
Abstract
The speaker identification in Teleconferencing scenario, it is important to address whether a particular speaker is a part of a conference or not and to note that whether a particular speaker is spoken at the meeting or not. The feature vectors are extracted using MFCC-SDC-LPC. The Generalized Gamma Distribution is used to model the feature vectors. K-means algorithm is utilized to cluster the speech data. The test speaker is to be verified that he/she is a participant in the conference. A conference database is generated with 50 speakers. In order to test the model, 20 different speakers not belonging to the conference are also considered. The efficiency of the model developed is compared using various measures such as AR, FAR and MDR. And the system is tested by varying number of speakers in the conference. The results show that the model performs more robustly.
Introduction
The speech wave extracted from the spoken language conveys several kinds of information. In speech production viewpoint, this signal conveys the linguistic information, which indicates the meaning the speaker wishes to impart, who is speaking and the emotion of the speaker [2, 4, 5, 21]. Whereas from the speech perception viewpoint, the environment of speech production and transmission can also get conveyed. The information to be transmitted in the form of speech signal involves complex encoding scheme but can be easily decoded by the human ears. This ability of humans has driven many researchers in developing systems that can extract the speech signals automatically and process the information. The processed information helps in recognition of the speaker.
Any speaker recognition systems have three specific tasks which are to be performed, viz., the speaker identification, speaker verification, speaker segmentation [28, 30]. The Speaker identification involves two processes, the open set, and the closed set. As the initial step, a database is generated with speech voices from different speakers of both genders and the aim of speaker recognition is to determine whether the individual belongs to a database or not. In the closed set mode, even called as, multi-classification problem, the speech recognition is done based on the voices from the generated databases, else if the voice is outside the database then it is said to be in open-set mode; the voices considered for open-set mode are called imposters. This open set mode is very much useful in applications like security/forensics, where the speech evidence can be used for the identification of the suspects or voice verification or the authentication on speaker detection [3, 6, 11, 14].
Training process for speaker recognition in teleconference applications.
Speaker verification is the second task which aims at the verification of a person basing on the speech signal. This can be a binary decision problem. In this process, the Claimly’s voice is to be tested with the large group of voices and the authentication is to be generated. This system has applications in control telephone and banking services.
The final task, speaker segmentation/clustering has wide applications in multi-speaker scenarios. In order to recognize a speaker, the test speaker voice is considered, processed and is compared with that of the existing voices in the data set. But may not be as simple as assumed, because, in most of the speaker recognition applications, it is always assumed that the speech from a particular individual is only available for processing, the speech signals, in most of the cases are interlined with other individual speech signals [12, 13, 18, 19]. Hence in order to identify a particular individual’s speech from the database, it is, therefore, necessary to divide the speech samples into clusters or segments, so that the homogenous speech samples can be identified [8, 15, 16]. These samples are then labeled using the speaker’s identity. These models of segmenting and identifying the homogenous voices have many advantages, including far speaker identification, identifying a speaker in the conference/meeting and consumer electronic devices [17, 27, 29]. In the process of speaker segmentation, the voice samples are indexed which helps the retrieval process simpler.
In this paper, we focus on the identification of the speaker from the group of speakers from the conference meeting. A lot of reviews are projected in this area of speaker segmentation. Many challenging issues are focused on dividing the voice speech into homogenous segments. The challenges include discriminating the boundaries between the speakers, identification of the regions/portions of the individual speakers and identifying the unique speakers from the voice database. The boundary location problem assumed to be the segmentation problem, region/portion identification of the individual speaker is assumed to be the clustering problem.
The above picture describes training process of conference speech, which includes clustering and obtaining MFCC-SDC-LPC feature vector combination [1, 2, 15], and then obtained probability density function (PDF) of the generalized gamma distribution [22, 24]. The model for any segmentation and clustering system is presented above. The voices from the meeting are considered and after processing the speech samples, the feature vectors are identified and the numerical equivalents are obtained from the speech sample [6]. The segmentation process is carried out by dividing the database into homogenous segments basing on the identity of each speaker. The environmental and transition channel conditions are also considered. The clustering process aims at identifying the homogeneous clusters basing on the speaker’s identity i.e. in this process we group all the speech that pertains to an individual speaker [7, 9, 10].
The speech segmentation and clustering process are useful in other applications such as far-speaker identification and identifying the 3
A meeting is defined as a gathering of a group of like-minded people to interact with each other and exchange their views regarding a particular issue. The set of people participating in the meeting need not be in the same location, video conferencing; tele-metering can also be viewed as the cases under consideration
The Fig. 2 is the schematic view of the Teleconference authentication system, aims to build speaker segmentation and clustering system for a meeting environment. Speaker segmentation segments the voice database into audio streams, with the intention of finding the changes in the acoustic points that may be due to the difference in the background or due to the change of the speaker.
