
Abstract
Spatial panel data model captures spatial interactions across spatial units and over time. Lots of effort have been devoted to develop effective estimation methods for parametric and nonparametric spatial panel data models. Varying coefficient model has received a great deal of attention as an important tool for modeling panel data. In this paper we propose a kernel-based spatial error model for the purpose of analyzing spatial panel data. This model is based on the idea of fixed effect time-varying coefficient model and the kernel technique of support vector machine along with the technique of regularization. A generalized cross validation method is also considered for choosing the hyperparameters which affect the performance of the proposed model. The proposed model is evaluated through numerical studies.
Keywords
Introduction
When analyzing house price data, we need to consider spatial heterogeneity and spatial dependence across spatial units and over time. Spatial panel data model allows for these two specific spatial aspects of spatial house price data. The analysis of spatial panel data is a field of econometrics. For recent developments of spatial panel data models see Andrews (2010); Baltagi and Liu (2008, 2011); Debarsy and Ertur (2010); Elhorst (2003); Lee and Yu (2010a, b, c); LeSage and Pace (2009); Millo and Piras (2012); Pesaran and Tosetti (2011), and references therein.
Under the cross-sectional setting, spatial lag model (SLM) and spatial error model (SEM) deal with interactions between spatial units. The panel literature has recently considered panel regression models with spatially autocorrelated disturbances as in SEM. The fixed and random effects SEM have been recently elaborated to deal with spatial panel data like house price data with spatial and temporal variations. In general, the fixed effects model is particularly desirable when the regression analysis is limited to a precise set of subjects such as regions and firms, whereas the random effects model is more appropriate if we draw a certain number of subjects randomly from a larger population of reference (Baltagi, 2001) Varying coefficient model has recently received a great deal of attention as an important tool for modeling standard panel data (Park et al., 2015). For this reason we propose a kernel-based SEM (KBSEM) by utilizing the idea of fixed effect time-varying coefficient model and the kernel technique of support vector machine (SVM) along with the technique of regularization.
We are going to illustrate the fixed effects SEM for spatial panel data. First we need to describe the basic idea of SEM. If we try to model a spatial error process by including a proximity-weighted error term, it ends up with an SEM. The starting point of SEM is the linear cross-sectional model
where
where
The standard fixed effects model for panel data is
where
where
where
For panel data Li et al. (2015) considered the following time-varying coefficients model (TVCM).
where
For analysis of spatial panel data we are going to propose the KBSEM using the kernel technique of SVM firstly developed by Vapnik (1995) and his group at AT&T Bell Laboratories. To the best of our knowledge, the VC approach has not been applied to SEM for modeling spatial panel data. The rest of this paper is organized as follows. Section 2 describes the KBSEM along with its model selection procedure. Section 3 and Section 4 present numerical studies and conclusion, respectively.
In this section we illustrate KBSEM with estimation and model selection procedures. The KBSEM is derived by applying spatial error term and the kernel technique of SVM to the TVCM (3) with fixed effects. We consider the balanced case
Estimation procedure
Given the training data set
where
We now assume that coefficient function
where
We consider the nonlinear case, in which the regression function given
With the weighted quadratic loss with regard to error term
subject to constraints
where
Then, by writing the constraints of the optimization problem (5) in a matrix notation, we can construct Lagrangian function for fixed
where
From the optimality conditions, we can get the followings:
where
After eliminating
where
For a point
and then the estimator of regression function takes the form:
We remark that
where
with
The solution to Eq. (8) cannot be obtained in a single step since unknown
Start with the initial value Calculate the solutions, Using
where Iterate steps 2 and 3 until convergence.
The estimation procedure is iterated until the following stop criterion is satisfied:
where the superscript
We now consider the model selection problem which determines the appropriate hyperparameters of the proposed KBSEM for spatial panel data. The functional structure of the proposed model is characterized by hyperparameters such as the regularization parameters
where
But the computational cost associated with CV function is formidable since
we have
Then the ordinary cross validation (OCV) function can be obtained as
Thus, the generalized cross validation (GCV) function can be obtained as
In fact, this GCV function Eq. (11) is utilized when determining the optimal value of
where the
where
In this section we investigate the estimation performance of the KBSEM for one synthetic example and one real example related to analyzing house price data. In these examples we compare the KBSEM with a spatial panel fixed effects model (SPFEM). The estimation of the SPFEM is performed by using splm module in R package. Throughout the paper, to determine the optimal parameters of the KBSEM we use the corresponding GCV function.
