
Abstract
Cross-validation (CV) and direct plug-in (DPI) are two commonly used bandwidth selection methods in nonparametric estimation. In this paper, we compare the performance of CV and DPI methods in local polynomial kernel regression through simulation study. We consider continuous response and binary response cases, with local constant, local linear and local quadratic kernel estimators, respectively. Furthermore, we investigate the first derivatives of local quadratic kernel estimators. Our results show that CV and DPI methods excel in different cases, in terms of minimizing the Mean Integrated Squared Errors (MISE); the results are also verified in empirical studies.
Keywords
Introduction
Local polynomial kernel regression is a widely used nonparametric smoothing approach, by which the pointwise estimation of the curve only depends on observations in a neighborhood of a to-be-determined radius (e.g., Woolhouse, 1870; Stone, 1977; Loader, 1996; Cleveland & Loader, 1996). There is a vast literature on choosing the radius, also known as the bandwidth selection problem. For example, the literature on local polynomial regression, where the pointwise estimate is given by a polynomial of a fixed and given order, has much discussion on bandwidth selection criteria, order of local polynomials, comparison among different selection methods, small and large sample properties of the estimators.
Essentially, the bandwidth acts as a smoothing parameter, balancing the bias-variance trade-off. Under a small bandwidth, the fitting curve is relatively volatile but follows the observations closely; under a large bandwidth, the fitting curve is relatively smooth, while the estimation bias is relatively large. An estimator will perform poorly with respect to the bandwidth near the boundaries of the data if a kernel density estimation is employed, particularly when the underlying density has long tails (Zambom & Dias, 2012). On the other hand, the specification of the local polynomials contributes to the curve estimation through the order of polynomial (Xia & Li, 2002; Li & Racine, 2007). Xia and Li (2002) stated that higher-order polynomial produces robust estimates for the optimal bandwidth, but only in a large sample; Li and Racine (2007) also mentioned that by using higher-order polynomial fitting, the estimation bias is reduced without any increase in the Mean Squared Error (MSE). Altogether, the selection of the bandwidth and the polynomial orders form a crucial part of the specification for a local polynomial kernel regression problem, and a nonparametric approach can be very powerful for estimating the mean functions and its derivatives (Fan & Gijbels, 1995).
In the context of bandwidth selection methods, a common optimization objective is Mean Integrated Squared Errors (MISE) where the minimizer is the theoretical optimal bandwidth (e.g., Fan & Gijbels, 1992; Li & Racine, 2007; Ruppert et al., 1995; Xia & Li, 2002). We can estimate MISE by replacing the unknown integrals in the expression of the MISE-minimizer with the estimators, which is the basic idea of a plug-in method (Li & Racine, 2007; Ruppert et al., 1995), or by utilizing a cross-validation (CV) method (Bowman, 1984; Li & Racine, 2007; Rudemo, 1982). The CV method provides a fully-automatic data-driven approach, while the performance of plug-in methods heavily depends on the pilot bandwidth specification. Further, the CV method reacts to the uncertainty of bandwidth selection by under-smoothing, while plug-in methods react by over-smoothing (Loader, 1999). The CV-selected bandwidth’s tendency to under-smooth can cause a downward bias and a lack of robustness in the estimators of derivatives (Newell & Einbeck, 2007). On the other hand, the plug-in method can asymptotically result in inefficient estimates due to its difficulties in efficiently using curvature information (Loader, 1999).
There are different types of plug-in bandwidth estimators, including the rule of thumb (ROT), direct plug-in (DPI) and solve the equation (STE); one of these “plug-in” bandwidth estimators, the DPI estimator, outperforms the others in the majority of cases in terms of converging to the MISE-optimal bandwidth (Ruppert et al., 1995). Wand and Jones (1994) discussed the performance of MISE- and DPI-bandwidth estimators for the density estimation. However, there has not been much discussion directly on the comparison between the two bandwidth selection approaches for local polynomial kernel regression in the literature. Hence, in this article, we compare the performance of CV and DPI methods for local polynomial kernel regression in both continuous response and binary response cases through both simulation and empirical studies.
