
Abstract
This paper intends to perform de-duplication for enhancing the storage optimization. Hence, this paper contributes by proposing a hybrid fingerprint extracting using simhash (SH) and Huffman coding (HC) algorithms. Secondly, the data is clustered using the latest technique called as grey wolf optimization (GWO) to extract the metadata. The extracted metadata is stored in metadata server which provides better storage optimization and de-duplication. Euclidean distance based GWO is adopted as it provides minimum Euclidean distance in the GWO based clustering for de-duplication. The proposed GWO based clustering method is compared with the existing methods such as k-means, k-mode, Euclidean distance based Particle Swarm Optimization and Euclidean distance based genetic algorithm in terms of accuracy, True Positive Rate (TPR), True Negative Rate (TNR) and performance time and the significance of the GWO based clustering method is described.
Introduction
The rapid growth of data in data centres leads to the problem of data/file duplication [8]. A recent survey by International Data Company (IDC) concludes that data/files in the digital world are doubling every 18 months and more particularly, 75% of stored data are duplicated. Specifically, in the backup system, duplication rate of data exceeds 90% [1]. As the growth of data increased rapidly [4], there is a need to protect and optimize data. Additionally, data loss is also one of the major concerns. Promisingly, “De-duplication techniques” are widely used to enhance the data reliability and storage efficiency. Moreover, de-duplication is an effective and efficient technology that used to backup data [3]. Data De-duplication [1, 34] is a distinct technique for compressing data that eliminates redundant copies of replicating data. It may also define in terms of single-instance (data) storage [36] and intelligent (data) compression and single-instance (data) storage [35]. This technique can also use in network data transfer that minimizes the byte number that is sent and also enhances the storage utilization. While processing de-duplication technique, the byte patterns or unique chunks of data are recognized and stored for analyzing purpose.
De-duplication technique is not only felicitous for structured data but also advantageous for unstructured data like key-value stores, distributed file system and backup/archival systems [9] since mostly the entire files in the cloud environment and enterprise is duplicated. However, several de-duplication techniques are proposed and processed for storage efficiency. DupLESS [2] is one of the de-duplication techniques that solve the issue of convergent encryption (CE) scheme and provides a better privacy policy. Moreover, Content-Defined Chunking (CDC) [2] algorithm is a chunk-level de-duplication is there to solve the boundaries shifting problem. Furthermore, an inline de-duplication model named I-sieve [3] and Resemblance and Mergence based De-duplication scheme (RMD) [4] increases the system performance and provides rapid response to fingerprint queries.
However, data de-duplication technique also faces many barriers. Computational resource intensity is one of the major issues that faced by data de-duplication. Moreover, the integrity of data has also been a challenge for de-duplication system since it purely depends on the design of the de-duplication system. Another important obstacle that faced by the de-duplication system is Scaling since the scope of the technique is necessary to share among the storage devices. Apart from this, maintaining the quality of the data while processing is also a major pitfall of de-duplication technologies. Since many meta-heuristic approach [37, 38, 39, 40, 41, 42, 43, 44, 45, 46] was exploited for de-duplication. Further, the space efficiency is also adversely affected if the infrastructure has multiple disk backup devices with distinct de-duplication. Furthermore, the attacker may hack the data by guessing or knowing the hash values that are owned by others. Despite, numerous techniques or schemes are available for de-duplication; still, it needs an efficient de-duplication model for storage enhancement.
The main contribution of this paper is to present de-duplication for improving the storage optimization. Therefore, a hybrid fingerprint extracting using simhash (SH) and Huffman Coding (HC) algorithms is proposed in this paper. Moreover, the data is clustered by exploiting a renowned algorithm termed as GWO in order to extract the metadata. The hybrid fingerprint and the exploitation of GWO method to extract the metadata is the new approach, which is proposed in this paper. The extracted metadata is stored in metadata server that presents better storage optimization and de-duplication. Euclidean distance based GWO is adopted as it provides minimum Euclidean distance in the GWO based clustering for de-duplication.
The rest of the paper is organized as follows. Section 2 portrays the related works. Section 3 illustrates the modeling of a heterogeneous network. Section 4 depicts the proposed handover decision algorithm. Section 5 describes the simulation results, and Section 6 concludes the paper.
Literature review
In 2015, Xing et al. [1] had proposed a cluster de-duplication system named AR-De-duplication to improve the data reliability and storage efficiency. Usually, de-duplication systems always face some challenges such as communication overhead is high for data routing, data de-duplication rate is decreased with more de-duplication server nodes as well as load balance for throughput improvement. However, in routing server, to speed up the index of handprints they have utilized a mechanism named application-aware mechanism. The proposed de-duplication technique experimented in two real datasets. Moreover, the results have demonstrated that the proposed system had the capability of achieving high data de-duplication rate. Along with this, the communication overhead is also low and also maintained better load balancing since they have adopted new data routing algorithm. Further, the application-aware mechanism has provided 30% improvement regarding performance.
