
Abstract
Video Super Resolution (VSR) applications extensively utilize deep learning-based methods. Several VSR methods primarily focus on improving the fine-patterns within reconstructed video frames. It frequently overlooks the crucial aspect of keeping conformation details, particularly sharpness. Therefore, reconstructed video frames often fail to meet expectations. In this paper, we propose a Conformation Detail-Preserving Network (CDPN) named as SuperVidConform. It focuses on restoring local region features and maintaining the sharper details of video frames. The primary focus of this work is to generate the high-resolution (HR) frame from its corresponding low-resolution (LR). It consists of two parts: (i) The proposed model decomposes confirmation details from the ground-truth HR frames to provide additional information for the super-resolution process, and (ii) These video frames pass to the temporal modelling SR network to learn local region features by residual learning that connects the network intra-frame redundancies within video sequences. The proposed approach is designed and validated using VID4, SPMC, and UDM10 datasets. The experimental results show the proposed model presents an improvement of 0.43 dB (VID4), 0.78 dB (SPMC), and 0.84 dB (UDM10) in terms of PSNR. Further, the CDPN model set new standards for the performance of self-generated surveillance datasets.
Keywords
Introduction
The rising popularity of the internet and social media is fueling an increasing need for image and video processing methods. The task of image processing in the computer vision domain involves techniques to enhance and recover a high-resolution (HR) image from a low-resolution (LR) counterparts [1]. Super Resolution (SR) is an emerging technique for increasing the spatial resolution of media files (image and video). The field of SR has been divided into two categories: video super-resolution (VSR) and image super-resolution (ISR), depending on the quantity of input frames. Most application domains like surveillance, academia, medical, and business industries require pleasant and high visual quality. It is vital because low-quality frames can often make it challenging to identify crucial information, especially in the surveillance field, which relates to security [2, 3]. VSR models trained on high-quality datasets boost the accuracy of video surveillance while also enhancing video quality in time sensitive manner. Therefore, scaling up and creating HR images from low-resolution images is necessary using VSR techniques. The ISR methods understand the relationships between frames and create more precise and detailed results by utilizing available patterns. VSR, in a broad sense, can be seen as an expansion of ISR where algorithms process frame-by-frame information without additional hardware demand.
Many VSR algorithms have been put forth in recent years; traditional approaches [4–6] and deep learning (DL) methods [7–11] make up most of them. Unlike other methods, learning-based methods—such as sparse representation and example-based use data to learn the mapping from LR to HR. [12, 13] used traditional approaches with the kernel regression method for motion estimation. Liu and Sun [14] proposed a Bayesian approach that simultaneously estimates motion, blur kernel and noise level to reconstruct HR frames. Similarly, Ma et al. [15] employed the expectation-maximization (EM) method to calculate the blur kernel while ensuring improved recovery of HR frames. However, these models are still insufficient to accommodate different video scenarios. DL-based approaches [7–9, 16–18] typically perform well on many publicly available benchmark datasets due to the nonlinear learning potential of deep neural networks. Moreover, DL had remarkable success in many fields [7–11] and has received much attention.
Deep neural networks, including convolutional neural networks (CNN), generative adversarial networks (GAN), and recurrent neural networks (RNN), have been widely used to enhance video resolution [10]. Several existing DL models mainly focused on increasing CNN depth to perform better. However, adding more layers to a neural network does not necessarily guarantee an improvement in performance, and it can lead to difficulties during training, such as vanishing or exploding gradients [13]. It can be challenging to restore a HR video from its LR counterpart with precision due to ill-posed issues in VSR [10, 11]. Existing literature shows two types of motion compensation (MC) VSR approaches: 1) explicit based [8, 9, 17, 19, 20] and 2) implicit based [21–25] MC methods. Kappeler et al. [19] suggest warping all nearby frames to reference optical flow estimates. The VESCPN [26] approach uses a combination of spatial-temporal networks to create a new approach for VSR. However, inadequate motion estimate and alignment in these methods can lead to artifacts. Additionally, estimating optical flow can be computationally intensive and limit the practical use of these methods. In contrast, implicit motion compensation-based methods do not require estimating or aligning motion between frames. According to the studies above, even though VSR has made remarkable strides, the three primary problems are still remaining in DL-based VSR methods:
In this study, authors have proposed a new method to capture features to produce high-quality frames precisely. The CDPN method prioritizes accuracy and visually pleasing results compared to other networks. The network is designed to learn the structural details and the fine details from the ground-truth HR frame to achieve high accuracy and detailed reconstruction. The proposed CDPN method can recover more structural details with high accuracy. The primary contributions of this research article are listed as follows:
1. Proposed a novel conformation detail preserving network (CDPN) to learn structural information from the ground-truth HR image, which allows it to achieve high accuracy and visually pleasing results, named SuperVidConform.
