
Abstract
Multimodal Biometrics are used to developed the robust system for Identification. Biometric such as face, fingerprint and palm vein are used for security purposes. In this Proposed System, Convolutional neural network is used for recognizing the image features. Convolutional neural networks are complex feed forward neural networks used for image classification and recognition due to its high accuracy rate. Convolutional neural network extracts the features of face, fingerprint and palm vein. Feature level fusion is done at Rectified linear unit layer. Maximum orthogonal component method is used for Fusion. In Maximum orthogonal component method, prominent features of biometrics are considered and fused together. This method helps to improve the recognition rates. Database are self-generated using these biometrics. Training and Testing is done using 4500 images of face, fingerprint and palm vein. Performance parameters are improved by this technique. The experimental results are better than conventional methods.
Introduction
Biometric authentication and identification system identify the individual through its physical or behavioral traits. Biometric traits are popular, as throughout lifetime individuals face, fingerprint, iris, palm print doesn’t change and they cannot be easily replaced hence, preferred for security system. Unimodal biometric systems use sole biometric feature for an individual’s authentication. Multimodal biometric systems use a different modalities combination such as iris and fingerprint, face and iris for recognition. Multimodal systems provide the high security and higher accuracy as compared to unimodal systems. Multi-biometric system also overcome issues of unimodal biometric system such as intra-class variability, noisy data, non-universality, restricted degree of freedom, spoof attacks [1]. But the major challenge of multimodal biometric system is selection of modalities and combination of modalities for improving the recognition rate. Next challenge is the selection of fusion algorithm which will provide good accuracy. Fusion of modalities can be performed at feature, sensor, score or decision level. The feature level fusion is performed just after extraction of features from the modalities. Feature level fusion has some challenges such as concatenating the features, which affects the performance parameters [2].
The main objective of multimodal biometric system is to develop a robust security system for the application of banking security, as many frauds are occurring during the transactions. In online transactions the account can be hacked, while in Automated Teller Machine (ATM) transactions the debit cards can be stolen. To overcome this problem, there is need to develop a computational system in ATMs which helps the person to withdraw the money without any debit cards. Person’s Identification through biometrics itself acts as password or pin for money transactions. Many different conventional methods are used for developing the security system. The biometrics such as face, fingerprint, palmprint, iris and many more combinations give good results but still they are having some issues. Face and fingerprint biometric provide a low recognition rates as they have some challenges such as non-uniform illumination, orientation of images, blurred images which affects the recognition rates. In this paper, palm vein is added with face and finger print as the unique biometric for improving the recognition rates. Palm vein’s uniqueness is that veins can’t be replaced or misplaced because veins are within the person body which is more secure. Hence conventional machine learning techniques are better suited for the lower database, but the accuracy of the system decreases for larger database and training time required is more. In Machine learning feature extraction plays an important role, there is need of the universal feature exaction techniques that can automatically extracts the color, texture and shape features. For the implementation, convolutional neural network (CNN), a deep machine learning technique is used which has ability to extract the features automatically, called as hidden feature extractor. CNN can also be applied for larger database resulting in good accuracy. A large database is generated of 4500 images for face, fingerprint and palm vein of different orientation and illumination. CNN consists of many layers such as convolutional layer, rectified linear unit layer, max pooling layer, fully connected layer, SoftMax classifier. In this Proposed System, two layered CNN is applied to each modality individually and features are fused together using maximum orthogonal component method.
This paper is organized as follows: Section 1 starts with brief introduction of the multimodal biometric recognition systems. Section 2 elaborates the related work carried out for multi-modal biometric recognition. Section 3 describes the generation of database. Section 4 describes the proposed methodology in details. Experimental results and discussion are discussed in Section 5. Final section concludes the proposed work and gives the open area for future development.
Finger print, face and palm vein sample modality images.
