
Abstract
The estimation of optimum cut points for covariates in lifetime regression models is of great interest under a medical view. Usually the choice of covariate cut points is made in an arbitrary way following the clinical expert knowledge. In this paper, it is proposed a simple and practical Bayesian approach which could be used to different lifetime distributions under AFT (accelerated failure time) modeling approach assuming censored or uncensored data to get optimum cut points with larger prognostic effects. For the Bayesian approach, MCMC simulations are used to get estimation for the cut points under a squared error loss (SEL) function. The proposed methodology is illustrated with three medical lifetime data sets.
Keywords
Introduction
Some parametric distributions like the Weibull, log-normal, gamma, generalized gamma distributions or non-parametric methods as the popular Kaplan-Meier (1958) estimates for the survival function and the Wilcoxon and log-rank tests (see, for example, Lee & Wenyuwang, 2003) used in the comparison of two or more treatment groups are usual methods in the analysis of lifetime data for homogeneous populations.
In medical studies, considering survival data, it is also common the presence of concomitant information like gender, age and status of the disease in the diagnostic associated to each patient denoted as covariates, explanatory variables or independent variables. The covariates can be considered as dependent or independent of time. They can be categorical like treatment and ethnicity or be continuous like blood pressure or height. Popular choices of regression models to incorporate the covariates are the proportional hazards model, the additive hazards model, the proportional odds model and the accelerated failure time model (see for example, Collett, 2003; Klein & Moeschberger, 2003; Meeker & Escobar, 1998; Kalbfleisch & Prentice, 2002).
The use of the Cox proportional hazards (Cox, 1972) regression model (or the equivalent in the case of two treatment groups, the log-rank test) is well established as common practice in the statistical analysis of medical data. The great popularity of this model is motivated by being free of a parametric distribution assumption for the survival times.
Usually many of the covariates of interest are continuous. Although these covariates could be modeled as continuous variables, it is common in medical applications to dichotomize continuous covariates to develop prognostic models. In this way, under a statistical approach, dichotomization eliminates the need for the linearity assumption under a regression model, makes data summarization more efficient, and allows for simple interpretation using the impact of a binary covariate on an outcome that it is easier than the interpretation of a regression parameter based on a change of one unit in a continuous covariate. Another great simplification: from the clinical approach, binary covariates give simple risk classification in terms of high versus low, simplify treatment recommendations and simplify the diagnostic criteria (Mazumdar & Glassman, 2000).
In terms of statistical interpretations although all advantages of dichotomization in terms of clinical interpretations, dichotomization could result in the loss of information considering a threshold association rather than a linear relation. In this situation, researchers could not be able to detect possible non-linear relationships (Altman & Royston, 2006; MacCallum et al., 2002). It has been emphasized that dichotomization is appropriate only when a threshold effect value truly exists, that is, if it is possible to assume some binary split of the continuous covariate that creates two relatively distinct but homogeneous groups with respect to a particular outcome (Abdolell et al., 2002).
In general, clinicians point out that the interpretation of continuous covariates could be difficult and they prefer to model these effects as categorical or binary covariates reflecting different prognostic groups of patients based on the measured value of the continuous covariate. In other cases, the covariate may represent the dose of some drug or some other therapeutic agent, and the clinician is interested in identification of a therapeutic threshold.
Even though evaluation of a variable’s prognostic value is best done with the variable in its continuous form and there is a possible loss of information when categorizing a continuous covariate, the need for thresholds for clinical use and treatment decisions justifies the development of appropriate statistical methods for finding optimal cut points (see for example, Lausen et al., 2004; Silva & Klein, 2011; Andrei & Murray, 2007; Lausen & Schumacher, 1996; Abdolell et al., 2002; Altman, 1991, 1998; Hollander & Schumacher, 2001; Hilsenbeck & Clark, 1996; Mazumdar et al., 2003; Altman et al., 1994; Contal & O’Quigley, 1999; Mazumdar & Glassman, 2000; Cumsille et al., 2000; Liquet & Commenges, 2001; Hollander et al., 2004; Ragland, 1992; Magder & Fix, 2003).
Considering a clinical point of view, usually binary covariates could be preferred based on some justifications as follows:
A simple risk classification into “high” versus “low”. Criteria for prospective studies. Criteria to make treatment recommendations. Diagnostic criteria for the disease. Estimation of prognosis. To establish an assumed biological threshold. Easiness to obtain association measures easily interpretable as odds ratio or hazard ratio.
When discretizing a continuous covariate and then testing for the covariate effect, a number of techniques can be used. One group of techniques relies on the investigator to provide cut points based on historical data or it uses cut points based on a split into groups at a predetermined percentile of the continuous covariate. Another approach is to let the data decide on the cutpoint and then perform the test of the covariate effect on the two resulting groups. In most cases the continuous covariate in this approach is split into groups based on either the largest value of the likelihood or the largest value of some two-sample test statistic after a search of possible cut points. This selection of the largest likelihood or test statistic leads to an inflated type-I error due to multiple testing, so some correction needs to be applied to obtain the correct type-I error.
Considering medical survival data, the literature presents many different approaches to select a cutpoint based on a data-dependent approach as for example considering a Cox proportional hazards model with a single covariate defined as 1 or 0 depending on the value of the continuous covariate. One of these approaches is based on an adjusted test on the maximum value of the score statistic from the Cox model and convergence to a Brownian bridge under the null hypothesis (Jespersen, 1986). Other approach is based on a modification of the log rank test statistic (Contal & O’Quigley, 1999) showing that the process consisting of the score statistics using cut points at the order statistics of the continuous covariates converges to a Brownian bridge process. Other approaches are introduced in the literature (Lausen & Schumacher, 1992, 1996). Klein and Wu (2004) compare these estimators and extend the Contal and O’Quigley approach to the accelerated failure time model and the Cox model with additional covariates.
A simple alternative for these existing approaches is the use of Bayesian methods especially using computer intensive MCMC (Markov Chain Monte Carlo) methods as the Gibbs sampling algorithm (see for example, Gelfand & Smith, 1990) or the Metropolis-Hastings algorithm (see for example, Chib & Greenberg, 1995) to find optimal cut points for the continuous covariates. In this way, it is possible to obtain in a simple computational way the Bayesian point estimates for the cut points given by Monte Carlo estimates of the posterior means (use of squared error loss function), accurate credible intervals for the cut points and estimates for the regression parameters based on the simulated Gibbs samples. Under a Bayesian approach, the posterior inferences are obtained within a Markov chain Monte Carlo (MCMC) sampling environment using the Open Bugs software (Spiegelhalter et al., 2003).
