
Abstract
Pedestrian detection has been a crucial issue over the last decades. The existing pedestrian detection methods are still face abrupt illumination, partial occlusion, different poses of humans, and cluttered backgrounds challenges. Consequently, the significance of pedestrian detection systems encourages us to propose a new method to address some of these challenges and offer higher accuracy rate. Noting that the power of various kinds of features are different and a single type of feature cannot extract the comprehensive information of human shape. Taking this fact into consideration, we combined pragmatic and useful features in order to detect pedestrian more accurate. Indeed, we combine histogram of oriented gradients (HOG), a proposed modified local binary pattern (M-LBP), and a proposed modified Haar-like features (M-Haar) to achieve these goals. By applying the proposed method, it is possible to extract various information on human shapes including the edge information, texture information, and local shape information. After feature extraction, Cascade Adaboost classifier is used to detect pedestrian images from non-pedestrian. In experiments, INRIA dataset, Daimler dataset, and ETH dataset are applied. The extensive experimental results demonstrate that our approach outperforms the traditional methods in terms of the accuracy and robustness.
Keywords
Introduction
Pedestrian detection has been a crucial issue over the last decades [1, 2] and is the most recognized example of object detection [3]. It has extensive utilization in various applications and services such as robotic [4, 5, 6], intelligent video surveillance system (IVS) [12, 13], intelligent image retrieval [1, 9], intelligent transportation, and advanced driver assistance system (ADAS) [2, 6, 10].
The main challenges of pedestrian detection are as follows:
It is an undeniable fact that when pedestrians overlap in the crowded scene, discovering them will become more difficult. In particular, when the population grows dramatically, occlusion and missing of body parts increase in urban traffic scene [3, 5, 11]. Environmental changes such as illumination alteration during the days and nights, the existence of shadow, and also weather conditions which can affect the efficiency of pedestrian detection [1, 10, 11]. The diversity of articulated poses based on the nature of human’s body in comparison with rigid objects, make pedestrian detection more struggling [5, 6, 41]. Pedestrians may appear in different colored clothing and even carry accessories like backpack and cap which can decrease the detection rate [1, 7, 12]. Cluttered backgrounds can decrease the accuracy of the detection rate. For instance, they might mistakenly be similar to a human’s shape and they may distract from the correct person’s boundary [1, 5, 27].
Taking these challenges into consideration, the significance of this issue encouraged us to design an innovative method based on combinations of essential features in order to eradicate these challenges and detect pedestrians effectively and efficiently. Since the potential effects of these features are different and a single feature cannot extract the comprehensive information of human shape [7, 27], a new method to combine practical features is proposed here. Our method is based on combinations of histogram of oriented gradient (HOG) features, a new proposed modified local binary pattern (M-LBP) features and a new modified M-Haar-like features. HOG is the most used and effective descriptors in previous pedestrian detection methods [3, 25]. Moreover, M-LBP and M-Haar are our new proposed descriptors inspired from the original LBP descriptor and the original Haar-like features respectively. In the following, we will describe this method in more depth.
The related works offer for possible solutions for pedestrian detection problem are extensive [2, 7, 38]. On account of the vastness of this field, comparative articles are published to compare the notable progress and evaluate the performance of different recent methods on pedestrian detection [3, 4, 5].
Some previous methods focused on pedestrian detection are based on a fixed camera. Background subtraction is the most famous strategy for a constant camera [14, 15]. The main idea behind this approach is extracting the background from the image by such methods as Codebook [16, 17, 40], the mixture of Gaussians model [8, 18], self-organizing background subtraction (SOBS) [14], and then classifying the moving objects to discover their types as pedestrian and non-pedestrian. Nevertheless, these mentioned methods are not able to detect human objects from a moving camera which is a more complex task [10, 13].
Feature extractions are extensively used in order to overcome this problem [3, 41]. For instance, an exceptional texture descriptor and invariant to monotonic gray level changes is the local binary pattern (LBP) feature [21] which is used for pedestrian detection [22, 23]. Although, LBP features could not achieve high accuracy rate for pedestrians in cluttered backgrounds. Haar-like features are also another selected set of features with simple and fast implementation [19, 24], but it is easily affected by complex backgrounds. In order to decrease the problem of original Haar-like features, an informed version of Haar-like features was presented in [2], however, informed Haar-like method [2] suffered from high false positive alarms. The most utilized feature for human detection is the histogram of oriented gradients (HOG) which is robust for changes of cloth colors, body shapes, and heights [25]. The main idea behind this strategy is obtaining the object appearance and shape by characterizing it and using local intensity gradients and edge directions [26]. HOG is used in various pedestrian detection methods. For instance, after HOG features extraction, linear SVM as a simply implemented classifier is used in [25]. Moreover, after HOG feature extraction, decision trees [12], cascade Adaboost algorithm [27, 35], latent SVM [36], and intersection kernel SVM (IKSVM) [37] as advanced and fast classifiers were exploited. All of the above-mentioned methods, which used HOG features, have high precision but also need high computational times.
