
Abstract
The comprehensive models can be used for software quality modelling which involves prediction of low-quality modules using interpretable rules. Such comprehensive model can guide the design and testing team to focus on the poor quality modules, thereby, limited resources allocated for software quality inspection can be targeted only towards modules that are likely to be defective. Ant Colony Optimization (ACO) based learner is one potential way to obtain rules that can classify the software modules faulty and not faulty. This paper investigates ACO based mining approach with ROC based rule quality updation to constructs a rule-based software fault prediction model with useful metrics. We have also investigated the effect of feature selection on ACO based and other benchmark algorithms. We tested the proposed method on several publicly available software fault data sets. We compared the performance of ACO based learning with the results of three benchmark classifiers on the basis of area under the receiver operating characteristic curve. The evaluation of performance measure proves that the ACO based learner outperforms other benchmark techniques.
Introduction
Software quality improvement method includes code inspections, design walkthroughs, prototype simulation, and measurement-based analysis. In order to improve the quality of high assurance software, prior identification of low-quality modules will provide enough time to design and testing team for focus on those modules. One of the tasks of the quality models is to identify the number of faulty modules in software also the risk category it belongs to, e.g., fault-prone (fp) or not-fault-prone (nfp). Software quality prediction is supportive for better exploitation of resources and to undeviating efforts to software modules with higher risk. Hence, it helps in reducing the cost by early assessment of faults also helps in the prior planning of testing the software modules that are likely to be fault-prone during operations. Machine learning approaches have been extensively used for software fault prediction (SFP) for quality modeling, such as Logistic Regression, Naive Bayes softcomputing [1], hybrid artificial neural network (ANN) and Quantum Particle Swarm Optimization (QPSO) [2].
Ant colony optimization (ACO) is one of the nature-inspired computing techniques which deciphers the problem by simulating the behaviors of real ant colonies. ACO can be used for classification and rules extraction to solve real-life problems. The goal of ACO based learning is not only to discover accurate knowledge but also interpretable rules for the user.
Comprehensibility is important whenever discovered knowledge will be used for supporting a decision made by a human user. Ant colony based software fault prediction model have been used for comprehensive rule generation. The proposed model has a higher accuracy rate and results are comprehensive and easily interpretable by software managers and developers.
The rule base generated by ACO is expressed in the form of IF-THEN rules, as follows: it IF
The rule-based generation by ACO classification can guide the user in an intuitive comprehensible way [3].
The rest of the paper is ordered as follows. Section 2 presents a brief overview of related work. Section 3 discusses the main characteristics of ACO algorithms. Section 4 introduces the software projects used in this study. Section 5 devoted to experimental design and Section 6 reports the performance of the proposed algorithm in terms of accuracy and area under the Receiver Operating Characteristics Curve (AUC). Also, comparative studies with benchmark machine learning algorithm across nine data sets have been performed. Finally, conclusion and directions for future research are given in the closing section.
Related work
Machine learning techniques have been extensively used to build software fault prediction models in the domain of software quality. Software metrics as a software quality indicator is used by researchers for the prediction of faulty and not faulty modules. Some of the recent studies in the field are:
An Eclipse-based SFP tool for Java programs using Naive Bayes as a plug-in is developed to present a practical view to software fault prediction problem to show the effect of combined software metrics with software fault data [4].
Czibula et al. have proposed a novel classification model based on relational association rules mining for software fault prediction [5]. Erturk and Sezer have applied an Adaptive Neuro-Fuzzy Inference System (ANFIS) for the software fault prediction problem [1]. Abaei et al. have automated software fault detection model using semi-supervised hybrid self-organizing map (HySOM). HySOM is a model based on artificial neural network and self-organizing map. The HySOM is able to predict defect prone (dp) or not-defect-prone (ndp) modules in a semi-supervised manner using software measurement threshold values in the absence of quality data. In semi-supervised HySOM, the role of expert for identifying fault prone modules becomes less critical and more supportive [6]. A new software defect prediction model based on atomic class-association rule mining (ACAR) is developed using data preprocessing and rule model building for improved defect prediction. They demonstrated that ACAR is better than CBA2 in terms of AUC, G-mean, Balance, and understandability. In addition, the average AUC of ACAR is increased by 2.9% compared with CBA2 [7].
Various ant based approaches have been developed for classification and rule generation for different applications. In particular [8] new ant-based classification technique is proposed, named AntMiner
In this work, ACO based learner is trained using modules metrics and fault data in order to generate a rule based expert system to classify the faulty and not faulty software module. In this paper, we demonstrate the application of ACO for rule extraction and its subsequent use for software fault classification.