When the response is continuous, not only can we do analysis and inference on the level functions but also on its derivatives for local polynomial kernel estimators of sufficient order. Fan and Gijbels (1996) suggested that assuming existence, to estimate the
Finally, Song et al., (2006) proposed to apply the function dpill() in R package to obtain the bandwidth for the local quadratic estimator and the first derivative of the function. As we have known, dpill() is only suitable to the local linear estimator. Therefore, based on this motivation, we also investigate the bandwidth selection methods for the first-order derivative. In essence, we estimate the first order derivatives using local quadratic kernel estimators. Our results show that CV and DPI methods selection methods excel in different cases; the results are also verified in empirical studies. Specifically, we find that results generated from the binary response case are not consistent with the results from the continuous response case. Furthermore, DPI is consistently better at identifying local maxima by estimating the first derivatives in a local quadratic kernel setting.
The remainder of this article is structured as follows: in Section 2, we will briefly introduce the bandwidth selection and estimation procedures of local polynomial kernel estimators for classic and generalized linear models. Section 3 presents the simulation study with the first three orders of the local polynomial case by case. We present the analysis of three different real data in Section 4. Finally, we will discuss and conclude our findings in Section 5.
Estimation procedure
In this section, we will briefly review local polynomial kernel estimation and bandwidth selection for a continuous response, of which the details are presented in Fan and Gijbels (1996). Afterward, we introduce the corresponding extension to a binary response case.
First, note that there are two unknowns in local polynomial kernel estimation – the bandwidth
Continuous response
Consider a model specified as follows:
where
Defining
As mentioned earlier, we will show the estimations of
With the orders of polynomials determined, we now consider the bandwidth selection. The idea behind the CV method is to optimize the out of sample performance of the estimator by minimizing the leave-one-out sum of squared error (SSE). Specifically, to obtain the leave-one-out SSE with a given bandwidth
where
In the numerical studies, we mainly use our code to illustrate the numerical results on bandwidth selection.
For the DPI method, the unknown integrals in the expression of the analytical MISE-minimizer are replaced with their local linear kernel estimators with the Gaussian kernel. The initial estimate is determined by the least squares quartic fits over neighborhoods of data, where the number of blocks is selected by Mallow’s
Note that “dpill()”, as mentioned earlier, replaces the unknown terms in the analytical MISE-minimizer with local linear kernel estimators. Nonetheless, we apply “dpill()” to not only the linear case
Consider the MISE criterion as follows:
where (Wand & Jones, 1994)
and
with
From Eqs (2.1) and (10), we can conclude that a pairwise comparison between two estimators with the same order of polynomial and the same kernel is equivalent to the comparison between their bandwidth. For example,
In this section, we extend the Gaussian setting to the generalized linear model. Similar to the discussion in Section 3.1, we mainly develop the R code to derive the bandwidth estimator based on the CV method and examine the use of dpill() in R package based on DPI method.
Consider a set of observations,
The latent function
where
Thus, for
For bandwidth selection, the CV score in the binary response case can be defined as a sum of negative log-likelihodd functions, such that
where
In this section, we present a simulation study, showing the performance of the estimators for 1) the level function of a continuous response; 2) the level function of a binary response; 3) the first order derivative of a continuous response.
