substantial mathematical and visual differentiation, allowing for an effective comparison between the proposed model and the existing literature.
Figure 6 shows a comparison between the VSR-IF and other existing video SR models. As shown in the figure, VSR-IF produces the highest PSNR (calculated using Eq. (5)) for
Execution time is a crucial comparison metric in comparative analysis of models. Figure 7 effectively shows the comparison of average PSNR achieved by the models and comparison of execution time for each model. Bicubic interpolation and sparse coding do not fall under methods of deep-learning and, hence require less time for execution. Our model takes a slightly longer time than SRCNN model to perform five different image fusion techniques and select one which produces maximum PSNR. Draft-CNN which depends on motion estimation is computationally expensive. Figure 7 is the average time of execution for just 1 frame. Assume that, we have to enhance the quality of a 5 second video with 60 fps we have 300 frames. In such a scenario, bicubic interpolation will take 30 seconds, sparse-coding will take 52 seconds, SRCNN will take 5 minutes, MFCNN will take 7.5 minutes, Draft-CNN will take 9 minutes and VSR-IF will take 6 minutes to execute. This shows that with increasing variation in the input size and frame size the proposed model outperforms MFCNN and draft-CNN where the difference in time for execution will keep on increasing eventually producing an input which can not be handled by MFCNN and draftCNN but will be executed by VSR-IF.
PSNR and execution time comparison for different models. VSR-IF is the proposed model. DRAFT-CNN performs better but is slower than our method.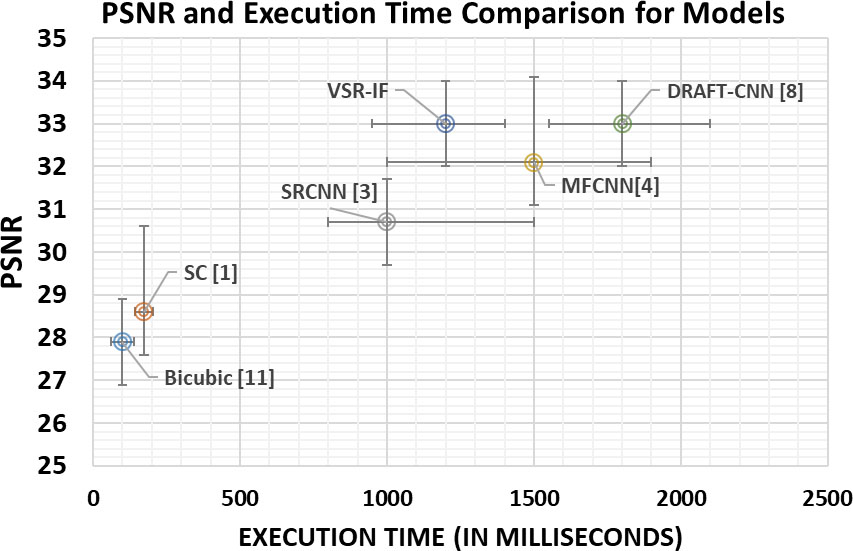
Winning % of models when compared to other models. VSR-IF shows better performance than other models in most cases.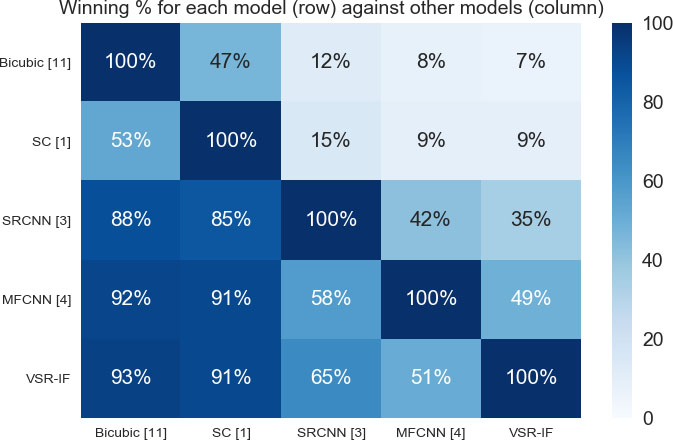
Figure 8 shows the winning percentage of each model against other models. We performed comparison of all models using 1000 test frames and PSNR as the criteria for judgment. Figure 8 shows the percentage of times VSR-IF won against other models when PSNR of the results of test-frames were compared. Our model shows better performance than MFCNN by a narrow margin. In 35% of the cases, SRCNN produced same or better results because the adjacent frames had no relative motion. The proposed model delivers better performance when compared to most of the situations. The model also lacks in some areas, showing there is scope for further work and improvement on the basis of the proposed model.
Using the existing model for single-image super resolution, we have proposed a novel method for video super resolution that takes advantage of adjacent low-resolution frames to enhance the quality of a particular frame. VSR-IF performs better than most of the existing models for single image super resolution and video super resolution. Our results are a testimony to the fact that video super resolution will benefit if we utilize the information from multiple frames rather than just one frame. In most of the frames with motion such as trains or fast-moving cars, we were able to avoid loss of information and reduce the blur effect by using multiple frames.
The primary disadvantage presented by the proposed model is the time taken to enhance a video of short length. Shorter videos may take longer to enhance, but as the input size increases, the proposed model outperforms the MFCNN and Draft-CNN models in terms of the execution time. Since the proposed model is based on SRCNN and is built further up on top of SRCNN, it is not mathematically possible to achieve a shorter execution time than SRCNN as the initial computation for SRCNN still needs to take place. With further development in technology, the SRCNN model can be replaced with a more optimal model. This conveys the flexible and adaptive nature of systems based on reference models.
The overall performance of the system can be increased by fine tuning the parameters of the VSR-IF model. Our model performs better when PSNR is compared but it is unstable for many frames. The proposed method is not robust enough to be subjected to outliers in the test frames. We expect to train the system to detect abrupt frame changes like scene changes in videos to broaden the use cases of the model although, the model has shown high success in most use cases. The proposed model thus makes a good case for models based on other reference models and models which are data oriented to produce effective models while reducing computational efforts.