2. We achieved the optimal learning performance based on a recurrent residual network (RRN) with a hidden state. The network utilization of motion information is optimized implicitly, which leads to superior performance compared to previous state-of-the-art methods on publicly available benchmark datasets.
3. The proposed method is evaluated on a surveillance dataset, and the results show that it performs better with the lightweight recurrent architecture.
The rest of the paper is structured as follows: Section 2 overviews related work. Additionally, the architecture of CDPN is described step-by-step in Section 3. The results of the experiments are presented in Section 4, and finally, Section 5 concludes with a summary of the findings.
Related work
As mentioned in Section 1, VSR is a challenging problem. Restoring an HR image from its LR counterpart is difficult, as multiple possible solutions exist for any given LR image. It is also hard to recover all the detailed and overall information in the original LR image. However, videos have temporal correlations among adjacent frames, which can be helpful for super-resolution. This has motivated the development of several recent VSR approaches. [1, 13, 29–32] aiming to exploit this temporal correlation effectively. Hence, this paper explores VSR models from three aspects: Temporal correlation, exploitation of motion information, and recurrent network.
Temporal correlation
Temporal correlations built into the VSR architecture [22, 25, 26, 33–35] are generally famous for end-to-end learning frameworks. Two strategies are widely used to model temporal information: Temporal Concatenation and Temporal Aggregation. Former is a widely used VSR method [17, 19, 20, 36] that concatenates several frames for preserving temporal information. Using multiple input images is an expansion of ISR using this method. However, the concatenation method can lead to difficult training as it fails to represent various motion regimes within a single input sequence correctly. Later uses temporal aggregation in which multiple SR inferences operate in various motion regimes as proposed by [8, 11, 22, 28] to overcome the dynamic motion issue in VSR. The final layer constructs an SR frame by combining the results of all branches
Exploitation of motion information
Several DL methods have recently been proposed to tackle the VSR problem explicitly and implicitly, such as [30, 37]. Most VSR methods use explicit MC, which takes a direct channel as MEMC with information fusion and upsampling. These methods include a joint motion compensation module proposed by VESPCN [26] and an SPMC module introduced by Tao et al. [20], task-oriented flow modules proposed by Xue et al. [9], and recurrent frame modules proposed by Sajjadi et al. [8]. They estimate motion frame-to-frame and align the results to a reference frame. However, a significant disadvantage of these techniques is high computational cost caused by MEMC. Conversely, implicit MC techniques reduce video SR computational load by implicitly using motion information rather than explicitly. This can be done by incorporating motion information into the network in a way that does not require additional computation. Methods with implicit MC [21–23, 25] develop an improved module that fully utilizes complementary information from different frames. Jo et al. [23] predicted a dynamic upsampling filter to recover the image, while Yi Huang et al. [25] fused spatial-temporal information. Huang et al. [38] used a bidirectional recurrent convolutional network; in [21] Fuoli used recurrent architecture in feature space. The proposed method in this paper utilizes an implicit MC technique to reduce the heavy computational burden of explicit MEMC. This method also takes advantage of the relationship between the current frame and the hidden state to actively use historical data within the hidden state, improving performance and lowering the risk of error accumulation.