Many approaches such as face recognition, iris recognition and fingerprint recognition have been applied for improving the biometric recognition rates. The limitations of unimodal biometrics motivate to use multiple traits with number of classes for improving the performance of recognition using multimodal biometrics [3]. Multiple biometrics contains the multiple sensors, biometrics, and matchers. This section provides the previous work carried out on the multimodal biometric recognition systems. Sobhan Soleymani et al. [4] used face, iris, and fingerprint for the deep multimodal fused network for the person authentication. Convolutional neural network is used for the multiple feature extraction and it outperformed the existing unimodal techniques, score level fusion and resulted in 99.81%. Further, Di Wu et al. [5] proposed the deep dynamic network for the multimodal gesture recognition in which multiple inputs are observed on the basis of joint information and depth of RGB images. They used Gaussian – Bernoulli Deep belief network (GBDBN) for skeleton joint information, Hidden Markov Model (HMM) for the gesture segmentation, Convolutional Neural network for RGB images and Khellat Kihel et al. [6] proposed multimodal person identification using finger-Knuckle print, fingerprint and finger vein which used feature level fusion and decision. Multi bank Gabor transform used for the feature extraction. Classification is carried out using SVM and KNN which resulted in accuracy of 94.91% and 95.58% respectively. Further, Basma et al. [7] proposed the hybrid level fusion based multimodal biometric system using face and iris. 2-D log gabor transform used for the feature extraction. Extensive experiment has been carried out on CASIA face database and Distance Iris dataset which resulted in EER of 0.24% and FAR of 0.06%. Subsequently, Nirmala Saini et al. [8] presented the paper on Gabor Wignor Transform (GWT) based multimodal biometric recognition system which used face and palmprint as modalities. Particle Swarm optimization (PSO) has been used for selection of prominent features. Reduction of feature vector significantly improves the accuracy up to 98.53%. Later, Leslie Ching et al. [9] proposed face and face periocular regions based multimodal biometric recognition using convolutional neural network. It resulted in 98.5% accuracy but performance of system degraded in illumination and appearance variation condition. Again, Dandawate et al. [10] described palm vein, face and fingerprint based multimodal biometric system which used wavelet and curvelet transform for feature extraction. For the classification euclidean distance is used which resulted in equal error rate of 0.03 and 0.05 for wavelet and curvelet transform respectively. Additionally, Sajjad et al. [11] implemented the two-stage multimodal person authentication and spoofing detection based on face, palm-vein and finger-print multimodal data. It used SIFT and hashing techniques for the person recognition and CNN is used for the spoofing recognition. It resulted in 100%, 99% and 98% accuracy for fingerprint, palm-vein and face respectively. Due to addition of many layers, the security increases but their computational complexity is compromised. Further, Tauheed et al. [12] proposed 4-dimensional local feature vector-based fingerprint recognition. For the identification minutiae triplet’s technique has been used. FVC and NIST database were used where the equal error rate was 0.0113. Next, Chang et al. [13] proposed Histogram of Oriented Gradient (HOG) method for fast and efficient face identification. The experimentation has performed on FRGC and CAS-PEAL databases. Whereas, Jianguo et al. [14] presented the system for face detection using SURF features. First it dealt with multidimensional local SURF features and second with area under ROC for convergence test. Finally, it cascaded with fewer stages with faster training convergence. Training done on large database and results showed that the time required is less.
Convolutional neural network is a method which extracts the prominent features. It is a feed forward network which has ability to extract the features from the input images and then classify the extracted features. Experimental results outperform the recognition than conventional methods such as PCA, Gabor filter, Gabor-Wigner transform and many more [15]. Hence to achieve the high accuracy we propose a novel technique with the combination of face, fingerprint and palm vein using CNN structure. The proposed novel approach involves the feature level fusion at second Rectified linear unit layer of Convolutional neural network using Multimodal for better performance.
Network architecture of proposed system.
Database are used for identification and authentication of person for security. In data base generation, the modalities used are fingerprint, face and palm vein. Fingerprint and face database images were generated by same camera [16]. Contactless fingerprint images are used in database, as the application is used in public places, in view of hygiene. During the capturing of images for database, there were 150 subjects. Xpro night vision web camera of 20 Mega pixels is used for capturing face and fingerprint images. For palm vein database generation, infrared optical source captures the vein known as IRVIS (Infrared vein image system). Infrared imaging contrasts the veins from the surrounding tissues, due to the differences in hemoglobin blood and muscle tissues. A higher hemoglobin causes higher absorption of infrared light and hence the veins appear darker compared to surrounding tissues. The system consists of camera and lightning. Infrared light is visible only through filtration where the lens are fully exposed to 35 mm color negative film. Figure 1 shows the database of face, fingerprint, palm vein of 150 individuals, 100 are male and 50 are female. In Proposed methodology self-generated database used of total 1500 images are of face, 1500 images of fingerprint and 1500 images of palm vein. A complete database of 4,500 images is collected, labelled and stored for the research. The face database collected for research has varying 30% images of orientation, 30% of illumination conditions and 40% good images. Out of these, 2700 images were used for training, 300 for validation, and 1500 for testing purpose. The attributes are 1. Image size 64
Details of biometric database
Details of biometric database
Output of convolutional layer 1 is representing the internal connectivity map of each convolutional layers
Shows both the convolutional layer 1 and Convolutional layer 2 internal connectivity maps. They represent the texture and edges of feature maps. In convolutional layer 1 figure shows several 30 features output and convolutional layer 2 figure192 features output.
