
Abstract
In multi-agent systems, the yellow pages service is very important for agents to be able to interact with each other. The more the number of agents is high, the more performance degradation will result, due to the overload of requests sent to central yellow pages. This issue didn’t get much attention from researchers despite its importance. The proposed approach for solving this scalability issue is based on the aspect-oriented paradigm. An aspect was used to play the roles of a replicator and a distributor of requests to several new yellow pages. The use of aspect-oriented programming simplifies the implementation, reduces the maintenance effort and offers a good reusability of the proposed solution. The approach is validated on three JADE applications and evaluated on five different machines. Results, which are very promising, show a significant scalability and performance improvement of the yellow pages service especially on Linux operating system.
Introduction
During the last decade, the development of multi-agent systems (MAS) has aroused great interest in the research community. The agent paradigm offers, in fact, undeniable advantages in the development of software systems that can operate in complex, distributed, heterogeneous and open environments. Several MAS development methodologies have, indeed, been proposed in the literature [1, 2]. The main objective is to facilitate and support the development of agent-based applications. These methodologies have allowed real progress in the design and implementation of MAS. However, maintenance of agent-based applications is not yet sufficiently addressed [3].
Software maintenance is still the most complex and expensive phase of agent-based applications life cycle. Maintaining existing source code is more economical than rewriting or replacing it with a new one [4, 5, 6, 7]. If the maintenance activity of procedural and object-oriented programs [8, 9] was the subject of several research projects, it is not the case of multi-agent applications, which have their proper specificities like deliberation, communication, etc. Although MAS represent an active research area, agent-based applications maintenance remains preliminary and has not yet achieved a high level of maturity [10, 11, 12]. Indeed, there are still various crucial issues that have not yet been addressed.
Enhancing the scalability and the performance of multi-agent systems [13] has been the interest of many researchers even recently by focusing on improving agent properties like deliberation [14, 15, 16], cooperation [17], communication [18], reactivity [19], etc. One of these properties is the yellow pages service [20] (directory or matchmaking service). It is a very important service for agents to be able to interact with each other. Many researchers have highlighted the importance of a scalable and efficient yellow pages service in many fields [21, 18, 22]. In this service, the more the number of agents is high, the more performance degradation will result, due to the overload of requests sent to central yellow pages, which cannot handle these requests especially on high frequency. This is a major problem and can lead even to a total system breakdown.
The proposed approach for solving this scalability issue is based on the aspect-oriented paradigm [23]. An aspect that plays the roles of a replicator and a distributor of requests to several new yellow pages was used. This aspect creates a number of yellow pages copies and manages all the registration, deregistration and modification requests to ensure data consistency. All the yellow pages take turn to respond to the search requests, which will be distributed by the aspect to ensure a load balancing over all the yellow pages of the system.
Furthermore, our approach facilitates the maintenance process which does not require any change in the original source code by using aspect-oriented programming. In addition, the added functionalities are located in one aspect, which means better understanding, tracking and documenting.
This work focuses on a crucial issue in agent-oriented software engineering and aims to developing a new perfective maintenance approach that allows to enhancing the scalability and the performance of the yellow pages service [24] for existing large scale applications.
The proposed approach has been validated on three JADE applications using five different machines. Obtained results are very promising and show a great performance improvement of the yellow pages service especially on Linux operating system.
The remainder of this paper is organized as follows. In Section 2, a brief overview of major related work is given. Section 3 presents preliminaries. The proposed approach is presented in Section 4. Section 5 illustrates the validation and discussion of the proposed approach using three concrete case studies. Section 6 gives some conclusions and future work directions.
Literature review
In MAS, agents need to interact in order to achieve their tasks. Therefore, interaction is an important property in agent societies. An agent is able to interact with another one only if it knows its location that can be found using a service called the yellow pages. The more agents search for each other using this service, the more performance decrease will result due to the overload of the requests. In this case, the MAS will not be able to respond to the search requests in a proper time, which increases exponentially. These delays will propagate to other processes leading to a very slow system, to exceed timeout constraints and even to a total system breakdown. To prevent these situations from accruing, many researchers have proposed different approaches even recently to enhance the system’s overall performance by enhancing some of its properties, like deliberation [14, 15, 16], cooperation [17], communication [18], and reactivity [19]. Unfortunately, not like other agent properties, only few researches have been done to enhance this service by proposing different architectures like in [21], where the authors have focused on how to store and propagate information within cyber physical production systems, using a directory facilitator different than the usually used one of the JADE platform. This is the consequence of its centralized architecture that can produce bottlenecks when the system is scaled up. They proposed an agent called Capability Dissemination Agent (CDA) which is a redundant, decentralized and resilient extension of the available Directory Facilitator (DF). They validated their approach which provided correct propagation with more robustness and change resilience. Their work needs more improvements to establish the best CDAs distribution based on the system topology and scale.
In [22], authors have presented the use of homophily, which is a social feature that is present in complex networks that acts as a self-organizing criterion to create a decentralized and self organized structures. The agents have a greater probability of establishing links with similar agents than with dissimilar ones. Their approach, where agents collaborate with each other to perform a service discovery in contradiction to the centralized services as they mentioned, suffers from bottleneck situations, lack of coordination, outdated data, larger required memory space, etc. The results of their evaluation showed a considerable improvement in the performance of the system providing a high success rate and short paths.
In [25, 26], authors propose a category based service discovery, which employs a category database searching method instead of a sequential searching method. Similarly to [27, 28], where the authors propose a new yellow pages service or DF. Their evaluations show an important improvement in memory usage in every time when the number of registered services grows from 10000 to 100000, comparing to JADE’s memory usage. In the other hand, the request response time of one request in JADE’s yellow page (DF) is better than their proposed DF when the searching service is by name only. But, when multiple searching parameters are involved, the proposed approach shows a small improvement in request response time at a high number of registered services. In our study, we are not interested in the memory usage but in reducing the overload and enhancing the performance when the number of search requests is high.
In [29, 30], the authors focused on the same performance and scalability issue of the yellow pages service when search requests number is high. Several solutions were proposed where the best one was the integration of a shared and distributed memory with the yellow pages service of JADE. In this solution, each agent container has its own yellow pages agent (DF) which: (a) receives only requests from agents located in the same container, and (b) connects to a central replication server responsible for the registered services consistency. The results were very significant in terms of decreasing search’s response time and on increasing the number of agents in the system before it crashes due to a Java virtual machine (JVM) out of memory error. Their maintenance process requires a new package named Replication.distributeddf to be imported into the MAS, along with some modifications in the original source code. The authors did not present how their solution was implemented (algorithms, memory type used, etc.), or where the source code can be found. Therefore, it was not possible for us to test and investigate the solution for comparing it with our approach. They validated their approach on an IBM Think Pad T43 machine with a 1.8 GHz (single core) processor and 512 MB of RAM. This configuration is very low and prohibited them to run the system with a larger number of agents where they reached only 70 agents. Therefore, we cannot say that the solution is suitable for large scale applications unless more tests with much higher number of agents have to be done.
The authors have replaced the original yellow page methods (register, deregister, modify and search) with new methods but with different arguments and return types (String), for example static void Register (String name, String service) and static String Search (String service), instead of the original JADE’s methods arguments like AID, DFAgentDescription, SearchContsraints, etc. Therefore, the methods have to be changed in the original source code. Another disadvantage of their proposal is when all or a large number of agents are located in the same container, and because the search requests can be only sent to the local yellow page, it takes us back to the initial overload problem where one central yellow page is responsible for all the requests. Another disadvantage is that their yellow page agents are not fault tolerant which means that in case they crash, they must restart again and restore the services previously registered; exactly like how the JADE’s default DF does, otherwise the agents of that container cannot start an interaction process any more. Also, this approach has an interoperability problem, where extern agents can’t interact with their proposed DF, but only with the JADE’s DF, which in this case has no registered services. Another weakness is that their proposal has no support for search constraints which is very useful for more search precision. The authors planned to enhance their proposal by incorporating the shared distributed memory principle within the original JADE’s DF. Therefore, we believe that the overload will still be improved than the original JADE’s DF due to the distributed and the duplicated yellow pages. But, the search response time will be slower than their first proposal, because the searching procedure in JADE’s DF is more complex and requires several actions and concepts like ACL (agent communication language) processing, matching: AID, services, ontologies, protocols, etc.; where the services are stored in a database which is slower in reading and writing operations than using a simple memory (arrays, lists, etc.).
In our approach, the yellow pages are copies of the original JADE’s yellow pages; they can be located in any container and receive requests from any agent. These requests are distributed over all the yellow pages evenly. These enhancements are managed by one aspect that makes it very easy to apply them in the MAS.
Preliminaries
In this section, some basic concepts and tools related to the proposed approach, namely, the yellow pages (matchmaking) service [20], JADE [31] and AspectJ [32] are introduced.
The yellow pages service
In MAS, the yellow pages service is also known as matchmaking or directory service. As defined in [20], it consists of a cooperative partnership between information providers and consumers, with an intermediate called the matchmaker or the directory facilitator. The providers advertise their services to a matchmaker and the consumers search for some services by sending requests to the matchmaker which identifies any registered information that is relevant to the search requests and send the results to the requester.
JADE platform
JADE (Java Agent DEvelopment Framework) [31] is a software framework fully implemented in Java. It simplifies the implementation of MAS through a middleware that complies with the FIPA specifications and through a set of graphical tools that support the debugging and deployment phases. The agent platform can be distributed across machines (which not even need to share the same operating system) and the configuration can be controlled via a remote GUI. JADE currently is one of the most widely used platforms for research purpose. It has three main modules:
The DF (Directory Facilitator) provides yellow pages services to other agents. Agents may register their services with the DF or query the DF to find out what services are offered by other agents, including the discovery of agents and services they offer in ad hoc networks. The AMS (Agent Management System) controls access and use of the agent platform and provides services like maintaining a directory of agent names. It provides white page services to other agents. Each agent must be registered with an AMS. The ACC (Agent Communication Channel) manages the communication between the agents.