Recurrent neural network
Recently, there has been a lot of use of recurrent networks in tasks related to video processing, such as VSR. These networks [11, 22, 28, 38–40] can handle input and output that involve time by analyzing sequential data by combining data from every frame while keeping track of their individual hidden states. However, a big challenge with this approach is that when working with long sequences of frames, the training process can become complex due to gradient vanishing [41–43]. To address this problem, the proposed method utilizes a Recurrent Residual Network (RRN), which uses a residual mapping between layers and includes identity skip connections, which helps to avoid the gradient vanishing risk in the training process. Therefore, motivated by these VSR aspects of temporal correlation, exploitation of motion information, and handling the level of recurrent network for temporal input and output, this work proposed a general framework for long-range encoding video.
Conformation detail preserving network
This section explains the methodology and general architecture of the proposed method for temporal modeling. The system is broken down into three parts: decomposition of the original images, modeling the passage of time, and a method for measuring performance. The process of breaking down the images preserves essential information about their structure. The temporal network blends several successive frames with a benchmark frame as its input. The loss function as a performance measurement helps to improve the network performance by considering motion information.
Network framework
The proposed CDPN comprises the following components: a decomposition of images to preserve essential details, a module for extracting features, a module for increasing resolution, and a module for combining these elements to produce the final high-resolution result as shown in Fig. 1. The annotation that follows, It, I t-1, I t C , I t-1 C , IHRC, IHR, and IGT, denote the current and previous input, the conformation details of current and previous input, the recovered details of the image, the final high-resolution output, and the original high- resolution image that serves as the reference point, respectively. Equation (1) decomposes the input from the current and previous frames to get corresponding conformation details from the image.
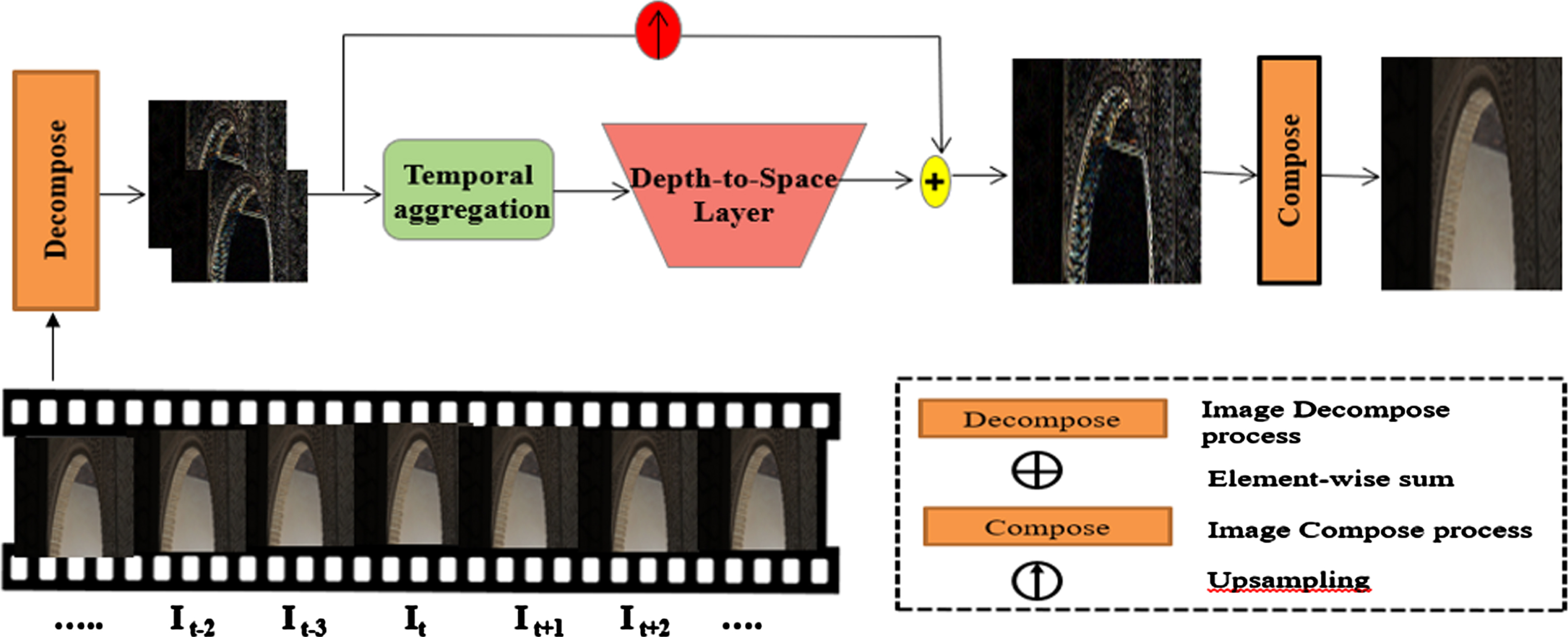
Schematic illustration of the proposed method.
