
Abstract
Single biometric modalities like facial features and vein patterns despite being reliable characteristics show limitations that restrict them from offering high performance and robustness. Multimodal biometric systems have gained interest due to their ability to overcome the inherent limitations of the underlying single biometric modalities and generally have been shown to improve the overall performance for identification and recognition purposes. This paper proposes highly accurate and robust multimodal biometric identification as well as recognition systems based on fusion of face and finger vein modalities. The feature extraction for both face and finger vein is carried out by exploiting deep convolutional neural networks. The fusion process involves combining the extracted relevant features from the two modalities at score level. The experimental results over all considered public databases show a significant improvement in terms of identification and recognition accuracy as well as equal error rates.
Introduction
The purpose of a biometric recognition system is to verify a person’s identity accurately. Biometric recognition systems can be classified based on physical traits and behavioral traits. Physical biometric systems rely on physical body parts of a person such as fingers, hand, face etc., whereas behavioral biometric systems rely on gait, signature, keystroke pattern and speech. The most widely adopted biometric solutions use finger and face based physical traits. These are vulnerable to spoof attacks such as static impersonations which render a person’s identity unsecure. This created a demand for more secure biometric modalities and as a result finger vein recognition techniques became relevant. The finger veins are internal components of the body which makes them harder to forge as compared to fingerprints. The medical sciences have proved that finger vein pattern is unique for each individual, even for twins. In addition to this, finger vein is immune to ageing which makes it sensible to adopt. Even if there is a deformity in the finger, the finger veins remain intact. Another important characteristic of finger vein verification is live body detection, making this technology even more secure.
Even with an edge over the existing solutions, any unimodal biometric system measures and analyzes a single characteristic of the human body. These have many limitations like noise in sensed data, non-universality of the modality being used, lack of individuality, intra-class variation (during training and testing) etc. [1]. To overcome these problems, we propose a multimodal recognition framework using finger-vein and face data by exploiting deep convolutional neural networks.
The two chosen modalities provide robustness over each other’s limitations. A face could become a victim of spoofing attacks so the corresponding finger vein could be relied upon for an identification result. On contrary if there is a lot of noise in the infra-red imaging of finger vein then the face would balance out the differences and provide a fair identification result. Perhaps the biggest advantage is the fact that both these biometric modalities are non-contact while offering high accuracy which not only makes them user friendly but also a perfect solution in such times of a pandemic where the use of the most widely adopted conventional state of the art techniques such as fingerprint biometric scanners becomes restricted.
In this work we have proposed a multimodal biometric system that performs both identification and recognition (genuine/imposture) based on score level fusion of face and finger vein modalities. The entire process can be broken down into the following stages: Image pre-processing that involves region of interest (ROI) extraction and data augmentation. Feature extraction using convolutional neural networks (CNN) with SoftMax (Section 4.2) classification. Score level fusion of classification result of the two modalities.
For feature extraction, we have proposed two CNN architectures for finger vein and face unimodal classification respectively.
Under data augmentation, rotation and illumination of finger vein images was performed in order to induce variations in original images and to increase the size of training data, which helps in creating a robust model that is not sensitive to sensor quality from which images have been obtained.
For score level fusion, different techniques were employed and compared. The SoftMax outputs obtained from the classification models of each modality are fused using these techniques. The resultant fused vector is then analyzed to perform identification and recognition.
For identification the class labels corresponding to the maximum value obtained in the fused score vector is recorded which provided the predicted class. In order to perform recognition, threshold values were calculated for each of the employed fusion techniques. This threshold would then provide the binary classification of imposter or genuine.
Literature review
Various multimodal techniques for biometric identification and recognition have been employed till date using different combinations of modalities among face, iris, fingerprint, finger vein, voice etc., along with different fusion mechanisms such as score level, feature level and decision level fusion.
Ammour et al. [1] constructed a multimodal biometric system with face and iris modalities. Singular Spectrum Analysis (SSA), Normal Inverse Gaussian (NIG) combined with statistical features of wavelet were used for facial feature extraction. Features for iris were extracted using multiresolution 2-D Gabor filter. Further in order to reduce the computational cost they used Spectral Regression Kernel Discriminant Analysis, to select the prominent and discriminative features. Feature level fusion of face and left iris and score level fusion of face, left iris and right iris was carried out. Finally, OR rule of decision level fusion was applied on previously obtained results. During training phase, they stored the fusion feature encodings in the database. Then while testing the fusion feature vector obtained from the input face and iris images was compared with the stored vector using simple Euclidean Distance method. The classification output indicated acceptance or rejection of the tested subject. They reported a Genuine Acceptance Rate (GAR) of 99.50%.
In 2010, Razzak et al. [2] developed a multimodal recognition system based on finger vein and face. The feature extraction for face was carried out using Client Specific Linear Discriminant Analysis (CSLDA) which generated imposter and genuine score for each specific face, which was later fused. For finger vein they used Gabor filter to enhance the images followed by thinning operation to obtain skeleton for feature extraction. Statistical and topological features were then extracted for vein images. Fuzzy fusion technique was employed to fuse the two modalities and fusion scores were obtained. Technique similar to [1] for training and testing was employed, comparing the scores of stored and input images using Euclidean distance followed by thresholding to distinguish between an imposter and genuine. A GAR of 91.4% was reported.
Kang et al. [3] built a multimodal system based on vein pattern and geometry of finger. Local adaptive binarization and skeletoning methods were employed for finger vein image segmentation. Ending and bifurcation points of a finger vein were extracted as finger vein features. Matching scores were then calculated using Modified Hausdorff Distance (MHD) between feature points of enrolled image and of input images. For finger geometry, thickness value of finger region was calculated using Fourier descriptors to represent the thickness values in frequency domain. For matching, again Euclidean distance technique was used. Score level fusion was then carried out to fuse the matching scores obtained previously followed by Z score normalization of the fusion score. Finally, Support Vector Machine (SVM) technique was employed to obtain classification results. The best Equal Error Rate (EER) reported was 0.37% for weighted sum score fusion technique. Later in 2011 Kang et al. [4] also worked on a multimodal system combining traits like vein, print and shape of a finger.