The research proposes a multimodal multilayer CNN for the person authentication as shown in Fig. 2. The CNN architecture is built for feature extraction and classification within a same structure. The proposed algorithm takes us to a further step where multiple modalities are processed and classified together to provide one single output which is predicted (or recognized) class of input images, i.e. person to whom the biometrics images belong to. For the proposed multiclass multimodality Feature level fusion CNN, dataset is prepared by getting biometrics of predetermined modalities. The resulting images should be of same size and must have same color channel information. Do
Image input layer
The images fed to input layer are of 64X64 size RGB images. Each of the modality input images are pre-processed during training for ensuring the same size.
Convolutional layer
In convolutional Layer 1, the number of filter banks is 96 and the sizes of filter are 7X7 each. The images are enhanced and reshaped through each of these filter banks during classification process. The filter coefficients are self-adjusted during training process to ensure a clear distinction for True/False decision line for the classifier. Convolution equation for original image
Convolutional Layer 1 has multiple filter banks which convolutes image with all the filters to give a band of smaller sized but higher dimensional data. Its volume size is given by
Rectified Linear Unit layer removes all activated image pixel values below zero. This ensures our classification work in a finite space with lower variance. A higher variance space for classification causes a much complex classification segmentation curve. ReLU layer decreases a need of complex classifiers and hence, a typical CNN has much smaller number of hidden layers in fully connected layer in comparison with typical machine learning algorithm which uses neural network as classifier [19]. Linearities in the convolutional layer output are removed using Eq. (4).
The data is fed to Max pooling layer though a hidden input layer which acts as a connection bridge between all CNN which processes each modality inputs. The Max pooling layers are just for reducing complexity of data and ensure faster classification process. Max pooling layer consists 2X2 max pooling filter with 2 strides which reduces the image size by half in both x and y dimension for all filtered channels.
As the data from Fusion layer will have very large size (The image sizes are 4800. Max pooling layer 2 reduces it further to 2400 (as it has size and stride of 2). The Max pooling layers does nothing else but reduces data size and propagates only higher valued, i.e. more prominent features for the following layer. It helps in reducing the complexity of fully connected layer by reducing data size and only retaining higher valued features.
Fully connected layer
Fully connected layer gets size reduced. Fully connected layer contains a multi-layered neural network designed as a self-bias feed forward type of network for calculation of matching probability. The number of neurons in input layer depends on the size of feature being fed to the classification layer. The higher number of neurons means more connections, more calculations. Hence gives higher accuracy, complex network and large time for calculation. while a smaller number of layers give faster result with lesser accuracy. As the proposed system have a CNN designed to generate a very large sized feature array a fully connected layer with only 10 hidden neuron layers proved to be a great classifier.
SoftMax layer
SoftMax layers takes output from output neuron layers from fully connected layer and converts that into matching probability equations. The Soft Max layer usually contains an equation which converts input data into decision and decision probability.
Fusion (proposed method)
Fusion Layer takes all activated outputs from convolutional layer 2 of all modalities. The Fusion are done by different fusion rule methods after ReLU layer.
Fusion Rules implemented on self-developed database:
Mean Method Maximum Method Maximum Orthogonal Component method.
a) Mean Method
Mean Method takes mean of each value from feature vector of face, finger and palm vein.
b) Maximum Method
Maximum method takes maximum of each value from feature vector of Face, Finger and Palm.
c) Maximum Orthogonal Component Method (Proposed Method)
Mean method fusion accuracy achieved is less due to averaging all features of multimodal. Maximum method accuracy achieved was better than mean method, but only highest features were considered. Modality whose feature value is high was selected rather than other two modalities. Hence Maximum Orthogonal Component (MOC) Method/rule is used for fusion where all modalities features can be considered. In MOC there are three input features of face, fingerprint and palm vein which are fused together from where the maximum eigen features is considered. In fusion, most prominent features are given to output.
Hence most of the times face features were considered rather than fingerprint or palm vein features. All modalities features should be considered at the output as prominent feature, so we proposed maximum orthogonal rotation method. The features are unevenly distributed of face, fingerprint and palm vein. The features which are orthogonally at the maximum distance from the diagonal line are selected as the output feature set which allows the selection of maximum discriminant features from the fusion of the face, palm vein and finger print as given in Eq. (7).
