We introduce a notion of a probability space of regression models and discuss its applications to financial time series. The probability space of regression models consists of a set of regression models and a probability measure , which is based on the model “quality”, i.e. its ability to “fit” into historical data and to forecast the future values of the target variable. The set of regression models is assembled by selecting various combinations of input variables with different lags, transformations, etc., and varying historical data sets that are used for model building and validation. It is assumed that the model set is “complete” in the sense that it exhausts all the “meaningful” regression models that are possible to be built given available historical data and independent variables. Each model from the set yields a scenario for the target variable , and thus the probability space of regression models allows one to build a probability distribution for for each projection time . We demonstrate how those distributions can be used to estimate risk capital reserves required by the regulators for large U.S. banks for credit and operational risks under the macroeconomic scenarios provided by the Federal Reserve Bank (FRB) for the Comprehensive Capital Analysis and Review (CCAR) stress testing.
“The recognition of risk management as a practical art rests on a simple clich? with the most profound consequences: when our world was created, nobody remembered to include certainty. We are never certain; we are always ignorant to some degree. Much of the information we have is either incorrect or incomplete.”
– Peter L. Bernstein
Introduction
The challenge of dealing with a financial time series can be formulated in its most general form as the following: given all the information available at the moment (data, results of analysis, expert opinions, etc.), find out what should be expected from this financial time series in the future. Common examples would include assessing future time development of credit losses, operational risk losses, mortgage default and prepayment, likelihood of a corporate bond default, etc., given available historical data on time development of such possible explanatory (independent) variables as industry and macroeconomic factors, interest rates, unemployment index, borrowers’ characteristics, etc. From the perspective of risk management, an ideal solution would be finding probability distributions of possible financial time series values for the projection times of interest.
In more formal settings. Let be a complete body of knowledge (data, results of analysis, expert opinions, etc.) available about a financial time series at the time . Find probability distributions
of the financial time series for the projection times .
The notation used in the Eq. (1) explicitly reflects the fact that both elements of the pair , possible values that the time series can take at and their corresponding probabilities are conditional upon the knowledge that is acquired at .
In this paper we introduce the notion of Probability Space of Regression Models (PSRM) as a comprehensive attempt to build a probability distribution for . The fundamental assumption underlying PSRM is that the body of knowledge consists of “meaningful” regression models that can be built for time series using available historical data. The objective for creating a PSRM is NOT necessarily to build the best model – the chance of developing a crystal ball is rather slim – we want to learn about ALL possible outcomes “suggested” by ALL meaningful regression models.
The choice of regression as the only modeling framework is driven to a certain degree by the necessity to be able to explain the modeling results to various regulation and consumer protection authorities which are very reluctant to accept any model (e.g., neural network) that lacks clear explanations of how the model inputs impact its output. It was observed (see, for example, Hastie et al., 2001) that “For prediction purposes they [linear regression models] can sometimes outperform fancier nonlinear models, especially in situations with small numbers of training cases, low signal-to-noise ratio or sparse data.”
The key reason for creating and employing a PSRM is developing a probability framework that encompasses and formalizes the model building process which is commonly employed in risk management. The process starts with the project’s business objectives and continues with selecting the data, choosing predictors, evaluating and using the models. All those steps whilst driven mostly by the project objectives and data availability have unavoidably some subjectivity. The employment of a PSRM allows one to make this subjectivity to be clearly stated and recognized. When all decisions are made and all meaningful models are built, the PSRM allows one to see a clear probabilistic picture of what should be expected from the financial times series of interest during the projection period.
The paper adheres to the following outline: Section 2 introduces the notion of Probability Space of Regression Models (PSRM) and provides a simple example illustrating in detail how a PSRM can be built and used for risk assessment and hedging of a financial time series. Section 3 discusses the general approach to creating PSRMs – building sets of regression models and defining corresponding model probabilities. Section 4 describes how PSRMs can be used to estimate risk capital reserves required by the regulators for large U.S. banks for credit and operational risks under the macroeconomic scenarios provided by the Federal Reserve Bank (FRB) for the CCAR stress testing. Finally, in Section 5 we present some of our conclusions.
An example of probability space of regression models (PSRM)
Let be a financial time series of interest (i.e., credit losses, operational risk losses, mortgage default and prepayment, likelihood of a corporate bond default, etc.). By we denote a set of all meaningful regression models that could be built using available historical data for both the target and the predictors as of time . Let us assume that for each model one defines a numeric value which is proportional to the “quality” of the model i.e. model’s ability to “fit” into historical data and to forecast the future values of the target variable. The pair
is defined as Probability Space of Regression Models (PSRM). Note that since the set encompasses all meaningful regression models, it is assumed to be complete, i.e.
Note that for this case, the complete body of knowledge consists of the historical data available at the time for both predictors and the target, the set of meaningful models , and the corresponding probabilities From here on, we will be omitting the time in the notations assuming that PSRM is built as of the latest for which the data are available.
The word “meaningful” is a key word in building a set of regression models for a PSRM. The meaningfulness of a model is defined by a set of criteria which combines requirements to model quality with business matter expert opinions about how a particular independent variable should affect the target variables. The latter usually takes the form of requirements to the signs of regression coefficients. For example, it is well known that the frequency and severity of credit losses for consumer loans are positively correlated with unemployment and negatively correlated with the GDP growth rate. Thus, for a model built to assess time development of consumer loss frequency/severity, the coefficient for the unemployment variable is expected to be positive and the one for the GDP growth to be negative. The former usually has two types of requirements: one assessing how well a model fits into the historical data that was used for model building and the other evaluating the model accuracy in predicting out-of-time values. For example, it can be decided that only the models with , all -values of the coefficient -statistics below 20%, and the root-mean-square error (RMSE) for the out-of-time period less than 15% are included into the set of regression models . Obviously, in some real life situations, there might be NO meaningful regression models.
