
Abstract
The aim of this research is to develop the novel procedure of Adaptive Neuro-Fuzzy Inference System (ANFIS) modeling for forecasting time series data. The procedure development applies statistical inference based on Lagrange Multiplier (LM) test for selecting input variables, determining the number of clusters, and generating the rule-bases. For selecting inputs, several lags which are indicated significantly different to zero are divided into 2 clusters (minimum number of clusters), and then the lags are selected as optimal inputs of ANFIS based on LM test procedure. The cluster numbers of optimal inputs are added using LM-test procedure such optimal clusters are obtained. Based on those results, a number of rule-bases are generated. The developed model is applied for forecasting cayenne production data in Central Java. The result of proposed procedure is that the optimal inputs consist of 2 lags (lag-1 and lag-3) which are divided into 2 clusters. In this case, the two rules are selected as optimal rules. Finally, the model can work well, and generates very satisfying result in forecasting cayenne production data. Based on the Root Mean Squares Error (RMSE) value, the ANFIS performance is better than performance of Autoregressive Integrated Moving Average (ARIMA) for forecasting cayenne production data in Central Java.
Introduction
Time series data which characterized by uncertainty, autocorrelation persistence and leptokurtic behavior are usually non-stationary and non-linear (Abiyev et al., 2005; Cheng & Wei, 2010; Maciel, 2012; Maciel et al., 2012; Makridakis et al., 1998; Tsay, 2005; Talebizadeh & Moridnejad, 2011; Samanta, 2011). Autoregressive Integrated Moving Average (ARIMA) is one of the most popular models which used for time series forecasting (Box et al., 1994; Brockwell & Davis, 1991; Engle, 1982; Haykin, 1999; Wei, 2006). Autoregressive Conditional Heteroscedasticity (ARCH) proposed by (Engle, 1982) and Generalized Autoregressive Conditional Heteroscedasticity (GARCH) developed by (Bollerslev, 1986) are the most popular variance models. ARIMA-GARCH has been applied in a lot of research for forecasting nonlinear time series data (Fahimifard et al., 2009; Tsay, 2005). The model still has some disadvantages when applied for forecasting nonlinear time series data, because the series is not appropriate with standardized theoretical phenomenon and also the model can not capture the uncertainty of data. Using linear models for non-linear data would cause cointegration errors in time series (Chen et al., 2009).
In recent years, alternative models have been developed to analyze non-linear time series such as neural networks (NN), fuzzy system and its hybrid (Fausset, 2009; Haykin, 1999; Jang, 1993; Jang et al., 1997). ANFIS that combines NN and fuzzy system has been implemented in many fields of time series research such as application of ANFIS based on singular spectrum analysis for forecasting chaotic time series (Abdollahzade et al., 2015); chaotic time series prediction using improved ANFIS (Behmanesh et al., 2014); fuzzy time series forecasting (Cheng et al., 2016); developing a new approach for forecasting the trends of oil price (Mombeini & Yazdani-Chamzini, 2015); computational intelligence for prediction of chaotic time series; modeling minimum temperature (Daneshmand et al., 2015); financial trading (Kablan, 2009); forecasting of mobile sales (Wang et al., 2011); forecasting of stock return (Boyacioglu & Avci, 2010; Hung, 2009; Wei et al., 2011); prediction of government bond yield (Chen et al., 2009); prediction for EPS of leading industries (Wei et al., 2011); forecasting of financial volatility (Luna & Ballini, 2012; Maciel, 2012; Maciel et al., 2012) and prediction of exchange rates (Alakhras, 2005, Alizadeh et al., 2009; Fahimifard et al., 2009). Conclusively ANFIS is better than the other methods.
All ANFIS models that have been proposed by the previous researchers did not apply LM-test for selecting the best model. To date, there is no research which using statistical inference based on LM test for selecting optimal model in ANFIS. Therefore, this research focused on procedure development of ANFIS modeling which uses LM-test for selecting the input variables, determining the number of membership function (cluster) and determining the number of rules. The procedure is extended based on LM-test for selecting NN model proposed by White in 1989 (Anders & Korn, 1999). The new procedure for determining input variables, determining number of clusters and generating rule-bases of ANFIS applies statistical inference based on LM-test. Finally, the model was implemented for forecasting paddy production in Central Java Province. This paper is organized as follows; Section 2 discusses an architecture of ANFIS and estimation of consequent parameters; Section 3 discusses about proposed procedure for selecting model by using statistical inference based on LM-test and application of developed model; and conclusion is discussed in Section 4.
