
Abstract
One of the most important issues of manufacturing systems optimization is scheduling. In fact, it plays a great role in reducing the production time and minimizing the required resources for production. Recently, due to the furious competition between companies, manufacturers are pushed to ensure products of high quality with a minimum amount of resources. In addition to that, they should satisfy the deadline of theirs customers. The Flexible Job Shop Scheduling Problem (FJSSP) is a very popular pattern in the real manufacturing systems. This problem is a generalization of the Classical Job Shop problem (JSP). FJJSP is called flexible because a machine can perform many types of operations. Each job in FJSSP has its own production sequence, composed of a set of operations. However, each machine can execute one operation at the same time. The problem is how to ensure the achievement of all jobs in the shortest time (Makespan).
A hybrid genetic algorithm (HGA) to solve FJSSP is proposed. An Improved Tabu Search (ITS) algorithm with an original neighborhood function is designed, to improve the performance of GA. The approach was tested and validated using one of the most known benchmarks. The effectiveness of the proposed approach is proved by tests.
Keywords
Introduction
One of the most difficult problems of manufacturing systems controlling is the scheduling problem [1]. In fact, an optimal schedule ensures a maximum quantity of products with low-cost in term of resources. The flexibility of resources (machines) allows managing undesirable events such as machine breakdown, but it increases dramatically the complexity of the problem, due to the second assignment sub-problem, which consists in selecting one machine of each operation.
The aim of this paper is to resolve the flexible job shop scheduling, which consist to organize the execution of many jobs by a set of machines in the shortest time. Each job is composed of a set of elementary operations. This problem can be divided into two sub problems: (a) Assign each job operation to a machine that is chosen among a set of candidate machines. (b) Find the best jobs sequence in each machine. Thus, searching the best assignment and sequencing combination among a big number of possible solutions, is considered as an optimization problem.
FJSSP problem is NP-Hard [1]. The flexibility increases greatly the complexity of the problem because it requires an additional level of decision (selection of a machine for each operation).
These are many real problems which are classified as FJSSP such us, assembling of manufacturing parts to get final products. FJSSP exists in many industrial processes, such as crane operations (simulation and optimization of transport systems), scheduling in real manufacturing systems, aircraft scheduling, etc. [2].
This paper is organized as follow: In the first section, we present a literature review about the flexible job shop scheduling problem. In the second section, the considered problem is illustrated. To simplify our approach, clarification of the proposed model for optimization is introduced, and how the Tabu search was integrated in the genetic algorithm (GA) and what is our contribution. The next two sections will cover the proposed Tabu search and GA used to reach good or optimal solutions. The last section is devoted to experiments and results.
Literature review
Due to the large application of FJJSP, especially in scheduling and control of manufacturing systems, FJJSP attracted many researchers in the last decades to provide solutions to manufacturers’ requests.
Mastrolili and Gambardella [3] proposed a new method based on the local search with two neighborhood functions. The assignment sub problem was solved by a special neighborhood function. A second neighborhood function was applied to sequencing sub problem.
A new approach based on the localization method with an evolutionary algorithm was proposed by Kacem et al. [4]. Two criteria were used to evaluate solutions: minimization of Makespan and the total machines workload. This method allows solving the assignment sub problem. Kacem used a procedure that takes into consideration the period of each operation and the workloads of machines. The second sequencing sub problem was solved by an evolutionary algorithm controlled by an assignment model using advanced genetic manipulations.
Zrib et al. [5] created an approach adapted especially for high flexibility problems. They proposed two methods for the assignment sub problem: The first one was based on the local search and the Branch & bound technique was used as a second method. The quality of assignment was evaluated by a boundary method. Then, a GA was used to solve the sequencing sub problem. However, the two sub problems are usually related for high quality of solutions.
Later, El-Kamel et al. [6] considered the FJSSP problem under machines availability constraints. These constraints are linked to a set of fixed machines breakdown periods. Two approaches were proposed: The first one begins with an assignment phase via local search, after that, a GA was used for operations sequencing. However, the second approach solved the two sub problems at the same time using an exact method, but only for two jobs.
