
Abstract
This article proposes an artificial intelligence-empowered and efficient detection approach for customers with Severe Failure in Digital Transactions (SFDT) through a deep transfer network learning approach from discretized fraud data. Presently, the Real-time global payment system is suffered primarily by fraudsters based on customer behavior. For the identification of fraud, scientists used many techniques. However, identifying and tracking the customers infected by the fraud takes a significant amount of time. The proposed study employs pre-trained convolution neural network-based (CNN) architectures to find SFDT. CNN is pre-trained on the various network architectures using fraud data. This article contributed to pre-trained networks with newly developed versions ResNet152, DenseNet201, InceptionNetV4, and EfficientNetB7 by integrating the loss function to minimize the error. We run numerous experiments on large data set of credit payment transactions which are public in nature, to determine the high rate of SFDT with our model by comparing accuracy with other fraud detection methods and also proved best in evaluating minimum loss cost.
Introduction
Fraud detection holds significant relevance in today’s digital payment landscape. Enhancing the performance and maintaining the stability of fraud detection models pose considerable challenges due to the dynamic nature of user payment behaviors and the ever-evolving tactics employed by fraudsters. Therefore, To diminish the losses incurred by platforms and users, numerous researchers have undertaken studies and put forth a plenty of classification models. Their aim is to provide effective solutions for identifying and categorizing fraudulent activities. Digital transaction fraud can be described as a binary classification problem that classifies the fraud and non-fraud behavioural transactions by customers, thereby helping the economy and financial institutions make appropriate decisions and early detection to avoid these huge losses. Therefore, a reliable detection system is essential for banking and other financial establishments to monitor transactions online. Fraud detection systems share a common objective: to extract potentially fraudulent transaction patterns from extensive transaction logs, enabling the identification and monitoring of incoming transactions. Machine Learning (MachL) has proven to be highly effective in this endeavor, as it excels at uncovering these patterns, essentially performing a supervised binary classification task.
In today’s world, classification [1] plays a significant role. It can be done by two most tremendous learning techniques called machine learning and deep learning. In this predictive modelling problem, a target label is predicted for a specified example of the input data. So, the categorization process is performed on a given set of transactional data that determines whether an activity is fraudulent or non-fraudulent. Machine and Deep learning (DeepL) have shown great success in various real-world applications. CNNs, which outperform other machine learning techniques by a considerable margin, have found extensive use in a variety of practical fields, including image processing, engineering, healthcare, and cognitive research. Especially, the success of CNNs can largely be attributed to advancements in fundamental CNN architectures. These improvements involve increasing network depth, utilizing skip connections, incorporating inner network structures, and more. However, the development of state-of-the-art CNN architectures with exceptional performance often relies on manual design by experienced experts, involving trial and error. Given the challenges of designing efficient CNN architectures, researchers have sought to automate this process. They have developed algorithms that aim to design CNN architectures automatically [2], thereby enhancing the applicability and universality of CNNs. This article emphasizes the acquisition of deep feature representations for both legitimate and fraudulent transactions, with a specific focus on the loss function of a deep learning-based neural network. The objective here is to get better separability of classes and improve the performance of our fraud detection model and keep its stableness. We utilized new versions of pre-trained models as shown in Fig. 3. To showcase the enhanced feature learning capabilities of our model, we present experimental results that compare it with other detection methods using a fraud dataset.
