
Abstract
The load and data management in Grid computing infrastructure is complex. A grid computing application is divided into several sets of tasks between which there are precedence relations. Such relationship poses a challenge for the tasks assignment witch have to minimize the average response time of applications and reduce the communication cost. This problem becomes much more complex when the tasks manipulate replicated data because we have to manage their consistency. In this paper, we propose a tasks assignment and data consistency management strategy based on Tasks and Data Replication. Our main goals are: (a) reducing, the average response time of tasks submitted to the System, (b) respecting the constraints of dependency between tasks, (c) managing data consistency, and, (d) reducing communication costs.
Keywords
Introduction
Grid computing has emerged as an essential technology that enables the effective exploitation of diverse distributed computing resources to deal with large-scale and resource-intensive applications, particularly in science and engineering. A grid typically consists of a large number of heterogeneous resources spanning across multiple administrative domains. The effective coordination of these heterogeneous resources plays a vital key role in achieving performance objectives. Grids can be broadly classified into two main categories (computational and data) based on their application focus. In recent years, the distinction between these two classes of grids is much blurred due to the ever increasing data processing demand in many scientific, engineering and business applications, such as drug discovery, economic forecasting, seismic analysis, back-office data processing in support of ecommerce, Web services, etc. [8].
The scheduling [12] has become one of the major research objectives, since it directly influences the performance of grid applications. Task assignment is the main step of grid resource management. It manages jobs to allocate appropriate resources by using scheduling algorithms and polices [16].
Dynamic tasks assignment assumes a continuous stochastic stream of incoming tasks. Very little parameters are known in advance for dynamic tasks assignment. Obviously, it is more complex than static tasks assignment for implementation, but achieves better throughput. Also it is the most desired because of the application demand [15].
Tasks includes independent and dependent tasks. Generally, applications could be decomposed into some dependent tasks and be described as Directed Acyclic Graphs (DAGs) in order to take advantage of the parallelism and cooperation capability of the distributed system. However parallelization is limited due to the communication latency and the iteration-dependent requirements. Thus there should be a tradeoff between maximal parallelization and minimal communication cost. Assigning dependent tasks under distributed environments is a strong NP-complete problem. It is very difficult to solve the problem by approximate algorithms because there is too many factors need to be considered [14].
In traditional intensive computing, tasks may require access to large numbers of files and high data volume witch are replicated among nodes. When mapping tasks to compute nodes, scheduling mechanisms need to take into account not only their computation times, but the staging of files should also be carefully coordinated to minimize the communications costs [7].
A task submitted to the grid can access a replica either in reading or writing. In the writing case, the operation causes an inconsistency of replicas and the system must handle this problem.
Maintaining data consistency is one of the most important tasks when designing and managing data. In a centralized system this task is more or less easily accomplished because the data is in a specific location, and updates are made locally without competition, which facilitates data management. On large scale environment such as grid computing, the management of consistency becomes more difficult, because the data is distributed over geographically distant clusters, the data is fragmented on these clusters, in addition some of them can be replicated on several clusters.
In this paper, we consider the task assignment problem with the following characteristics: (a) Tasks are modelled using a directed acyclic graph (DAG); (b) We propose a assignment strategy of dependent and independent tasks in Grids; (c) The strategy takes into account the clusters capacity and data locations. Our Strategy is able to replicate data and tasks if necessary and try to meet the following objectives: (1) reducing, whenever possible, the average response time of tasks submitted to the grid, (2) respecting the constraints of dependency between tasks, (3) Managing data consistency, and, (4) reducing communication costs.
The rest of this paper is organized as follows. A Literature review is illustrated in Section 2. The Grid computing environment is explained in Section 3. Section 4 describes the main phases of the associated strategy. We evaluate the performance of our scheme in Section 5. Section 6 gives some discussions. Finally, Section 7 concludes the paper and gives some perspectives.
Literature review
Tasks assignment and data replication
Our work is related to two distinct areas: tasks scheduling and data consistency in Grid computing systems. In this section we discuss related works in these areas (see Fig. 1).
Taxonomy of related works.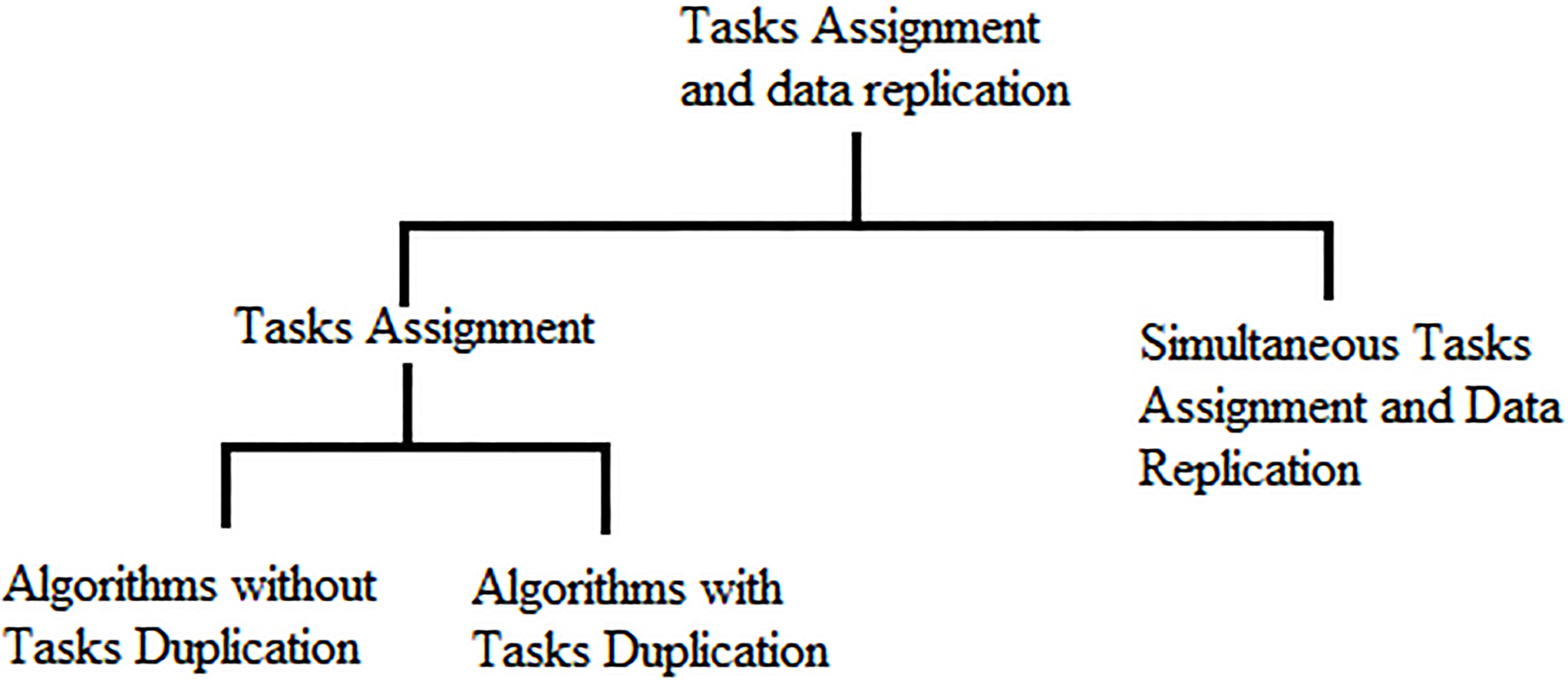