Synthetic example
In this example we conduct the simulation study on the efficacy of the proposed KBSEM, and compare our model with SPFEM. We use the following data generating process:
where
Performance comparison of the proposed KBSEM and SPFEM for the synthetic example (standard error in parenthesis)
Performance comparison of the proposed KBSEM and SPFEM for the synthetic example (standard error in parenthesis)
The synthetic region map.
For this example we generate 50 training and 50 test data sets. For each training data set and test data set we compute MSE with regard to
Data explanation
In order to estimate the hedonic house price function of the US, we set up 48 states and District of Columbia (DC) of the United States of America as targeting areas. At this, the reason that we restrict 48 states out of total 50 states is only because Alaska (AK) and Hawaii (HI) are located apart and noncontiguous from the main land of the US. We collect the data from various sources. First of all, we use housing price index (HPI) from Federal Housing Finance Agency as a dependent variable. According to Federal Housing Finance Agency, this data is broadly measured from the repeat sale prices average of single-family house prices, so that it seems to have sufficient representativeness for the movement of housing sale prices of the US.
On the other hand, we collect data focusing on the variables empirically proven by large literatures. At this, we only include collectable variables with panel data format out of the entire candidate variables. To begin with, it is well known that GDP or income are closely related to housing market (Davis & Heathcote, 2005; Iacoviello & Neri, 2010; Goodhart & Hofmann, 2008; Adams & Füss, 2010). In this regard, we use GDP in current dollars from Bureau of Economic Analysis and median household income by state (denoted as INCOME) from United States Census Bureau as independent variables. Besides, interest is also a well-known factor for determination of housing prices: especially, negative relationship. This is because rise of interest can make lessen the financing ability of the prospective buyers, so this explains that interest and housing prices are negatively related (Apergis & Rezitis, 2003; Anselin et al., 2010; Igan et al., 2011). In this context, this research uses mortgage interest rate (MIR) from Federal Housing Finance Agency as an another independent variable for estimating HPI.
