The new exponential power-G is introduced following Alzaatreh et al. (2013). Some of its main statistical properties are provided in terms of the exponentiated-G properties. Maximum likelihood estimation and simulations are addressed using the log-logistic for the baseline distribution. The log-exponential power log-logistic regression model is constructed and applied to censored data. The utility of the new models is proved by means of two real data sets.
Classical distributions, such as exponential, Weibull, Burr XII, log-logistic, normal, beta, and gamma, have been adopted to model data in various fields. Engineering, medicine, biology, and economics are just a few of them. However, with the progress of science, more flexible distributions have become mandatory.
Several studies have been conducted over the past three decades to construct new families by adding parameters to known distributions to achieve more flexibility. Among well-known generators, one can cite the Marshall-Olkin-G (Marshall & Olkin, 1997), exponentiated-G (Gupta et al., 1998), beta generated (Beta-G) (Eugene et al., 2002),, gamma-G (Zografos & Balakrishnan, 2009), Kumaraswamy-generalized (Kw-G) (Cordeiro & de Castro, 2011), McDonald-G (Mc-G) (Alexander et al., 2012), exponentiated generalized-G (Cordeiro et al., 2013), Transformed-Transformer (T-X) (Alzaatreh et al., 2013), Weibull-G (Bourguignon et al., 2014), Lomax-G (Cordeiro et al., 2014), Kumaraswamy odd log-logistic-G (Alizadeh et al., 2015), type I half-logistic-G (Cordeiro et al., 2016), generalized odd log-logistic-G (Cordeiro et al., 2017), transmuted Gompertz-G (Reyad et al., 2018), Kumaraswamy odd Lindley-G (Chipepa et al., 2019), modified Kies-G (Al-Babtain et al., 2020), and exponentiated Fréchet-G (Baharith and Alamoudi, 2021).
Let be the cumulative distribution function (cdf) of a random variable with parameter vector , and let be the cdf of any random variable depending on a parameter vector . The Transformed-Transformer (T-X) family cdf has the form (Alzaatreh et al., 2013)
The cdf and probability density function (pdf) of the exponential power (EP) distribution (Smith & Bain, 1975) with two parameters (for ) are, respectively,
and
If has the cdf Eq. (2), the exponential power-G (EP-G) family cdf follows from Eq. (1) as
By differentiating Eq. (3), the EP-G density reduces to
where .
The hazard rate function (hrf) corresponding to Eq. (4) has the form
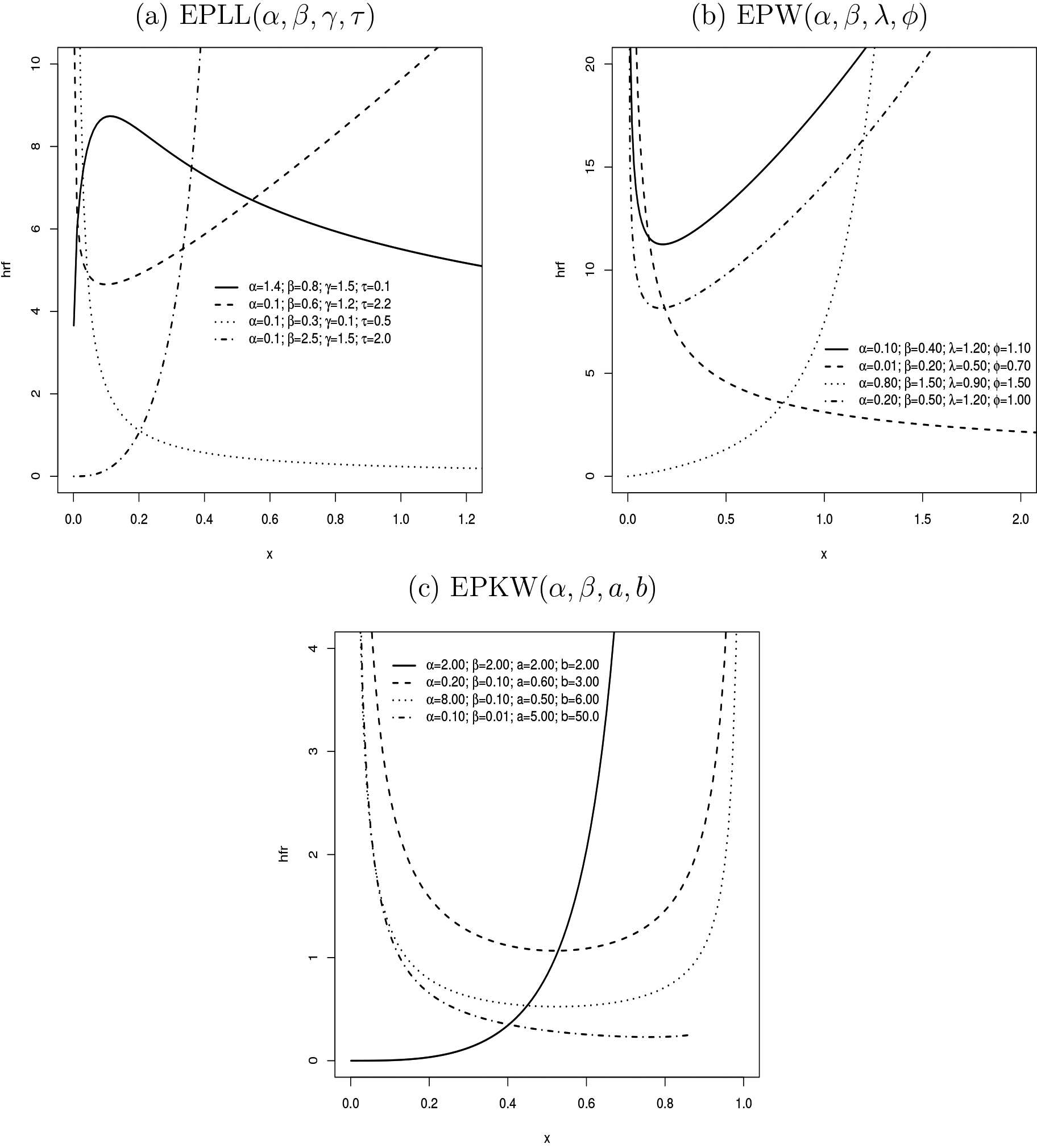
Henceforth, denotes a random variable with pdf Eq. (4), which has excellent flexibility and different hrf shapes, including the bathtub-shaped in Fig. 2, where the Weibull and log-logistic distributions do not have this shape.
