
Abstract
BACKGROUND:
Fault data is vital to predicting the fault-proneness in large systems. Predicting faulty classes helps in allocating the appropriate testing resources for future releases. However, current fault data face challenges such as unlabeled instances and data imbalance. These challenges degrade the performance of the prediction models. Data imbalance happens because the majority of classes are labeled as not faulty whereas the minority of classes are labeled as faulty.
AIM:
The research proposes to improve fault prediction using software metrics in combination with threshold values. Statistical techniques are proposed to improve the quality of the datasets and therefore the quality of the fault prediction.
METHOD:
Threshold values of object-oriented metrics are used to label classes as faulty to improve the fault prediction models The resulting datasets are used to build prediction models using five machine learning techniques. The use of threshold values is validated on ten large object-oriented systems.
RESULTS:
The models are built for the datasets with and without the use of thresholds. The combination of thresholds with machine learning has improved the fault prediction models significantly for the five classifiers.
CONCLUSION:
Threshold values can be used to label software classes as fault-prone and can be used to improve machine learners in predicting the fault-prone classes.
Introduction
Software testing is a challenging activity that is necessary to find faults in systems. Software testing is a costly activity that requires a large amount of software production effort (i.e., between 50 to 70 percent) [3, 12]. In addition, software systems are becoming larger and more complex. Therefore, software quality assurance efforts are increasing and software testing teams need to be larger. Furthermore, the exhaustive testing of software is impractical for large systems. Therefore, software testers need to allocate testing resources effectively and efficiently. Software testers need to use code analysis tools to measure fault-proneness of classes using software metrics and direct the testing efforts to such classes.
The fault-proneness refers to the probability of faults in a particular class. The fault-proneness models are either machine learning or statistical models. Building fault-proneness prediction models requires a dependent variable (i.e., fault-proneness) and many independent variables (i.e., software metrics). Instances of values closer to 1 are more fault-prone than otherwise. Therefore, the dependent variable is a binary variable of two values, faulty for the classes that have at least one fault and non-faulty otherwise. The independent variables are the software metrics that measure the internal software quality. Improving the performance of fault-prediction models helps the software testers in allocating resources more accurately.
A static analyzer collects quantitative measures of the internal software quality such as complexity, coupling, cohesion, inheritance, and class responsibility. Internal quality of software systems is measured using metrics that were linked with many external quality attributes such as fault-proneness. Software metrics were validated as predictors of fault-proneness of code using machine learning and regression techniques [2, 22, 23, 24, 34, 40, 47, 49]. Examples of prediction models include decision trees [12, 15, 35], naïve Bayes [52], and logistic regression [2].
Most reported fault data in literature show imbalance, i.e., faulty classes are the minority while the majority of classes are not faulty [38, 48]. One important reason of data imbalance could be that software testing coverage was incomplete or that the time was not sufficient for the testing team. Therefore, many faults are expected in systems and many classes can be labeled as fault-prone even if these classes were not reported in the first place as such by the developers and the testers. If the fault-prone classes can be identified amongst the unlabeled classes, improvements are expected on reducing the data imbalance and consequently, the fault prediction performance can be improved as well. The classes that are complex and fault-prone but not reported as such hinder the fault-prediction models. Therefore, there is a need to improve the datasets, which improves the performance of prediction.
Software components were found correlated with high measurements such as high coupling, high lack of cohesion, large complexity, and large classes. High measurements increase the fault-proneness of classes. Software thresholds can provide these indicators to the fault prediction models. Thresholds for these metrics can be used to identify the classes that are highly complex and fault-prone.
Metric thresholds were identified in the literature as reference points at which fault-proneness increases [14, 41, 50]. Therefore, thresholds are usually used to label classes as faulty for further quality investigation. In previous literature, all derived thresholds were set such that large values are fault-prone whereas smaller values are not. Threshold values are used in this work to improve fault-prediction performance. The datasets quality is improved by identifying the classes where metric values exceed particular thresholds that were reported as non-faulty.