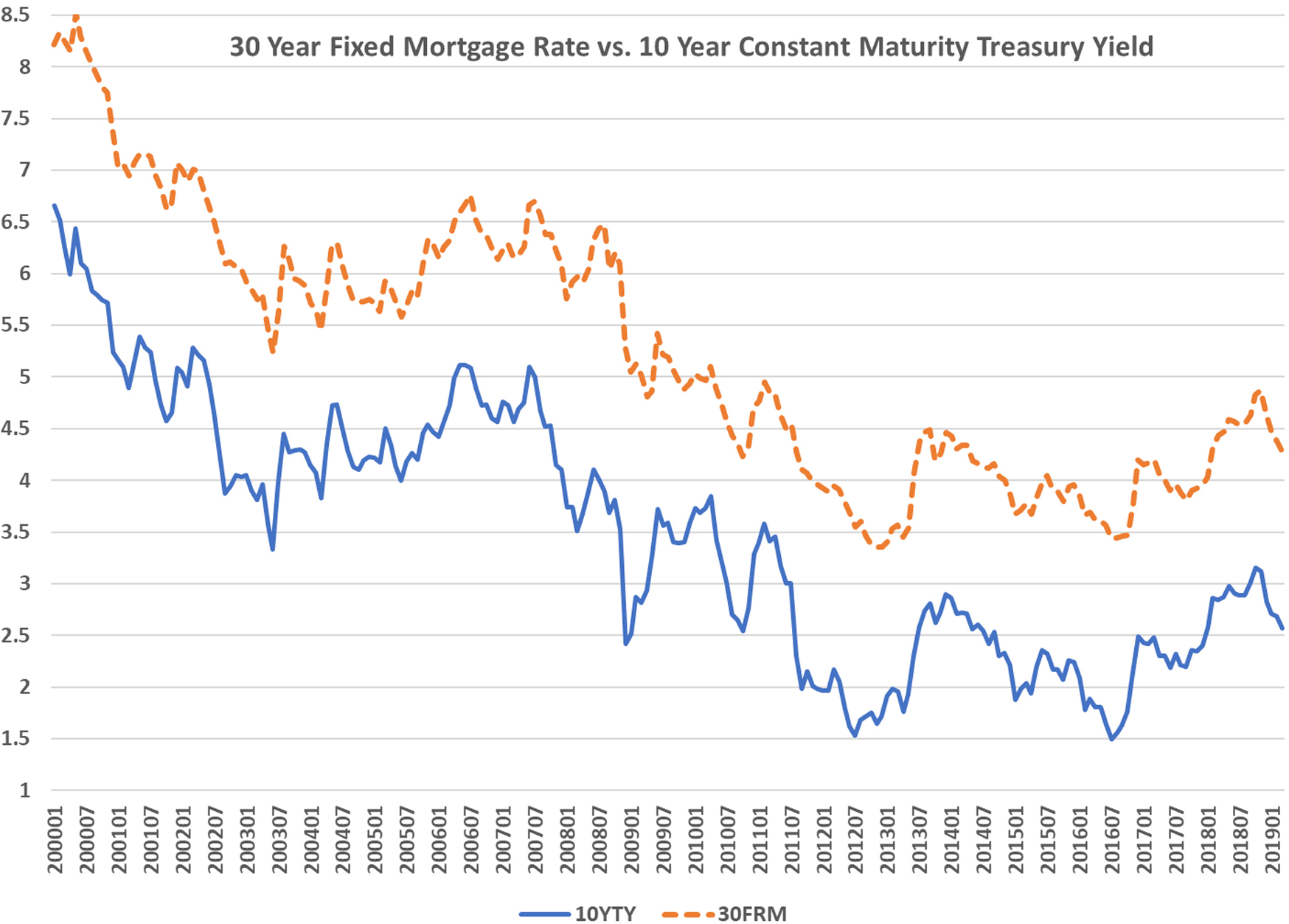
Let us consider a simple example of building and applying a PSRM for risk management and hedging. In this example, the financial time series of interest is the 30-year Fixed Mortgage Rate (30FRM). This rate is heavily used by the mortgage industry to price and hedge fixed-rate 30-year mortgages (see, for example, (Young, 1997)), and it is traditionally assessed through the spread between 30FRM and 10-year Constant Maturity Treasury Yield (10YTY). So for this example, the target variable is the difference between 30FRM and 10YTY reported monthly. To better illustrate how a PSRM can be created and used, we limit the model inputs to just variable 10YTY and build regression models that takes 12 monthly projections for 10YTY and yields 12 monthly projections for the 30FRM-10YTY Spread.
The historical data that were used in model building and testing (please see Fig. 1) cover the period of January 2000 through March 2019 (please see (Economic Research Division, March 2019) for 10YTY and ((FedPrimeRate, March 2019) for 30FRM). The last 12 months of this period were used to replicate the real life situation: given 12 monthly projections of 10YTY, assess ALL possible 30FRM – 10YTY spread outcomes “suggested” by ALL meaningful regression models.
