
Abstract
Data distribution summary has been commonly used in databases to support query optimization, and histograms are of particular interest. A significant issue in histogram estimation is the large amount of data transmission. This paper presents a distributed and parallel construction method for equi-width histogram in cloud database (called DPHCD). Unlike previous methods, the DPHCD does not require the transfer of any table detail during histogram construction. Only small information about buckets and a few necessary data need to be transmitted over the network. The data transmission of DPHCD is unrelated with table size. DPHCD divides the histogram task into small tasks that could be simultaneously executed in a distributed cluster. It uses an innovative tablet-level sampling method to reduce the computing overhead in each cluster node. DPHCD is implemented in the Xugu cloud database management system. Experimental results demonstrate that DPHCD can achieve small data transmission and speed up histogram construction.
Introduction
The data acquisition method and source have become increasingly complicated with the rapid development of cloud computing, the Internet of Things, and the 4G communication technology. NoSQL (Not only SQL) databases based on key/value pairs, such as BigTable [1], HBase [2], Cassandra [3], MongoDB [4], and Redis [5], develop rapidly. However, these NoSQL databases do not support the transaction and SQL (Structured Query Language) interfaces in relational databases and are not fully compatible with existing business intelligence tools. Thus, they have many limitations [6]. Google’s Spanner [7], Oracle’s Exadata [8], and other relational cloud data management systems based on the share-nothing architecture, which have the extensibility of NoSQL and the efficiency of relational databases, still dominate their field.
In terms of the efficient summarization of data distribution and statistical information, histograms are important for improving the performance of data access in the cloud. The accuracy of data distribution assessment directly affects the execution sequence of basic algebra operations, such as join and selection [9]. Histograms can be classified into equi-width, equi-depth, V-optimal, compressed, maxdiff, and other histogram types according to their construction methods. One or many histograms are maintained in most commercial database systems. However, the popular relational database management system (RDBMS), Oracle, does not open its source code to users. Few literature exist on how to build a histogram inside a distributed RDBMS. On the contrary, many papers on building different types of histograms based on the distributed and parallel computing architecture, MapReduce, have been published in the annual top-level database conferences (i.e., Special Interest Group on Management of Data, International Conference on Very Large Data Bases, and International Conference on Data Engineering).
Histogram construction in single-node RDBMS has been studied extensively. Meanwhile, its implementation in the cloud has received limited attention [10]. Estimating histograms of data in cloud databases is challenging, and a simple extension of the traditional solution is insufficient. Cloud database is typically a distributed environment in which parallel processing, data distribution, data transmission cost, and other problems should be considered during histogram estimation. The issues studied in this work include the maximum use of computing resources in distributed working nodes to construct histograms and the direct combination of sub-histograms, which are built in distributed nodes. Network saturation should be avoided when processing large amounts of data in cloud databases.
Based on the study of the internal structure of NoSQL databases and the MapReduce framework, a distributed and parallel construction method for equi-width histogram in cloud databases (called DPHCD) is proposed in this paper. In this algorithm, histogram construction task is divided into several sub-histogram tasks in the application request node. The working nodes in the cluster are responsible for the actual estimation of each sub-histogram. The DPHCD obtains the global maximum and minimum values of the entire distributed cluster. Then, all the working nodes in the cluster estimate sub-histograms according to the global maximum and minimum values that could be directly accumulated to get the global histogram. Only local histogram information, which is very small compared to the table size, is transmitted across the network. To fully utilize the generated data in the sampling phase, tablet-level sampling is adopted for estimating sub-histograms in the working nodes. The main contributions of our work include the followings:
We present a novel algorithm for exploring data transmission over the network in a distributed cluster during histogram estimation to reduce network congestion in the cloud database. We adopt tablet-level sampling, which is significantly faster than the tuple-level random sampling method, to fully utilize the generated data in the sampling phase. We implement the DPHCD in the Xugu cloud database management system and conduct comprehensive experiments. The results suggest that DPHCD is efficient in histogram estimation and scalable.
The rest of the paper is organized as follows. We briefly introduce the storage architecture of the cloud database and the overall framework of the proposed algorithm in Section 2. The design and implementation details of the DPHCD approach are discussed in Section 3. Using this method, we explain how the reduction of data transmissions is achieved in Section 4. Section 5 shows representative experimental results, Section 6 discusses related works, and Section 7 concludes the paper.
Cloud database
With the recent development of cloud computing, the importance of cloud databases has been widely acknowledged. A cloud database is a collection of structured or unstructured content that resides on a private, public, or hybrid cloud computing infrastructure platform. Many cloud databases for managing data in the cloud exist. Each cloud database product is implemented differently and often attempts to address different kinds of data management requirements and priorities. To provide details of cloud databases, we briefly introduce one of the most useful cloud databases, HBase.
Storage architecture of HBase
HBase is a key-value store that supports a single data abstraction known as the table-structure (popularly referred to as column family), which is based on the Google Big Table design. HBase is designed to work on top of the Hadoop Distributed File System (HDFS). It accesses HDFS storage blocks directly and stores a natively managed file type.
HBase uses partitioned/shared data and master-slave distributed architecture, where data is hashed and sent to a set of external master processes known as “region servers”, which are responsible for managing subsets of the key space. Region servers write data (thru several layers of indirection) to HDFS, which ensures data availability thru file system replication. The architecture of HBase is shown in Fig. 1.
The HBase architecture has two main services: HMaster, which is responsible for coordinating Regions in the cluster and executing administrative operations, and the HRegionServer, which is responsible for handling a subset of the table’s data. Each HRegionServer serves a set of HRegions, and one HRegion can be served by only one HRegionServer. HRegion is the basic element of availability and distribution for tables and is composed of a Store per column family. A Store hosts a MemStore and 0 or more StoreFiles (HFiles). A Store corresponds to a column family in a table for a given HRegion. The MemStore holds in-memory modifications to the Store. Modifications are KeyValues. When asked to flush, a snapshot of the current MemStore is taken before it is cleared. HBase continues to serve edits out of the new MemStore and create snapshots until the flusher reports in succeed. At this point, the snapshot is released. HFiles are where data reside and are composed of blocks [11].