Considering the fact that only one kind of descriptor cannot extract the widespread information of pedestrian [4, 14, 38], most scholars focused on combinations of features with each other to improve the speed or accuracy of detection rate. For example, Wang et al. [28] incorporated HOG and LBP features. Those authors show that the body shape of a pedestrian can be better acquired with combinations of both the edge features and the texture features [29].
In addition, a method based on integrations of local self similarity (LSS) and HOG achieved better performance in the cluttered background with noisy edges [20]. Next, a combined method on the HOG-Haar features was designed [30]. HOG descriptor has a high accuracy of detection rate, although is deprived of high speed. On the other hand, Haar-like features have fast speed but the low accuracy. This method proved augmented HOG-Haar features can improve the pedestrian detection performance. However, both HOG and HAAR, could not extract the widespread information of pedestrian due to the complexity of human shape and appearance.
The diagram of the proposed method.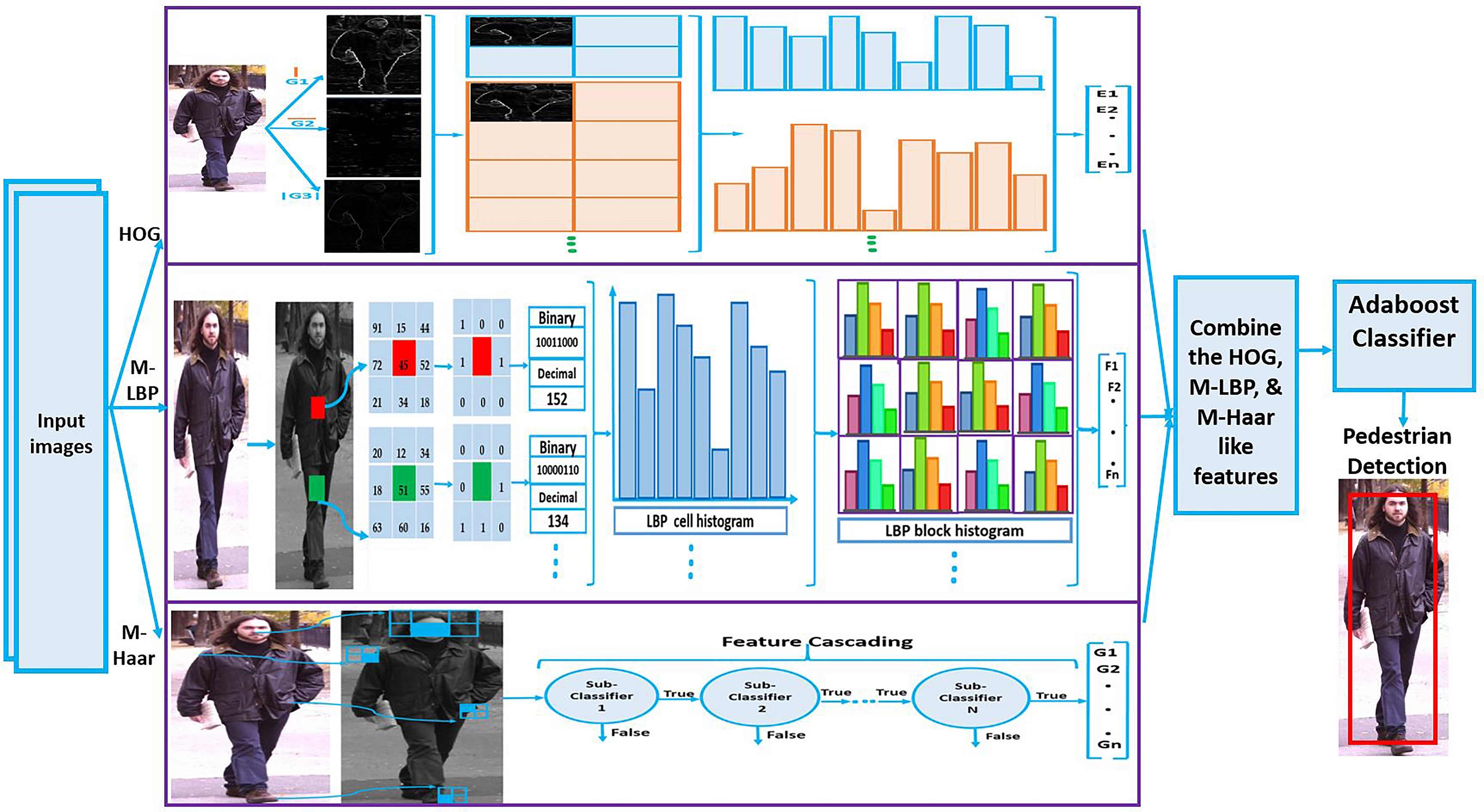
All of the above-mentioned methods were based on combinations of different features. Thus, we aim to improve a pedestrian detection system by extracting various effective features. Indeed, by having different descriptors we may have a more accurate detection rate [3, 13, 27]. Based on these analysis, we proposed a method based on combinations of HOG, M-LBP, and M-Haar-like features in order to detect the pedestrians with higher precision as follows.
