
Abstract
Knowing stability constants for the complexes HgII with extracting ligands is very important from environmental and therapeutic standpoints. Since the selectivity of ligands can be stated by the stability constants of cation–ligand complexes, quantitative structure–property relationship (QSPR) investigations on binding constant of HgII complexes were done. Experimental data of the stability constants in ML2 complexation of HgII and synthesized triazene ligands were used to construct and develop QSPR models. Support vector machine (SVM) and multiple linear regression (MLR) have been employed to create the QSPR models. The final model showed squared correlation coefficient of 0.917 and the standard error of calibration (SEC) value of 0.141 log K units. The proposed model presented accurate prediction with the Leave-One-Out cross validation (
Introduction
Mercury is one of the most dangerous heavy metals found in nature’s trace elements, and it has a high toxicity to the environment and microorganisms even at low doses. It is a carcinogen, teratogen, and mutagen with no known biological roles and considerable health effects [1, 2]. Similarly, HgII is hazardous in the same way as mercury metal is, but methylmercury, a neurotoxin that is biomagnified through the food chain from marine species to humans, is the most harmful. The toxicity of mercury is highly altered by organic ligands during complexation, and chronic or acute mercury poisoning by chelating agents has been studied in HgII complexes [3–5]. Furthermore, the binding of HgII to natural organic matter has a major influence on biological availability of HgII in ecosystems [6] which limits the availability of methylating bacteria to HgII [7]. From an environmental and medicinal aspect, knowing the stability constants for HgII complexes with extracting ligands is critical.
Triazenes are relatively old compounds, which defined by containing a diazoamino functional group (–N–N = N–). These compounds have been analyzed for over 150 years regarding their interesting activity [8]. The research of transition-metal complexes containing substituted triazene ligands has increased substantially in recent years due to the reactivity potential of these ligands. Substituted triazenes have recently gotten a lot of attention because of their anti-tumor, information-storage, and insecticide properties [9]. Triazenes have the ability to bind to mercury ions, and the resulting compounds are moisture and air resistant. However, a spectrophotometric analysis of complexation between HgII and triazene ligands in acetonitrile revealed that the HgII ion complex has a high stability binding constant. the complex stability constant (here log KHgII - triazene) expresses the ligand’s selectivity for the ion. As a result, triazene ligands have a high level of complex selectivity for HgII, resulting in excellent recognition properties for mercury ions. Hence, triazene ligands have a high level of complex selectivity for HgII, resulting in excellent recognition properties for mercury ions. The selective complexing capabilities of triazenes with mercury ions allow them to be employed in a variety of applications, including mercury ion pre-concentration and determination, adsorption and separation, and the creation of mercury ion selective electrodes.
Experimental measurement of the stability constants of HgII binding by triazene ligands is time consuming and costly. It is, hence, favorable to calculate those stability constants without incurring any more costs for getting additional experimental data is advantageous [10]. Mercuric ion occupational exposure, on the other hand, can occur through skin contact and the respiratory system. Mercuric ion exposure at work can have negative health consequences, particularly for the kidneys and central nervous system [2, 11]. In addition, workers who were exposed to chemicals on a regular basis experienced gum inflammation and excessive salivation. Gradually, the accumulation of mercuric ions in the human body causes long-term brain damage, manifesting as deafness, headaches, forgetfulness, and cognitive impairments [12, 13]. Hence, in studies of high-toxicity materials like mercuric ion, the importance and central health of computational approaches is highly noticeable compared to laboratory methods [14, 15] ensuring the health of researchers and practitioners working with such dangerous chemicals.
Since the selectivity of ligands (as extractant) can be stated by the stability constants of cation–ligand complexes, quantitative structure–property (QSPR) relationship investigations on binding constant of HgII complexes were done. This research develops and validates a QSPR for estimating equilibrium constant of HgII binding by triazene ligands. A suitable QSPR model for predicting mercuric ion binding by substituted triazene ligands, should require as minimum information as possible, information about constitutional descriptors such as topological structure and molecular charges [16, 17].