Raich et al. [7] created a new method based on simulating annealing (SA) for FJSSP. They compared the results of SA with other methods such as SPT and LPT. The results showed that it is possible to obtain a global minimum solution but only for small instances.
Sridhar et al. [8] have considered many objectives which are the minimization of the overall completion time (Makespan), the total workload of machines and the workload of the most loaded machine. The results indicate the possibility to achieve optimal solutions. But the Makespan remain the most important criterion for FJJSP and find a solution that satisfies all objectives remain a hard task.
Ziaee [9] proposed a heuristic based on a constructive procedure to produce quickly good schedules. This constructive procedure is simple and doesn’t require a lot of execution time. However, this constructive procedure can be limited in the case of a big number of manufacturing operations.
The authors [2] proposed an algorithm using a new initialization method to improve the quality of the initial population and to accelerate the speed of the GA convergence. Authors [10] tried to improve the GA for flexible job shop scheduling with overlapping in operations. However, unknown instances were used in this study.
Several hybrid approaches were proposed for FJSSP but specifically for multi objective problems. Fatahi [11] proposed a hybrid multi objective algorithm for flexible job shop scheduling to minimize the completion time and the total tardiness. The author combined simulated annealing with Tabu search. Authors [12] combined simulated annealing with local search for multi objective flexible job shop scheduling. In another study [13], a hybrid approach was proposed, they used Ants colony with GA for preventive maintenance of machines. [14] proposed a hybrid algorithm using swarm optimization and GA.
Generally, the initial population of the GA is generated randomly which can create weak initial population and decrease the global performance of GA. To face this issue, a strong heuristic based on the concept of the active schedule (schedule without delay) is proposed, to generate the initial population. As a result, the high quality of the initial population solutions will contribute to accelerate the speed the GA convergence to an optimal solution.
According to the precedent works, the combination of the GA with the Tabu search stills limited in this field. The GA is a strong search method but, reinforces it with an efficient metaheuristic such as Tabu search, represents an excellent hybrid method to find solutions of high quality. In addition, contrary of the precedent works, an improved Tabu search based on new two concurrent algorithms is presented, which work as neighborhood function. The FJJSP has two main issues:
Assignment sub problem: A machine chosen among a set of candidate machines for each manufacturing operation. Sequencing sub problem: Prepare an execution order to perform the manufacturing operations on each machine. According to the literature, there are two main approaches of FJSSP:
The hierarchical approach: Both of sub problems are resolved separately. The integrated approach: In this approach, the two sub problems are resolved at the same time. Due to the speed and efficiency of the integrated approach, an integrated hybrid GA is adopted in this paper.
Chromosome coding
Example of flexible job shop problem
Problem formulation
In this section, a mathematical model of FJSSP with the constraints for feasible schedules is presented. In FJSSP, the aim is to organize the execution of N jobs
where for each operation
The resolution of FJSSP is very hard due to its high complexity. In the following part, an explanation of the designed optimization approach is presented.
In this part, answers to three main questions are given: why we have combined the GA with the Tabu search; how this combination was made; and what is our contribution.
