
Abstract
This paper examines the extent of poverty in different districts (small domains) of the State of Odisha, India using direct, synthetic, composite, and model based small area estimation techniques. The district level poverty estimates are based on data collected during the 68
Keywords
Introduction
Odisha is the tenth largest State in the Indian Union located on the eastern coast of the country bordered in the east by the Bay of Bengal. The geographical boundary of the State comprises 4.74% of India’s land mark, having population of 41.97 million as per 2011 Census, out of which 83.31% live in rural areas. Administratively Odisha has been divided into 3 Revenue Divisions, 30 Districts and 314 Community Development Blocks. Odisha is a land of diversities and inhabited by different ethnic groups. About 40% of the population of the State belong to backward communities like the Scheduled Caste (17.1%) and the Scheduled Tribe (22.8%) communities. The per capita income (Net State Domestic Product (NSDP)) of Odisha during 2014–15 is estimated at Rs. 28, 384.00 (approximately 435 USA Dollars) indicating a growth rate of 7.3% over 2013-14 which is well below the National figure.
Agriculture is the major source of income of the rural Odisha accounting to 15.5% of Gross State Domestic Product (GSDP) as per advance estimate 2016–17. The vagaries of nature exposed to the State’s agriculture sector economy frequently cause cyclones, droughts and flash floods which substantially affect the production and productivity of agriculture. In spite of rich cultural heritage and being endowed with abundant natural resources e.g. minerals, forests, rivers etc. and long coast line and favourable political and social climate, Odisha stands at the bottom of the economic development as compared to most of the states of the country.
As per the World Bank Reports (2016) the districts of Odisha in the south and west are among the poorest in the country and the State. The coastal districts are economically more developed than other districts of the State. There is also widening gap between the rich and the poor across the social groups as well as across the regions.
Inputs on different socio-economic characteristics at grass root level like district, block etc. are highly essential for decentralised planning and strategies for programme implementation to handle the backward areas of the State. Certain items of information such as consumer expenditure/income data essential for grass-root planning are not covered in the population census schedules. Besides, conduct of the decennial census in India, the National Sample Survey Office (NSSO) carries out country wide surveys in India on various socio-economic parameters related to the national economy on varied topics as per demand of the Government of India from time to time in a regular basis in the form of different rounds during the inter-censal periods. The sample sizes so designed for the surveys of the NSSO are modest in nature and are fixed in such a way that it is possible to get some usable estimates at the national and state level. However, due to the importance of micro level planning in a developing country like India, where there is large scale poverty in most parts of the country, reliable estimates are being demanded by the administrators and policy planners at the small area level as per the recommendations of “Working Group on District Planning” set up by the Planning Commission of the Government of India during 1982. The Working Group in its report clearly highlighted the data requirement for planning and decision making at the district level. The sample sizes in NSSO surveys at the State level are not large enough to provide reliable direct estimates at small area level like district level, block level, community level etc. Conduct of district specific surveys with large sample also becomes expensive as well as time consuming.
During recent years in view of the demand for reliable statistics at micro level, Small Area (domain) Estimation (SAE) techniques have been developed to produce reliable estimates for such small areas with small sample sizes by borrowing strength from data relating to other areas through explicit and implicit models which connect the small areas via supplementary data (Rao, 2003). Typically, small area in our study refers to a subset of the population for which enough information is not available from the sample survey because of limited sample size. This creates problems to derive reliable estimates of small geographical areas like districts.
The main objective of the study is to estimate the rural poverty in Odisha at district levels based on the 68
Data
The data have been collected from the Population Census, 2011 and the Household Consumer Expenditure Survey, 2011–12 of the NSSO (68
Sampling design
The sampling design used in the 68
Distribution of districts-wise rural sample size
Distribution of districts-wise rural sample size
The poverty line for identifying whether a given household is poor or not, is fixed by the Planning Commission of the Government of India as per the methodology adopted by an Expert Group headed by Prof. Suresh Tendulkar at the National level in 2009. For rural Odisha the poverty line is fixed at Rs. 695.00 (roughly equivalent to 10.80 USA dollars). Monthly Per Capita Expenditure for the year 2011–12 is defined as the minimum or the cut off standard of expenditure on food below which an individual or household is described as poor. State level rural poverty lines were calculated from the National level poverty line by applying appropriate regional price indices.
As such, a single State level official poverty line for Odisha as recommended by the Planning Commission, Government of India has been used. The poverty estimation carried out for the districts of the Odisha State has not taken into account the different administrative efficiencies, available natural resources, infrastructural facilities, and political initiatives because of lack of required quantitative indicators. It may be mentioned here that the current poverty analysis of the NSSO consumer expenditure data is based on samples, assumed to be selected by simple random sampling (without replacement) from the population of households in the country, although the samples have been selected at different stages. This is done in order to simplify the mathematical complexities involved in the estimation and to provide a reasonably good approximation for the purpose for which it is supposed to be applied.