The general methodology of the proposed method is denoted in Fig. 1. As shown, the HOG, M-LBP, and M-Haar like features are extracted from the input image and then these features are sent to an Adaboost classifier to detect pedestrian images from non-pedestrian images. In the next part, this process is explained in more depth.
HOG features
The basic idea behind histogram of oriented gradients (HOG) is acquiring the object shape by characterizing it using local intensity gradients and edge directions [25]. Indeed, HOG may obtain local object shape by the distribution of edge directions even without exacting the corresponding gradient or edge direction information.
At the first step, normalization strategy is suggested to eliminate the variety of illumination, local shadows, and colors in the surrounding [3, 25]. Then, first order image gradients in y and x orientation, and the absolute value of gradients are calculated [38]. Weighted votes for gradient direction are accumulated as well. The image is densely divided into small special regions called cells.
For each cell, a 1-D histogram of gradient directions is calculated and then all cell data is mixed to generate a complete HOG descriptor of the window called block. To enhance the performance, we utilize overlapping local contrast normalizations and collect HOG descriptors for all blocks over detection window. As is displayed in Fig. 2, for each block, a local 9-D histogram of gradient directions over the pixels of the block is collected. Indeed, each block has 9 direction bins and the mixed histogram entries form the representation. Finally, the HOG descriptors are collected as our feature vectors
Performance of HOG descriptor. G1, G2, and G3 are first order image gradients in 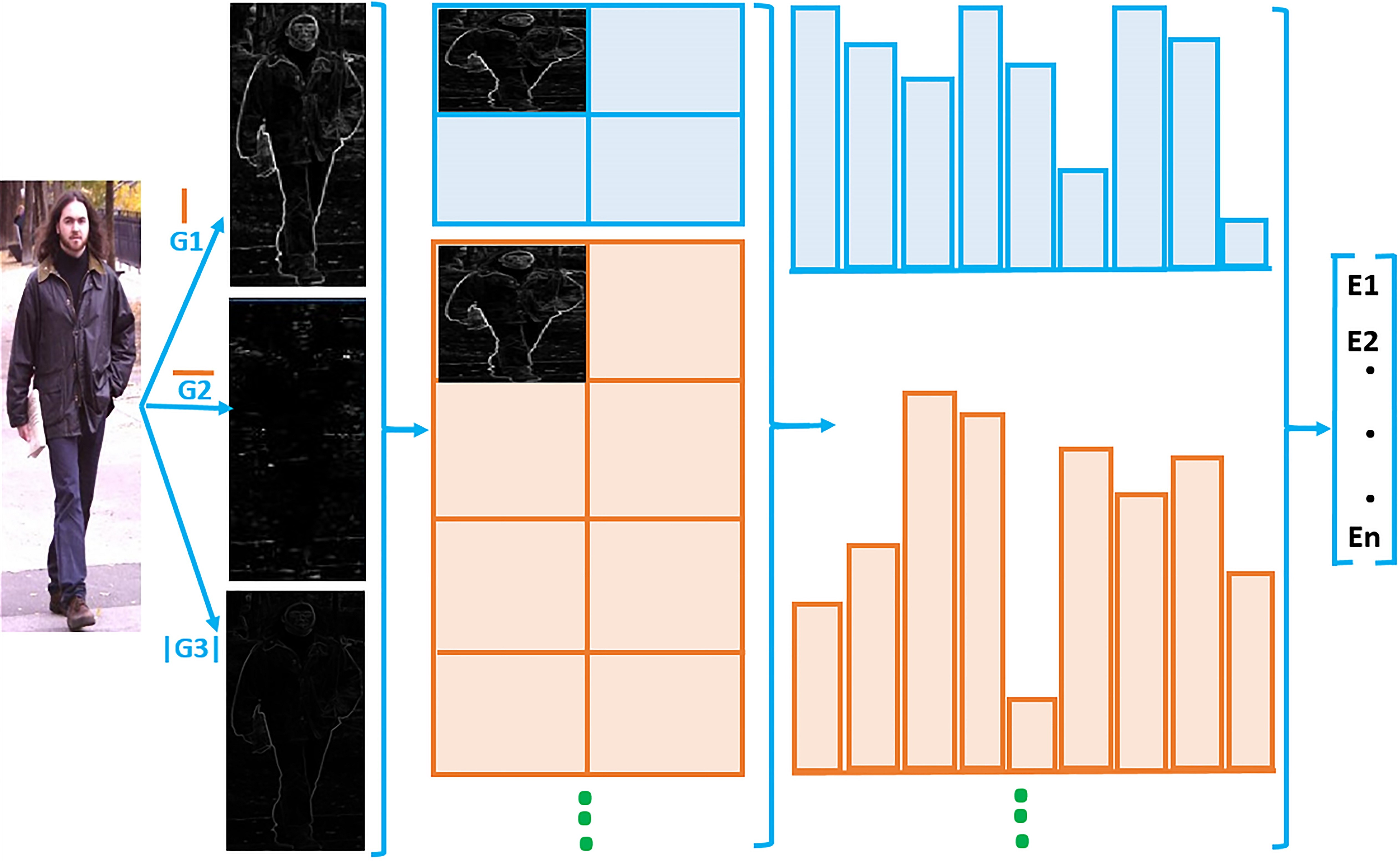
Two simple 3*3 original LBP descriptors.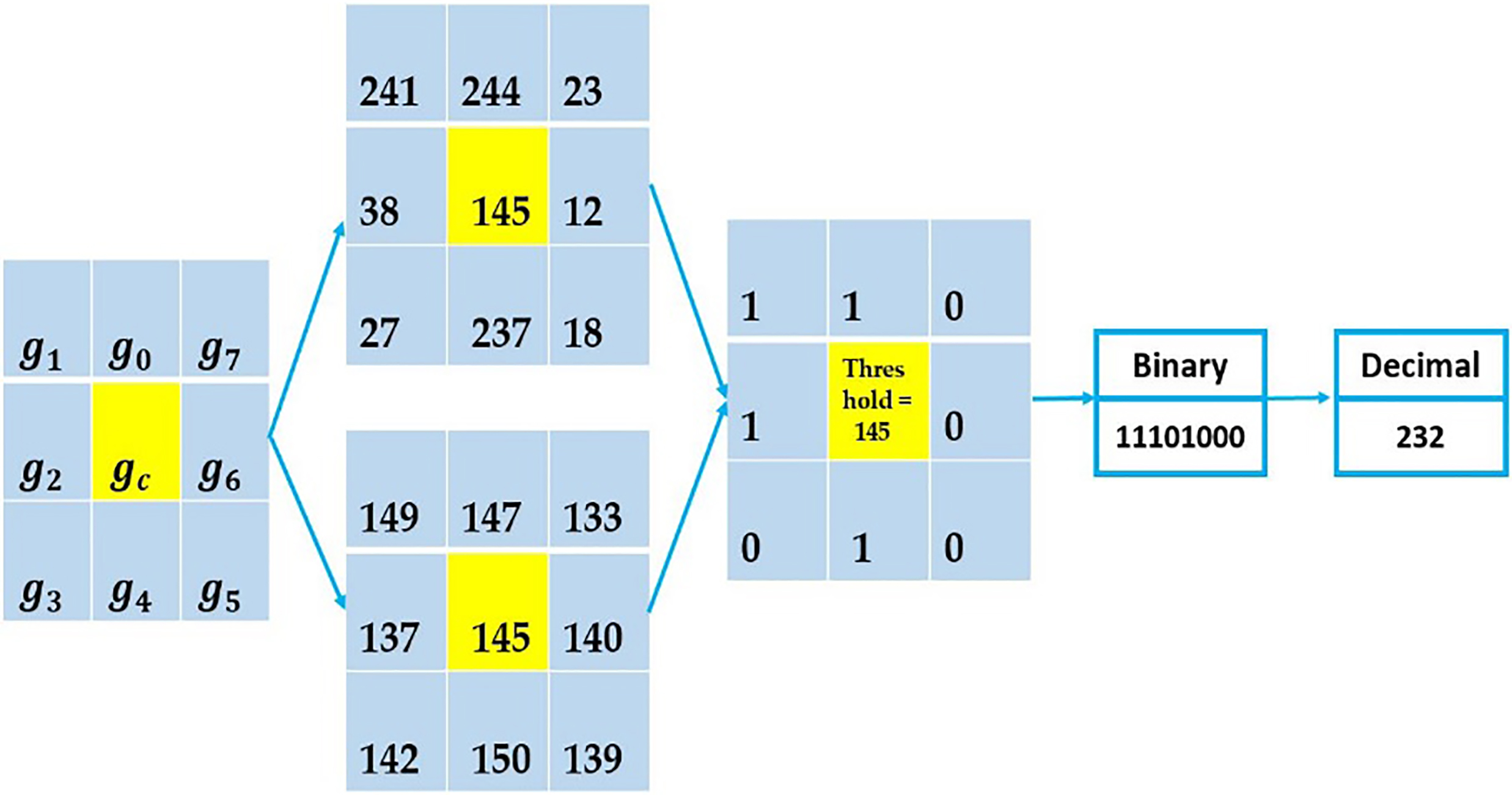