In 2016, Zhang et al. [2] have proposed a new CDC algorithm named Asymmetric Extremum (AE) code for chunk-level de-duplication. The proposed algorithm has solved the boundaries shifting problem in which the extreme values cannot be considered as a new extreme value. The proposed algorithm has experimented with real-world datasets, and the results have shown increased chunking throughput. Moreover, when compared to the existing CDC algorithms, the proposed algorithm has provided smaller chunk size variance, and it could find proper chunk boundaries even in low entropy string. Besides, the throughput performance of state-of-art CDC algorithms was also improved by the proposed AE algorithm. The improvement was 2.3 times higher than the existing algorithm, and while comparing, the system throughput has been enhanced more than 50%.
In 2015, Wang et al. [3] had proposed a novel de-duplication model that named as I-sieve. In the cloud storage system, the proposed de-duplication architecture I-sieve has aimed to get increased data sieve system performance which was on the basis of iSCSI. More particularly, they have presented the multi-level cache that reduced the RAM consumption and optimized the lookup performance by designing the mapping and index tables. Moreover, on the basis of open source iSCSI target, they have implemented the prototype of I-sieve. Further, the experimentation of the proposed architecture was carried out by testing tools and virtual machine images. The results have shown the excellent performance with the aid of de-duplication and foreground performance. More precisely, the proposed I sieve system architecture co-exist with the existing systems since it supports the iSCSI protocol.
In 2017, Zhang et al. [4] have proposed a de-duplication scheme that provided faster response to the queries of the fingerprint which was named as resemblance and mergence based de-duplication scheme RMD. Moreover, the ultimate goal of the proposed scheme was to reduce the range of query and to grasp a Bloom filter array. The proposed de-duplication scheme has used a resemblance algorithm in order to resemble the data segment and the corresponding resemblance segments were put together into the same bin. Therefore at the query session, to detect the duplicate content they need only to search in the corresponding bin and thereby the query process was significant speeds up. In addition, the proposed RMD scheme has exploited the frequency-based fingerprint retention policy and to accumulate resemblance segment; they have used a mergence strategy which improved the data duplication ratio and query throughput. The proposed RMD scheme has experimented with real-world datasets, and the results have shown that the proposed method could obtain high query performance and outperforms various de-duplication schemes.
In 2015, He et al. [5] had proposed a new scheme named public auditing policy for storing cloud system in which both the data integrity analyze and de-duplication of encrypted data were achieved together in the same framework. In such a way that the auditor could exactly check the integrity of de-duplicated data and cloud server could exactly check the new owner’s ownership. Along with this, the proposed method has used the method of proxy re-encryption that supported the de-duplication of encrypted data, and they aggregated the tags from varying owners and achieved the de-duplication of the data tags. The experimentation results have shown that the proposed scheme was more efficient and proved that the scheme was more secure.