The complex stability constants are an essential experimental quantity describes the binding consistency of metal-ion with (in) organic ligands. The complex stability constants are an important experimental variable that describes how well metal ions bond to organic ligands. The stability constants are particularly important in controlling the complexation process in the environment [18–21], biology [22], medicine [23–25], and analytical chemistry [26–29]. At present, QSPR, quantum chemical modelling [30–34] and linear free energy relationships [35] are utilized for computational prediction of the stability constants. QSPR method has been utilized to simulate complex stability constants of organic ligands with various metal ions in the field of computer aided stability constant prediction. The QSPR study is a significant field of research in computational chemistry and has been successfully used in the prediction of stability constant of complexes [36, 37].
Available empirical data on stability constants can be used as a guideline in QSPR modeling to predict the stability constants of newly synthesized ligand complexes [30] and each of a compound’s observed physicochemical behaviors is correlated with its numerical descriptors. The most main structural descriptors affecting the physicochemical properties of a structure are identified and separated in QSPR approach hence, this method typically needs variable selection for building well-fitted models. One of the most significant advantages of such a strategy is that it is confined to chemical structural knowledge and does not necessitate any experimental properties. As a result, it can be used to estimate the properties of novel compounds that have yet to be synthesized, discovered, or tested. As a result, the QSPR approach can hasten the creation of molecules with desirable features that have not yet been produced.
In this paper, we establish new QSPR models for predicting the stability constants of HgII - triazene complexes from the molecular descriptors and to look for structural variables that are connected to this trait. To create nonlinear and linear models, two modeling approaches were used: SVM and MLR. The obtained models’ efficiency was compared to one another. It should be noted that, to our knowledge, no research on QSPR modeling of the stability constants of HgII binding by triazene ligands has been published.
Materials and methods
Data set
The substituted triazene ligands (Table 1) were synthesized as stated in the literature [38]. In order to specify stability and stoichiometry of the resulting HgII - triazene complexes, in a conventional process, 2.0 mL of 5.0×10–5 mol L–1 triazene solution in ACN and 25°C were put in the spectrophotometer cell (10 mm) and the absorbance of solution was measured in range of 250 –550 nm. Then a certain amount of the HgII concentrated solution (1.4×10–3 mol L–1) in ACN was added in a step-by-step manner using a 10μL Hamilton syringe. After each addition the absorbance spectrum of each solution was acquired. In the following, the binding constant of the HgII -triazene resulting complex was assessed from the absorbance versus [HgII]/[triazene] mole ratio data by means of applying a nonlinear least squares curve fitting program, KINFIT. Finally, the obtained stability constant values (log KHgII - triazene) were used as experimental input data for modeling in this study. The chemical structures of substituted triazene ligands with their observed and predicted values of binding constants in the complex with HgII are presented in Table 1.
The structure, value of descriptors selected, experimental and predicted of formation constant of HgII complexes
The structure, value of descriptors selected, experimental and predicted of formation constant of HgII complexes
All the chemical structures of complexes were checked, drawn, and conformational minimized by HyperChem 8.0 software. Pre-optimization of the geometrical structure was done by the MM+ Polake-Ribiere algorithm (molecular mechanics method), and by a more accurate optimization with the semi-empirical Austin Model-1 method (AM1), the final geometries of the minimum energy configuration with a gradient norm criterion of 0.005 kcal/molÅ were obtained.
Descriptor calculation
PaDEL-descriptor calculates molecular 0D-3D descriptors and fingerprints. PaDEL-descriptor is available as free and open-source software (http://padel.nus.edu.sg/software/padeldescriptor/). Various 2D and 1D molecular descriptors such as electrotopological state indices descriptors, chi indices descriptors autocorrelation descriptors, constitutional descriptors, topological descriptors and BCUT descriptors were computed using PaDEL-Descriptor [39].
Variable selection
Stepwise regression procedure is widely used in QSPR analysis for select an appropriate and limited number of descriptors. It is one of the easiest and suitable methods for descriptor election in QSAR research [40]. Moreover, this approach can offer a number of the substantial descriptors for modeling against other procedures. Nevertheless, when the descriptor pool is vast, stepwise regression cannot give satisfactory results [38].