There are many threshold identification techniques that were reported in the literature. In this research, three threshold identification techniques [14, 41, 50] are used to mark classes as faulty if they exceed threshold values. These techniques derive thresholds for software metrics using statistical parameters such as the mean and the standard deviation. These techniques are selected for various reasons, first, the three techniques were validated on a large benchmark. Most systems used as benchmarks were large in size and coming from different application domains. Second, these techniques are simple and easy to use by software engineers. Third, these techniques are easy to repeat on future data.
The proposed research improves the quality of fault data. Threshold values are used to target the classes that are marked as not faulty. The non-faulty instances are separated using thresholds into two parts: classes that are larger than thresholds and classes that are lower than thresholds. Classes selected by thresholds are unlabeled and removed from the dataset waiting for further investigation. The labeled datasets are used to build fault prediction models. These models are then used to test the unlabeled instances. The results of testing are used to improve the fault datasets. An instance that is predicted as faulty is labeled as such, whereas the instances that are predicted as not faulty are kept non-faulty.
Our contribution to fault prediction research is summarized as follows:
We propose easy to use three threshold identification techniques to label classes and to reduce data imbalance. The results of threshold identification techniques are used to improve the quality of the datasets. The improved datasets are used to build five fault-prediction models.
Therefore, this research answers three research questions:
RQ1: Does traditional learning suffer under data imbalance? RQ2: Does using thresholds reduce the data imbalance in fault data? RQ3: Does using thresholds improve the fault prediction models?
In the rest of the paper, the related work is discussed in section two. Study design and research methodology are described in Section three. Results analysis is presented in section four to answer the three research questions. Study limitations are briefed in section five. Finally, the work is concluded in section six.
This research combines the use of fault prediction with the threshold values to improve the fault-prediction models on imbalanced datasets. In the following, we discuss the three important aspects of fault prediction models.
Fault prediction in literature
There is a plethora of research on the relationship between faults and software metrics [23, 26, 37, 45, 51]. Software metrics are utilized for predicting faulty parts in current and future releases of software. Different sets of software metrics have been validated as predictors of fault-proneness including [25, 30, 45, 53]. However, The Chidamber and Kemerer metrics were the most studied among all [38, 39]. In a systematic review, Malhotra has found C&K useful metrics for predicting fault-proneness. Therefore, this research focuses on the use of C&K metrics only for fault prediction.
Previous works on C&K metrics [45] have found an empirical association with fault-proneness [23], fault counts and fault categories [44]. Researchers have built empirical fault prediction models using several methodologies, including statistical models [23, 25, 40], and machine learning models (for example, neural networks, and classification trees) [35]. Such studies on fault-proneness categorized software classes into several groups based on the number of faults in a class. Usually, classes are divided into two groups: faulty classes that had one or more faults in the current release under investigation, and not faulty classes that did not have any faults [35].
Some other researchers used the severity of faults to create several categories (low, medium, and high) [40]. These researchers used the bug repository to extract the information on the severity of bugs as proposed by the developers and the testers of open-source systems. The authors could build sound and plausible models using the severity levels
Fault data quality
The fault prediction models are used for binary variables in most published work because of the data imbalance and the low variability in the number of faults uncovered in classes. Data imbalance degrades fault prediction performance [18]. Folleco et al. also reported that noise has a large effect on classifiers’ performance [1]. Both studies in [1, 18] have shown that noise in the minority class (faulty instances) has a more detrimental effect on classification performance than noise in the majority class (non-faulty). Gray et al. noted that NASA metrics data needs significant preprocessing before inclusion in machine learning algorithms [9]. They suggested many preprocessing techniques to eliminate parts of the data such as removal of repeated attributes, removal of repeated and inconsistent instances, and enforcing metrics integrity. Gao et al. conducted many sampling techniques followed by feature selection techniques to improve the effectiveness of the software fault prediction [21]. Dallal studied the effect of special methods (such as constructors, destructors, and access methods) on measuring cohesion of classes [16]. Dallal conducted an empirical study to find the effect of including/excluding these special methods for refactoring and predicting faulty classes [16]. The results showed significant differences in cohesion measurements and significant effects on refactoring prediction but no significant effects on fault prediction. Recently, Song et al studied the data imbalance using extensive techniques and found significant improvements in fault-prediction models [38]. Therefore, researchers have used techniques such as oversampling and undersampling to improve the performance of the predictions [7, 38]. Other techniques were also employed including semi-supervised learning and feature selection [2]. Data imbalance could happen because of class noise which can be attributed to either data entry errors or insufficient information used to label instances [17]. In this work, we aim to reduce the data imbalance by using threshold values to increase the instances in the minority class. Thresholds are used to label instances as faulty if they exceed particular threshold values and if the prediction models confirm the outcome.