In 2015, Kwon et al. [6] had proposed a secure de-duplication scheme along with user revocation to solve the problem that occurred in CE scheme. The problem of the CE scheme is even if the user lost his/her ownership to the cloud data, the CE based policy that permits users to decrypt the cloud data. In order to generate the encryption key, the proposed scheme has grasped the oblivious privilege-based encryption. The experimentation of the proposed scheme has been done on some data sets, and the security analysis has proved that the proposed scheme was safer from decryptions that are unauthorized by cloud server, brute-force attack and revoked users.
Taxonomy of de-duplication scheme.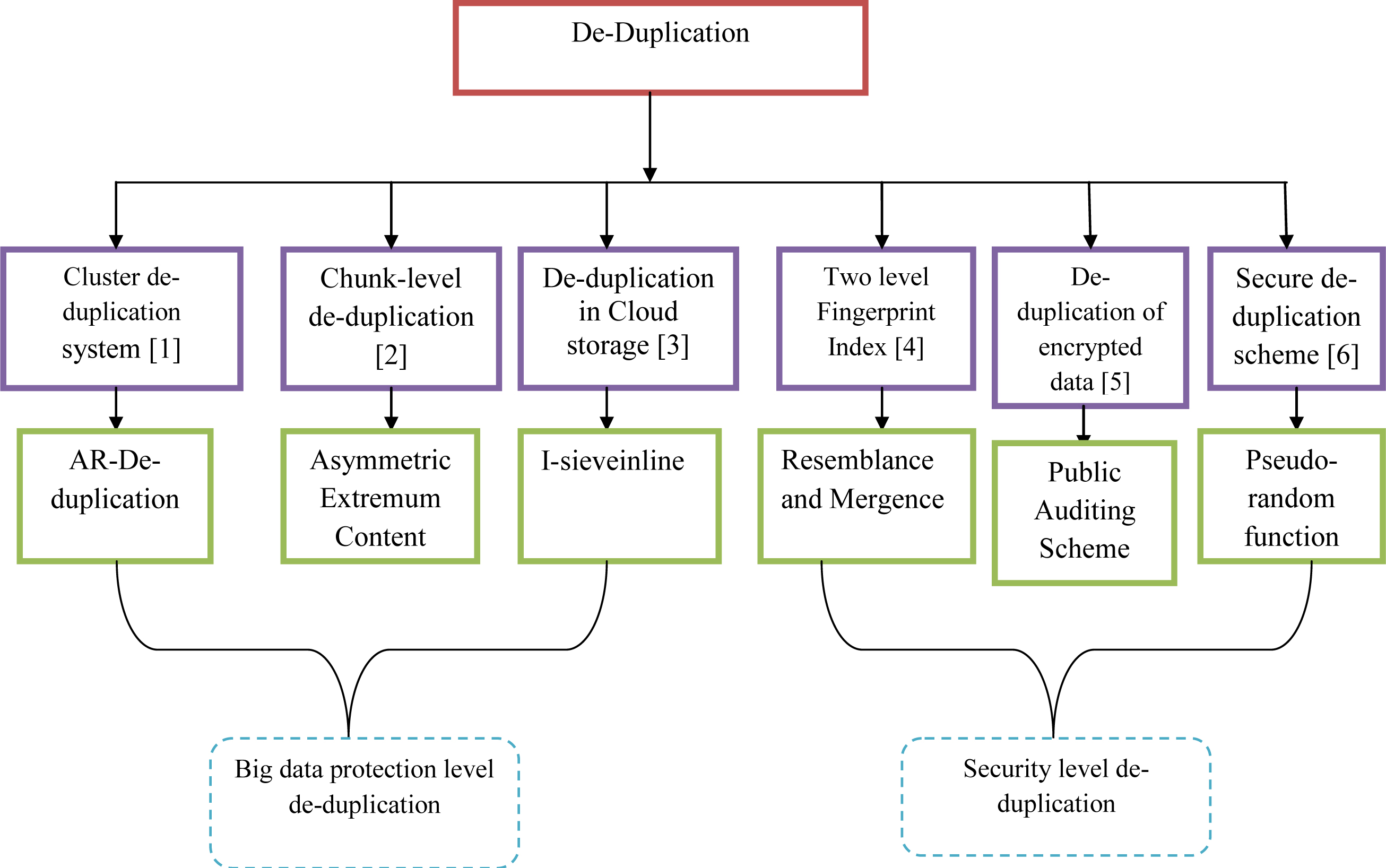
The properties and limitations of the literature review reveal the significance of adopted methodologies of data de-duplication. AR-De-dupe cluster de-duplication system [1] reduces the communication overhead, and meanwhile, it produces high data de-duplication rate. However, if the file is larger, it needs more capacity. Asymmetric Extremum (AE) Content-Defined Chunking (CDC) algorithm [2] gives high chunking throughput and able to eliminate low-entropy strings. But the experimental evaluation is difficult since it needs more tests. Similarly, I-sieve inline de-duplication model [3] supports iSCSI protocols, and it is possible to de-duplicate data in small storage environments but the computational time is more. Furthermore, RMD [4] achieves high query performance, but problems may occur while buffering fingerprints. Subsequently, Public Auditing Scheme [5] is more secure and also achieves de-duplication of data tags. But, the Computational process is complicated, and there is a chance of problem in the cloud if the data owners increased. Moreover, [6] protects from brute-force attack, but the access policy is complex. However, there is a need for efficient data de-duplication methodology for reliable and better storage enhancement. Figure 1 represents the taxonomy of de-duplication scheme.
Architecture of the proposed de-duplication method for storing files.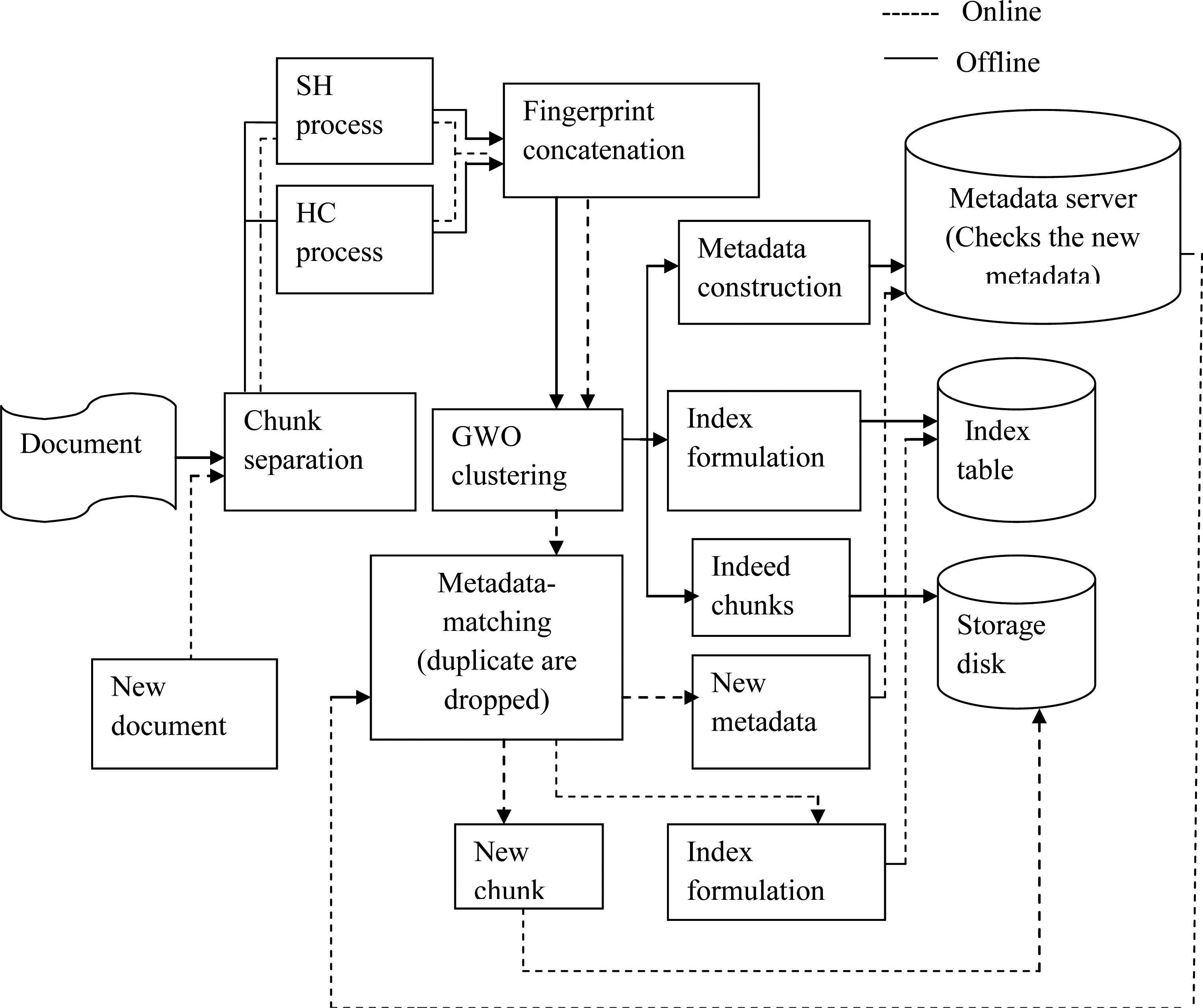
Figure 2 demonstrates the architecture representation of the proposed de-duplication method for storing files. In the process of storing metadata, two stages are involved the namely online storage and offline storage. In offline mode, when the webpage or document is provided, the chunks are separated initially. Then for detecting the near duplicates and to generate fingerprints, the separated chunks are subjected to simhash and Huffman coding. After generating the fingerprints using simhash and Huffman coding, the fingerprints are concatenated. The hash collision of exploiting concatenated simhash and Huffman coding as the fingerprint is possible but the compressed hash coded data is uncertain. To extract the metadata, GWO [27] method, which performs clustering, is employed. The resultant centroids from the clustering are constructed as metadata and saved into the metadata server. The index of the respective chunk is stored in the index table, while the chunks are indexed and stored in the storage disk. In online mode, when we attempt to save a new file, the chunks are first separated.