Estimating the level function of a continuous response
Consider the model of the form in Eq. (1), where
Monotone increasing function: Periodic function: General function:
Considering different distributions of the random error to see the robustness of the estimators and the comparison results, let
Bandwidth under three different situations for continuous response,
MISE of different bandwidths,
Table 1 presents the average levels of the bandwidth from the 1000 sets of simulated data, selected using either CV or DPI methods with
Setting (a) with 
First, we interpret results for case (a) under
By the analysis in Section 2.1, we can intuitively conclude that pointwise bias of
Setting (b) with 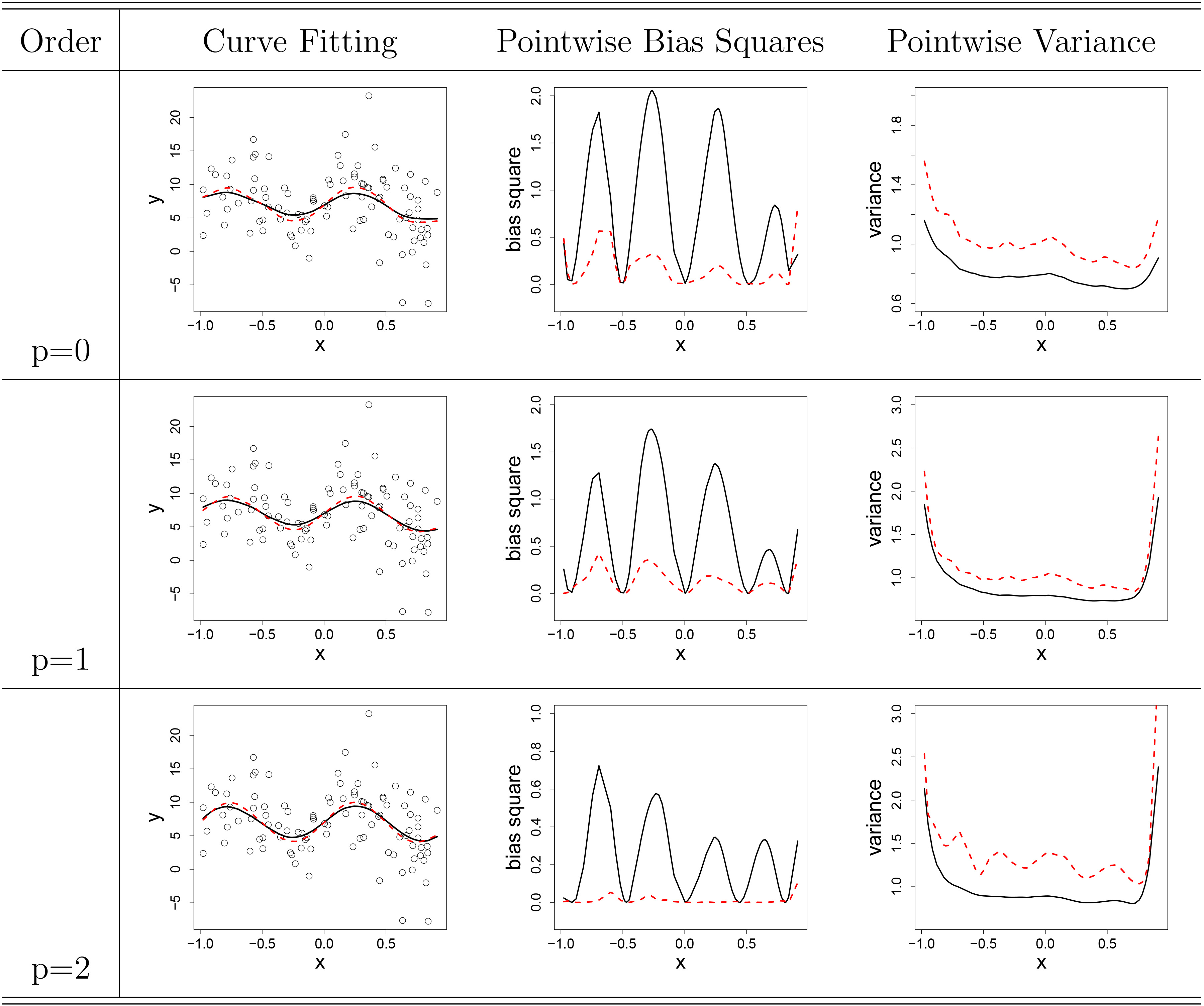
Second, for case (b) under
Setting (c) with 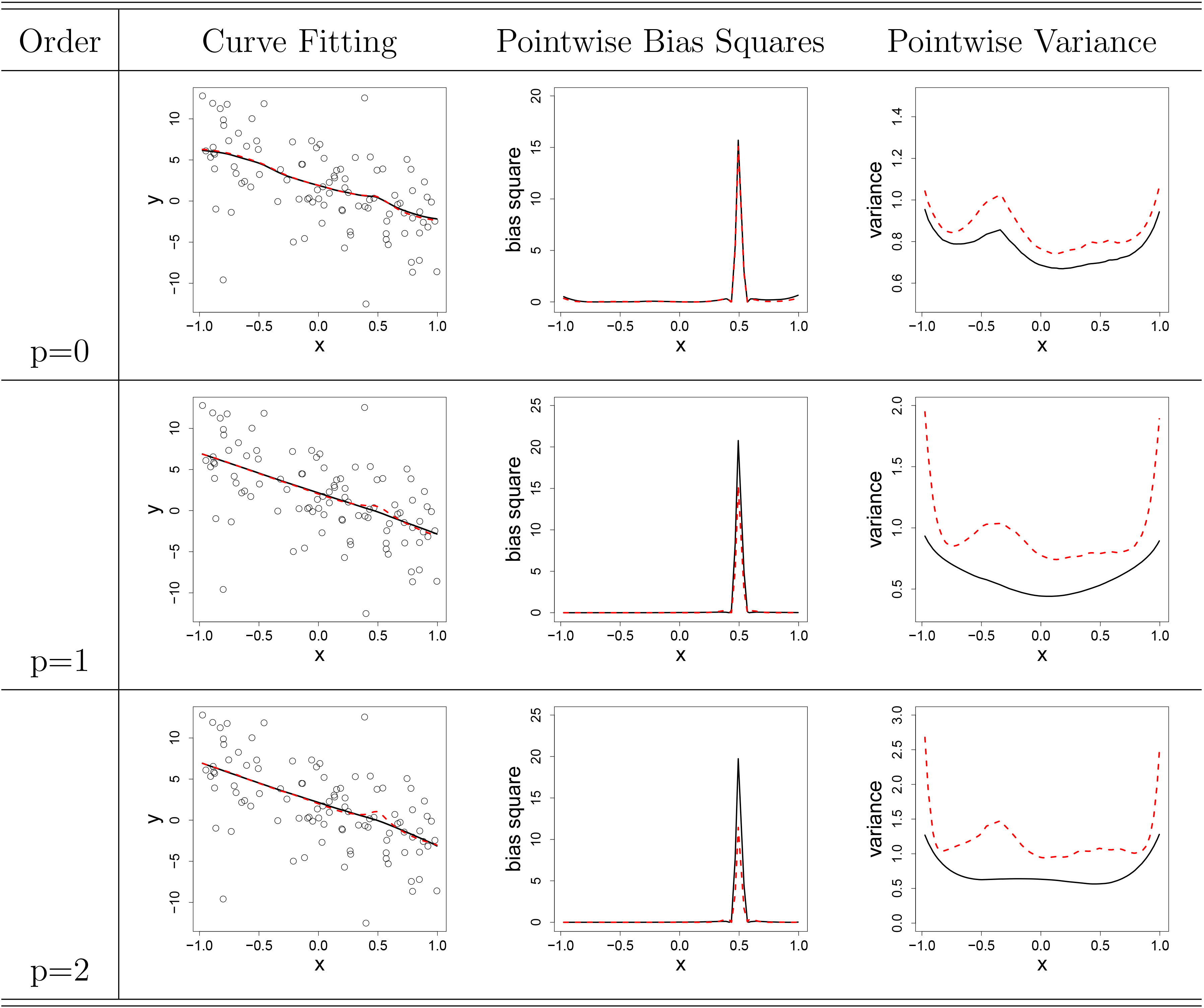
Lastly, for case (c) under
Next, we briefly interpret results for local linear estimation. As
2
Finally, we briefly interpret results for local quadratic estimation. For
Remarks
Here we summarize and elaborate on the results above. First, for the overall comparisons under
Second, we briefly summarize the performances of two different bandwidth selection approaches. Though we reach a simulated-based conclusion, the cases and functional classes considered in Subsection 3.1 are sufficient to compare the bandwidth selection methods. From our simulations, we have a consistent observation.
