
Abstract
Increasingly, customers use social media and other Internet-based applications (e.g., review sites) to voice their opinions and to express their sentiments about brands. These reviews influence brand identity, either directly (by affecting consumer behavior) or indirectly (by generating positive or negative word-of-mouth through online social networks). We present an automated methodology that can be used to collect data from popular brand review sites and discussion boards. Customer feedback is then analyzed using best-practices of text mining and supervised sentiment analysis. Strategic implications of customer sentiments are discussed as we explore the role of sentiment analysis on modification of branding strategy.
Keywords
Introduction
The explosion of unstructured and qualitative customer data that is available from the Internet has created challenges and opportunities in the field of marketing analytics (Che et al., 2013; Labrecque, 2014). Increasingly, customers are using Social media and other Internet-based applications (e.g., review sites) to voice their opinions and express their sentiments about brands (Trainor et al., 2014). Past research suggests that such opinions and discussions influence brand performance either directly by impacting behavior and brand choice (Hinz et al., 2009), or indirectly by generating positive or negative word-of-mouth in social networks (Elsner et al., 2010; Yadav et al., 2013). It is evident from the extant research that such deep consumer insights have considerable strategic value for firms (Germann et al., 2013; Quan & Ren, 2016).
However, a majority of the tools that are being currently used by firms to obtain and analyze data from social media platforms, blogs, and discussion boards can be classified as social media channel reporting tools (Thiel et al., 2012). These tools are designed to collect and analyze data from consumer reviews across multiple sites. Generally, these dashboards report overall (reputation) metrics such as the average overall ratings, provide a trend analysis of the overall ratings across time, and identify platforms where positive or negative reviews are posted. The visual scorecards and dashboards that are produced, provide a good overview of channel performance. Managers can identify negative reviews and respond individually to consumer concerns raised in them. Thus, these tools can be used to make tactical adjustments at the product level.
Useful as these tools are, however, they are not designed for monitoring and managing brand identity. According to the Association of National advertisers, firms spent nearly $600 billion on branding in the U.S. in 2016. To differentiate a firm’s brands from those of its competitors, a brand identity is carefully created. The consistency of brand image, though, must be monitored and maintained to avoid consumer confusion about the brand identity. Subaru, for instance, strives to create consumer perception that every Subaru model is safe. The emphasis on safety as a consistent attribute means that potential buyers will pay close attention to the reviews and comments of Subaru owners, particularly those that relate to the characteristic (in this case, safety) seen as most important in deciding which car to buy. A dependence on social media reporting tools in this context will not yield helpful results. These tools are not designed to reveal customer sentiments identified by a single term (such as safety) or by a string of terms (such as blind spots). Since reporting tools are not useful in revealing which words or phrases in a review relate to a category such as safety, they do not help in active management of brands.
Over the last decade, sentiment analysis (SA) or opinion mining has been increasingly used to learn from online postings. SA uses the principles of natural language processing and affective computational techniques to determine attitudes towards a specific product, characteristic, or value (Quan & Ren, 2016). Given the abundance of data that is available on the web, manual evaluation of sentiments is not an option. Automation – both in collecting and in analyzing data – is the only practical means through which online reviews and posted opinions can yield truly helpful insights. These insights can then be used to make effective decisions (Ren & Quan, 2012). Decision-making using SA has been used in various fields that include finance, marketing, e-commerce, politics, law, and public policy making (D’Andrea et al., 2015). Given the benefits of SA, it is not surprising that there is considerable research attention on developing SA methodologies that are simple to implement, but provide key insights to decision-makers (Germann et al., 2013). Our paper expands the body of literature that has contributed to automated marketing analytics specifically designed to improve marketing decision-making related to branding (Feldman, 2016). While the general principles of SA are not new, our approach – specifically designed to help in brand management – has not been reported previously.
In this paper, we propose a methodology that can be used to collect consumer reviews from popular brand review sites and discussion boards to help marketers monitor and manage brand identity. These reviews are then analyzed by using the best-practices of text mining to reveal customer sentiments at the attribute level of each brand. Sentiment analysis is performed by identifying consumer sentiment that relate to determinant brand attributes and by considering the valence (positive or negative) of these customer sentiments. Thus, our paper is designed to help brand managers understand the specific strengths and weaknesses of a brand based on a thorough analysis of consumer sentiments. Managers can then modify existing products and/or advertising strategies to either exploit strengths or counteract weaknesses in brand perceptions. In summary, our methodology allows managers to adjust branding strategies based on a continual assessment of consumer sentiments.