New chunks are formed for data that are mismatching and are stored in a storage disk. The new metadata generated are stored in metadata server. Then the index is formulated and stored in the index table.
Simhash fingerprint
In fingerprint computation, we use simhash algorithm [32] for addressing the near duplicates. simhash have two vital but conflicting features that make it an ideal method to address the presence of near duplicates. They are: (i) The fingerprint of a
Generation of fingerprints for file chunks using simhash.
Nowadays an advanced coding method known as simhash coding is used for extracting the fingerprints from chunks. Since the simhash based fingerprint focuses mainly on the indexing of the respective keywords, this paper proposes fingerprint based on Huffman coding [33] and to generate the final fingerprint by combining both the simhash and Huffman coding. The Huffman coding based fingerprint generates the fingerprint by providing more significance to the frequency of occurrences of the keywords, rather than their indexing. As Huffman coding provides the frequencies of the chunks, it helps for better de-duplication and chunk separation process.
Generation of fingerprint for file chunks using Huffman coding.
Exemplary Huffman coding tree for generating the fingerprint for chunk keywords.
Figure 4 demonstrates the generation of fingerprint for file chunks using Huffman coding. Figure 3 is explained by a Huffman coding tree in Fig. 5. The tree is constructed with different frequencies and weights are allotted to them.
In an Huffman coding tree, the corresponding symbol for any codes can be known by beginning from the root and moving down till we locate the particular leaf that carries the symbol. 0 is assigned for all the left branches and 1 is assigned to all the right branches in a tree. For example, in Fig. 4, we reach the leaf
The objective model for clustering the chunks is given in Eq. (1),
where,
Metadata, here, is the representative of the group of chunks to be presented as a fingerprint. To construct the metadata, the fingerprints of the chunks are clustered to identify the homogeneous and heterogeneous chunks. The homogeneous chunks are the chunks that share common keywords, whereas the heterogeneous chunks are highly different from each other. The promising clustering process is enabled at this moment to cluster the chunks for which the Euclidean distance-based similarity measure is exploited in the paper. There are wide ranges of algorithms such as k-means, SOMs [9] etc. Due to the lack of diversification and curse of dimensionality problem, this paper exploits GWO to cluster [28] the chunks.
To solve the objective model, which is given in Eq. (1), GWO [27] is adopted here. The GWO algorithm depicts the hunting mechanism and leadership hierarchy of grey wolves. There are four classifications of grey wolves such as
Initial centroid
In GWO, the grey wolves represent the optimal centroid Q
Flowchart to describe the steps involved in GWO.
Centroid representation for GWO optimization.