The idea of local binary patterns (LBP) [21] was suggested by Ojala et al. for the first time in order to measure the differences between a given pixel and its neighbor pixels for texture classification task. LBP is well-known to be an exceptional texture descriptor and invariant to monotonic gray level changes [22]. Furthermore, it is a highly discriminative operator [23]. LBP is based on differences of a given pixel and its neighbor. For instance, for 9 pixels, where the gray value of the center pixel is considered as a threshold, if a neighbor pixel has a lower gray value than the center pixel then a zero is assigned to that pixel, else it gets a one. Afterward, the LBP code for the center pixel is generated by concatenating the obtained zeros or ones to a binary code. The original LBP operator is defined as [21]:
Where
Although original LBP is a strong texture descriptor, in some cases performs poorly. For example, two simple 3*3 LBP descriptors are illustrated in Fig. 3. As is obvious, they have different local structures but have the same LBP vector which is not reasonable.
Two simple 3*3 modified LBP descriptors.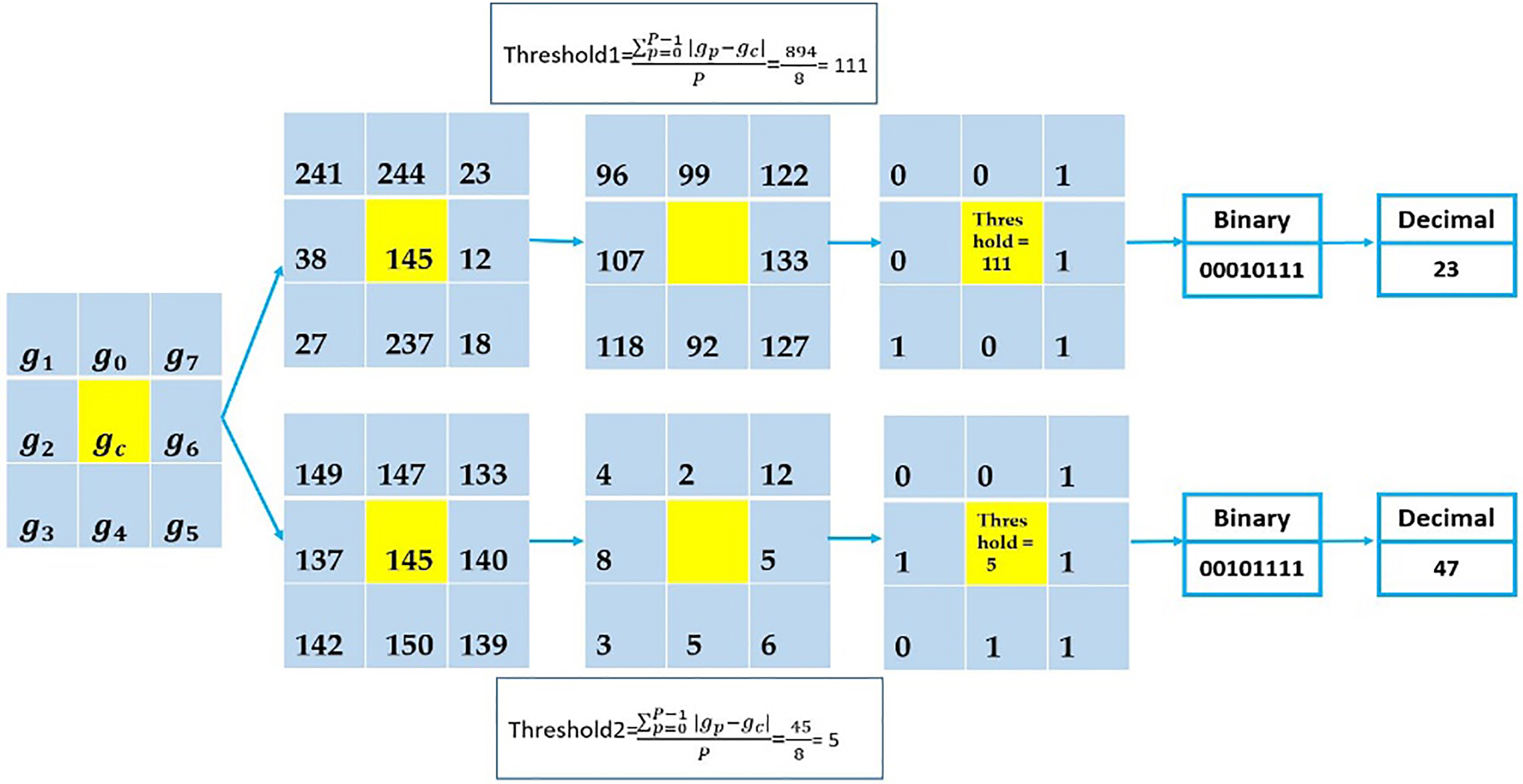
The process of modified LBP feature extraction from an input image. 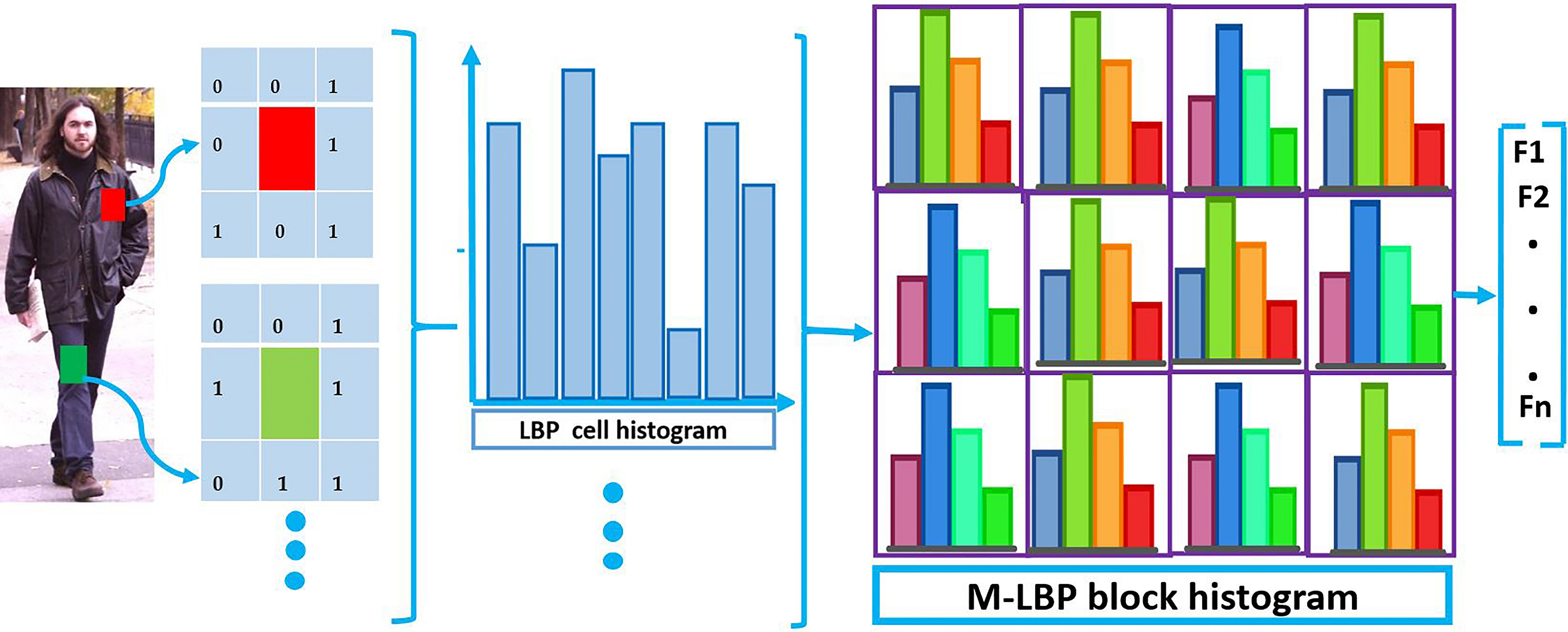
To eliminate this drawback, we suggest a modified LBP (M-LBP). As mentioned earlier, in the original LBP the gray value of the center pixel is considered as a threshold. However, in our modified LBP the mean value of the neighborhood magnitude space is defined as a threshold. Our modified LBP operator is defined as:
Where
After extracting different M-LBP codes for a specified image region, its histograms can be produced by counting the frequencies of each value of M-LBP codes. Finally, the M-LBP histograms, obtained in various blocks of histograms, are collected in a feature vector and are utilized as information for more accurate classification in the next step [38]. This process is shown in Fig. 5.