Thresholds techniques
The work on fault prediction was extended to include the derivation of threshold values on software. Threshold values are usually used to separate instances into two groups, faulty or not. Threshold values separate between good quality and low quality types in the system. Some researchers have used advanced techniques such as the logistic regression to derive thresholds [39, 42, 44]. The logistic regression technique requires having the fault data in advance to build fault prediction models and then thresholds are derived from the parameters of the logistic regression. The logistic regression was not successful in all studies. Thresholds were identified for some metrics in [42] and no thresholds were identified in [44]. The logistic-based thresholds were also derived again in [39] for object-oriented metrics and thresholds were used in prediction models.
Shatnawi et al. have proposed to derive thresholds using the Receiver Operating Characteristic curve (ROC) [43]. Catal et al. have employed the ROC technique to detect outliers and labeling non-faulty classes as faulty to improve fault predictionperformance [6]. The ROC technique requires knowing which classes are faulty and which are not in advance. The use of thresholds resulting from ROC analysis are affected by fault data which are also used to train and test the prediction models. These models may have a confounding effect as the same data are used to derive thresholds and build the prediction models.
Some researchers have used the statistical distribution of metrics such as frequencies and percentiles to rank classes into several levels [20, 36]. Ferreira et al. have classified classes into three levels: high frequency values, low frequency values, and regular values [20]. Oliveira et al. on the other hand have used percentiles to identify relative threshold values [36]. Shatnawi has proposed to use the log transformation on metrics to reduce skewness in measurement [41]. Shatnawi has proposed to use one standard deviation after transformation for threshold derivation [41].
Statistical methods were successful in finding thresholds for all metrics in the C&K suite. In addition, statistical methods depend on static analysis only and do not require information about faults in systems. Therefore, we select three statistical methods (Shatnawi, Alves, and Vale) that have reported thresholds for the C&K metrics. These methods are proposed to find thresholds and then thresholds are used to find which unlabeled instances are faulty. The results of threshold application are used to improve the quality of the datasets and therefore to improve fault prediction models.
Methodology
The process of building fault-prediction models includes many steps. In the first step, the metrics and fault data are collected from code repositories. In the second step, threshold values are derived for the six metrics using three techniques. Threshold techniques are applied for every dataset and the instances that exceed threshold values are selected. In the third step, instances that exceed thresholds and were labeled as non-faulty are marked unlabeled and are separated into the testing dataset to be used in the fifth step. In the fourth step, five classifiers are trained on the labeled instances using 10-fold cross-validation. In the fifth step, the models are run on unlabeled instances and tested using the five classifiers. The instances that are tested and classified as fault-prone by all classifiers are labeled as faulty, not faulty otherwise. In the sixth step, these instances are returned back to the training datasets. In the final step, updated datasets are used to build the final fault-prediction models using the 10-fold cross-validation to classify the instances into faulty or non-faulty. Figure 1 shows the updated fault prediction models after adding the derived thresholds to the model. In the following sections, we provide details of the different parts of the methodology.
Fault prediction model with thresholds.