Framework of proposed model.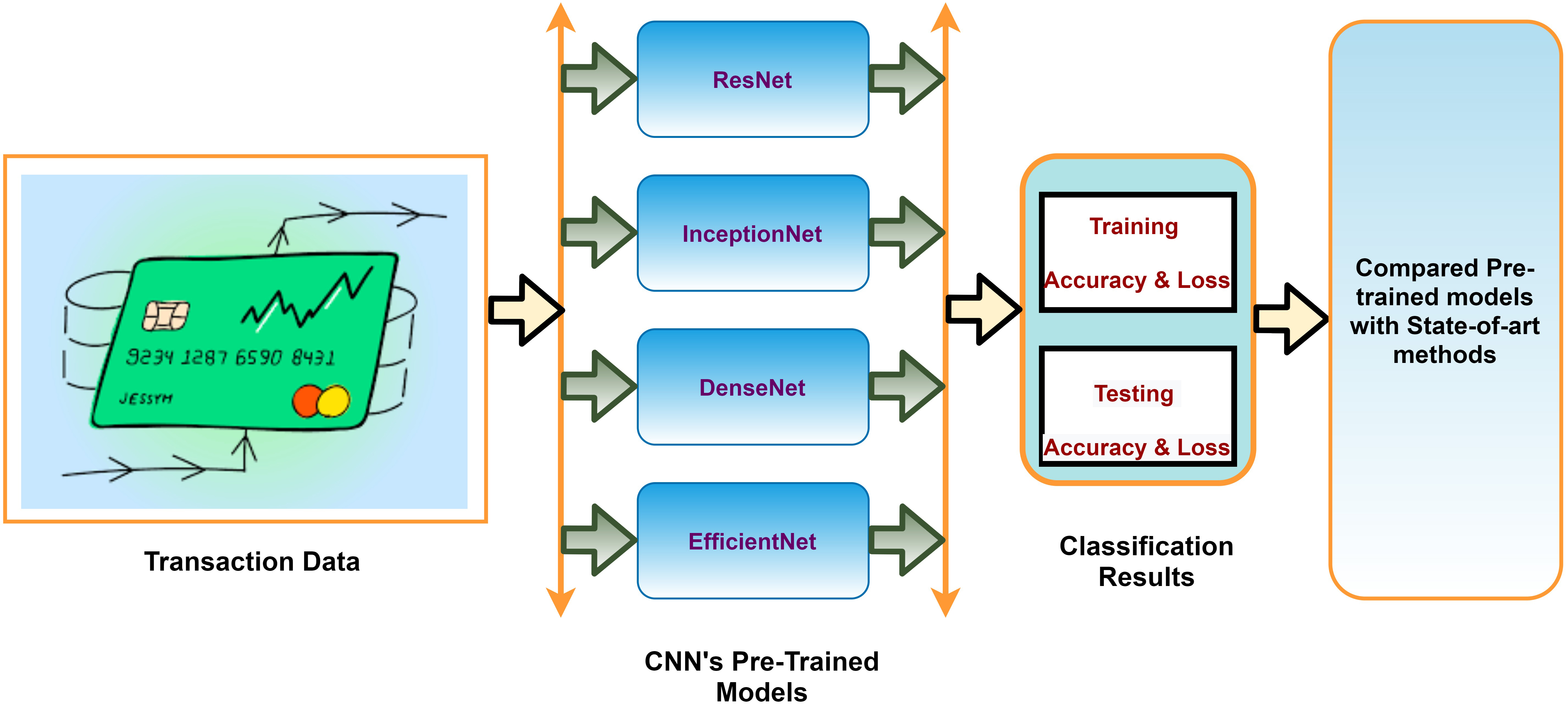
Here is a summary of our contributions:
Latest versions of pre-trained models are proposed. As far as we are aware, no prior investigation has been carried out on the application of network-based DTL using CNNs to identify the SFDT. We provide a summary of the state-of-the-art methods employed in deep representation learning and conduct a comparative analysis on large-scale fraud test datasets. Additionally, we showcase the superior performance stability of the proposed model.
The remainder of this work is structured as follows: In Section 2, we provide a review of the related work. Section 3 describes the deep pre-trained models, activation function and loss function utilized. Subsequently, in Section 4, we present the details of our experimental setup. Finally, Section 5 concludes the article, highlighting key findings and suggesting areas for future research.
To the best of our knowledge, no prior work has been conducted on the application of network kind Deep Transfer Learning (DTL) using CNNs to the task of digital fraud detection but applied on various applications to know the learning ability of model. In general these DTL are divided into four categories: instances-based DTL, mapping-based DTL, network-based DTL, and adversarial-based DTL. All other categories have been thoroughly investigated for various ML techniques known as domain adaptation or transfer learning over the past couple of decades, with the exception of the adversarial-based and network-based approaches. However, the majority of those strategies are still useful to DTL as well. Network-based (parameter-based) approaches are widely employed in DTL due to their ability to address domain adaptation challenges between source and target data by adjusting the network (model). DTL primarily emphasizes network-based approaches. Notably, network-based approaches within deep learning models can effectively handle the adaptation between input and target data, even when they are significantly dissimilar.