Methods of estimation of poverty
The district wise poverty estimation has been carried out by (i) Direct Method (ii) Indirect/Synthetic Method, (iii) Composite Method, and (iv) Small Area Estimation (SAE) technique using mixed model approach.
Direct method
Let
Define
Let
Let
An unbiased estimator of
The district level poverty estimation of Odisha for the rural sector is computed by head count method (direct estimation procedure) using the 68
Direct estimates are generally computed when the sample size for each small domain (small area) is sufficiently large to provide reasonably accurate estimates about the parameters of interest. However, when the data are collected to provide national and regional level statistics, the sample sizes for the sub-domains of the original domain happen to be usually very small leading to unacceptably large sampling variance.
An extension of direct estimation approach is to use the auxiliary information in the sample to arrive at more precise estimates for the small domains based on suitable regression technique (model-assisted approach to the design-based sampling theory). This improves the precision of direct estimates, but still affected by small sample sizes.
In the present study we have used direct method for estimation of proportion of households in poverty using log linear regression model. The unknown regression coefficients in the model can be estimated by the method of least squares using sample households, the population means of the auxiliary variables (usually unknown), may be used from either from recent census or from administrative official records or from other sources.
The covariates (auxiliary variables/independent variables) observed in NSSO sample survey used in regression analysis are household size, social group, total land possessed, primary source of lighting, primary source of cooking, salary earner, age, sex, marital status and general education of the head of the household, percentage of food in MPCE and household amenities etc. But only the effects of covariates such as household size, social group, total land possessed, primary source of lighting, salary earner, age, marital status, general education of the head of the household, percentage of food in MPCE are found to be significant, ascertained from the stepwise regression method of fitting the regression. The value of R
The district wise estimates of proportion of poverty along with standard error, CV and CI using headcount method and log linear regression model are shown in Table 2.
Indirect methods
As stated earlier, the sample size for each small area is usually very small the direct estimator does not seem to be reliable. Further, the associated standard errors of these estimates are likely to be very large and unreliable. Under such circumstances, it is required to devise estimation methods which borrow strength from the related areas. These estimators are known as the Indirect estimators since they use supplementary/explanatory variables from other small areas or times and possibly from both or from census. The usual indirect estimation techniques based on implicit models produce synthetic and composite estimators.
Synthetic estimators
Gonzalez (1973) described synthetic estimation as follows: “An unbiased estimate is obtained from a sample for large area; when this estimate is used to derive estimates for sub-areas on the assumption that the small areas have the same characteristics as the large area, we identify these estimates as synthetic estimates”. This method borrows strength from related subareas to increase the effective sample size for estimation and hence, the accuracy of the resulting estimates (Holt et al., 1979).
The method of synthetic estimation presupposes the availability of estimates from an inquiry or survey of estimates for a large subset of the population such as large geographical area (e.g. Country, State etc.) or demographic group (e.g. age group, sex group etc.) or social group (e.g. community, disability group, or an industrial group etc.). Appropriate weights are then applied to large population subset estimates to arrive the desired small area estimates. In certain studies censuses provide sources of their weights.
Matching variables in the survey and the census
Before modelling, it is essential to select the list of explanatory variables that exist both in the survey and the census. If the sample selected for the household survey is representative and randomly selected from the population, one can expect the distribution of the variables to be similar both in the survey and in the population. Initially, a list of common variables was constructed using both the census schedule (the house list schedule) and the household schedule of NSSO Consumer Expenditure survey. Due to non-availability of village directory from the census, the household level variables have been converted into village characteristics in both, the census and the survey data and then, the village level data is converted into district level and hence district level variables are generated to be used in the regression model. National Sample Survey (NSS) data do not contain any village/district level variables. As the location effects captured by the village/district level variables are important determinant of consumption behaviour in order to control for location effects, we rely only on village/district level variables that can be created from the available household level variables (Sisodia & Singh, 2001). But the covariates (explanatory variables) are available at districts level not below that level. So, the area level area model is adopted to derive the small area level estimates. These covariates are drawn from the census 2011. The relationship between variables of interest and covariates used in this study are assumed not to change significantly over the period. There were more than 100 covariates available from the population census for the purpose of modelling.