Storage architecture of HBase.
The file of the Xugu cloud database is organized based on the relational model of the data. It stores a table in a sequence of rows (row-based). The database is stored as a collection of files. Each file is a sequence of records, and one record is a sequence of fields. A file can contain fixed- and variable-length records. Fixed-length records are easy to implement. Thus, we briefly introduce variable-length records. The organization of variable-length records using a slotted page structure is shown in Fig. 2.
Figure 2 shows that a certain number of bytes are allocated to the file header. The page header contains the number of record entries, the end of free space in the block (EFS), size of each entry (ES), and the pointer of each entry (EP). Intuitively, EFS points to the end of the free space, while EP points to the starting address of a variable-length record.
Slotted page structure for variable-length records.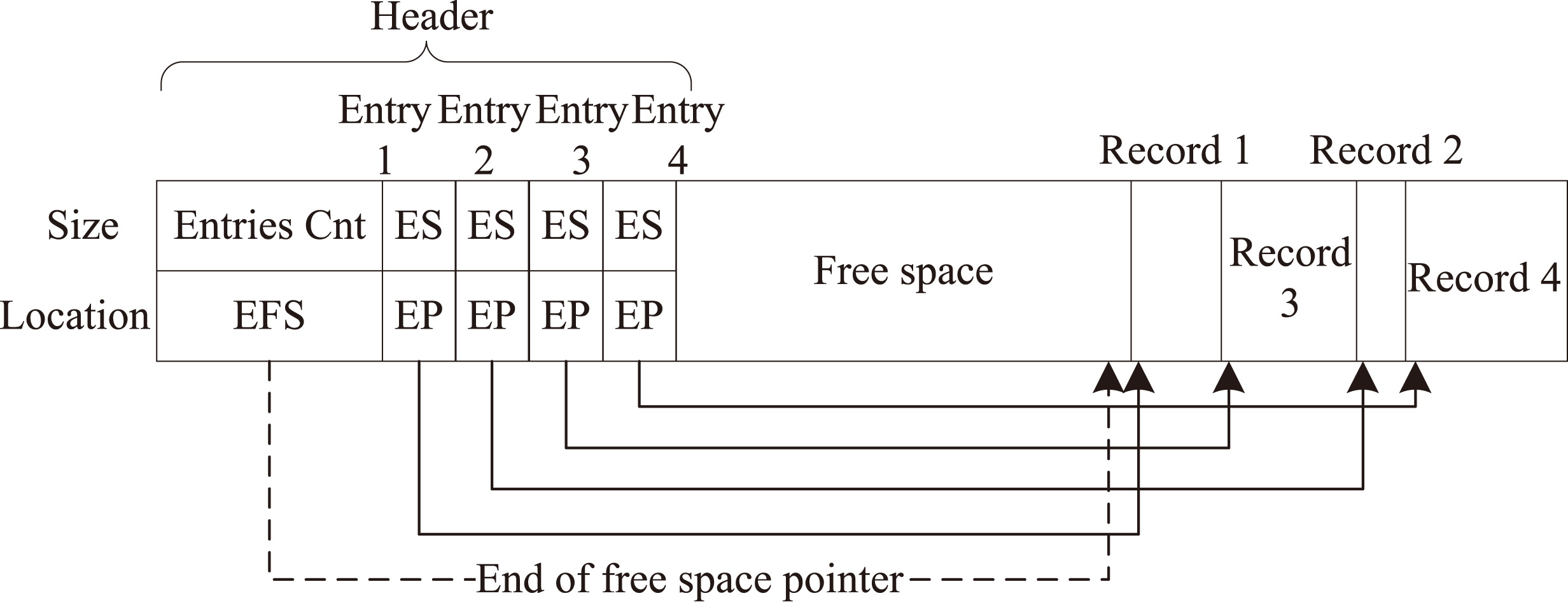
General storage architecture of Xugu cloud database.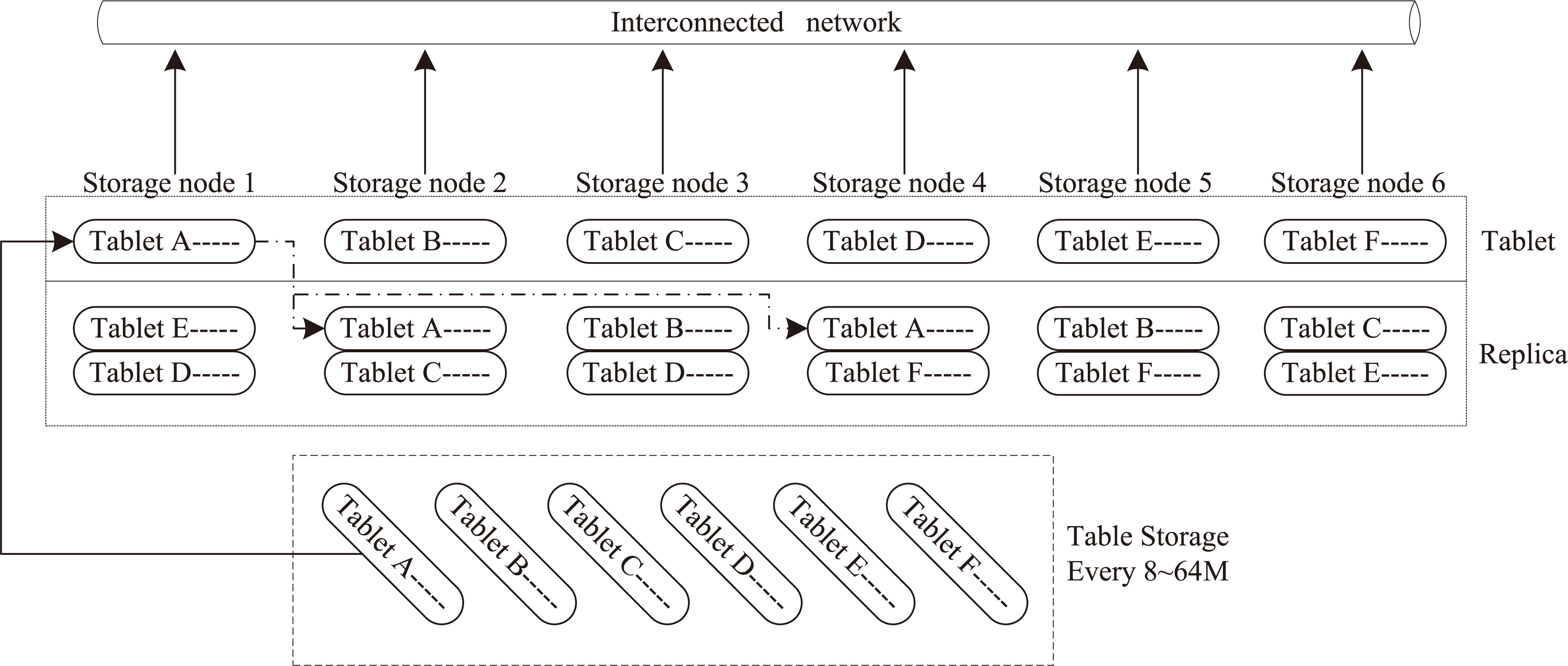
The file system of the Xugu cloud database is similar to the HDFS. The table files in the Xugu cloud database are broken into 64 MB tablets and distributed among storage nodes. Each tablet is replicated on a different distributed storage node to ensure fault tolerance. The general storage architecture of the Xugu cloud database is shown in Fig. 3.