The remainder of the article is structured as follows: Section 2 provides three EP-G sub-models. A linear representation for the pdf family Eq. (4) is derived in Section 3, and some of its structural properties are addressed in Section 4. The estimation of the parameters and a new regression model are reported in Sections 5 and 6, respectively. A simulation study is presented in Section 7. The potentiality of the new models is illustrated in two real-data applications in Section 8, and some conclusions are offered in Section 9.
Special distributions
This section provides three EP-G sub-models. All calculations are done using the R software (R Core Team, 2020).
Exponential power log-logistic (EPLL)
Consider the baseline log-logistic (LL) with two parameters and cdf (for )
Then, the pdf from Eq. (4) and hrf of the EPLL model are
and
respectively.
Exponential power Weibull (EPW)
The Weibull cdf with parameters is (for )
Thus, the EPW density can be obtained from Eq. (4) as
and its corresponding hrf has the form
Exponential power Kumaraswamy (EPKW)
The Kumaraswamy cdf (for , ) is
Then, the pdf and hrf of the EPKW model are
and
respectively.
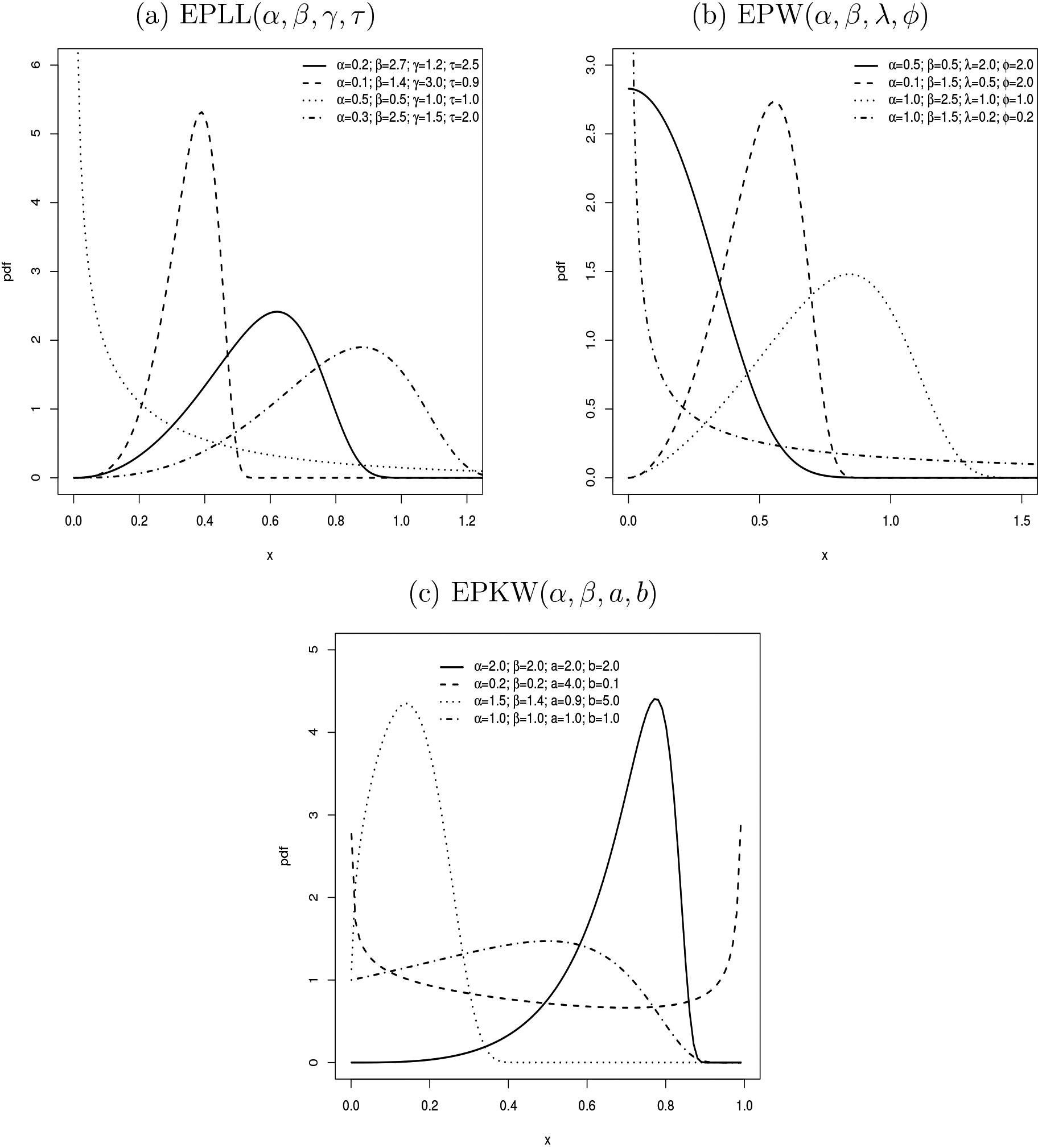
Figure 1 displays the EPLL, EPW, and EPKW densities for some parameters, which can model symmetric, right-skewed, and left-skewed data. Their hrfs are reported in Fig. 2, which have different shapes, including the bathtub-shaped.