The main contributions of our empirical study are highlighted in the following aspects:
An attempt to perform ACO based rule generation using ROC measure as the objective function for the quality of rule and empirical study with feature selection methods. Extensive experiments on the Promise repository dataset and AEEEM datasets with a comparative study to prove the effectiveness of the proposed model over the other state-of-art techniques.
An ACO is a system based on reproduction of the usual behavior of ants, including mechanisms of collaboration and adaptation. ACO is an optimization technique based on the investigation of the foraging behavior of ants [15].
Ant colony-based learning algorithm.
Ant colony based optimization techniques are used to solve numbers of problems ranging from the Traveling Salesman problem to the difficult data clustering and classification problems. Parpinelli et al. [3] have proposed a novel algorithm called Ant-Miner., for data mining tasks. In this work, the concept of Ant-Miner algorithm has been adopted to obtain the comprehensive rules that can be used by software developer as the necessary guideline for identification of faulty and not fault-prone modules. Ant-Miner algorithm’s brief introduction is given below.
In an ACO algorithm, each ant incrementally constructs/modifies a solution for the target problem. In our case, the target problem is the discovery of comprehensive rules for software fault prediction. As discussed in the introduction, each classification rule has the form
IF
Each term is a triple
In order to remove extraneous terms, rule Ri constructed by Ant
No of constructed rules If no more features to be added to the rule antecedent.
After the outer loop is completed, the preeminent rules extracted by all ants are added to the category of revealed rules. The reinitializing of all trails with an equal quantity of pheromone is performed for the new iteration of the inner loop.
In standard definition of ACO [15], a population is defined as the set of ants that build solutions between two pheromone updates. Next we present the rule generation process.
Let term
Where
The entropy of every term is calculated as follows
Where
After computation of the entropy of the terms, the heuristic value
Where
After an ant discovers a rule and the rule is pruned, the pheromone level of each of the terms in the rule is incremented by a factor of the rule’s quality. The rule’s quality is computed empirically on the set of remaining uncovered training examples using the ROC. ROC analysis is commonly applied in visualizing model performance, decision analysis, and model combinations with great scope and applications. As the performance index of a classifier, the AUC of a ROC can be calculated as follows [13, 14].
where
Where
Ant
Any term All features
Characteristics of the software fault data set D’
In the experiments, we have used the following parameter for rule generation. No of ants equal to 3000, Min cases per rule is 10, and Maximum uncovered cases are 10.
In order to predict software fault of the module, the discovered rules are applied in the manner they were identified. The case is assigned the class predicted by the first rules consequent. There may be a possibility that no rule of the list covers the new case. In this circumstance, the new case is predicted as the majority class by a default rule.
To evaluate the effectiveness of our approach, we used software fault dataset in the study originate from the public PROMISE data repository [15]. To investigate whether dataset types affect the conclusions that are drawn from the NASA dataset, we also used four projects of AEEEM dataset [16]. This dataset was developed in a different setting compared with the NASA dataset and performs defect prediction at the class level. Features in AEEEM dataset include source code metrics, such as the change metrics, source code metrics, and the entropy of source code metrics and churn of source code metrics. The only common metric between NASA and AEEEM datasets is lines of code. Table 1 shows the statistical information of the software projects used in the first and second experiments. Table 4 shows the statistical information of AEEEM projects used in experiment3.
Experiment design
To evaluate the performance of Ant colony based miner and compare it with other benchmark machine learning algorithms we set up the experimental study as follows.
AUC comparison learning schemes for D’ dataset
AUC comparison learning schemes for D’ dataset
We have conducted three experiments to show the effectiveness of the proposed ant based system. The first one is on the data set shown in Table 1. In this, we performed the proposed ACO based classification and compared the results with the other benchmark algorithms like J48, Naïve Bayes and Random forest. Figure 2 shows the proposed model and the implementation steps in the block diagram. The result of experiment one is shown in Table 2. Feature selection has been widely used in machine learning tasks to make a model with a small number of features which improves the classification accuracy. In recent years, a large number of feature selection approaches have been proposed. In experiment 2 we have investigated the effect of feature selection by selecting the top five features and passing them to the machine learning algorithms.