Enhanced replacement method (ERM) algorithm provides specifying an appropriate subset of descriptors from a wide descriptors dataset and N objects using MLR procedure. It requires lesser amount of linear regressions than a time-consuming complete research method whereas attaining similar results [41]. algorithm of ERM comprises the following steps: [42, 43]. An initial collection of descriptor d (d = {X1, X2,..., Xd}) is randomly designated from D (D = {X1, X2..., Xd . . . . . . XD}. According to d, an MLR model is created. The residual standard deviation (RSD) of the created model is estimated in accordance with using following equation:
N = umber of data points in the training dataset. resi = discrepancy between the predicted and experimental value for the data point i in the training dataset. From this resulting set, the descriptor was selected with the highest standard deviation in the coefficient and all the remaining (D-d) descriptors were replaced one by one, for it. This procedure was repeated until the set remained unmodified. In each cycle, the descriptor optimized in the previous period was not modified. Thus, the candidate dm (i) was obtained from the so constructed path i. The above process was carried out for all the probable routes i = 1, 2, 3, 4 . . . , d and was kept dm with the minimum standard deviation.
Development of QSPR model and screening
MLR
Multiple linear regression (MLR) procedure is extensively worked in linear problem. MLR models the relation between two or more independent or predictor variables, and a dependent or criterion response variable, by fitting a linear mathematical equation to experimental data. Each value of X (the independent variable) is related with a value of Y (the dependent variable). The MLR method presented a mathematical linear equation linking the logarithm stability constants of complexes to the structural descriptors. By this approach the two most related descriptors were chosen to develop the model. MLR advantage is its simply interpretable mathematical expression.
Support vector machine
The support vector machine (SVM) which developed by Vapnik [44], is a modern algorithm acquired from the machine learning community, and has increasingly popularity and obtained wide applications in various aspects such as drug design [45], pattern recognition problems, [46] and QSPR analysis [47] because of its attractive aspects and significant generalization operation. SVM is a normal progress of neural networks and is categorized according to the optimal hyperplane generation method. The SVM approach outperforms the artificial neural network algorithm in terms of efficiently avoiding data over-fitting [48]. The model with optimal parameters supplying best efficiency of SVM on the cross-validation training set, were confirmed on the corresponding test set. The QSPR model was established using the following process: (I) build of many base models using diverse descriptor subsets, (II) elect appropriate base models to create a model, and (III) evaluating the model efficiency. Base models are separate predictor models that are added to construct consensus models. In this work, base models were built from the training set utilizing diverse descriptor subset(s). The efficiency of the consensus model was then assessed using the validation set.
All calculations were accomplished with MATLAB. PLS toolbox 4.2 was used to create SVM and MLR models.
Results and discussion
The MLR and SVM were used to obtain quantitative relationships between the stability constants of HgII complexes with substituted triazene organic ligands and the computed descriptors. The ERM variable selection technique was used to select the significant variables.
The summary of statistical results of MLR and SVM models are depicted in Table 2. The plot of calculated versus experimental stability constants of HgII - triazene ligands obtained by the MLR and SVM modeling are shown in Fig. 1.
Summary of statistical results of MLR and SVM models
Summary of statistical results of MLR and SVM models
Q2Loo: Leave one-out cross validation correlation coefficient, Q2LGO n = 4: Leave four-out cross validation correlation coefficient.