AspectJ [32] is a seamless aspect-oriented extension to Java. It enables a different way to further and cleaner modularize all crosscutting concerns in a complex system compared to the object-oriented paradigm. AspectJ adds to Java several new constructs, including join points, point cuts, advice, intertype declarations, and aspects. An aspect is a modular unit of crosscutting implementation in AspectJ. Each aspect encapsulates functionality that may crosscut several classes in a program. Join Points are well-defined points in the execution of the program, such as, method call (a point where a method is called), method execution (a point where a method is invoked) and method reception join points (a point where a method received a call, but this method is not executed yet). Pointcuts are a means of referring to collections of join points and certain values at those join points. Advice is a method-like construct used to define additional behavior at join points. It consists of instructions that are executed before, after or around a join point. The around advice executes in place of the indicated join point, which allows the aspect to replace a method. An aspect can also use an intertype declaration to add a public or private method, field or interface implementation declaration into a class [33]. AspectJ has two types of weaving: a static weaving where it provides all the codes corresponding to the join points declared in a pointcut without execution, and a dynamic weaving where only the executed join points are intercepted at runtime. AspectJ Plugin is an aspect-oriented extension to the Java programming language. AJDT (AspectJ Development Tools) is the name of this AspectJ Plugin.
The proposed approach
Over the last decade, a considerable progress on MAS engineering techniques has been made in terms of methodologies and mature tools. However, maintenance of existing MAS code, which is an important research area, is not explored enough. The proposed approach provides a solution for enhancing the performance and scalability of yellow pages service in multi-agent applications. For clarity reasons, it is preferred to present the proposed approach through concrete examples of JADE platform. The proposed approach consists in three activities managed using aspect-oriented programming (Fig. 1) for the following reasons:
The simplicity of the implementation. The added functionalities are located in one file (aspect) and separated from the original code which remains intact (better separation of concerns). Requests (register, search, etc.) are intercepted and changed or forwarded during execution, which is easy to implement using aspect programming. The reusability of the solution and the maintenance effort is better, because it is only needed to insert the aspect to the system to be enhanced. So, no redevelopment or manual refactoring is required. Updating the documentation of the system is easier.
The proposed approach.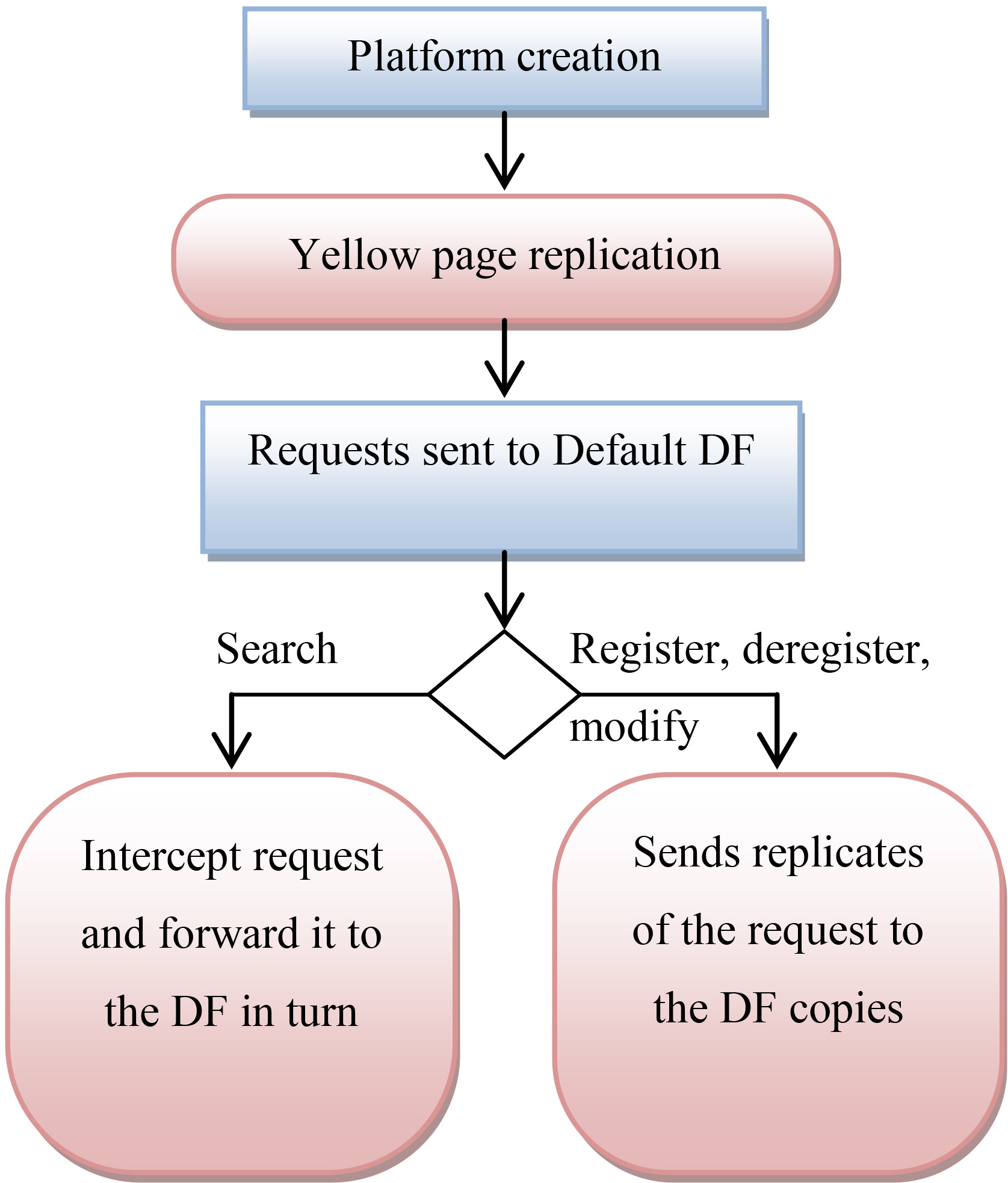
After the platform creation, the aspect creates a number of yellow page (DF) copies in the system. When agents send register, deregister or modify requests to the default DF, the aspect replicates the requests to all the DF copies to insure data consistency. In the other case of search request, the aspect intercepts and forwards it to the DF in turn (including the default DF).
In JADE applications, agents are located in containers which have to be created before any agent. The container creation is the starting point of the replication process.
This activity is managed by the DFenhancer aspect which intercepts the container creation and creates DF copies in it (Fig. 2), using an agent class named DFCopy which extends the Jade.domain.df agent class. So, it can acquire the same DF behaviors like register, deregister, modify and search. An empirical research has to be made to find the optimum number of DF copies according to system status, but for now this number is set by the administrator.
The implementation of the DFCopy agent presented in Snippet 1 is very simple. Its class needs to extend the jade.domain.df class and execute the super.setup() method to acquire all behaviors of the default DF agent like register, deregister, modify and search.
The DFenhancer.aj aspect will be presented now. It plays two roles, first as a replicator of DF agent and register, deregister and modify requests, secondly as a distributer of search requests. The code fragments responsible for DF replication are presented next.
The yellow pages replication in JADE.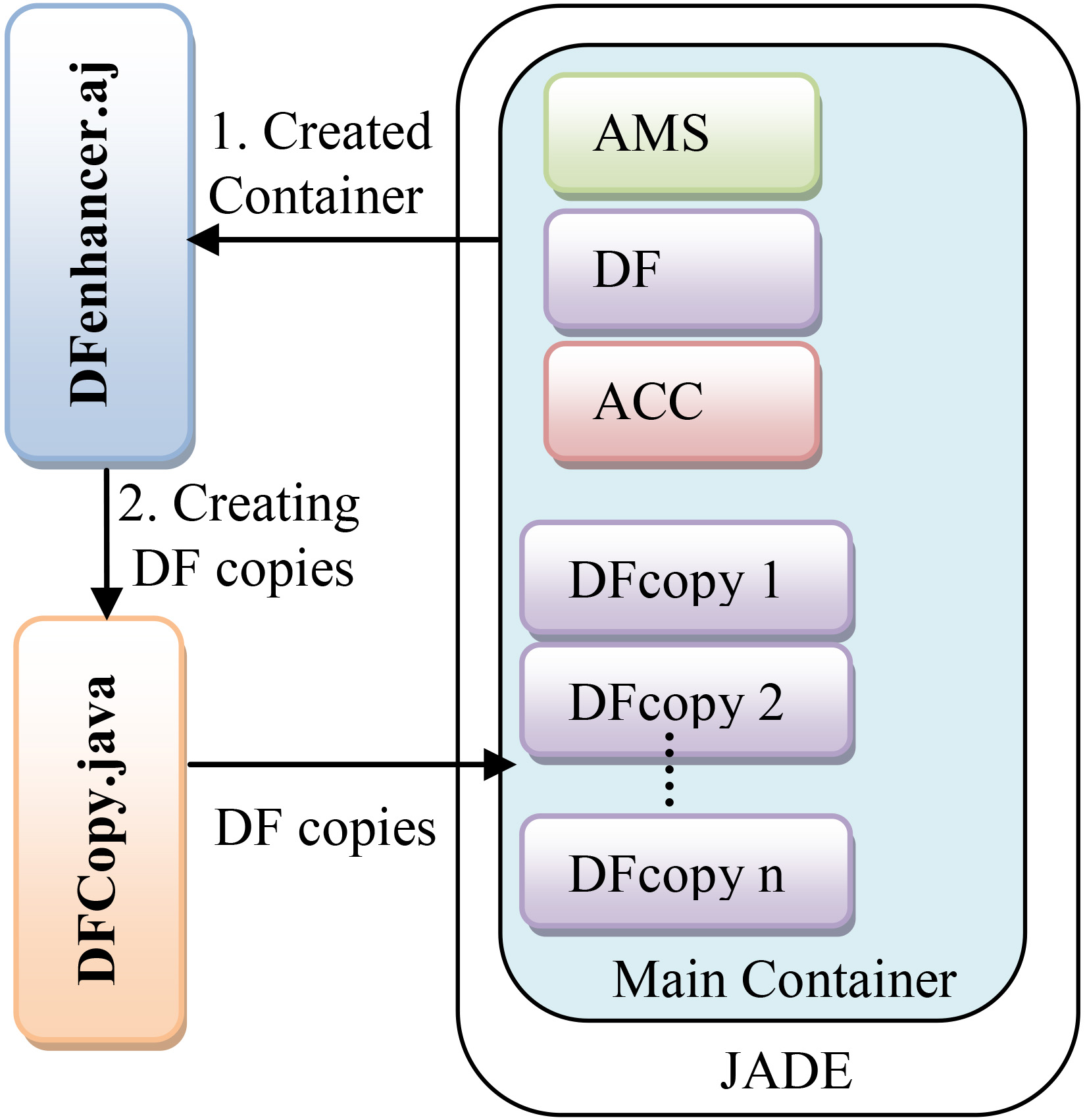
When the application starts, it is required to have some variables as presented in Snippet 2: (a) the number of DF copies needed, which is a fixed value for now, (b) a list to save the agent IDs of the DF agents including the copies, and a counter for its size, so it can be used instead of calling for the list size method at every request, (c) a counter of intercepted search requests that will be used to define the DF in turn, and (d) a Boolean variable used to find the default DF AID that will be added to the DF agents list.