Implementation of the proposed software fault prediction model.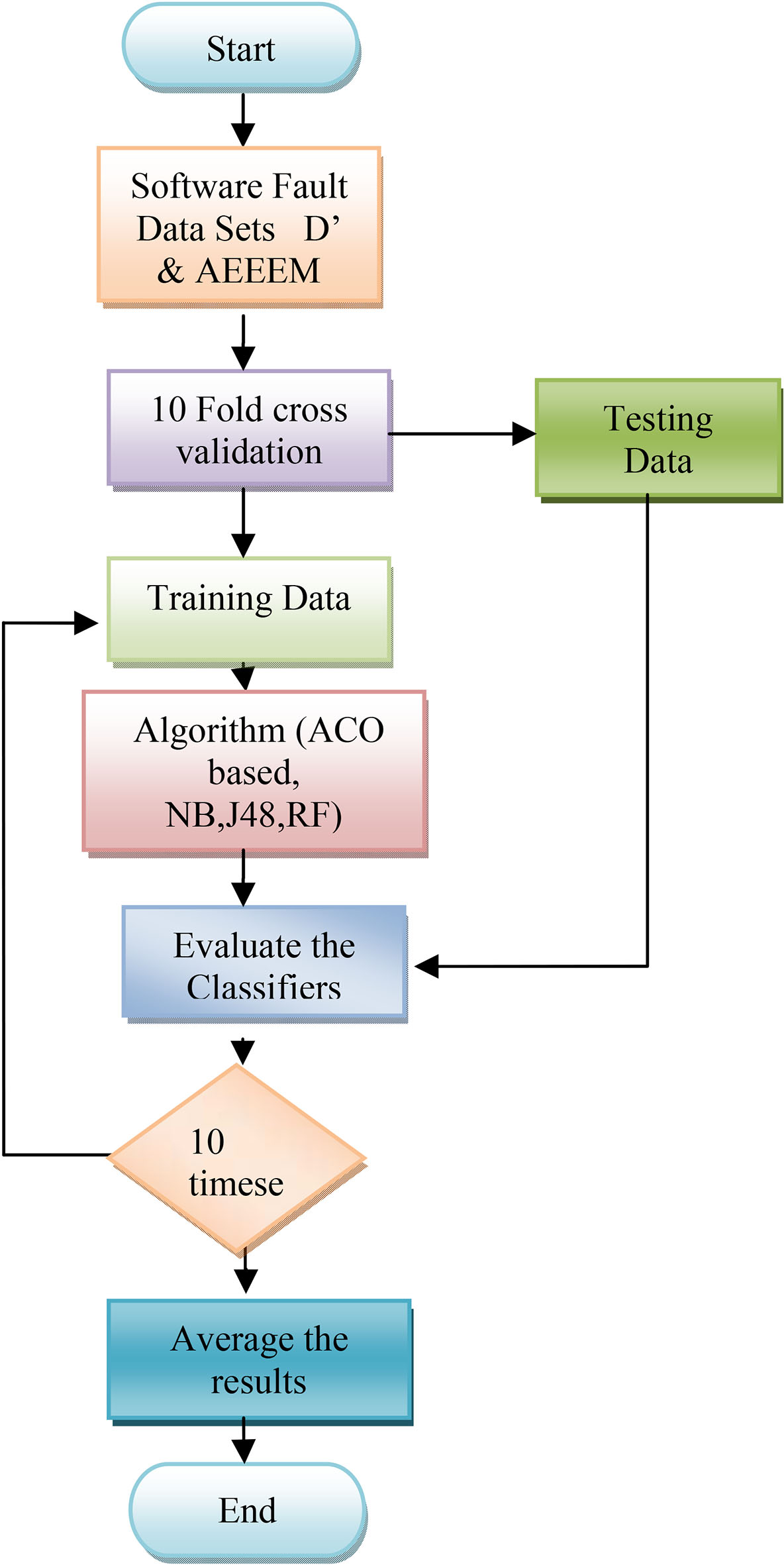
In order to compare with the effect of features, we have employed mRMR (minimum redundancy maximum relevance) method feature selection technique. We first extracted the top five features from all N source {s1, s2, …, sn}, using chosen “mRMR” [17] (minimum redundancy maximum relevance) method. This method selects features, without using any classification algorithm. It takes the whole set of features X, the subset S of m features that has the maximal relevance criterion is the subset that satisfies the maximal mean value of all mutual information values among individual features, and the equation is:
The subset
Thus, the complete “mRMR” feature selection is:
Where,
The equation shows the mutual information values among the feature
Top five features are selected from D’ dataset, and a comparative study is performed to investigate the effect of features in classification. Table 3 shows the result of the comparative study with top five selected features. The goal of our approach is to build a high-quality training set from the original dataset, which may contain the most important features with the objective to improve the performance of classification models used for SFP.
Finally, in the third experiment, we have employed the proposed approach on the AEEEM data set which consists of include source code metrics, such as the change metrics, source code metrics, the entropy of source code metrics and churn of source code metrics.