In 2014, Manjunathswamy et al. [5] proposed a multimodal personal authentication system (MPAFFI) using finger vein and face. Features from both modalities were extracted using Gabor kernels. Using Gabor Kernels fine grain localization was obtained in spatial and frequency domain that negated various environmental conditions like intensity, position, orientation and illumination. Fischer Score and Linear Discriminate Analysis (LDA) was used to carry out dimensionality reduction of feature space. Feature fusion was obtained by applying simple union method on unimodal extracted features. Finally, Weighted K-Nearest Neighbor (KNN) technique was employed for classification and an accuracy of 98.22% was reported.
In recent years, convolutional neural networks (CNN) and deep learning have proven to be superior when compared to traditional methods in various recognition problems in terms of performance and robustness as these automatically the most relevant features. Many of such CNN and training based multimodal techniques were studied.
Kim et al. [6] designed a multimodal biometric system based on finger vein and finger shape. Images were first binarized and accurate finger regions were extracted using Convex Hull algorithm followed by masking to detect finger boundaries. Features for both modalities were extracted using different CNN architectures like ResNet-50, ResNet-101 and VGGNet-16. For finger vein, difference images (pixel value differences between two images belonging to separate classes) were fed into the CNN for feature extraction. For finger shape Dimensional Spectrogram images were generated to detect finger shape features and frequency components were extracted using short-time Fourier transform (STFT). These were then fed into CNN to extract features. Various score level fusion techniques were employed where weighted product rule showed the best accuracy.
Kisku et al. [7] developed a multimodal system using face and ear as two modalities and used Gaussian mixture model for generating scores and Dempster-Shafer (DS) decision theory to interpret scores.
Peng et al. [8] presented an evaluation of normalization and fusion techniques using finger-vein and fingerprint biometrics. Using a commercially available undisclosed feature extractor, they compared and contrasted fusion methods using three score normalization techniques (Min-Max, Z-Score and Hyperbolic Tangent) and four score level fusion approaches (Minimum Score, Maximum Score Simple Sum and User Weighting). The fused-score classifies an unknown user as genuine or impostor. Best fusion performance was achieved by the combination of Hyperbolic Tangent (TanH) score normalization technique and Simple Sum (SS) method for fusion, yielding an EER of 0.00010%. In addition, it was observed that MinMax and Z-Score methods are sensitive to outliers while TanH was both robust and efficient.
Cherrat et al. [9] developed a multimodal biometric identification system based on fingerprint, finger vein and face. For finger print, Soble and TopHat filtering methods were used that improved the quality of the image by limiting the contrast. After that, K-means and DBSCAN approaches were applied to classify the image into foreground and background region. In addition, the Canny method (Canny, 1987) [9] and the inner rectangle were adopted to extract ROI. For finger vein after following similar ROI extraction as finger print, contrast amplification of the vein image was carried out. Feature extraction was carried out using CNN and Random Forest (RF) method was employed as a classifier. For face images, feature extraction based on CNN and SoftMax classifier were employed. Traditional data augmentation was also performed involving rotation and translation variation of images. Score level fusion of the features extracted was carried out based on the weighted sum and weighted product methods. The results proved superior accuracy of multimodal system over unimodal system in terms of accuracy. Overall, CNN was shown to provide better accuracies (99.33% for the finger vein and face combination) than traditional methods. The image enhancement techniques employed also helped in improving high identification rates.
Later, Cherrat et al. [10] proposed a score fusion based human recognition system based on finger vein and face modalities only. In this model, they employed Adaptive Histogram Equalization (AHE) technique to improve the contrast of finger vein image. Then feature extraction was done using CNN and classification using RF classifier. For face, after extracting features using CNN, SVM was employed as a classifier for face classification. Weighted sum score level fusion of the tow modalities provided the final score that was compared against a threshold to provide acceptance/rejection result. The AHE technique proved to improve accuracy as features became more distinguishable. An accuracy of 99.93% and 99.98% on their two considered datasets was reported for the complete multimodal system.
Work focused specifically on unimodal biometric systems involving face and finger vein modalities was also studied.
For finger vein recognition traditional state of the art non-training based methods like Maximum curvature [11], Repeated line tracking [12], Gabor filter with LBP [13] were studied. Training based methods that employed deep CNN models were also studied. Das et al. [14] constructed a deep CNN architecture to extract features and classify finger vein images reporting the best accuracy of 97.53% on FV-USM dataset. Hong et al. [15] used VGGNet-16 architecture to extract features from finger vein images and reported an EER of 0.396% on good quality dataset and 3.906% on bad quality dataset. Meng et al. [16] employed modified AlexNet [17] architecture and an authentication system was developed based on Euclidean distance between feature vectors of vein images with an accuracy of 99.4%. Methods proposed by Parkhi et al. [18] using ResNet-50 architecture and one by Schroff et al. [19] were also studied for facial recognition.
Findings from our previous study Chawla et al. [20] were also used as a basis for finger vein feature extraction using deep CNN. The study proposed a unimodal finger vein biometric identification system where a CNN architecture inspired from AlexNet [17] was proposed for feature extraction of finger vein images. Further a one-shot learning model was also discussed based on the Triple Loss Network proposed in [19] for image verification purpose. The model was trained on raw data and highest accuracy reported was 97.35% for FV-USM dataset. In this paper we have significantly improved upon this previous unimodal system performance with modifications and additions at several stages in the entire process the intricacies of which are discussed in further sections.
Database description
The considered datasets are among the most common publicly available datasets employed by the majority of existing proposed models.
Finger vein
From the two datasets used, first one is provided by Universiti Sains Malaysia (FV-USM) and second by Shandong University (SDUMLA-HMT). The FV-USM database contains images from 123 subjects recorded in 2 sessions while the SDUMLA database consists of images from 106 subjects.
An important thing to note is that there is no relation between vein patterns among different fingers belonging to the same person. Hence each individual finger can be treated as a separate identity. A more detailed description of the datasets is given in Table 1.
Dataset used for finger vein
Dataset used for finger vein
From the two datasets used, first one is provided by Shandong University (SDUMLA) and second by University of Essex (UE). The SDUMLA dataset contains faces from 106 subjects (male and female) with different poses, facial expressions, accessories and illuminations. The dataset provided by the University of Essex contains images of 395 subjects (male and female) of various racial origins with age groups mostly between 18–20 years old but some older individuals are also present. Variations among samples also include facial expressions, accessories (glasses), illumination and image backgrounds. A more detailed description of the available classes is given in Table 2.