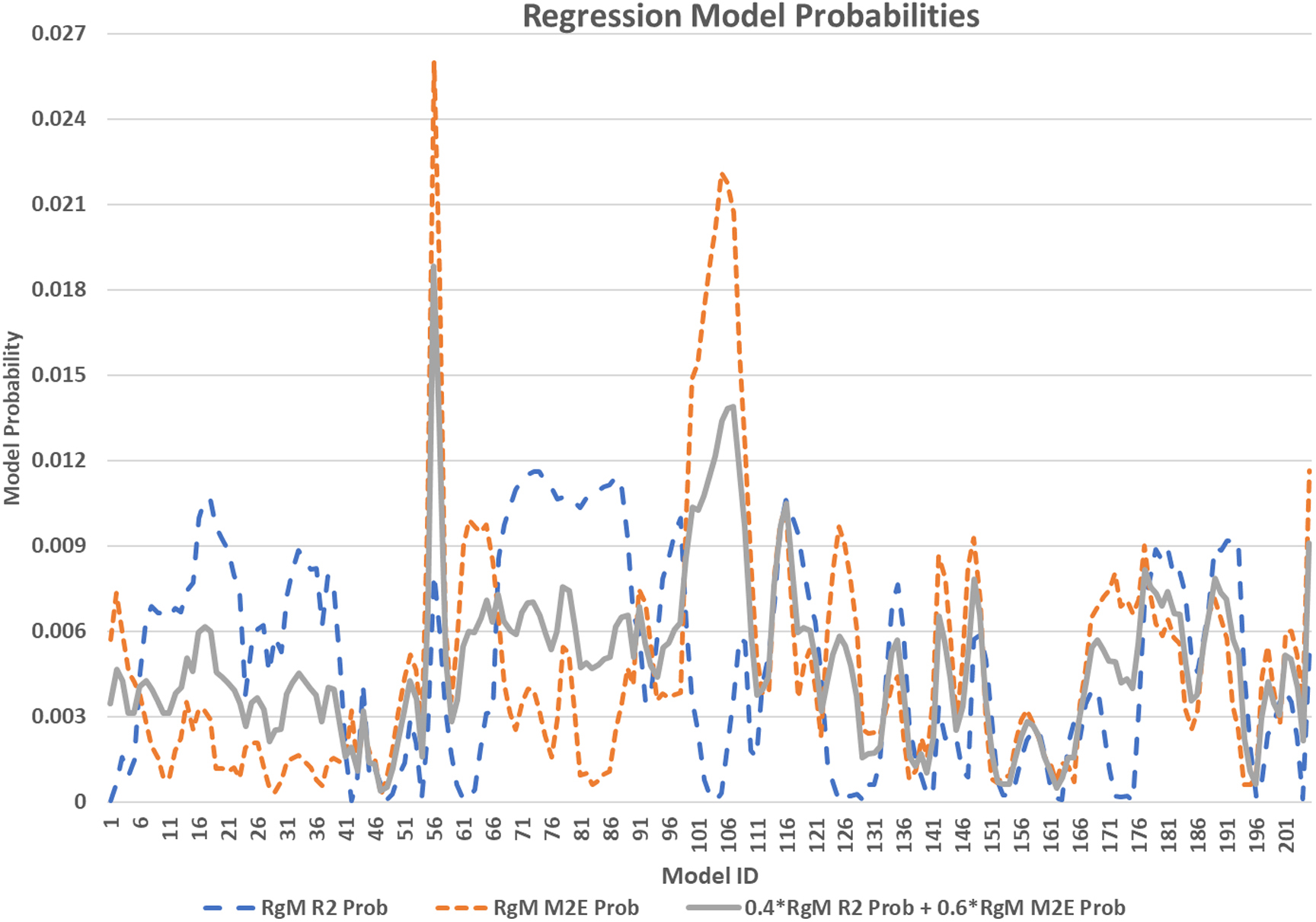
Historical fit , out-of-time accuracy and combined for .
We say that a regression model is meaningful if the following conditions are met:
Here denotes the -value of the t-statistics for the model coefficient and stands for the root-mean-square error (RMSE) for the out-of-time period. The coefficient for 10YTY is required to be negative since a higher 10YTY usually goes along with a smaller 30FRM – 10YTY spread.
The set of total of 205 meaningful regression models satisfying Eqs (2a)–(2d) were built. For each model , a 12-month historical period was used to find the coefficients and the following 3 months were used to assess the accuracy in predicting out-of-time values. For example, for a model , the coefficients and along with and were calculated using the data for the period March 2014 through February 2015 and was assessed using data for the period March 2015 through May 2015.
For each model , we define
and
can be interpreted as a numerical measure of the model ability to “fit” into historical data and measures the model accuracy over the out-of-time period. Figure 2 above shows and for all . As one can see, a high or low does not always come with a high or low and vice versa.
Combining and allows us to define the probability of by the following formula:
for given . Equations (3) and (4) obviously imply that the value is proportional to model quality and .
In general, the values of and are decided upon by the perceived importance of good in-historical data fitting versus importance of good out-of-time-fitting. For this example, we have selected and and considered PSRM