Creating DF copies
In this paper, the goal is to improve the scalability and the performance of the yellow pages service in a local host with DF agents created on the main container only, to avoid any influence of the network that can affects the results. Therefore, distributing the DF copies or creating new ones in each container or in other hosts is possible, but it’s not our goal for now.
When the aspect intercepts the main container creation call, it completes its creation first. Then, it creates DF copies in it, as presented in Snippet 3.
Adding all DFs AID to a list
Once the DF copies are created, their AID information must be saved in a DF agents list. The getAID method cannot be accessed using method call like it is done with objects, because this will violate the principal of the privacy of agents attributes and behaviors. Therefore, as presented in Snippet 4, their execution is intercepted to access to their attributes. The last AID to be added to the list is the default DF.
Registering, deregistering and modifying services
When an agent sends a registering, deregistering or modifying request for its services to the DF agent
by invoking its proper method, the DFenhancer aspect intercepts this invocation and sends request copies to the DF copies created earlier. Then, it allows the original request to reach the DF (Fig. 3).
Registering, deregistering and modifying services.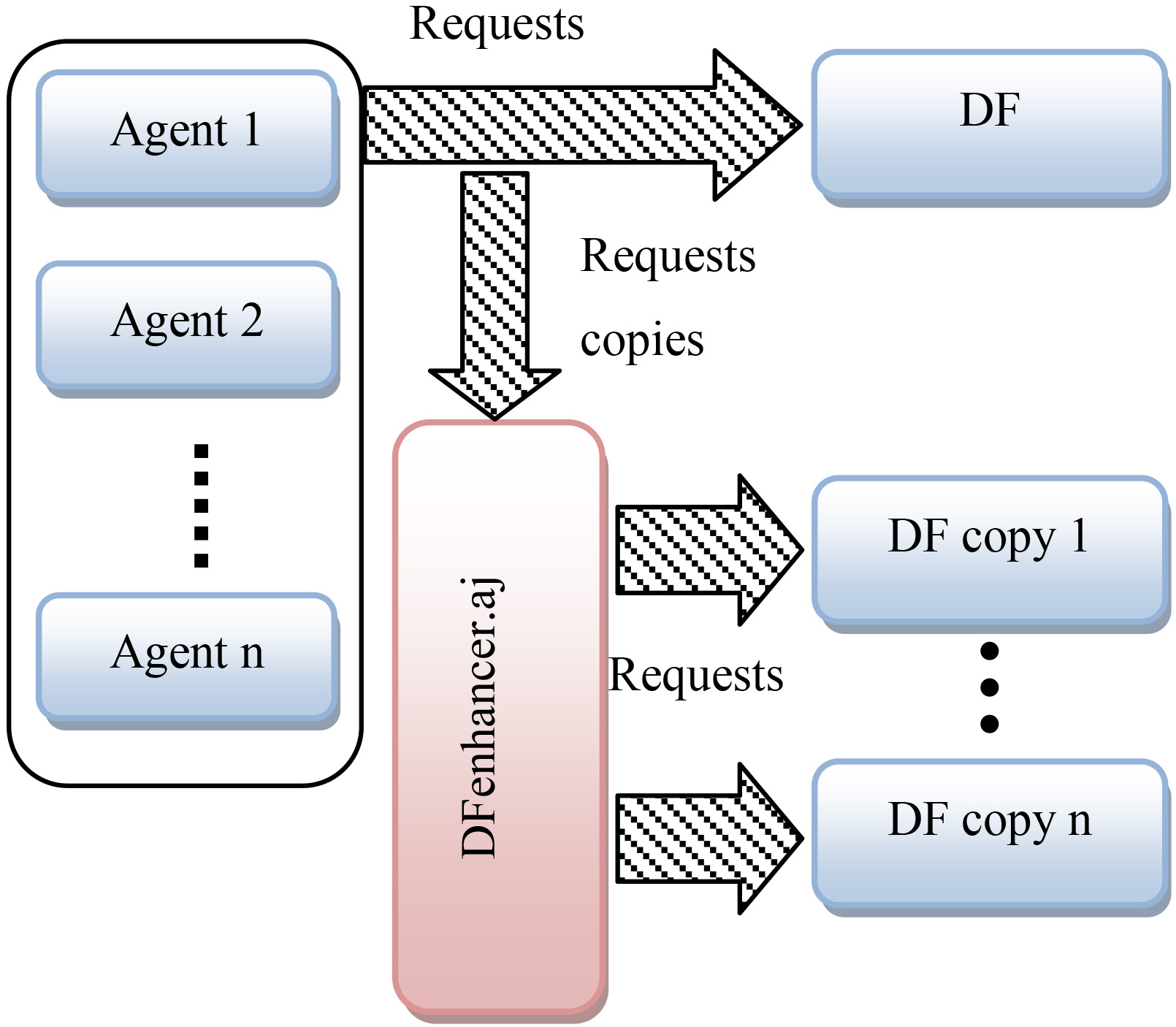
As shown in Snippet 5 of the aspect code, the registration requests called by the DFService.register() method are intercepted by the intercept_Register() pointcut. In the around advice, the requests are replicated and forwarded to all the DF copies, then by calling proceed() the original request is passed to the default DF.
Deregistering services
In deregistration process presented in Snippet 6, the same idea like in the registration is used, only that the join point to intercept is the DFService.deregister method.
Modifying services
Service modification presented in Snippet 7 also is similar to registration and deregistration, with the method DFService.modify as the pointcut which will be intercepted.
Searching services
When the two previous activities are well achieved, the yellow pages service is ready to face a high number of searching requests, which will be passed to many DF agents instead of one using the DFenhancer aspect (Fig. 4).
Searching for services by distributing requests on DF agents.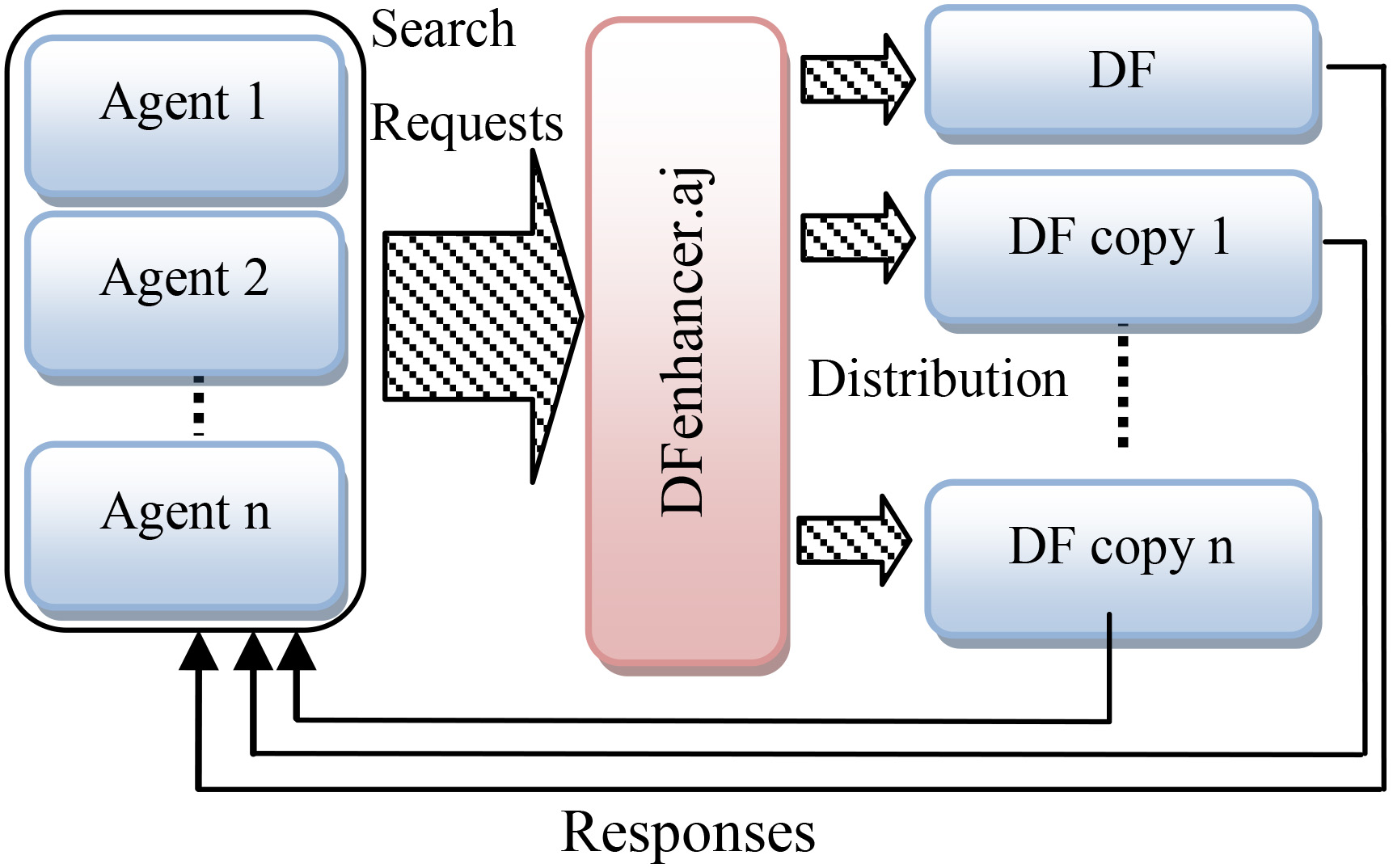
The DF copies and the default DF will take turns to respond to search requests. This load balancing process is managed by the DFenhancer aspect, which intercepts the search request and directs it to the DF in turn (Fig. 5).