Genetic algorithm with improved Tabu search for flexible job shop scheduling.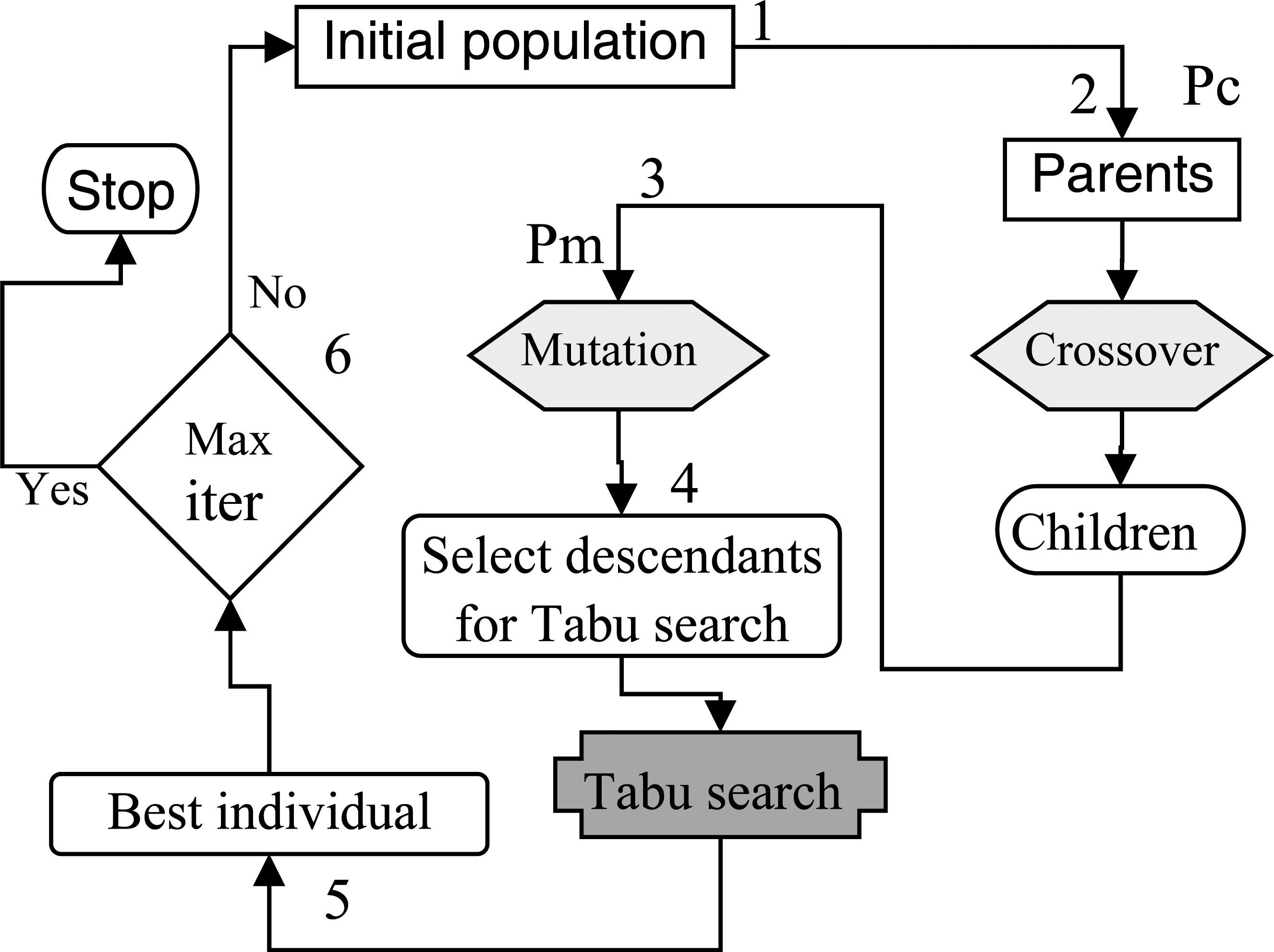
The force of the GA is its capacity to explore the space of feasible solutions in a global way. However, sometimes, an optimal solution can hide behind any feasible solution (a neighbor solution). In this situation, the GA becomes inefficient to achieve these neighbor solutions, which can be better than the precedent solutions or even, the best one. To face this problem, the Tabu search is perfectly adapted to explore these neighbors. Figure 1 illustrates how the Tabu search reinforces the GA. The aim of the Tabu search is to explore deeply the neighbors of each generated chromosome (child) from the genetic operators. As a result, each selected solution will be replaced by its best neighbor.