Dataset used for face
Dataset used for face
The multimodal classification process can be broken down into two stages: Unimodal classification and Fusion. In order to classify, the images first needed to be processed to remove noise and extract useful information. Processed images of respective modalities are passed to their corresponding convolutional neural network in order to compute scores. These scores are then fused using various score level fusion techniques to obtain multimodal classification.
Image preprocessing
Image preprocessing is required in order to rule out unnecessary areas/part of an image that does not provide any information. The processing of images is split into the following 2 stages: ROI extraction and Data augmentation.
Finding the region of interest (ROI)
For finger vein images, initially all the images are acquired from the database and are cropped to extract the ROI as illustrated in Fig. 1. As the samples do not involve much drastic variation a simple brute force method for cropping proved to produce satisfactory results. Also the FV-USM dataset already provides ROI cropped images.
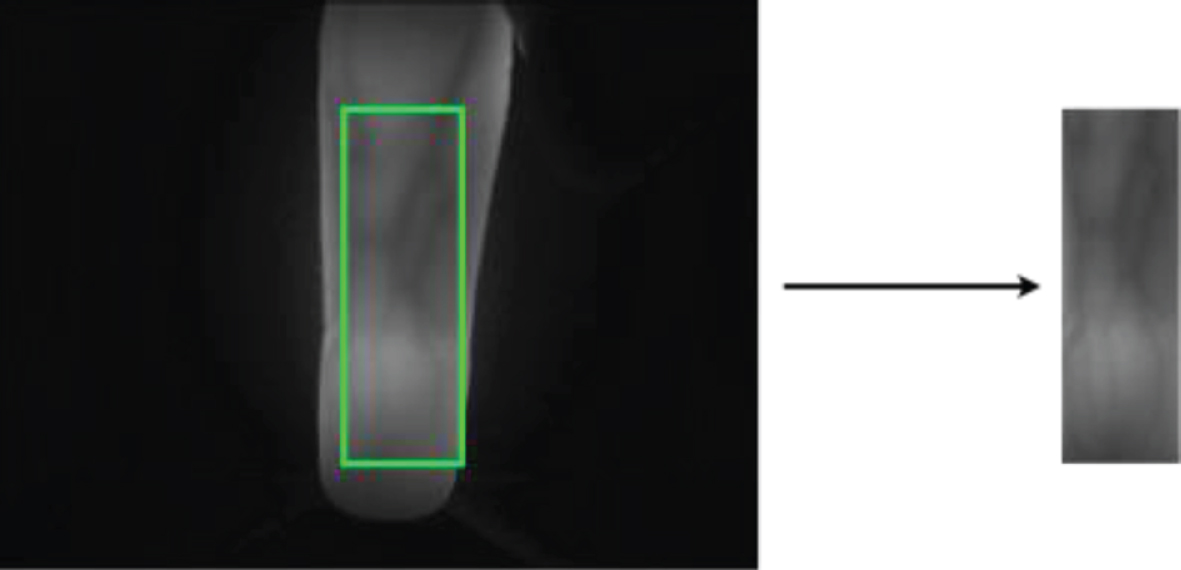
Finger vein ROI extraction and resizing to 100×300 pixels.
For face images, even though the SDUMLA dataset provides all images in a uniform format and resolution, there are still prominent variations like poses and accessories where the face of the individual occupies roughly 30% to 40% of the total raw image area. The other dataset from the University of Essex contains no uniformity over resolution or quality. Additionally, the dataset consists of 4 sub-datasets of increasing difficulty where the quality of image and area occupied by face compared to the complete image decreases and background noise increases.
The required ROI is just the face of the individual. Due to the range of variations across the two face datasets a brute force cropping solution wouldn’t provide satisfactory results hence a more sophisticated method was needed. The method employed is multitask cascaded convolutional networks (MTCNN) [21]. Figures 2 and 3 show the variations among face image samples of an individual and the ROI extraction process respectively.

Face samples of one individual from SDUMLA dataset.

Face image ROI extraction and resizing to 224×224 pixels.
Training deep learning neural network models on greater data makes them more skillful, and the augmentation techniques can improve the ability of the fit models by helping them learn in a more generalized way by creating variations of the images.
The images obtained from the finger-vein datasets contain only 6–12 samples per individual class. Taking a look at these samples reveals some variation in terms of translation whereas little to no variation of the finger image in terms of rotation and illumination. Translation, rotation and illumination are the three major types of variations pertaining to this domain that are expected in a practical scenario. In addition, by comparing the quality of a single image belonging to each dataset against each other indicates an image’s heavy dependence on sensor quality. Since the finger vein images contained in the datasets show only a slight indication of the presence of major variations and the number of samples are too less to make the classification robust against quality of the sensor, the data needed to be artificially augmented.
Since the provided samples show prominence of translational variations only, more emphasis is laid upon generating rotated and varied illumination samples.
For all 6 samples per class per session, 5 rotated samples are generated where the rotations for each sample are randomly chosen in the ranges 10 degrees anticlockwise to 10 degrees clockwise. As illustrated in Fig. 4 this produced 5 additional samples for each of the 6 original samples.