There have been many heuristic algorithms proposed with and without duplicating tasks. Task duplication is related to tasks dependencies; By duplicating some communicating tasks on a single processor, the interprocessor communication cost can be minimized. Tasks duplication can be also used to achieve reliability and fault tolerance [18].
In [16], Naglaa et al. propose a Sort-Mid tasks scheduling algorithm in grid computing. The proposed algorithm depends on the minimum completion time and the average value of completion times for each task. It puts constrains to map the most appropriate task to the best convenient resource, which increases the grid efficiency. Performance tests show a good improvement over existing popular scheduling algorithms such as Min-Min [10, 1], Max-min [10, 1], Suffrage [10], MET [6], MCT [6], OLB [11].
In [15], authors considered the task assignment problem with the following characteristics. (a) The tasks are modelled using a DAG. (b) Proposed a assignment strategy considers dependent and independent tasks in Grids, which has the advantage of being able to divide the input task graph into set of connected component to reduce the response time of system application.
Comparing with the HEFT [19] algorithm, the first experimental results are encouraging since we can significantly reduce the average response time and the average waiting time.
Tasks scheduling with tasks duplication
In [20], Zong et al. proposed two energy-aware duplication scheduling algorithms, to schedule precedence-constrained parallel tasks. Proposed algorithms judiciously replicate predecessors only if the duplication can help in conserving energy.
The energy-aware scheduling strategies are conducive to balancing the scheduling length and energy consumption of precedence-constrained parallel tasks.
First, the authors build an energy consumption model used to estimate power dissipation in CPUs and network links. Second, they proposed two duplication-based scheduling algorithms, called EADUS and TEBUS, to provide energy savings in network links by duplicating tasks on more than one computational node to reduce network traffic.
In [18], Singh and Auluck propose a controlled duplication algorithms for scheduling real-time periodic tasks with end-to-end deadlines on heterogeneous multiprocessors. The authors observe that although using duplication can help a task graph instance to meet its deadline, it may cause the other tasks to miss their deadlines because of the unavailability of the appropriate schedule holes. Hence, an interesting tradeoff exists between the number of duplicated jobs and the number of schedule holes available. Simulations have shown that the proposed algorithms improve the success ratio by 15% to 50%. Other known non-duplication and duplication based algorithms, even under higher processor utilizations and communication costs.
In [17], the authors propose a scheduling approach that does not use any king of information needed by the scheduler. This approach uses task replication to cope with the dynamic and heterogeneous nature of grids without depending on any information about machines or tasks. When a task is replicated, the first replicas that finishes is considered as the valid execution of the task and the other replicas are cancelled. Results show that this approach delivers good performance.
Although these algorithms deal with tasks assignment problem and give good results, they do not take into account the problem of replicas consistency.
Simultaneous tasks assignment and data replication
Relatively little research has so far addressed the assignment of task execution and data consistency.
In [9], the authors first propose a job scheduling and data replication algorithm, which not only has theoretically provable performance but also dramatically reduces the time complexity compared to that of the optimal algorithm. Authors then design a series of polynomial heuristic algorithms.
This work is very interesting, it refer to the problem as Integrated Scheduling and Replication Problem which is NP-hard. However, the authors consider that all the tasks submitted to the grid are independent. Tasks dependencies make the problem much more difficult.
In [4], Djebbar et al. propose an optimization approach that takes into account an effective data placement and scheduling of tasks grouped based on data replication in scientific Cloud environments. This proposed approach improve data placement and minimize response time due to scheduling tasks to data centers that contain the majority of the required data.
The proposed approaches, as well as the strategy used, were able to improve data placement and minimize response time due to scheduling tasks to data centers that contain the majority of the required data.
This work addresses the problem of scheduling dependent tasks and replicating data but does not consider the data consistency problem which is important in grids.
Tasks assignment
Tasks assignment is very important in a distributed environment. In distributed systems, every node has different processing speed and system resources, so in order to enhance the utilization of each node and shorten the consumption of time, tasks assignment will play a critical role. On the other hand, in distributed systems, the policies and methods for keeping a tasks assignment will directly affect the performance of the system. In addition, the tasks assignment policies for distributed systems can be generally categorized into static tasks assignment policies and dynamic tasks assignment policies [15].