Selection of covariates
First, examine the correlation of all the available covariates with the target variable and then select the covariates with reasonably good correlation with the target variable. After the selection of covariates, the model can be estimated controlling for both the household and village level effects following the step-wise regression analysis. Covariates are retained in the model according to their statistical significance. The variables with low t-values are removed. So, the five variables like household size, ST percentage, SC percentage, Work Participation Rate (WPR), and female literacy rate were identified for further analysis which significantly explained the model.
The regression synthetic estimator of
where
Ghosh and Rao (1994) suggested a weighted combination of the direct estimator and synthetic estimator to arrive at a composite estimator for the population total of
where
Ghosh and Rao (1994) suggested to obtain optimal weights by minimizing the Mean Square Error (MSE) of
The composite estimator is expected to balance the potential bias of the synthetic estimator against the sustainability of the direct estimator. In the present study composite estimates for poverty at district level is obtained by combining direct estimate and the synthetic estimate giving weight as the inverse of root mean square error. Table 2 presents the district wise percentage of poverty using synthetic and composite estimates.
The traditional indirect estimator assumes that all the areas of interest behave similarly with reference to the variable of interest and do not take into account the area specific variability. This will lead to severe biasness if the assumption of homogeneity within the larger area is violated or the structure of the population changed since the previous census. This limitation is taken care up by an alternative estimation techniques based on an explicit linking model named as mixed effect model. Random area effects in the mixed effect model take into account of the dissimilarities among the areas.