Author E.Chaves [3] applied transfer learning VGG-16, ResNet-18, AlexNet, VGG-19 and GoogLeNet on breast cancer detection by taking input as infrared images which do not emit harmful radiation. ResNet-18 is best suited this application which achieves more in performance of classification as normal or pathology. A Zhang [4] differentiated their credit score dataset into static and dynamic behavioural data. The author combined ResNet (for static behavioral data) and LSTM (dynamic behavioral data) as a hybrid which is added to the attention system to improve the model efficiency. An introduction of the focal loss function is presented here to enhance the performance of classifier XGBoost and the evaluated efficiency of their method has been significantly improved on F1 value, Area Under Curve (AUC), Kolmogorov-Smirnov (KS) value for better discrimination between positive and negative samples. Author I Kandel and M Castelli [5] discussed transfer learning deeply. Each and every layer in the convolution neural network are explained here and applied to all pre-trained models of CNN on diabetic retinopathy which is a dangerous disease to the eye of diabetes patients. In a study conducted by M. A. Morid [6], transfer learning with convolutional neural networks (CNNs) was employed. The study utilized pre-trained CNNs that were originally trained on non-medical ImageNet datasets. This approach has demonstrated promising results in the area of medical image analysis in advancement. A scoping review was conducted by the authors to find relevant studies and aggregate their characteristics in the problem domain. The scope was to provide an overview of existing research in the field and capture the key aspects of these studies. B. E. Garcia [7] introduced a novel vision-based classification system for the identification of weeds in crop fields. The study utilized pre-trained deep neural networks and specifically focused on real datasets pertaining to tomatoes and cotton. Extensive evaluations were conducted using authentic data, resulting in the identification of the best crop/weed identifier. Impressively, this identifier achieved a promising performance of 99.29% F1 score while exhibiting minimal overfitting tendencies. S. Agduk [8] conducted a study to determine the author and gender of handwritten text from sample images. The study utilized a dataset comprising 3250 handwritten sample images from 65 distinct individuals. To extract features from the handwritten images, 32 transfer learning methods were employed, followed by a classification process utilizing 28 different algorithms implemented in Python. The study yielded a classification success rate of 92.46% for author identification and 92.77% for gender classification, demonstrating promising results. The research conducted by [9] provides a comprehensive overview of deep learning (DeepL) applications in various operational domains, with a specific emphasis on plant weed detection. The motivation behind this study stems from the necessity to address a related type of weed with a designated herbicide. To accomplish this, a CNN ResNet50 model was employed. Subsequently, the model’s attainment was assessed by a classifier Random Forest (RF). The resulting skilled model was then deployed on a single board device called Raspberry Pi to predict test data. The CNN classifier achieved an impressive training accuracy of 99%, while the RF classifier achieved 93%. Aggregation of Ensemble (AOE), a technique that the author K Singh et al. [10] presented, is a means to take advantage of pre-trained CNN’s existing capabilities and extract high-level features that can be utilised to train a pool of classifiers. The researchers introduced an innovative approach for detecting crowd anomalies that exhibits high efficiency in distinguishing between normal and abnormal events. This method proves particularly valuable for enhancing surveillance systems in densely populated areas. The ensemble of fine-tuned ConvNets like VGG, GoogleNet, and AlexNet cooperates for detecting anomalies. The ensemble of fine-tuned CNN’s cooperates in detecting anomalies on UCSD Ped1, UCSD Ped2 and Avenue data set and achieved 93.2%, 92.1%, 92.7% respectively. Many other researchers used pre-trained models of deep CNN in multiple applications [11, 12, 13, 14, 15].
Deep transfer pre-trained networks
Transfer learning refers to the practice of utilizing a pre-existing model on a different problem domain. It has gained significant traction, especially in the realm of deep learning, as it enables training of deep neural networks with limited data. This aspect holds great significance in the field of data science, where the majority of real-world scenarios do not necessitate an extensive collection of labeled data points to effectively train complex models. Some of the pre-trained models are used for this work namely, ResNet152, InceptionNetV4, DenseNet201, and EfficientNetB7. These models were trained with the dataset which is generated by the tool Sparkov. This dataset is a completely imbalanced one. Hence, initially applied data preprocessing stage to this framework to check missing values and to balance the dataset. The Adaptive Synthetic Minority Oversampling Technique (ADASYN) is one of the best algorithms to generate synthetic data. After applied this, our dataset gave and generated a good number of synthetic samples irrespective of minority samples that are necessary for improving the classification process.