Parents are selected by taking randomly, a rate of individuals
The Tabu search (TS) is a metaheuristic based on the local search [15]. It explores the feasible solutions to get the optimal ones. Starting from an initial solution, the best neighbour is selected at each iteration. The neighborhood process is made by one transition on the current solution using special neighborhood functions. Thus, these solutions are called neighbours of the current solution [16]. Tabu search uses memorization structure in which, it saves the last visited solutions (Tabu list). A solution is forbidden for a certain number of iterations, which equals to the size of the Tabu list. Then, the best neighbour non-Tabu will be selected for the next iteration (Fig. 1). Tabu search is an efficient method for many difficult problems, but it remains difficult to be adapted to FJSSP. In fact, it requires the definition of several parameters such as the initial solution, neighborhood functions, evaluation of solutions, the size of Tabu search, etc.
The neighborhood functions
For the FJSSP, the traditional neighborhood functions are related to the notion of critical path.
The traditional neighborhood functions are made by making a simple transition on critical operations. These transitions can be a permutation between two critical operations or a mutation of a critical operation to another machine. However, these transitions can’t guarantee an improvement of the initial solution and all the possible transition have to be explored before finding a possible improvement.
In this context, an original neighborhood function designed to find derived solutions of better quality is presented in this paper. Instead of making random transitions which could be obsolete and take a lot of time, our approach is based on a deep analyze of the initial solution in order to take decisions which allow an improvement for each critical operation. The proposed neighborhood function is based on two concurrent algorithms using probabilities of improvement. The first one is for optimization by free windows and the second for optimization by occupied windows. Both of them allow assignment and sequencing improvement. Both of the two algorithms will be illustrated in the next part.
A probability is proposed for each algorithm, to measure the degree of improvement by each one for each critical operation
Probability of optimization A for free windows (Algorithm 2)
Probability of optimization B for occupied window (Algorithm 3)
where
S: The initial schedule or solution to be optimized.
Definition of free window for
Definition of occupied window for
The first formula in Eq. (3.3.1) controls the constraints of
This algorithm can improve assignment and sequencing of a critical operation by detecting the best adequate free window, without breaking the resource and the precedence constraints and without delaying others operations. The free windows are detected from all the candidate machines of the current critical operation. After, a test is released to check if the current improvement (assignment or sequencing) is the best one among the precedent improvements. At the end of the algorithm, the updating procedure is executed, to update the starting and the finishing time of specific operations.
Algorithm of optimization B for occupied windows
This algorithm starts by exploring all the adequate occupied windows for the current critical operation
The idea is to exchange the position of
Before starting the algorithm, all the detected occupied windows are adapted to the current critical operation
The two precedent algorithms work as neighborhood function for Tabu search. In order to increase the efficiency of Tabu search, three criteria are chosen (Eqs (1), (7) and (8)) to select the individuals which will be subjected to the Tabu search according to the fitness Eq. (9). These individuals are more adapted to the neighborhood function than the others.
Both Algorithms 2 and 3 use the updating procedure after the optimization of the current critical operation. The pseudo algorithm of updating is given in part:
The schedule updating changes only the starting and the finishing times of the operations which are affected by either Algorithm 2 or Algorithm 3.
In the next point, the three criteria used for selecting individuals for Tabu search application are presented, and a pseudo algorithm of the Tabu search is given.
The makespan: this criterion represents the completion time of all jobs. It reflects the quality of the schedule (Eq. (1)).
The average quantity of free windows: the average unexploited time reinforces the efficiency of Algorithm 2. Where
The workload distribution between machines: a schedule more equilibrated makes easy the application of optimization by occupied windows (Algorithm 3).
where
According to these three criteria, the individuals will be selected for Tabu search using the following equation:
The purpose of this equation is to choose solutions, which have the maximum average of free time, and the minimum value of makespan and the most balanced workload distribution between machines.