In general, we see that the CV method performs better than the DPI method when
Estimating the level function of a binary response
Bandwidth under three different situations for GLM
Bandwidth under three different situations for GLM
GLM Under Setting (a), (b) and (c). Note: the dashed line is for DPI, and the solid line is for CV.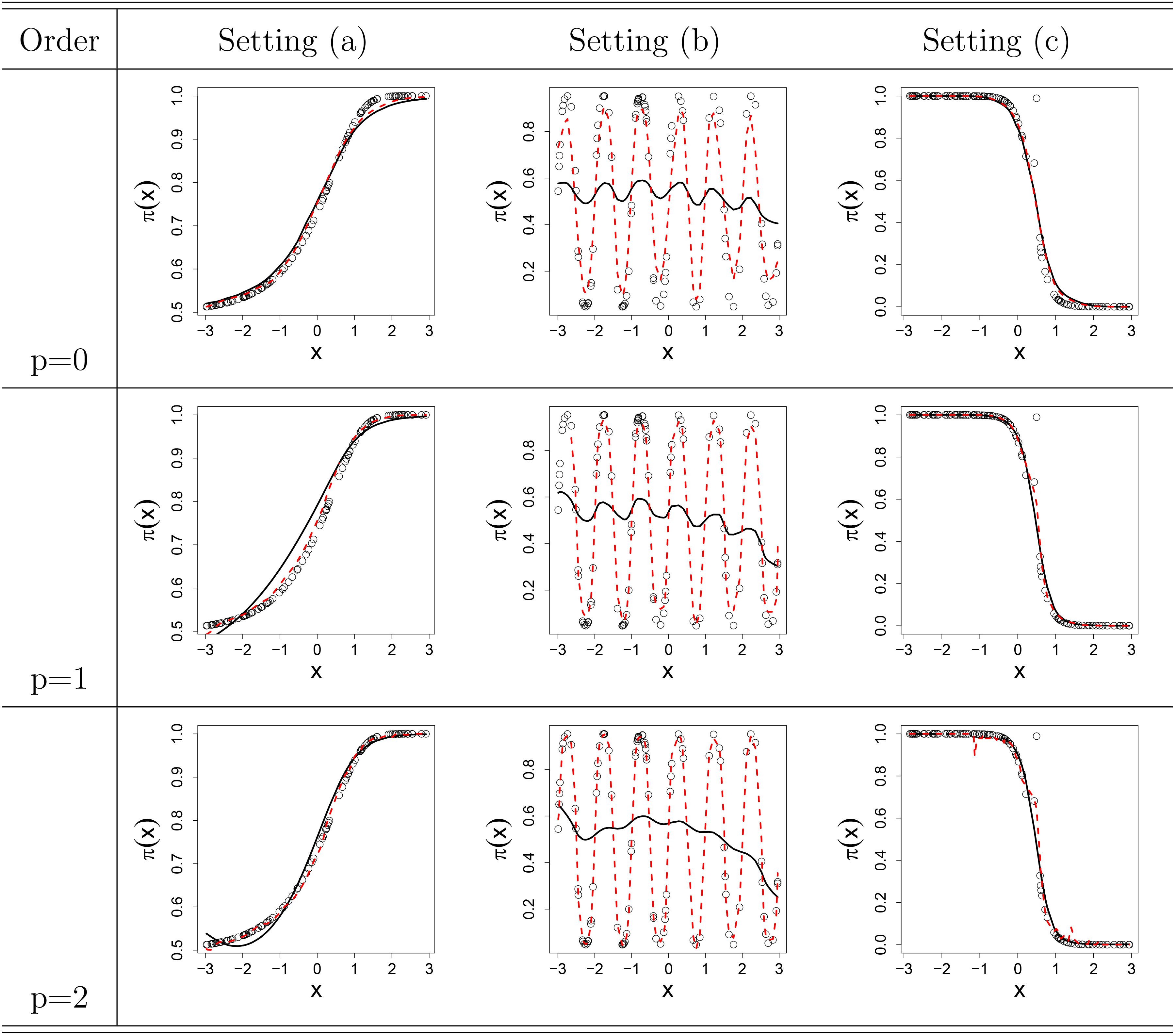
Consider the model of the form in Eq. (11). Following the idea from Section 3.1, we perform the simulation 1000 times for each of the following three underlying functions:
Monotone increasing function: Periodic function: General function:
By the analysis we introduced in Section 2.2, we find bandwidth first and then obtain estimators
For case (a) in the first column of Fig. 4, we can see that CV and DPI are similar under
From the graphical results, it is surprising that the DPI method performs better than the CV method in general, especially in case (b). We find that the CV method produces a larger bias and the curve fitting is worse than the DPI method. In addition, from case (a) and case (c), DPI method also fits better. Furthermore, it is interesting to note that DPI method always performs well for all orders
In some cases, we wish to estimate the derivative of a function. This is usually the case when the goal is the identification of local maxima and minima. Although this is not always the case, for our purposes we focus on the behavior of the derivative around zero. Specifically, we explore the estimation of the first derivative under quadratic kernel fit. The question is how the choice of bandwidth effects the identification of critical points (points such that
In the first simulation study, we examine the effects of cusp points. That is, points at which the function is continuous but the derivative does not exist. For example, the following function has a cusp and global maxima at
Cusps are of particular importance due to the behavior of the derivative. As we know, the derivative doesn’t exist at
Mean bandwidth and coverage rate for derivative and
In the second simulation, we examine the empirical power of the test. This is particularly relevant because power is equivalent to
In our earlier simulation, we found that DPI controlled type I error better, and referring to Fig. 5, we see that DPI is also a more powerful statistic. Again, this is an ideal case, since DPI does not over-smooth but is still more powerful than CV.
Empirical power function.