The next five sections discusses each step of our methodology. Since the input to a SA system is a corpus of documents from the web, a brand review site is selected in the first step. Following that, we discuss text preparation, sentiment detection, and sentiment classification, as suggested by D’Andrea et al. (2015). The steps that are involved, appear in Fig. 1. Since the primary objective is of SA is to convert unstructured text into meaningful information, the strategic implication of the results are discussed. We conclude by outlining some research limitations and possible research extensions.
Sentiment analysis methodology.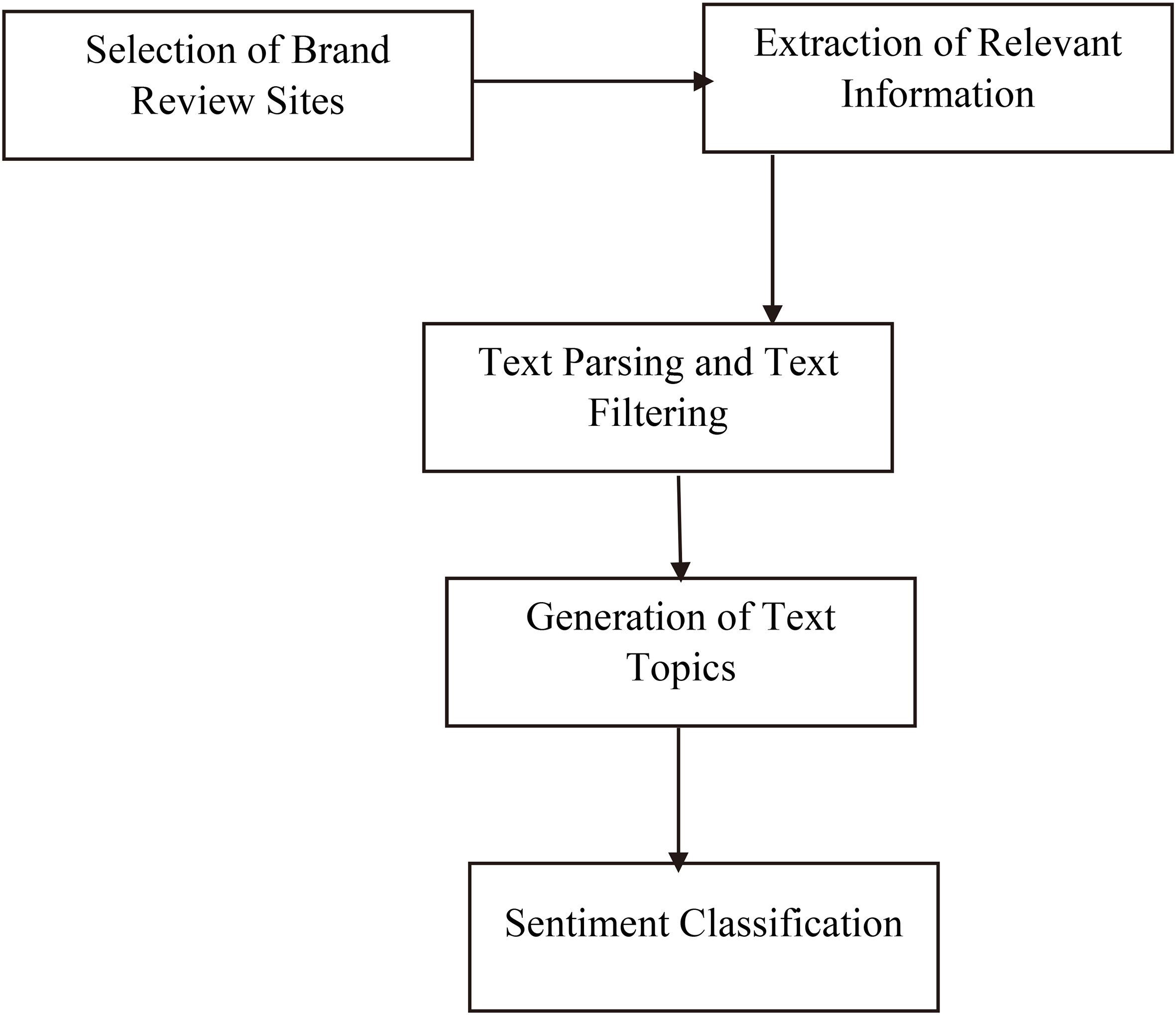
In this paper, we decided to focus on popular review sites where consumers express post-purchase brand sentiments. These brand reviews are likely to influence future brand choice by generating positive or negative word-of-mouth in social networks (Kuznetsov, 2009). Edmunds.com website was selected for two reasons. First, buyers of new cars post textual reviews in this website after they have had a chance to use the car for some length of time. Therefore, consumer reviews are likely to reflect sentiments based on their post-purchase brands experiences. Such descriptive reviews are widely read by consumers considering purchase of a new car and are likely to influence which brand these consumers eventually buy (Hinz et al., 2011). Furthermore, brand reviews on such sites also influence brand sentiments shared through social networks (Elsner et al., 2010). Second, in addition to posting textual review, reviewers have to numerically rate cars on several key attributes. These attributes are comfort, quality of technology, safety, interior quality, and performance. These numeric attribute ratings are used in this paper to determine the valence or the positive or negative nature of the consumer sentiments using the principles of supervised sentiment classification system.