Maximum orthogonal components select the specific features from the given features. Maximum orthogonal components work on rotation of Principal Components features as given in Eq. (8),
Where,
Where rotated feature projections are given by
Proposed CNN parameters
Comparison of accuracy using fusion rules
For assessment of the proposed network, a lab-generated high-variance database was used for training and testing. For each modality, a database was generated by collecting samples from 150 individuals. From the generated dataset of each modality, sixty per cent (900 images) were used for training the CNN. Every individual had ten samples for each of the modality (10 for a face, 10 for a finger and 10 for palm-vein). Out of these images, six images were used for training, one image for validation, and three for testing. Therefore, the whole dataset was divided into 60:10:30 division. Considering 150 individuals for each modality accumulated a dataset of total 4,500 images. Out of these, 2700 images were used for training, 300 for validation, and 1500 for testing purpose. Dataset generated had considerable variation in illumination and orientation. Even though having a variation in database, the performances of CNN were not hindered by a high degree. Experimentation was done in MATLAB
Features extraction from each trait using Convolutional Neural Network is applied to each modality face, fingerprint and palm vein from where the accuracy parameter is calculated. Here the image is firstly applied to the convolutional layer where the input size is of face 64x64x3, Fingerprint 64x64x3, and Palm vein 64x64x3. Filter size is 7x7x3. Subsampling is done through [2x2] and stride is [1,1] and padding [0.0]. Convolutional filter used 96 filters for first layers and 576 filters for second convolutional layer. Fully connected layer consists of 10 hidden layers. Accuracy calculated using this CNN structure on the self-generated database is high for all three modalities network. The Accuracy for Face is 95%, Fingerprint is 94% and Palm vein is 99%. Table 2 gives the CNN configuration required for CNN network.
Fusion rules such as mean rule and max rule are applied for fusion in convolutional neural network after ReLU layer. Self-developed database was used for the network. As observed that due to mean rule and max rule applied to fusion, the accuracy achieved is not satisfactory. The performance of the proposed system is compared with the mean and maximum method of fusion and it is found that MOC outperforms both techniques by resulting in to 96.7% accuracy. The maximum orthogonal component method is proposed for fusion which increases the accuracy and improves the recognition rates as shown in Table 3.
ROC curve of fusion.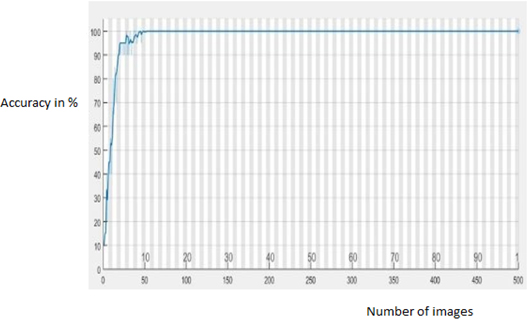
Figure 5 shows the ROC curves where accuracy is overall high for Fusion. ROC curve also shows high convergence during training process.
Comparison of accuracy using different algorithms
CNN configuration and output features
Proposed method run time
Feature level fusion using CNN-MOC Output features. The fused feature array is shown between length of features and magnitude of CNN.
Table 4 indicates Comparison of accuracy using different algorithms. For developing the robust system different algorithms were experimented on the same database of face, fingerprint and palm vein. Automatic feature extraction without pre-processing of original image is the advantage of our proposed network. The overall fusion accuracy using CNN achieved is 96.7% on same database as compared to other conventional fusion method. It is concluded that our network gives very good accuracy.
Table 5 indicate the output features of each layer of the CNN.
Figure 6 Feature level fusion using CNN-MOC Output features. The fused feature array shows the feature array between length of features and magnitude of CNN. Fused Feature array shows high magnitude for the prominent features.
The Run time of the proposed method using CNN for face, fingerprint, palm vein and fusion of all modalities is shown in Table 6. The run time for face, finger print and palm vein and fusion are nearly same.
Multimodal biometric recognition system is developed by using modalities such as face, palm vein and finger print with convolutional neural network. Two layered convolutional neural networks with maximum orthogonal component fusion technique is carried out for recognizing the person. Maximum orthogonal component selects the more informative features from the CNN feature maps of the face, palm vein and finger print, it also reduces the output feature map. The performance of the proposed system is evaluated on the basis of % recognition accuracy. Proposed maximum orthogonal component gives better performance than the mean and maximum rule for fusion and resulted in 96.7% accuracy. Future work consists of increasing number of CNN layers and minimization of training time to improve the recognition accuracy.