Static tasks assignment
Static tasks assignment policies use some simple system information, such as the various information related to average operation, operation cycle, etc., and according to these data, tasks are distributed through mathematical formulas or other adjustment methods, so that every node in the distributed system can process the assigned tasks until completed. The merit of this method is that system information is not required to be collected at all times, and through a simple process, the system can run with simple analysis. However, some of the nodes have low utilization rates. Due to the fact that it does not dynamically adjust with the system information, there is a certain degree of burden on system performance [15].
Dynamic tasks assignment
Dynamic tasks assignment policies refer to the current state of the system or the most recent state at the system time, to decide how to assign tasks to each node in a distributed system. If any node in the system is over-loaded, the over-loading task will be transferred to other nodes and processed, in order to achieve the goal of a dynamic assignment. However, the migration of tasks will incur extra overhead to the system. It is because the system has to reserve some resources for collecting and maintaining the information of system states.
If this overhead can be controlled and limited to a certain acceptable range, in most conditions, dynamic tasks assignment policies outperform the static tasks assignment policies [15].
Consistency management
The Consistency is a relation which defines the degree of similarity between copies of a distributed entity. In the ideal case, this relation characterizes copies which have identical behaviors. In the real cases, where the copies evolve in a different way, consistency defines the limits of divergence authorized between these copies.
Consistency is ensured by synchronization between the copies (replicas). To reach the copies, a protocol of management of consistency is necessary, which ensures the mutual consistency between the copies according to a behavior defined by a consistency model.
The consistency protocol gives an ideal view as if there is only one user and only one copy of the data in the system. The pessimistic approach and the optimistic approach are two strategies of maintenance of consistency. They represent the two edges of the dilemma coherence availability [2].
Pessimistic approach
It is a traditional strategy of management of consistency. In this strategy, the users do not observe any contradiction between the copies of the same shared data. In terms of consistency, it appears for the users like if there is only one copy. Conceptually, an update in a copy is propagated to all the other copies in a synchronous way, and no copy is accessible before it will be up to date (for this reason it is called pessimistic). When nodes or networks break down, the access to the data is refused to prevent the users from taking contradictory data.
For example, in the case of partition of the network, this means that the access to the data can be refused until the handing-over of the partition. Divergences between copies are not allowed and the consistency is strong.
The pessimistic approach has many disadvantages. Most significant are [2] the Need for a process of synchronization between copies is too expensive for the environments on a large scale and not realizable in the environments with partitions, response time is very height and the scalability is limited, the degree of availability decreases as the number of replicas of the system increases.
Optimistic approach
The optimistic strategy allows users to reach any copy for the reading or the writing operations, even when there are breakdowns of network or when some copies are unavailable. Optimistic strategy present several advantages compared to pessimistic coherence, among them, we have [2]: (a) Accesses to the data are never blocked, (b) The networks do not need to be entirely connected so that they will be entirely accessible, and (c) A great number of elements can be supported by the grid because the synchronous communication is not necessary to accept updates. It is applied in a large scale environments.
In spite of these advantages, optimistic consistency suffers from [2]: (i) The states of copies can be temporarily mutually contradictory, (ii) An update can be applied to one copy without being synchronically applied to other copies, and there will can be even a substantial time since the application of an update in a copy until the propagation of the update to other copies, and (iii) The concurrent updates with the various copies can present conflicts, for example, in a distributed system of air line reservation which uses the optimistic strategy of consistency, two copies can accept a reservation for the same seat.
Grid computing environment
Grids are large-scale distributed systems that contains.
Grid model
We model a grid computing as a collection of clusters constituted of worker nodes (storage and computing elements) and belongs to a local domain. Figure 2 describes this topology [14].
Representation model of grid.
Stage 0: The Resource Broker is connected to all Cluster Managers (CM) and receives dependent and independent tasks from the grid users. The Resource Broker Divides the waiting tasks into some dependent set of tasks, Duplicates some tasks if there is no cluster capable to receive a set of dependent tasks, and Sends tasks among cluster managers. Stage 1: The cluster manager is selected from the worker nodes of the cluster. The manager Receives set of dependent tasks from the resource broker and assign them to worker nodes of the same cluster, Replicates some files when necessary, Maintains files consistency by using a pessimistic approach inside the cluster, and an optimistic approach between clusters. Also, the manager Receives the workload information related to each one of its worker nodes, Estimates the workload of the cluster and diffuses it to other cluster managers, Decides to start a local dynamic assignment, Initiates a global dynamic assignment. Stage 2: The worker nodes are linked to their respective clusters. Worker Nodes are heterogenous and each one is composed of a computing element and a storage element. Computing elements are characterized by their processing speed, and storage elements that host distributed datafiles.
To each worker node in the grid, we assign a task queue capacity. That is to say that at a given moment we can not place all tasks of a set of dependent tasks on the same Worker Node. so we need to put the part of the set of dependent tasks that is not yet assigned on another Worker Node (preferably that belongs to the same cluster).
The worker nodes Calculates its workload information and send it to the manager, Executes the assignment decisions of the cluster manager, Sends files updates after a writing request to the cluster manager and Executes the files updates decisions received from the cluster manager.
Generate applications with specific characteristics. Each user is only connected to one scheduler to submit his/her jobs. Although, users can generate their own data files or use the existing data files in the grid.
Data files
Data files are characterized by their sizes. This characteristic is used by the cluster managers to replicate them on different storage elements.
Tasks
An application can be represented by a directed acyclic graph (DAG)
A node in the DAG represents a task which in turn is a set of instructions which must be executed sequentially without preemption in the same processor. The edges in the DAG, each of which is denoted by (
A node with no parent is called an entry node and a node with no child is called an exit node [13].