Mixed models are used in specific situations based on data availability or the response variable of interest. These are (i) area level random effect models which use area specific auxiliary information and where information or response variable available only at the small area level (Fay & Herriot, 1979) and (ii) unit level regression models which uses the unit level auxiliary information and where information on the response variable is available at the unit level (Battese et al., 1988). In the absence of unit level data we resort to area level models.
Area level models
This model first conceived by Fay and Herriot (1979) was used for the prediction of mean per capita income in small geographical areas. An area level model based on two components:
Direct estimates of
where
At linking model (Srivastava, 2016) is
where
Combining these two models we finally obtain a linear mixed effect model given by
Here
In the present discussion
The Fay and Herriot (FH) method for SAE is based on area level liner mixed model and their approach is applicable to a continuous variable. But for discrete, particularly binary variable, the model linking the probability of success
The expected values of
Let
An estimate of proportion of poor households
It is obvious that in order to compute the estimates given by the above two equations we require estimates of the unknown parameters
The estimation of mean squared error (MSE) for predictors given by Eq. (9). The MSE estimates are computed to assess the reliability of estimation and also to construct the confidence interval (CI) for the estimates. The mean squared error estimates of Eq. (9) under model (1) is given by
The first two components
In this study area level models which was used by Chandra et al. (2011) and Mantiga et al. (2007) have been applied for computing district level poverty estimates along with their mean square error estimates following the mathematically tedious developed by Prasad and Rao (1990), for which R-software packages version 3.3.0 are available.
The aim of the diagnostic procedures are used to validate the reliability of the model based small area estimates vrs direct survey estimates. Generally, two types of diagnostic procedures are used in SAE, ie. model diagnostics and small area estimates validation/diagnostics. The model diagnostics are used to verify the assumptions of underlying the model. The second diagnostics are used to validate the reliability of the model-based SAE. Model-based estimates should be consistent, more precise, more stable and acceptable.