Information extraction process
The next step was to extract data from Edmunds.com website. This site can be accessed through five different application program interfaces (APIs) to facilitate queries and dynamic data retrieval. We designed a tool based on Python code that can collect data for a specific brand of car from the website and then return the data in a JavaScript Object Notation (JSON) format. The tool also iterates through all the models that are available for a certain brand of car within a certain time period.
The tool was then used to access the Dealers API of Edmunds.com website and we extracted textual reviews along with numerical ratings for car models released from 2012 till 2017 for four brands – Chevrolet, Honda, Subaru, and Toyota. Since the research purpose was to investigate sentiments at the brand level (e.g., Toyota) and not at the model level (e.g., Corolla), data on each model within a certain brand was ignored. All user reviews posted for the four brands were downloaded in November 2016. A total of 2,176 reviews were extracted that included 696 reviews of Chevrolet, 429 reviews of Honda, 257 reviews of Subaru, and 794 reviews of Toyota. Finally, the JSON string was converted to excel data and the excel file was imported to SAS Enterprise Miner for further analysis.
Text parsing and text filtering
Text parsing begins by tokenization which is a process of breaking down sentences to tokens such as a word, a number, or a punctuation mark (Dale et al., 2000). In this paper, text parsing was used to break up sentences that appeared in the textual reviews to terms that relate to the attributes of cars. Terms could be a single word or a string of words such as a noun phrase. The text parsing and filtering node of SAS Text Miner was used for this purpose. The objective was to retain terms that specifically related to the attributes of a car and to eliminate articles and connectors that may have a high frequency but do not actually describe any particular feature of the car (Manning & Schutze, 1999). Thus, a list of stop words were used to exclude specific term from the analysis as suggested by Montemurro (2001). The stop list also included the names of different car models, so that brand sentiments could be analyzed at the level of brands and not at the model level. A custom dictionary was also used to detect synonyms, correct spellings, and to detect multi-word terms. Multi-word terms, such as ‘fuel economy’, ‘blind spots’, and ‘oil leak’, were identified using the principles of context-specific N-grams. To suit to our analysis goals, we ignored parts of speech ‘Abbr’, ‘Aux’, ‘Conj’, ‘Det’, ‘Interj’, ‘Num’, ‘Part’, ‘Pref’, ‘Prep’, ‘Pron’, ‘Prop’. Entities ‘Address’, ‘Currency’, ‘Date’, ‘Location’, ‘Measure’, ‘Percent’, ‘Phone’, ‘Timeperiod’ and attributes ‘Punct’, ‘Mixed’, ‘Num’ were also not considered in the analysis. Ignoring some parts of speech, entities, and attributes is a simplification strategy which is necessary to generate meaningful insights from unstructured data and is consistent with current best-practices in the industry (Chakraborty et al., 2013).
In textual analysis, one of the essential objectives is to differentiate documents so that they can be meaningfully classified into groups that reflect text topics. Past research in the field of information retrieval suggests that term frequencies, or the number of times terms appears in a document collection, are generally not considered to be good discriminators (Chakraborty et al., 2013). Since the terms with the largest frequency of occurrence do not relate to car attributes, they are unlikely to help us analyze attribute-based customer sentiments. Inverse document frequency (IDF) was used as term weight as suggested by Salton and Buckley (1988). IDF calculates term weight as the inverse of the frequency of occurrence of a term across all documents. A log transformation was then used to stabilize the variability across frequencies. In essence, terms with higher frequencies were considered to be less important discriminators while terms with lower frequency were considered to be more important. However, we noticed that terms with very low frequency were also not likely to add any value to our analysis. Thus, unless a term appeared in at least four documents, it was excluded from the analysis.