Each task arrive with specific characteristics, such as: Task dependencies, Required files, Type of task (read or write)
A graph
Dependent tasks assignment and data consistency management strategy
In order to (1) reduce the global response time of tasks, (2) respect the tasks dependencies, and (3) guarantee data consistency, this study proposed a tasks assignment and consistency management policy.
Our strategy consists of four phases ; two phases for tasks assignment (Static and Dynamic) and two phases for data consistency management (Pessimistic and optimistic).
Figures 3 and 4 show the interaction process between this phases.
Phases executed by a cluster manager.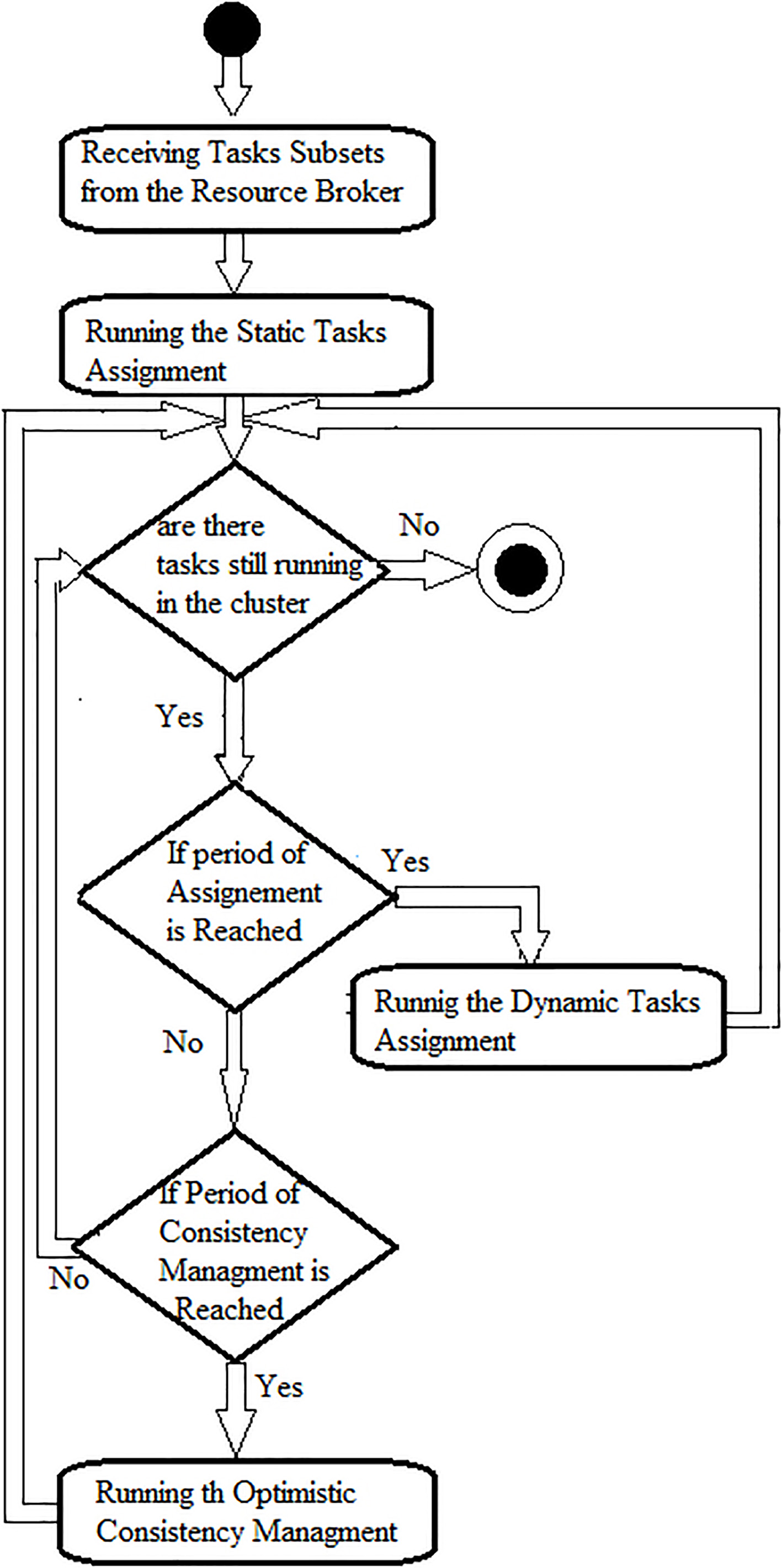
Phases executed by a worker node.
The resource broker will assign tasks to cluster managers which will assign them to the different worker nodes containing in the cluster.
The resource broker (resp. cluster manager) will performs the following: (a) Receives the state of each cluster manager (resp. worker node), (b) Partition the tasks graph of all tasks waiting in the queue to sets of dependent tasks (This is performed by the resource broker only), and (c) Sends each set of dependent tasks
Selects a set of dependent tasks Calculates the average execution time of each cluster manager (resp. worker node),
where Sends the set of dependent tasks to the cluster manager which has the lowest execution time. The cluster manager send the set of dependent tasks to the worker node that maximizes the following function:
where disp_files: file available on the worker node and N_files: number of files required by the set of dependent tasks. The cluster manager duplicate the missing files required by the set of dependent tasks on the worker node.
If the capacity of the cluster manager (resp. worker node) is less than the size of the set of dependent tasks, the resource broker (resp. cluster manager) try with the next cluster manager (resp. worker node). if there is not a possibility to assign all the set of dependent tasks, the resource broker (resp. cluster manager) must decompose if possible the set of dependent tasks to obtain different sub-sets with a smaller size. Repeat the previous instructions until the assignment of all sets of dependent tasks.
The graph partitioning (resp. set of dependent tasks) is done by duplicating some tasks using the following: (a) Browse the graph from the root to find a node
Each subtree successor of this node The subtree predecessor of this node
The result would be a sub-sets of dependent tasks.