The paper is organized as follows: in Section 2, it is introduced the general accelerated failure time (AFT) model; in Section 3, it is introduced cut points in AFT models assuming a Weibull distribution for
In accelerated failure time models (AFT) the effect of the covariates is given by a multiplication of the expected survival time. A general formulation for the AFT hazard for an individual
where,
For AFT models it is common to use the log-linear representation,
where
In applications it is common the use of maximum likelihood approach to get estimation of the unknown parameters in the log-linear regression models. The likelihood function is obtained assuming a distribution of the error. Let us assume
From Eq. (4), the likelihood function in presence of censoring data is given by,
where
Maximum likelihood estimates for
A popular regression model derived from Eq. (3) is given by the Weibull regression model where the term
The parameter
The survival function and hazard functions of the Weibull distribution with density Eq. (7) are given, respectively, by,
and
The hazard function
and
Also note that from model Eq. (3), the scale parameter
that is, the regression model defined by Eq. (3) defines a regression model in the scale parameter (see for example, Lawless, 1982) assuming the same shape parameter.
The log-linear regression model Eq. (3) can be extended to other distributions for
Let us assume a Weibull distribution for the lifetimes
In this way, it is defined the following regression model:
where
For a Bayesian analysis, it i assumed that the parameters
where
Combining the joint prior distribution for
Or,
where,
Samples of the joint posterior distribution for
and
where,
Bayes estimates for the regression parameters
In the same way it is also possible to assume other regression lifetime models as in special case, a log-normal regression model in Eq. (3).
In this section, it is considered different applications of the proposed methodology assuming uncensored and censored medical survival times. For this purpose, three data sets are considered. In each application it was assumed a Bayesian analysis using the Open Bugs software (Spiegelhalter et al., 2003) with a burn-in sample of 11,000 samples deleted to eliminate the effect of the initial values in the iterative algorithm and 100,000 additional samples from where it was considered every 100
TTT plot based on the (a) Krall data set, (b) Greene and Byar data set and (c) German breast cancer data set.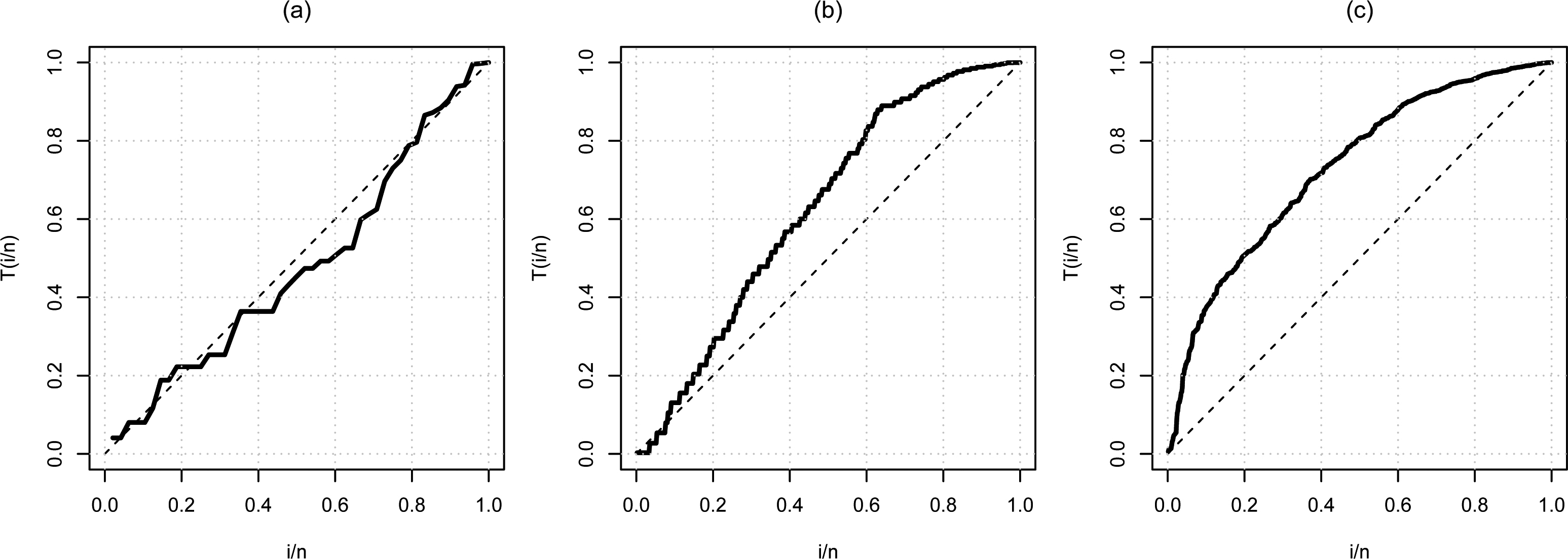
Before doing a modeling, a Total Time on Test (TTT) plot showed that the three data sets do not have constant risk function, one with decreasing risk function and the other two with increasing risk function (Fig. 1), suggesting that the Weibull distribution may be appropriate. The TTT concept was introduced by Barlow et al. (1972).
Convergence of the Gibbs sampling algorithm was observed from trace plots of the simulated Markov Chains (Fig. 9).
The uncensored data set is part from a more extensive data introduced by Krall et al. (1975) (here we only consider the uncensored data). The problem is to relate survival times for multiple myeloma patients to a number of prognostic variables. The survival times (given in months) consists of 48 observations and include measurements on each patient for five covariates:
For the statistical analysis of the data set, it is assumed a Weibull regression model with density Eq. (7) and regression model Eq. (10) for the scale parameter
for
From the results of Table 2 (a), it is concluded that only the predictor BUN associated with covariate logarithm of a blood urea nitrogen has significative effect on the lifetimes for the patients with multiple myeloma (significative at 5%, since
A visual form to verify the possible existence of cut-off points is from risk functions. The risk ratios of continuous covariates are presented in Fig. 2. Each estimate is presented with a 95% confidence interval, intervals below the dotted line suggest greater risks while the above suggest minor risks. In the chart (a) BUN values above 1.4 present higher risks and in graph (c) in the age ranging between 50 and 70 years there seems to be a risk change.