We used the 12-month period of available historical data as a projection period, and for each month the model yielded 30FRM – 10YTY spread forecast . Thus, for each we built an EDF
where is a set of projections yielded by for .
It is important to note that while the values might be different for different , the corresponding probability stays the same for all
For each the EDF was fitted into a continuous distribution , which, in its turn, allows one to learn about ALL possible 30FRM – 10YTY spread values “suggested” by regression models . Table 1 below shows the parameters and errors of fitted distributions.
Parameters and errors of fitted distribution
Y(t) distribution fits with R2 weight 0.4 and RMSE weight 0.6
PrjYYYYMM
Gauss
Gauss fit
Gauss fit err
Gamma fit
Gamma fit
Gamma fit err
201804
1.895
0.507
0.0623
13.192
0.138
0.057
201805
1.863
0.504
0.0612
12.899
0.139
0.055
201806
1.883
0.506
0.0621
13.041
0.139
0.056
201807
1.889
0.506
0.0622
13.140
0.138
0.056
201808
1.889
0.506
0.0622
13.140
0.138
0.056
201809
1.857
0.503
0.0606
12.873
0.139
0.055
201810
1.819
0.498
0.0571
12.531
0.140
0.051
201811
1.827
0.498
0.0578
12.632
0.139
0.051
201812
1.906
0.510
0.0632
13.204
0.139
0.058
201901
1.943
0.516
0.0646
13.370
0.140
0.059
201902
1.952
0.517
0.0646
13.435
0.140
0.059
201903
1.984
0.523
0.0638
13.532
0.141
0.059
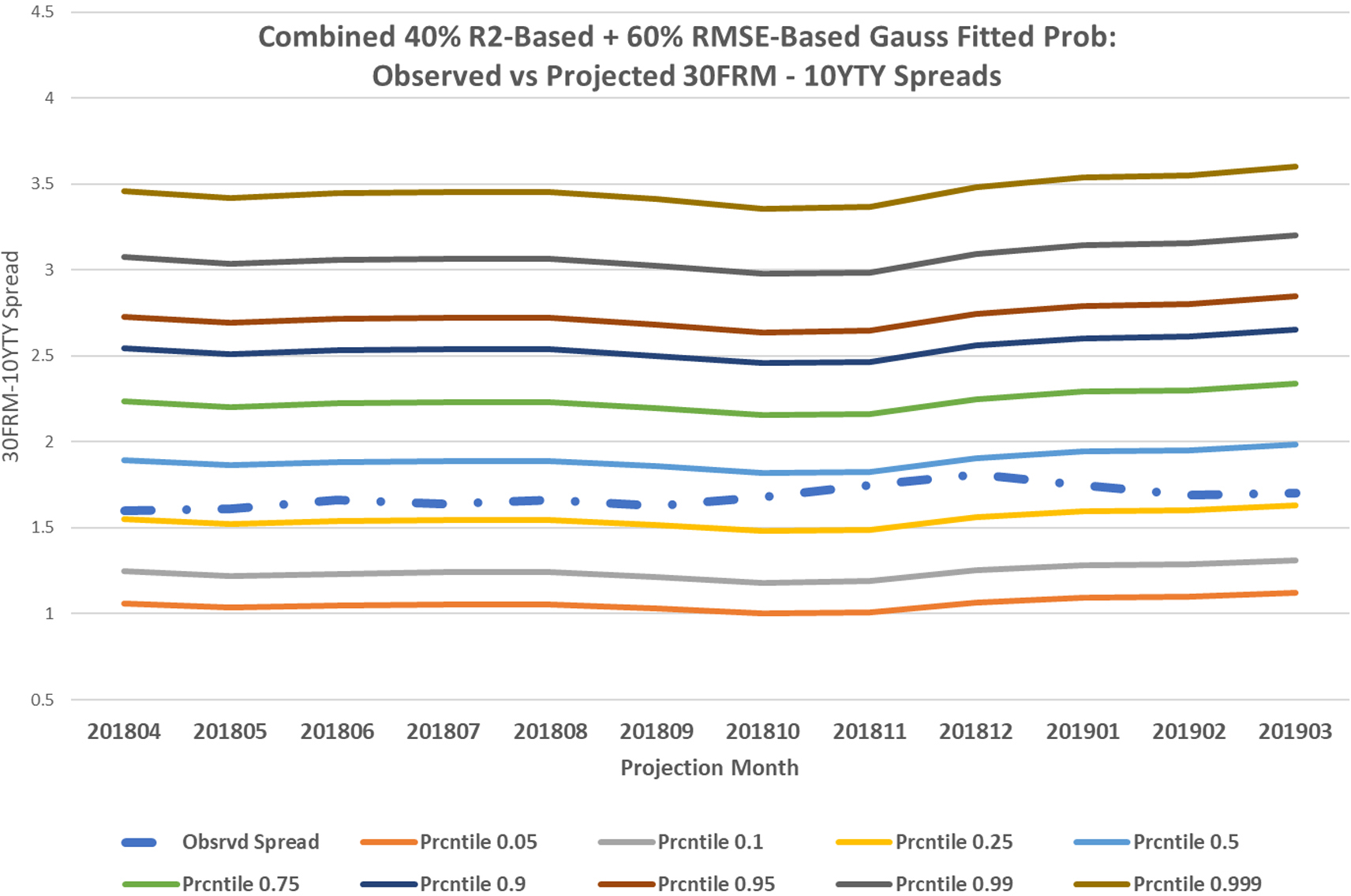
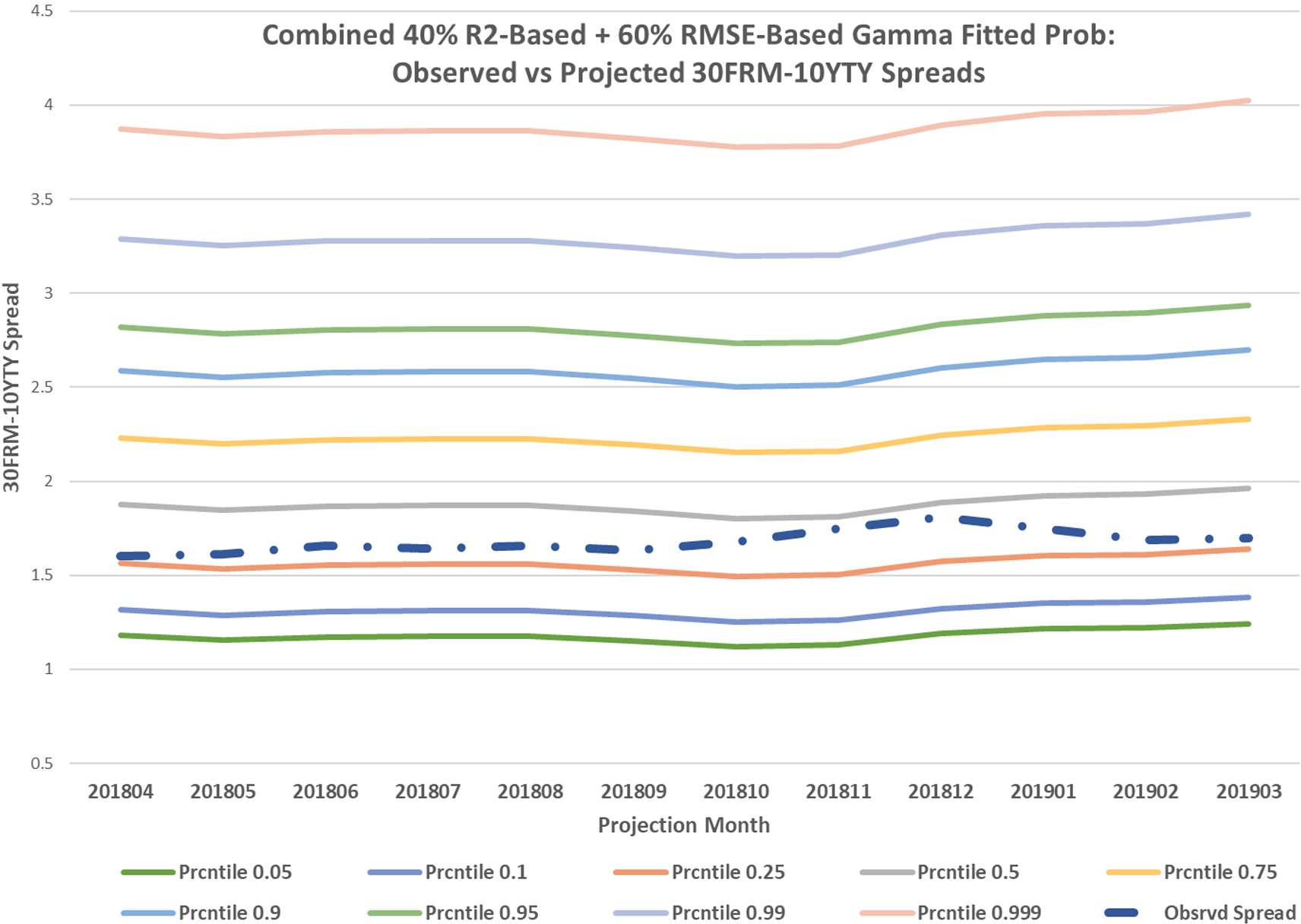
Figures 3 and 4 on the next page show various percentile levels of the 30FRM-10YTY Spread suggested by the PRSM for the projection months. The risk managers with portfolios exposed to the 30-year fixed rate mortgages could use those estimates to hedge their positions or allocate capital that is sufficient to cover potential losses.