A schematic view of the teleconference authentication system.
The continuous speech signal is considered, and the boundaries of the speech are identified to categorize the speech labels are classes. The speech signals of all the speakers involved in the meeting are recorded and the speech samples are synthesized/processed. The feature vectors are identified using spectral coefficients. MFCC coefficients and MFCC-LPC are used for the feature extraction [16, 20]. MFCC is preferred because of its ability to recognize the noise in noisy environments and also in short frames. In order to eliminate the silence part/white speech, segmentation process will be useful. The individual speaker voice from the overlapping sequence is overcome by considering an overlapping window of 10 ms, 25 ms; 30 ms varying the speech frame length of 10 frames each. The meeting database considered for the study is a recorded data of a continuous speech of 5 min. the testing purpose, we have considered the data of 0.5 sec.
In order to segment the data, effectively we have to model the voice-parameters accurately and to differentiate the voices/speakers, maximum likelihood criteria will be of more advantageous and K-Means algorithm is utilized for the segmentation process. Many model-based techniques have been used for speaker segmentation and clustering, GMMs which GMM based approach is of most preferred. But the main disadvantage of GMM is that GMM segments the data effectively when the shape of the speech signal under consideration is symmetric and the range is infinite [15, 23, 25]; but most of the speech signals, in reality, are non-Gaussian in shape i.e. either Lepty-kurtic or Platy kurtic and the range of the speech signal is not infinite. Hence to model the parameters most effectively maximum posterior algorithms are mostly preferred. Hence in this paper, generalized gamma distribution is utilized. For any segmentation process, the initial clusters are to be identified. In the process we have utilized the histogram process, to identify the number of peaks, which helps to identify the number of segments. Once the segments are identified, the k-means algorithm is utilized to segment the data into clusters of homogenous groups. The initial estimates that are obtained from the k-means algorithm are updated using E-M algorithm and the updated model parameters are used for the labeling of the speakers.
An Experiment is conducted in mat lab environment by considering a meeting environment sequence recorded for 10 min duration. The efficiency of the model developed is contemplated to that of the existing model based on GMM [31, 32]. The performance evaluation is carried out using measures such as Acceptance Rate (AR), False Acceptance Rate (FAR), and Missed Detection Rate (MDR). The results show that the model developed obtains good results.
The probability density function of each speech spectrum of speakers
By using Bayes’ rule equal prior probability (i.e.
The speaker’s identity can be determined by the sum of the hypothesis log probability scores obtained from speech samples from
The Mel frequency cepstral coefficients (MFCC) are used to represent the speaker identification characteristics. In the setup used, a Mel-scale filter bank is used to process the magnitude spectrum from a short frame. The outputs of the log energy filter are the cosine transformed into cepstral coefficients. Each frame repeats the process resulting in several feature vectors [1]. We assume that each of the Mel frequency cepstral coefficients follows a generalized gamma distribution. The entire speech spectrum of each speaker can therefore be characterized as M-component Generalized Gamma Distribution. Using Generalized Gamma Distribution, the probability density function of each individual speech spectra speaker is modeled. In order to identify an individual speaker, from the meeting situations, we have to cluster the data.
The speaker identification problem is defined as the determination of a speaker identity from his/her voice. Speech recognition is used in real-world human language applications, such as information retrieval. It is the most common means of the communication because the information contains the fundamental role in conversation. From the conversation or speech, it converts an acoustic signal that is captured by a microphone or a telephone, to a set of words. A set of word can either be the final result or it can then apply the synthesis to pronouns into sounds, which means speech-to-speech. Its means that, speech recognition can serve as the input to further linguistic processing in order to achieve speech understanding. Speech recognition systems are characterized by speaking style, speaking mode, environment, vocabulary, acoustic model, language model, perplexity, SNR and transducer.
A speaker identification system is said to be open-set if it can determine whether the given testing utterance belongs to the set of enrolled speakers or not. Otherwise, it is called a closed-set speaker identification system. In order to recognize the speaker, different classification techniques are presented in literature.
Classification refers to deciding the class label (the unknown identity) of the testing signal. In closed-set speaker identification systems, classification is performed by assigning a score for each class that attempts to measure how likely the corresponding speaker produced the given testing utterance. A decision is made in favor of the speaker whose model provides the highest matching score. The classifier performance is measured by its ability to predict the true labels of unknown testing utterances as well as the time need for making a decision. In order to have a good classification performance, training examples (utterances) with known labels are used to estimate the classifier parameters.
The main approaches for speaker identification include Unsupervised learning models, Supervised learning models, Dimensionality reduction techniques and other models based on Acoustic speaker recognition, Feature vector based and speaker Diarization.