Each tablet has two replicas that are randomly stored in the storage cluster. In Fig. 3, the table has 6 tablets labeled A, B, C, D, E, and F. These tablets are assigned to storage nodes through polling. Tablets A–F are stored in storage nodes 1–6, respectively. Each tablet has two replicas, and the replica randomly selects a storage node. For example, the first replica of tablet A is assigned to storage node 2, while the second replica selects storage node 4. Tablets transfer data information over an interconnected network. Figure 3 shows that different tablets with the same version of the table
According to the storage architecture of the Xugu cloud database, a file is split into one or more tablets, which are stored in a set of distributed storage nodes. These storage nodes serve read and write requests from the file system’s clients.
Overall framework of DPHCD.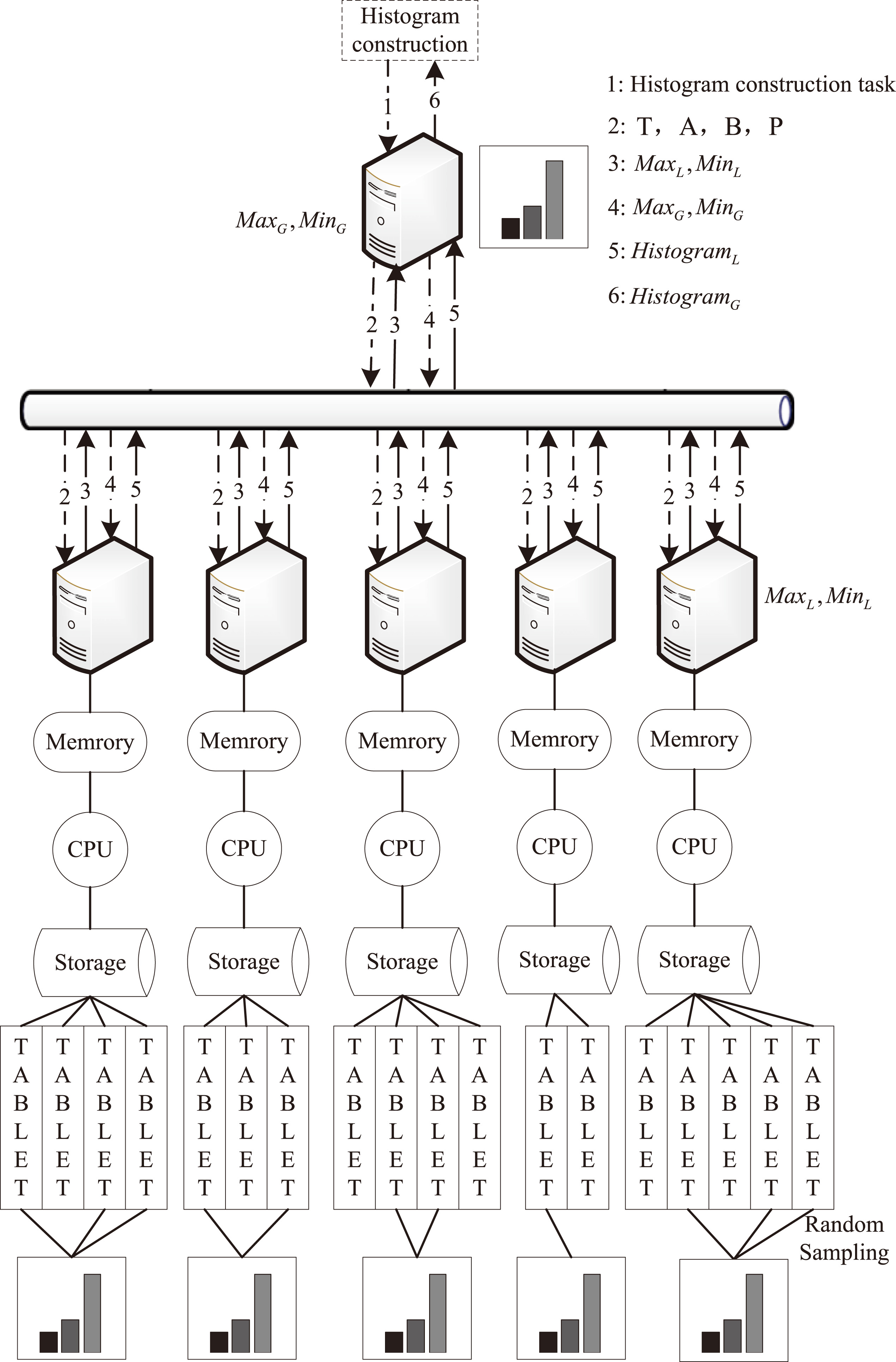
To construct an equi-width histogram in the cloud database, the origin method used in the Xugu database requires for all the tablets data in the distributed nodes to be obtained. Then, these data are scanned in the histogram request node to obtain the equi-width histogram. The origin method requires a full scan of the entire table, and all the tablets data should be transmitted to one node, which is expensive and may result in network saturation in the cloud.