For a Bayesian analysis of the Weibull regression model Eq. (15) in presence of cut points for the continuous covariates, it is assumed a Weibull distribution in another parametrization with density (parametrization given in the Open Bugs software),
and regression model for the scale parameter
Descriptive statistics for the continuous covariate
Risk functions of covariates, (a) logarithm of a blood urea nitrogen (BUN); (b) Hemoglobin (Hb); (c) Age; (d) Serum calcium.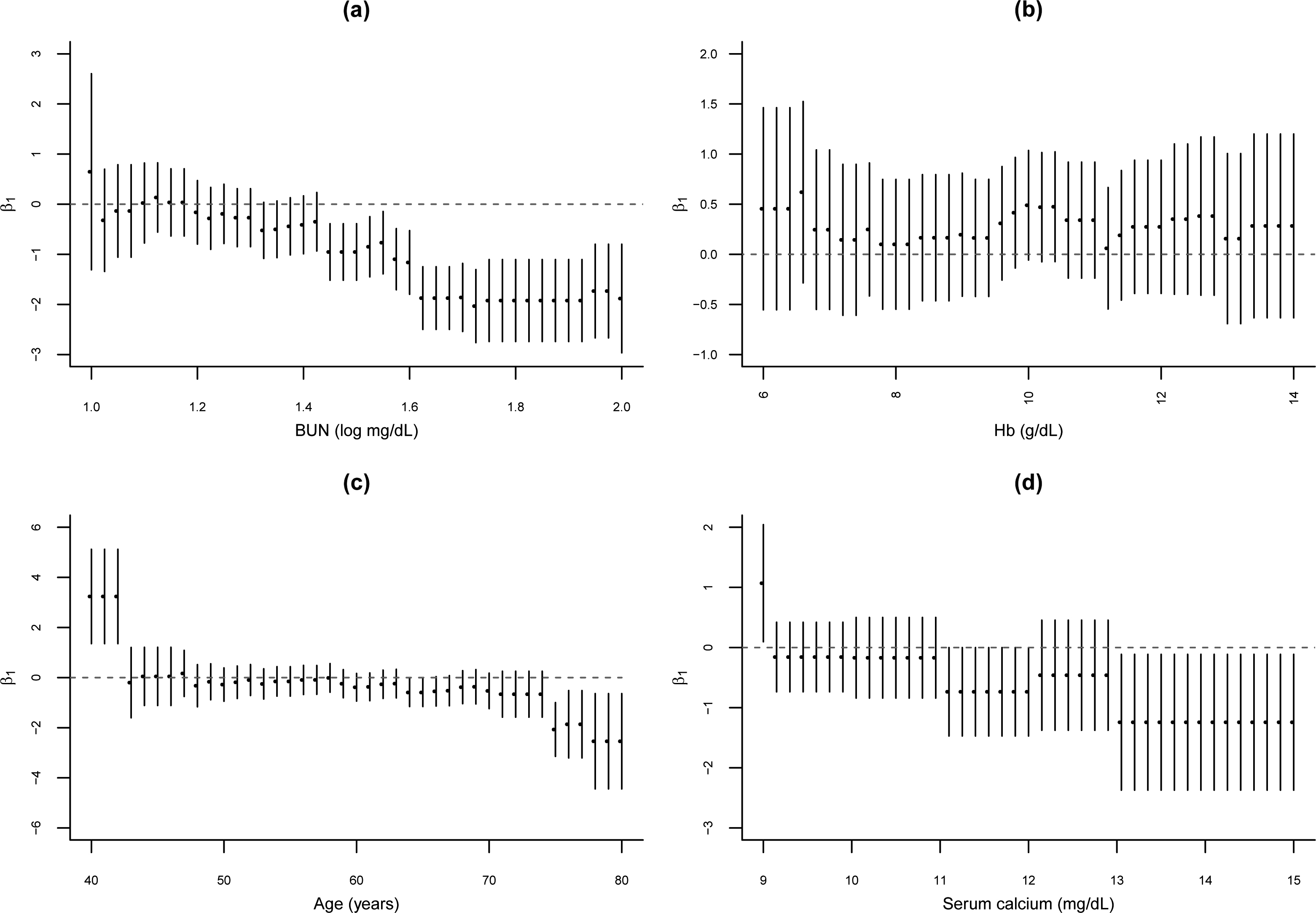
Observe that the covariate
MLE estimates for the parameters of the Weibull regression model (Krall data set)
Histograms for the simulated Gibbs samples of the cut points (Weibull regression model – Krall data set).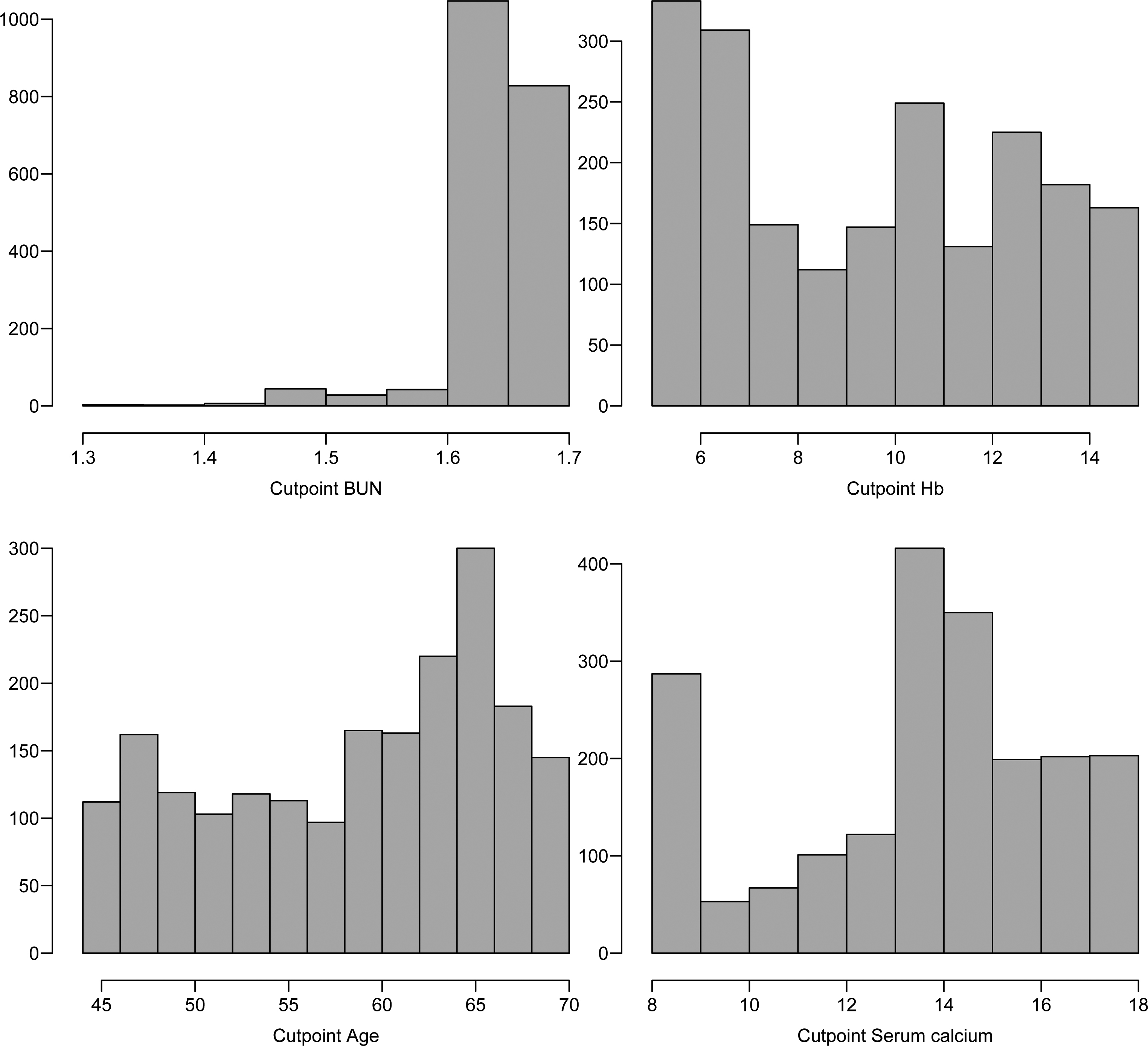
In Table 3, it is presented the posterior summaries of interest (Monte Carlo estimates for the posterior mean, posterior median, posterior standard deviation and 95% credible intervals for each parameter). From the results of Table 3, it is concluded that only the predictor BUN associated with covariate logarithm of a blood urea nitrogen has significative effect on the lifetimes (95% credibility intervals not including the value zero) for patients with multiple myeloma. The cut points for the continuous covariates are respectively estimated by 1.688 (blood urea), 9.484 (hemoglobin), 62.15 (age) and 13.72 (serum calcium).