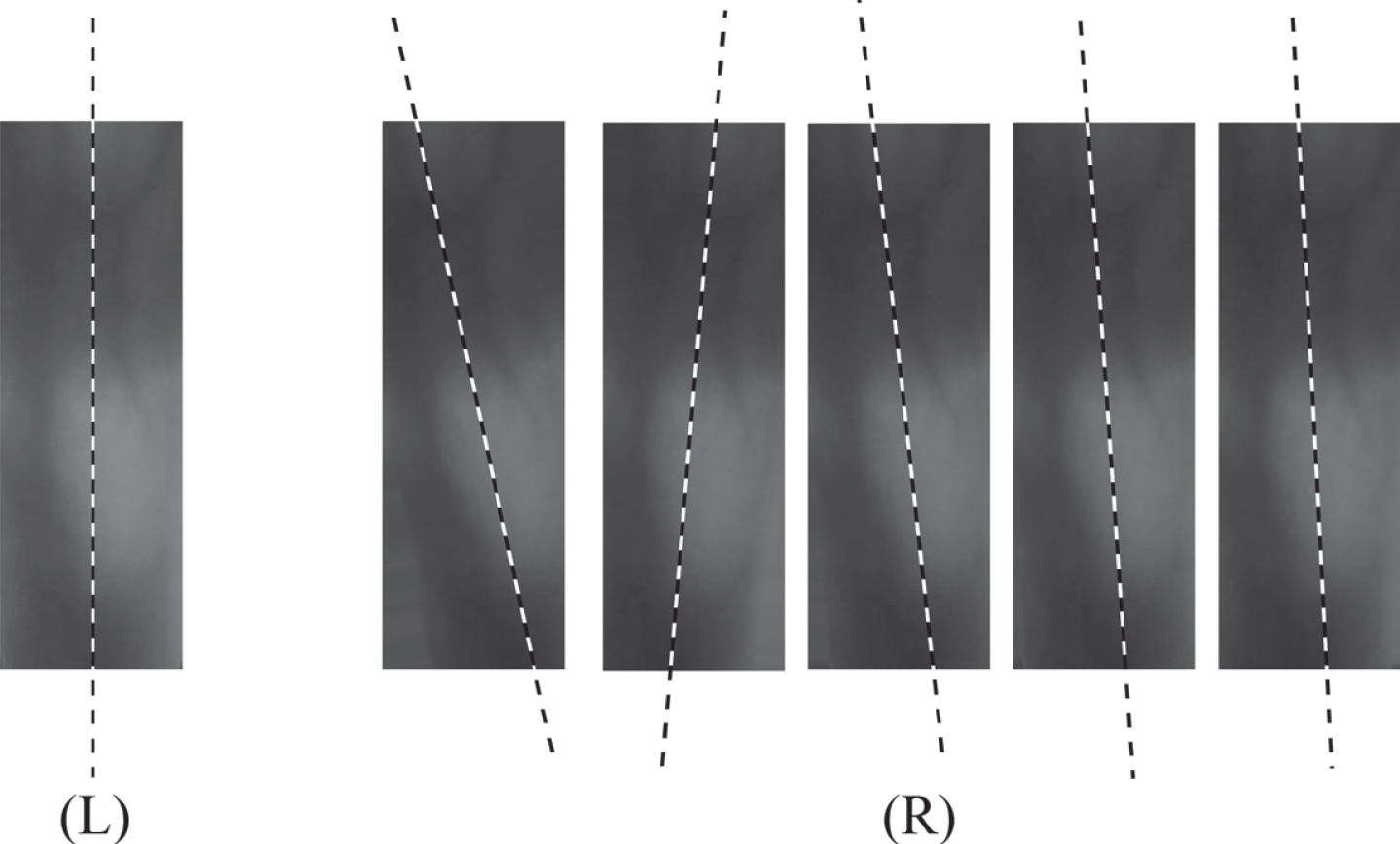
Finger vein data augmentation of original image (L) by generating 5 random image rotation samples (R).
Now consider a subset containing only those samples which were artificially generated in the previous step i.e. rotated samples only. For each of these rotated samples, 10 samples are generated randomly from a range consisting of varying brightness levels as illustrated in Fig. 5.

Finger vein data augmentation of rotated image (L) by generating 10 random brightness samples (R).
This procedure is carried out for samples across both sessions. Hence the three major types of variations - rotation, translation and illumination are artificially introduced to the finger-vein dataset which increased the number of samples to 615 per class.
The face datasets already consist anywhere between 20 to 80 samples per individual. There are more than enough prominent variations among these samples as they span over different types of poses, lighting conditions, quality, accessories etc. to achieve an acceptable accuracy over classification hence data augmentation is not required.
The generated finger vein samples are all resized to 100×300 for both datasets and face samples to 224×224 to match their respective convolutional neural network input shapes as the proposed architectures needs to be independent of the dataset used. Hence resizing ensures uniformity and robustness. The resizing of samples is done using bicubic interpolation method.
The proposed model uses Convolutional Neural Network (CNN) for unimodal classification of finger vein and face images. CNN extracts the most robust features from the images which are then used to classify images. CNN consists of a set of Convolutional layers, Pooling Layer, Activation Layer etc. followed by a fully connected network.
Convolutional layer performs convolution operation between kernels matrix and input matrix.
Pooling layer draws the predominant features from convolved output.
Activation functions estimates the activation of a neuron. ReLu activation function is represented by Equation (1), where F (x) is the natural output/activation of a particular neuron:
Soft Max classifier performs exponential normalization of network output scores yielding the probability distribution across all class labels as shown in Equation (2) where O
i
is the natural output/activation of a particular i
th
neuron, C is the total number of classes and σ (O) denotes the probability distribution.
Dropout Layer: To avoid the problem of overfitting, dropout layer during training blocks out a random set of activations in that layer. This is done by setting these random activation values to 0. They are used only in training, to make the model more robust and redundant for the same training samples.
Padding: Filters reduces the dimensionality of input feature map in CNN, hence in order to avoid the loss of information in early stages of training Padding is used. Padding is the addition of pixels to the edge of an image. These pixels are set to zero, so that they have no effect on the dot operation when the filter is applied. This is called zero-padding.
Batch Normalization: It is a normalization process applied on hidden layers to limit the covariance shift. This helps in reducing the distribution of parameters in higher layers due to changes in lower layers, i.e. it makes hidden layers weekly coupled, more independent, and thus makes the system more robust.
Separate CNN architecture models are constructed for unimodal classification of face and finger-vein. Both CNN architectures are inspired from AlexNet [17] which is one of the most popular standard CNN architectures. A detailed discussion of the proposed architectures has been done in Section 5.
The unimodal classification models will produce SoftMax classification output which is a vector of C × 1 where C is the number of classes. SoftMax function is a normalized exponential function hence the output from the last layer of CNN is normalized between the values 0 and 1 which signifies the probability distribution amongst C classes. The SoftMax output for all classes together sums to 1. The two classification results now need to be fused together to produce a single scalar identification result. This fusion is carried out using various score level fusion techniques.
Score level fusion consolidates the scores obtained from unimodal subsystems in order to make decision about the identity of an individual. Let Δ
i
represent score obtained from the i
th
unimodal subsystem and n represents the total number of modalities used. Various score level fusion techniques [22] employed are stated as follows: Sum Rule: Combines the score from individual unimodal subsystems but taking summation of their scores as given by Equation (3).
Weighted Sum: Combines the score from individual unimodal subsystems by taking summation of their weighted scores as given by Equation (4). Weights w1, w2, . ., w
n
are assigned to each score value.