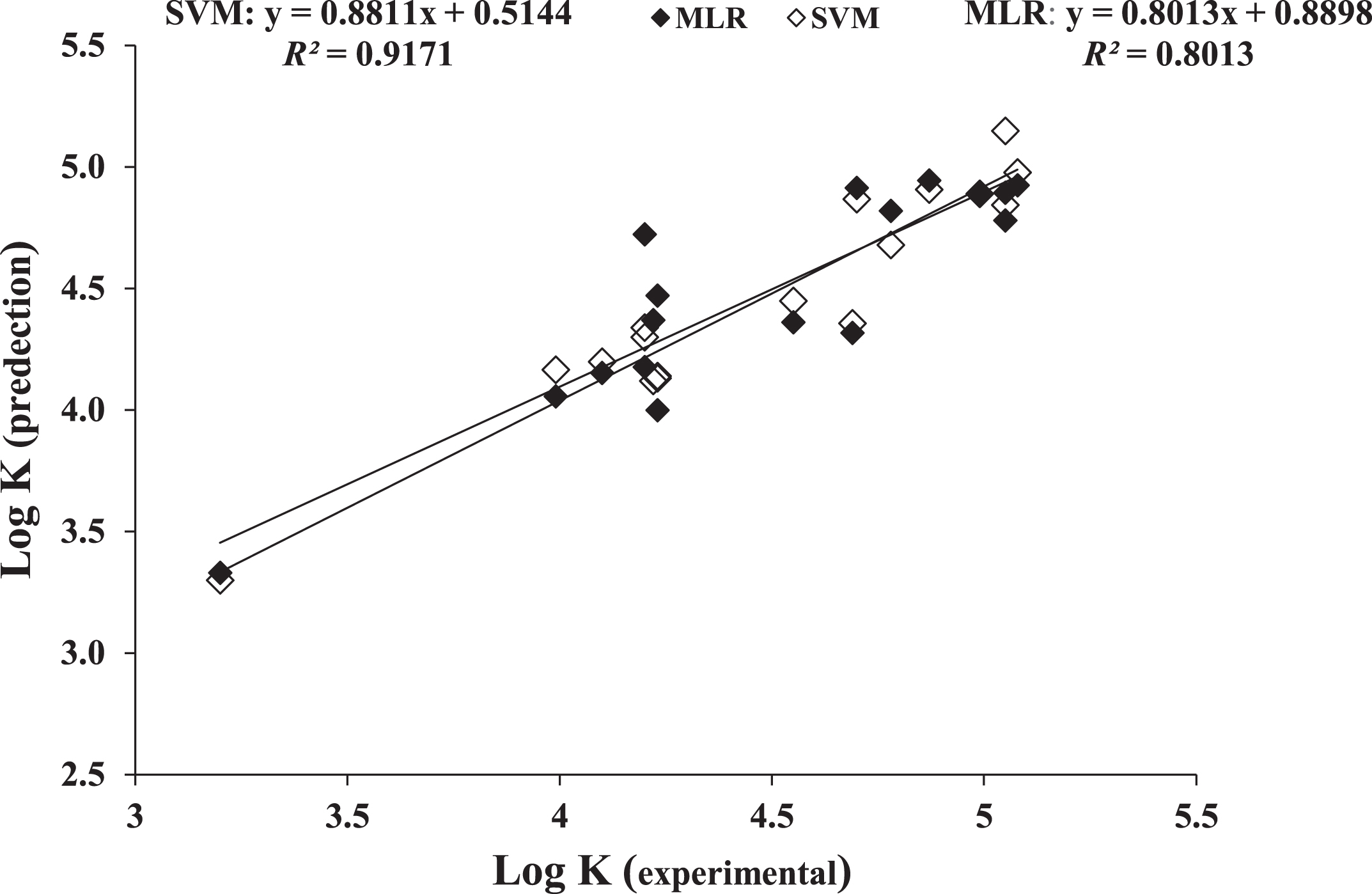
Plot of calculated versus experimental stability constants of HgII - triazene ligands complexes two-variable MLR and SVM models.
Because of its significant generalization efficiency, the SVM has possessed attention and obtained widespread application, such as QSPR/QSAR [49] and drug design [50] analysis. In most cases, efficiency of SVM modeling either competes or is dramatically improved than that of conventional machine learning methods. In light of the foregoing, we chose the MLR and SVM models because the MLR model allows us to comprehend the link between response and explanatory factors, and the SVM model, as a machine learning approach, is supposed to provide great prediction accuracy. SVM regression analysis was used to create a non-linear model using the same subset of descriptors, and the statistical findings of SVM and MLR were compared (see Table 2).
The best subset of descriptor selected by ERM variable selection techniques are ATSC3s and GATS6s. The MLR model based on the selected descriptors and the log KHgII - triazene gave a two-variable equation as follows:
The developed model reveals significance of GATS6s and ATSC3s descriptors in logarithm stability constants prediction. GATS6s is the Geary autocorrelation of lag 6 weighted by I-state, and it presents data about the distribution of inherent state along the topological structure.