Biased scatter plot of the direct and model-based estimates.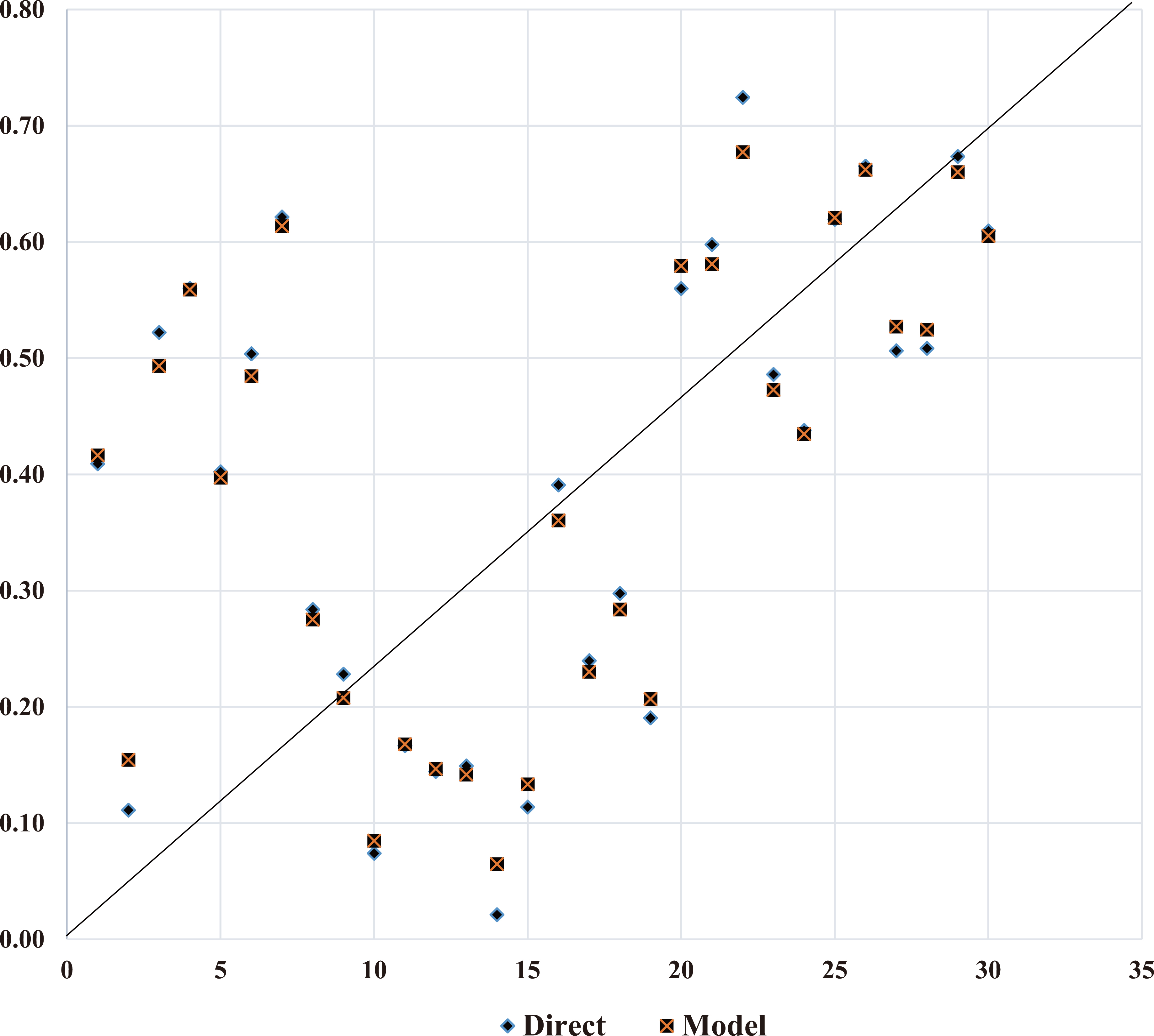
District level residuals.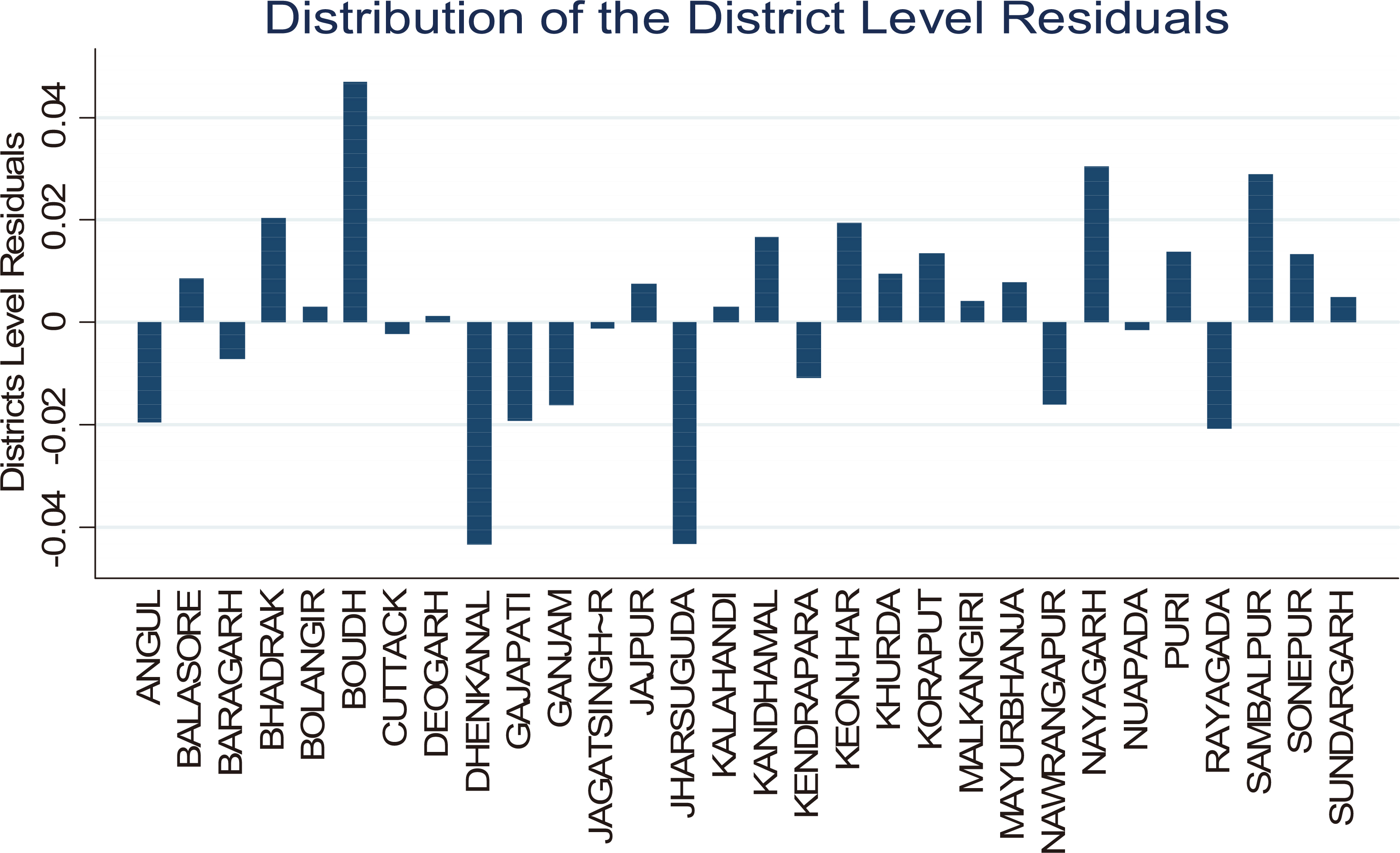
q-q plot.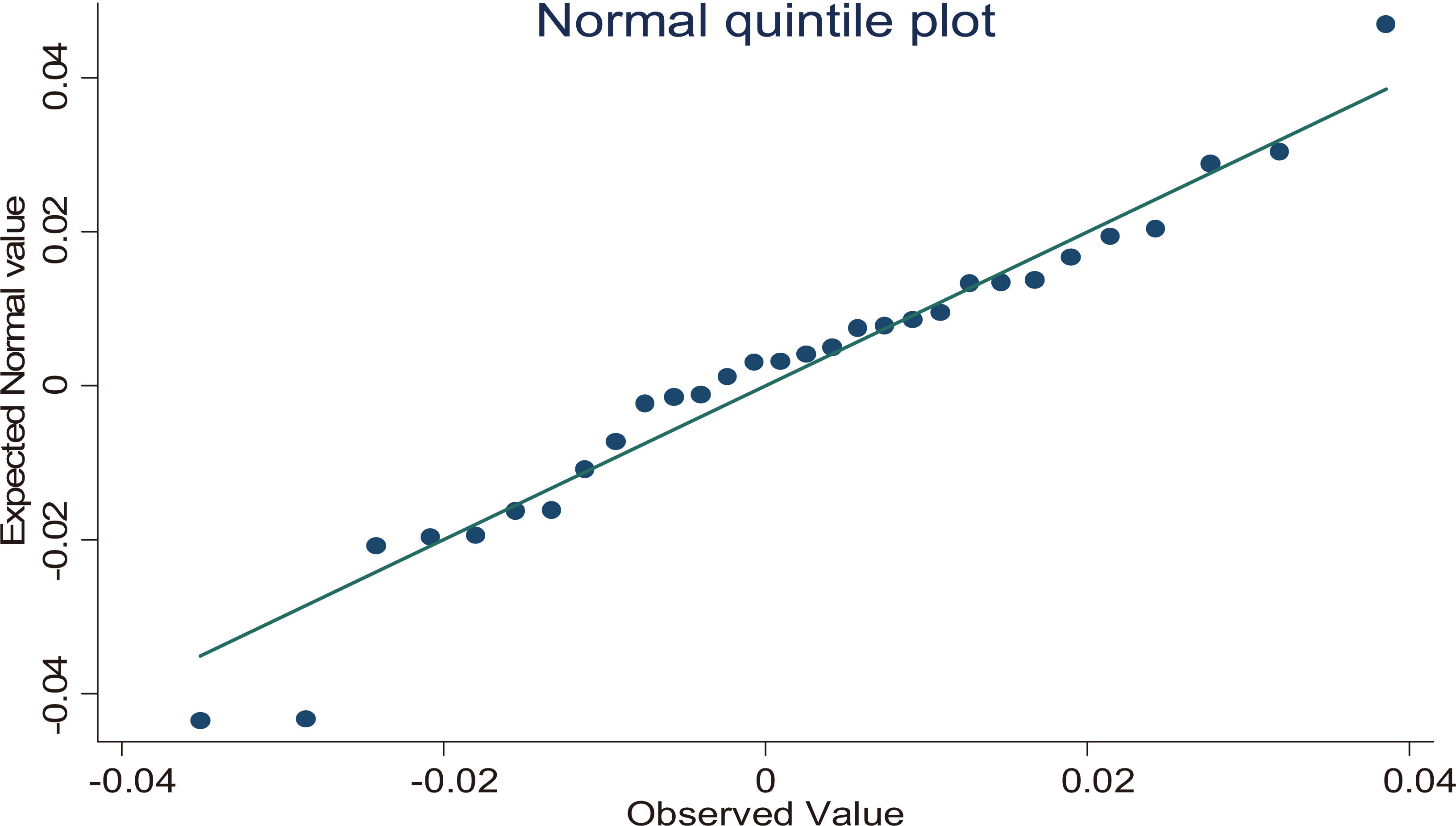
The bias diagnostics are used to assess the deviations of the model-based estimates from the direct survey estimates. The model-based estimates are expected to be biased predictors of the direct estimates. The model-based estimates will be unbiased predictors of the direct survey estimates if the relationship between the variable of interest and the covariates have been mis-specified or mis-estimated. Where, the relationship has not been mis-estimated, a linear relationship of the type
Districtwise estimates of incidence of poverty, coefficient of variation and 95% confidence interval
Source: Computed from Primary data of NSSO, 68
Source: Computed from Primary data of NSSO, 68
The CVs for the model based estimates have been computed to assess the improved precision of the model based estimates compared to the direct estimates, synthetic estimates, and composite estimates (Table 2). The CVs show the sampling variability as a percentage of the estimates. Estimates with large CVs are considered unreliable (i.e. smaller is better). There are no internationally accepted norms available that allow us to judge how large is too large (less than 20% is better). However, United States Census Bureau Center for Statistical Methodology (CSRM) – Small Area Estimation Research Group, 2013 want the majority of the CVs of key estimates to be less than 30%. The estimated CVs show that model-based estimates have a higher degree of reliability and stable as compared to other estimates. It is observed in direct estimate of poverty that in many districts the lower bound (Lower) of 95% confidence interval (CI) is negative which results in practically impossible and inadmissible values of CI for direct estimates. Out