Product Rule: Combines the score from individual unimodal subsystems by taking product of their scores as given by Equation (5).
Weighted Product Rule: Combines the score from individual unimodal subsystems by taking product of their scores raised to the power of weights respectively, such that Perceptron Rule: As shown in Equation (7) it combines the score from individual unimodal subsystems with weights Frank t-norm: Combines the score from individual unimodal subsystems as shown in Equation (8).
Yager’s t-norm: Combines the score from individual unimodal subsystems as shown in Equation (9).
Schweizer-Sklar t-norm: Combines the score from individual unimodal subsystems as shown in Equation (10).
Triangular norm (t-norm) is a binary operation that satisfies commutativity, associativity and monotonicity. It maps [0, 1]×[0, 1] to [0, 1] range. 1 is the identity element of t-norm.
Figure 6 illustrates the high level architecture of the proposed multimodal framework. The individual components have been discussed in following subsections.
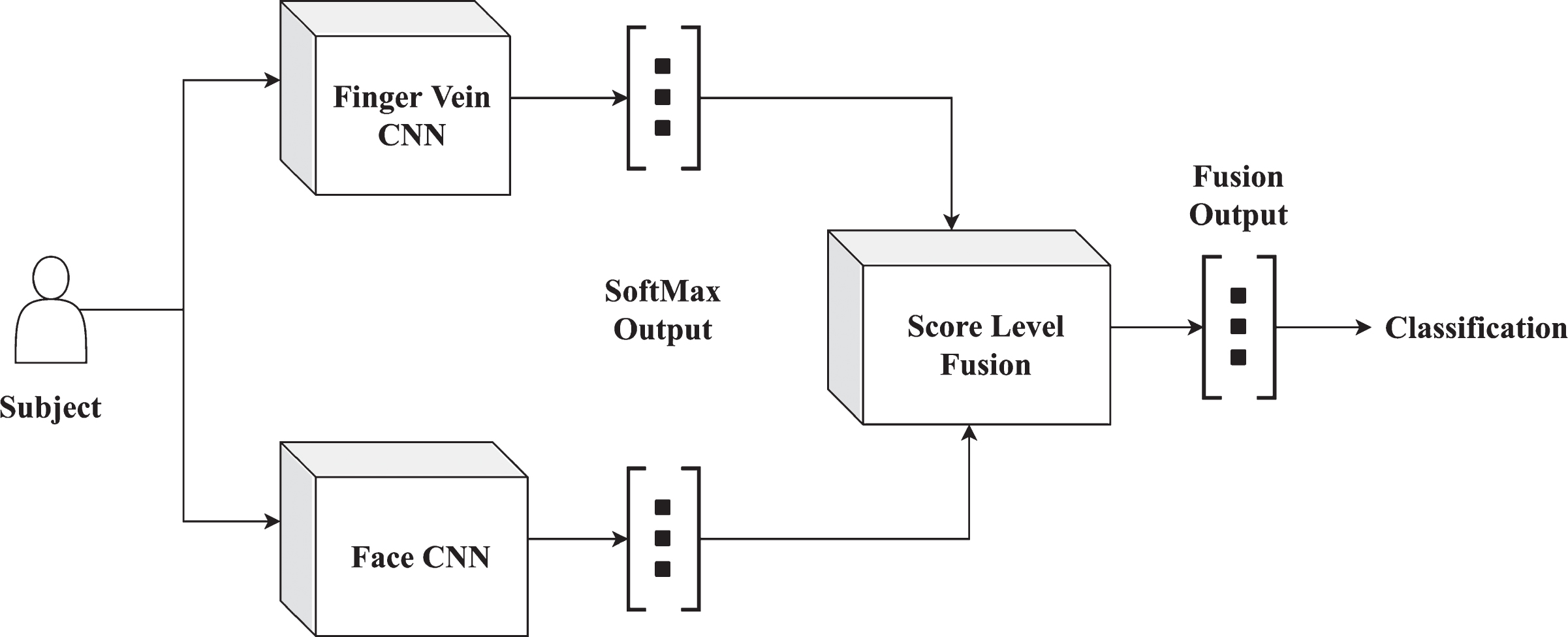
Proposed multimodal classification high-level architecture.
Both deep convolutional neural network architectures for unimodal classification are inspired from the AlexNet [17] architecture.
The architectures are comprised of a number of Convolutional, Max Pooling, Zero Padding and fully connected (Dense) layers. A detailed summary of the two architectures has been described in Fig. 7. In both architectures, the final output layer consists of C units where C is the number of classes. The intermediate convolutional layers use ReLu activation as per Equation (1) and the final output layer uses SoftMax activation as per Equation (2). The face architecture in addition contains zero padding layers.