Distribution of requests by turn.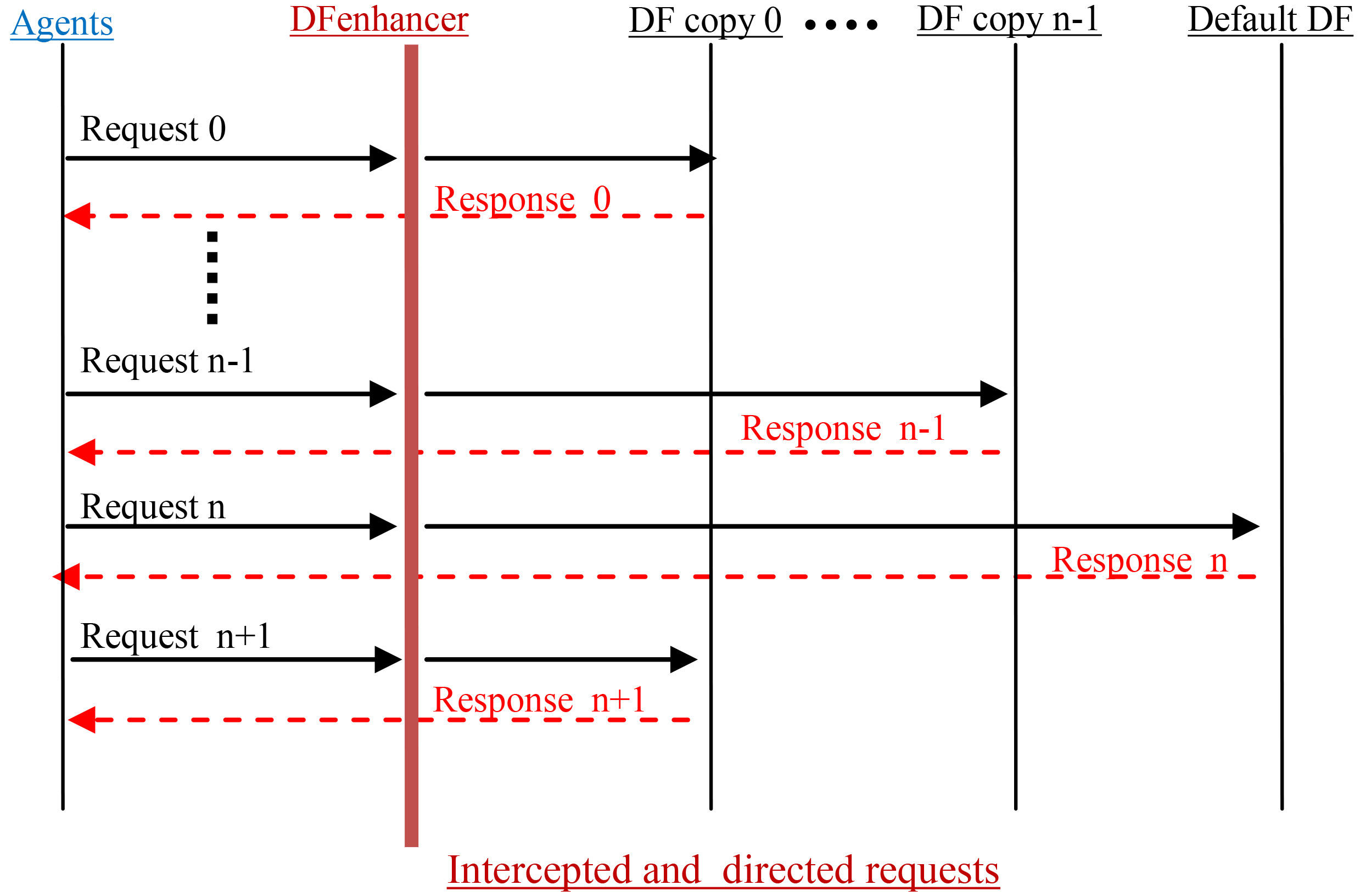
The aspect code, responsible for distributing requests, uses an around advice type, which is presented in Snippet 8. In JADE applications, developers must use the method DFService.search to search for services in the DF. If the search request is addressed to the default DF, there is no need to specify its AID in the method’s arguments. Otherwise, when the second argument is set to a specified DF other than the default DF, the administrator must not alter the request, unless he takes this case into account while implementing the DFenhancer aspect, so that the system runs properly.
The search request can be configured also with a search constraints argument. Therefore, in this case or the other, the same search request has to be directed.
Managing DF agents turns is implemented by a circular list which holds the AIDs of all the DFs in the system. To implement the circular list, a modulo function is used which returns the position (index) in the DF agents list of the DF responsible for the current intercepted request as presented in Eq. (1).
The aspect-oriented programming paradigm used in the proposed approach has simplified its deployment by separating the concern of enhancing the performance and the scalability of the yellow pages service from the other original concerns of the multi-agent system.
Therefore, to use and validate the proposed approach, we don’t need to change any line of code in the application’s source code. Instead, only these elements have to be added to the application as follows (Fig. 6):
Add the DFCopy.java class and the DFenhancer.aj aspect to the default package in the source code. Add the AspectJ package to the BuildPath.
Applying the proposed approach.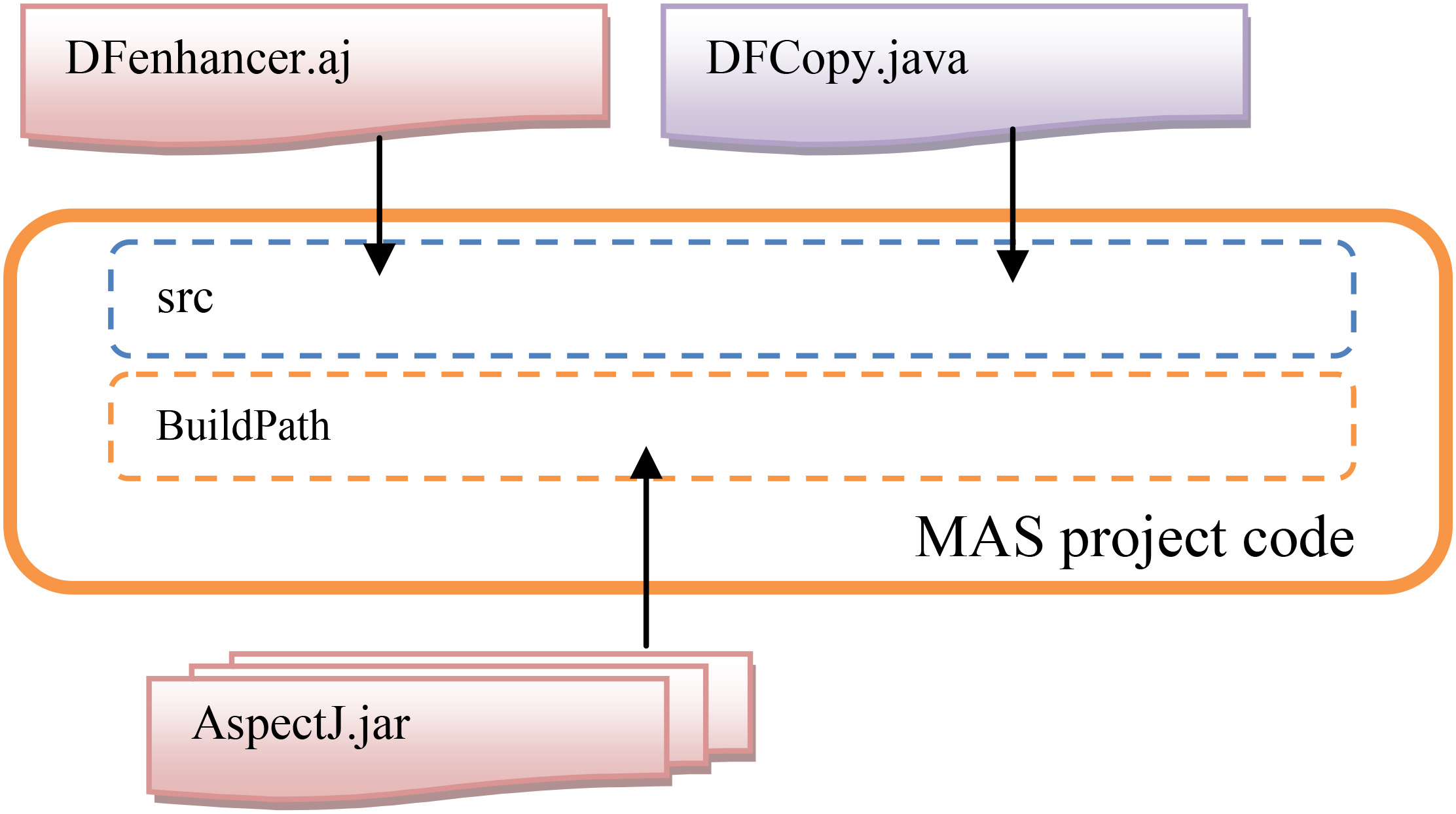
A search has been done for unified benchmarks used by the community in multi-agent systems that can be used to validate the proposed approach, but no results have been obtained except for the examples offered within the agent platforms. Therefore, three multi-agent systems have been proposed to validate the proposed approach, which are: (a) A simple example provided with the JADE platform named bookTrading [34]. It is about sellers (book selling agents) who register their services into the DF agent, and buyers (book buyer agents) who search in the DF agent for book selling services. (b) Translators, another simple JADE application that we developed which has 4 agents types. The first type is a requester agent for translating an English word, the other 3 agent types offer translation services each one specializes in a specific language. (c) im2008-jade [35], is a more complex application that we used in previous work [36]. It’s an information system for real-time sharing of resources whose availability is manifested with very short notice and with a very limited useful lifetime. For example, such resources can be linked to situations such as:
Resale of tickets (train, show, etc.) already purchased and no longer available to the first buyer. Availability of places on private transport. Short-term discounts on products for sale.
