
Abstract
Collaborative filtering (CF), a representative algorithm of recommendation systems, is a method of using information of the neighbors of active user. The main idea of CF is that users who agreed in the ratings of certain items are likely to agree again in new items. The degree to which the two users’ tendencies in the ratings of the co-rated items are consistent is measured using a similarity measure. Therefore, the similarity measure in CF plays a key role in the extraction of the representative neighbors. Studies on the improvement of similarity indicators for selecting representative neighbors are still ongoing. Recently, a new similarity measure, named OS, was proposed to enhance the recommendation performance by utilizing mathematical equations, such as the integral equation, system of linear differential equations, and non-linear systems. This study aims to understand the limitations of OS and overcome these limitations using the proposed method. In the proposed method, a sigmoid function was used to reflect preferences, such as the positive or negative sentiment of user ratings. In addition, to consider the absolute score difference, some of the formulas were modified, and finally, the performance improvement of the recommendation system was proved through experiments.

Introduction
The importance of recommendation systems in e-commerce and content platform companies overflowing numerous products, news, and information is increasing [1]. Many companies have introduced a recommendation system that efficiently provides a list of recommended products or contents to their customers among a wide range of products or contents to increase user satisfaction and the purchase or service subscription rate [2].
Most recommendation systems analyze historical users’ purchase or rating data to generate a list of recommended items that a user has a high probability of purchasing, or is expected to give a high rating score among items that the user has not yet purchased or evaluated [3]. Collaborative filtering and content-based filtering are very popular for building recommendation systems.
Collaborative filtering recommends items based on the interests of similar users of a specific user or items based on the similarity between items using user ratings [4]. In general, collaborative filtering utilizes data that contain a set of items and a set of users who have evaluated some of the times, and it shows good recommendation performance without complicated calculations. In contrast, content-based filtering uses item features to recommend items similar to what the user likes based on user ratings [5]. Since it uses the characteristics of items for recommendation, it is possible to recommend a new item to a user, which is impossible in collaborative filtering.
Collaborative filtering includes memory-based,model-based, and hybrid memory- and model-based approaches. Among them, memory-based methods utilize the similarity between users or items based on user ratings for recommendations. The performance of recommendation by the memory-based methods is highly affected by a similarity measure.
To measure the similarity between users or items in memory-based collaborative filtering algorithms, traditional similarity measures such as cosine (COS), Pearson correlation coefficient (PCC), mean squared difference (MSD), and Jaccard (JAC) measures have been widely used. However, they have certain limitations. COS and PCC may fail to obtain reliable similarity values between two users when the number of common items evaluated by the two users is small and they mainly focus on the directions of the rating vectors but ignore their lengths. MSD ignores the number of co-rated items and JAC ignores the rating values in the similarity calculation. Hence, many studies have proposed new similarity measures for collaborative filtering to improve traditional ones.
Recently, [6] proposed a new similarity measure, named OS, by transforming some intuitive and qualitative conditions that should be satisfied by the similarity measure into relevant mathematical equations, such as the integral equation, system of linear differential equations, and non-linear systems. OS consists of two parts: (1) percentage of non-common ratings (PNCR) which takes into account the number of co-rated items, and (2) absolute difference of ratings (ADF) which uses elementary similarity expression for all items rated by two users. PNCR uses an exponential function to reduce the range of similarity values that change sensitively according to the number of common evaluation items, which is one of the limitations of JAC. In addition, ADF also uses an exponential function and calculates the relative difference according to the rating value instead of the absolute difference in ratings between two users, unlike MSD. As a result, OS showed better performance than the other similarity measures.
Although OS addresses the limitations of traditional similarity measures, it also has some limitations. First, the ADF value when both ratings are small is larger than that when both ratings are high because the relative difference of the two ratings in ADF is obtained by dividing the absolute difference between the two ratings by the larger value of the two ratings. Second, OS does not consider whether the sentiments of the two ratings (positive or negative) coincide. Even if the absolute difference of ratings is the same, it might be better to have a larger difference when the sentiments of the two ratings do not match than when they match.