Percentile levels of the 30FRM-10YTY Spread for suggested by the PRSM with Gaussian fit for the projection months.
Percentile levels of the 30FRM-10YTY spread for suggested by the PRSM with gamma fit for the projection months.
General approach to PSRMs
In the most general case, the objective for building a set of regression models for a target variable is to demonstrate that the available data and the independent variables under consideration can be used to build meaningful regression models for estimating time development of the target variable. As was mentioned earlier, the building efforts can result in proving that there are no meaningful regression models connecting the target variable to possible predictors.
In business settings the model set is created by varying the following model specifications:
MS1: The independent variables that are used in a model. It is well-known that each independent variable requires a certain number of data records. So if one has a large number of variables “supported” by relatively few records, the number of variables used in a model should be restricted accordingly.
MS2: Lags for the independent variables that are used in a model. In many cases, the target is effected by the inputs with delays that vary from an input to an input.
MS3: Historical period that was used to build a model. This is undoubtedly the most important model specification. When a model is built using the data from a certain historical period, then the forecast yielded by this model is what can happen if the model projection period is “similar” to the historical data upon which the model was built.
MS4: Historical period that was used for out-of-time assessment of the model performance.
Formally, a regression model is described as a collection
where is the target variable;
are variable “participation” flags:
are variable lags:
are data history settings:
and are correspondingly the beginning and the length of the historical period that was used for model building, is the length of history that was used to assess the model performance over the out-of-time period.
are model coefficients:
is a set of statistics that are used to evaluate the model performance.
The set of meaningful regression models is built by varying the vectors , and (please see MS1 through MS4 above) and by using the vectors and to define which of the built regression models are meaningful. It is assumed that the model set is “complete” in the sense that it exhausts all the regression models that are possible to be built given available historical data and independent variables. This assumption allows us to introduce a probability measure over as follows.
Let be statistics that are used to assess the model performance, and they are such that for any two models one can say that () is “better” or “worse” than (). For example, if includes such statistics as and , we say that
Similarly, we say that
For a performance statistic we use the notation
and for a model we define the model rank by
For a vector of weights , corresponding to the statistics , for each we define the model score
Finally, the probability associated with the model is calculated as
It is easy to see that specified by the Eqs (5)–(8) satisfies
and we say that a pair of meaningful regression models and corresponding probabilities is Probability Space of Regression Models (PSRM).
One can note that defined by Eq. (6) can be interpreted as an assessment of how well/poorly model “is doing its job” in comparison with the other models in from the “perspective” of the statistic . The weights are assigned in accordance with relative importance of statistic for evaluating model performance. The quantity defined by Eq. (7) can be viewed as overall model score (the higher the better) for assessing the performance of model . Finally, can be interpreted as a “likelihood” that the model “will do a good job” in assessing future time development of the target variable .
Using PSRMs for the CCAR stress testing
The Dodd-Frank Wall Street Reform and Consumer Protection Act (Board of Governors, February 2017) requires the Board of Governors of the Federal Reserve System to conduct an annual supervisory stress test of bank holding companies (BHCs) with $50 billion or greater in total consolidated assets (large BHCs), and to require BHCs and state member banks with total consolidated assets of more than $10 billion to conduct company-run stress tests at least once a year.
Every year the Board provides the banks with three supervisory scenarios – baseline, adverse, and severely adverse – for time development of key macroeconomic factors (Board of Governors, February 2019) listed in Table 2.
Macroeconomic factors suggested by FRB/OCC
Factor #
Macroeconomic factor name
1
Real GDP growth
2
Nominal GDP growth
3
Real disposable income growth
4
Nominal disposable income growth
5
Unemployment rate
6
CPI inflation rate
7
3-month treasury rate
8
5-year treasury yield
9
10-year treasury yield
10
BBB corporate yield
11
Mortgage rate
12
Dow Jones total stock market index
13
House price index
14
Commercial real estate price index
15
Market volatility index
16
Prime rate
The Board uses those scenarios in its supervisory stress test for the stress test cycle. It is required that a large BHC must use the same scenarios to estimate projected revenues, losses, reserves, and pro forma capital levels as part of its annual capital plan submission. BHCs are expected to use the Fed’s macroeconomic scenarios to demonstrate how the projected revenues, losses, reserves are affected by changes in the macroeconomic environment. Federal Reserve Bank (FRB) and Office of the Comptroller of the Currency (OCC) have been strongly recommending that financial institutions consider using macroeconomic factors to develop adverse and severely adverse scenarios for various types of risks.