There is plenty of software metrics to measure the internal quality of software metrics. The Chidamber and Kemerer (C&K) [45] are among these metrics. However, the C&K metrics have gained more attention from researchers than other types of metrics because they measure the most important aspects of object-oriented software. The C&K suite measures software properties including size, complexity, aggregation, generalization, coupling and cohesion. C&K has defined the metrics as follows:
Coupling between Objects (CBO): the CBO counts the number of couplings of a class to other classes in the system. Coupling increases interconnectedness and interdependence between components of the system, which causes side effects when a class changes. Hence, large values of CBO are considered riskier than low values. When a threshold is identified, a CBO value that exceeds the threshold value is considered more fault-prone than otherwise. Response for Class (RFC): the RFC counts the responsibility of a class by counting local and remote methods involved in the activities of a class. Large responsibility causes more side effects on the quality of the software. RFC values that are larger than a threshold are faultier than otherwise and require more quality investigation. Weighted Methods per Class (WMC): the WMC counts the complexity in a class by counting the number of methods. A large number of methods are indicated as god classes. Such classes are problematic and difficult to maintain and test. Classes that have WMC values are larger than a particular threshold require more attention and more quality investigation. Depth of Inheritance Hierarchy (DIT): the DIT counts the number of direct ancestors of a class to the root class in the inheritance hierarchy. DIT is an indicator of the extent of inheritance. Classes that have DIT values larger than a threshold require more effort to maintain and test. Number of Child Classes (NOC): the NOC metric counts the number of direct children of a class. Large values of NOC indicate the number of specializations of a class and therefore more complicated behavior in the system. Lack of Cohesion of Methods (LCOM): the LCOM metric measures interrelationships between methods and data fields in a class. If the relationship is strong then the class is coherent and represents similar functionalities. Low cohesive classes require more refactoring and maintenance. The LCOM is calculated from two parameters (P and Q). P counts method pairs using no data fields in common, whereas Q counts method pairs that have shared data fields. Therefore, the LCOM is calculated as follows:
Large values of LCOM denote lack of cohesion and therefore such classes require more maintenance and testing.
In this research, the study is conducted on fault data from the Promise repository that is publicly available for reuse by researchers. The use of this data is easier for more experimentation and replication. Fault data were collected from the repositories of systems under investigation as shown in the work of [26, 27]. The tool has used regular expressions to analyze logs of every software and has associated the bugs found in the repository with relevant classes. Whenever a bug is associated with a class then the bug count is incremented by one for the class. The procedure is applied for all systems under study. The bytecode of systems was analyzed using a specialized static analysis tool called Ckjm for java applications only. Ckjm is an open-source tool and can be validated or improved.
Five large open-source systems and five large commercial systems are used in this research. All open-source systems are built under the license of Apache systems. The study is conducted on the following five open-source systems.
Ant: A Java Building tool (http://ant.apache.org) Camel: A versatile open-source integration framework ( Ivy: A dependency manager focusing on flexibility and simplicity ( Jedit: A Java IDE and editor ( Tomcat: an implementation of the Java Servlet, JavaServer Pages, Java Expression Language and Java WebSocket technologies (
The five commercial software systems are large applications that were developed for insurance businesses. The metrics and fault data were collected similarly as for the open-source systems. These systems are given anonymous names.
Data distribution affects the quality of the machine learning models and therefore it is necessary to understand the fault distribution. Table 1 shows the imbalance in fault classes in most systems. Faulty classes are the minority whereas most classes are labeled non-faulty. However, this behavior is not necessarily correct as more faults may be uncovered in future releases of software.
The fault distribution for ten systems
Threshold values are reference points that can be used to investigate when classes can be at risk when exceeding a particular value. In this work, three threshold identification techniques are used for validation The three techniques were selected for the following reasons:
All techniques should use statistical distribution parameters. Shatnawi’s work uses the standard deviation and the mean after applying the log transformation. Vale’s work uses the percentiles to select classes as bad smells on a large benchmark. Alves’s work selects the top 90% of classes after applying a weighted ratio. All techniques should be validated for quality prediction. Shatnawi’s thresholds were found correlated with fault-proneness. Vales’ and Alves’ thresholds were found correlated with bad smells, e.g., large classes. All techniques should be configured to characterize a metric value into several labels. However, in this work we have selected two labels to be consistent with fault-prediction models. All techniques should be easy to implement and repeat on future systems.