HRRN (·) denotes the residual RNN feature extraction module, consisting of residual learning to extract deep features (DF). Furthermore, the extracted detail feature FDFi is then upscaled via the upsampling module to eliminate the pixelation effect and estimate extra image details.
HUP (·) and FUPi refer to the module for increasing resolution and the features that have been increased in resolution, respectively. This approach employs a post-resampling method that relies on the high-level detail obtained from the low-level space and yields improved outcomes for VSR than a predefined upsampling method. Then, the recovered conformation details input IHRC was estimated from FUPi, where i = 1,2.
Where HREC (·) stands for the recovered upsampled input. Finally, these recovered conformation details of IHRC are inputted into a composition module to produce the final HR image IHR, where Hcomp (·) represents the composition module.
Recovering the high-resolution image from its low-resolution counterpart can be difficult due to its ill-posed problem. To overcome this challenge, the authors in this paper utilized the conformation detailing approach, as shown in Fig. 2. This method learns the high-frequency information, such as texture, separately, thereby enhancing the final image quality.
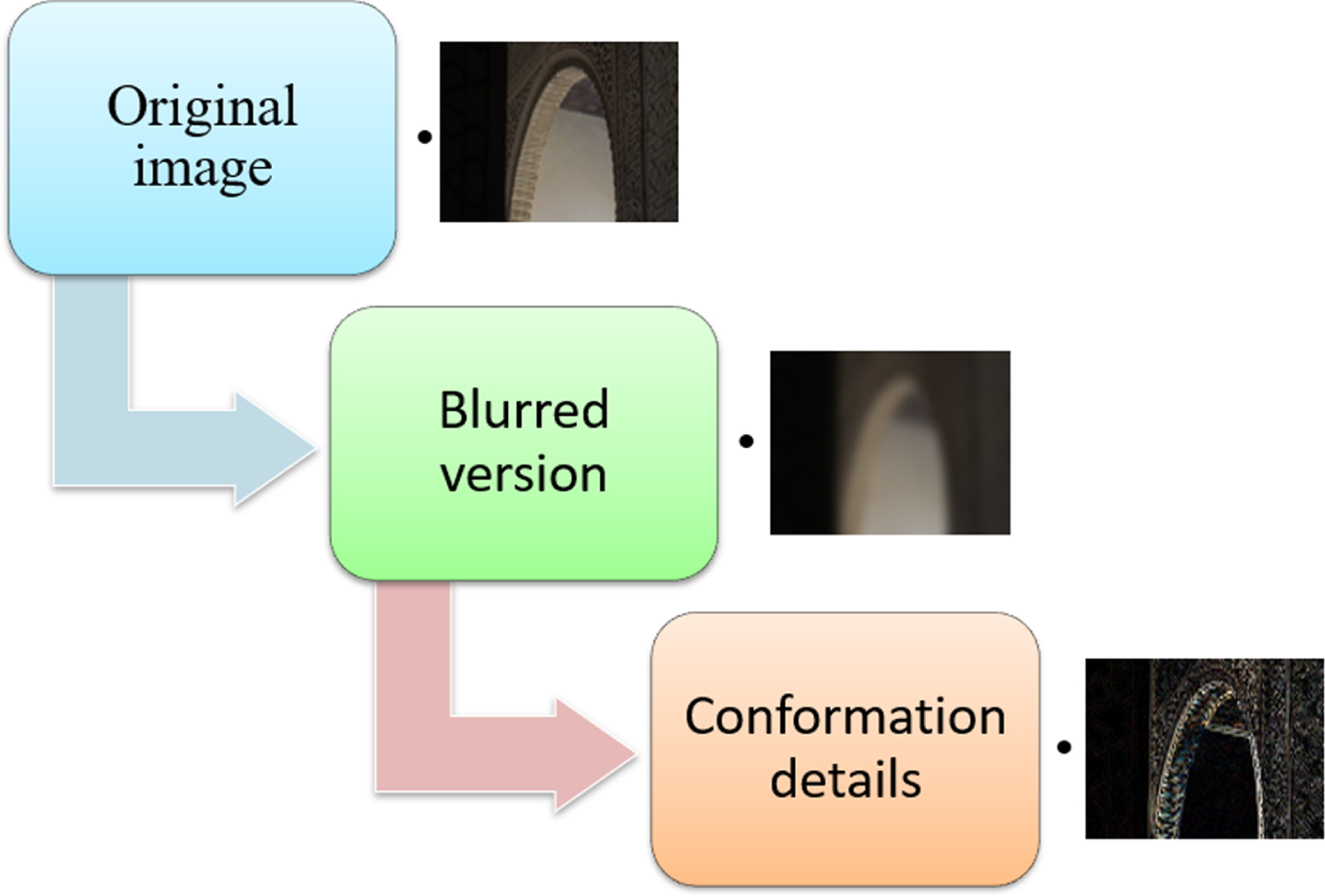
Illustration of the decomposition process.
The high-frequency information in an image, such as textures, can be extracted by taking the difference between the original image and a blurred version [27, 44]. This method has been used in low-level image processing tasks, such as identifying boundaries and assessing image quality [45].
Motivated by the above findings to recover high-frequency information, the input image is separated into its high-frequency components, which are obtained by subtracting the original image from a version that has been blurred using a Gaussian filter. These high-frequency details are then used in a composition module to generate the final high-resolution image, as shown in Equation 5.