Some EP-G density shapes.
Some EP-G hazard rate shapes.
Linear representation
Firstly, using Taylor expansion, the cdf of the EP-G family in Eq. (3) can be expressed as
Applying the binomial theorem to ,
Again, using Taylor expansion in ,
From the proposition 2 of Castellares and Lemonte (2015), we can written
where , , , for , and the quantities , , , etc., are the Stirling polynomials.
For any arbitrary , the density of the exponentiated-G class (exp-G) with power parameter is defined as
See Table 1 of Tahir and Nadarajah (2015) for properties of various published distributions in the exp-G class, including well-known models such as exp-Weibull (Mudholkar & Srivastava, 1993), exp-gamma (Nadarajah & Gupta, 2007), and exp-Fréchet (Nadarajah and Kotz, 2003).
Replacing by and rearranging the terms in Eq. (8),
where
By differentiating Eq. (9), the pdf of the EP-G family takes the form
where is the exp-G density with power .
Hence, some mathematical properties of the EP-G family can be determined from Eq. (10) and those of the exp-G class.
Main properties
The quantile function (qf) of follows by inverting Eq. (3) as (for )
where is the baseline qf. So, the EP-G observations for given can be easily generated from Eq. (11). Further, the Bowley skewness (Kenney & Keeping, 1962) and Moors kurtosis (Moors, 1988) of this family are
and
respectively. Plots of these measures for the EPLL distribution as functions of ( and fixed and ) reported in Fig. 3 show that both measures decrease when increases.
Bowley skewness and Moors kurtosis of the EPLL distribution.
The th ordinary moment of is . We can write from Eq. (10)
where denotes the exp-G random variable.
The th incomplete moment of follows from Eq. (10) as
For a given probability , the Bonferroni and Lorenz curves are
respectively, where is determined from Eq. (11). Plots of these curves for the EPLL distribution versus for specific values of and ( and ) are reported in Fig. 4.
Bonferroni and Lorenz curves of the EPLL distribution.
The generating function (gf) of can be determined from Eq. (10) as
where is the gf of .
Estimation
The parameters of the new family are estimated utilizing the maximum likelihood method. Let be independent and identically distributed (iid) observations from the pdf Eq. (4). Then, the log-likelihood function for is
The maximum likelihood estimate (MLE) can be determined by maximizing numerically Eq. (12) using the functions optim, MaxBFGS, or PROC NLMIXED in R, Ox, or SAS software, respectively.
Regression
Here, the log-exponential power log-logistic (LEPLL) random variable is defined by the transformation , where has pdf Eq. (5). The LEPLL density reparameterized by and has the form
where and . Equation (13) has the location-scale form, where and are location and scale parameters, respectively. Therefore, if , then .
The survival function referring to Eq. (13) and the density of are
and
Equation (14) is the standard LEPLL density. In addition, we construct a regression model for the response variable and the explanatory variable vector based on Eq. (13) as
where , is the vector of unknown coefficients, and is the random error with density function Eq. (14).
The survival and density functions of are
and
respectively, where .
Let be the lifetime and be the non-informative censoring time, assuming that and are independent random variables, and . The log-likelihood function for from the regression model Eq. (15) (for right censored data) has the form
where is the number of failures, and are sets of uncensored and censored observations, respectively. Equation (16) reduces to the usual log-likelihood for and .
The MLE of is calculated by maximizing numerically Eq. (16) using R, Ox, or SAS software.
Simulations
A first simulation study is done to check the accuracy of the MLEs in the EPLL distribution under three different scenarios. We perform one thousand Monte Carlo trials using the log-logistic qf in Eq. (11) for four sample sizes . The average estimates (AEs), biases, and mean squared errors (MSEs) calculated in Table 1 show that the AEs converge to the true values of the parameters and that the biases and MSEs tend to zero when increases.
Simulation results from the EPLL distribution
(1.8, 0.4, 5.3, 7.8)
(1.7, 0.6, 1.6, 0.3)
(2.0, 0.8, 1.7, 0.2)
Par
AE
Bias
MSE
AE
Bias
MSE
AE
Bias
MSE
50
3
.358
1
.558
23
.710
3
.654
1
.954
26
.249
5
.097
3
.097
49
.876
0
.662
0
.262
0
.379
1
.103
0
.503
0
.962
1
.362
0
.562
1
.189
5
.879
0
.579
8
.040
1
.963
0
.363
1
.838
2
.576
0
.876
4
.464
6
.938
0
.861
8
.090
0
.267
0
.032
0
.110
0
.179
0
.020
0
.050
ANI
31.7077
31.3941
33.5482
100
2
.357
0
.557
5
.901
2
.395
0
.695
5
.004
3
.287
1
.287
13
.443
0
.542
0
.142
0
.138
0
.889
0
.289
0
.386
1
.133
0
.333
0
.513
5
.361
0
.061
3
.442
1
.689
0
.089
0
.586
2
.013
0
.313
1
.129
7
.156
0
.643
4
.107
0
.274
0
.025
0
.061
0
.182
0
.017
0
.024
ANI
16.4643
18.6651
18.3673
200
1
.939
0
.139
0
.358
1
.956
0
.256
0
.613
2
.449
0
.449
1
.906
0
.451
0
.051
0
.020
0
.738
0
.138
0
.123
0
.982
0
.182
0
.212
5
.239
0
.060
1
.389
1
.597
0
.002
0
.204
1
.768
0
.068
0
.258
7
.498
0
.301
0
.006
0
.275
0
.024
0
.027
0
.183
0
.016
0
.013
ANI
7.8456
12.6940
14.5364
500
1
.852
0
.052
0
.126
1
.786
0
.086
0
.165
2
.142
0
.142
0
.288
0
.421
0
.026
0
.006
0
.652
0
.052
0
.031
0
.876
0
.076
0
.064
5
.252
0
.047
0
.538
1
.586
0
.013
0
.074
1
.702
0
.002
0
.079
7
.680
0
.119
0
.546
0
.289
0
.010
0
.011
0
.191
0
.008
0
.005
ANI
6.6297
9.3544
11.7072
For the second simulation, the observations are generated from , where , and is obtained from a uniform distribution. The precision of the MLEs is investigated for samples by taking , , and , and . A uniform distribution is also used to generate the censoring times , where determines the censoring percentage (0%, 10%, 30%). The censoring indicator if and otherwise, and provides the observed times.