ResNet152
The Microsoft research team developed ResNet152 [16] as a solution to alleviate the training challenges associated with deeper neural networks. ResNets operate on the principle of learning additive residual functions through identity mapping, employing short connections [17]. ResNet comes in versions with different numbers of weight layers, including 18, 34, 50, 101, and 152 [18]. In ResNet architectures, instead of learning non-discriminatory functions, residual functions are adopted using input layers. Unlike the VGG architecture, ResNet utilizes shortcut connections in feed-forward neural networks. These shortcut links do not introduce additional parameters or computational complexity. Instead, they facilitate the transfer of relevant information from previous layers to subsequent ones [17]. In contrast to VGG architectures, ResNet architectures include a global average pooling layer and a fully connected layer at the network’s end. This design does not involve a dropout operation, as the average value in each property map is directly transferred to the next layer during the global average pooling process.
DenseNet201
DenseNet201 [19] DenseNet is a unique network architecture in which every layer is straightly linked to every other layer in a feed-forward manner, forming dense blocks Within each dense block, the feature maps of all previous layers are considered as distinct inputs, while the layer’s own feature maps are transmitted as inputs to all successive layers. This connectivity pattern has demonstrated remarkable accuracy levels on datasets such as CIFAR10/100 and SVHN, regardless of data augmentation techniques. When applied to the large-scale ILSVRC 2012 (ImageNet) dataset, DenseNet achieves a comparable accuracy to ResNet while utilizing fewer than half the parameters and approximately half the number of floating-point operations (FLOPs). Within DenseNet, the characteristic feature is that each layer acquires supplementary inputs from all forerunning layers while transmitting its own feature maps to all successive layers. This is accomplished through the utilization of concatenation. Consequently, every layer benefits from a comprehensive “collective knowledge” derived from its previous layers. As each layer receives feature maps from all prior layers, it enables the network to become more compact and streamlined, resulting in a reduced number of channels. The growth rate, denoted as ‘k,’ represents the additional number of channels allocated to each layer. Consequently, DenseNet exhibits heightened computational efficiency and memory efficiency. The accompanying figure illustrates the concept of concatenation during the forward propagation process.
InceptionNetV4
In the latest iteration of the Inception model, referred to as Inception-v4 [20], significant modifications have been made to the initial set of operations preceding the inception layer. A notable addition in this version is the incorporation of Specialized Reduction blocks, which facilitate adjustments to the grid’s height and width. Unlike previous versions, this functionality is explicitly introduced in Inception-v4, offering enhanced flexibility in grid manipulation.
EfficientNetb7
A type of convolutional neural network called EfficientNetB7 [21] has a higher parameter efficiency than preceding models and trains more quickly. During its initial development, it extensively employs both MBConv (Mobile Inverted Bottleneck Layer) and the newly introduced fused-MBConv. Regarding the situation of MBConv, a smaller expansion ratio is favored due to its lower memory access overhead. Additionally, MBConv tends to favor smaller 3
Activation function
In the context of image multi-classification tasks, the input image undergoes various operations such as convolution and pooling to generate an N-dimensional array. Here, N is the number of image categories, and each dimension of the array signifies the likelihood of the image belonging to a specific category. This N-dimensional array is then passed to the output layer, where the activation function employed is Softmax. The Softmax function [22] transforms the array into a one-dimensional probability distribution, where each value represents the probability of the prediction belonging to a particular class. Assume that the representation of the neural network output is
While training the network, the network parameters are updated using backpropagation. The softmax function generates a one-dimensional probability distribution, which is subsequently utilized as an input for the loss function. The loss function output is then backpropagated to update the network parameters. The cross-entropy loss function is used in this article. In Eq. (2), the loss function LS is calculated as follows.