In Fig. 3, it is presented the histograms of the simulated Gibbs samples for the cut points assuming a Weibull regression model.
From the graphs of Fig. 3, it is observed that the cut point 1 (
Based on the cut points given in Table 3, Kaplan-Meier survival curves are estimated for each dichotomized covariate.
From the graphs of Fig. 4, it is possible to observe that the covariate logarithm of a blood urea nitrogen measurement at diagnosis and serum calcium measurement at diagnosis have distinct groups at survival times.
Posterior summaries for the Weibull regression model considering the presence of cut points (Krall data set)
Plots of Kaplan-Meier estimates for dichotomized covariates, (a) logarithm of a blood urea nitrogen (BUN); (b) Hemoglobin (Hb); (c) Age; (d) Serum calcium.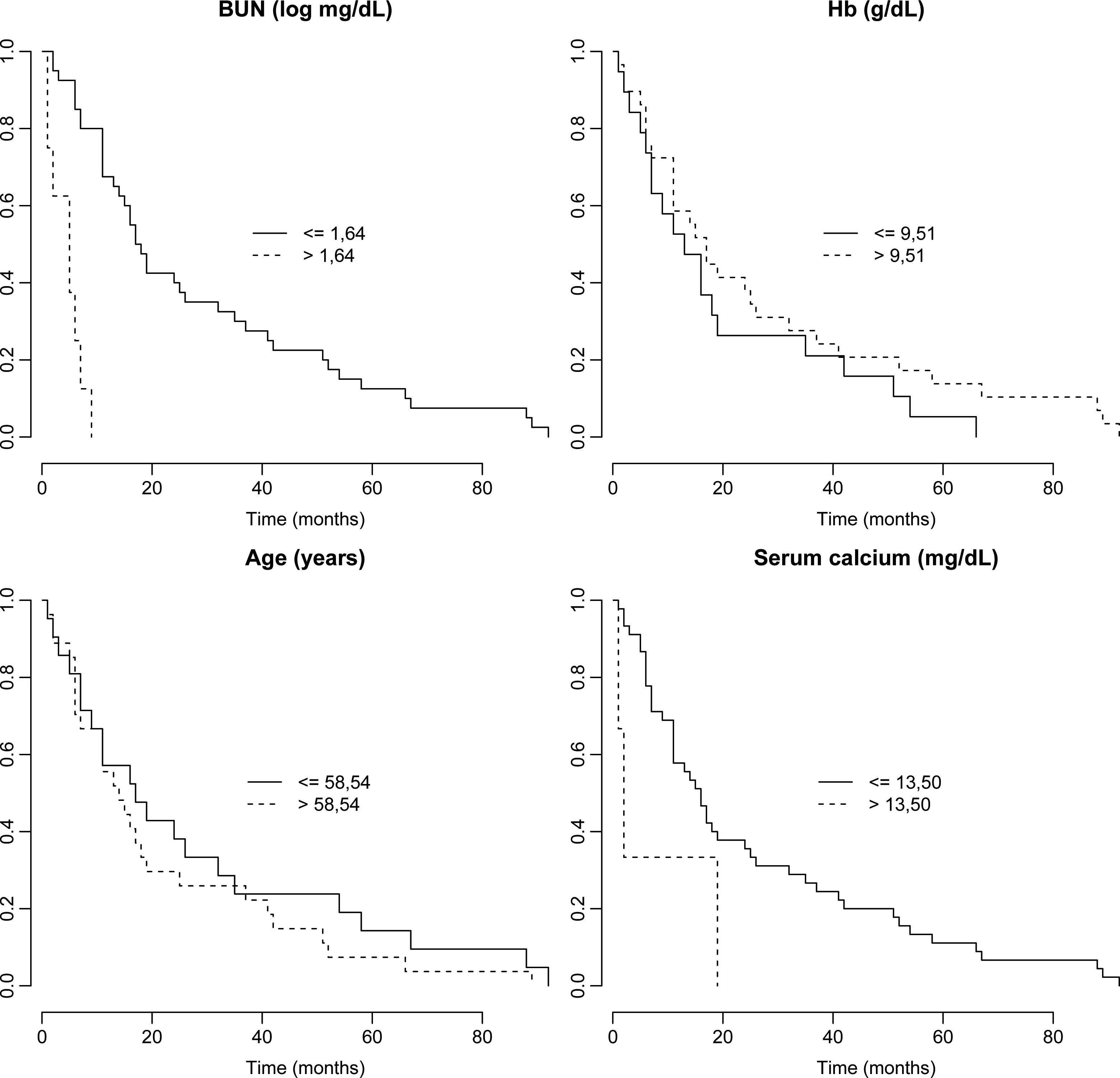
Assuming the dichotomized covariates, in Table 3 it is presented the maximum likelihood estimates (MLE) for the parameters of the model in Eq. (15). From the results of Table 2 (b), it is concluded that the predictor BUN has significative effect and Serum calcium also has a significative effect on the lifetimes for the patients with multiple myeloma (significative at 5%, since
MLE estimates for the parameters of the Weibull regression model (Greene and Byar data set)