Here the centroid value is iterated until the best wolf is found out by minimizing the Euclidean distance based evaluation function
In the evaluation, the initialized centroids are evaluated using Eq. (1), since the objective is to minimize the error function; the wolves are assigned with
Centroid update
After initialization, the fitness values of the wolves are calculated. The best wolves
In Eqs (10) and (11), coefficient vectors are given by
After performing a number of iterations, the
| Percentage of duplication | k-mode | k-means | ED-PSO | ED-GA | ED-GWO |
|---|---|---|---|---|---|
| 10 | 0.352 | 0.362 | 0.402 | 0.425 | 0.598 |
| 20 | 0.456 | 0.485 | 0.489 | 0.498 | 0.685 |
| 30 | 0.624 | 0.634 | 0.658 | 0.666 | 0.695 |
| 40 | 0.657 | 0.663 | 0.674 | 0.684 | 0.725 |
| 50 | 0.698 | 0.721 | 0.722 | 0.754 | 0.845 |
True Positive Rate (TPR) versus % duplication for the proposed and conventional de-duplication methods.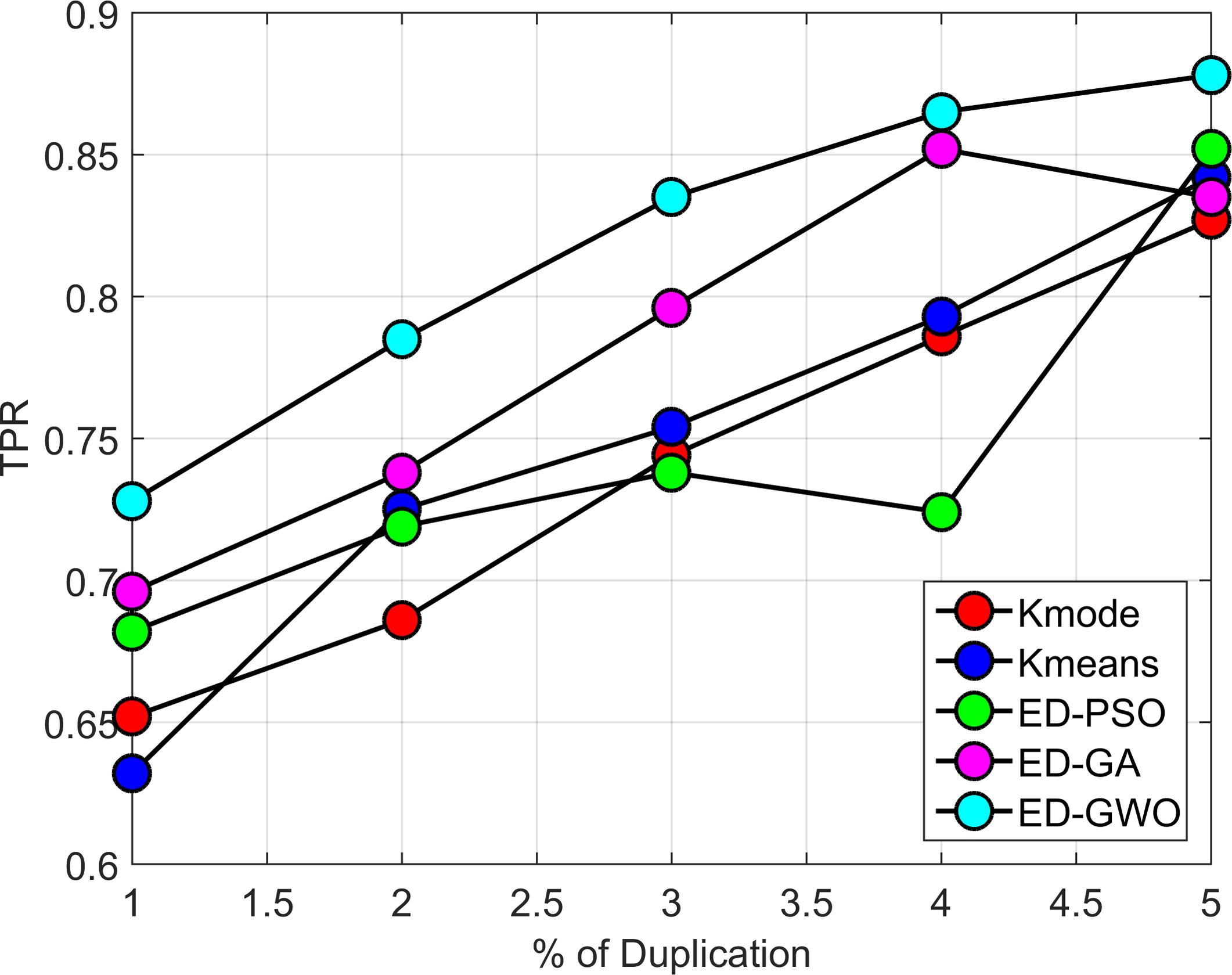
True Negative Rate (TNR) and % duplication between the existing methods and the proposed clustering method.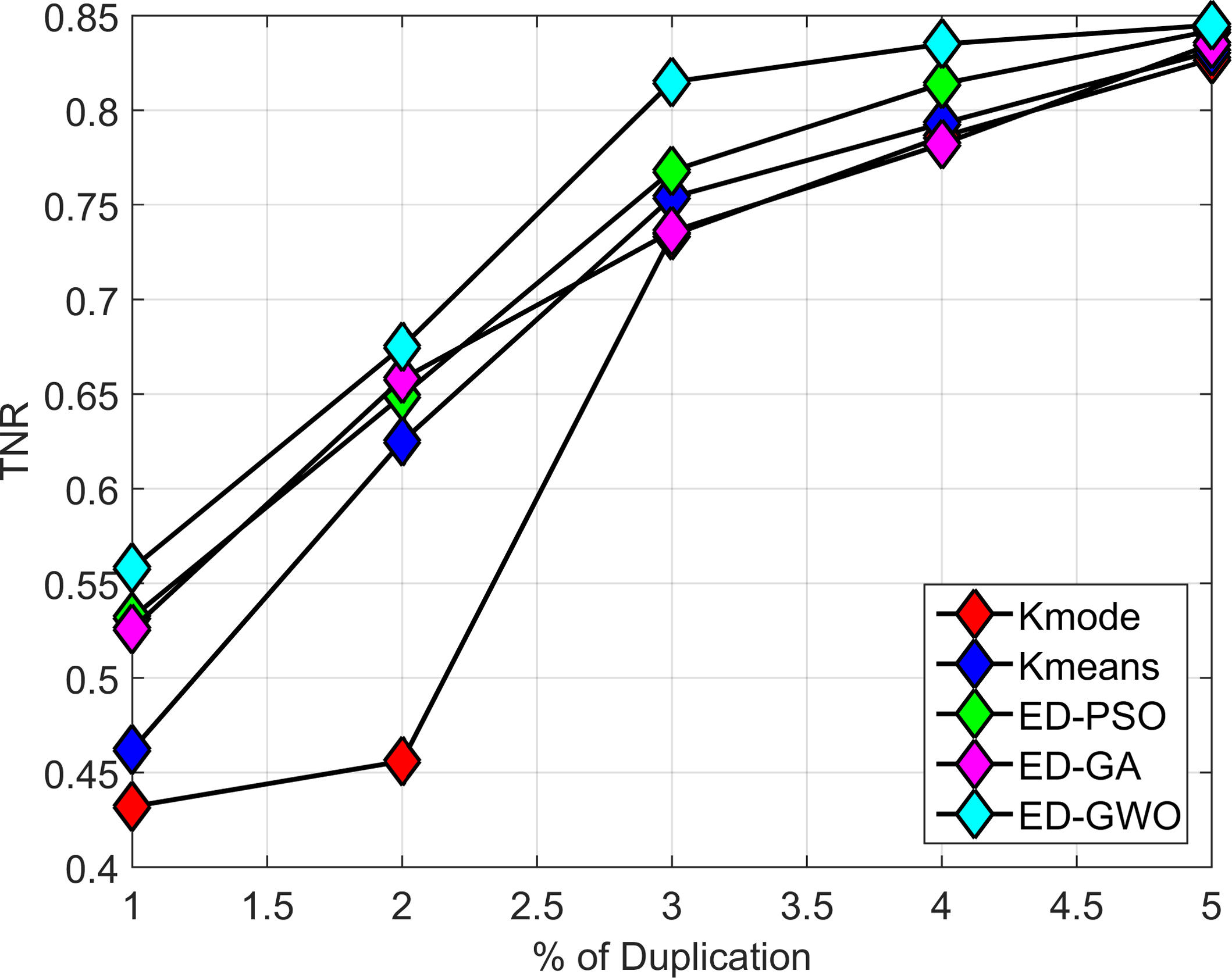
Procedure
The proposed intelligent de-duplication methodology is developed in Java and compared with traditional methods such as particle swarm optimization (PSO) and genetic algorithm (GA), which are used for clustering. Moreover, the traditional k-means [30] and k-mode [31] clustering