In the final simulation, we examine the effect of multiple local maxima. We proceed in a similar vein to our cusp example, and enforce that one maxima be smooth and one be a cusp. Specifically, we use the example used in Song et al. (2006):
Referring to Table 5, we see that DPI still outperforms CV in terms of coverage rates. Like the earlier examples, this is ideal because DPI does not over-smooth to outperform CV.
Mean bandwidth and coverage rate for derivative and
To conclude, we find that
In this section, we provide three empirical studies: one with a set of cyclical-pattern data, another is with the binary response and the last one is for the estimation of derivatives.
Weather data
We employ a set of cyclical-pattern data – daily temperature records and implement data analysis using the estimation and bandwidth selection methods introduced above. Essentially, the purpose of this analysis is to apply the first three orders of local polynomial kernel estimators with CV-/DPI-selected bandwidth to estimate the underlying temperature functions and compare the goodness of fit.
The Quality Controlled Local Climatological Data (QCLCD), from the National Climatic Data Center (NCDC), consists of hourly, daily, and monthly climatic information summaries for approximately 1,600 U.S. locations. Our sample contains the daily maximal temperature reports from 791 of the stations, covering from January 01, 2015 to December 31, 2015, which forms a panel of 365-time observations and 791 cross-sections.1
Ramsay (2006) applied a non-parametric recovery to the mean monthly temperatures for Canadian weather stations, assuming temperature records from different stations have the same underlying properties, which are primarily sinusoidal in character and certainly periodic over the annual cycle. For our data set, we simply assume, without further tests, that the temperature records from all stations follow the same underlying structure up to the sense that a curve-by-curve fitting by the local polynomial kernel estimators with the same order of polynomial and the same kernel can be implemented to all stations, while the estimation for different stations can have their own smoothing parameters, so that the six estimators (
Our estimation results, consistent with the simulation results, show that
Graduate school admission rates
As an example of the binary response case, we employ a set of data, including the GRE (Graduate Record Exam) scores, GPA (grade point average) and admission into graduate school for 400 individuals.2 The response variable, admit/not admit, is a binary variable; the GRE scores and the GPA are treated as continuous.