Simulation results from the LEPLL regression model
0%
10%
30%
Par
AE
Bias
MSE
AE
Bias
MSE
AE
Bias
MSE
50
2
.370
0
.570
4
.928
2
.420
0
.620
5
.697
2
.752
0
.952
12
.942
0
.588
0
.188
0
.287
0
.560
0
.160
0
.414
0
.524
0
.124
0
.803
0
.690
0
.090
0
.278
0
.635
0
.035
0
.368
0
.603
0
.003
1
.002
1
.261
0
.438
2
.458
1
.367
0
.332
2
.812
1
.571
0
.128
3
.151
0
.195
0
.004
1
.183
0
.227
0
.027
1
.152
0
.244
0
.044
1
.080
ANI
36.855
36.863
35.365
100
2
.058
0
.258
1
.238
2
.173
0
.373
1
.977
2
.374
0
.574
4
.317
0
.508
0
.108
0
.108
0
.560
0
.160
0
.238
0
.578
0
.178
0
.433
0
.657
0
.057
0
.085
0
.671
0
.071
0
.139
0
.664
0
.064
0
.329
1
.403
0
.296
1
.185
1
.301
0
.398
2
.116
1
.295
0
.404
2
.683
0
.179
0
.020
0
.532
0
.169
0
.030
0
.649
0
.184
0
.015
0
.664
ANI
14.225
21.724
25.760
200
1
.936
0
.136
0
.462
1
.967
0
.167
0
.657
2
.071
0
.271
0
.983
0
.443
0
.043
0
.027
0
.470
0
.070
0
.062
0
.515
0
.115
0
.175
0
.622
0
.022
0
.022
0
.640
0
.040
0
.047
0
.656
0
.056
0
.114
1
.552
0
.147
0
.413
1
.491
0
.208
0
.657
1
.381
0
.318
1
.277
0
.199
0
.000
0
.226
0
.185
0
.014
0
.266
0
.176
0
.023
0
.341
ANI
7.667
8.393
10.559
500
1
.832
0
.032
0
.132
1
.835
0
.035
0
.159
1
.853
0
.053
0
.223
0
.417
0
.017
0
.006
0
.426
0
.026
0
.012
0
.435
0
.035
0
.027
0
.613
0
.013
0
.008
0
.620
0
.020
0
.016
0
.626
0
.026
0
.035
1
.654
0
.045
0
.121
1
.629
0
.070
0
.168
1
.612
0
.087
0
.236
0
.198
0
.001
0
.084
0
.206
0
.006
0
.091
0
.207
0
.007
0
.101
ANI
7.166
7.304
8.182
The findings in Table 2 reveal that the AEs converge to the true parameter values and the biases and MSEs decay when increases, thus proving the consistency of the estimators. In general, the AEs, biases, and MSEs become larger as increases.
These simulations were performed using a script in R with the function optim using the quasi-Newton method (BFGS), which has a maximum limit of 100 interactions by default. We calculate the average number of interactions (ANI) at each sample size considering the scenarios in Tables 1 and 2, which indicate that the ANI decreases when increases and that the ANI increases when the censoring percentage increases. The choice of the parameters for the distribution is done in order to achieve a faster simulation speed. The simulation process is slower when the parameters and .
Applications
The potential of the proposed family is evaluated on two data sets for the log-logistic as the baseline distribution. The Cramér-von Mises , Anderson-Darling , Akaike information criterion (AIC), Consistent Akaike information criterion (CAIC), Bayesian information criterion (BIC), Hannan-Quinn information criterion (HQIC), and Kolmogorov-Smirnov (KS) (with its -value) are chosen to compare the fitted models. All calculations in Section 8.1 are determined via the AdequacyModel package (Marinho et al., 2019) in R software, and the optim function is used in a script in R to produce all the results in Section 8.2.
COVID-19 data
The data set corresponds to the recovery times (in days) of patients diagnosed with COVID-19 in the city of Cuiabá (Brazil) in 2020. This study consists of 70 infected individuals confirmed by laboratory tests. The recovery time is defined as the period between the onset of symptoms and the cure of the disease. This data set are: 34, 33, 43, 33, 75, 33, 47, 48, 52, 53, 56, 41, 58, 58, 37, 55, 31, 59, 43, 43, 42, 43, 43, 30, 63, 32, 30, 30, 26, 43, 82, 31, 69, 32, 45, 45, 35, 34, 37, 64, 25, 28, 71, 62, 34, 44, 53, 47, 74, 42, 54, 27, 49, 44, 65, 44, 45, 50, 70, 71, 37, 66, 67, 36, 53, 37, 47, 37, 42, 32. See http://www.saude.mt.gov.br/painelcovidmt2.