Two simple examples were selected for the evaluation to avoid interferences of other functionalities on the yellow page service.
The im2008-jade application is more complex and can demonstrate how the proposed approach will perform with other agent properties in the system, taking in consideration that many concerns can be faced during evaluation:
Other functionalities can take too much CPU resources that the DF needs to respond in time, this can degrade the performance of the yellow page service which means slower response time due to the CPU sharing, not due to the yellow page itself. If an agent behavior takes too much execution or waiting time before requesting a service, this can reduce the pressure on the DF agent, which will prevent any DF bottleneck from happening. An agent can perform cyclic behaviors which sends more than one search request per agent. Therefore, the evaluation is no longer related to the number of agents, but to the number of requests which is not unique for all the agents and with frequencies that can’t be controlled (agents are unpredictable and can send different number of requests).
To run the bookTrading application, the Jade.boot command line is supposed to be used to lunch the JADE platform and start the agents manually, which is not proper to validate our proposal. Therefore, the application was instrumented with a main class to start the evaluation programmatically and perform these tasks, exactly like in the Translators application:
Launching the JADE platform. Creating 100 (which is the default results number of one search offered by the DF) book seller agents and wait for all their services to be registered (in the Translators application there are three translators types, in each translator type 100 agents were created). Launching five iterations where in each one book buyer are created. These agents will be terminated after each iteration, starting with 2000 buyers at the first iteration. In the next iteration, the number of buyers is incremented with 2000 agents, until the last iteration where 10000 buyers is reached. Each new iteration starts with our demand, so the results of the previous one could be saved.
The im2008-jade application has its launcher class which starts the system. To maintain the original functioning of the application, the only modifications that have been applied are an augmentation of the requester agents number to 6000 agents while the number of registered services remains intact, and a removed waiting time of 30 seconds used to be set in the requester’s setup method.
The number of DF copies to be added into the system is fixed as a randomly choice to four agents beside the original DF agent.
The proposed approach was evaluated on different machines, desktop and laptop with different RAM and CPU capacities and under different operating systems (Linux 64 bits and Windows7 64 bits). In Table 1, the technical characteristics of these machines are presented.
The used machines for the yellow pages service evaluation
The used machines for the yellow pages service evaluation
All the computers systems have the same used software versions, which are:
Eclipse Luna (4.4.1) with JDK8 Update 91 JADE v4.1.1 (since v4.2, a DF search timeout was set to 30 seconds, last version now is v4.4) AspectJ (AJDT 2.2.4 for Eclipse 4.4)
In a heavy loaded multi-agent system, DF search requests frequency is very high which makes it difficult for the DF agent to answer in a proper time.
The performance of the JADE’s DF agent will be examined now under several search request frequencies using only two previously mentioned applications bookTrading and Translators.
The search request response time or
The examples were instrumented with a simple main class responsible for starting the JADE platform and the required agents as mentioned before.
Starting with the bookTrading example presented in Snippet 10, where the book seller agents were created first to register their services in the DF (100 seller agents), then the book buyer agents were lunched starting from 2000 buyers in the first iteration to 10000 buyers in the last iteration by adding 2000 agents after each one. The agents of the previous iteration were terminated before starting the next one.
In the Translators application we used the same execution sequence, only that in this example 300 translation services have been registered (100 services for each one of the three translator agents), while in the im2008-jade the original execution was used which will be explained later with its evaluation results.
In each machine, the same evaluations were launched, where each one has a different search requests frequency, and because the performance and scalability observations were similar in all the used computers, only the investigation results lunched on the desktop linux machine using the bookTrading example will be presented.
The first evaluation was started with no delay and in full frequency of requests. In each evaluation, 2000 buyers were started as the first iteration to the 5
In each iteration, the median (Table 2) and the mean (Table 3) of search response times (RTTs) using the bookTrading application are calculated (Translators has approximately similar results).
The median of RTTs of JADE’s DF performance in the Desktop Linux machine according to requests frequency (bookTrading)
The median of RTTs of JADE’s DF performance in the Desktop Linux machine according to requests frequency (bookTrading)
The mean of RTTs of JADE’s DF performance in the desktop Linux machine according to requests frequency (bookTrading)
In statistics [39], when the mean and the median values of certain data are close to each other, it is preferred to use the mean values, otherwise when data is skewed and there is a difference between them, the use of the median is more appropriate. Thus, in Fig. 7, only the median values of the RTTs are presented next.
The RTT necessary for the DF to return 100 services of only one search request varies about 10 to 25 ms (could be less or more).
The performance of Jade’s DF in a Desktop Linux machine according to requests frequency (bookTrading).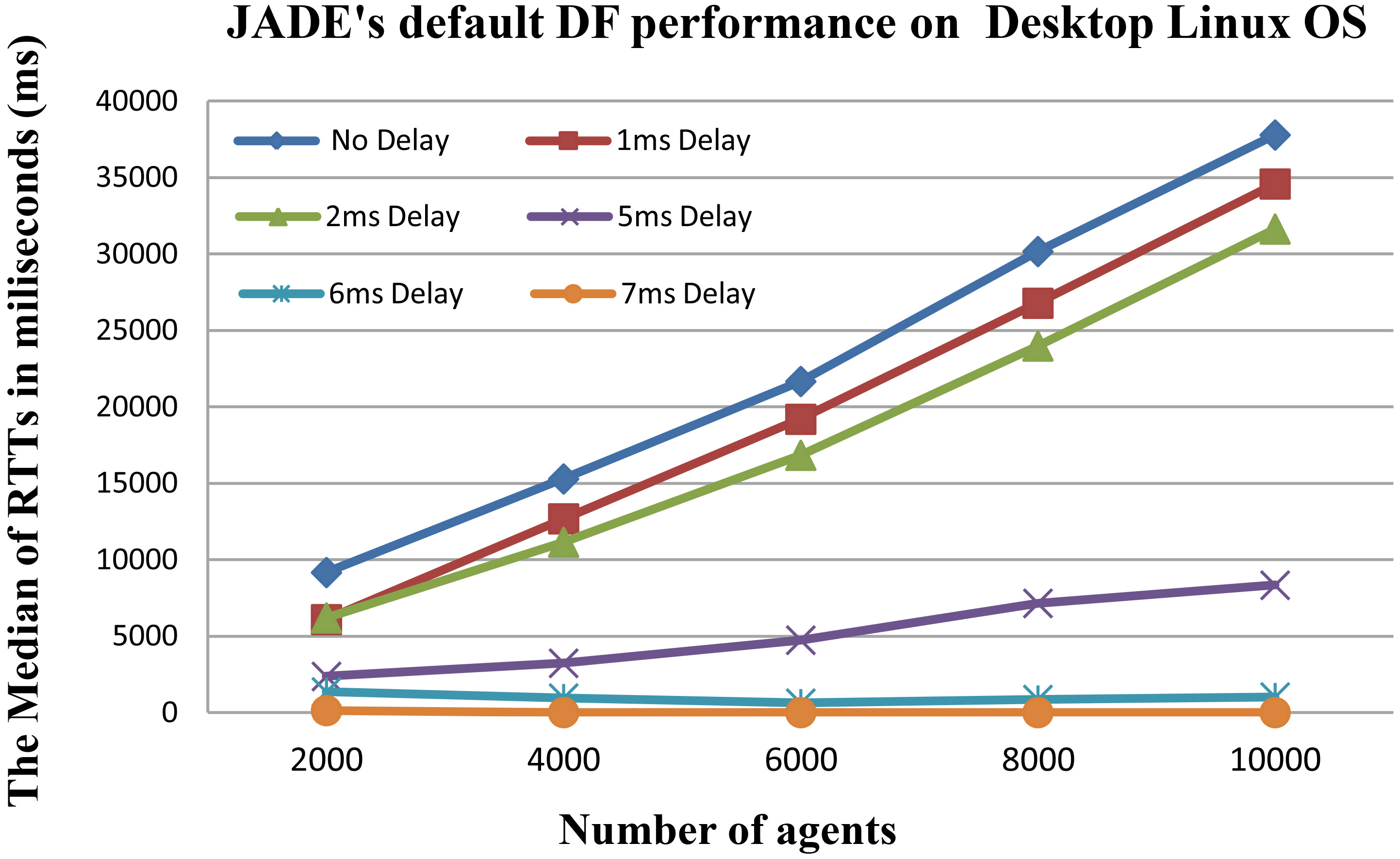
Figure 7 shows six curves for the response time of service search requests sent to the DF agent. Each one depends on the requests frequency. We observe that at higher frequencies (less delay time between requests), the more performance degradation will result when the number of agents is augmented. But, when the delay time was set to 6 ms, the RTTs were nicely stable even if they were not optimal like in the 7 ms delay curve, which shows that The DF agents runs smoothly at high number of agents. We also notice that the RTT in the first iteration (2000 agents) of the 7 ms delay is a little larger than the others, where the first requests of the iteration 1 has higher RTTs than the rest of values in the same iteration.