In essence, the results are consistent with the simulation results in that the DPI-selected bandwidth is smaller than then the CV-selected bandwidth, and thus the CV-generated estimated curves are smoother than the DPI-generated curves. For the estimation result itself, it shows that in general, higher GRE and GPA score will help to increase the probabilities of getting admitted up to around 50%. The corresponding figures and the numerical results can be requested from the author.
Yeast genome dataset
In this section, we analyze a subset of the oligonucleotide microarray of yeast. This dataset was used by Song et al. (2006) to demonstrate the strength of their nonparametric kernel smoothing technique. The purpose of our analysis now is to see the effects of bandwidth selection procedures on the estimation of local maxima, or peaks, in hybridization intensity profiles. We are concerned with peaks because they correspond to autonomous replication sequences, containing the putative origin of replication, which is of importance to genetics.
To help contrast the bandwidth selection procedures, we adopt the same methodology by Song et al. (2006) and estimate the first derivative of the hybridization intensity profile curve with quadratic kernel smoothing. Our main question is whether CV selected bandwidth is better than direct plug-in methods. By computations, the bandwidth values determined by the CV and DPI methods are 0.684 and 1.444, respectively. Analysis by Song et al. (2006) relied on the built-in R function “dpill()” for DPI bandwidth estimates, but again, this approach is questionable since “dpill()” is known for local linear kernel estimation. Therefore, we would expect that bandwidth selected by “dpill()” is not optimal.
In our analysis, however, we find that the purported suboptimal bandwidth selection by “dpill()” does not present a problem in the identification of peaks. Bandwidth acts as a smoothing parameter in a kernel regression setting and “dpill()” tends to overestimate the bandwidth compared to CV. This can easily be seen from the peak estimates in our numerical results, where the peaks identified by CV form a superset of the peaks identified by DPI. The corresponding numerical tables can be requested from the author.
First of all, we identify the peaks using the estimates of the first derivative. There are two cases of equilibrium points that we analyze. For Case I, we look for a positive first derivative estimate followed by a negative one. By the mean value theorem, we know that a continuous function will possess extrema somewhere in that interval, and we take the point estimate closest to zero. The Case II equilibrium point is unique and is found by considering all confidence intervals that contain zero and taking the corresponding point estimate that is closest to zero. The corresponding results of figures can be requested from the author.
Second, we obtain confidence intervals for chromosomal coordinates by a local inversion technique. That is, we know that the inverse of the lower 95% confidence interval for the derivative provides the maximum of the 95% confidence interval for the chromosomal coordinate, as well as vice-versa. Then we do a search for the point estimate that is closest to the lower/upper confidence interval and takes the value that minimizes the absolute difference. Since we are using a Gaussian kernel, this confidence interval is symmetric and so we mirror the half confidence interval. In our comparisons, we also provide the point estimate and confidence interval for each peak, where the corresponding results of figures can be requested from the author.
In summary, we find that identification issues typically arise only if the bandwidth is too low, which results in the degenerate estimation of peaks (e.g. overlapping peaks/confidence intervals and overabundance near the end-points of the data). Some of these problems, such as the problem at endpoints, can be fixed by simply ignoring them as spurious estimates. However, multiple identified peaks in a small region present a persistent problem in deciding which (if any or perhaps all) are true peaks.
Discussion
In this article, we illustrate the comparison between the CV method and the DPI method through the simulation study, considering both the continuous response case and the binary response case. From the comprehensive simulations, we conclude that the DPI method performs better than the CV method when
However, since the function “dpill()” is predetermined based on linear estimators, one possible extension of our study would be to generalize DPI to all
Although we mainly study bandwidth selection for
Footnotes
The 791 stations are chosen by eliminating the stations with missing data during 2015, and no other sampling scheme is employed.
The data can be obtained from
Acknowledgments
The author would like to extend the great gratitude to an Editor, an Associate Editor and a reviewer for valuable suggestions and useful comments to make this paper be better. The author also extends his great gratitude to Dr. Pengfei Li, an associated professor in the Department of Statistics and Actuarial Science, University of Waterloo, for his generous help, valuable advice and guidance on this project.