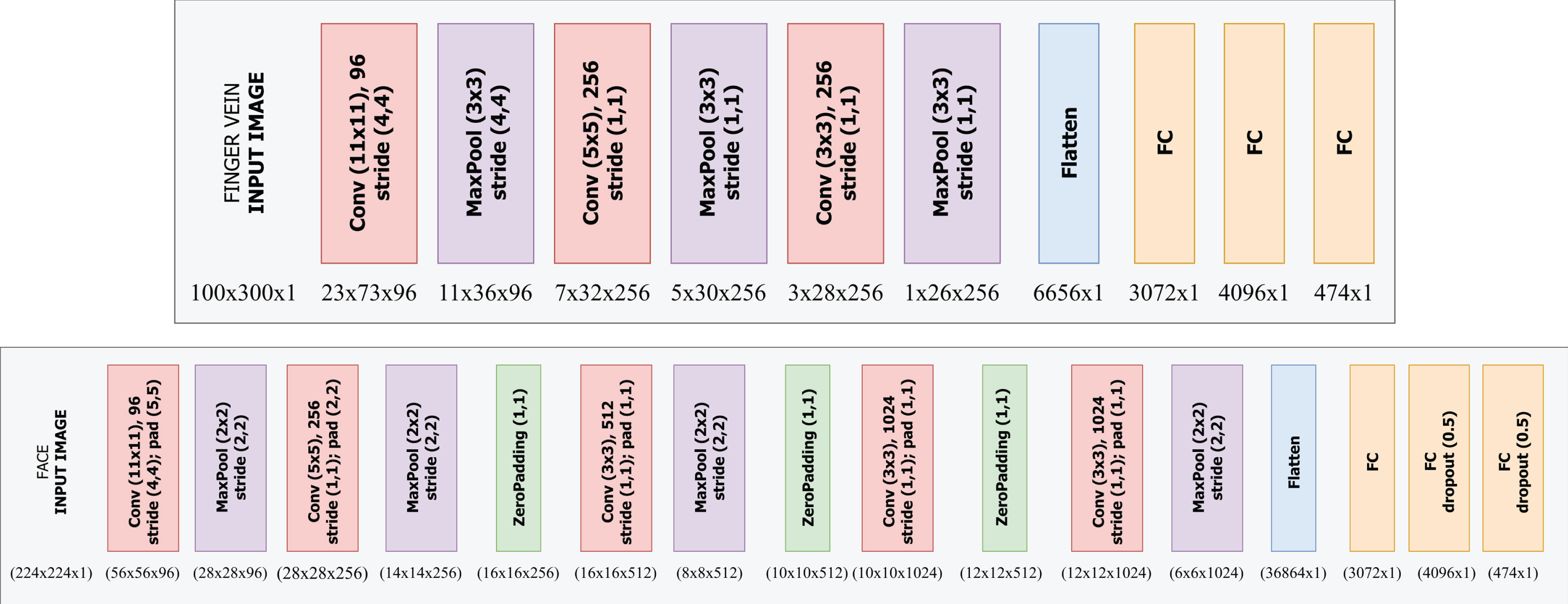
CNN architecture for finger vein (top) and face (bottom).
Let C1 and C2 denote the number of classes in finger vein and face datasets respectively. As discussed in Section 4.1.1 the MTCNN [21] method is used for face detection and ROI extraction from the samples provided by the two face datasets. Hence the number of total available classes C2 as well as number of samples in each class gets reduced in number due to limitations of MTCNN [21] algorithm and poor quality of some samples. Let C T denote the total number of classes which in our case is min(C1, C2) that came out to be 474.
After performing data augmentation for finger-vein images as discussed in Section 4.1.2, a total of 615 samples for an individual would be present. Now as evident by trial and error, too many training samples cause the deep neural network to learn very specific features for a single class not resulting in the best accuracy. Hence the total finger-vein samples for a single class are limited to 66 chosen in random fashion. From these limited samples 20% were assigned to the testing dataset. A uniform 60% –40% split was performed on remaining data samples where 40% samples are used for validation and 60% for training.
For face classification all available samples are considered. Since the total samples S per class vary across a wide range of 20 to 80, to maintain uniformity in the training and testing patterns 2 samples are chosen at random out of the S available samples for testing. An 80% -20% split is performed on the remaining samples for training and validation purposes respectively. Since the samples already show more than enough variations as discussed in Section 4.1.2, randomized selection ensured generalized learning for the neural network. A batch size of 32 is decided upon for both networks for training by trial and error.
Once the network models are trained, the 2 vectors of dimension C × 1 representing the SoftMax classification output needed to be fused where C is nothing but value of C T .
Let the two vectors of dimension C × 1 generated by the unimodal subsystems be vector V1 (Finger) and V2 (Face). A fused vector V F is obtained by performing each of the employed score level fusion techniques as mentioned in Section 4.3. Each V i is mapped to Δ i and V F to the output value Δ in the formulae. All the other parameters used are mentioned in Table 3.
Score level fusion techniques along with their parameter values
Score level fusion techniques along with their parameter values
Identification
Following the calculation of fusion score vector V F for a test sample, the label or class associated with the maximum score S max inside the resultant fusion vector is recorded. This maximum score S max represents the score belonging to the predicted class C P of the given test sample, since during preprocessing, images are mapped to their classes which are nothing but indices from 1 to C (474) forming a C × 1 vector O actual containing actual classes C A and trained accordingly. As shown in Fig. 8, this predicted class C P is compared with the actual class C A for that test sample present in O actual . The process is carried out for 100 iterations and average accuracies are reported.
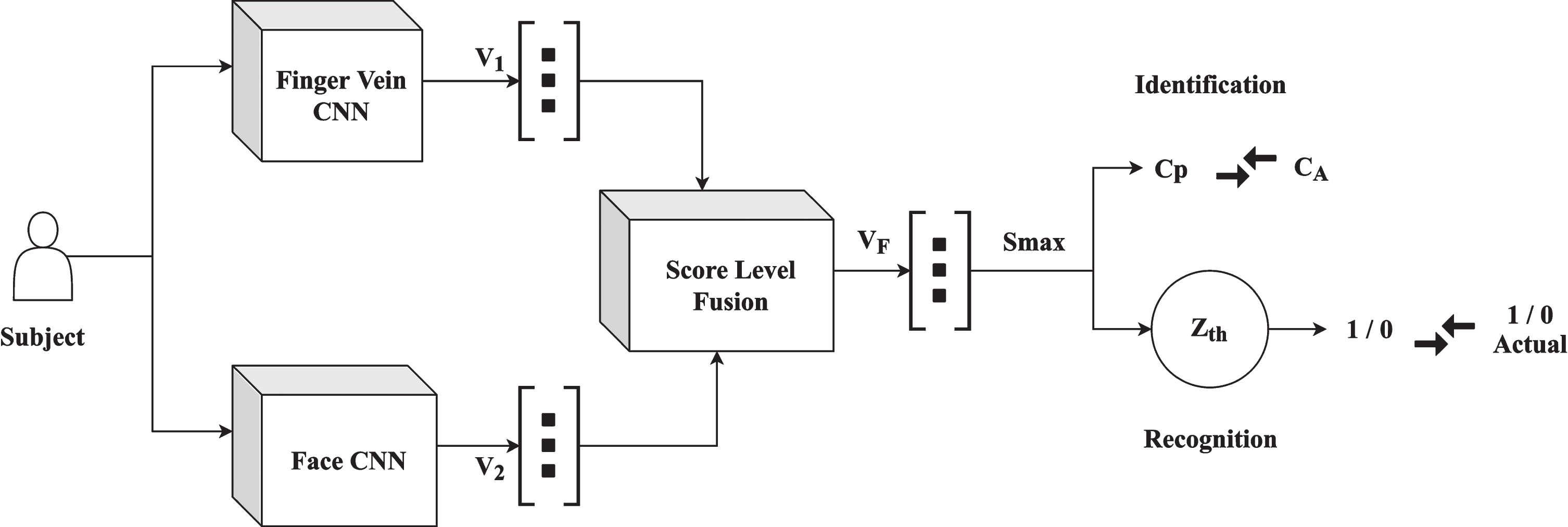
Identification and recognition architecture.