In this study, we propose a new similarity measure to overcome the limitations of OS. The proposed similarity measure reflects whether the sentiments of the two ratings coincide to calculate the relative difference between them. The idea behind this approach is that it should be considered as having a larger difference if the sentiment of the ratings by two users is different than if the sentiment is the same, even if the difference between the ratings is the same. To reflect this idea in the new similarity measure, a function using a sigmoid function to transform the ratings of items was proposed in this study. In addition, instead of the maximum value of the ratings of two users for the same item, the user-defined constant is used in ADF to address the issue that ADF does not treat the difference between low ratings and the difference between high ratings equally.
In subsequent sections, first, a literature review that includes some limitations of traditional and advanced similarity measures to enhance the performance of recommendations is presented. Second, the proposed similarity measure to address the limitations of OS and improve the recommendation performance is proposed with a brief explanation of OS. Third, the experimental procedure is illustrated and then the results are presented. Finally, this paper concludes with a discussion of the study’s limitations and future research directions.
Related work
In memory-based collaborative filtering, the set of recommended items for a specific user is determined based on the similarity between the users or items. User-based collaborative filtering (UBCF) identifies users that are similar to the queried user based on the similarity between users, whereas item-based collaborative filtering is based on the similarity between items calculated using people’s ratings of those items. In UBCF, the
where
Several traditional similarity measures have been used to calculate
where
PCC estimates the similarity between users as the ratio of the cross product of overrating or underrating of means divided by the product of the sum of squares of the mean rating difference as follows [8]:
Unlike COS, the range of cosine similarity is
JAC mainly focuses on the number of co-rated items of two users and is defined as follows [6]:
where
MSD is calculated by the ratio of the sum of squares of the difference of ratings on co-rated items to the cardinality of co-rated items as follows [9]:
Unlike JAC, MSD does not consider the number of co-rated items.
Several studies have been steadily conducted to overcome the limitations of the traditional similarity measures.
[10] proposed the new similarity measures that combine the balance factor with the traditional similarity measures such as the adjusted cosine (ACOS) [11] and PCC measures. The balance factor takes the differences in users’ rating scales into account in the user similarity calculation to compensate for the shortcoming of the traditional similarity calculation method, which is defined as follows:
where
[12] proposed the modified version of PCC by replacing the average rating with an absolute reference as follows:
where
[13] proposed sigmoid function-based Pearson correlation coefficient (SPCC) to enhance the performance for sparse data by applying an weight calculated from the number of co-rated items as follows:
When the number of co-rated items between two users is small, the similarity value decreases as the weight factor has a small value.
[14] developed the modified version of JAC, named relevant Jaccard (RJAC) to solve the problem of the traditional similarity measures that they sometimes select users who does not evaluate the target item as k-nearest neighbors and RJAC is defined as follows:
where
In addition, several studies have combined several similarity measures to compensate for the limitations of similarity measures. [15] proposed a method that combined JAC and MSD (JMSD), in which JAC is used to capture the proportion of the co-rated items and MSD is used to obtain the information of ratings. JMSD is defined as follows:
[16] proposed a new similarity measure of triangle multiplying Jaccard (TMJ) which combines triangle similarity (TRI) and JAC to improve recommendation accuracy where the triangle similarity considers both the length and the angle of rating vectors between them, defined as follows:
Because
[17] proposed a new similarity measure, named Cosine-Jaccard-Mean of Divergence (CjacMD), which combines COS, JAC, mean measure of divergence (MMD). In CjacMD, MMD is the most common and popular distance measure used for the computation of bio-distances based on non-metric traits, which is defined as follows:
where
In other words, CjacMD is defined as the sum of the three similarity values: COS, JAC, and MMD. In addition, COS, JAC, and MMD contribute equally to CjacMD, because they have values between 0 and 1.