From Fig. 3, we can see that a table is split into several tablets and are distributed into different storage nodes in the cluster. The number of tablets and data ranges stored on different nodes may be different. Therefore, sub-histograms which are built simultaneously in distributed nodes cannot be merged directly to obtain the global histogram. The overall framework of the DPHCD for constructing an equi-width histogram in the Xugu cloud database is shown in Fig. 4. In DPHCD, the histogram task is broken into small subtasks that can be built in distributed nodes to utilize the advantages of parallel computing to reduce execution time. Before estimating sub-histograms in distributed nodes, every storage node scans and sorts the local data of tablets to get the local maximum and minimum values. Then, the maximum and minimum values of the distributed nodes are transferred to the histogram request node to obtain the global maximum and minimum values. After all the sub-histograms are estimated according to the global maximum and minimum values in parallel. Finally, the histogram request node combines each bucket of these sub-histograms directly to obtain the global histogram. The detailed steps of the DPHCD algorithm is described in Section 3.3.
Generating the exact histogram requires every node in the distributed cluster to scan all the tablets, which involves a significant amount of time to complete. DPHCD constructs the approximate histogram with desired accuracy to reduce the construction time. A tablet-level parallel sampling algorithm is designed for approximate histogram. In Fig. 4, a certain percentage of tablets is sampled in parallel before estimating approximate sub-histograms in each distributed node. Tablet-level parallel sampling is discussed in Section 3.2.
As can be seen from the procedure above, the details of the tablets need not be transferred from the distributed storage nodes to the application node. The amount of data transmission over the network is significantly reduced. Data transmission over the network is discussed in Section 4.
Definitions
Without loss of generality, a table
Tablet-level parallel sampling
The amount of data in a cloud database is very large. Thus, generating the exact histogram requires full scan of the whole table, which is expensive and involves a significant amount of time to complete. Sampling is the process of selecting a representative sample from a target population and collecting data from that sample to recognize the statistical properties of the underlying data. The sample usually represents a subset of manageable size data. Sampling has been established as an effective tool for reducing the size of data and avoiding huge costs in subsequent processing. Constructing approximate histograms based on sample data to reflect the data distribution and summarize the contents of large tables is an efficient approach. Histogram construction has been extensively studied in single-node RDBMS, but has received limited attention in the cloud. Tablet-level sampling is adopted for estimating histograms in a distributed cloud database. The data in the cloud database are organized into tablets, and tablet is the unit of data stored in the cluster. To reduce the computational complexity of building a sub-histogram in each node, tablet is used as the unit of random sampling.
The tablet is selected uniformly and randomly with probability
Proof
Notice that there are some deviations from the frequency value of the
To enable a histogram construction task for large-scale data in a cloud database could be performed simultaneously in a distributed cluster. The histogram task should be divided into small sub-histogram tasks, which can be estimated in parallel. As shown in Fig. 3, tablets with the same version are stored on different storage nodes in the cluster. The size of data files, range of data, and other attributes in different nodes are irrelevant to each other. Thus, the sub-histograms constructed in distributed nodes cannot be merged directly.
Equi-width histogram is easy to construct. It can be estimated according to the maximum and minimum values and the number of buckets contained in the histogram.
The cloud database storage architecture in Fig. 3 and the definition in Section 3.1 show that
The proposed DPHCD algorithm constructs equi-width histograms in the Xugu cloud database using the following steps:
When a database client receives a histogram construction task through a SQL statement, the application request is sent to the database engine for execution. In the Xugu cloud database, any node in the cluster can be used as an application request node. Histogram construction task in the Xugu RDBMS is implemented by a stored procedure in the DBMS_STAT package, and the name of the stored procedure is ANALYZE_TABLE. The application request node with parameters, such as table name Each storage node, which stores tablets of table These Every node in the cluster has the same
In Eq. (5), Finally, the global histogram is shown to users.
The detailed workflow of the DPHCD algorithm in the Xugu cloud database which implements share-nothing architecture is shown in Fig. 4. The algorithm utilizes the advantages of parallel computing and does not need to transmit the detailed data of the table over network. DPHCD is suitable for constructing histograms for large-scale data. The pseudo-code of the DPHCD is shown in Algorithm 1.