The static tasks assignment algorithm is formalized as follows.
[h] Static tasks assignment[1] Waiting for tasksEvery cluster manager
Local dynamic assignment
Periodically, each cluster manager tries to balance its workload locally.
We don’t take the communication costs into account because its is constant (the cluster is interconnected by a LAN network).
The cluster manager:
Receives periodically the execution time of each worker node. Sorts the worker nodes table in descending order relative to their execution time.
Transfer some sets of dependent tasks from the overloaded worker nodes to the under loaded worker nodes and so on. The sets of dependent tasks are transferred only if all needed files are available on the receiver worker node.
The local dynamic assignment algorithm associated to cluster C is formalized as follows (where CNN is the worker nodes number in the cluster C):
[htp] Local dynamic tasks assignment[1] each time period Receive execution time of all worker nodesSorts worker nodes in descending order relative to their execution time.
Each cluster manager computes and sends workload information to the other cluster managers of the grid.
The execution time of cluster is computed as follow:
The overloaded cluster manager transfers some sets of dependent tasks to an under loaded cluster.
Here we should consider the communication cost among clusters. Knowing the global state of each cluster, a sets of dependent tasks can be transferred only if
all needed files are available on the receiver cluster. the sum of its latency in the source cluster and cost transfer is lower than its latency on the receiver cluster. This assumption will avoid making useless task migration.
The global dynamic assignment algorithm associated to cluster C is formalized as follows:
[htp] Global dynamic tasks assignment[1]
each time period Receive execution time of all Cluster managersSorts Cluster managers in descending order relative to their execution time.Select an under loaded cluster
Pessimistic consistency management
The cluster manager try to ensure consistency in a continuous way between the various replicas of the same data inside a cluster (at stage 2 of the model), which corresponds to make converge the replicas towards a relative replica for a cluster and it is founded on the Pessimistic approach.
To each replicas we associate a version number. This number is incremented when the replicas is updated by a writing tasks.
After the execution of a writing task type, the worker node sends the updates to the cluster manager with the number of version.
The cluster manager propagate the updates by sending the version number to all worker nodes. Each worker node compare the version number of his replicas to the version number received from the cluster manager.
If the received version number is bigger, the nodes requires the new version from the cluster manager and updates his replicas.
We note that an update of a copy is propagated to all the other copies in a synchronous way, and no copy is accessible before it will be up to date.
The pessimistic algorithm is formalized as follows:
[htp] Pessimistic algorithm
Optimistic consistency management
The cluster managers try to ensure consistency between the various replicas of the same data of the Grid, which corresponds to make converge the replicas towards a reference replica for a Grid and it is founded on the optimistic approach of replication.
Periodically, each cluster manager (
If the received version number is bigger, the cluster manager requires the new version from
The optimistic algorithm is formalized as follows:
[htp] Optimistic algorithm
Simulation results
We have implemented the proposed approach on our own simulator developed in java.
Architecture and settings
As illustrated in Fig. 5, the simulation was constructed assuming that the Grid consists of several clusters each of which contains a number of worker nodes that may provide computational and data-storage resources for Tasks.
Basic architecture of our simulator.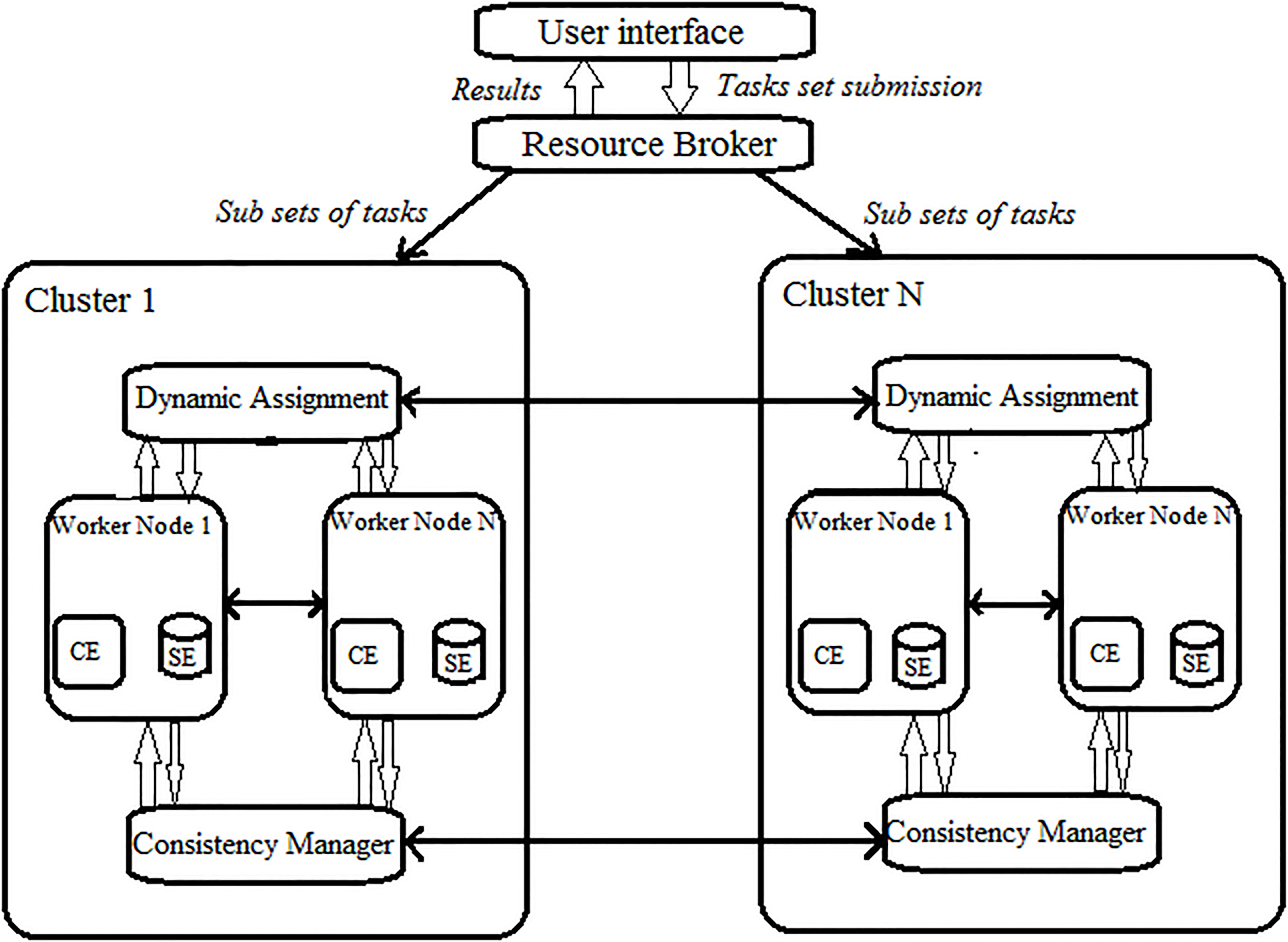
Each Worker Node contains one Computing Element and one Storage Element. A Resource Broker controls the static tasks assignment to Clusters. Clusters controls the static and dynamic tasks assignment and manages the consistency of replicas.