This work comprehensively studies different temporal modeling frameworks, which include 2D CNN and RNN. Figure 3(a) and (b) illustrate these networks, respectively, and Fig. 3(c) shows the proposed hidden state architecture. The input frames are joined together in a 2D CNN. RNN, on the other hand, uses fewer frames as input and processes a video sequence repeatedly. Typically, the hidden state at a particular time step is composed of three components: the previous output from time step ot-1, the previously hidden state representation ht-1, and the two neighboring frames It–1,t. Intuitively, pixels in consecutive frames of a video sequence are often similar. The result is improved by using information from the previous layer to refine the t-th time step that contains the high-frequency details. However, like other video processing tasks, RNN in VSR [21] can be affected by the issue of gradient vanishing [41–43]. The recurrent residual network (RRN) is proposed to overcome this problem, which uses residual learning and includes identity skip connections [37].

Frameworks for modelling temporal data that are frequently used: A) 2D CNN, B) RNN, C) Proposed RRN.
The recurrent residual network (RRN) design ensures that information flows smoothly, allowing it to retain texture information over a long period, making it easier for RNNs to handle longer videos and using a set of equations within the RRN framework, it may reduce the chance of gradient vanishing during training by using each time step is ‘t’ to produce two outputs, ht, and ot, which are then used to guide the next time step, ‘t + 1’:
where,
k ∈ [1, K]
h t = σ (Wconv2D {xK}) ot = Wconv2D {xK} Equation 6 uses the ReLU function represented by σ (·). In the k-th residual block, the term g (xk–1) denotes a simple mapping, indicating that (xk–1) = xk–1 in Equation 7. In contrast, the newly obtained residual mapping is denoted by the notation F (xk–1).
The CDPN is optimized using a training loss function, the sum of all outputs.
The symbol Θ represents the set of parameters for the proposed network, as shown in Fig. 2. The term ι 1 (IHR, IGT) represents the overall loss for the network, where IHR is the final HR output of the CDPN, and IGT is the ground-truth HR image. The term ωk represents the weight of each loss.