Theoretical framework
ANFIS architecture
The ANFIS architecture consists of fuzzyfication (layer-1), fuzzy inference system (layer-2 and layer-3), defuzzyfication (layer-4) and aggregation (layer-5). The NN architecture which used in ANFIS architecture has 5 fixed-layers (Jang et al., 1997). Generally, the architecture of ANFIS for time series modeling with p input variables
where
The architecture of ANFIS (see Fig. 1) consist of 5 layers that can be described as follows (Jang et al., 1997).
ANFIS architecture for time series modeling.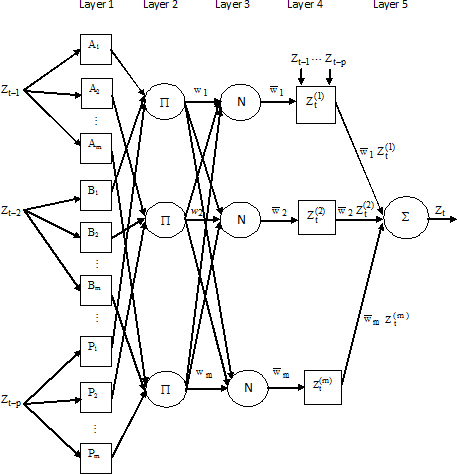
Every node in the first layer is adaptive with one parametric activation function. The output is membership degree of given inputs which satisfy membership function
Every node in the second layer is fixed node which the output of this layer is the product of incoming signal. Generally, it uses fuzzy operation AND. The output of each node represents firing strength
Every node in the third layer is fixed node, which computes ratio of firing strength of
Every node in the fourth layer is adaptive node, the output of each node
Every node in the fifth layer is a fixed node which adds all of incoming signal. The output of fifth layer is the output of the whole network.
The general model of ANFIS is given as follow.
If the general ANFIS model is given as expression (5) then the estimation of consequent parameters
If the consequent parameters had been estimated, then the premise parameters can be updated using back-propagation method. Optimal quality is obtained by minimizing the ANFIS error function.
Lagrange Multiplier (LM) test is used for testing hypothesis of adding variables in ANFIS modeling. Some variables should be included to the model because the new inputs, number of clusters or number of rules to be added in the model.