In the simulation Cluster Managers and Worker Nodes are represented by threads. the Resource Broker is another thread witch manage the tasks submission (Static tasks assignment).
At any time, a Computing Element will be running at most one task from his tasks queue.
The storage Element contains a set of files; files are accessed by reading or writing.
The experiments were performed on a Core i3 CPU 2.67 Ghz, with 4 GB of memory and running on Windows 7.
As performance measures we are interested in:
Represent the some of the average response time of each tasks divided by the number of tasks.
Represent the number of non-updated replicas (the version number of a replicas is different from the maximum version number).
Represent the difference between the maximum version number and the minimal version number of each replicas divided by the number of replicas.
Average response time of tasks by varying the tasks number (for 6 clusters).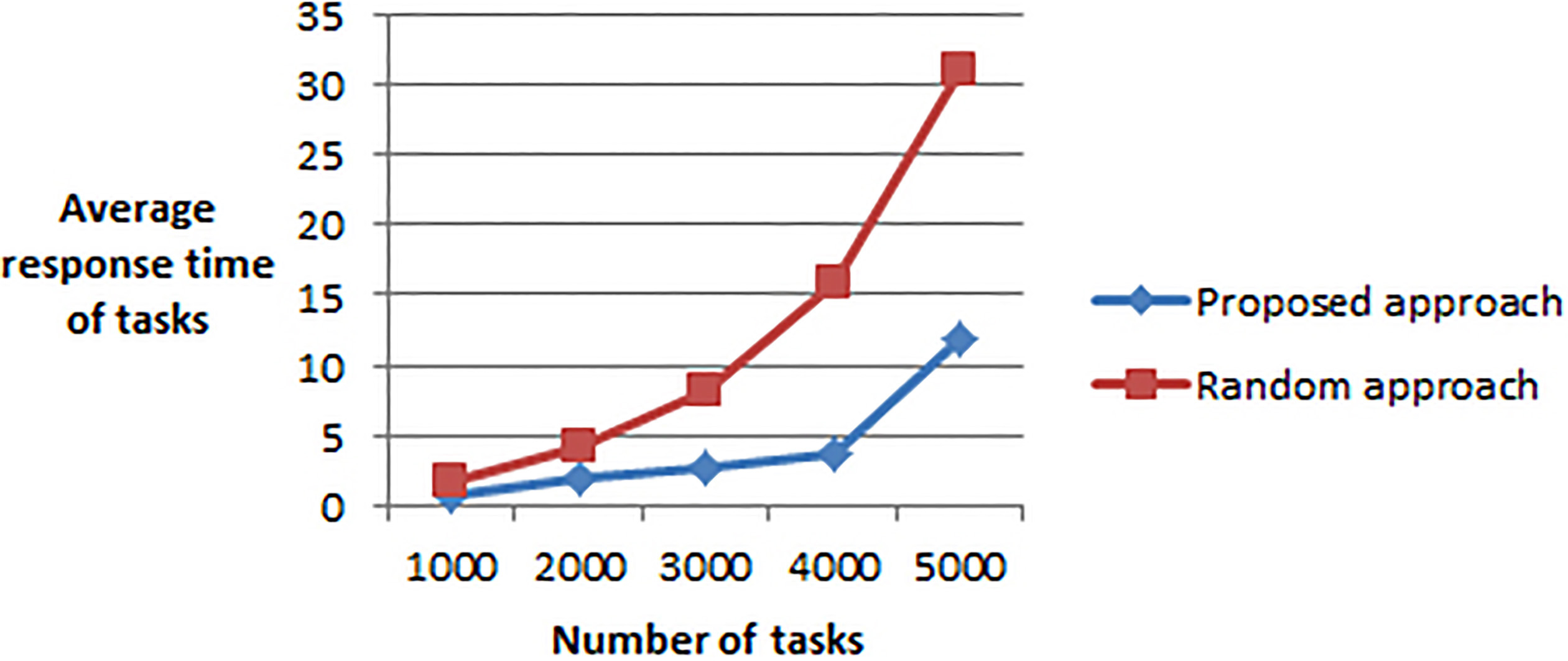
Average response time of tasks by varying the clusters number (for 3000 tasks).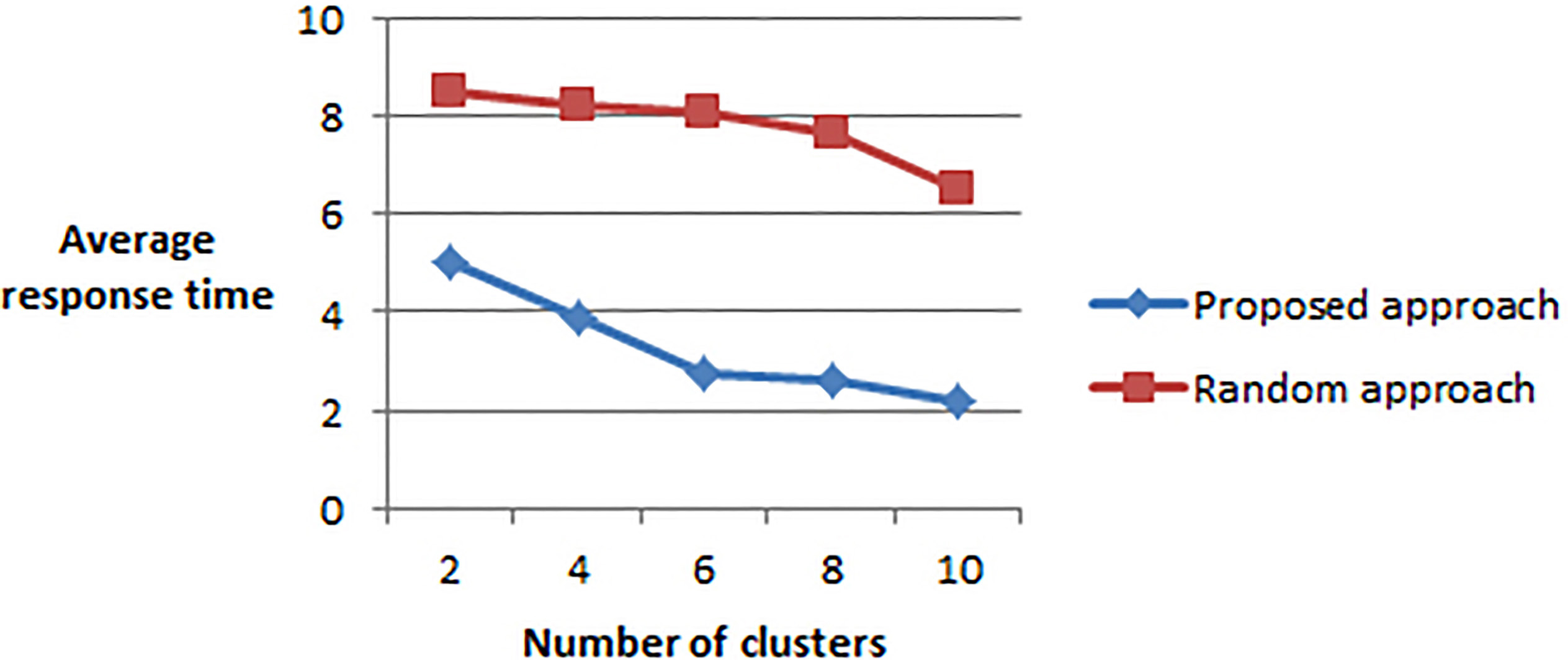
For the needs of our experiments, we have randomly generated nodes capabilities, tasks and files parameters.
After many evaluation tests, various thresholds were set to:
For each node we randomly generate associated speed varying between 5 and 30 MIPS.
We also generate randomly tasks dependencies.
Tasks length is between 1000 et 100000 MI (millions d’instructions).
The worker nodes tasks queue capacity is between 200000 and 100000.
files are distributed randomly.
The type of tasks is generated randomly.
In this experiment, we are studying results about the average response time of tasks, according to various numbers of tasks and clusters.
We have taken the clusters number from 2 to 10 by step of 2. For each cluster we generate randomly from 10 to 50 worker node.
The tasks number has been varied from 1000 to 5000 by step of 1000.
The initial number of files in the grid is 10.
Figures 6 and 7 show the results of our approach compared to a complectly random approach (random assignment in stage 0 and 1).
Compared to the random approach, the results of our strategy are butter since the average response time of tasks is significantly reduced.
When increasing the tasks number, response time benefits increase.
We observe also that when increasing the clusters number, response time benefits decrease.
Experiment 2: Number of conflicts
The count of conflicts is a very important metric in the evaluation of our strategy; it allows us to evaluate the effectiveness of the adopted consistency management approach.
First, we variate the number of tasks from 1000 to 5000 by step of 1000 for six clusters.
We count and compare the number of conflicts of the proposed approach and a totaly optimistic approach. The number of files is equal to 5 initially.