In the field of VSR, various loss functions have been proposed to guide the optimization of networks, such as pixel loss [8, 22, 46, 47] (e.g., ι1 loss), content loss [25, 31], etc. The ι
1 loss function is a simple yet effective method to obtain a high peak signal-to-noise ratio (PSNR) with less complexity. The pixel loss promotes the recovered HR image (IHR) to be visually similar to its ground truth (IGT). Thus, to achieve a high PSNR and high-quality regional recovery, and accurate edges, the proposed method uses loss as a ι
1 loss function:
Specifically, the L1 loss function is defined as follows: Given a set of N training data pairs {IiHR, IiGTNi=1 where IiHR is a recovered image and IiGT is the corresponding ground truth image, the ι
1 loss function measures the difference between the recovered and ground truth images using the ι1 metric.
Experimental analysis
Datasets
Authors in this experimental analysis utilized the publicly available Vimeo-90k [9] dataset for model training. This dataset consists of 90k video scenes with high visual quality. Gaussian blur with σ = 1.6 was applied on a dataset, with patch size 64×64, and further down sampling was performed with a 4× scale factor. The performance evaluation for the proposed method was done using VID4 [14], SPMC [20], and UDM10 [25] standard benchmark datasets. Four scenes make up VID4, each with its motion. The most recent validation sets, SPMC and UDM10, feature a variety of senses with frames that are far higher in resolution than VID4. For a fair comparison, the quantitative results are evaluated using PSNR and structure similarity index metrics (SSIM).
Implementation details
This work considers two models for a given temporal method: CDPN-S and CDPN-L, where S represents five and L represents ten 2D residual blocks, respectively. Each residual block comprises two convolutional layers with ReLU activation in between. The convolutional layer has 128 channels and a 3×3 filter size. This method uses sub-pixel convolution to increase the resolution of the LR features to HR [35]. At the starting time of step t0, the previous estimation is set to zero. The learning rate starts at 1×10–4 and decreases by 0.1 every 60 epochs until 70 epochs to train the CDPN models. The models are trained using a pixel-wise loss function and an Adam [19] optimizer with parameters β1 = 0.9, β2 = 0.999, and a weight decay of 5×10–4. All experiments were conducted using Python 3.6.4 and Pytorch 1.1.
This work comprehensively studies and compares two temporal modeling methods, including 2D CNN and RNN. The proposed model specification comparison is shown in Table 1, with their respective residual blocks. The authors utilized 5 and 10 residual blocks as the hidden states S and L, respectively.
Specification comparison of temporal modeling methods
Specification comparison of temporal modeling methods
The results are measured using the luminance (Y) channel, with the L1 loss applied to all pixels between the ground truth frames and the network output. Further, PSNR (dB) values of VID4, SPMC and UDM10 benchmark datasets of these temporal modeling methods are given in Table 2.
PSNR values of VID4, SPMC, and UDM10
This section validates CDPN with other state-of-the-art VSR methods to demonstrate its effectiveness, including Bicubic, FRVSR [8], DUF [23], RBPN [22], and RLSP [21]. For intense comparison, this work uses both explicit and implicit MC methods.
1) Quantitative comparison: Table 3 compares the proposed method quantitatively with state-of-the-art video super-resolution methods with and without alignment methods, such as CNN and RNN. For a fair comparison of reported methods, this work utilized three benchmark datasets with a scale factor of ×4. Specifically, comparing the recovered results at ×4 scale on the VID4, SPMC, and UDM10 datasets wrt to RLSP method, the proposed CDPN show an improvement of 0.43 dB, 0.78 dB, and 0.84 dB, respectively, in terms of PSNR. RLSP also passes historical information like the CDPN method without ME in feature space. The main reason for achieving this optimal performance is improved feature extraction from conformation detail information such as repetitive patterns, edges, and textures. In many VSR methods, recovering this information is a difficult task. Moreover, the conformation detail-learning enables the network to focus on information detail learning of the original image and obtains satisfying results. The RRN with residual learning focuses on learning abundant local features in images and achieves a high PSNR.