Some descriptive statistics for these data include: mean 46.30, median 43.50, standard deviation 13.78, skewness 0.60, kurtosis 2.49, minimum 25, and maximum 82.
Next, the EPLL distribution is compared with seven other models widely studied in the literature, namely, the beta log-logistic (BLL) (Lemonte, 2014), Kumaraswamy log-logistic (KLL) (De Santana et al., 2012), beta Weibull (BW) (Lee et al., 2007), Kumaraswamy Weibull (KW) (Cordeiro et al., 2010), gamma Burr XII (GBXII) (Guerra et al., 2017), gamma log-logistic (GLL) (Ramos et al., 2013), and gamma Weibull (GW) (Nadarajah et al., 2015) models.
Findings from the fitted models to COVID-19 data
Model
MLEs (SEs)
EPLL
25.22
1.65
28.25
24.18
(1.12)
(0.17)
(0.02)
(0.01)
BLL
31.41
9.49
1.28
17.01
(86.86)
(20.97)
(1.34)
(39.81)
KLL
30.36
5.07
1.86
10.53
(73.74)
(6.39)
(0.93)
(16.83)
BW
28.14
0.12
0.06
2.11
(11.58)
(0.02)
(0.01)
(0.05)
KW
7.07
0.14
2.61
0.04
(0.06)
(0.04)
(0.02)
(0.01)
GBXII
18.92
9.47
1.54
12.14
(2.10)
(0.22)
(0.17)
(0.20)
GLL
18.58
12.27
14.46
(0.84)
(0.50)
(0.39)
GW
18.36
0.79
1.18
(1.93)
(0.04)
(0.27)
Table 3 lists the MLEs and their respective standard errors (SEs) in parentheses of the fitted distributions to the current data. The estimates are accurate for the EPLL, BW, KW, GBXII, GLL, and GW distributions. In contrast, the SEs for the BLL and KLL distributions are higher compared to their estimates. The EPLL distribution has the lowest values of the adequacy measures in Table 4.
Some measures of the fitted models to COVID-19 data
Model
AIC
CAIC
BIC
HQIC
KS
-value
EPLL
0.05
0.30
560.39
561.00
569.38
563.96
0.07
0.89
BW
0.06
0.32
561.66
562.27
570.65
565.23
0.08
0.74
KW
0.07
0.45
563.49
564.11
572.49
567.07
0.09
0.60
GBXII
0.07
0.46
565.12
565.74
574.12
568.69
0.08
0.69
GLL
0.07
0.46
563.48
563.49
569.87
565.80
0.08
0.68
GW
0.09
0.61
564.56
564.93
571.31
567.25
0.09
0.56
Findings from the fitted regression to AIDS data and the adequacy measures
LEPLL
LGL
Logistic
Parameter
MLE (SE)
MLE (SE)
MLE (SE)
0
.90 (0.34)
()
()
0
.18 (0.03)
0
.69 (0.10)
()
0
.20 (0.03)
0
.84 (0.22)
0
.74 (0.06)
7
.88* (0.05)
7
.30* (0.44)
7
.08* (0.28)
1
.17* (0.03)
1
.16* (0.17)
1
.16* (0.17)
1
.23* (0.05)
1
.17* (0.18)
1
.17* (0.18)
AIC
410.58
410.94
411.31
CAIC
411.03
411.72
412.10
BIC
423.63
430.51
430.89
HQIC
415.86
418.86
419.24
-value 0.0001.
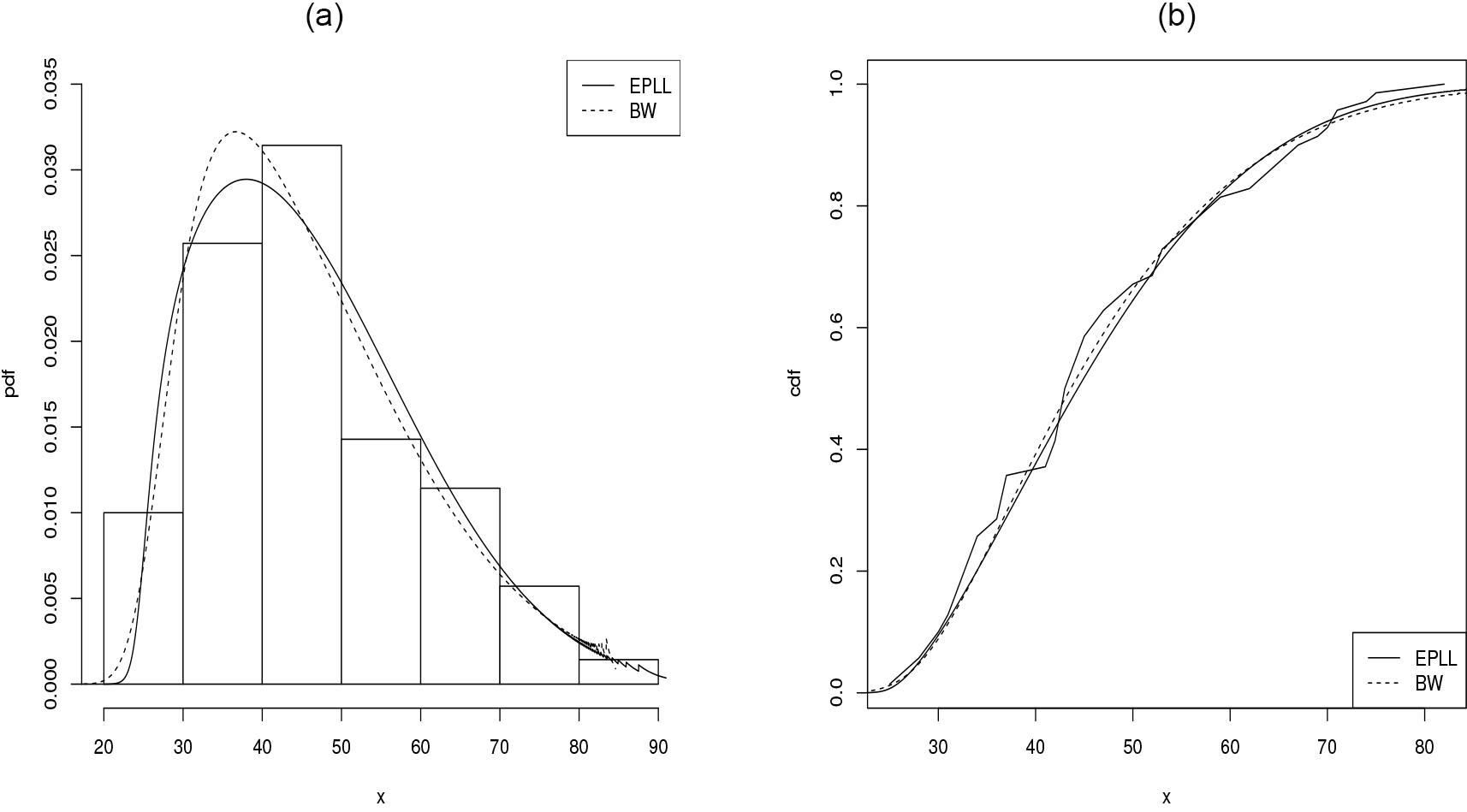
Figure 5 shows that the estimated pdf and cdf of the EPLL distribution are closer to the histogram and the empirical cdf, respectively. Based on these results, the EPLL distribution provides the best fit for these data.
(a) Estimated pdfs, (b) estimated cdfs and the empirical cdf.
AIDS data
We consider 193 individuals diagnosed with AIDS treated at the Instituto de Pesquisa Clínica Evandro Chagas (IPEC-FIOCRUZ) between 1986 and 2002. These data can be downloaded directly from the link http://sobrevida. fiocruz.br/aidsclassico.html. The analysis does not include individuals younger than 13 years of age or with less than 15 days of follow-up. See Campos et al. (2005) for a complete exploratory data analysis.
Survival time (in months) is the period elapsed from the date of AIDS diagnosis to the date of death (failure) or last attendance. Deaths not related to AIDS were considered censoring times (0 censored and 1 observed lifetime). The censoring percentage is 53.33%. The explanatory variable denotes the antiretroviral therapy (0 none, 1 mono, 2 combined, 3 potent) and the explanatory variable represents the type of follow-up (0 outpatient/day hospital, 1 later admission, 2 immediate admission).