The maximum score S max is obtained in a similar fashion as in Section 5.4.1 and a threshold is applied to S max . If this score crossed the threshold value Z th then the tested sample is recognized as genuine otherwise it is deemed as an imposture. This now becomes a case of binary classification where label 1 represents a genuine individual and 0 represents an imposture. Thus pairs of input images representing the face and finger of a person are passed through the model which the model would recognize as genuine or imposture.
As shown in Fig. 8, the predicted binary classification is compared against the true labels (0 or 1) set for the input pairs. The process is carried out for 100 iterations and average accuracies are reported. The threshold values used for different score level fusion techniques are provided in Table 4.
Recognition threshold values for different fusion techniques
Recognition threshold values for different fusion techniques
Performance characteristics like False Acceptance rate (FAR), False Rejection Rate (FRR), Equal error rate (EER) and accuracy are reported to quantify the performance of the proposed model and are compared with existing training and non-training based approaches. Figure 9 shows the confusion matrix for multi-class systems, where TP (True positive) is the number of samples of i th class which have been classified correctly, FN (False Negative) is the number of samples of i th class which have been classified incorrectly, FP (False Positive) is the number of samples of j th class where j ≠ i, which have been incorrectly classified as i th class. TN (True Negative) is the number of samples of j th class where j ≠ i which have been classified correctly.
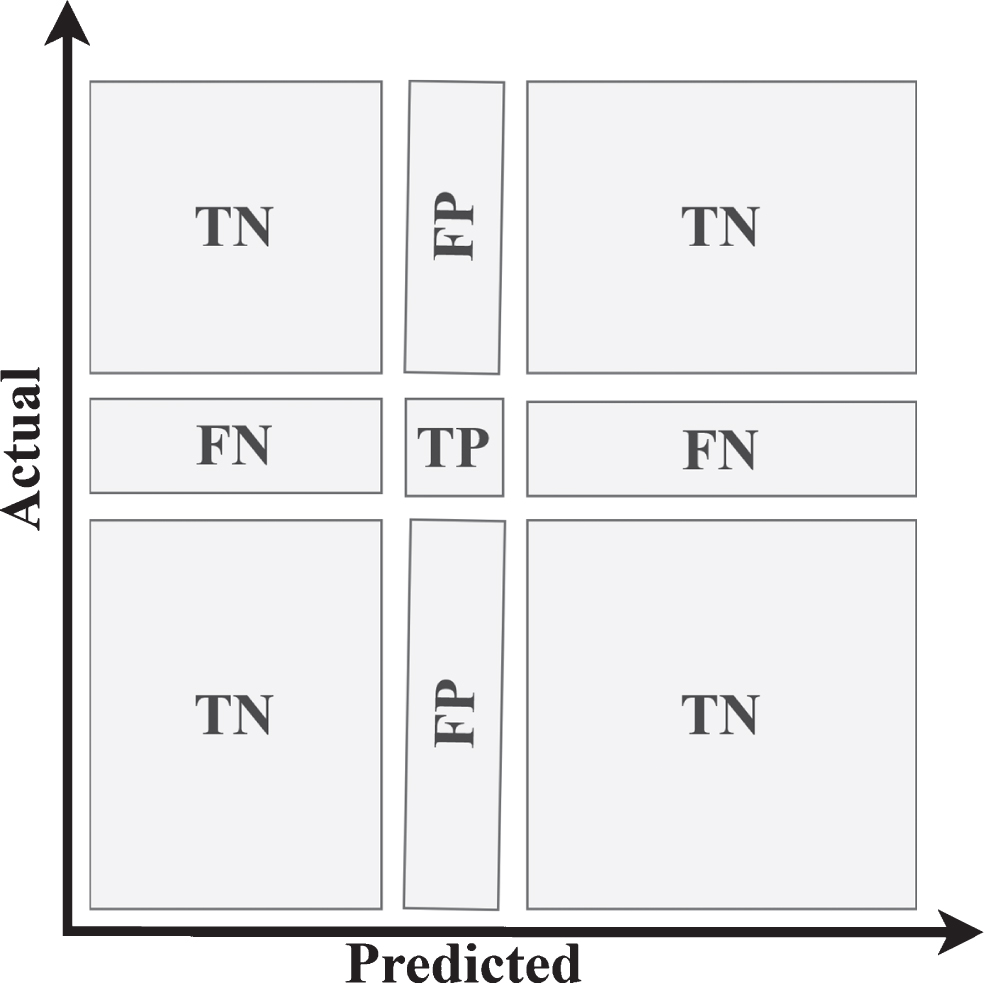
Confusion matrix for multiclass systems.
False Acceptance Rate (FAR) represents the share of the total instances being accepted which otherwise were unauthorized, as described in Equation (11).
False Rejection Rate (FRR) represents the share of the total instances being rejected which otherwise were authorized, as described in Equation (12).
Equal error rate (EER) as given by Equation (13) is the value at which FRR and FAR are equal, i.e. it indicates the proportion of false acceptances being equal to the proportion of false rejections. Lower the EER, more accurate is the model.
The Receiver Operating Characteristics (ROC) investigates the performance of a binary classifier as its discrimination threshold is varied. The area under the Receiver Operating Characteristics curve (AUC-ROC) determines the capability of the model in distinguishing between classes. The AUC-ROC always lies between 0 and 1. Higher the AUC, better the model.
Table 5 shows the phase wise i.e. training, validation and testing accuracies and EER for the two unimodal systems. Table 6 compares the performance of proposed finger-vein unimodal architecture with other training and non-training based methods. Testing for unimodal subsystems was performed as mentioned in Section 5. It can be observed that proposed architecture performs much better than other models. The finger vein CNN along with data augmentation clearly outperforms our previous model [20].