In the case of operational risk, it is expected that financial institutions use those macroeconomic factors to estimate their losses by the seven operational risk event categories (please see Table 3) specified by the Basel II document (Basel, June 2004). Further in this section, we will discuss some findings of a comprehensive study where the PSRM framework was employed for assessing time development of operational risk losses for various Basel II Operational risk categories under stress testing macroeconomic scenarios. This study was carried out by a large international consumer bank with the objective to find out whether the macroeconomic factors suggested by FRB can be used to build meaningful regression models for estimating time development of operational risk losses. For each of the seven event types listed in Table 3, the regression models were built for the following two target variables:
Basel II operational risk event categories
Event type #
Event type name and description
1
Internal fraud – misappropriation of assets, tax evasion, intentional mismarking of positions, bribery
2
External fraud – theft of information, hacking damage, third party theft and forgery
3
Employment practices and workplace safety – discrimination, workers compensation, employee health and safety
4
Clients, products, and business practice – market manipulation, antitrust, improper trade, product defects, fiduciary breaches, account churning
5
Damage to physical assets – natural disasters, terrorism, vandalism
6
Business disruption and systems failures – utility disruptions, software failures, hardware failures
7
Execution, delivery, and process management – data entry errors, accounting errors, failed mandatory reporting, negligent loss of client assets
The operational risk data that were used in the study came from the following two sources:
Source 1: The Operational Riskdata eXchange Association (ORX) (please see (ORX, March 2019)) – a not-for-profit industry association, which provides its members and subscribers with anonymized high-quality operational risk loss data covering all major World regions.
Source 2: The American Bankers Association (ABA) (please see (ABA, March 2019)) – The largest professional association of America’s hometown bankers – small, regional and large banks which provides its members and subscribers with anonymized high-quality operational risk loss data for the United States.
There are no guarantees that a particular bank’s stream of revenues or losses do exhibit dependency on various macroeconomic factors. In the case of operational risk, Federal Reserve Board (FRB) expressed reservations about relying on macroeconomic factors for developing realistically conservative stress scenarios (Board of Governors, October 2014). It names the limited length of operational risk datasets and potential problems classifying and reporting events (especially legal ones) to be major challenges in identifying meaningful and robust relationships between operational losses and macroeconomic factors.
Our study did prove that it is only possible to build meaningful regression models and corresponding PSRMs for the following four categories of operational risk events: Internal Fraud (ET1), External Fraud (ET2), Clients, Products, Business Practices (ET4), Execution, Delivery and Process Management (ET7). Employing the PSRM framework was instrumental for demonstrating to the FRB/OCC representatives that for the other three operational risk event types there is no meaningful model or a combination of models that is “good enough” for assessing future time development of the target variable.
Let us consider a PSRM that was built with the target variable
An example of regression model is one with the following components: (2009Q1, 21 (in quarters), 2 (in quarters)), the vectors , and along with the variable standard error and -value of -statistic shown in Table 4.
As was described in Section 3, a regression model is meaningful if its coefficients and the evaluating statistics meet certain conditions. Table 5 shows the signs that are expected from the coefficients of a meaningful regression model, and Table 6 lists the requirements to the statistics that it should meet. Table 7 shows the values of statistics for the model described above.
Example of a meaningful regression model
Economic factor name
EF#
F
L
C
Standard error
-value of -statics
Real GDP growth
1
0
1
0
N/A
N/A
Nominal GDP growth
2
0
1
0
N/A
N/A
Real disposable income growth
3
0
1
0
N/A
N/A
Nominal disposable income growth
4
0
1
0
N/A
N/A
Unemployment rate
5
0
1
0
N/A
N/A
CPI inflation rate
6
0
1
0
N/A
N/A
3-month treasury rate
7
0
1
0
N/A
N/A
5-year treasury yield
8
0
1
0
N/A
N/A
10-year treasury yield
9
0
1
0
N/A
N/A
BBB corporate yield
10
0
1
0
N/A
N/A
Mortgage rate
11
0
1
0
N/A
N/A
Dow Jones total stock market index
12
1
3
0.381
0.1376
0.0131
House price index
13
1
0
2.568
0.4693
0.0004
Commercial real estate price index
14
0
1
0
N/A
N/A
Market volatility index
15
1
1
0.103
0.0649
0.0813
Intercept
16
1
0
17.54
2.2114
0.0001
Requirements to the coefficient signs
Economic factor name
EF#
Meaningful coefficient sign
Real GDP growth
1
Negative
Nominal GDP growth
2
Negative
Real disposable income growth
3
Negative
Nominal disposable income growth
4
Negative
Unemployment rate
5
Positive
CPI inflation rate
6
Any
3-month treasury rate
7
Any
5-year treasury yield
8
Any
10-year treasury yield
9
Any
BBB corporate yield
10
Any
Mortgage rate
11
Any
Dow Jones total stock market index
12
Negative
House price index
13
Negative
Commercial real estate price index
14
Any
Market volatility index
15
Positive
Intercept
16
Any
Requirements to the model statistics
Model statistic
Statistic requirement
Adjusted
30%
Mean squared error
10%
Standard error
10%
F-statistic significance
5%
Max -value of coefficient -statistic
15%
AICc
30
Abs[one quarter forward error]
5%
Abs[one quarter forward error]
15%
Example of the statistics values for the model
Model statistic
Value
Adjusted
58.723%
Mean squared error
0.963%
Standard error
9.816%
F-statistic significance
0.039%
Max -value of coefficient -statistic
13.122%
AICc
55.920
Abs[one quarter forward error]
0.812%
Abs[one quarter forward error]
14.362%
As it was discussed earlier in Section 3, the weights for the model score are assigned in accordance with relative importance of statistic for evaluating model performance. For this study we used the weights shown in Table 8. The first six statistics ( evaluate how well the model fits into the historical data whilst the last two ( assess the accuracy of out-of-time accuracy. Overall the weights are in 60% to 40% split between the historical fit and the out-of-time accuracy. The reader can note in the example discussed in Section 2, this split was an exact reverse: 40% was assigned to the model ability to fit into historical data and 60% to its out-of-time accuracy. In both cases, the weight distributions were driven by the business objectives of the corresponding projects.