In this research, Shatnawi proposed to use the mean and standard deviation for each metric to derive thresholds. The log transformation is used to reduce data skewness. This methodology was originally proposed and validated in [41]. Thresholds are calculated as in Eq. (2).
Where
The derived thresholds are calculated from the data distribution and since each system has different parameters then we do not expect to have the same threshold values for a particular metric among different systems. In [41], threshold values of C&K were derived (WMC, CBO, RFC, LCOM DIT and NOC).
This threshold derivation technique is easy to implement and interpret. The selected instances are outliers at the right-hand side of the distribution. The statistical distribution is skewed to the right and depending on statistics without log transformation may produce biased parameters for threshold derivation. In addition, this technique reports thresholds for individual systems. Although this technique cannot be generalized to other systems, the statistical distribution gives information about the data quality.
Alves et al. proposed a benchmark-based approach for threshold derivation [50]. Alves method consists of six steps. First, software metrics are calculated for each system. Metrics are separated for each system in a separate file. Second, a weighted ratio is calculated for each class in each system. The weighted ratio is calculated by dividing the LOC of each class by the total LOC of all classes. For example, if a class has 100 LOC and the system is composed of 10000 LOC, then the weighted ratio is 100/10000. In the third and fourth steps, the weights of each class at each system are aggregated. In the fifth and sixth steps, the classes are ranked by weight and the top 90% are used to derive thresholds. A threshold at 90% means that this threshold represents 90% of the overall code. In other words, this threshold selects 10% of the code as low-quality parts that require more quality assurance. The authors proposed thresholds at four levels: low (between 0–70%), moderate (70–80%), high (80–90%), and very high (
Thresholds used in this research
Thresholds used in this research
Vale has divided his methodology into six steps. The first step starts with metrics collection from a large benchmark of systems and metrics are collected for each class. In the second step, the percentages are computed for each class with respect to the total number of classes in a benchmark. In the third step, metric values are ordered ascendingly in a way equivalent to calculating a density function. In the fourth step, the percentages are aggregated for all classes per metric value. In the fifth step, thresholds are derived for the top 90% and 95% of classes for each metric. In the sixth step, thresholds are derived from the lower bounds below 3% and 15% for small classes. In our research, the top percentages are only relevant, hence step six is irrelevant to this work. Vale thresholds are shown in Table 2. These thresholds are derived from a benchmark of 100 systems.
Threshold values in Table 2 were previously published in [41, 14]. Vale has initially conducted his methodology on software product lines. He extended his work to other types of systems for generalizability. The authors selected a benchmark that consists of more than 100 systems from Qualitas Corpus [11]. The benchmark was used to find thresholds using the Alves’ method as well. Thresholds derived using Alves and Vale methodologies are used to improve fault-prediction models.
Machine learning techniques
Machine learning techniques help in building fault prediction models. These models predict the fault-proneness of classes using software metrics as independent variables. There are many machine learning techniques that can be employed. Machine learning techniques were selected for two purposes: first, validating the use of thresholds on reducing class imbalance. The classes that were selected as fault-prone by the threshold values and all classifiers are labeled as fault-prone; otherwise, such classes are labeled as not fault-prone. Second, building fault-prediction models after reducing the effect of class imbalance. Therefore, we proposed to use five machine learning techniques that represent five different techniques that build models based on different mathematical properties, i.e., Bayesian (Naïve Bayes), regression (Logistic regression), nearest neighbors (KNN), rule-based (JRip) and trees. The implementations of these techniques are provided by Weka and all algorithms were kept at default parameters. The following machine learning techniques were used in previous research on fault prediction.