The JADE’s DF performance in the Desktop Linux machine according to requests frequency with No Delay (full frequency) (bookTrading)
Basically, these high RTTs values were observed at the beginning of all the evaluations that have been made. But, they were hidden because the RTT keeps on increasing after every new search request inside every iteration. When the RTTs drop down and stabilized after that, we noticed that something is influencing the response time when the evaluation starts. Therefore, this observation needed a further investigation by performing a system profiling (using JProfiler [40]), which detected that an activity of the garbage collector was started with the system execution and takes a lot of CPU resource for a small period. Another explanation was provided by the founders of JADE in [41] which can be relevant, where they explained that the performance degradation at the beginning of system execution may depend on several factors such as: (a) ClassLoading: At the first round, the agent classes as well as the DB driver classes must be loaded but at next rounds they are already there, (b) DB connections: At the first round, all connections with the DB must be opened. But, at the next round (depending on how you access the DB) they may be already there, and (c) just-in-time compilation.
It is clear now that at 6 ms delay between search requests the RTTs are stable and can handle high number of requests even if they are not optimal, while under 6 ms delay. The JADE’s DF starts to lose scalability and as known that the search response time in the late versions of JADE starting from JADE 4.2 was limited to 30000ms (30 seconds). Therefore, in every iteration shown in Table 4 where the Max value exceed 30 seconds, the system returns a timeout error. This is the reason why the 4.1 version was used, so we can test the limits, as in this case the DF could pass only the 4000 agents (2nd iteration) if an earlier version of JADE was used.
Next, our approach will be applied on the mentioned applications to enhance the matchmaking service especially at high request frequency when it did fail with the JADE’s default DF.
The first evaluation was with the bookTrading application with four extra DF copies and a search request frequency with no delay using five machines. The results are presented in Table 5 using only the median of RTT values, without missing to mention that in all the performed evaluations the number of requested services returned in every search response was the exact count of 100 services like with the JADE’s DF, which means a success rate [24] of 100%. The results in Table 5 have shown a great improvement in RTTs which means better performance and scalability of the yellow pages service than with the JADE’s DF especially in the Linux machines, the improvement percentage was stable at more than 99.5%.
The performance of the proposed approach with four new DF copies in using the bookTrading application and according to requests frequencies with no delay
The performance of the proposed approach with four new DF copies in using the bookTrading application and according to requests frequencies with no delay
The performance of the proposed approach with four new DF copies in using the bookTrading application and according to requests frequencies with 1 ms delay
The improvement percentage was calculated in every iteration by Eq. (2).
In Windows machines, about 25% to 45% in performance improvement percentage was obtained, where it was maintained at about 42–44 % with more than 4000 running agents, which is different than the Linux machines results where it was stable at more than 99.5%.
The performance of the proposed approach with four new DF copies in using the Translators application and according to requests frequencies with no delay
The proposed approach evaluation on bookTrading with 1 ms delay. The proposed approach evaluation on bookTrading with no delay.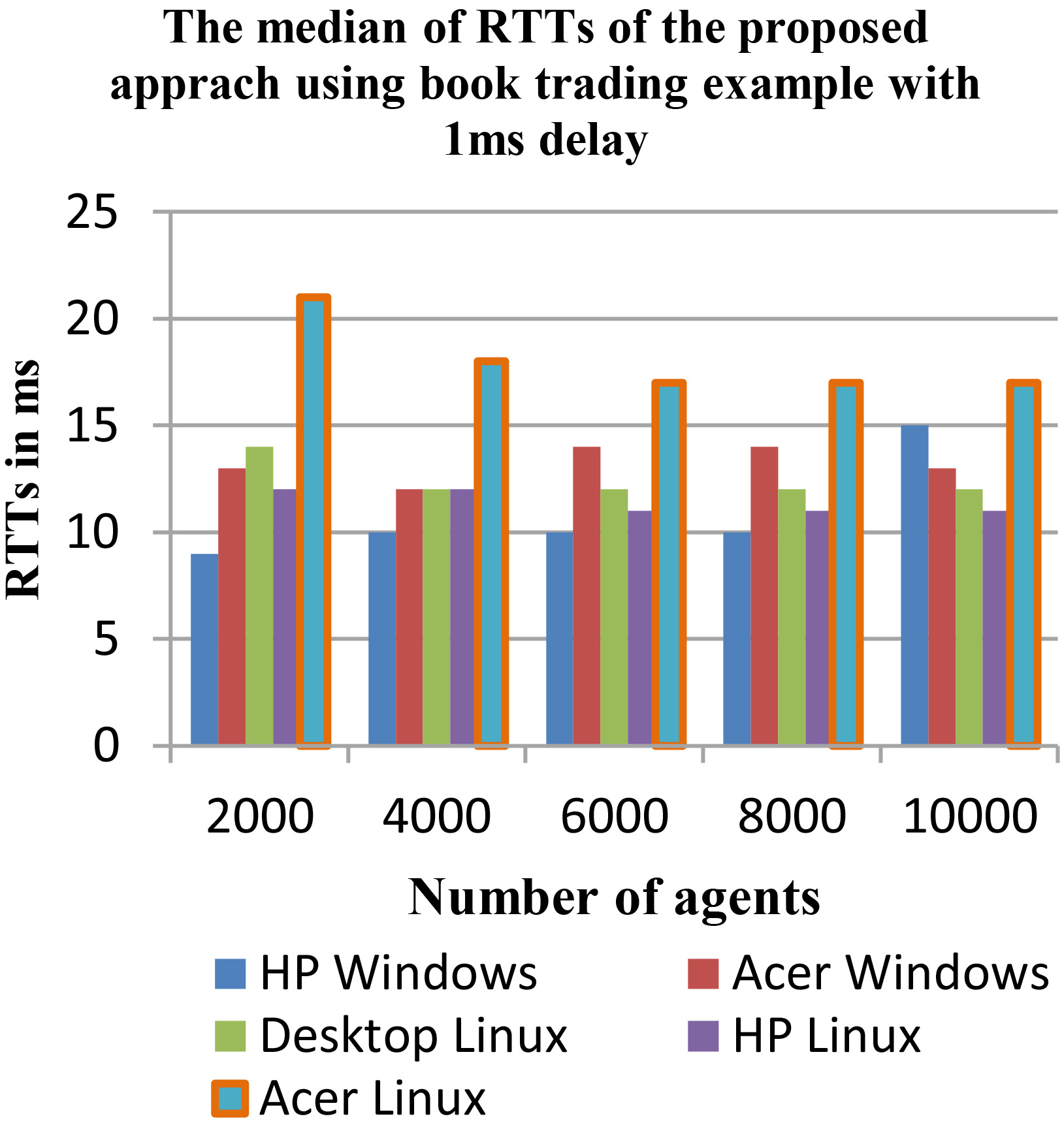
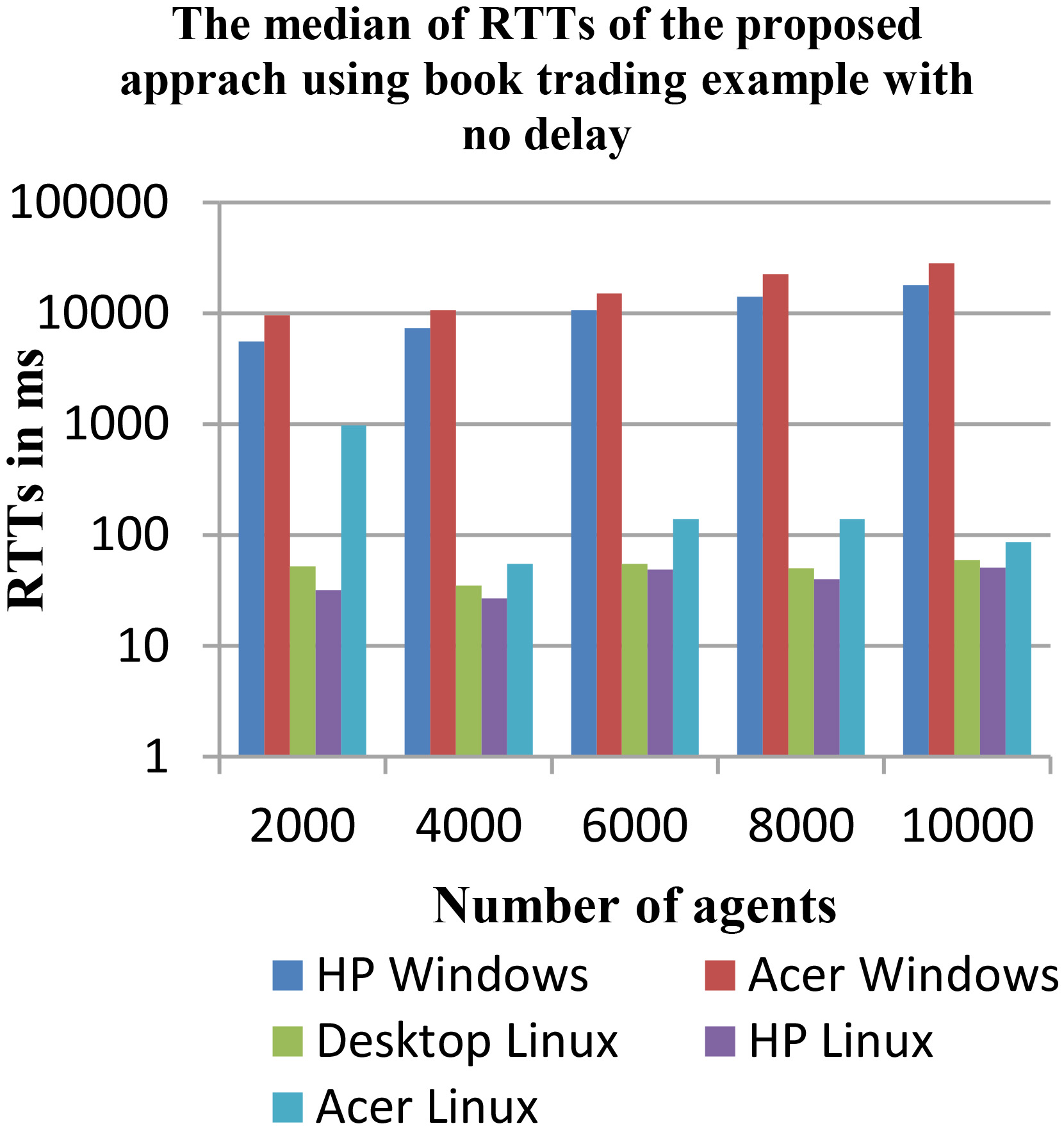
In Table 6, the results for the evaluation using bookTrading example according to requests frequencies with 1ms delay show a significant and stable improvement percentage of more than 99.5% even with the Windows machines with median of RTTs from 9 ms to 15 ms. While the RTTs were even more optimized with Linux systems than the previous no delay evaluation with median of RTTs of (11 ms and 12 ms).