The proposed regression model for these data has the form
where has density Eq. (14). The results are compared with the log-gamma logistic (Hashimoto et al., 2017) and logistic regression models. Table 5 provides the MLEs, SEs in parentheses, -values, and adequacy measures for the three regression models fitted to the AIDS data. The estimates determined by the three regression models are accurate. The explanatory variables and are statistically significant for all models, thus meaning that antiretroviral therapy tends to prolong the failure times of patients. On the other hand, the negative sign of indicates that the greater the need for admission, the shorter the failure time.
The adequacy measures indicate that the LEPLL regression model is the best model among the three. Further, we use the generalized LR test (GLR) ((Vuong, 1989)) given by
where
is an estimate of the variance of Eq. (17), and correspond to the estimated densities. If , . Thus, the null hypothesis is not rejected at significance level if . In the first case, and denote the LEPLL and LGL regressions, respectively, which yields . In the second case, and are the LEPLL and logistic regressions, respectively, yielding . Therefore, the null hypothesis is rejected for in favor of the LEPLL regression in both cases, confirming the results of Table 5.
For a residual analysis of this fitted regression, we adopt the quantile residuals (qrs) (Dunn & Smyth, 1996), namely
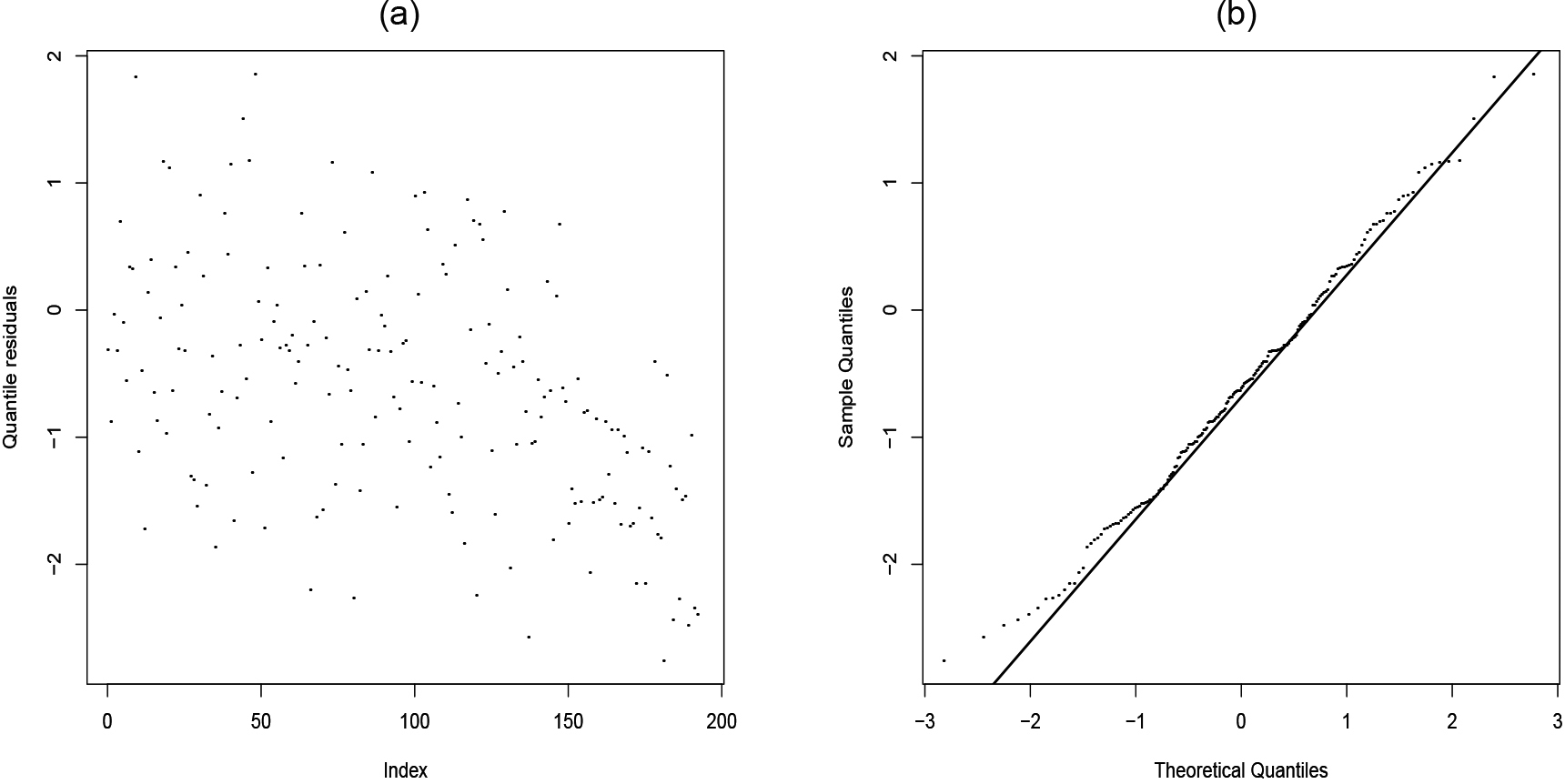
where is the standard normal qf and . The residual index plot reported in Fig. 6(a) reveals that the qrs are randomly distributed and that no observations are outside the [3.3] range. The normal probability plot for the qrs in Fig. 6(b) indicates that the residuals approximately follow a standard normal distribution. Hence, there is no evidence against the LEPLL regression assumptions for this data set.
(a) Index plot and (b) normal probability plot of the qrs.
Conclusions
We defined the exponential power-G family of distributions and discussed some of its mathematical properties. Also, we constructed a new log-exponential power log-logistic regression model. The simulation results reveal that the maximum likelihood estimators are consistent. Two applications to real data indicated that the new models obtained by the new family of distributions are competitive compared to the models generated by the beta-G, gamma-G, and Kumaraswamy-G generators. As a result, this new family can generate promising distributions and may be attractive for practical applications in other areas.
Footnotes
Acknowledgments
This work was supported by the Fundação de Amparo C̀iência e Tecnologia do Estado de Pernambuco (FACEPE) [IBPG-1448-1.02/20]. The authors thank the associate editor and the anonymous referees for some comments that improved the original version of the paper.
References
1.
Al-BabtainA. A.ShakhatrehM. K.NassarM., & AfifyA. Z. (2020). A new modified Kies family: Properties, estimation under complete and type-II censored samples, and engineering applications. Mathematics, 8, 1345.
2.