where Let
The optimizer in use employs the RMSProp (Root Mean Squared Propagation) optimization method [23], which was originally proposed by Hinton. The parameter update is represented by Eq. (3), where
It is a simulated credit card transaction dataset that is generated by Brandon Harris using the Sparkov Data Generation tool. It contains legitimate and fraud transactions from the duration 1st Jan 2019–31st Dec 2020. It covers the credit cards of 1000 customers doing transactions with a pool of 800 merchants. This dataset presents transactions with 24 features, where we have 9651 frauds out of 18,52,394 transactions. The dataset is highly imbalanced, the positive class (frauds) accounts for 0.52% of all transactions whereas the remaining are 18,42,743 (99.478%). After performing the data cleaning process, not found any missing values in the dataset. But we need to change the structure of the dataset according to the requirements of implementation. For example, we divided our dataset into three parts: training, testing, and validation, with a distribution of 70% for training, 20% for testing, and 10% for validation.
Results & discussions
Transfer Learning was performed on a system with an Intel core i5 processor and 8 GB of RAM, using the python platform jupiter notebook for classification. It was done on benchmark dataset transaction samples which are depicted in Section 4. The preprocessed data is fed to the pre-trained models. These models have built-in structures and are efficient in classification and prediction. The deep transfer approaches are applied to many publicly available datasets to determine the performance of the study. All these transfer models performances depend on the activation function, loss function, and also an optimizer. These techniques outperforms when compared with other state-of-the-art models. For comparisons, well-known machine learning models and conventional deep learning models are utilized. The Pre-trained approaches ResNet152 and EfficientNetB7 yield better results in identifying the SFDT.