Data transmissions reduction
In this section, we elaborate how data transmissions are reduced using an intuitive example. We assume a table
Data transmission of the origin histogram construction method.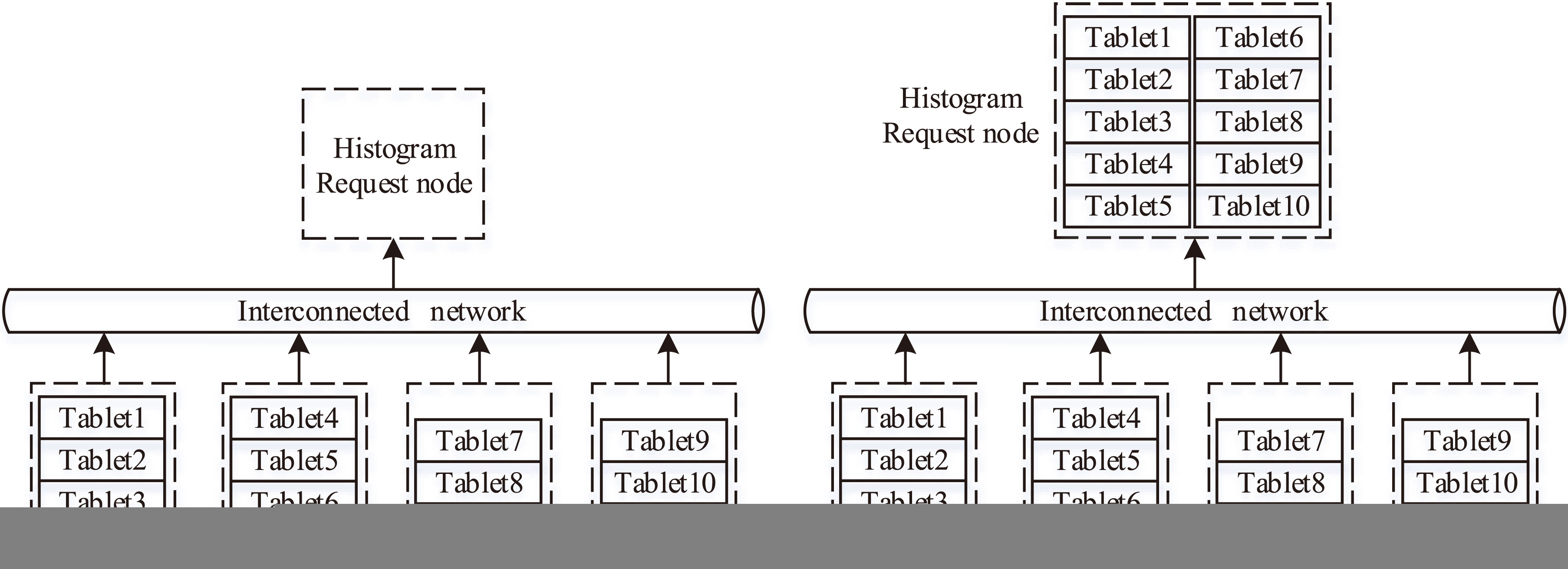
Data transmission of DPHCD.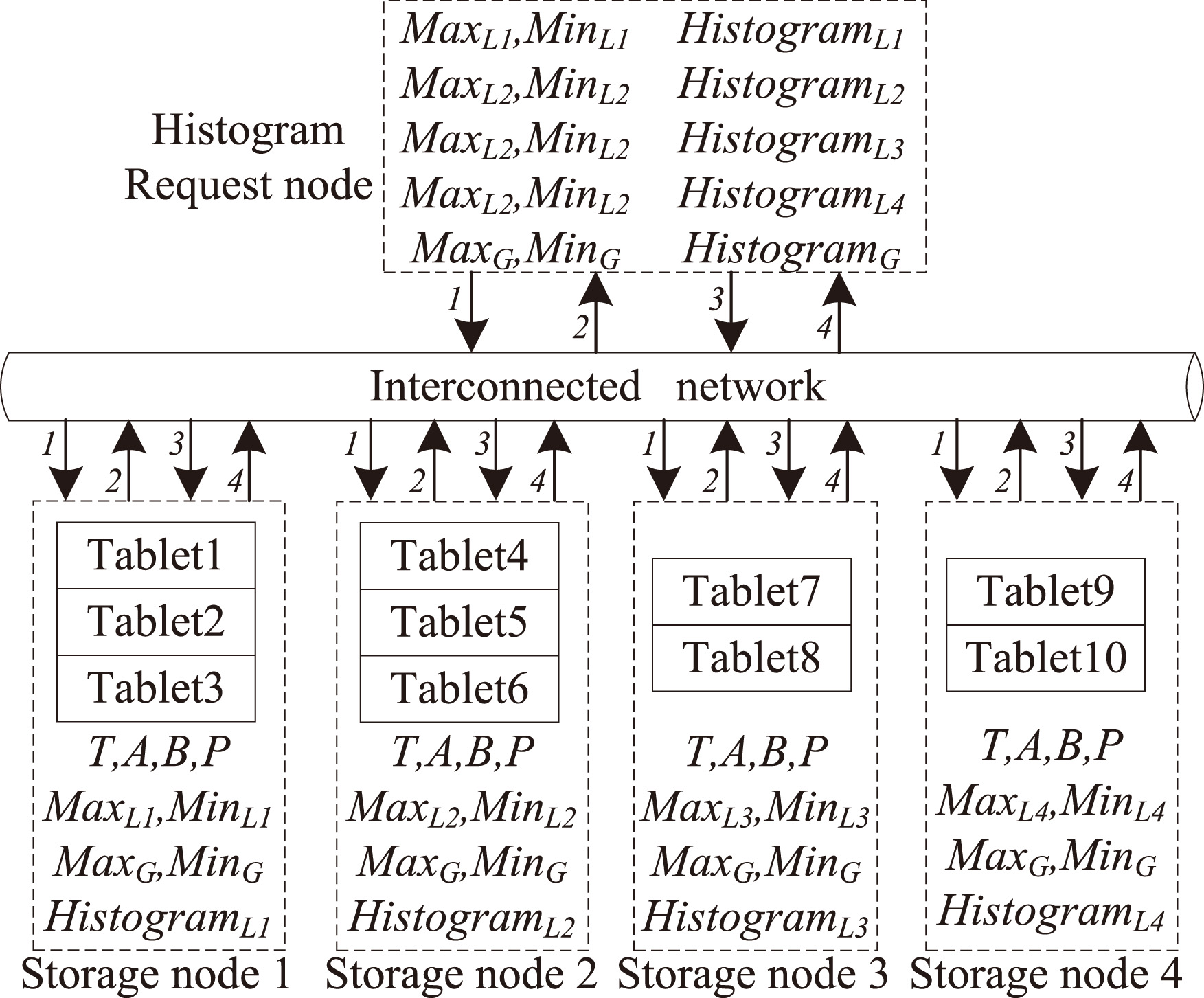
In DPHCD, when the node receives a histogram construction task, table name
The maximum and minimum values, bucket information, and sampling probability should be transmitted over the network during the estimation process. The detail data transmission over the network of the DPHCD algorithm is
The HEDC
Comparison of data transmission
Comparison of data transmission
Table 1 shows that during histogram estimation, the data transmission of HEDC
Line chart of Gaussian dataset.