Naïve Bayes (NB) is a simple classifier that is usually used for building fault prediction models [46, 52]. NB is based on simple Bayesian networks that have two assumptions: the features are independent given the class (faulty or non-fault) and no hidden features affect the prediction [13]. Logistic Regression (LR) is a regression-based model that has a binary dependent variable. The LR model is built from a logistic curve as a combination of all metrics to predicting fault-proneness of software [4]. Nearest neighbor (kNN) determines the distance with the closest k instances and assigns the label of the dominant group. kNN uses distance (similarity) metric to find the nearest neighbors and assigns the label to the one that has the majority [8]. JRip implements a propositional rule learner, Repeated Incremental Pruning to Produce Error Reduction (RIPPER), which was proposed by [53]. The algorithm has two phases to build ruleset, grow and prune. Conditions with the highest information gain are selected. Decision tree (C4.5) is an extended form of the original ID3 algorithm designed by Quinlan. C4.5 uses information gain to build the decision trees [19] by selecting the decision for the attribute with the highest information gain.
In machine learning, fault prediction models are usually assessed by considering all errors equally distributed, which does not work properly when the data is imbalanced [29, 32]. Therefore, thresholds are proposed to increase the number of faulty instances to reduce the imbalance ratio in data. The machine learning models are trained and tested for the fault data before and after using thresholds.
The five classifiers are evaluated on ten systems using the tenfold cross-validation. In a tenfold cross-validation, the dataset is divided to 90% for training, and 10% for testing. To reduce the variance in the results, the cross-validation is repeated ten times (e.g. 10
MCC is a type of correlation coefficient between the actual and the predicted classification. MCC has values between
The confusion matrix of classification models
The confusion matrix of classification models
The MCC values for five classifiers
MCC is calculated from the confusion matrix as shown in Eq. (4). All values in Eq. (4) are derived from the confusion matrix in Table 3. MCC is relatively easy to understand and interpret. Furthermore, MCC has been validated to be a reliable measure for fault prediction models [31, 38].
Machine learning techniques can be improved for the imbalanced data by increasing the number of minority instances. The data imbalance affects the performance of fault prediction models. In the following, we build fault-prediction models before and after processing imbalanced data. We present how data imbalance affects the data and how thresholds reduced data imbalance.
Traditional fault-prediction models
The models without thresholds are experimented using five classifiers. For validation, we run the experiment using the 10-fold cross-validation for all systems. The MCC results are shown in Table 4. MCC measures the correlation between the predicted and the actual classes. MCC values that are significantly larger than zero are favored for classification.
The MCC values, shown in Table 4, are weak for most classifiers (close to 0.0) whereas few have performance that can reach a value 0.40. The MCC values in Table 4 are closer to a random prediction than a perfect prediction for all classifiers. Some classifiers for the Ant system have MCC values that is less than zero, which is an indicator of weak classifiers. The MCC values for all classifiers show weak prediction results. Therefore, RQ1 is answered and the data imbalance affects the fault prediction performance greatly.
Data imbalance effect
Data imbalance affects fault-prediction. Therefore, we use thresholds to find whether data imbalance can be reduced using threshold values. Threshold values are used to select the instances that were marked not fault-prone but that exceed threshold values. Instances that are larger than one of the thresholds and non-faulty are kept unlabeled and separated into the testing dataset. The rest of instances are used as training dataset. This procedure is repeated for the three threshold identification techniques for each system.
Number of unlabeled instances selected fault-prone using Shatnawi thresholds
Number of unlabeled instances selected fault-prone using Shatnawi thresholds
Number of unlabeled instances selected fault-prone using Alves thresholds
The three threshold identification techniques (Shatnawi, Alves and Vale) have selected a different number of instances (N) as shown in Tables 5–7. These instances are selected as fault-prone using thresholds. However, we need to make sure that the threshold identification techniques are consistent in predicting the fault-pone instances. These instances (N) are unlabeled and separated into a testing dataset whereas the rest are used as training dataset.