Figures 2 to 3 are evaluations of pre-trained models respectively of training and validation stages. We evaluated all these models with tuning parameters accuracy and loss which are specified in X-axis and Y-axis respectively. We run these models for up to 8 epochs. Both the accuracy and loss results are taken into the same graph. While doing experiments, results observed that the performance of all pre-trained models mentioned was almost the same in the training phase. While coming to the validation part, the EfficientNetB7 and ResNet152 are good in the accuracies of 99.96%, and 99.92% and caught up with very few losses of 0.001 and 0.003 respectively.
Accuracy and losses of pre-trained models
Accuracy and losses of pre-trained models
Performances of different transfer learning models on simulated credit card transaction dataset.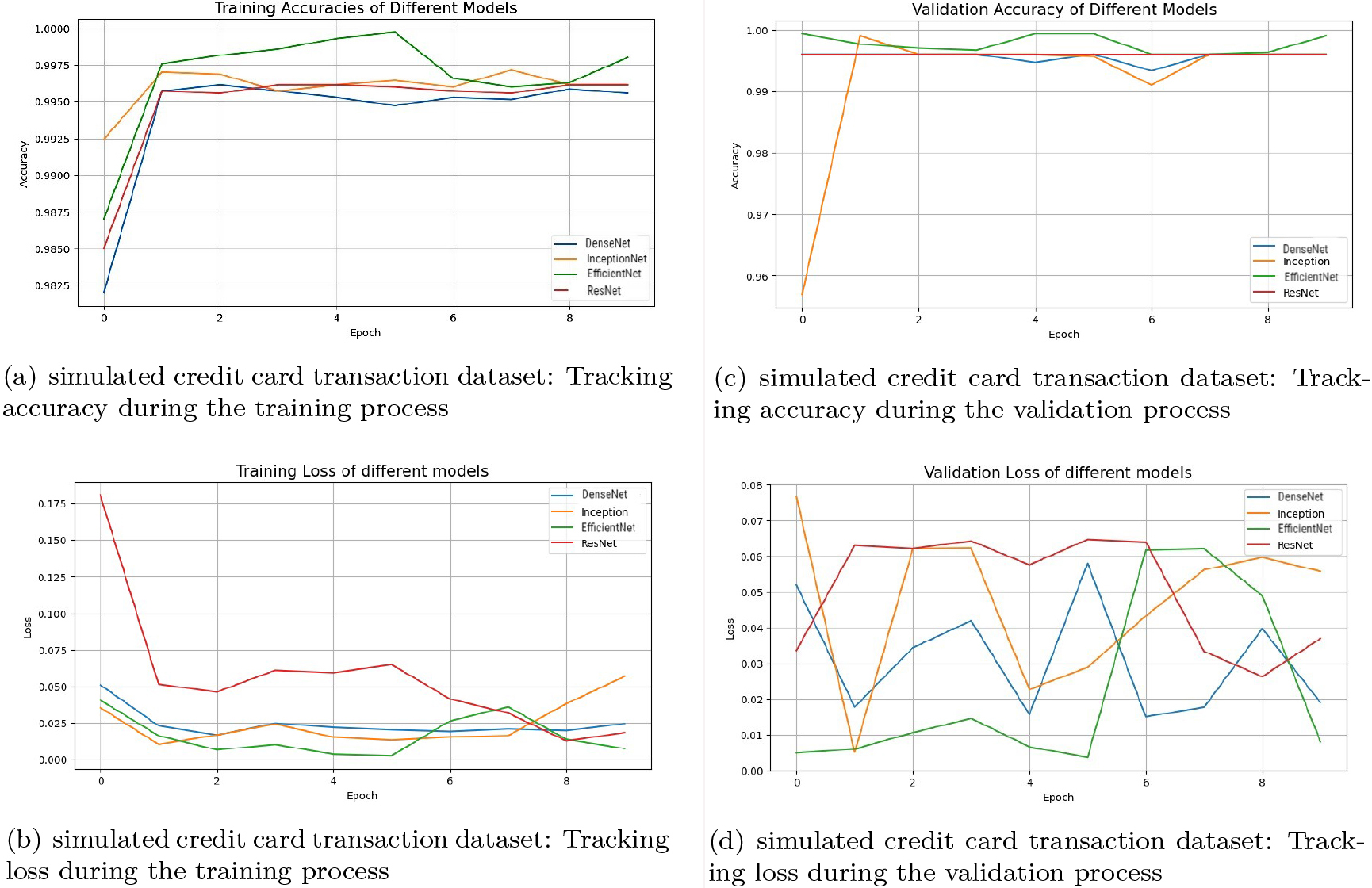
The mentioned data in Table 2 are the accuracy & losses of specified pre-trained models in the training and validation stages. The ResNet152 yields an accuracy 0.997 with a loss 0.01 in training phase. All most of all pre-trained models are performing equally in identifying fraud transactions. Because, here used all the latest versions of the pre-trained models called ResNet152, DenseNet201, InceptionNetV4, and EfficientNetB7. In the training phase, EfficientNetB7 achieved greater in their accuracy (99.97%) and fewer in loss (0.001) followed by InceptionV4, ResNet152 and DenseNet201 of 99.87%,99.70% and 99% respectively. In the validation phase, EfficientNetB7 achieved greater in their accuracy (99.97%) and with 0 loss followed by ResNet152, DenseNet201, and InceptionV4, of 99.90%,99.90% and 99.80% respectively. Hence, proved that almost all the specified latest versions of pre-trained models are having similar performance on fraud data.
Accuracy and losses of pre-trained models
Performances of different transfer learning models on UCI dataset.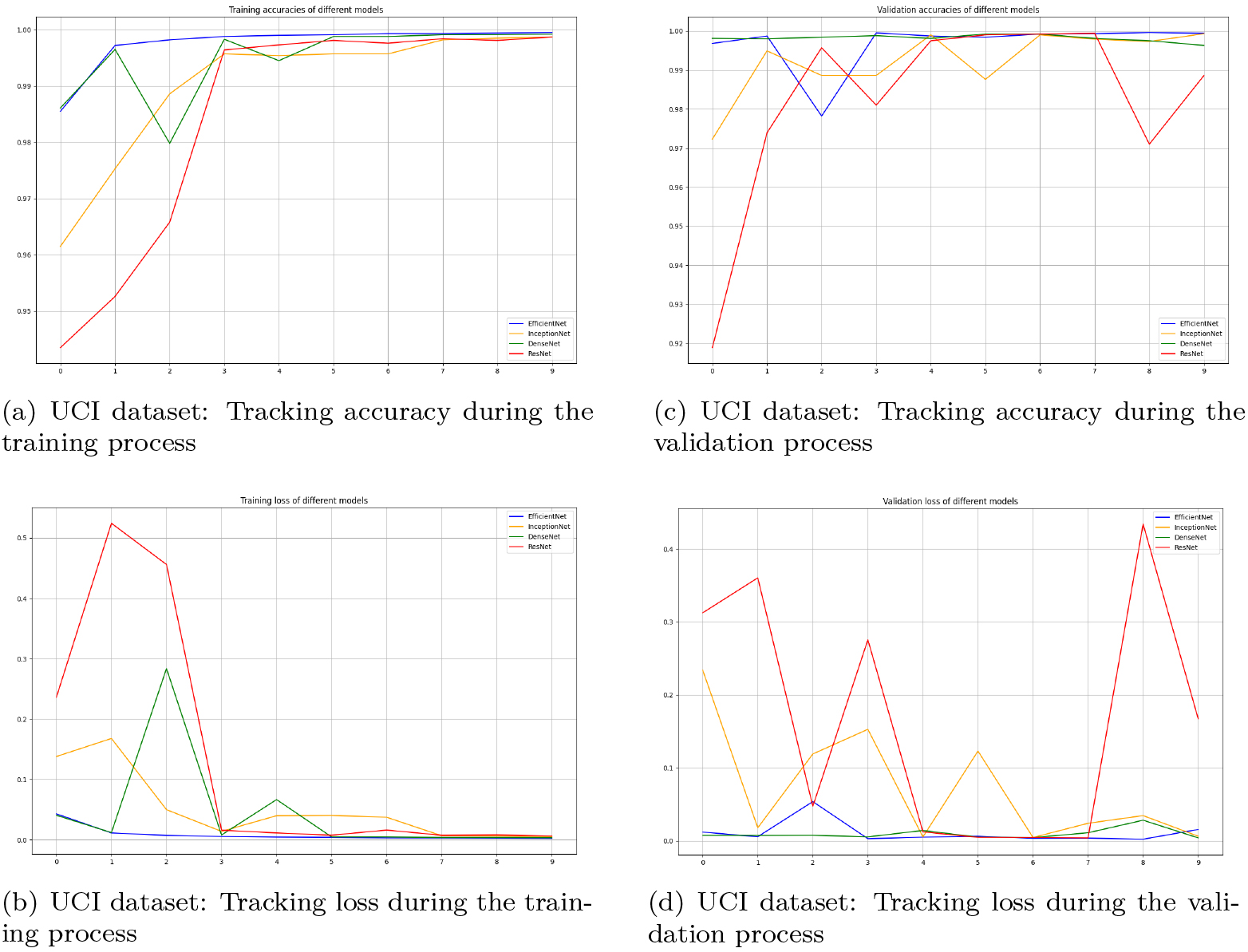