Both descriptors selected are autocorrelation descriptors. Autocorrelation descriptors are topological descriptors that encoding both molecular structure and physico-chemical properties of a molecule. ATSC3s is the Centered Broto-Moreau autocorrelation weighted by charges and it provides information about the molecular charges. GATS6s is the Geary autocorrelation of lag 6 weighted by I-state, and it offers data about the intrinsic state distribution along the geometrical structure. This descriptor had negative contribution to log KHgII - triazene values. The negative coefficient of this descriptor as a mark that the value of this descriptor changes inversely with log KHgII - triazene amount and the spatial barrier created in the topological structure by substitution, reduce the metal-ligand interaction. The ATSC3s and GATS6s descriptors have been weighted by charge and I-state respectively. These indicated that the charge descriptors along with the topological properties of the ligand have a great influence on the formation of the HgII - triazene complex.
The efficiency of the generated models was assessed using the leave-one-out (LOO-CV) and leave-group-out (LGO) cross validation procedures during the model development stage. The resulting regression model has an excellent ability to predict both internally and externally, according to cross-validation indices. In the LOO-CV method, a QSPR model was generated from a total data set (n–1) samples, and the property of the left-out sample was assessed by the constructed model, and the estimated property for that point was compared to its factual quantity. This process was continued until all of the samples in the data set had been excluded. For LGO-CV, a subset of the data was removed from the dataset and the model was rebuilt; the estimated values were then compared to the actual values for the omitted data. This method was repeated once more until all data points had been deleted. Other statistical indices were also computed, including the standard error of prediction (SEP), standard error of calibration (SEC), and square of the correlation coefficient (R2). As shown in Table 2, the R2 values of the original models were much higher than those obtained from the randomization test, indicating that the produced models are statistically robust and significant. The statistical indices show well-fitting ability for internal as well as external sets (great values of R2) and high predictability (low value of SEC and SEP) and low relative difference between Q2 and R2. The designed model was too investigated by Y-randomization test for robustness. The vector of dependent variable (log KHgII - triazene) was shuffled randomly and by using the matrix of original independent variable a new QSPR model was designed. According to Table 2, though SVM seemed more robust due to the nonlinear effects of the modeling approach and was expected to obtain better result from the MLR, here it did not provide only slightly improved modeling (
Whereas even a validated and robust QSPR, it is not expected to predict the modeled property of compounds globally with certainty; hence, the applicability domain (AD) of the ultimate proposed model should be determined. AD is a theoretic chemical [51] area in the space specified by the model descriptors and modeled response, for which a particular QSPR model must make valid predictions. The credibility of the model prediction and the AD analysis of ERM-MLR are checked by the leverage methodology, where, the Williams plan (h) can be applied for a simple and urgent graphical finding of the response outliers and structurally effective chemicals in a model. In this plan, the two parallel horizontal dotted lines demonstrate the limit of usual values for Y outliers (that’s mean, samples with standardized residuals more than±3.0 standard deviation units); the vertical dash line demonstrate the limit of usual values for X outliers (that’s mean, samples with leverage values more than the critical value, h > h*). On the model AD analyzing in the Williams plot of MLR model no compound in the data set was identified as outlier (see Fig. 2). The applicability domain analysis of the two-variable models is shown in Fig. 2.

Plot of standardized residuals versus leverages. Dotted lines represent±3.0 standardized residuals and dash line represents warning leverage (h* ≈.0.35).
In this work, some QSPR models were developed to predict the stability constants for HgII- triazene ligands using MLR and SVM methods. The most obvious conclusion to be drawn from this study is that HgII- triazene complexation mainly affected by two main factors: the distribution of inherent state along the topological structure and topological properties. These descriptors may be useful in synthesizing and developing triazene ligands that are highly efficient in the HgII selective extraction and/or separation procedure. The developed MLR and SVM models were successfully employed to predict HgII - triazene complexation stability constants after their robustness and accuracy were evaluated. Finally, it is expected that the hidden information in the generated models will lead to more cost-effective, faster, and environmentally friendly methods of reaching the stability constant of HgII using novel triazene ligands.
Conflict of interest
The authors declare there is no conflict of interest.
Funding
No funding was received for this work.
Authors’ contributions
Ahmadreza Hajihosseinloo and Mohammad Kazem Rofouei performed the experiments; Ahmadreza Hajihosseinloo, Maryam Salahinejad and Jahan B. Ghasemi made the modeling and developed the theoretical framework; Ahmadreza Hajihosseinloo and Maryam Salahinejad wrote the article. We confirm that the manuscript has been read and approved by all named authors.
Availability of data and material
The authors confirm that the data supporting the findings of this study are available within the article.