The modified Haar-like features.
A sample of employing modified Haar-like features on an input image. 
Haar-like features were suggested by Viola and Jones [24] for rapid object detection. These features are an over complete set of two-dimensional Haar functions. It can be employed to discover the local appearance of objects [24]. These features include two or more rectangular regions. The principal reason for the utilization of the Haar-like features is that they effectively capture different image details and prepare a very attractive trade-off between accuracy and speed of evaluation [2]. The logic behind its high speed of calculation is applying integral images [24] which can be utilized to quickly assess any Haar-like features at any scale. It is described by the boundary box of its white regions and black regions with opposite signs. The features, indicated by
Where
Because of the complexity in cloth and appearance, the human shape cannot be explained completely through the original Haar-like features. Thus, we improve rectangular features in our modified Haar-like features, as shown in Fig. 6. These added various rectangular features, can precisely explain local human shape. The human local parts in tilted positions of rectangular characteristics are ignored to make the computation simpler. A sample of extracting the M-Haar-like features from a pedestrian is illustrated in Fig. 7. The modified Haar-like features are multi-scaled to explain the human’s local area easily.
Analysis of feature descriptors
A comparison of different number of weak classifiers on INRIA, Daimler, and ETH datasets

Miss rate of previous pedestrian detectors on three datasets
After extracting M-Haar-like features, a cascade classifier is used since it can acquire high accuracy rate while dramatically reducing computation time. Each classifier in the cascade is learned to obtain high detection rates and modest false positive rates [24]. In this process, simpler classifiers with a small number of features are located earlier and complex classifiers with a plethora of features are located later [24]. The cascade classifiers inspired by a decision tree [7, 24]. As is obvious in Fig. 7, in feature cascading phase, a positive outcome from the first sub-classifier starts the assessment of a second sub-classifier which has also been optimized to obtain the best M-Haar features. A positive outcome from the second classifier starts the third classifier, and so on. A negative result at any stage propels to the refusal. Stages in the cascade are created by training classifiers employing AdaBoost and then optimizing the threshold to minimize the false negatives. After feature cascading, the best-selected M-Haar features are sent to the final classifier named Adaboost classifier. It will be discussed in the following sections in more depth.
At this section, the extracted features including HOG, M-LBP, and M-Haar like features are aggregated together. It is expected to achieve a new feature with powerful description ability. As shown in Table 1, with the exception of HOG, other descriptors (Our proposed M-Haar and M-LBP) need to compute the difference operator captured by subtraction between the pixels of image blocks. HOG descriptors are constructed on the basis of gradient values, and they need to convolve with filters in order to obtain the pyramid scale space. HOG descriptor compute histograms through the angle interval of pixels, but the proposed M-LBP features need to project the outputs into their own templates. Except for the proposed M-Haar like features, M-LBP and HOG features require histogram computation. Table 1 illustrated that HOG features contain three operators except difference operator. When HOG, M-LBP, and M-Haar features are aggregated, the new achieved combined features comprise all the four operators. Actually, it is expected that human shape can be completely recognized if the texture information, the edge information, and the local shape information are mixed together.
Sample detection on images. The blue boxes, black boxes, yellow boxes, and red boxes depict detected pedestrians through using only M-LBP feature, only HOG feature, only M-Haar-like feature, and our suggested method (HOG, M-LBP, and M-Haar), respectively.
continued.
In order to assess the performance of the proposed method, a dataset is required. Therefore, the INRIA dataset [25], the Daimler datasets [32], and the ETH dataset [33] are considered as our database. The reason of the selection of these three datasets is that INRIA, Daimler, and ETH databases are more diverse and complex compared to other limited datasets, such as MIT, NICTA, and CVC datasets.