AlexanderC.CordeiroG. M.OrtegaE. M. M., & SarabiaJ. (2012). Generalized beta-generated distributions. Computational Statistics & Data Analysis, 56, 1880-1897.
3.
AlizadehM.EmadiM.DoostparastM.CordeiroG. M.OrtegaE. M. M., & PescimR. R. (2015). A new family of distributions: the kumaraswamy odd log-logistic, properties and applications. Hacettepe Journal of Mathematics and Statistics, 44, 1491-1512. Alzaatreh et al., 2013 Alzaatreh, A., Lee, C., & Famoye, F. (2013). A new method for generating families of continuous distributions. METRON, 71, 63-79. Baharith and Alamoudi, 2021 Baharith, L. A., & Alamoudi, H. H. (2021). The Exponentiated Fréchet Generator of Distributions with Applications. Symmetry, 13, 572. Bourguignon et al., 2014 Bourguignon, M., Silva, R., & Cordeiro, G. M. (2014). The Weibull-G Family of Probability Distributions. Journal of Data Science, 12, 53-68. Campos et al., 2005 Campos, D. P., Ribeiro, S. R., Grinsztejn, B., Veloso, V. G., Valente, J. G., Bastos, F. I., Morgado, M. G., & Gadelha, A. J. (2005). Survival of AIDS patients using two case definitions, Rio de Janeiro, Brazil, 1986-2003. Aids, 19, S22-S26. Castellares and Lemonte, 2015 Castellares, F., & Lemonte, A. J. (2015). A new generalized Weibull distribution generated by gamma random variables. Journal of the Egyptian Mathematical Society, 23, 382-390. Chipepa et al., 2019 Chipepa, F., Oluyede, B. O., & Makubate, B. (2019). A new generalized family of odd Lindley-G distributions with application. International Journal of Statistics and Probability, 8, 1-22. Cordeiro et al., 2016 Cordeiro, G. M., Alizadeh, M., & Marinho, P. R. D. (2016). The type I half-logistic family of distributions. Journal of Statistical Computation and Simulation, 86, 707-728. Cordeiro et al., 2017 Cordeiro, G. M., Alizadeh, M., Ozel, G., Hosseini, B., Ortega, E. M. M., & Altun, E. (2017). The generalized odd log-logistic family of distributions: properties, regression models and applications. Journal of Statistical Computation and Simulation, 87, 908-932. Cordeiro and de Castro, 2011 Cordeiro, G. M., & de Castro, M. (2011). A new family of generalized distributions. Journal of Statistical Computation and Simulation, 81, 883-898. Cordeiro et al., 2013 Cordeiro, G. M., Ortega, E. M. M., & Cunha, D. C. C. (2013). The exponentiated generalized class of distributions. Journal of Data Science, 11, 1-27. Cordeiro et al., 2010 Cordeiro, G. M., Ortega, E. M. M., & Nadarajah, S. (2010). The Kumaraswamy Weibull distribution with application to failure data. Journal of the Franklin Institute, 347, 1399-1429. Cordeiro et al., 2014 Cordeiro, G. M., Ortega, E. M. M., Popović, B. V., & Pescim, R. R. (2014). The Lomax generator of distributions: Properties, minification process and regression model. Applied Mathematics and Computation, 247, 465-486. De Santana et al., 2012 De Santana, T. V. F., Ortega, E. M. M., Cordeiro, G. M., & Silva, G. O. (2012). The Kumaraswamy-log-logistic distribution. Journal of Statistical Theory and Applications, 11, 265-291. Dunn and Smyth, 1996 Dunn, P. K., & Smyth, G. K. (1996). Randomized quantile residuals. Journal of Computational and Graphical Statistics, 5, 236-244. Eugene et al., 2002 Eugene, N., Lee, C., & Famoye, F. (2002). Beta-normal distribution and its applications. Communications in Statistics – Theory and Methods, 31, 497-512. Guerra et al., 2017 