algorithms are also used for comparative study. Henceforth, the clustering methods are called here as Euclidean distance based GWO (ED-GWO), Euclidean distance based PSO (ED-PSO) and Euclidean distance based GA (ED-GA). The benchmark database, called as 20 Newsgroups data set which can be accessed from the given link: http://qwone.com/∼jason/20Newsgroups/ is synthesized for duplication by 10%, 20%, 30%, and 40% and 50%. The comparisons on identifying and reconstructing from duplication are studied using accuracy, True Positive Rate (TPR) and True Negative Rate (TNR) against the different percentage of duplication and it is summarized in Table 1.
De-duplication
The TPR of all the methods has increased with respect to the percentage of duplication, which is shown in Fig. 8. However, the proposed method achieves a TPR value of 4.8% better than ED-GA, 0.8% better than ED-PSO, 1.3% better than k-mode and 0.2% better than k-means. Thus the proposed GWO based clustering method provides better TPR rate than other existing methods.
The TNR of all the methods increases with respect to the percentage of duplication is shown in Fig. 9. Anyhow, the proposed method achieves a TNR value of 1.8% better than ED-GA, 1.7% better than ED-PSO, 0.5% better than k-means and 3.2% better than k-mode techniques. Thus the proposed GWO based clustering method provides better TNR rate than other existing methods.