Our detection approach is implemented in Matlab 2016 on Windows 8 with 2.50 GHz Intel Core i7 4870HQ, 64 bit and 16 GB RAM.
According to the PASCAL measure [34], the detection is true if the overlap of the ground truth annotation and the detection bounding box is more than 50%:
Where
After combining HOG, the proposed M-LBP, and the proposed M-Haar like features, Cascade AdaBoost algorithm [2] is applied for classification. Intuitively one would expect more weak classifiers cause higher accuracy rate because decision boundaries become more precise. However, too large number of weak classifiers may create overfitting of the training data. We adjust the number of weak classifiers to 32, 64, 128 and 256 alternatively. The best result is achieved when the number of weak classifiers is 128 which obtains 7%, 17%, and 27% miss rates for INRIA, Daimler, and ETH respectively. Table 2 illustrate the miss rates of different number of weak classifiers. Detection accuracy starts to decline gently when the number of weak classifiers is more than 128 because of over fitting.
A question which may be raised here is that why we choose HOG, M-LBP, and M-Haar-like features among other existed features? In order to provide further legitimacy of choosing these features, we combined HOG-M-LBP for the first time, HOG-M-Haar-like features for the second time, and M-LBP-Haar-like features for the third time and compared the accuracy of these combined-features. The obtained results in Table 3 illustrates the superiority of our method in comparison with the above-mentioned combined features. In addition, another question which often raised is whether there is any logic behind the selection of cascade-AdaBoost as our classifier or not? We used SVM classifier and compared its result with our suggested classifier. The achieved results in Table 3 denotes that using cascade AdaBoost can lead us toward a high detection accuracy rate in comparison with SVM classifier.
It is important to note that that deep learning and Convolutional Neural Networks (CNNs) has revolutionized the object detection methods [6] and recent researches on the solution of pedestrian detection which used this approach are no exceptions to achieved high accuracy with real-time running [6, 42, 43]. However, our proposed method successfully outperformed the previous feature-based methods as illustrated in Table 3.
Using three various datasets (INRIA, Daimler, ETH), we can not only enrich our dataset extensively, but also evaluate the robustness and precision of the proposed method comprehensively. The image of these datasets contains abrupt illumination, different human shape, and cluttered backgrounds but our method has the ability to detect pedestrians in these challenges situations which is another advantage of it. Figure 8 display some sample results of pedestrian detection. In Fig. 8, the blue boxes, black boxes, yellow boxes, and red boxes depict detected pedestrians through using only the proposed M-LBP feature, only HOG feature, only the proposed M-Haar-like feature, and our suggested strategy (combination of HOG, M-LBP, and M-Haar like features), respectively. Indeed, for one time, only the M-LBP features are extracted from images and then these extracted features are sent to the AdaBoost classifier to detect pedestrian (blue boxes). For the second time, only the HOG features are extracted from input images and sent to the AdaBoost classifier to detect pedestrians (black boxes). For the third time, only the M-Haar-like features are extracted from input images and feed to the AdaBoost classifier to detect pedestrians (yellow boxes). For the fourth time, the extracted HOG, M-LBP, M-Haar-like features are sent to the AdaBoost classifier and pedestrians are detected through our method (red boxes). As illustrated in Fig. 8, each of the aforementioned features alone performs poorly. However, the combination of these features achieved higher accuracy and lower miss rate because it contains gradient, difference, convolution, and histogram operators, which are supplementary with each other. We do not provide an exhaustive comparison of runtimes among state-of-the-art detectors in this work because various detectors are implemented on various machines, some even heavily rely on GPU computations [38]. It, therefore, does not make much sense to list runtimes from different computing architectures. However, our method can be readily and efficiently implemented with high speed and low computational time.
Conclusion and future work
In this contribution, a precise pedestrian detection method was suggested. The first novelty of this investigation was improving two original features named as modified local binary pattern (M-LBP) and modified Haar like features (M-Haar like features). Then these features were combined with the HOG features as the most famous descriptor in feature-based pedestrian detection methods. Another positive aspect of this work was adopting three different datasets (INRIA, Daimler, and ETH). Each dataset was recorded in various environments, resolution, background occlusion, and light condition. Thus, by employing three different datasets, we can evaluate the robustness and precision of the proposed method comprehensively. The extensive experimental results denoted that our suggested approach obtained better detection-rate and accuracy compared to the traditional feature-based pedestrian detection methods. Considering the widespread success of deep learning and CNNs in object detection methods, we will focus on employing deep learning techniques or combining it with our method in pedestrian detection systems and try to achieve better results.