Lastly, employment also functions as an important factor for the real estate activity of individuals (Lerbs, 2011; Giussani et al., 1993; Baffoe-Bonnie, 1998). Therefore, we set up employment status of the civilian noninstitutional population (denoted as EMP) from Bureau of Labor Statistics as the fourth independent variable. In regard of obtaining data, we set up time period from 1991 to 2015 in which data can be annually collected as many as possible. While there are only missing data on MIR in Oklahoma (OK) period 2005–2008 out of entire panel data. Hence, we fill in the missing data with the average value between 2004 and 2009 MIR values.
Estimation results
We now investigate the estimation performance of the KBSEM for house sales price data, for which the repeat sale prices average of single-family house prices is recorded from 1991 to 2015 in 48 states and District of Columbia (DC) of the United States of America. We now consider the parametric and nonparametric specifications for the hedonic price function and the estimation procedures. We compare the KBSEM with the SPFEM in terms of estimating regression function and fixed effects. We also report the estimation results for varying coefficient functions. For analysis, each independent variable and time variable are standardized using
Definition and description of the variables for house sales price data
Definition and description of the variables for house sales price data
Let
where
where
First we develop the SPFEM using the given data, which is then used to investigate estimation performance. The regression equation representing the average relationships of the spatial units between the level of housing price and four factors is presented in Table 3. We also examine MSE with regard to