Generation of text topics
The next step was to create text topics. The objective in this step was to group the primary terms in a manner that reflected sentiments related to the specific attributes that are the focus of study in this paper. The attributes under consideration were comfort, quality of technology, safety, interior quality, and performance primarily because numerical ratings were available for these factors. It was determined that a completely automated system for generation of text topics would not be desirable for several reasons. First, an examination of the terms (generated in the last step) revealed that several terms were related to issues such as price and good value. While price and value are important attributes, there are no numerical ratings for these in the Edmunds.com site. Thus, they are not the focus of the study in this paper. Second, a single core term such as “seat” could be classified under multiple attributes depending on the context or the other terms that were associated to it. A heated seat, the material with which it was made, or the contour of the seat could contribute to comfort perceptions. The same term could also influence consumer sentiments about how good the interior looked.
Due to these issues, we used a lexicon-based approach as suggested by D’Andrea et al. (2015). Five custom topics that reflected the five attributes under consideration, were created in SAS Enterprise Miner. These five topics were investigated to identify terms that could be classified under each text topic. Five hundred and ninety-three terms were identified based on our examination of auto magazines and review sites. Out of these, 213 terms were related to performance, 123 terms to comfort, 102 terms to safety, 71 terms to quality of technology, and 84 terms to interior quality. As mentioned before, a certain term could relate to multiple text topics. These terms were comprised of single words or a string of words.
These terms were specified as inputs to the topic selection node of SAS Enterprise Miner. The algorithm used the input list of terms and the concept maps (or the association across terms) to determine whether a certain sections of the review reflected sentiments about a specific text topic. A single review could express sentiments about multiple text topics. For instance, a review might be positive about the performance of a car but might express apprehension about the technological features of the same car. However, a review that has none of the user input terms, would not be evaluated.
Text topic selection
Text topic selection
The results of text topic generation appear in Table 1. The top three issues or terms that are associated with each text topic also appears in this table. Terms related to performance seem to be the most dominant in textual reviews followed by terms related to comfort. In many cases, multiple performance related sentiments are expressed in a single review. In contrast, safety related sentiments are the least likely to appear in reviews. It is noteworthy that “seats” contribute to perceptions related to comfort and to interior, while “camera” influences views about safety as well as about technology.
The final step was to determine the polarity or valence of the sentiments expressed in the reviews. Document level analysis (where the entire document can be classified as a positive or negative sentiment) is not recommended since consumers could express multiple sentiments related to multiple text topics in a single review. Some of these sentiments could be positive while others could be negative. Each of these sentiments could provide useful information for brand managers. In such situations, attribute-based or aspect-based SA is recommended (Feldman, 2013). Therefore, SA was performed at the level of a brand (or object) as well as at the level of an attribute (or text topic.) Thus, our methodology is versatile and allows consumers, for instance, to express positive sentiment about the performance of a certain brand of car but indicate apprehension regarding its safety features.
In this paper, a supervised sentiment classification system is used. The numeric ratings of the five attributes that were collected from the Edmunds.com website, were used to determine the valence of the sentiments in accordance to the procedure suggested by Chakraborty et al. (2013). If a certain text topic was detected in the textual review for a certain consumer, a numeric rating of four or five (on a five point rating scale) for the same attribute would indicate a positive sentiment. However, a rating of three or below would indicate a negative sentiment. Past research has shown that this naïve Bayes classification system works well for supervised classification tasks (Pang & Lee, 2008). In order to complete the classification task, we used the median to impute attribute ratings for observations that had missing values. The supervised sentiment analysis was performed on all the 2,156 textual reviews.
Exhibit 1 shows the results of sentiment analysis for a consumer with a mixed review. The transmission-related problems, coupled with a negative rating for performance, leads to a negative performance sentiment. The textual review also expresses concern related to technological aspects such as Bluetooth, touch screen, and voice and results in a negative assessment of technology. However, “plenty of seats” results in a positive sentiment about the interior of the car.
I need this car for haul my growing family around. I knew the good and bad before purchasing and for a while I loved it because it is very functional. Until the transmission (6-speed) gave temperature warning in the middle of a camping trip. I will be taking it in soon to get it checked out. The goods: plenty of seats, MPG is awesome compare to other vehicle in class and all the technology is good even for an EX model. The bads: infotainment screen is useless in direct sunlight, touch screen is very hard to use while the car is moving, armrest is uncomfortable, Bluetooth takes SIX buttons push to change connected phone, voice command is none functional, very hard to jump start because engine cover and placement of the battery. Mother of all problems, the transmission overheats!!!