Speaker recognition models based on unsupervised techniques
In this approach, a model is constructed for each speaker. The training examples (feature vectors) of each speaker are used to train the corresponding model. In the testing phase, each model calculates a likelihood score with respect to the given testing utterances. This approach is called unsupervised learning because, when each speaker model is trained, the corresponding class label information is not used. Various unsupervised modeling approaches include k-NN, vector quantization (VQ), GMM and HMM.
The advantage of unsupervised learning algorithms over supervised methods is that; new speakers can be added easily to the identification system without the need to retrain other speaker models; another advantage of unsupervised learning algorithms is in the flexibility of adding and removing speakers from the system. Unsupervised learning algorithms are often characterized by the decision function that is used to measure the match between a given testing utterance and a certain speaker model. While distance metrics are utilized with the NN, the dynamic time warping (DTW),and the VO classification methods, a probabilistic likelihood is used with statistical classifiers such as the GMM and the HMM.
In this section we briefly review some of the Speaker recognition models based on Unsupervised Techniques
Speaker recognition based on nearest neighbor
The NN classification method is a conceptually simple classification technique that is found to be efficient in many pattern classification problems. The training phase just consists of storing all the training data vectors with their corresponding labels. To classify a testing example, the closest
Generalized gamma distribution
The probability density function of the generalized gamma distribution is given by
where
Recorded waveform of the conference audio.
One cluster of conference speech.
We obtain estimates of model parameters via EM algorithm in this section. It is mandatory to estimate the speaker model’s parameters effectively for effective speaker identification model. To estimate the parameters EM Algorithm is used that maximizes the model’s likely hood function for a sequence I; let
The likelihood function of sample observation
is given by
The updated equations for the initial parameters
For updating
To develop the model of speaker identification, in a teleconferencing situation, estimating the speaker model parameters is necessary. In order to estimate the parameters in the model, we consider the EM algorithm that maximizes the model’s probability function for a speaker I from the teleconference
where
A popular approach to segmenting speech samples into K-Clusters is the K-Means clustering [34]. The steps to be taken are:
Start with an initial value of Choose the number of By assigning each speech sample
Calculate a cluster assignment matrix
where,
Use the membership values to recalculate the centroids
If there is no change in the cluster centroids or assignment matrix from the previous iteration, stop go to step 3 otherwise.
The speech signals are extracted using the MFCC coefficients. In the situations of identifying a speaker in the conference or group meeting, it is needed to cluster/segment the speech data set, so that the individual speaker having the same frequency speech signal or feature vectors are pooled together, i.e., the likelihood of each speaker is to be modeled from the M-speakers. K-Means algorithm is utilized for this purpose.
The K-Means algorithm requires the initial value of K, false estimation of the K value results in either overestimation or underestimation. To overcome this situation, the initial value of K- is determined by plotting the Cepstrum of the Mel cepstral coefficients associated with each speaker, and for one speech sample, it is shown in Fig. 5.
After obtaining the value of K, the EM algorithm is used for the updating of the initial estimates, given in the Eq. (7).
The steps for the speaker recognition are given below
Mel frequency cepstral coefficients.
In order to initialize the model parameters, EM algorithm can be effectively used. Obtain the range of each feature vector by estimating the minimum and the maximum frequency value of each speaker. The initial value of the Apply the K-Means algorithm, described in Section-3. After estimating the initial values of K from the histogram of MFCC. Segment the speech data into K-clusters. Arrange the speech samples either randomly or serially. The procedure for the K-Means algorithm is given below.
Choose the speech signals, train the speech data for all the M-speech samples, take the MFCC coefficients Assume that there are N-samples and train the remaining (N-M) samples by computing the centroid of each sample and assign the samples to the component with the minimum centroid. If there are N-samples and M-coefficients, then the samples ( The mean is calculated as Mean
After obtaining the speech sample of the all the speakers in the participating in the meeting, the main purpose is to identify who is speaking or who is the speaker when a speech voice is generated by considering the test voice and comparing with that of the database of the speaker in the meeting and another feature that can be included is that when the speech test voice is obtained, it is compared with that of the voices of the speakers in the meeting and we can conclude whether the speaker is participating in the meeting or not [26, 28, 30, 33]. For the effective recognition of the speaker, the following algorithm is adopted using Generalized Gamma Distribution as model building tool to store voice template.
Record continuous speech in the conference. Cluster the speech using a k-means clustering algorithm, call the clusters as Train the clusters after extracting feature using MFCC-SDC-LPC and then obtain probability density function of the generalized gamma distribution. Perform step3 for test speeches (including conference speakers and non-conference speakers). If the test speech PDF is matched with the trained PDF (range of min and max values of PDF).
Then speaker is accepted (conference-speaker), otherwise reject (non-conference speaker).