Statistic weights for calculating the model score
Model statistic
Weight
Adjusted
8%
Mean squared error
8%
Standard error
8%
F-statistic significance
8%
Max -value of coefficient -statistic
20%
AICc
8%
Abs[one quarter forward error]
20%
Abs[one quarter forward error]
20%
One of the major challenges we were facing while running the project was the number of regression models that we needed to build and evaluate. Given variables to choose from and assuming that a quarterly lag between a predictor and the target does not exceed , the number of -variable regression models that can be built for the same history settings is given by
So for (Prime Rate was the same for the all FED historical records and thus, was not used) and for quarters (it was assumed that a macroeconomic factor cannot possibly influence operational risk events over the period exceeding two years) the number of models definitely needed to be reduced.
The reduction was carried on in two steps. First, it was taken into account that the number of records describing the quarterly operational risk event counts and loss amounts did not warrant building models with more than five macroeconomic factors. This immediately brought the number of models for one history settings
For the second reduction step we used the observation that in many cases the signs of correlation coefficients between the target variable and a macroeconomic variable are different for different lags. It is hard to expect that the same macroeconomic factor exhibits a positive effect on, let us say, the operational event counts when taken with lags 0, 1, and 2, but then goes negative with larger lags. So in the model building process, for each macroeconomic variable, only lags yielding correlations with the same signs as one with the zero lag were considered.
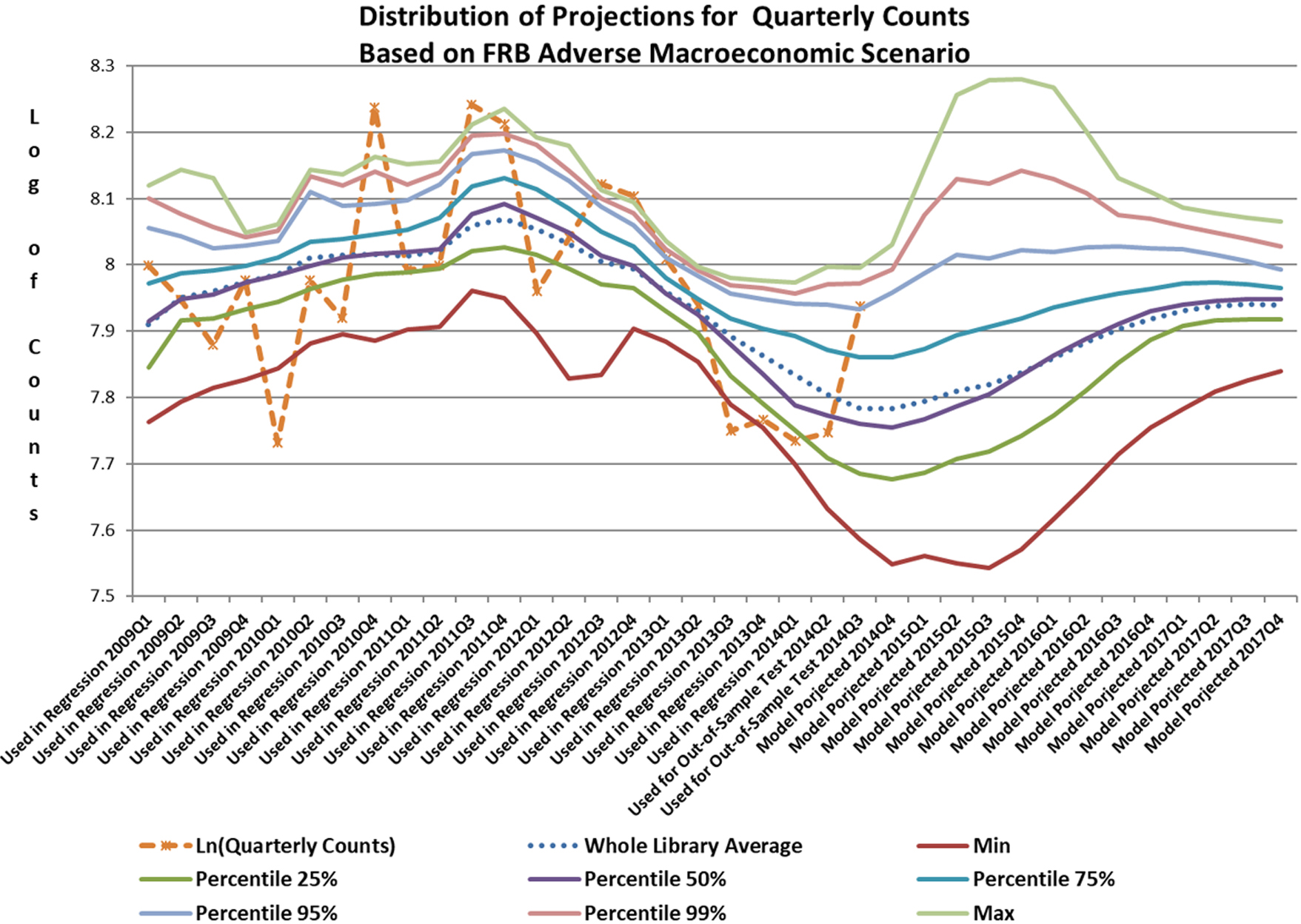
- based distributions generated for the FRB Adverse Macroeconomic Scenario.
So after those reductions and applying the coefficient requirements listed in Table 5 and the model evaluating statistic requirements listed in Table 6, we built a PSRM encompassing about 150,000 meaningful regression models. In accordance with Eq. (7), for each model its score was calculated by
Since the set was sufficiently large, there was no need for distribution fitting similar to the one discussed in Section 2, and the Empirical Distribution Functions (EDF) yielded by PSRM were used for the analysis required for the bank CCAR submission. Figure 5 shows an example of the distributions that were produced by for the FRB Adverse Macroeconomic Scenario.
Whilst having a large model set allows one to avoid uncertainty related to the distribution fitting, in some cases, dropping models with “wrong” coefficient signs and “poor” statistics might fail to reduce the model set to a manageable size. One of the remedies that can be used to address the issue is the Branch and Bound Algorithm suggested in the early 1960s by Land and Doig (1960) and which is currently commonly used for discrete optimization problems (see, for example, Mehlhorn et al., 2008). This method can be effectively applied to reduce the number of regression models to a target number while assuring that the models with the “best” statistics are included in the model set .