of 30 districts, 24 districts have CV less than 20%. The CV between 20% to 30% is in 5 districts like Angul, Jagatsinghpur, Jajpur, Jharsuguda and Kendrapara of Odisha. The CV more than 30% in Dhenkanal district of Odisha implies an unstable estimates. But model-based estimates with precise CI and reasonable CV percentage are reliable. The results show the advantage of using SAE technique to cope up the small sample size problem in producing the estimates with reliable confidence intervals.
The estimation of district level statistics of poor household has been carried out by using different techniques like direct (head count), direct (by fitting log linear regression model), indirect (synthetic), composite and model-based methods. The proportion of poor, its coefficient of variation (CV) and confidence interval (CI) of different techniques for the districts of Odisha are presented in Table 2 and Fig. 1. It is observed that for some districts the lower bound of the confidence interval (CI) is negative in direct, synthetic and composite method except for the model-based method. But it is found that model-based estimates have precise CI and reasonable CV percentage which may be accepted as reliable.
In our study we have observed that 9 districts in direct estimate, 3 in regression-based direct estimate, 15 in synthetic estimate, 6 in composite estimate and 1 in model-based estimate are CV more than 30%.
The districts of Odisha have also been classified according to percentage of poverty into 4 categories like mild (0–20%), moderate (20%–40%), severe (40%–50%) and highly severe (above 50%) category as per model based method and shown in Map 1.
It is observed from Table 2 that the districts like Dhenkanal, Kendrapara, Angul, Cuttack, Jajpur, and Jharsuguda are the common districts according to mild category (0–20%) in case of incidence of poverty using different methods of estimation. In the moderate category there are eight districts in direct method and seven districts in model-based method. It is seen that Boudh, Kandhamal, Koraput, Nabarangpur, and Mayurbhanj are included in severe and highly severe category (above 40%) in all methods of estimation.