Posterior summaries for the Weibull regression model in the presence of cut points (Greene and Byar data set)
Histograms for the simulated Gibbs samples of the cut points (Weibull regression model – Greene and Byar data set).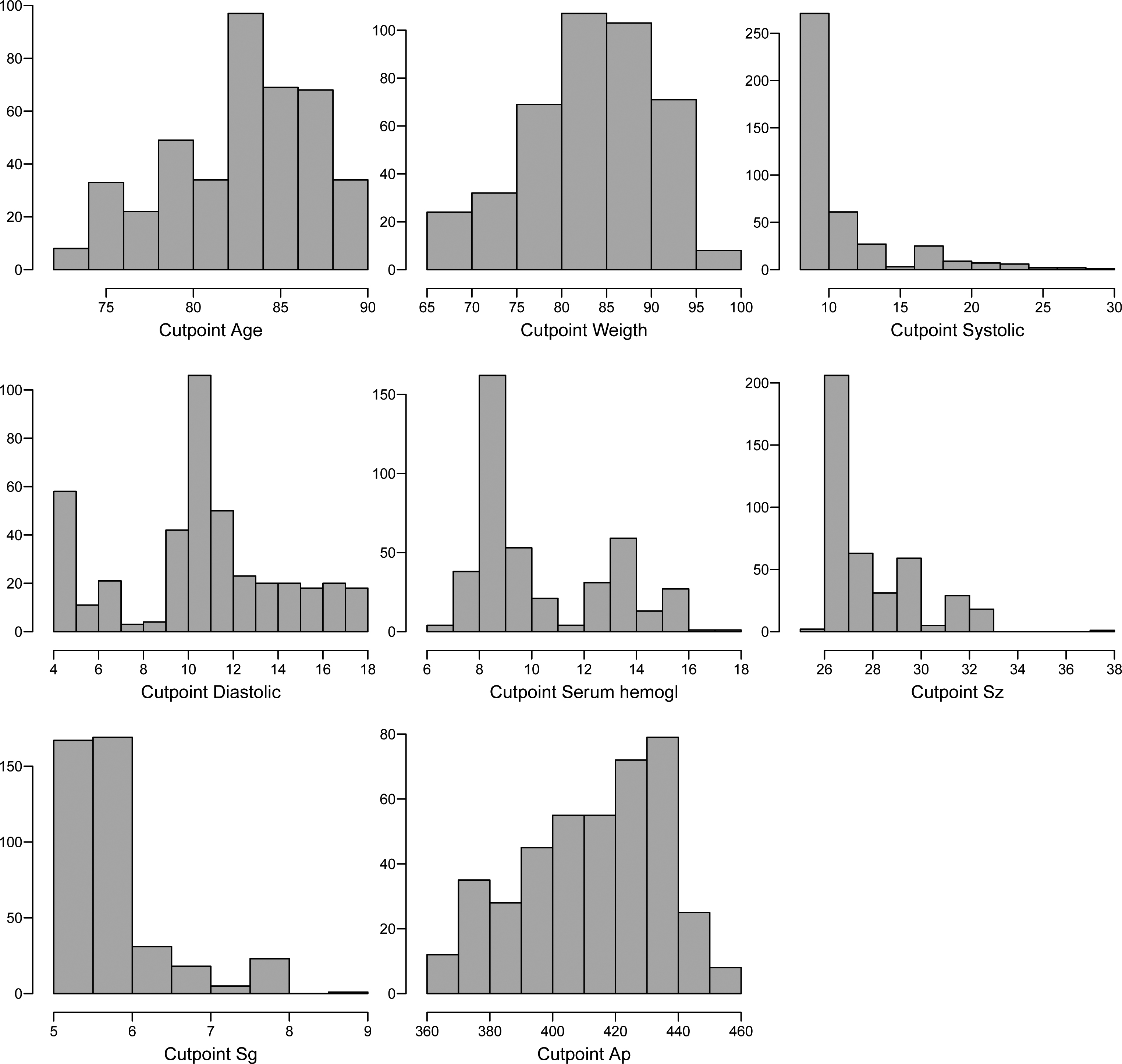
As a second application, let us consider the Greene and Byar (1980) prostate cancer data in presence of censored data, available in the Andrews and Herzberg (1985). The original data set consists of 502 observations and 18 variables. In our study it was deleted some missing data (it was considered a total of
Stage: Stage (3 or 4), Age: (in years), Weightindex: (wt (kg) Carddisease: Carddisease (0 or 1), Systolic: (systolic blood pressure/10), Diastolic: (diastolic blood pressure/10), Hemogl: Serum hemogl (mg/dL), sz: (size of primary tumor in cm sg: (combined index of stage and hist. grade) (5–15), ap: (serum prostatic acid phosphatase), bm: (bone metastases) (0 or 1), rx: (placebo
The censoring variable is given by status (1
Similarly to the first example, it is assumed a Weibull regression (see Eq. (15)) with
From the results of Table 4 (a), it is concluded that the covariates with significative effects on the lifetimes for patients with prostate cancer are:
Significative at 5% ( Significative at 10% (
MLE estimates for the parameters of the Weibull regression model (German breast cancer study data set)
Plots of Kaplan-Meier estimates for dichotomized covariates, (a) Age; (b) Weight; (c) Systolic blood pressure; (d) Diastolic blood pressure; (e) Serum prostatic acid phosphatase; (f) Size of primary tumor; (g) Combined index of stage and hist. grade; (h) Serum prostatic acid phosphatase.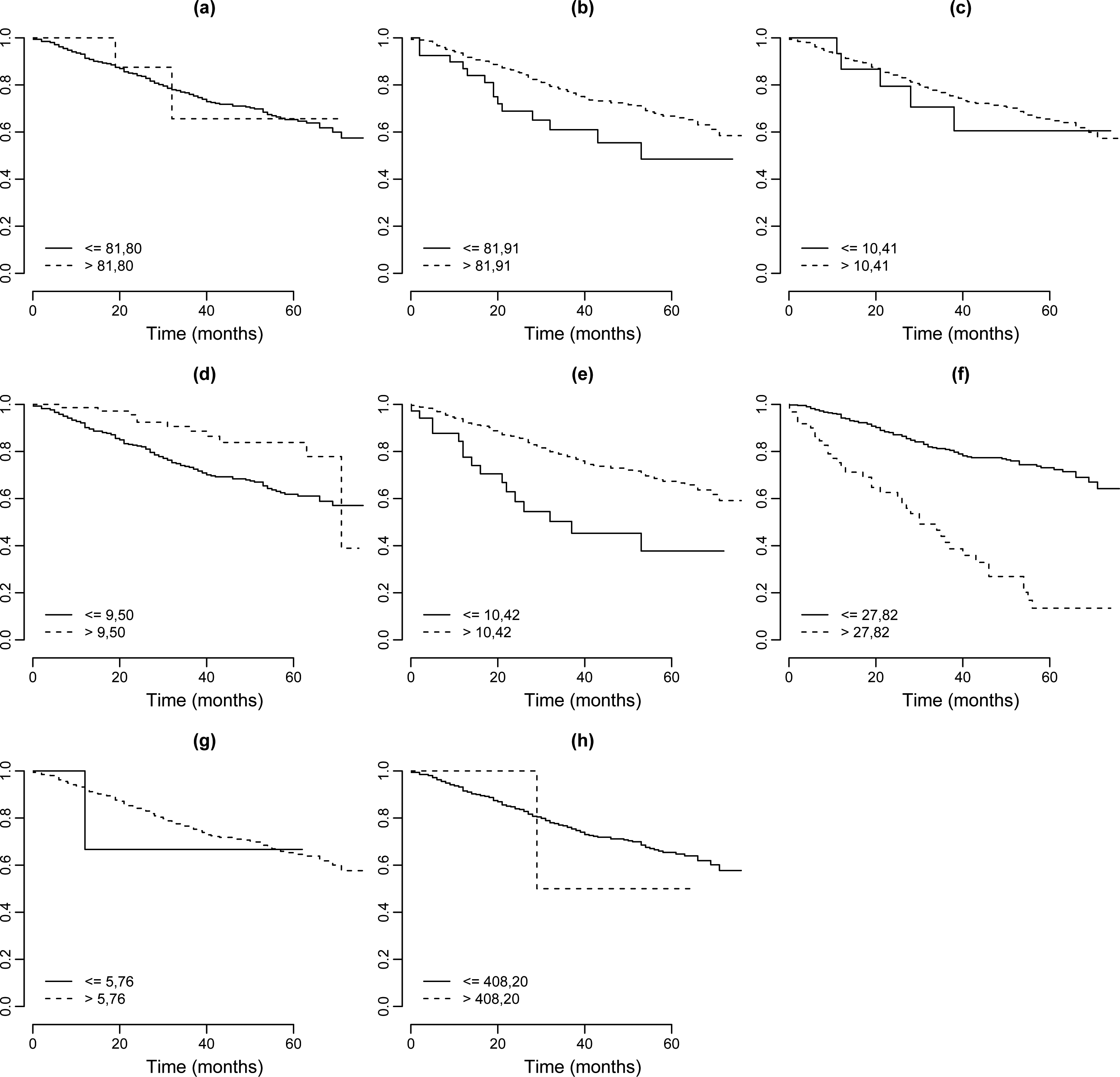
Posterior summaries for the Weibull regression model in the presence of cut points (German breast cancer data set)
Histograms for the simulated Gibbs samples of the cut points (Weibull regresssion model – German breast cancer data set).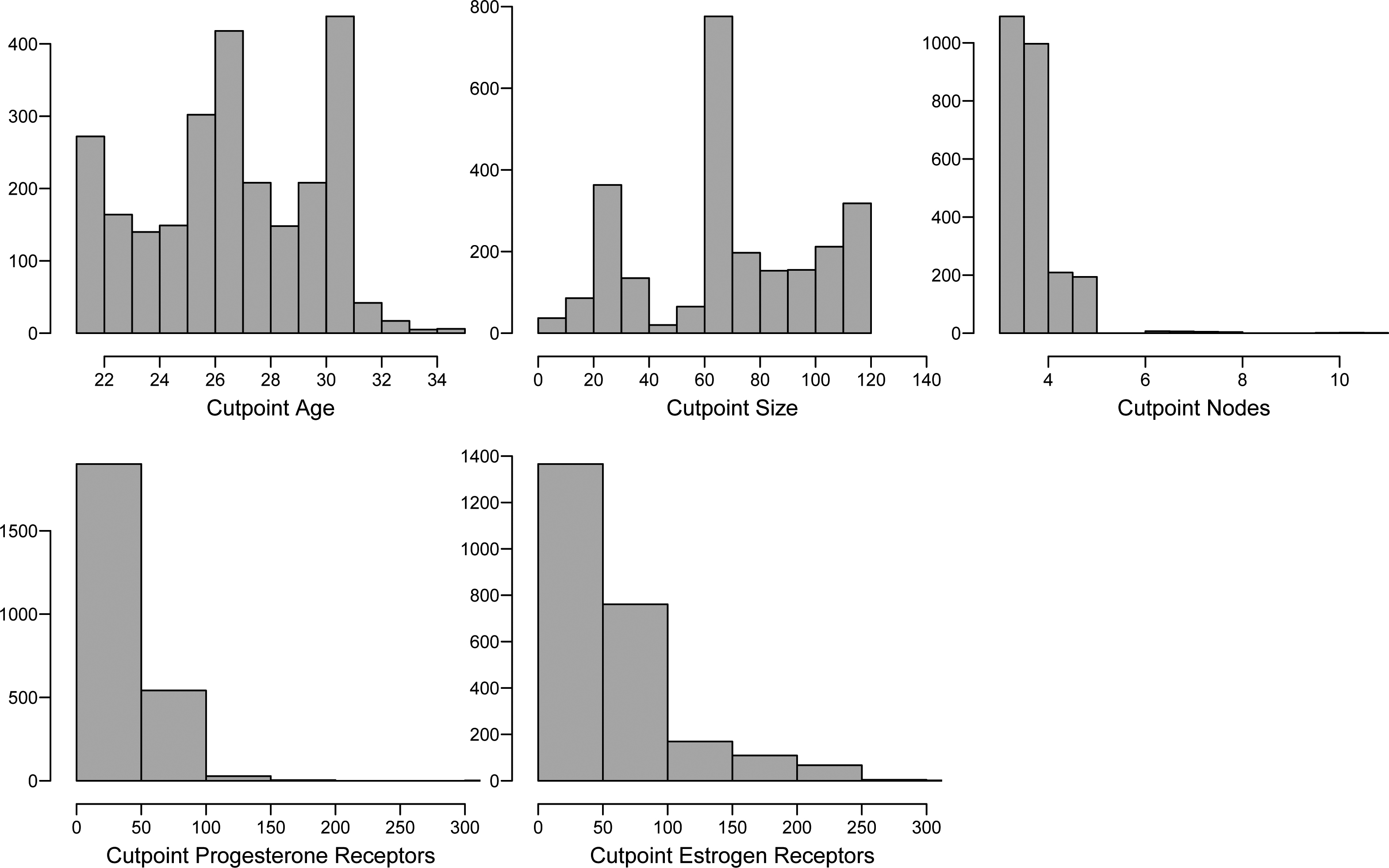
Plots of Kaplan-Meier estimates for dichotomized covariates, (a) Age; (b) Tumour size in mm; (c) Number of nodes; (d) Number of progesterone receptors; (e) Number of estrogen receptors.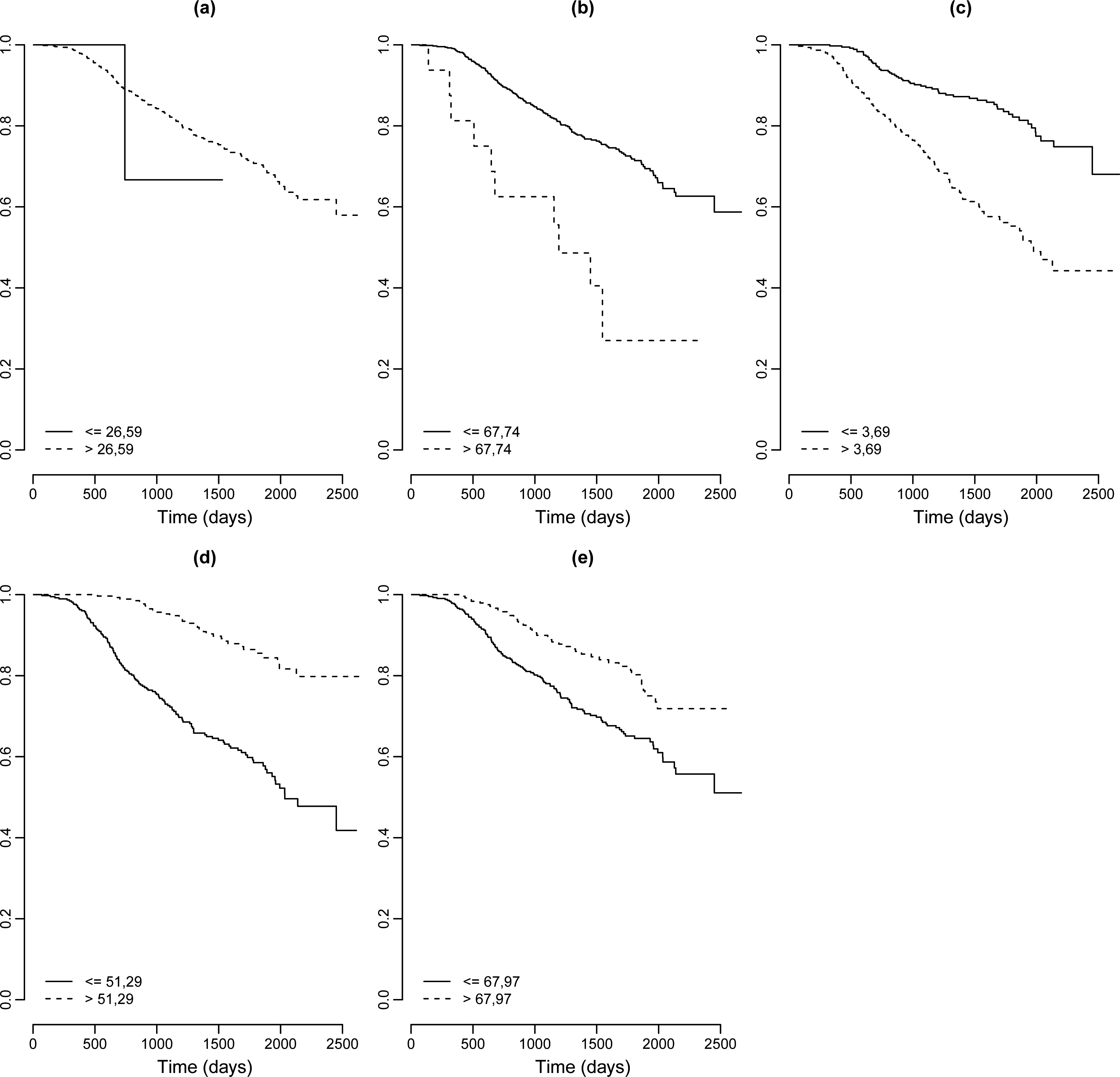
In the same way as considered in application 1 (see Eq. (16)), it is assumed the model in presence of cutpoints given by,
and the prior distributions:
Trace plots of the simulated Gibbs samples for each parameter (application 4.1 An application with a multiple myeloma uncensored data).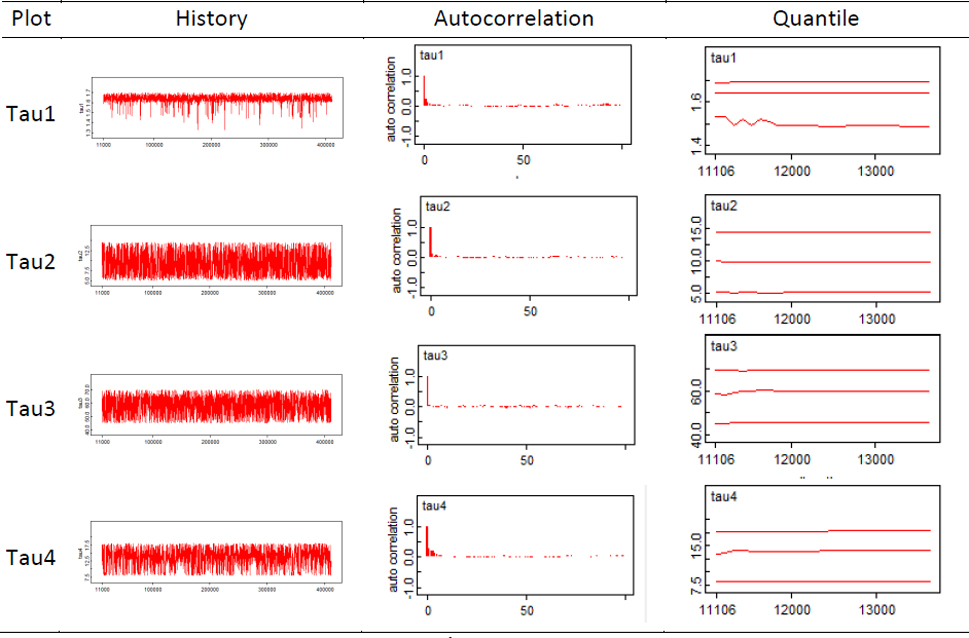
Also observe that the cut points
In Table 5, it is presented the posterior summaries of interest (Monte Carlo estimates for the posterior mean, posterior median, posterior standard deviation and 95% credibility intervals for each parameter).
From the results of Table 5, it is concluded that the binary covariates with significative effects on the lifetimes (95% credibility intervals not including the value zero) for patients with prostate cancer are: stage, serum hemogl, sz, sg, bm and rx. The cut points for the continuous covariates are respectively estimated by: 81.80 (age), 81.91 (weight index), 10.41 (systolic), 9.50 (diastolic), 10.42 (serum hem), 27.82 (sz) and 5.76 (sg).
In Fig. 5, it is presented the histograms of the simulated Gibbs samples for the cut points assuming a Weibull regression model. From the graphs of Fig. 5 it is observed that for some cut points as for example, cut points
Given the cut points for continuous covariates in Table 5, Kaplan-Meier survival curves are estimated for each covariate dichotomized. From the graphs of Fig. 6, it is possible to observe that the covariates weight, diastolic blood pressure, serum prostatic acid phosphatase and size of primary tumor have distinct groups at survival times.