Conclusions
As we mentioned in Section 1, the major reason for creating and employing a PSRM is to develop a probability framework that encompasses and formalizes the model building process which is commonly employed in risk management. In practical risk management there is a significant degree of subjectivity in how models are built and which of them should be dropped or retained. Various historical periods covering different observations are commonly used in the model building process as well as lags and a variety of variable transformations (taking logarithm, applying moving averages, to mention a few). There are no universal recipes to follow or formal requirements to meet for those activities (two examples of building and using PSRMs described in Section 2 and Section 4 are illustrations.) They all are very project specific and frequently reflect expertise of the people involved.
The key idea underlying PSRM comes from the following methodological suggestion: as soon as the model building process is complete, i.e., the model set encompasses all the models that are deemed to be “meaningful,” this set can be considered to be “complete” and hence each model in this set is assigned a probability value calculated as described in Section 3. The employment of a PSRM allows one to make this subjectivity to be clearly stated and recognized (e.g., defining which statistics are employed for model evaluation and what are the weights used in calculating the model score .) When all decisions are made and all meaningful models are built, the PSRM allows one to see a clear probabilistic picture of what should be expected from the financial times series of interest during the projection period.
The idea of building an exhaustive (complete) space of regression models can probably be traced to the pioneering works of A. G. Ivakhnenko who introduced it in his publications dated back to the 1970s (please see Ivakhnenko and Madala, 1994). Since the recent advances in machine learning, the idea of building and working with large sets of various types of predictive models has become quite prevailing in many areas of research and practical applications including financial risk management (please see, for example, Leo et al. (2019), which includes an exhaustive list of references).
The notion of a meaningful model is commonly used in many areas of statistical research and applications and was introduced in 1980s, under the name of “intentional statistical analysis” (the reader can find a short description of it in Mandel (2014) and more details in Mandel (1988).
Assigning a probability measure to statistical models is a common feature of the Bayesian framework (see for example, George & McCulloch, 1993; George & McCulloch, 1997; and an excellent review on the subject (Fragoso & Neto, 2015)). The principal difference between the PSRM approach to calculating model’s probability and one employed in Bayesian framework is due to the absence of any prior or posterior distributions and explicit incorporation of expert opinions into the probability calculations.
Defining model probability measure as a “likelihood” that the model “will do a good job” in assessing future time development of the target variable is reminiscent to Peter L. Bernstein’s observation (Bernstein, 1998) that “In the first sense, probability means the degree of belief or approvability of an opinion – the gut view of probability.”
The author’s first attempt to explicitly incorporate model quality into developing time series projections goes back to the paper (Ladyzhets, 2012) published in 2012 where the Final House Price Model was built as a weighted average of Base Models with the weights that are proportional to Base models’ ability to estimate accurately the latest house prices. Using the terminology introduced in this paper, a Base Model is a member of the set of meaningful regression model and the corresponding probability is defined by only one component, which is proportional to the model accuracy in estimating house prices one step ahead.
References
1.
American Bankers Association (ABA). (March 2019). Retrieved from the association website: https://www.aba.com/Pages/default.aspx.
2.
Basel Committee on Banking Supervision. (June 2004). International Convergence of Capital Measurement and Capital Standards, A Revised Framework. BIS.
3.
Bernstein, P. L. (1998). Against the Gods: The Remarkable Story of Risk. Wiley.
4.
Board of Governors of the Federal Reserve System. (February 2017). Comprehensive Capital Analysis and Review 2017 Summary Instructions for LISCC and Large and Complex Firms.
5.
Board of Governors of the Federal Reserve System. (February 2019). 2019 Supervisory Scenarios for Annual Stress Tests Required under the Dodd-Frank Act Stress Testing Rules and the Capital Plan Rule.
6.
Board of Governors of the Federal Reserve System. (October 2014). Comprehensive Capital Analysis and Review 2015 Summary Instructions and Guidance, Section 8.
7.
Economic Research Division, Federal Reserve Bank of St. Louis. (March 2019). Retrieved from the Federal Reserve Bank of St. Louis website: https://fred.stlouisfed.org/series/GS10.
8.
FedPrimeRate.com. (March 2019). Retrieved from the FedPrimeRate.com website: http://www.fedprimerate.com/mortgage_rates.htm.
9.
FragosoT. M., & NetoF. L. (2015). Bayesian model averaging: A systematic review and conceptual classification. arXiv:1509.08864v1.
10.
GeorgeE. I., & McCullochR. E. (1993). Variable selection via Gibbs sampling. Journal of the American Statistical Association88(423), 881-889.
11.
GeorgeE. I., & McCullochR. E. (1997). Approaches for Bayesian variable selection. Statistica Sinica7(2), 339-373.
12.
HastieT.TibshiraniR., & FriedmanJ. (2001). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer.
13.
IvakhnenkoA. G., & MadalaH. R. (1994). Inductive learning algorithms for complex systems modeling, CRC Press.
14.
LadyzhetsV. (2012). What unemployment data can tell us about house prices: stabilizing a strong but unstable connection. in: 2012 Proceedings of the American Statistical Association, 1042-1053.
15.
LandA. H., & DoigA. G. (1960). An automatic method of solving discrete programming problems. Econometrica, 28(3), 497-520.
16.
LeoM.SharmaS., & MadduletyK. (2019). Machine Learning in Banking Risk Management: A Literature Review. Risks7(29), 1-22.
17.
MandelI. (1988). Cluster Analysis (Klasternyj analiz). Moscow: Finance and Statistics.
18.
MandelI. (2014). Three and one questions to Dr. Mirkin about complexity statistics. In Clusters, Orders, and Trees: Methods and Applications (Eds: Aleskerov, F., Goldengorin, B., & Pardalos, P.) Springer, 1-12.
19.
MehlhornK., & SandersP. (2008). Algorithms and Data Structures: The Basic Toolbox. Springer.
20.
Operational Riskdata eXchange Association (ORX). (March 2019). Retrieved from the association website: https://managingrisktogether.orx.org/about.
21.
YoungA. (1997). A Morgan Stanley Guide to Fixed Income Analysis. New York: Morgan Stanley.