The experimentation is conducted using 50 speakers involved in a meeting scenario. The Speech samples of the individual speakers are obtained and stored in.WAV format. The preprocessing is done for eliminating the white speeches and noise removal. The MFCC cepstral coefficients for each speech signal of every speaker is obtained and stored in the database. The following sequence of graphs indicates every stage of the speech signal for training and to acquire probability density function (PDF) for comparing with test speech PDF. And also tested this system with TIMIT dataset available in literature.
Speech Cepstrum after application of MFCC-SDC-LPC.
Probability density function of the generalized gamma distribution.
The Fig. 3 is speech waveform after recorded in.wav format. This spectrum further clustered for identifying conference speaker and non-conference speaker.
The Fig. 4 is one cluster of conference speech after cluster the speech into k-clusters.
This clustered speech further calculated MFCCs for feature extraction.
The Fig. 5 is Mel frequency cepstral coefficients (MFCC) of the individual cluster, these MFCCS are further converted to shifted delta coefficients (SDC) and then given to calculate LPC for extracting low frequencies.
Performance of speaker recognition system with AR, FAR, MDR.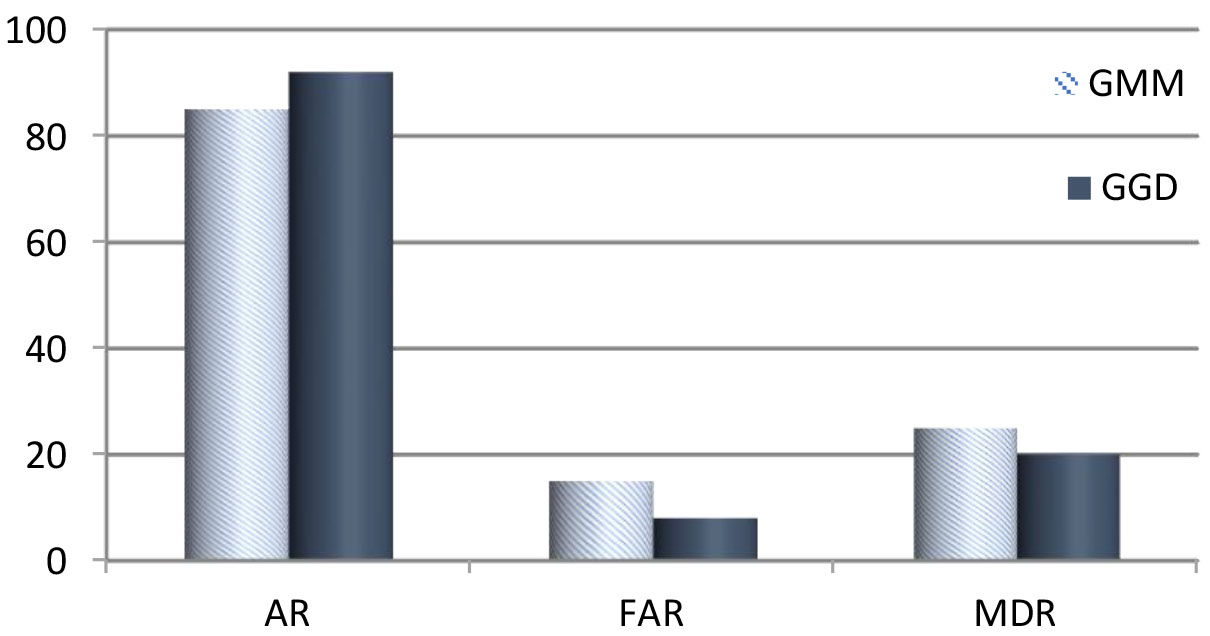
The Fig. 6 indicates speech Cepstrum after applying MFCC-SDC-LPC, This feature vector further given to generalized gamma distribution for computing PDF.
Figure 7 indicates probability density function of the generalized gamma distribution. This PDF will be used for comparing trained speech and test speech for taking a decision about acceptance.
In order to evaluate the performance of the developed model various metrics such as Acceptance Rate (AR), False Acceptance Rate (FAR), and Missed Detection Rate (MDR) are considered. The various formulas for evaluating the metrics are given below.
The developed model is tested for accuracy using the above metrics.
The Fig. 8 shows performance of teleconference authentication system with AR, FAR, MDR metrics. Also shows the Comparison between existing Gaussian Mixture Model (GMM) and Generalized Gamma Distribution (GGD) and it is observed that the Generalized Gamma Distribution gives better performances.
Further analysis is needed for to Speaker Diarization to establish who said when and for the tasks of speaker segmentation and 230 indexing of multi-speaker speech and further dimensions are to be developed to assess the behavior of the speaker in the absence of an interviewer. These methods are to be addressed effectively for the development of a robust speaker identification system.