The following pseudo-algorithm summarizes how the ITS (Improved Tabu Search) was implemented:
Genetic algorithm
The Tabu search illustrated in the precedent section will be used to improve the solutions of the GA which are created by the genetic operators. This Improved Tabu Search has a double goal; first, it works to discover new solutions in the neighborhood space. Second, it contributes to accelerating the speed of the GA by reducing the number the generations required to achieve a solution of high quality.
GA is one of the best metaheuristics to deal with flexible job shop scheduling problem [17]. This algorithm uses crossover as a genetic operator for recombination of parental genes to form new descendants. The second genetic operator ‘Mutation’ changes randomly the values of certain genes, in order to avoid premature convergence of GA. But, due to the combinatory nature of the present problem, it stills difficult to ensure optimal or quasi-optimal solutions via this algorithm. Thus, a combination of the Tabu search approach with the GA is suggested to get stronger solutions (Fig. 1). GA is an algorithm that tries to improve the best solution found from generation to generation. However, the first generation is important, because the future populations depend on it.
A good initial population must be composed of individuals (solutions) of different nature and good quality. The following subsection illustrates how the initial population is created to ensure both of individuals’ diversity and quality.
The initial population
The generation of the initial population is prepared as follows:
Fifty percent of individuals are created randomly in order to ensure the diversity of this population, which is useful to avoid a premature convergence. The rest of individuals are made by a strong heuristics such as SPT (shortest processing time), MWR (most work remaining), etc.
In the following part, an efficient heuristic is proposed, able to find the best free window of time for each operation. This heuristic provides active schedules in which, it is impossible to advance any operation without delaying other one [18]. This schedule reflects a solution of high quality.
Equation (11) provides the best free window for
To exploit the GA, each solution (schedule) must be coded using a specific representation to obtain a chromosome, this representation will be used later by the genetic operators such as crossover and mutation to discover new solutions.
This representation is linear and reflects the chronology of scheduled operations.
Respecting the precedence constraints on each job is necessary. However, avoid a correction process on the generated solutions, which increases dramatically the completion time, will be more interesting. This is why the crossover operator developed by [19] is adopted, which respects the problem’s constraints. In the second genetic operator, mutation is applied by choosing randomly a chromosome and a machine, which will be subjected to this perturbation (modifies some chromosome genes). Next, two operations are chosen randomly, on which, the mutation will be applied.
Crossover
This operator exchanges information from the chosen parents in order to obtain better descendants. Crossover is applied to each pair of chromosomes (parents) to get two new individuals (children). An improved Precedence Preserving Order-based crossover (POX) is adopted in this study [19].
GA vs HGA (TS 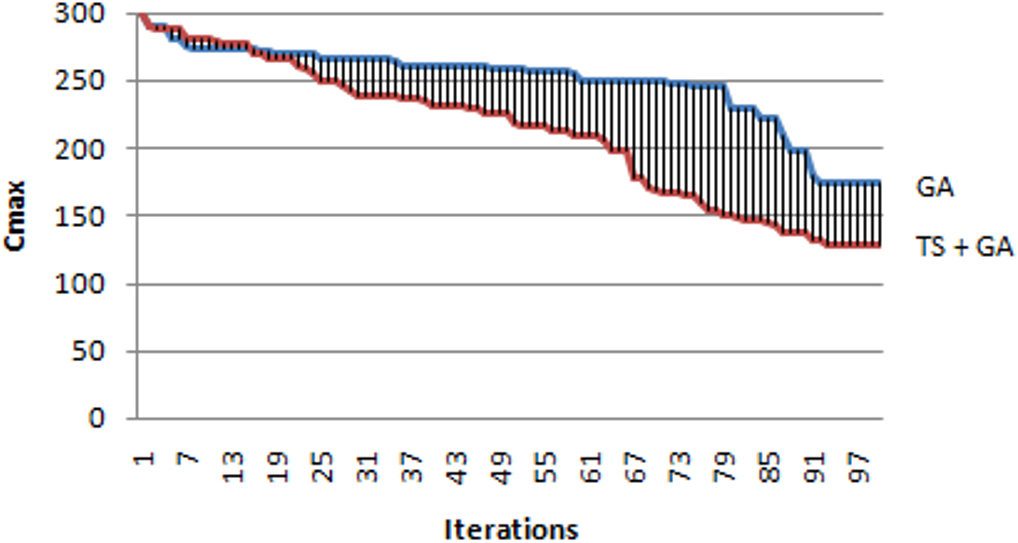
In this study, we apply assignment mutation and sequencing mutation:
In the assignment mutation, two different indexes L1 and L2 are chosen from the interval
In the sequencing mutation, two different operations are chosen randomly (from different jobs) then, these two operations will be permuted.