Experimental design
To verify the effectiveness of the DPHCD algorithm in constructing equi-width histograms, three different experiments are designed as follow:
Effect of the number of buckets. Exact histograms that contain different numbers of buckets are constructed for synthetic data sets to demonstrate how the number of buckets can affect the data distribution with desired accuracy. The numbers of buckets in the histograms are 10, 20, and 100. For the real dataset, the exact and approximate histograms are estimated to verify the effect of the tablet-level sampling mechanisms. The histogram built on real dataset is set to contain 5 buckets, and the sampling probability is set to 0.4. Scalability evaluation. Experiments are conducted to evaluate the scalability by varying the node number of the testbed cluster for equi-width histogram estimation. The running time of the algorithm is observed by varying the number of machines in the cluster from 1 to 4. Comparison of running time. Experiments are designed to compare the DPHCD algorithm against the HEDC
Effect of histograms including different buckets. (a) 10 buckets histogram. (b) 20 buckets histogram. (c) 100 buckets histogram
Comparison between exact and approximate histograms.
All experiments are performed on a cluster running the Xugu cloud database, which is independently developed by a Chinese company in Chengdu, Sichuan. The cluster consists of 3 DELL PowerEdge R730 rack servers. Each machine is equipped with one Xeon E5-2603 v3 processor, 8 GB of memory, and 1.2 TB of disk, and is connected with 1 GB Ethernet. The Xugu cloud database can run on Linux, Windows, and various Unix platforms. In this experiment, it runs on Window Server 2008. The DPHCD algorithm is implemented using the C
We conducted experiments on synthetic datasets and real datasets to evaluate the performance gains achieved by the DPHCD algorithm. The synthetic datasets containing 100,000 records are generated with Gaussian distribution. Every tuple in the dataset includes three columns: primary key, data value, and data description. The maximum and minimum values are 4.2891 and
Experimental results and analysis
Effect of the number of buckets
In this experiment, each record in the synthetic dataset is inserted into a table in the cloud database. Three histograms, which contain 10, 20, and 100 buckets, are estimated using the DPHCD algorithm, and the results are shown in Fig. 8.
As shown in Fig. 8, the equi-width histogram with 100 buckets has higher accuracy in terms of data distribution than the histograms containing 10 and 20 buckets. The more buckets constructed in a histogram, the more detailed the description presented for data distribution. However, increasing the number of buckets in the histogram inevitably leads to high storage and computing overhead. When the size of the dataset is fixed, the accuracy of data distribution cannot be improved by increasing the number of buckets excessively. The bucket number of a histogram should be determined by data size, data characteristics, and desired accuracy with specific conditions.
Approximate and exact histograms are estimated on the real dataset, as shown in Fig. 9. The real dataset contains 24,000,000 ratings applied to 40,000 movies by 260,000 users. Figure 9 illustrates that the frequency of ratings between (3, 4] is the highest and nearly reaches 40% of the whole data. The comparison between the exact histogram constructed on the entire data and the approximate histogram constructed on the samples verify that tablet-level sampling also provides accurate estimated results for equi-depth histograms. Histograms provide data distribution information that are valuable for rating prediction, user analysis, and so on.