The implementation of the proposed model is illustrated in Fig. 2, where 10-fold cross-validation is used to evaluate the performance of the algorithms.
Given training software fault dataset
such that
The detailed process is described with pseudo code in the following procedure (Fig. 3), which consists of other benchmark learning algorithms.
Software fault prediction model evaluation.
To get fairer and more informative measure than comparing their misclassification rates area under receiver operating characteristic (AUC) is used in this study. Operating Characteristic (ROC) curves compare the classification performance by plotting the TP rate on y axis and FP rate on X axis across all the possible experiments. A typical ROC curve has a concave shape with (0, 0) as the beginning and (1, 1) as the endpoint. The ideal point on the ROC curve would be the one when no positive examples are classified incorrectly and negative examples are classified as negative. Every model gets different values for area under curve. AUC is used to get the complete order of model performance and is independent of the decision criterion selected and prior probabilities. The AUC comparison can establish a dominance relationship between classifiers [18]. The bigger the area under the curve, the better the model is. As opposed to other measures, the area under the ROC curve (AUC) does not depend on the imbalance of the training set [19].
All the results of the comparison were obtained using Intel core
In this section, we present the experimental results in terms of the area under the receiver operating characteristic (ROC). Table 2 records the result of nine projects. It can be seen that out of nine ant miner has outperformed in eight cases when compared with the Naïve Bayes, nine out of nine in case of J48 and seven out of Nine in case of Random Forest. For CM1 Ant-based classification algorithm has outperformed than Naïve Bayes and J48. KC1, KC3, MW1 PC1, PC2 and PC3 also has the best accuracy result for Ant-based classification algorithm in comparisons with all other algorithms. From Table 2, it can be observed that ACO is outperforming in terms of average AUC for D’ dataset.
Let us now look at the type of rules extracted by the Ant-based system in a typical run for the PC1 data set.
IF PERCENT_COMMENTS IF NUM_OPERATORS IF LOC_CODE_AND_COMMENT IF LOC_TOTAL IF CONDITION_COUNT IF CYCLOMATIC_COMPLEXITY IF BRANCH_COUNT
The framework provides a set of intuitive and comprehensible rules for the user and can provide insights into the process.
Comparative analysis using radar chart.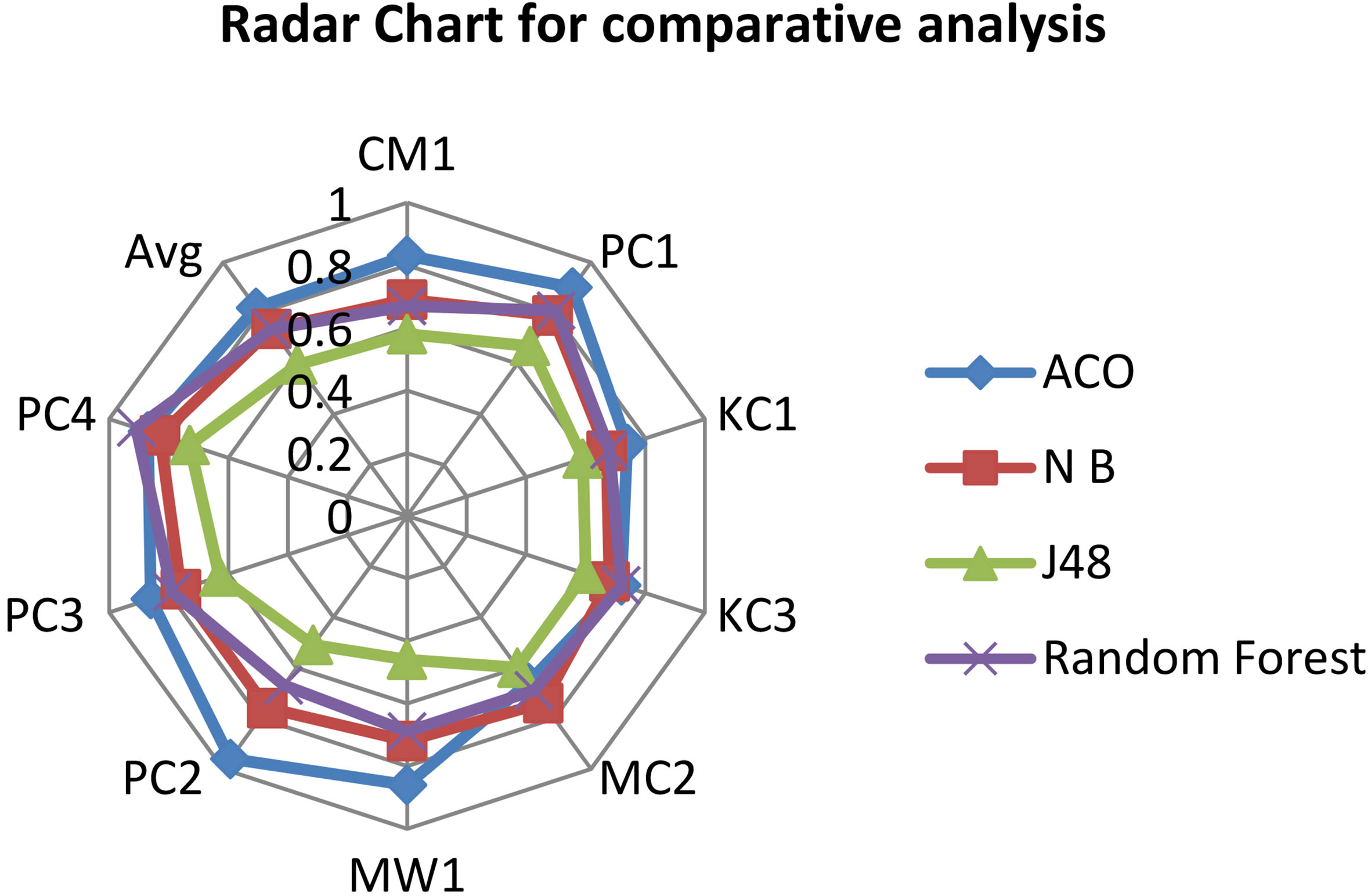
Form the comparative analysis; it can be seen that ACO is outperforming with other benchmark algorithms and also provides comprehensive rules. Figure 4 shows the radar chart to show a better view of the overall performance of the proposed model.
The results of experiment 2 with five best feature selected by mRMR (minimum redundancy maximum relevance) method feature selection technique is shown in Table 3.
AUC comparison learning schemes for D’ dataset with five best features