So, it is only in the no delay evaluation using windows machines where the proposed approach did not result as expected theoretically and practically like in the Linux machines, which means that the operating systems has definitely an impact on the approach. Unfortunately, no other explanation is found yet, unless other investigations have to be performed.
For visual presentation of the results, Figs 9 and 9 present the evaluation of the proposed approach on the bookTrading example using 1 ms and no delay in requests frequency. For each used machine the scalability and the performance were secured, except for the Windows machines with the no delay evaluation where the system has been enhanced by up to 45%.
The maximum number of agents reached before (10000 agents) has been increased to 50000 agents in one last evaluation using the bookTrading example, which has showed a significant scalability and performance improvements just like with the 10000 agents.
The second evaluation was performed on the Translators application that we developed. It is a simple JADE application which require one type of agent to request some words translation from three possible agent types that offer translation services of three languages Dutch, French and Arabic (each agent type offers translation to only one specific language).
Differently from the bookTrading example, in this evaluation, the number of the registered services is 300 services (100 translator agent for each language) instead of 100 services.
The results of this evaluation are presented in Table 7 using five computers with no delay in requests frequency. The obtained RTTs were approximately similar to those of the bookTrading example, where the best improvements were in the Linux machines.
In Table 8, the results for the evaluation using Translators application according to requests frequencies with 1ms delay shows a significant and stable improvement percentage of more than 99% even with the Windows machines. While the RTTs were even more optimized with Linux systems than the previous no delay evaluation. Compared to the bookTrading evaluation on Windows machines with 1ms delay, the RTTs obtained in this evaluation on Windows machines are slightly slower but very stable.
The performance of the proposed approach with four new DF copies in using the bookTrading application and according to requests frequencies with 1 ms delay
The last evaluation was performed differently from the two previous ones. A more complex JADE application named im2008-jade was used. The evaluation was performed on the five machines with only no delay in requests frequency and with 6000 requester agents. Noting that the number of returned services from the DFs was varied from 1, 3 to 5 services only, differently than before (100 services). The results are presented in Table 9 using the median of RTTs.
The performance of the proposed approach with four new DF copies in using the im2008-jade application and according to 6000 requester agents with no delay in requests frequency
Performance comparison between JADE’s DF and the proposed approach using im2008-jade application with no delay and 6000 requester agents.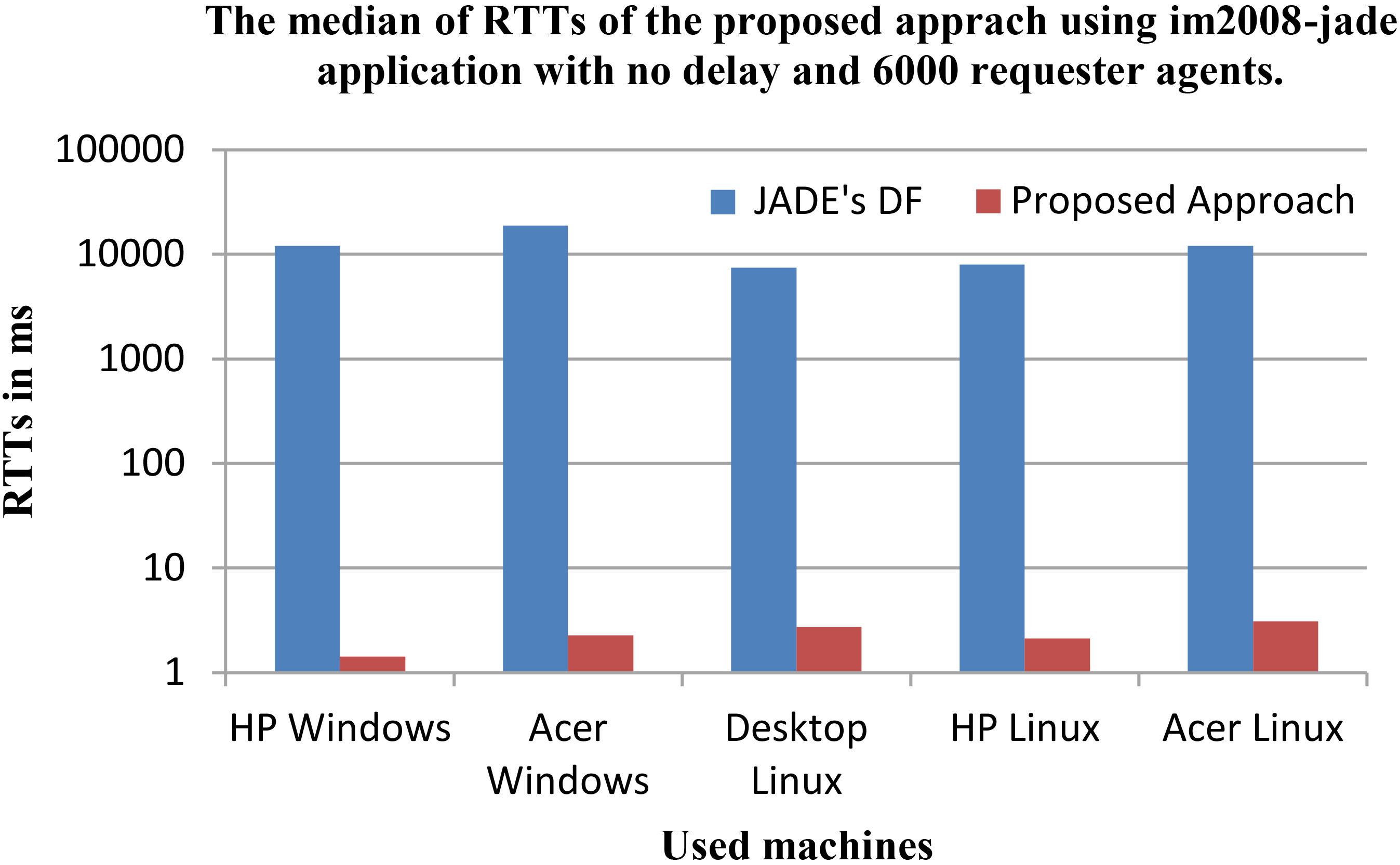
As expected, the improvements on the Linux machines where very promising like in the previous evaluations. Only that, in the Windows machines, the improvement percents were much higher than the previous evaluations on the same machines using no delay in requests frequency, where it reached now 99.99%.
Even that this application is more complex and larger in size, the results of the proposed approach were very significant than the two simple examples. This could mean that: (a) The DFs does not spend much time in searching services because only few have been registered (1 to 5 services), and yet, a bottleneck was detected in the JADE’s DF. So, the pressure of requests was nicely handled by the proposed approach. (b) Other application’s functionalities were influencing the evaluation. Therefore, for better performances evaluations where much pressure is needed for bottlenecks situations, simple applications are preferred.
The presented diagram in Fig. 10 shows that JADE’s DF suffers from weak performance in all the machines, where the proposed approach has successfully enhanced the yellow pages service performance.
To investigate the impact of the proposed approach on the CPU and the memory usage, a profiling process has been performed using JProfiler [40]. The presented results in Figs 11 and 12 were obtained from the Linux desktop machine and performed on the bookTrading example with 4000 buyer agents and 100 seller agents with no delay on requests frequency. A sampling technique with the default 5 ms interval was used as a configuration of the JProfiler.