[18] proposed a new similarity measure inspired by a physical resonance phenomenon, named resonance similarity (RES). RES consists of three different factors: consistency, distance, and Jarccard factors as follows:
where
[19] suggested an improved similarity measure, which takes three impact factors of similarity into account to minimize the deviation of similarity calculation. Moreover, a new similarity measure that employs the information entropy of user ratings so that the user’s global rating behavior on items can be reflected was proposed in [20]. The entropy-weighted similarity measure (EW) provided in [20] introduces the weighting factor using entropy into traditional similarity measures, such as COS and COR. For example, entropy-weighted COS (COS
where
where the probability that the rating of item
Before explaining the proposed similarity measure, OS, which is the basis of the proposed similarity measure, is explained in detail. As explained in Section 1, OS is the multiplication of PNCR and ADF defined as follows [6]:
where
In addition, ADF divides the absolute difference by the maximum value of two ratings. Hence, the ADF value when
To overcome this limitation of OS, this study suggests considering the sentiments of ratings rather than using their maximum value when calculating the relative difference in the ratings used in ADF. The underlying assumption of this suggestion is that the relative difference when one rating is positive and the other is negative is greater than the relative difference when both ratings are positive or negative if the absolute difference is the same.
To reflect this assumption in the relative difference, the original rating is first transformed as follows:
where
Sigmoid transformation of ratings.
Using the converted ratings, the modified version of ADF (MADF) is defined as follows:
where
In our experimental study, four datasets were utilized: MovieLens100K, MovieLens1M, Yahoo-Music and FilmTrust. MovieLens100K and MovieLens1M were obtained from GroupLens Research website1 and Yahoo-Music data was obtained from Yahoo Research by request.2 FilmTrust data are open to anyone through the Harvard Dataverse.3 The properties of the four datasets in terms of number of users, number of items, and density are summarized in Table 1.