Reduction of computation time in the proposed clustering method when compared with existing methods
Reduction of computation time in the proposed clustering method when compared with existing methods
Restoration accuracy and % duplication among the existing methods and the proposed clustering method.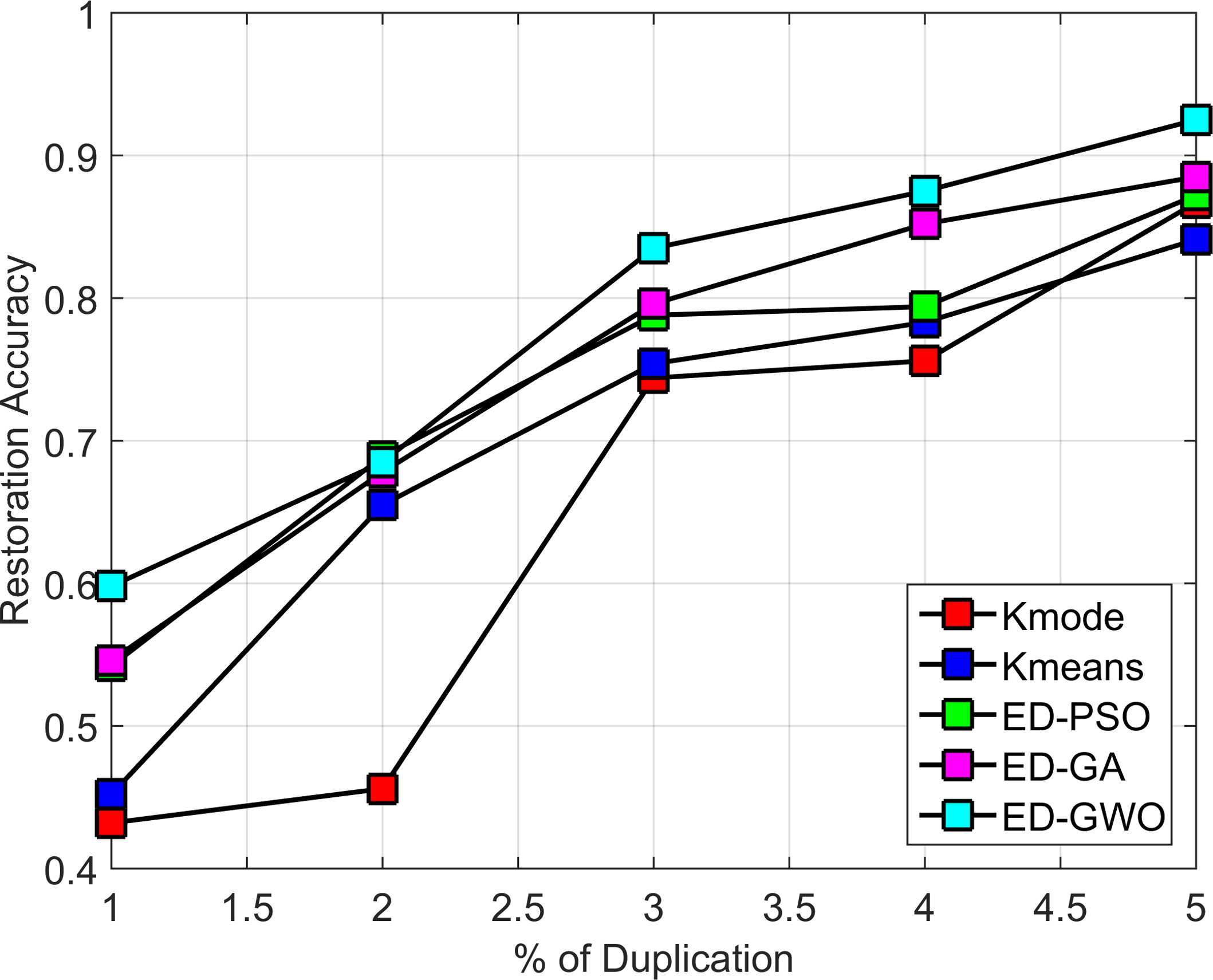
The restoration accuracy increases with increase in the percentage of duplication in all the methods, which is shown in Fig. 10. The proposed system achieves an accuracy of 1.3% better than k-mode, 0.8% better than ED-PSO and 4.8% better than ED-GA. The accuracy of k-means is slightly greater than GWO by 0.1% but in other cases the proposed method provides better accuracy of about 1.6%, 1.4% and 0.5% than k-means. Thus the proposed GWO based clustering method achieves better accuracy than other existing methods.
De-duplication vs restoration
The restoration accuracy increases with increase in compression ratio for all techniques, which is shown in Fig. 11. But the proposed clustering method achieves an accuracy of 0.8% better than ED-PSO, 4.7% better than ED-GA and 1.6% better than k-mode. The accuracy of k-means is slightly greater than ED-GWO by 0.3%, but in other cases the proposed method delivers higher accuracy of 1.3%, 1.4% and 0.6% better than k-means. Thus the proposed GWO based clustering method provides better accuracy rate than other existing methods.