Scalability experiments. (a) Scale-up experiment on synthetic dataset. (b) Scale-up experiment on real dataset.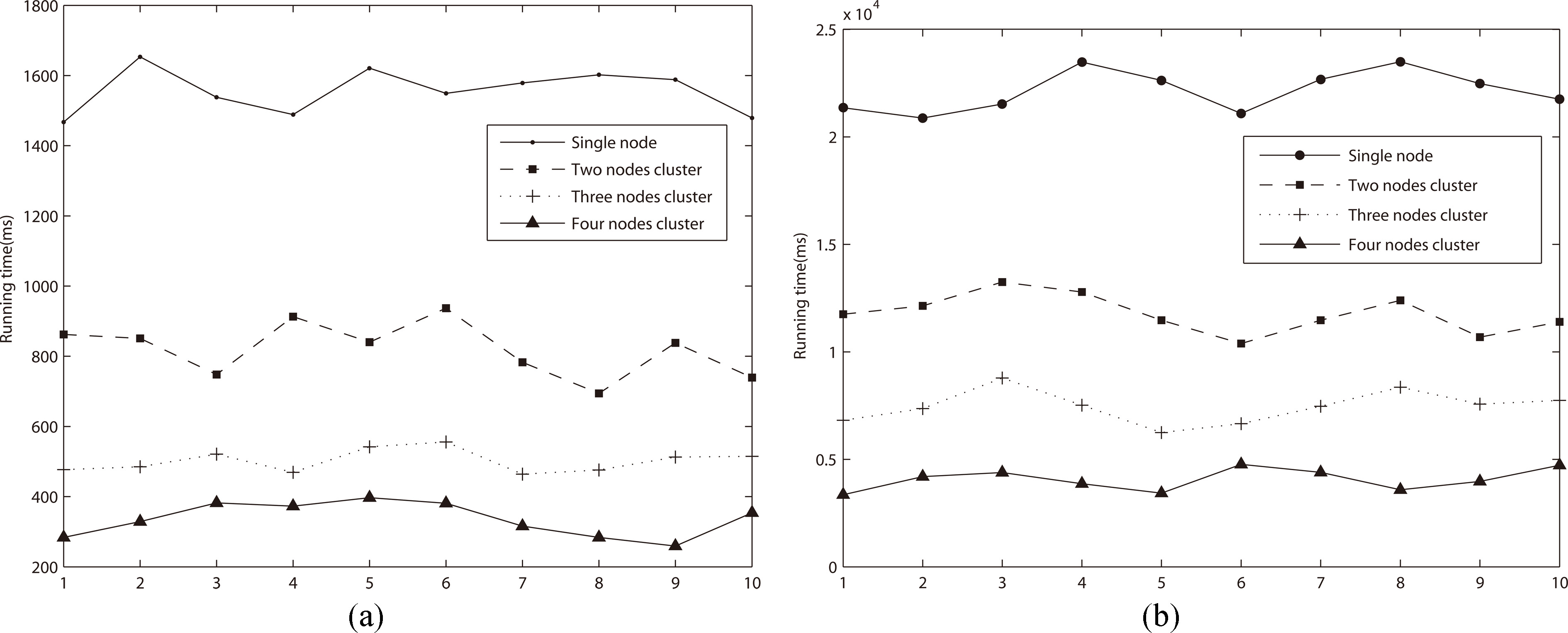
Scale-up experiments are conducted to evaluate the scalability of the DPHCD algorithm. As we add and reduce machines in the cluster, the running time of the histogram task that can be executed within a given time should be increased and decreased by the same factor. Two scale-up tests are conducted for the synthetic and real datasets. For the synthetic data set, the runtimes of estimating an exact histogram are compared by varying the number of machines (From 1 to 4). Meanwhile, the approximate histogram is constructed 10 times on the real dataset under the same condition as that for the synthetic dataset. The results are shown in Fig. 10. The results of equi-width histogram construction on synthetic and real datasets in Fig. 10 illustrated that the running time of DPHCD decreased with the increasing number of nodes in the cluster. This is because when machines are added in the cluster, more nodes can process the histogram task after balancing the workload of each node. The results demonstrate that the DPHCD algorithm can reduce histogram construction time using parallel computing in a distributed cluster and has scalability for cluster scale.
Comparisons of running time and data transmission
5.3.3.1 Execution time
In [21], the HEDC
5.3.3.2 Data transmission over the network
In Section 4, we obtain the detail data transmission over the network is
Comparison with HEDC
on data transmission
Comparison with HEDC
Comparison with HEDC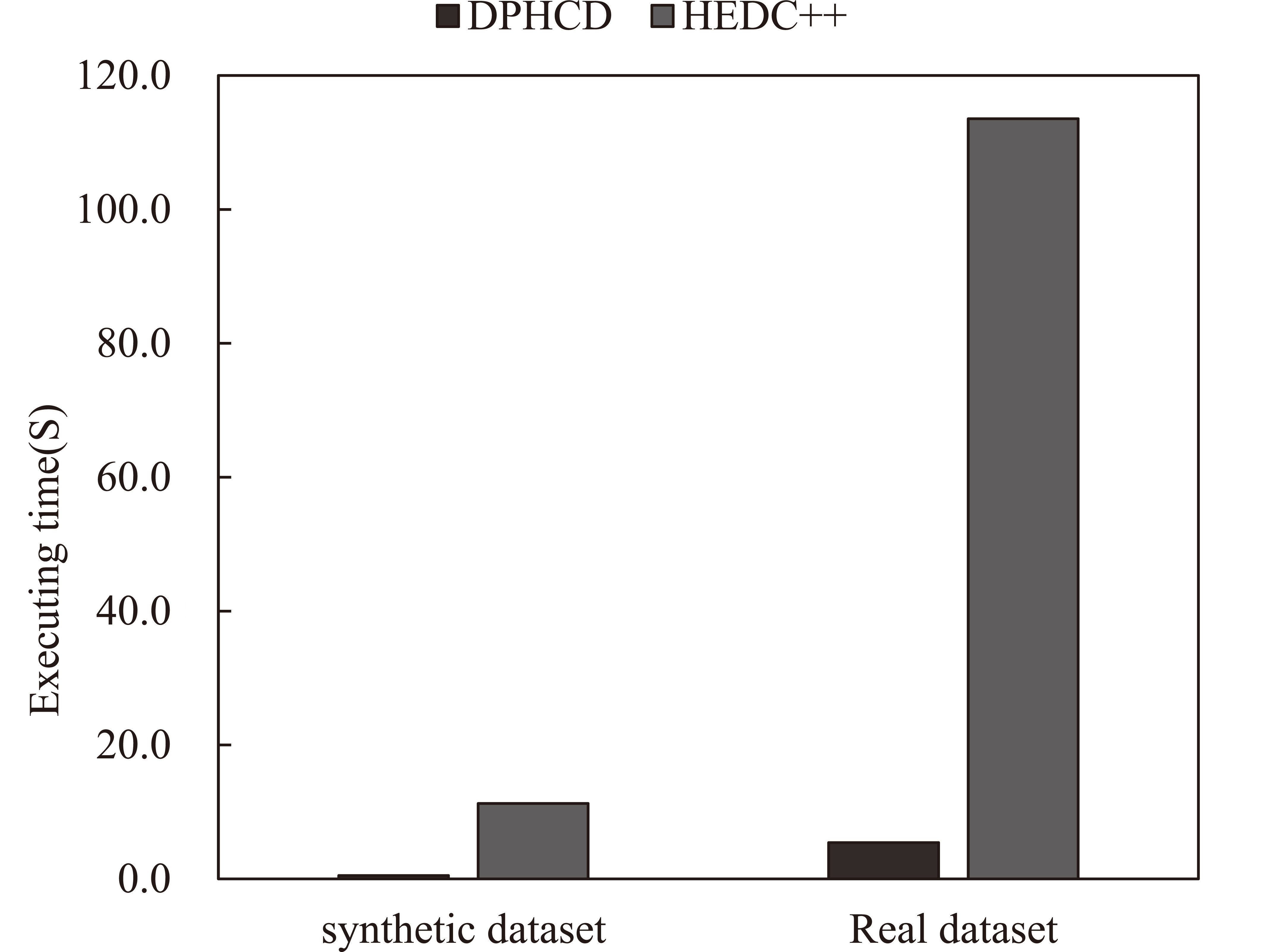
Histograms play an important role in cost-based query optimization, approximate query, and load balancing in the database. In Oracle database, the histogram is used to evaluate data distribution to optimize query plans. Estimating histograms is extensively studied in the field of single-node RDBMS. However, many limitations exist in the big data environment.