Accuracy and EER in percentage for finger vein and face unimodal systems for training, validation and testing phases
Accuracy and EER in percentage for finger vein and face unimodal systems for training, validation and testing phases
EER comparison of finger vein unimodal classification systems
Table 7 shows EER and accuracy, obtained by applying different score level fusion techniques on the fused results as mentioned in Section 5.3. For different techniques threshold values were decided by plotting the threshold versus accuracy graphs. Threshold values as mentioned in Table 4 were used to obtain recognition accuracy.
Performance of proposed multimodal system for various score level fusion techniques
Performance of proposed multimodal system for various score level fusion techniques
Table 8 shows the recognition performance characteristics comparison of the proposed model with other developed multimodal systems that use the same modalities (finger vein and face). The proposed multimodal system outperforms all the models in considered existing researches. The recorded identification accuracy of the proposed multimodal system was 100% thus clearly outperforming both unimodal subsystems.
Performance comparison of proposed multimodal system with other multimodal systems based on same modalities
The ROC curve obtained for multimodal recognition system using various score level fusion techniques has been illustrated in Fig. 10. The best AUC of ROC was recorded as 0.99 for weighted sum rule. The SoftMax output of unimodal subsystems not only helps us to classify input as imposter or genuine, but also to identify the class of the input sample, hence a single unimodal subsystem is able to perform both functions of recognition and identification as opposed to a binary CNN classifier. This further adds on to the advantage of multimodal system, by reducing interclass dependences.
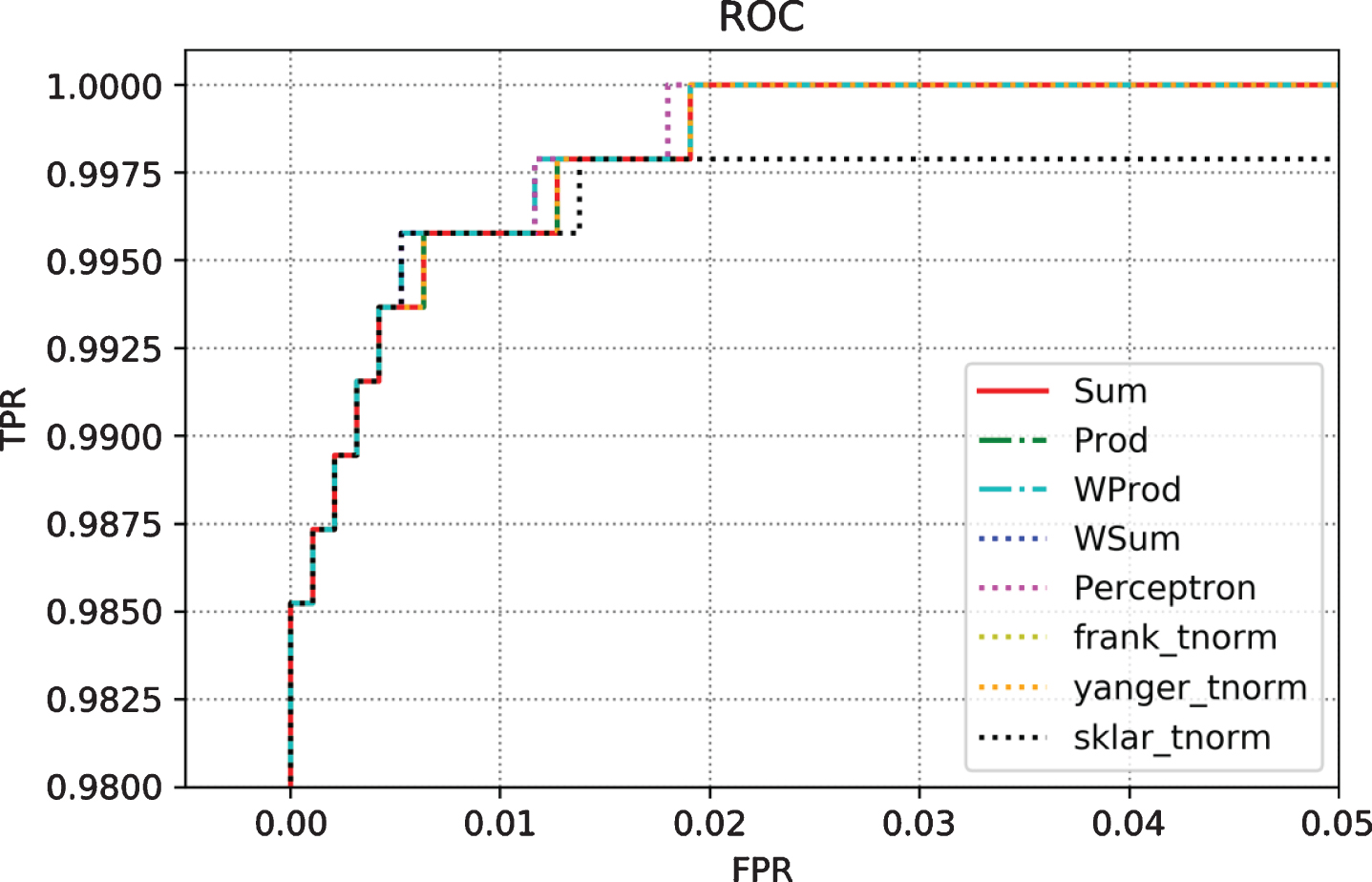
ROC Curve for Multimodal Recognition System using various score level fusion techniques.
Score level fusion for finger vein and face has been investigated. As evident from simulation results, the proposed multimodal biometric system is very efficient in terms of increasing accuracy and decreasing equal error rates. Obtained identification accuracy of 100% clearly indicates the high performance and robustness of the proposed multimodal system against the inherent limitations of individual underlying modalities, as it outperforms each individual unimodal classification system as evident form Tables 6 and 7. Moreover, the recognition EER of 0.27% and accuracy of 99.78% outperforms other state of the art methods. The overall accuracy of the multimodal system proposed is confirmed to be better other training/non-training based methods as evident from Table 8. The weighted sum rule provides the best area under the ROC curve.
The data augmentation technique improves performance and reduces overfitting problem during training ensuring robustness of the unimodal deep CNN making them independent of the sensor quality or the source of data as evident from Table 6. This approach also overcame the problem of interclass dependencies allowing correct recognition result for cross paired input samples. For instance, say two individuals that are present in datasets A and B and we provide face of A and vein image of B for genuine/imposture detection. These cross paired individuals must not be classified as genuine as the two images belong to different individuals.