Table 2 presents a comparison between the proposed pre-trained models and recent MachL and DeepL techniques in terms of accuracy. The HOBA+Deep Belief Network (DBN) model achieved the highest accuracy of 98.25%, followed by LSTM with 97.48%. Notably, MachL approaches such as Coarse KNN, Cluster, and SBS demonstrated commendable performance, achieving accuracies of 99.87%, 96.6%, and 96.29% respectively, while the PCA+KNN methodology reached an accuracy of 96.6%. The results obtained from our proposed pre-trained network models surpassed those of state-of-the-art methods, showcasing their effectiveness.
Comparing performance of Pre-Trained models with state of art methods
The major constraint of digital fraud detection is binary classification where identifies fraudulent and non-fraudulent transactions. Many algorithms use classic MachL and DeepL models to classify all the observations as fraud and non-fraudulent ones. In this research work applied DTL algorithms called pre-trained models on fraud datasets. All these pre-trained models are the latest versions in their structure and which is utilized as a skeleton for any problem. This results in higher overall accuracy yet lower loss with respect to model interest. Results confirmed that the EfficientNetB7 would be more efficient in classifying fraud and non-fraud data with more accuracy and less loss followed by ResNet152, DenseNet201, and InceptionV4. Then, the performance of the DTL models is proved better for the classification of efficient fraud & non-fraudulent transactions and also compared with some of the state-of-the-art deep learning models.
Furthermore, DTL can be applied to any kind of application which requires support for classification and prediction. Meanwhile, in the future, other latest versions of pre-trained models are also considered for efficient performance.
Footnotes
Conflict of interest
The authors declare that no conflict of interest.