Guerra, R. R., Peña-Ramírez, F. A., & Cordeiro, G. M. (2017). The gamma Burr XII Distributions: Theory and Applications. Journal of Data Science, 15, 467-494. Gupta et al., 1998 Gupta, R. C., Gupta, P. L., & Gupta, R. D. (1998). Modeling failure time data by lehman alternatives. Communications in Statistics – Theory and Methods, 27, 887-904. Hashimoto et al., 2017 Hashimoto, E. M., Ortega, E. M. M., Cordeiro, G. M., & Hamedani, G. (2017). The log-gamma-logistic regression model: Estimation, sensibility and residual analysis. Journal of Statistical Theory and Applications, 16, 547-564. Kenney and Keeping, 1962 Kenney, J., & Keeping, E. (1962). Moving averages. 3 edn. NJ: Van Nostrand. Lee et al., 2007 Lee, C., Famoye, F., & Olumolade, O. (2007). Beta-Weibull distribution: some properties and applications to censored data. Journal of Modern Applied Statistical Methods, 6, 17. Lemonte, 2014 Lemonte, A. J. (2014). The beta log-logistic distribution. Brazilian Journal of Probability and Statistics, 28, 313-332. Marinho et al., 2019 Marinho, P. R. D., Silva, R. B., Bourguignon, M., Cordeiro, G. M., & Nadarajah, S. (2019). AdequacyModel: An R package for probability distributions and general purpose optimization. PLOS ONE, 14, 1-30. Marshall and Olkin, 1997 Marshall, A. W., & Olkin, I. (1997). A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika, 84, 641-652. Moors, 1988 Moors, J. J. A. (1988). A quantile alternative for kurtosis. Journal of the Royal Statistical Society. Series D (The Statistician), 37, 25-32. Mudholkar and Srivastava, 1993 Mudholkar, G. S., & Srivastava, D. K. (1993). Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Transactions on Reliability, 42, 299-302. Nadarajah et al., 2015 Nadarajah, S., Cordeiro, G. M., & Ortega, E. M. M. (2015). The Zografos–Balakrishnan-G family of distributions: Mathematical properties and applications. Communications in Statistics – Theory and Methods, 44, 186-215. Nadarajah and Gupta, 2007 Nadarajah, S., & Gupta, A. K. (2007). The exponentiated gamma distribution with application to drought data. Calcutta Statistical Association Bulletin, 59, 29-54. Nadarajah and Kotz, 2003 Nadarajah, S., & Kotz, S. (2003). The exponentiated Fréchet distribution. Interstat Electronic Journal, 14, 1-7. R Core Team, 2020 R Core Team (2020). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria.
4.
RamosM. W. A.CordeiroG. M.MarinhoP. R. D.DiasC. R. B., & HamedaniG. (2013). The Zografos-Balakrishnan Log-Logistic Distribution: Properties and Applications. Journal of Statistical Theory and Applications, 12, 225-244.
5.
ReyadH.JamalF.OthmanS., & HamedaniG. (2018). The transmuted Gompertz-G family of distributions: properties and applications. Tbilisi Mathematical Journal, 11, 47-67.
6.
SmithR. M., & BainL. J. (1975). An exponential power life-testing distribution. Communications in Statistics, 4, 469-481.
7.
TahirM. H., & NadarajahS. (2015). Parameter induction in continuous univariate distributions: Well-established G families. Anais da Academia Brasileira de Ciências, 87, 539-568.
8.
VuongQ. H. (1989). Likelihood ratio tests for model selection and non-nested hypotheses. Econometrica, 57, 307-333.
9.
ZografosK., & BalakrishnanN. (2009). On families of beta-and generalized gamma-generated distributions and associated inference. Statistical Methodology, 6, 344-362.