Districtwise coefficients of variation for different methods of estimation.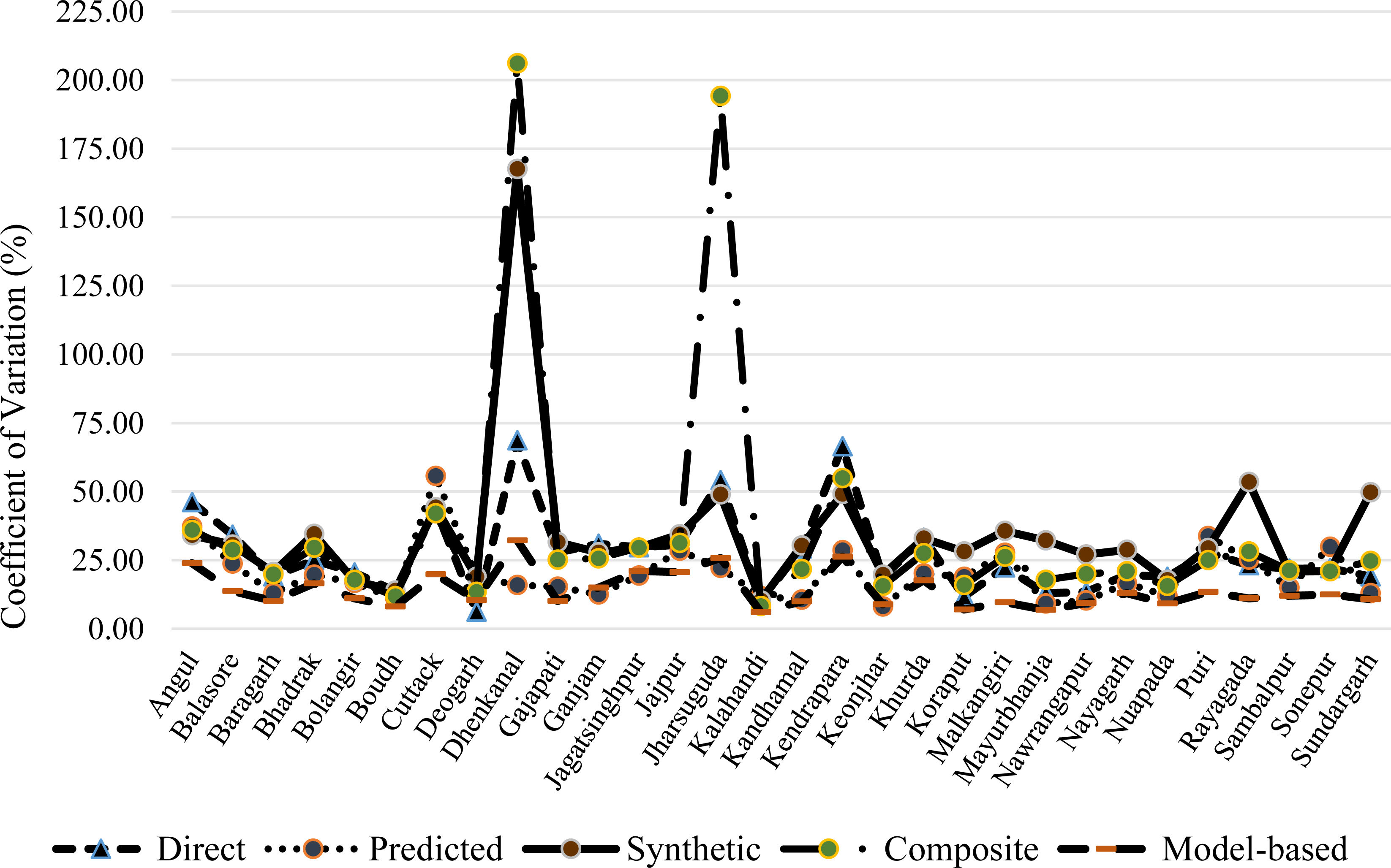
Estimation of poverty of Odisha (model based method).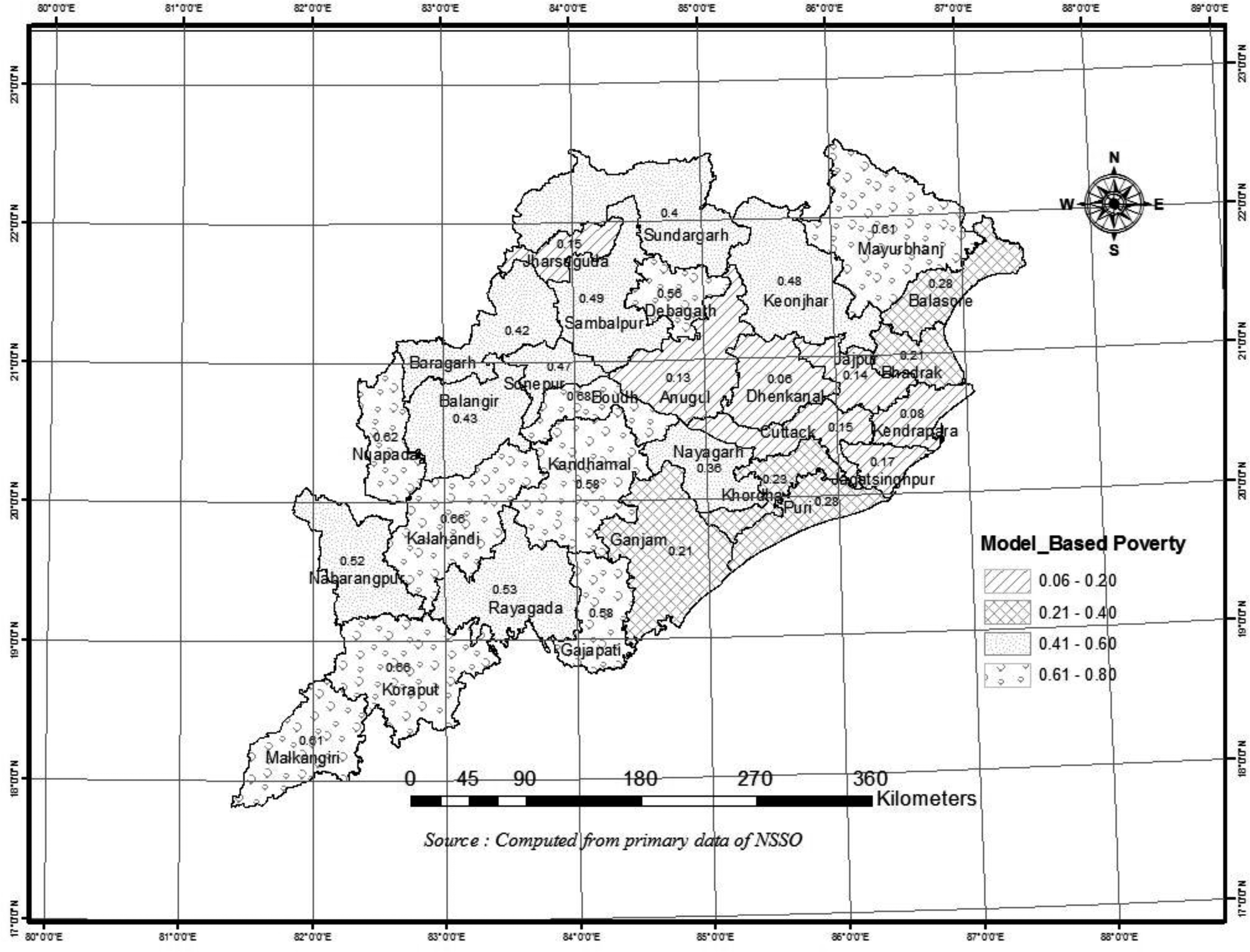
As the model based method is supposed to be reliable method (CV within 30%), the classification of percentage of poverty and poverty mapping has been made based on estimates derived using mixed model method. It is observed that seven districts come under mild, six districts under moderate and seventeen districts under severe category. It implies that more than 50% districts of Odisha are under severe poverty. Particularly, the Southern region of Odisha which are hilly and tribal dominated districts are more vulnerable than the other regions in case of poverty incidence. Only six districts namely Bhadrak, Ganjam, Khordha, Balasore, Puri, and Nayagarh are come under moderate category (20–40%) of poverty.
In India the district is an important domain for planning process in the State and therefore, availability of the district level statistics is vital for monitoring the policy and planning. Reliable estimates of poverty at district levels in Odisha are not available except the estimates based on headcount, which are accompanied by large sampling error due to small sample sizes allocated for the districts. This leads to unreliability of the poverty estimates at district levels. In this context the recently developed small area estimation pioneered techniques developed by Rao (2003), Ghosh and Rao (1994), Saei and Chambers (2003), Manteiga et al. (2007) and Chandra et al. (2011) have been applied to capture the district level poverty for Odisha.
The method of estimation of poverty proportion for small areas using reliable small area estimation technique is well developed and practised widely in many countries of the world. But, there is very less known application to the Indian data and no application to the valuable and informative NSSO data for Odisha.
The present analysis using model-based method is found to be more reliable than the direct and indirect methods for computing district level estimates of proportion of poor households in Odisha by using the 68
Footnotes
Acknowledgments
The authors thank the reviewers for their helpful suggestions. Special thanks go to Dr. Hukum Chandra for his valuable comments and academic discussions which helped the presentation of results to a great extent.