Ioannidis [12] surveyed the history of histogram and its comprehensive applications in data management systems. [13] analyzed different types of histograms and their properties. Chaudhuri et al. [14] proposed an approximate histogram construction method based on sampled data, which provided the exact relation between the size of the sampled data with the histogram. Luo et al. [15] developed an adaptive histogram construction method in compressed database. The method tracks hot data in compressed databases by scheduling batched queries and using the feedback in query results to accelerate the convergence speed of the constructed adaptive histogram that can be maintained incrementally. Bruno et al. [16] introduced a “workload-aware” histogram called STHoles that allows bucket nesting to capture data regions with reasonable uniform tuple density. Kanne and Moerkotte [17] designed new bucket types that do not store the number of distinct value and average frequency in the buckets of histogram. All the above methods focus on histogram estimation in the single-node database management system. Adapting them to the cloud environment requires sophisticated considerations. The proposed method is concerned with building histograms in parallel in the cloud environment.
With the arrival of big data era, several scholars have begun to study the parallel histogram construction method based on the MapReduce framework. Jestes et al. [18] proposed a wavelet histogram construction algorithm based on MapReduce using tuple-level sampling method. [19] presented a comprehensive study on the scalable histogram for large probabilistic data sets in MapReduce. They focused on V-optimal histogram based on the expectation-based semantic for the value and tuple models. The MaxDiff histogram construction method based on MapReduce is similar to V-optimal histogram estimation method, with the histogram type as the only difference [20]. Shi et al. [21] extended the original MapReduce framework by adding a sampling phase and a statistical computing phase, which focuses on estimating the equi-width and equi-depth histograms for data in the cloud. To fully utilize the data generated in the sampling phase, they adopted the block of the HDFS as the sampling level. In the MapReduce programming model, each job is divided into two phases: a map phase and a reduce phase. The above techniques based on MapReduce require the transfer of data over the network from the map phase to reduce phase. They retrieve tuples from the block randomly and send the outputs of mappers at certain probability, which aims to provide unbiased estimated histograms and reduce communication. However, the sampled method has a limitation. The sampled data should still be transferred over the network, which entails the use of a certain percentage of network bandwidth. Yıldız et al. [10] proposed a merge-based histogram construction method with a histogram processing framework that constructs an equi-depth histogram for a given time interval. This method is similar to our proposed algorithm, which requires transferring precomputed equi-depth histograms of data partitions. They implemented the method on Hadoop, whereas our method is applied in a relational cloud database.
The histogram computational task can be broken into several subtasks that can be processed independently in a distributed cluster based on the MapReduce architecture. The performance is improved significantly compared to the traditional database. However, the above approaches require the transfer of the converted intermediate key-value pairs from the map phase to reduce phase, which results in high data transmission over the network. The proposed algorithm utilizes the advantages of parallel computing and reduces the amount of data transmission over the network for large-scale data in the cloud database. Few information and sub-histograms, which are built in distributed nodes, are required to be transferred over the network. Data transmission is significantly reduced using the proposed algorithm. The distribution of data may be skewed and lead to highly varying execution times in distributed nodes. The node with low load has to wait for the node with high load. This reduces the overall performance of the algorithm. During sub-histogram estimation, the load balance between different nodes is not considered in this paper.
Conclusions
In this study, we address the problem of constructing equi-width histograms in the cloud database. A novel solution, which can build several sub-histograms in a distributed cluster and only requires the transmission of few information to obtain the summary of data distribution, is proposed. Each node in the cluster estimates a sub-histogram according to the global maximum and minimum values of the entire cluster. Then, all the sub-histograms are directly accumulated to obtain the global histogram. During the histogram estimation, few histogram information are required to be transferred over the network. The approximate histogram construction using tablet-level sampling achieves the desired accuracy. The algorithm is applied to Xugu cloud database management. Experimental results show that the performance of the DPHCD is better in terms of time and data transmission.
Footnotes
Acknowledgments
This work is partly supported by the National Science Foundation of China under Grant Nos. 61640209, the Science & Technology Project of Sichuan under Grant No. SCMZ2006012, and the Science & Technology Project of Guizhou under Grant No. [2014] 2004, [2014] 2001, [2016] 7433 and [2015] 13.
Authors’ Bios