The value of MSE of the SPFEM is 0.0752. These results indicate that the assessed house values can be modeled by the selected four variables. Therefore, the hypothesized relationships between the independent variables and the house values are supported by the data. Indeed, GDP, INCOME and EMP determinants are statistically significant at 95% confidence level according to their
Hedonic model (SPFEM) parameter estimate summaries
Hedonic model (KBSEM) parameter estimate summaries
The estimated 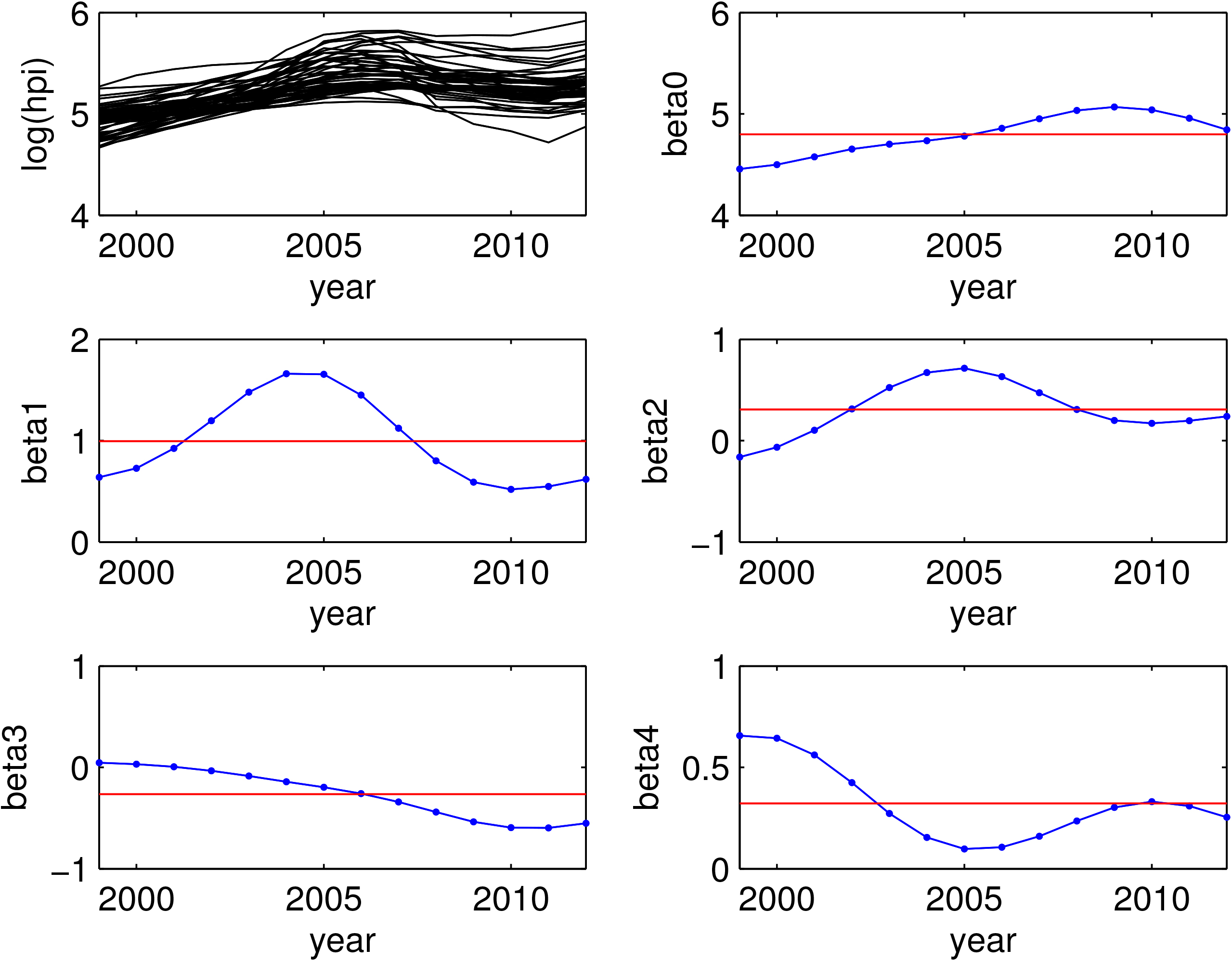
We now develop the KBSEM using the given data. The values of hyperparameters
The estimated values of spatial specific effects 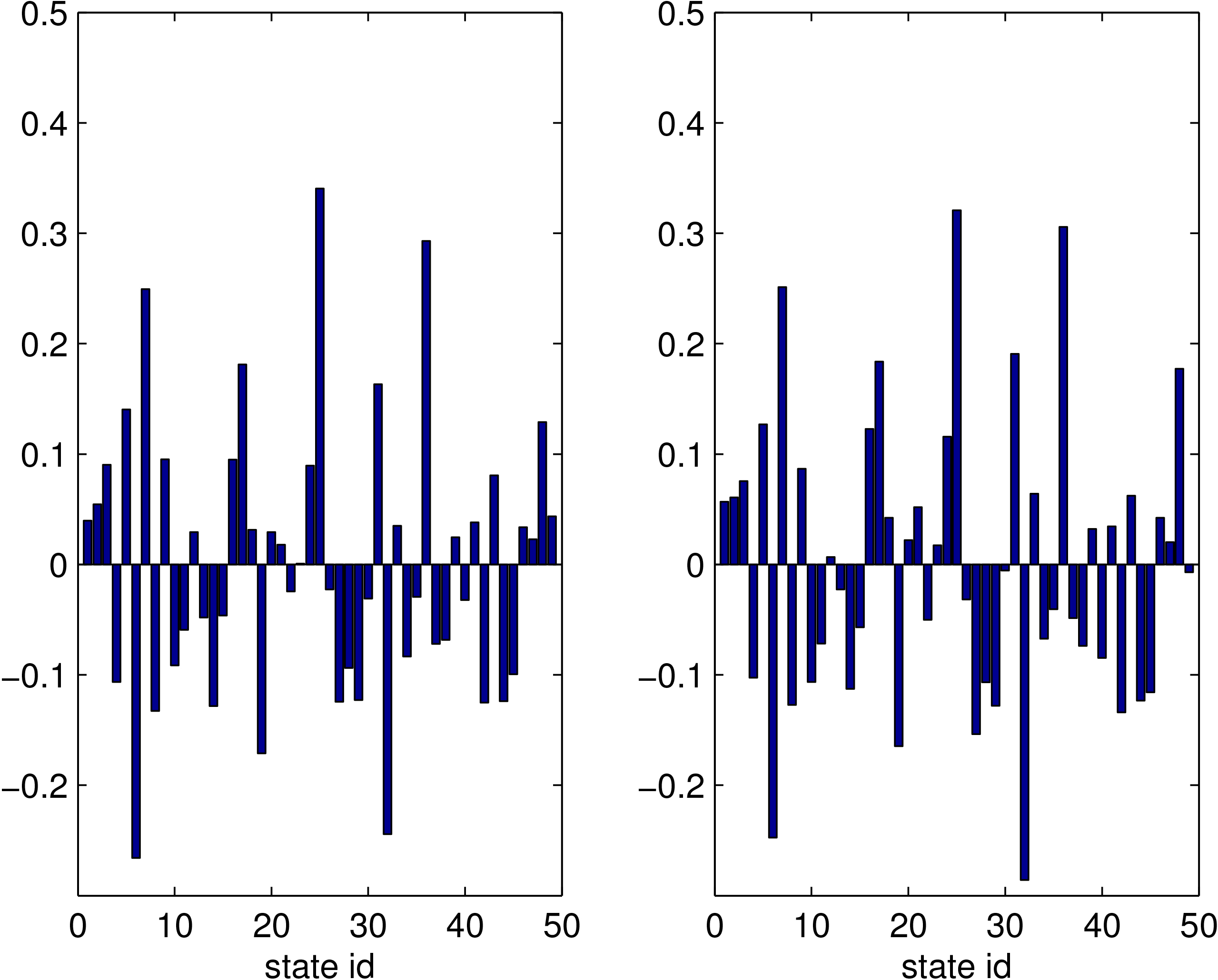
In this paper we proposed the KBSEM to account for spatial interactions across spatial units and over time that exist in the house prices. The underlying idea of the proposed KBSEM is that SEM is approximated by a combination of linear least squares SVM (LS-SVM) and nonlinear feature mapping function of the coordinate
This paper analyzed data incorporating spatial effects through error term and reflecting spatial interactions of house prices across spatial units and over time. The SPFEM and KBSEM used in the study were built based on synthetic data and house price data collected from 1991 to 2015 in 48 states and District of Columbia (DC) of the United States of America. The performances of these models were then compared based on MSE. This paper demonstrates that the proposed KBSEM provides good results in goodness of fit for the given two examples. To conclude, we proposed a more efficient KBSEM to capture spatial interactions across spatial units and over time.
Footnotes
Acknowledgments
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology with grant no. (NRF-2018R1D1A1B07042349). This research was supported by the Bio & Medical Technology Development Program of the National Research Foundation (NRF) funded by the Korean government (MSIT) (No. 2019M3E5D4066897). This research was supported by the Human Resources Program in Energy Technology of the Korea Institute of Energy Technology Evaluation and Planning (KETEP) granted financial resource from the Ministry of Trade, Industry & Energy, Republic of Korea (No. 20174030201740).