It can be seen that out of nine ant miner has outperformed in eight cases when compared with the Naïve Bayes. Comparing column 2 and 4 we find that 9 out of 9 cases the ACO rule perform better than J48 Algorithm. Comparing column 2 and 5 we find that 6 out of 9 cases the ACO rule perform better than Random Forest Algorithm. From Table 3, it can be observed that ACO is outperforming in terms of average AUC for D’ dataset. Also by comparing the results of Tables 2 and 3, it can be seen that the average performance of ACO is improved whereas the performance of all other three algorithms slightly degraded.
In order to show the effectiveness of the proposed algorithms experiment 3 is performed on AEEEM dataset. The properties od AEEEM dataset is shown in Table 4. The results of experiment 3 on data set with different metrics set used from the NASA projects is shown in Table 5.
Projects in AEEEM dataset
AUC comparison learning schemes for AEEEM dataset
It can be seen from Table 5 that out of five ant miner has outperformed in all five cases when compared with the Naïve Bayes. Comparing column 2 and 4 we find that 5 out of 5 cases the ACO rule perform better than J48 Algorithm. Comparing column 2 and 5 we find that 3 out of 5 cases the ACO rule perform better than Random Forest Algorithm. From Table 3, it can be observed that ACO is outperforming in terms of average AUC for D’ dataset. Also, it proves that the ACO based learner is outperforming not only nine NASA datasets but also on the other AEEEM dataset.
In this paper, an investigation is performed on the software fault data by using ACO based classification algorithm with the objective of improving the rule quality with of ROC. Lessmann et al. [10] argued that the assessment of fault prediction techniques should not be done just by the performance of the predictor. The other factors to be considered are computational complexity, ease of use, and, more importantly, comprehensibility of the predictor. The proposed system has not only outperformed in the performance of AUC but also fulfills all other properties especially the comprehensibility. The effectiveness of the method is demonstrated using data sets from the PROMISE repository and AEEEM datasets. To generate the best rule base, we have used AUC for rule quality updation. The proposed method selects the best software metrics and generates rules using these important software metrics to achieve better performance. The results of our experiments demonstrate that the proposed ACO rule-based classification approach achieved better performance than C4.5, random forest learner, and Naive Bayes classifier. Also, our model is a better choice compared to other opaque models for gaining insight about different factors which drive software faults. This approach provides intuitive rule which can be used as a software quality system. This provides the system designer and developer to follow a set of rule in design and development. In future work, we plan to modify the algorithm in such a way that it generates more interpretable rule sets for categorization of software faulty modules.
Footnotes
Acknowledgments
This research is partially supported by the Chhattisgarh Council of Science and Technology (CGCOST) under Grant 8068/CCOST. The author would like to acknowledge the support of the funding organizations.