Restoration accuracy and compression ratio between the existing methods and the proposed clustering method.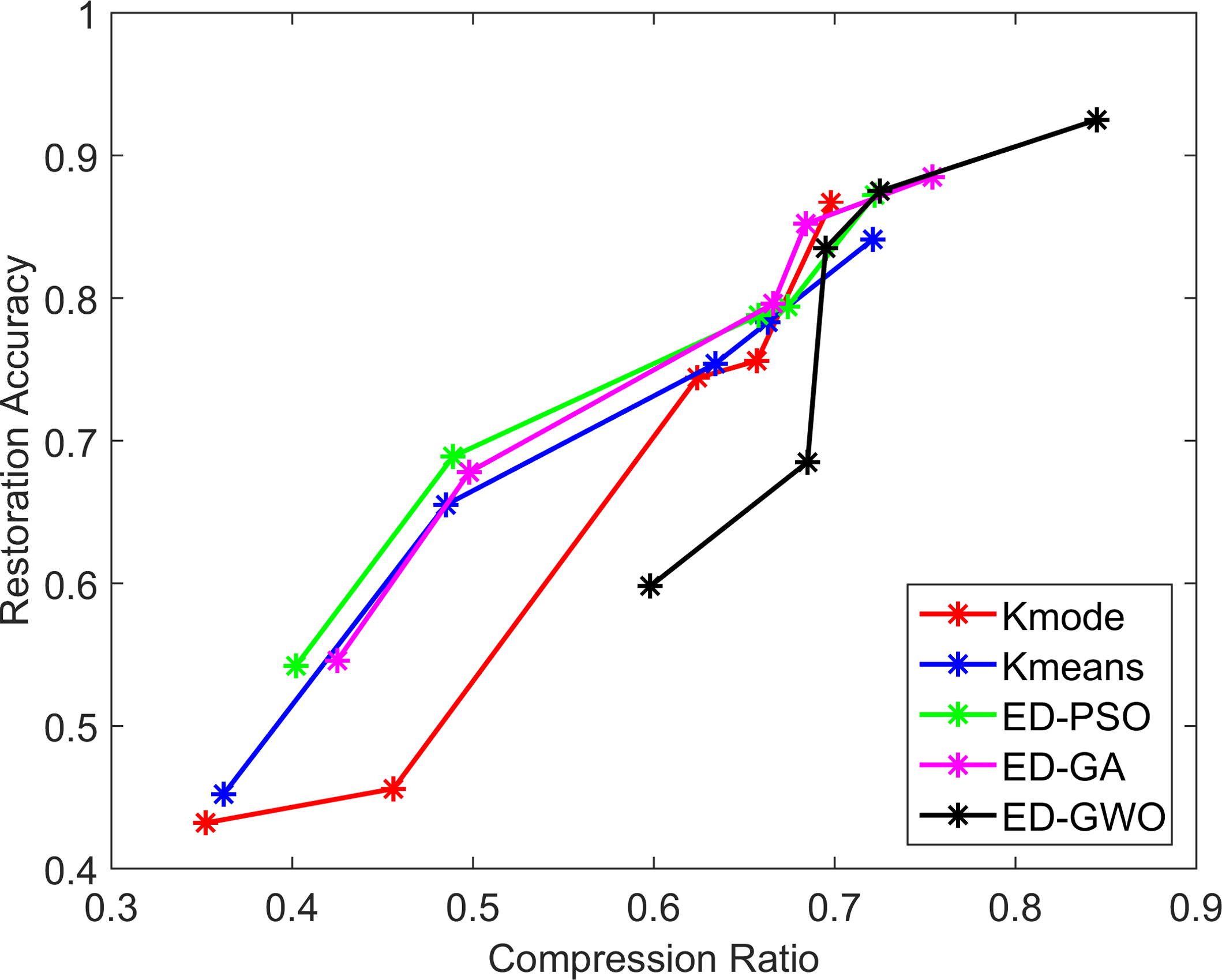
The computational time is reduced in the proposed algorithm when compared with other algorithms, which are shown in Table 2. The computational time for ED-GWO is slightly increased than k-mode and k-means by 1% and 9% respectively. As ED-GWO achieves 3.2% TNR rate higher than that of k-mode and 0.5% TNR better than k-means, the performance time of proposed method can be considered as negligible. From the obtained results, it can be concluded that the proposed system, i.e., ED-GWO system achieves better accuracy, TPR and TNR rates and less computational time for de-duplication when compared with other existing methods.
Conclusion
With the rapid growth of the data, a single-node de-duplication system cannot assure the required performance in data storage as well as data protection. Hence, cluster-based de-duplication system emerges. However, the storage node information island will outcome in the cluster de-duplication system failing to improve the performance of de-duplication throughput and scalability. In order to solve this problem, we have introduced a novel clustering method, GWO to obtain de-duplication in this paper. It overcomes the performance gaps from conventional methods such as, ED-PSO, ED-GA, k-means and k-mode. Finally the proposed ED-GWO based clustering method was compared with other existing methods such as k-means, k-mode, ED-PSO and ED-GA. From the result it was concluded that the proposed de-duplication system provides better TPR of 1.3%, TNR of 3.2%, accuracy of 4.7% based on compression ratio and accuracy of 4.8% based on a percentage of de-duplication than existing methods for enhancement on de-duplication and storage optimization. In future, a novel clustering method, second order mutual information based grey wolf optimization can be adopted in order to obtain de-duplication in an effective way.
Footnotes
Authors’ Bios