For each experiment, 5-fold cross-validation for the evaluation was applied for comparison, which implies that 80% of the data were used for training and the rest were used for testing for each fold and this was repeated five times for each dataset. Each user had at least 20 ratings for all datasets; therefore, all users could be included in the training and test sets. In the training process, the similarity values between users were calculated to determine the
In this study, SIGOS was compared with OS and other traditional or recently developed similarity measures such as COS, PCC, TMJ, and RJAC. For SIGOS,
Properties of datasets for experiments
Properties of datasets for experiments
Experimental procedure.
For the evaluation of the predicted ratings and recommendation performance, mean absolute error (MAE) and F1 were used. MAE is a representative metric for evaluating the prediction accuracy and measures the average difference between the predicted ratings and their corresponding actual ratings by users. MAE is defined as follows:
In addition, F1, which is the harmonic mean of precision and recall, measures the performance of the recommendations. In this study, the set of items that are actually relevant to the user (
In other words, items with higher predicted ratings than the average rating of the training set were finally determined as the recommended items. Then, precision and recall are defined as follows:
Using precision and recall, F1 is defined as follows:
After predicting the ratings of items in each validation set, MAE and F1 were computed using the predicted ratings. Then, the average values of MAE and F1 for the five validation sets were calculated and these average values were used to compare the performance of SIGOS with that of other similarity measures.
Evaluation results using different
Evaluation results using different
Evaluation results using different
Evaluation results using different
Comparison results by MAE.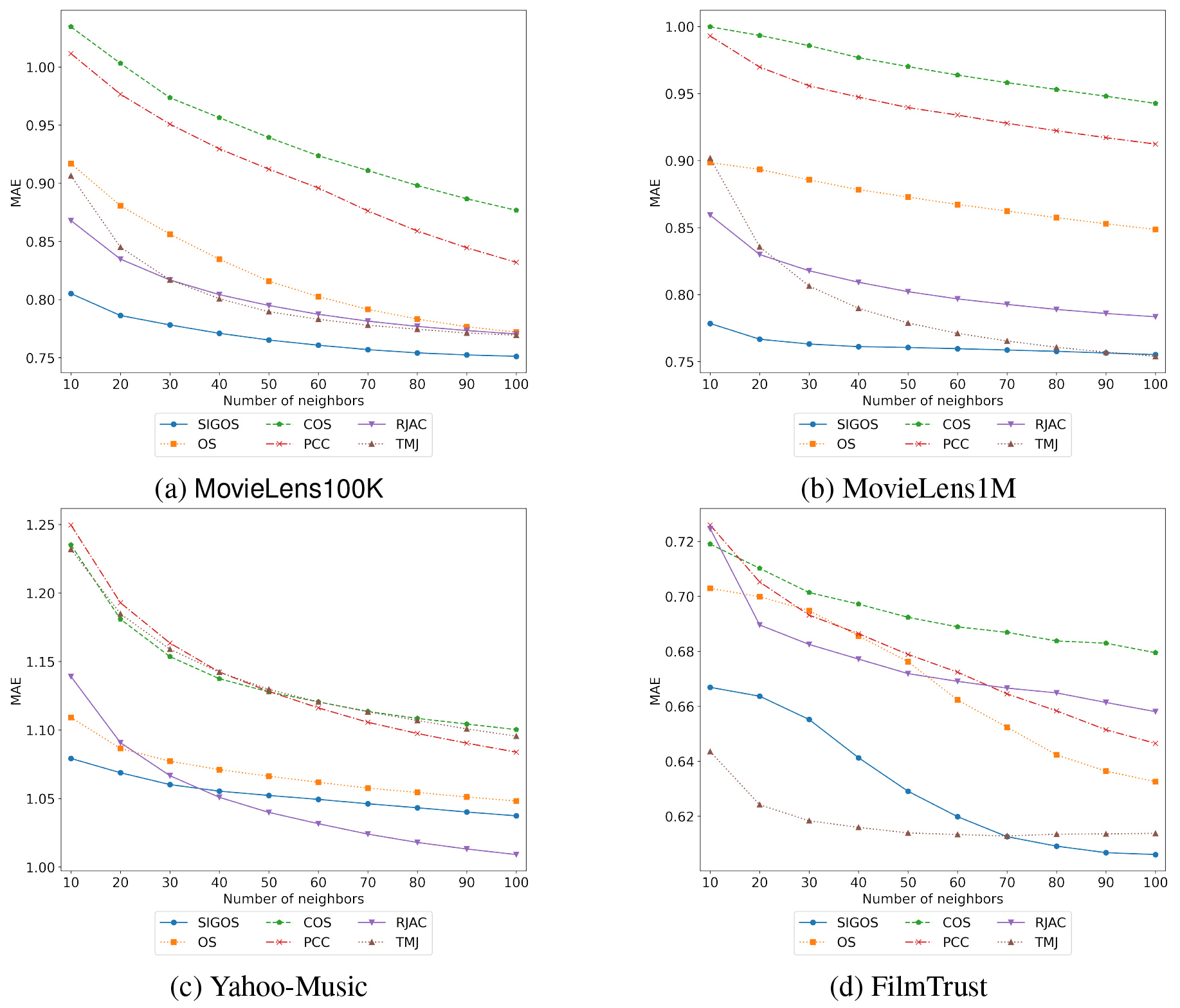
Comparison results by F1.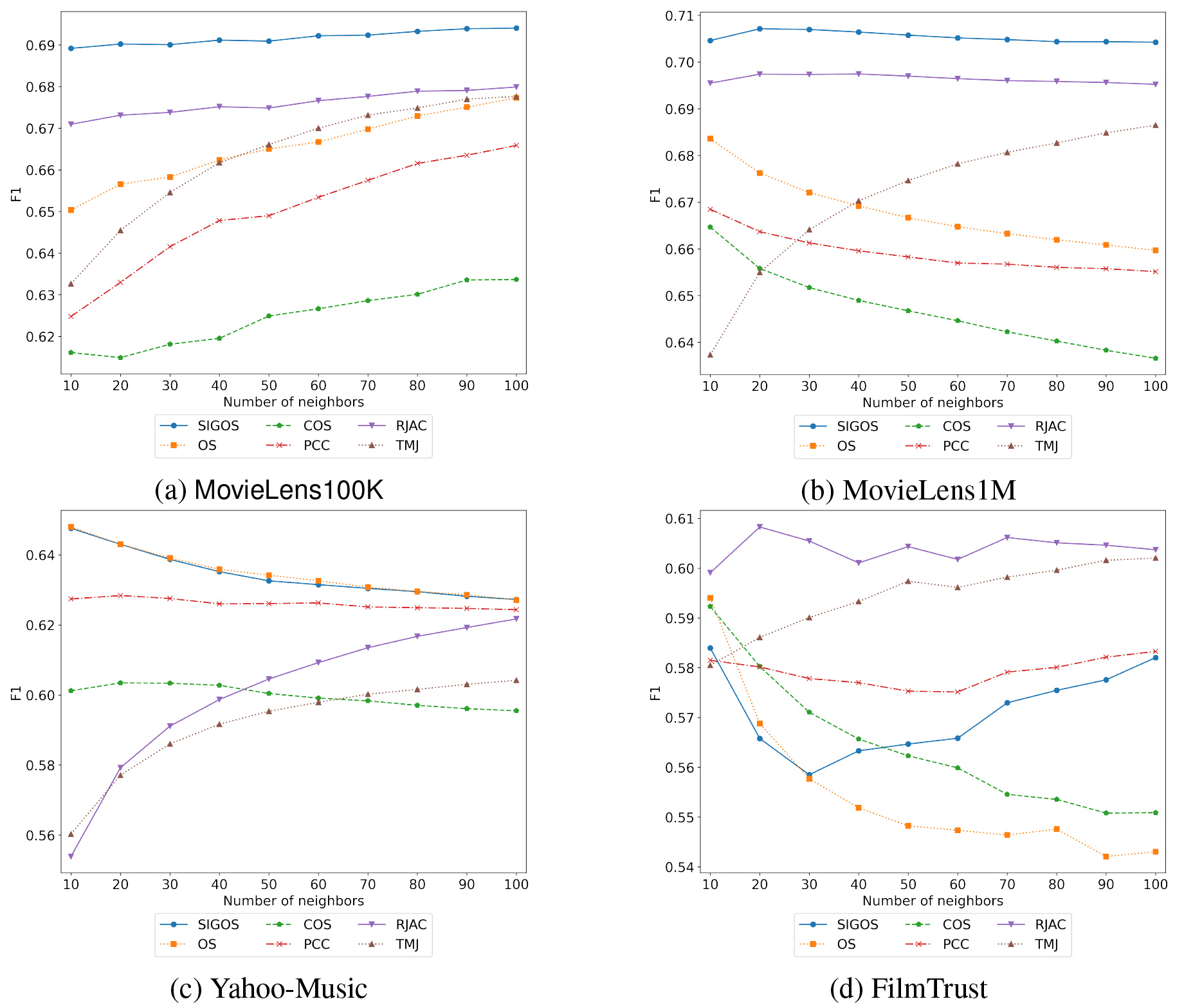
Before comparing SIGOS with the other similarity measures, the optimal
As