Quantitative comparison of VID4, SPMC, and UDM10 datasets for 4x VSR and PSNR (dB) values and SSIM
Quantitative comparison of VID4, SPMC, and UDM10 datasets for 4x VSR and PSNR (dB) values and SSIM
2) Qualitative Comparison: Most existing VSR methods, such as FRVSR, DUF, RBPN, and RLSP, focused on PSNR-based results and not perceptual details [8, 21–23]. The proposed temporal method reconstructs consistent frames with fewer flickering artefacts than other VSR methods. Figure 4 shows the superior visual quality of our CDPN in qualitative results.

Qualitative comparison on the VID4, SPMC and UDM10 datasets for 4× VSR.
All dataset consists of rich information in scenes like sharp edges and fine texture with fewer artefacts. The proposed method produces sharper edges in the calendar scene, the fine texture of the RMVTG_011 scene, and a clear pattern in the auditorium scene. All dataset consists of rich information in scenes like sharp edges and fine texture with fewer artefacts. The proposed method produces sharper edges in the calendar scene, the fine texture of the RMVTG_011 scene, and a clear pattern in the auditorium scene. In contrast, it is difficult for the remaining methods to recover the high-definition outcomes as they suffer from unpleasant blurring artefacts and unclear structure. The proposed CDPN method recovered and obtained sharper results by detailed conformation. The results indicate that the proposed method generates more realistic and natural outputs than other methods.
3) Model Parameter Size Comparison: Table 4 compares the proposed and state-of-the-art method parameters. The proposed method produces better results with fewer parameters, resulting in the highest efficiency in terms of parameters compared to other methods, demonstrating exceptional performance with less computational overload.
Model size and performance on VID4 dataset with scaling 4 ×
This ablation study works in two models of 5 L and 10 L residual blocks. Table 5 displays the results of the ablation study performed on the surveillance dataset for a scale factor of 4 to evaluate the impact of conformation details.
Analysis of the proposed method on the surveillance dataset with a different model for scale factor ×4 and values in PSNR
Analysis of the proposed method on the surveillance dataset with a different model for scale factor ×4 and values in PSNR
For investing the impact of the kernel on the given dataset, this work used kernel_1 and kernel_3 on Model1, Model2, Model3, and Model4, respectively. Model 3 and Model 4 constructed a better image and high performance with more residual blocks compared to Model 1 and Model 2. Figure 5 shows the further analysis of the qualitative comparison of surveillance data with different residual blocks as 5 L and 10 L.