The five prediction models are trained and the testing datasets are provided to the models. For brevity, the number of instances that are predicted as faulty are counted and provided in Tables 5–7 for Shatnawi, Alves and Vale techniques, respectively. For each classifier, the total number of instances that are classified as faulty are reported in the columns NB, LR, J48, KNN, JRip. For example, NB has classified 169 out of 177 classes as faulty.
There is a variation in instance classification among the five classifiers. To get reliable results we have considered a class faulty if it was predicted as faulty using all the five classifiers together as shown in the last column. For example, 100 instances were considered as faulty out of 177 in Ant when Shatnawi thresholds are used whereas only 28 out of 64 when Alves thresholds are used. The rest of instances that are not predicted as faulty are then considered as non-faulty again as were originally reported in the datasets. This process guarantees that the imbalance in data is reduced after using threshold values with confirmation by five machine learners.
Number of unlabeled instances selected fault-prone using Vale thresholds
The percentages of faulty modules before and after applying three thresholds techniques
Percentage of instances predicted as faulty using Shatnawi technique.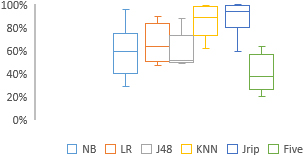
Percentage of instances predicted as faulty using Alves technique.
To answer RQ2, we notice that the number of instances selected to be added to the minority group (faulty) is increased for all systems using the three threshold techniques as shown in Table 8. Table 8 shows the percentages of faulty instances after using thresholds and their validation using the five machine learning techniques. Therefore, we can conclude that threshold values help reduce data imbalance. To summarize this finding we have reported the boxplots (Figs 2–4) that show the percentages of classes that are selected as fault-prone using thresholds. The use of Shatnawi and Vale thresholds shows that classifiers have selected about 50% of classes as indeed faultprone using the single classifiers as reported in Figs 2 and 4. However, the five classifiers together have selected about 38% of classes as fault-prone. Therefore, we can conclude that RQ2 is answered by the experiment. Threshold values can be used to reduce imbalance in fault data as shown clearly in Table 8. For all systems, Shatnawi’s thresholds reduced data imbalance more than Vales’ and Aleves’ thresholds.
Percentage of instances predicted as faulty using Vale technique.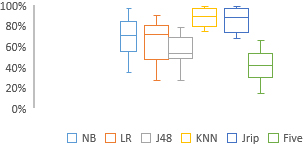
Datasets are rebuilt according to the classification of the unlabeled instances. The prediction models are then trained and tested using the 10-fold cross validation on the updated datasets. We report the results of each classifier to compare the updated datasets with the original datasets. The results of the five classifiers are shown in the Tables 9–13. The MCC values of each classifier are shown for the three threshold techniques.
NB Classification of faulty and non-faulty
NB Classification of faulty and non-faulty
LR Classification of faulty and non-faulty
KNN Classification of faulty and non-faulty
The results of classifiers’ performance on the original data are shown in the second column in the Tables 9–13. The classifiers’ performance on the original data (i.e., without the use of thresholds) is weak on all classifiers, i.e. a small MCC value that is close to zero means a random correlation between the actual and the predicted values. The results for the classifiers after using thresholds are also shown in the tables.
JRip classification of faulty and non-faulty
C4.5 Classification of faulty and non-faulty
To answer RQ3, we need a more formal analysis to find the significance of the differences between two models, the traditional and the modified models. We conduct a statistical comparison using a non-parametric test, cliff’s
Effect size (Cliff’s
Boxplots of classifiers performance (MCC) on ten datasets for (Original, Alves, Shatnawi and Vale).
For comparison purposes, the boxplots for all the classifiers’ performance (MCC values) are reported in Fig. 5. The boxplots show the MCC values for four datasets: original, and modified using Alves, Shatnawi and Vale techniques. The boxplots in Fig. 5 show better prediction performance after using thresholds than otherwise. The performance of using classifiers with Shatnawi and Vale thresholds are better than with Alves thresholds.