Performance (Term
Negative numerical rating Technology (Term
Negative numerical rating Interior (Terms
Positive numerical rating
In this paper, we propose a methodology that it consistent with best-practices in text mining and analysis. It is used to evaluate post-purchase brand sentiments since past literature suggests that these sentiments greatly influence consumer purchase decisions. Our paper provides valuable insights for both managers and analysts that we now discuss.
Percentage of positive sentiments across corpus of documents
Percentage of positive sentiments across corpus of documents
s
A comparison of the proportion of times each text topic was mentioned appears in Table 2. Performance-related sentiments are the most prevalent in reviews and occurred in over 39% of the documents. In contrast, safety related issues appeared in just over 10% of the documents. These results suggest that consumers tend to discuss topics that they are more likely to observe through user experience. Consumers can feel the acceleration and the smoothness of transmission. They can observe the economic benefit of gas mileage. In contrast, the effectiveness of safety features are less likely to be observed – probably only in cases where there was an accident or where an accident was averted. Thus, while people might buy different brands for different reasons, they are more likely to talk about the more observable attributes. Brand managers would benefit by informing users about the distinctive performance feature of their brand through social media and through television advertising. It is conceivable that different brands might focus on different aspects of performance. Honda might focus on excellent gas mileage, for instance, while Chevrolet might stress quick acceleration.
Brand management using text mining relies on uncovering the competitive advantages of a focal brand on the basis on consumer sentiments (Netzer et al., 2012). Unfortunately, comparative sentiment analysis cannot be performed since consumers express their sentiments primarily about one brand in most product review sites. These reviews lack comparable opinions such as “I drove brand x. It has a much better gas mileage than brand y.” However, our methodology provides valuable insights to brand managers by revealing competitive advantages of each brand. Marketers can determine the strengths and weaknesses of brands by comparing the sentiments across brands on key attributes.
To illustrate this capability, we use the Subaru brand as an example. The percentage of positive attribute-level sentiments appear in Table 2. Subaru’s strength seems to be that 95% of the sentiments related to safety are positive and is higher compared to other competitive brands. However, consumer sentiments about the quality of technology (50%), interior quality (57%), and performance (61%) are considerably lower compared to the other brands. Thus, while safety is a strength, the other attributes are weaknesses of Subaru. Its brand positioning is likely to appeal to prospective buyers who are motivated primarily by safety. However, buyers who also care about some of the other features may not be as excited about Subarus. Even buyers who care about safety might be turned off by some of its weaknesses on technology, interior quality, and performance. Brand managers could use these insight to modify existing models and/or introduce new models to improve the brand position of Subaru.
This paper proposes a methodology to enable the collection of textual data posted on brand review sites and discussion boards. The Dealer API of Edmunds.com was accessed by using a JSON package in Python and 2176 textual reviews were collected for four major brands. Reviewers on the site were also required to submit five-point numerical ratings of five auto attributes and of overall preference, and this data was collected as well. We purposely collected data on post-purchase reviews since these are read by consumers who are planning to buy a car and are interested in learning about the actual experience of users.
The data was imported to SAS Enterprise Miner for further analysis. Terms that specifically related to the five attributes were retained. A custom user-defined text topic generation node was used to identify terms that related to each of the five attributes. Finally, a supervised sentiment analysis methodology that utilized numerical ratings on the five attributes was used to determine the valence or polarity of the sentiments.
Several key insights were uncovered in this paper. Results from the auto marketplace suggest that consumer reviews are likely to focus on more observable attributes and “feel good” attributes such as performance. Safety-related concerns are least likely to be discussed. The percentage of positive sentiments across product attributes and brand can also help marketers understand the strengths and weaknesses of brands. In summary, our methodology allows brand managers to actively manage brands based on a thorough understanding of the brand sentiments.
This paper focuses on five attributes only since numerical evaluations were available for these on the Edmunds.com site. Future research could focus on expanding this list. Text topics could be expanded by including factors such as price, value, and predicted reliability. Also, in order to demonstrate the true benefits of sentiment analysis that can be used to assess brand identity, data should be collected across multiple brand review platforms and then analyzed. However, most review sites do not collect numerical ratings on brand attributes. This paper utilizes supervised sentiment analysis. Addressing both issues would require the use of unsupervised sentiment analysis to determine the valence of customer perceptions. These methods use sentiment lexicons to determine the polarity of sentiments (Wiebe et al., 2005). The list of brands and product categories should be expanded to determine whether the insights can be generalized. Currently, we are collecting data from four other brands to improve the generalizability of the study results. Sentiment analysis is a topic of increasing importance to marketers. Although this paper is a modest attempt to investigate consumer sentiments, we hope that it will lead to more discussion and research in this vital area of marketing.