Qualitative comparison of surveillance dataset for 4× VSR.
Moreover, this work plotted the PSNR with time to examine the information flow between various temporal modeling methods. Figure 6 shows the video series of the calendar sequence in VID4, RMVTG_011 sequences in SPMC, and auditorium sequences in UDM10. The method without conformation details falls overdue after a few frames. The proposed method outperforms the other method by incorporating conformation details, allowing for information accumulation over time.
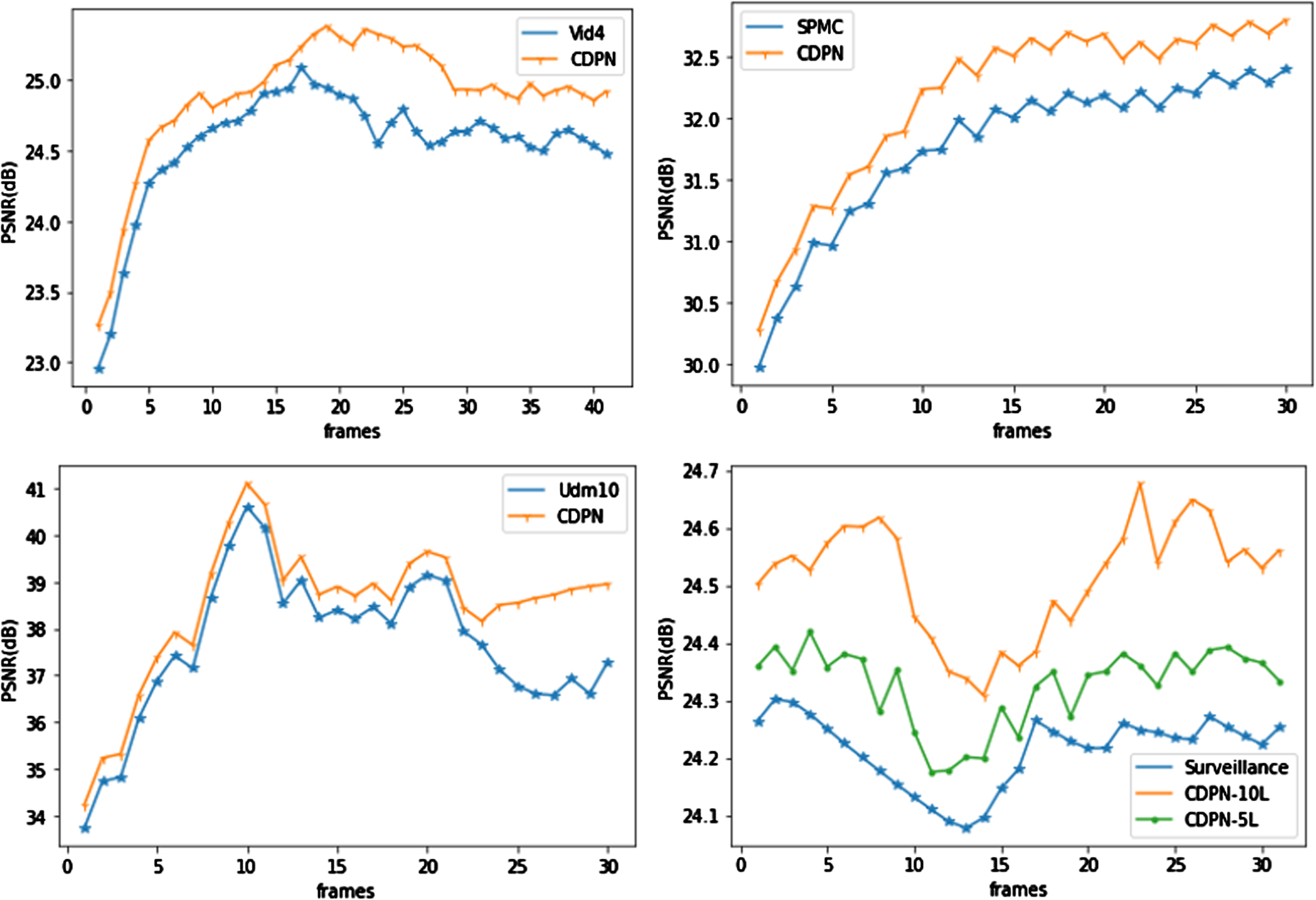
Information flow for VID4, SPMC, UDM10, and Surveillance data on sequences over time.
More interestingly, the CDPN-based method keeps improving while, without conformation detailing, the method suffers from performance degradation. Information from a previously hidden state is complementary to restoring missing details. In addition, this work also plotted surveillance data information flow with and without conformation details, demonstrating high performance. Through the above experimental results and analyses, the findings of this work are that both the network architecture and the proposed loss contribute to the visual improvements and that the network architecture plays a crucial role in achieving high performance.
In this research work, we proposed a new method called SuperVidConform. It is designed to improve the accuracy of VSR by producing results with both high PSNR and visually pleasing quality. The SuperVidConform architecture consists of conformation detail and RNN with residual learning. The conformation detail-learning enables the network to focus on detailed information learning of the original image. It can be supervised by the ground-truth HR image and obtained satisfying results. The RNN with residual learning focus on learning abundant local feature contained in images and achieves high PSNR. Further, the proposed network paid more attention to surveillance data to obtain sufficient sharpness recovery and archives the model optimization. Comparing the recovered results at ×4 scale on the VID4, SPMC, and UDM10 datasets w.r.t. RLSP, the proposed CDPN showed an improvement of 0.43 dB, 0.78 dB, and 0.84 dB in terms of PSNR. The results of the experiments showed that the CDPN outperforms other methods on various benchmark datasets and the surveillance dataset, not only in PSNR but also in visual quality.