CPU load comparison with no delay in requests frequency.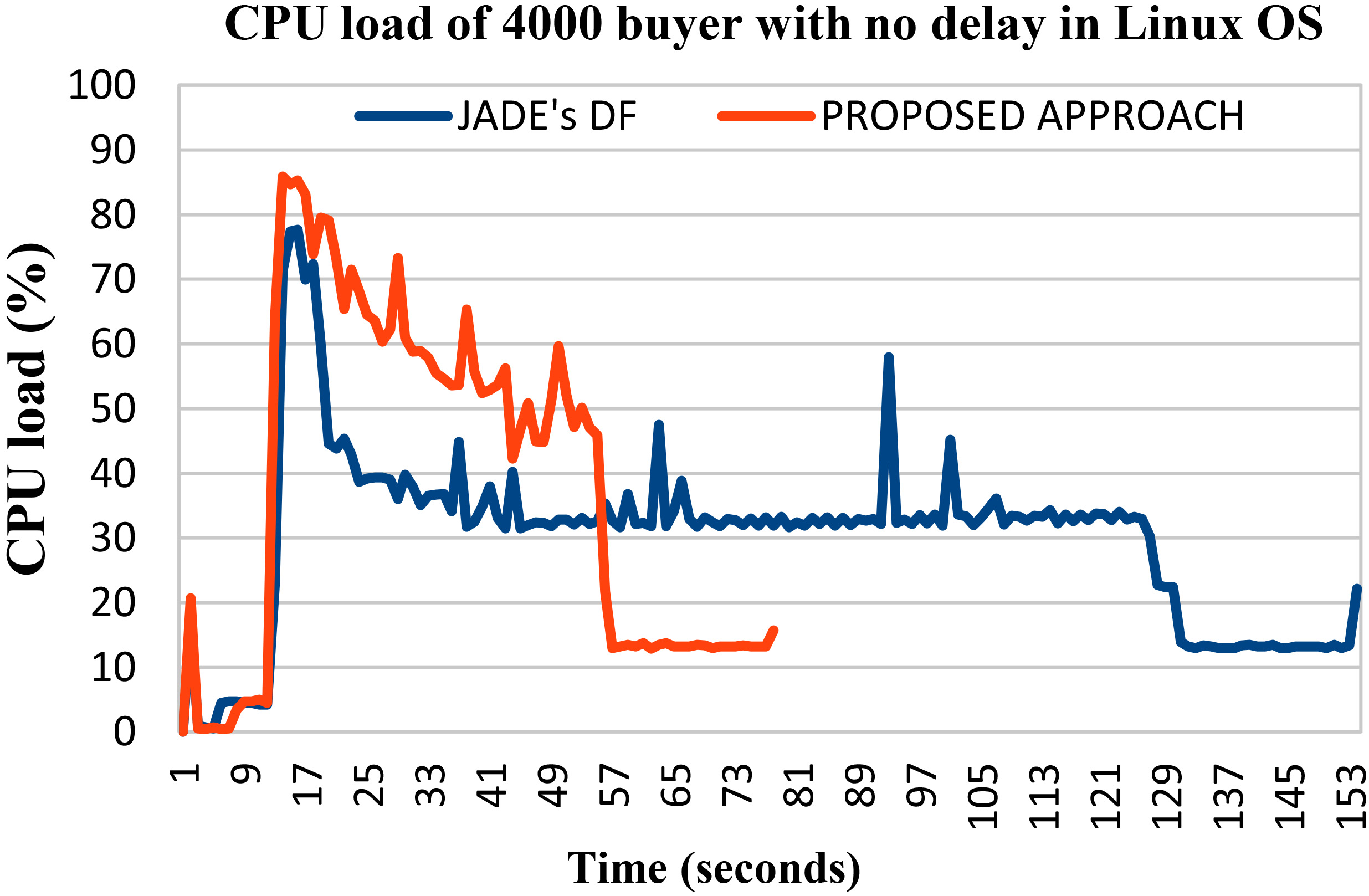
Memory usage comparison with no delay in requests frequency.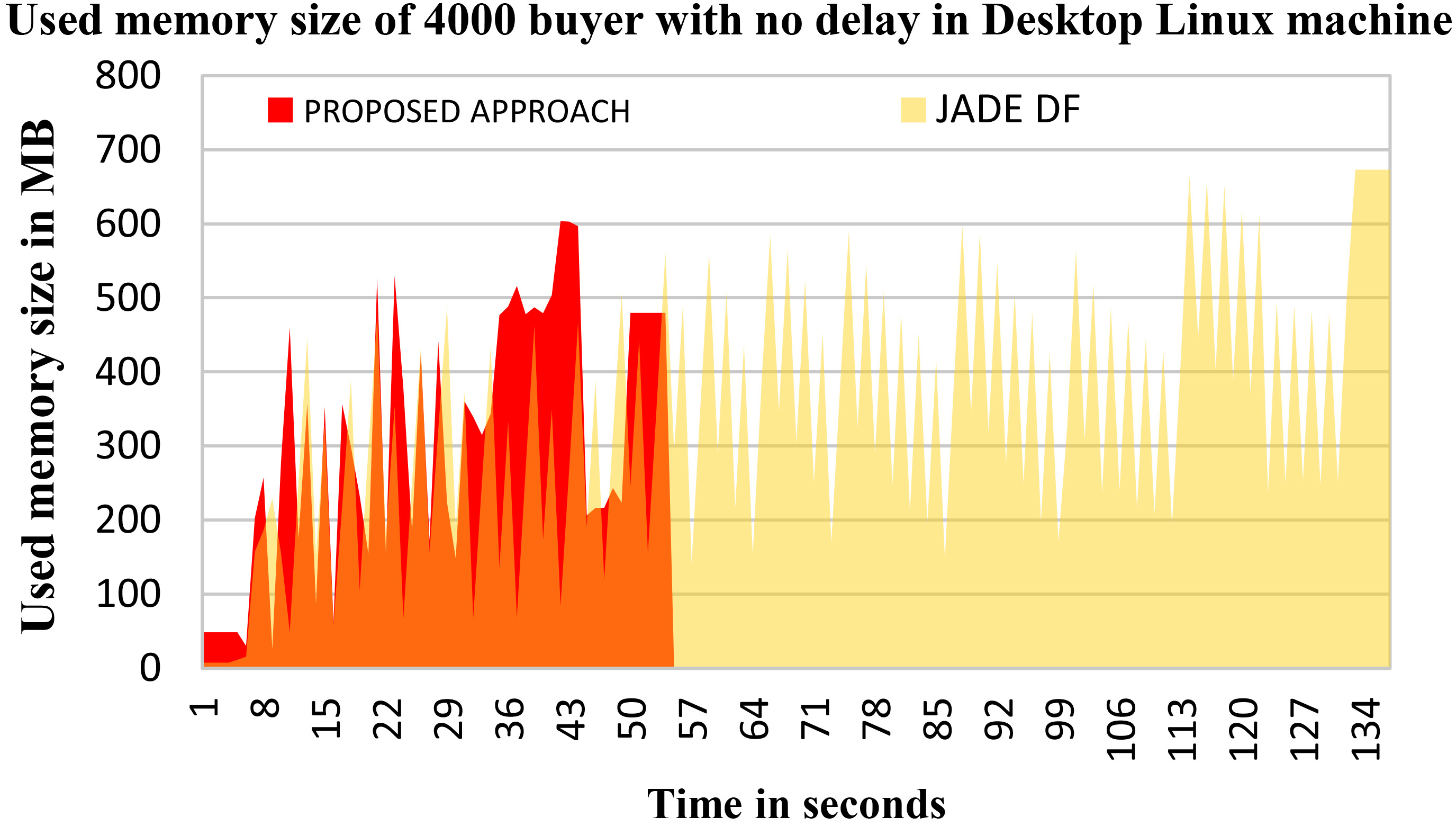
The selected buyers number (4000 agents) shows approximately the same CPU and memory usage variation when higher number has been used but with much more execution time, especially that the JProfiler has its own load on the CPU usage.
In Fig. 11, the CPU load diagram is presented where the buyer agents were started at the 11th second with an initial load of 4.5% on CPU usage.
The proposed approach’s curve shows an average increase of 20% of CPU usage than the JADE’s DF curve, while the overall execution time was decreased from 118 seconds with the JADE’s DF to 44 seconds with the proposed approach.
In fact, the high CPU usage can be seen as a negative point, even with that, a system that can’t exploit the full potentials of the machine or an added resources (better CPU ) when it is needed has a scalability issue.
In Fig. 12, the memory usage diagram is presented. The profiler has recorded a negligible increase of 0.54% in memory usage but much less memory occupation time, where the average of recorded memory sizes was from 253.45 MB with JADE’s DF to 254.83 MB with the proposed approach, during only the execution time of the proposed approach (44 seconds). But during all the execution time with JADE’s DF (118 seconds) an average size of 339.18 MB has been recorder.
In a large scale MAS, the yellow pages service implemented in a centralized manner in which a single agent is responsible for all the requests will face a big performance degradation due to service overload. This propagates a time delay in the system and can lead to a breakdown situation. This problem didn’t get much attention from researchers despite its importance.
In the literature, the proposed solutions are either: (a) new designs for the yellow pages service and can’t be integrated easily in an agent system unless they are applied within the agent platform used for the system development, or (b) refactoring approaches for the agent system’s source code which aren’t fully developed and need more enhancements to be able to handle all possible situations of an agent system. Our approach offers a replication of the yellow pages with a distribution strategy of search requests using aspect-oriented programming. Therefore, no changes in the source code are required, it’s easy to implement and to reuse. The proposed approach was evaluated on three JADE applications (bookTrading, Translators, im2008-jade) using five different machines. The obtained results are very promising in terms of reducing the search’s response time and handling more requests especially on Linux operating system with an improvement of more than 99% and a success rate of 100% in all the evaluations where all the search responses have the exact number of requested services (100 services). A CPU and memory usage profiling process has been performed to evaluate the impact of the proposed solution on the system. About 20% increase was observed in the CPU usage but with much less execution time than the original JADE’s DF and a negligible increase on the memory usage using the proposed approach with much less memory occupation time than in the JADE’s DF evaluation.
Further studies will be done to enhance our proposal by:
Proposing a sensor to detect any degradation in the performance and scalability of the yellow pages service during runtime, for starting and stopping the DF enhancer automatically. Proposing an approach to identify automatically the optimum number of yellow pages replicates needed to enhance the service, which can be changed during runtime depending on the service performance. Reducing the memory space after replicating yellow pages, especially when the number of registered services is high, by dividing the services on the DF agents and connecting them together, so that the request get passed to another DF if no results were found by the previous one. Adapting the approach for external DF requests in multi-hosts systems. Developing an eclipse plug-in that facilitates this maintenance process.
Footnotes
Authors’ Bios