Assuming the dichotomized covariates, Table 4 (b) presents the maximum likelihood estimates (MLE) for the parameters. From the results of Table 4 (b), it is concluded that the dichotomized covariates with significative effects on the lifetimes for patients with prostate cancer are:
Significative at 5% ( Significative at 10% (
In this example, it is considered a lifetime dataset related to the German Breast Cancer Study Data (gbcs.dat) consisting of 686 observations (dataset available in Hosmer et al., 2008). Also available at the Wiley’s FTP site:
In this study, it is only assumed the response survival times in days (0
Age in years (age at diagnosis); Menopause (1 Hormone (hormone therapy; 1 Size (tumour size in mm); Grade (tumour grade; 1,2,3); Nodes (number of nodes; 1 to 51); prog. recp (number of progesterone receptors; 1 to 2380); estrg. recp (number of estrogen receptors; 1 to 1144).
It is assumed as continuous covariates (in some cases the covariates are really not continuous) the variables age, size, nodes, prog.recp and estrg.recp. The dataset has 171 uncensored lifetimes (death from breast cancer) and 515 right censored values (alive or death from other causes).
Once again, the Weibull regression model Eq. (10) it is assumed for the scale parameter
From the results of Table 6 (a), it is concluded that the covariates with significative effects on the lifetimes for patients with breast cancer are:
Significative at 5% ( Significative at 10% (
With the same empirical Bayesian approach (use of descriptive summaries for the choice of priors for the cut points given in Table 1) used in example 4.2, the posterior means for the cut points are given in Table 7: age
In Fig. 7, it is presented the histograms of the simulated Gibbs samples for the cut points assuming a Weibull regression model. From the graphs of Fig. 7, it is observed that for the cut points associated to the covariates size, nodes, estr.recp and prog.recp there are very accurate Bayesian inferences. That is, the proposed approach, even in the presence of censored data is able to capture good estimates for the cut points of the continuous covariates, especially when these covariates have some significative effects on the lifetimes.
Based on the cut points given in Table 7, Kaplan-Meier survival curves are estimated for each dichotomized covariate.
From the graphs of Fig. 8, it is possible to observe that the covariates size, nodes, number of progesterone receptors and number of estrogen receptors have distinct groups at survival times.
From the results of Table 6 (b), it is concluded that the hormone therapy, tumour size, number of nodes and number of progesterone receptors has significative effect and tumour grade has no more a significative effect on the lifetimes for the patients with breast cancer (significative at 5%, since
The estimation of optimum cut points for covariates in lifetime regression models is of great interest under a medical view. Despite the loss of information when using a dichotomizing of an independent variable under a regression modeling approach, these cut points are very useful to better diagnosis in different medical situations. One of these applications is given when the medical doctors want to find cut points in covariates which affect the lifetimes of the patients. It is interesting to point out that the lifetime data could be, besides the common situation of lifetime until death, be associated to many other events of interest, as for example, the time of recovery following a medical treatment, the time of a recurrent event, the time of effect of a drug among many others.
The proposed methodology could be used to different lifetime distributions in the AFT model Eq. (3) assuming censored or uncensored data under a Bayesian approach and using MCMC simulation methods.
The computational simulation approach using MCMC methods is greatly simplified using existing simulation free available softwares like the Open Bugs software.
Footnotes
Conflict of interest
The authors declare that there is no conflict of interest.
Appendix A. Open Bugs code
Uncensored data (Krall Data set) model{ for(i in 1 : N) { time[i] ∼ dweib(r, mu[i]) mu[i] <- exp(beta0+beta1*step(x1[i]-tau1)+ beta2*step(x2[i]-tau2) + beta3*step(x3[i]-tau3)+ beta4*x4[i] + beta5*step(x5[i]-tau4)) } r ∼ dgamma(1,1) beta0 ∼ dnorm(1,0.1) beta1 ∼ dnorm(0,1) beta2 ∼ dnorm(0,1) beta3 ∼ dnorm(0,1) beta4 ∼ dnorm(0,1) beta5 ∼ dnorm(0,1) tau1 ∼ dunif(1.3,1.7) tau2 ∼ dunif(5,14.6) tau3 ∼ dunif(45,70) tau4 ∼ dunif(8,18) } A Graphical model for this model:
Grenne e Byar Data set model{ for(i in 1 : N) { dtime[i] ∼ dweib(r, mu[i])I(cen[i],) mu[i] <- exp(beta0+beta1*stage[i]+beta2*step(age[i]-tau1)+beta3* step(weightindex[i]-tau2)+beta4*carddisease[i]+beta5* step(systolic[i]-tau3)+beta6*step(diastolic[i]-tau4)+beta7* step(serum.hemogl[i]-tau5)+beta8*step(sz[i]-tau6)+beta9* step(sg[i]-tau7)+beta10*step(ap[i]-tau8)+beta11*bm[i]+beta12* rx[i]) } r ∼ dgamma(1,1) beta0 ∼ dnorm(5,0.1) beta1 ∼ dnorm(0,1) beta2 ∼ dnorm(0,1) beta3 ∼ dnorm(0,1) beta4 ∼ dnorm(0,1) beta5 ∼ dnorm(0,1) beta6 ∼ dnorm(0,1) beta7 ∼ dnorm(0,1) beta8 ∼ dnorm(0,1) beta9 ∼ dnorm(0,1) beta10 ∼ dnorm(0,1) beta11 ∼ dnorm(0,1) beta12 ∼ dnorm(0,1) tau1 ∼ dunif(48,89) tau2 ∼ dunif(69,152) tau3 ∼ dunif(8,30) tau4 ∼ dunif(4,18) tau5 ∼ dunif(5.9,18.2) tau6 ∼ dunif(0,69) tau7 ∼ dunif(5,15) tau8 ∼ dunif(0.1,999.9) } German breast cancer Data set model{ for(i in 1 : N) { time[i] ∼ dweib(r, mu[i])I(cen[i],) mu[i] <- exp(beta0+beta1*step(age[i]-tau.age)+beta2*menopause[i]+ beta3*hormone[i]+beta4*step(size[i]-tau.size)+beta5*grade[i]+ beta6*step(node[i]-tau.node)+beta7*step(progrecp[i]-tau.progrecp) +beta8*step(estrrecp[i]-tau.estrrecp)) } r ∼ dgamma(1,1) beta0 ∼ dnorm(8,0.1) beta1 ∼ dnorm(0,1) beta2 ∼ dnorm(0,1) beta3 ∼ dnorm(0,1) beta4 ∼ dnorm(0,1) beta5 ∼ dnorm(0,1) beta6 ∼ dnorm(0,1) beta7 ∼ dnorm(0,1) beta8 ∼ dnorm(0,1) tau.age ∼ dunif(21,80) tau.size ∼ dunif(3,120) tau.node ∼ dunif(1,51) tau.progrecp ∼ dunif(0,2380) tau.estrrecp ∼ dunif(0,1144) }