Parameters of the genetic algorithm
The performance of the GA depends strongly on a set of parameters. After many tests, these parameters are configured as follows:
The fitness function reflects the quality of each solution. It is calculated using the following equation:
The probability of crossover
The population’s size is a parameter which depends on the size of instances. In our case, the initial population contains 100 chromosomes, but this number increases when the size of the instance became more important.
In our case, the best individuals according to their fitness (Elitism) are selected for the next generation. The GA is iterated until the maximum number of iterations is reached.
In order to evaluate the quality of our approach, one of the well-known benchmarks of the flexible job shop scheduling problem is used. Many tests are performed in term of quality and performance. The proposed approach was implemented using java as a programming language and eclipse as an IDE.
Figure 2 illustrates the role of the Improved Tabu Search on the performance of the GA. This figure shows that the best solution found by the hybrid GA is better than the simple GA. The most critical step of the GA is the generation of the initial population. In fact, a good initial population must provide both of diversity and quality of individuals.
According to Fig. 2, the improvement of the makespan by the proposed HGA is clearly better than the one obtained by the traditional GA.
In Table 3, a comparison is presented between the proposed heuristic (last column) and many other methods used to generate the initial population, the values represent the makespan of the best solution found among 100 generated individuals.
J
Heuristics for the initial population
Heuristics for the initial population
Results using Brandimart’s instances
According to the results mentioned in Table 3, the proposed heuristic based on the concept of active schedule provides the best solutions.
The second best heuristic is SPT (shortest processing time). However, the SPT heuristic is improved by taking into consideration the workload of machines.
The MWR (most work remaining) is less efficient than the two last heuristics. It gives priority to the operation belonging to the job that has the most remaining time.
The solutions generated randomly are not as good as the precedent heuristics solutions but, this method is crucial to maintain the diversity of the initial population. Its advantage is to avoid a premature convergence of the GA.
Table 4 represents a comparison between the proposed approach (HGA: Hybrid GA) and other approaches. The values reflect the best makespan found by each approach using the same instances of Brandimarte. Improved values found by our approach are written in bold style.
Obtained results of Cmax (seconds)
*Optimal solution. **The best found solution.