Procedure for adding input variables
Determining input can be identified by lag plot of data or the partial autocorrelation function (PACF) plot. Lag plot can be used for testing linearity. The lag plot or PACF plot can be used for identification of autoregressive (AR) input. Based on lag plot and PACF plot, the significant lags should be tested as input variables of ANFIS. Determining input is performed by constructing models which involve a number of input variables with minimum number of clusters and minimum number of rules. Firstly, construct the models with 1 input variable, 2 clusters and 2 rules and then select the model which has the largest
where
where
The null hypothesis for testing of adding variables can be formulated as follow:
Procedure of hypothesis test using LM-test can be done as the following steps:
Estimate the parameters of restricted model
Determine the estimate of residual:
Regress the residual
When the ANFIS model with optimal inputs was obtained, adding number of clusters can be executed using LM-test procedure to get a model with optimal number of clusters. If given p input variables
where
The null hypothesis for testing adding variables
Procedure of hypothesis test using LM-test can be done as the following steps:
Estimate the parameters of restricted model:
Determine the estimate of residual:
Regress the residual
Time series, ACF and PACF plots of cayenne production data.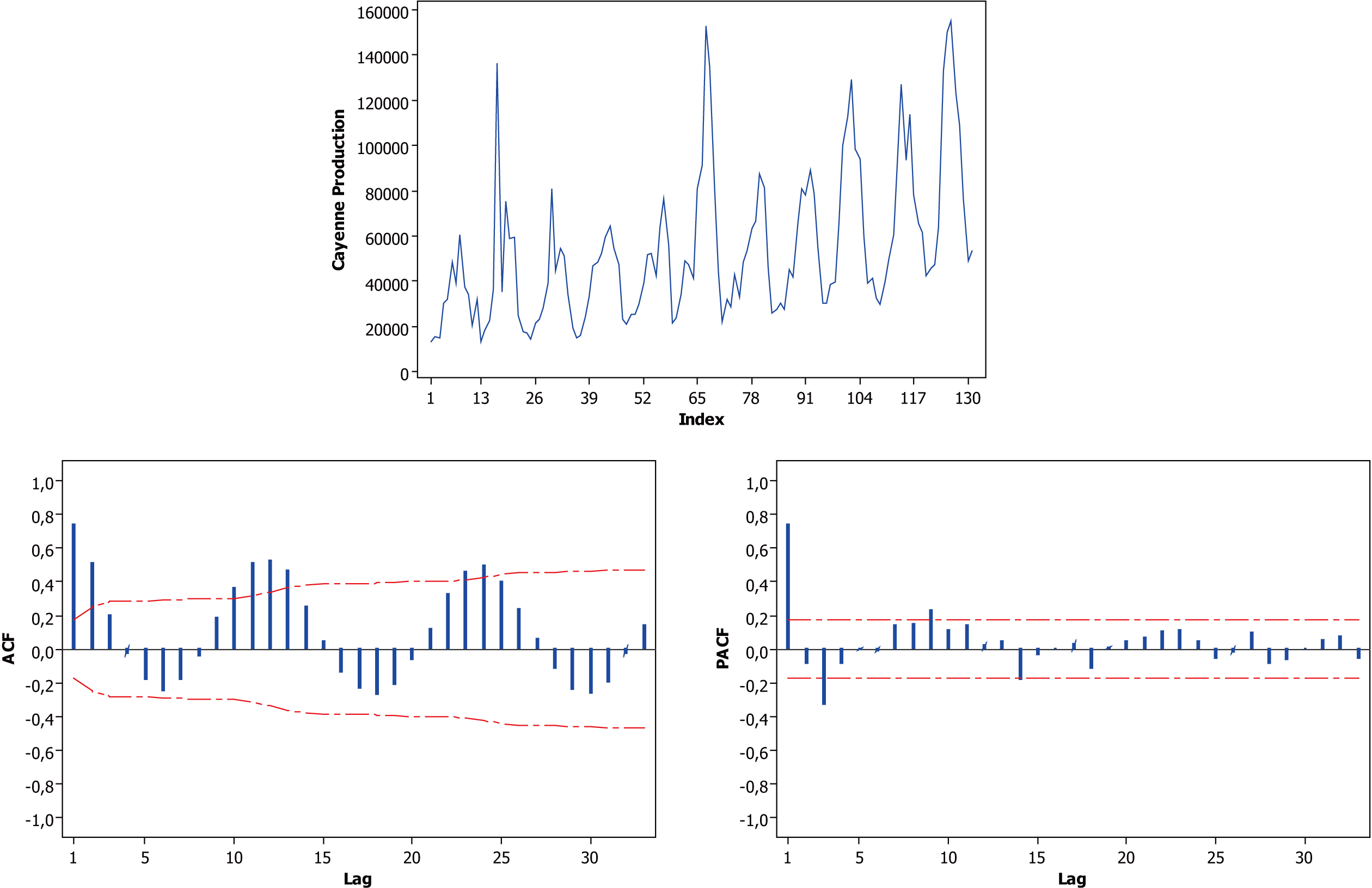
The rule-bases of ANFIS are generated based on the optimal input variables and optimal number of clusters. The all possible combination of rules which can be generated is
then the output of ANFIS is given by equation:
As an implementation of ANFIS modeling for forecasting time series data, we construct ANFIS model for forecasting cayenne production as a case study. In this research, the monthly cayenne production data from January 2003 up to December 2014 (
Cayenne production data and its prediction.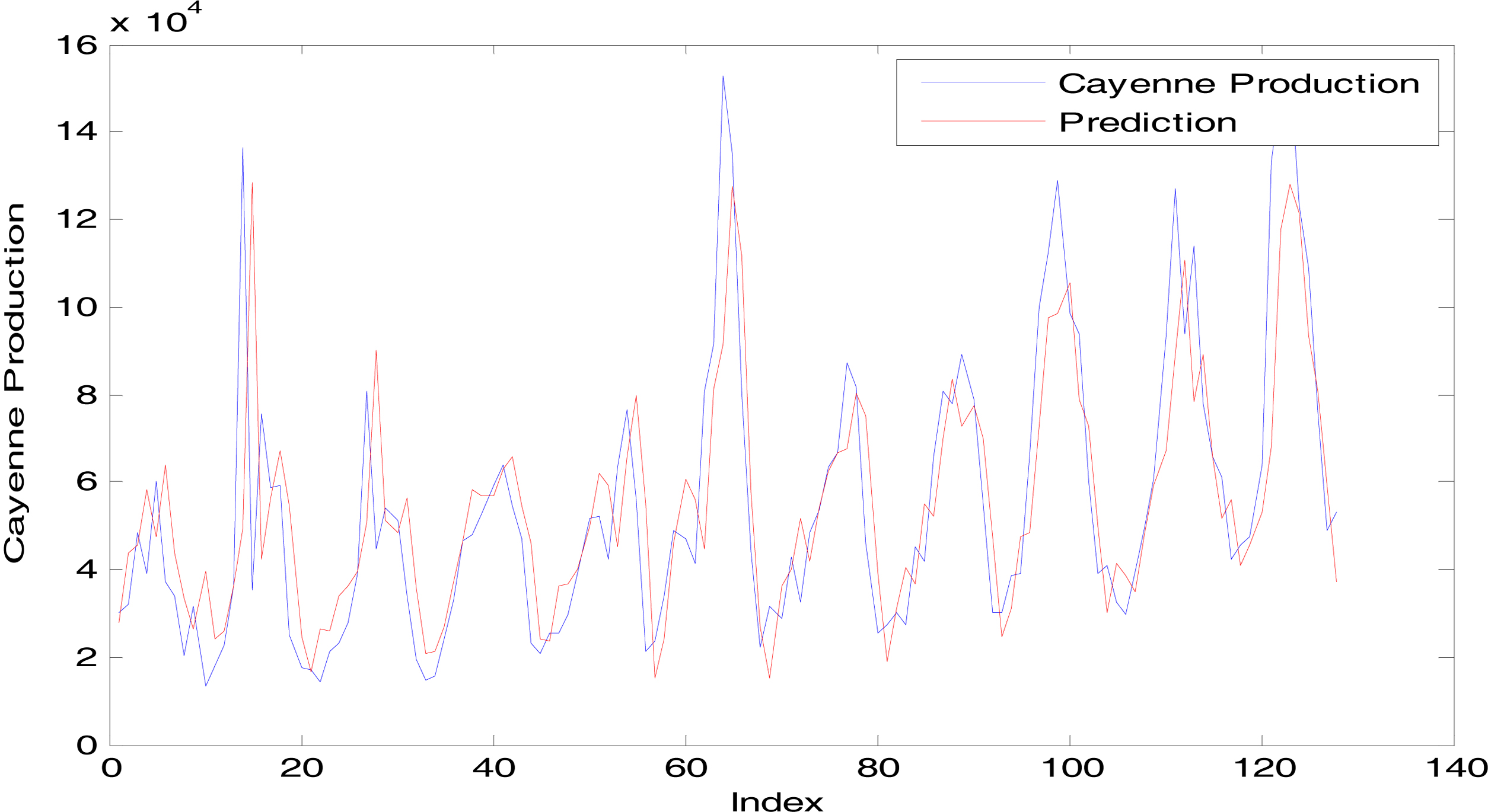
Based on the partial autocorrelation function (PACF) plot of cayenne production data (see Fig. 2), lag-1 and lag-3 are significant different to zero. Based on LM test, the variables: lag-1 and lag-3 can be selected as inputs ANFIS. The optimal cluster number of the inputs variables is two clusters (membership functions). The result of optimal model selection can be written as follow:
where
The RMSE value of forecasting for in sample data using ANFIS is 20558. Whereas the RMSE value using ARIMA ([1,3],0,0) is 20739.9. Therefore, the performance of ANFIS model is better than ARIMA model for forecasting cayenne production data in Central Java Province. The predicted value of cayenne production data based on model (11) can be seen as Fig. 3.
The proposed procedure of ANFIS modeling using statistical inference based on LM-test can work well for forecasting time series data. Based on the empirical study can be concluded that the developed model has a good performance for forecasting cayenne production data. An optimal ANFIS model for forecasting cayenne production is a model with 2 inputs (lag-1 and lag-3), 2 membership functions and 2 rules. Based on RMSE values, the performance of ANFIS model is better than ARIMA model for forecasting cayenne production data in Central Java Province.
Footnotes
Acknowledgments
We would like to give thank to Rector of Universitas Diponegoro, Chief of Research and Public Services Universitas Diponegoro for their support to this research.