For the five classifiers, we observe similar patterns, i.e., the original data has the least performance whereas using Shatnawi thresholds produces the best performance, i.e., the median value is the largest. The MCC values are larger than random in models when using thresholds. These results show reliable prediction models. Generally speaking, using thresholds improves fault prediction performance. The improved classifiers have shown a great improvement on average when compared with models on original data. Table 15 shows the percentage of improvements on the average values of the performance for each model. For example, the performance of models with Shatnawi’s thresholds shows the most improvements for J48 (358%). All thresholds have shown improvements on average. The Alves’ thresholds are showing the least improvement, however, there improvements are significantly large.
Improvements on models before and after using thresholds
Improvements on models before and after using thresholds
Threshold values shown in Table 1 can be ordered by the number of instances that are selected for inclusion in faulty classes, i.e., Alves, Vale, and Shatnawi. Shatnawi’s thresholds select more instances for further investigation. Threshold values can be used separately to mark classes as fault-prone or can be used in combination with fault prediction models to improve the prediction performance. This is the reason why Shatnawi’s thresholds have better improvement on the modified datasets than the other threshold techniques. As noticed in Tables 5–7, using thresholds has selected a large number of instances as faulty and we found at least 50% of these instances were classified as such.
Using classifiers such as naïve Bayes, nearest neighbors and JRip show better results than LR and C4.5. However, LR and C4.5 performances were significantly larger than random (MCC
In this section, we discuss several study limitations:
Internal validity threats: there are static analysis tools that may use variants of metric definitions. For example, the WMC and LCOM metrics have many variants. However, the metrics data in this research are based on the original definitions of C&K metrics. External validity threats: All systems under investigation were developed in Java and the results may not be generalized to other programming languages. Threshold identification techniques and fault prediction models are valid for other languages. Although, there are abundant number of software metrics that have been already proposed, the C&K metrics are the most reported for fault prediction and threshold identification. In addition, the systems under investigation come from two domains only, development tools and insurance business. Construct validity: The fault-proneness variable is defined as binary variable. The number of fault fixes provides more detailed evidence of the software quality. However, most classes are not faulty and therefore, the fault data is sparse and imbalanced. The use of a binary variable is more convenient for analysis. In addition, threshold identification techniques were only reported for binary variables.
Conclusions
This research aims to answer three important questions related to the effect of data imbalance on fault-prediction. First, we found data imbalance has a great effect on the performance of fault prediction. Second, thresholds reduced the magnitude of imbalance by increasing the minority instances. Third, the use of thresholds improved the fault prediction significantly when compared with models on the traditional imbalanced data.
In this research, we propose to use thresholds derived from a large benchmark to improve fault-prediction models. Three techniques that were proposed by Shatnawi, Alves and Vale are used in this research. For validation, the datasets of ten object-oriented systems are used. The dataset of each system includes both metric data (C&K suite) and fault data. Data shows imbalance in the ten systems, i.e., the majority of instances are not faulty, whereas the faulty instances are the minority.
Threshold values have identified many instances as faulty. The three threshold identification techniques have increased the number of faulty instances and reduced the imbalance in fault data. However, thresholds may not be accurate in the selection of faulty data. We run five classifiers on the selected instances as testing datasets. If all five classifiers classify an instance as faulty then the instance is marked as such. The process is repeated for all datasets and all three threshold techniques.
The resulting datasets are updated and used to build fault prediction models. The fault prediction models were trained and tested using the 10-cross validation techniques. The results show improvements in the prediction models when compared with the models without the use of thresholds. The performance of using Shatnawi and Vale thresholds have produced models that are better than the ones produced using Alves thresholds.
In conclusion, threshold values can be used as reference points for prioritization and management of software verification and validation efforts. Moreover, threshold values can improve fault-prediction models.
Footnotes
Funding
This work is supported in part by Jordan University of Science and Technology, Deanship of Research.