Gantt diagram for the product order 1XAIP by IGA.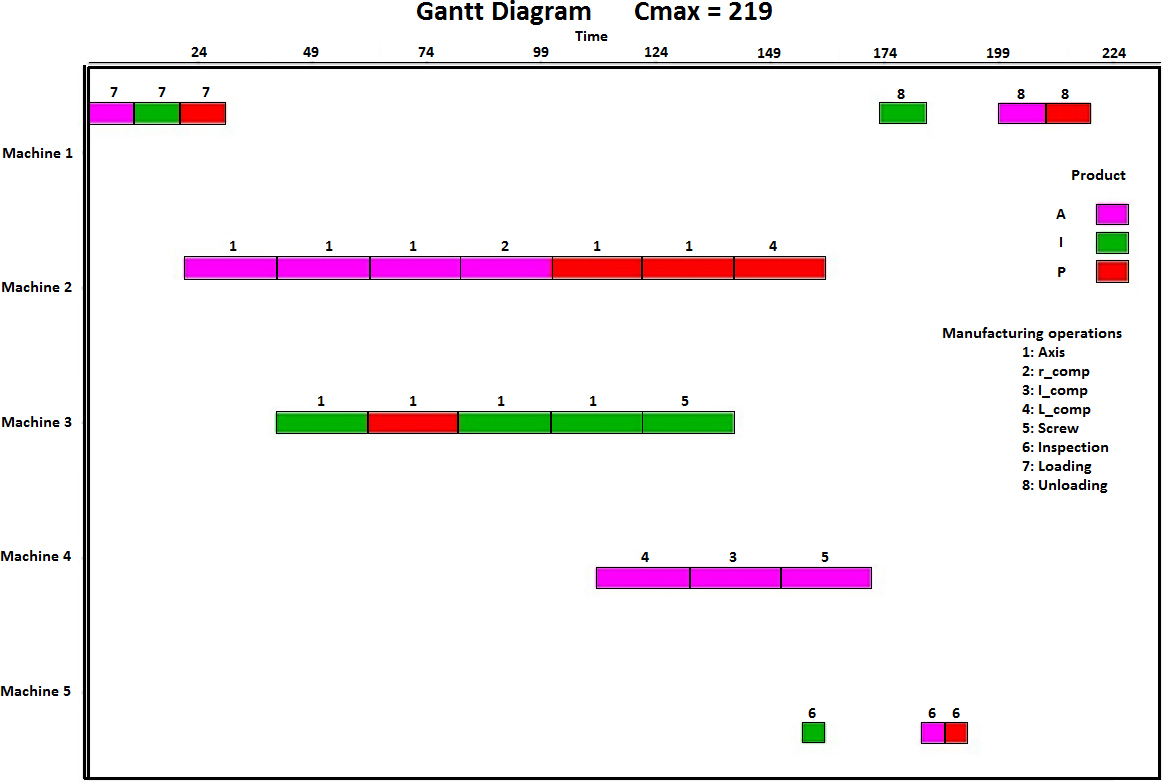
Table 4 shows that 60% of the results obtained by our approach (less than 5 minutes) are better than the other approaches results, such as Po&JA, Gi and Ho&TA [19, 20]. The results of the remained instances (40%) are as good as the other approaches.
The obtained results can be explained by the proposed approach for the generation the initial population and the improved proposed neighborhood function used in the Tabu search to get solution of better quality.
We have tested our approach IGA (Improved GA) on another special benchmark which reflects a real manufacturing cell, developed by the University of Valenciennes in France [15]. This benchmark takes into consideration the transportation time between machines. We have compared our approach with five approaches which are MLIP: the Mixed-Integer Linear Program [15], PF: Potential Field [21], IGT: the Iterative Greedy Insertion Technique [22], GA: and ORCA-FMS [23]. The obtained results are presented in Table 5.
There exist many schedules representation forms. However, the most used one is the Gantt diagram. Figure 3 shows the best solution found by IGA method for the product order 1XAIP.
In this paper, the Genetic algorithm (GA) is adopted for flexible job shop scheduling problem. However, the GA is considered as a global search method and it can’t explore deeply the neighborhood solutions, which can be better than the initial one. To solve this problem, the Tabu search is incorporated, which can cover perfectly the weakness of the GA and improve the global performance of the proposed approach.
The proposed Neighborhood function is original and more efficient than the traditional ones, which are based on random transitions. The proposed neighborhood function is based on tow concurrent algorithms which exploit deeply the information about the schedule to be optimized. A probability is proposed to measure the degree of optimization of either algorithm of optimization A for free windows or optimization B for occupied windows 2 or 3. According to the highest probability, one of the two algorithms will be applied to optimize each critical operation.
The proposed heuristic based on the concept of the active schedule, creates solutions of good quality. This heuristic allows enhancing the quality of the GA’s initial population. This heuristic accelerates the speed of GA’s convergence.
Actually, the two algorithms, of optimization A, B for free windows and occupied windows, are being adapted for an uncertain environment such as energy volatility.
Footnotes
Authors’ Bios