Next, Figs 3 and 4 show the evaluation results obtained by MAE and F1 for each dataset, varying with the number of nearest neighbors. For comparison,
Conclusion
This study proposes a new similarity measure that enhances the recently developed similarity measure, OS for recommendation systems. In this study, SIGOS was proposed to consider whether the sentiments of ratings from two different users match in the calculation of the relative difference in ratings. SIGOS considers that the relative difference in ratings is larger when the sentiments of ratings are not the same than when the sentiments of ratings are identical.
The experimental results on four datasets, MovieLens100K, MovieLens1M, Yahoo-Music and FilmTrust, showed that SIGOS generally outperformed OS for UBCF in terms of the prediction accuracy evaluated by MAE and F1. The proposed similarity is obtained from the assumption that resolving the asymmetry according to the magnitude of the ratings will improve the performance of OS, while considering whether or not the sentiment of the ratings agrees. Comparing SIGOS with OS, the prediction accuracy for the ratings was significantly improved in terms of MAE. In particular, the performance improvement in MAE was remarkable for MovieLens1M and FilmTrust datasets. In terms of F1, SIGOS showed better recommended performance than OS, except for Yahoo-music dataset. These results imply that the shortcomings of OS raised in this study degrade the recommendation performance, and the hypothesis that the recommendation performance will be improved if this shortcoming is eliminated is true. Moreover, SIGOS exhibits the excellent performance when
Moreover, the performance of SIGOS was improved as the value of
This study also has some limitations. SIGOS does not consider users’ rating behaviors. The thresholds for dividing positive and negative ratings by users may differ. Therefore, we will improve SIGOS to reflect users’ rating behaviors. In addition, we will investigate the performance of SIGOS for other evaluation metrics, such as the normalized discounted cumulative gain in future work.
Footnotes
Acknowledgments
This work was supported by the NationNR (NRF) grant funded by the Korea government (MSIT) (No. 2020R1F1A1054496).