Number of conflicts by varying the tasks number.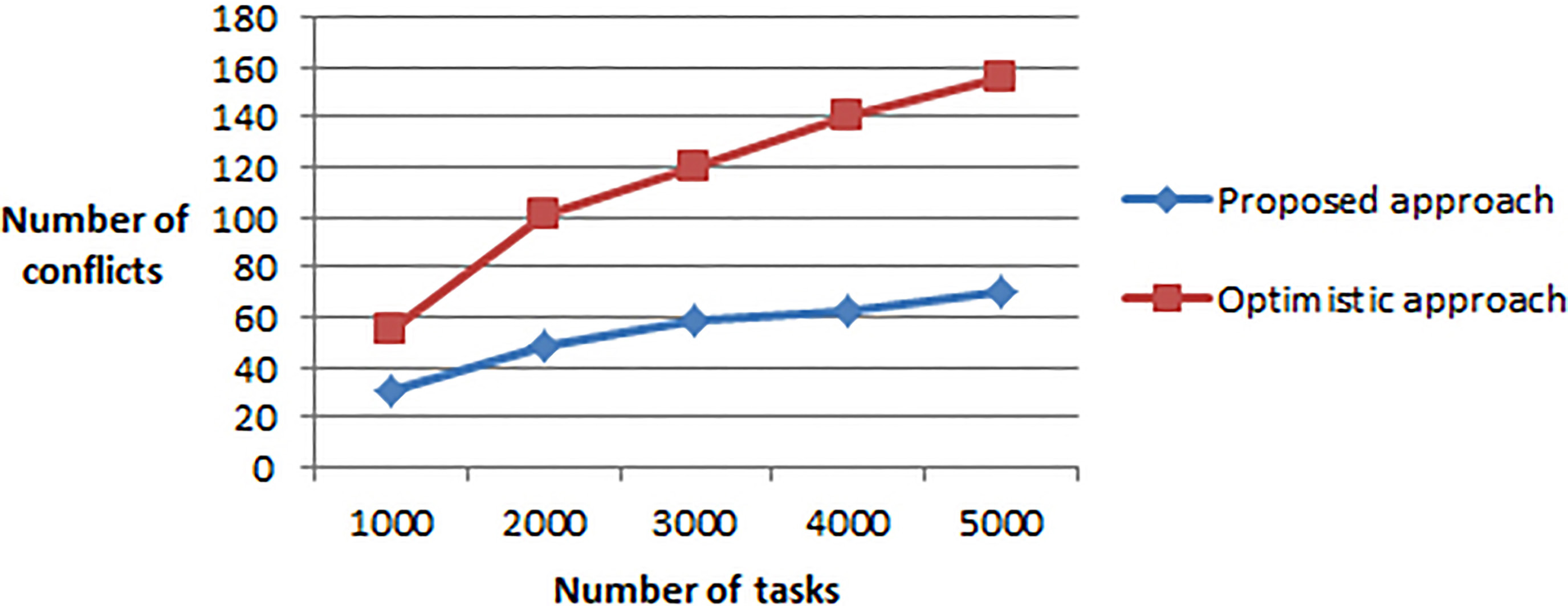
Number of conflicts by varying the clusters number.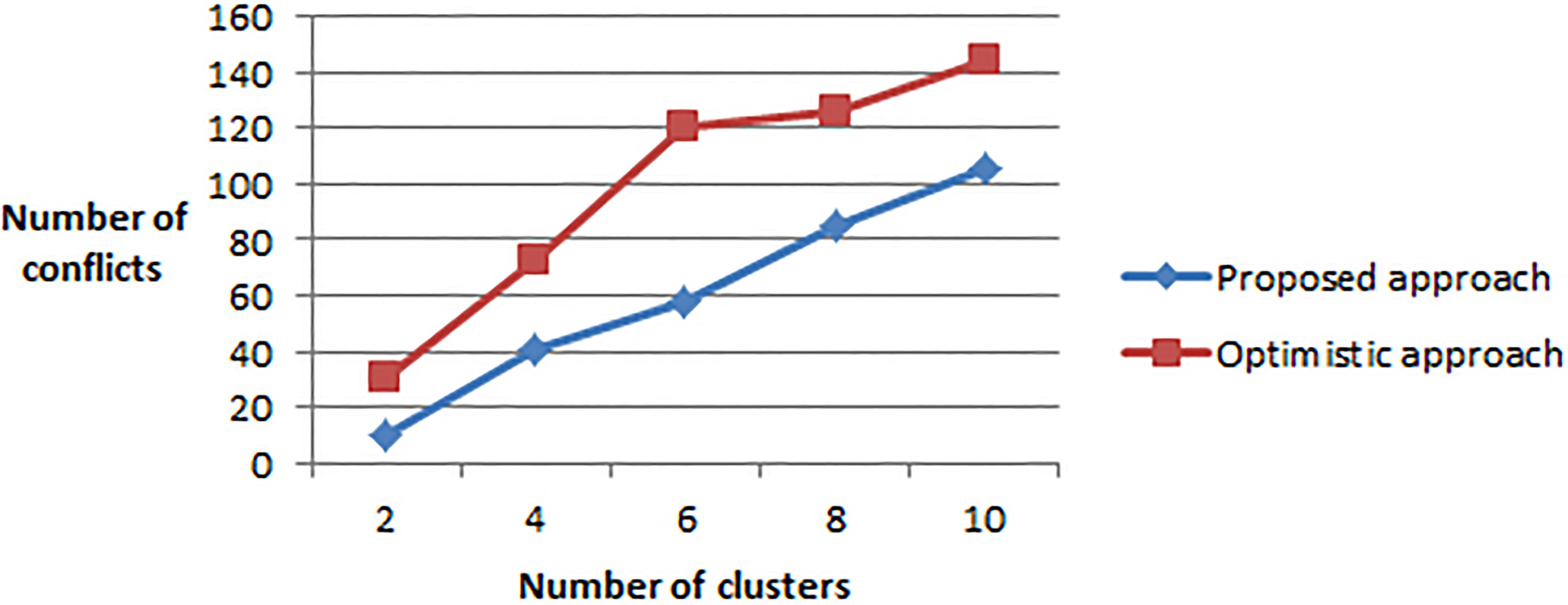
We notice in Fig. 8 that the number of conflicts increases by increasing the number of tasks.
Our approach gives better results than optimistic approaches since it reduces considerably the number of conflicts.
We also note that by increasing the number of tasks, the gap between the two approaches increases which proves that our approach will be much better if we move to a larger number of tasks.
We note in Fig. 9 that by increasing the number of clusters our strategy always gives better results than the optimistic approach.
However, we note that the difference between the two approaches is not as important as in the previous results. Since update propagation takes more time at stage 1 of the model when the clusters number increases.
This experiment calculate the distance of conflicts in our approach and compare the results with a totally optimistic approach.
Figure 10 shows that the distance of conflicts is very significant in the optimistic approach compared to our strategy.
Discussion
The originality of our paper is that it deals with a double problematic. On the one hand, the problem of dependent tasks assignment and on the other hand, the problem of replicas consistency in grids.
Distance of conflicts by varying the tasks number.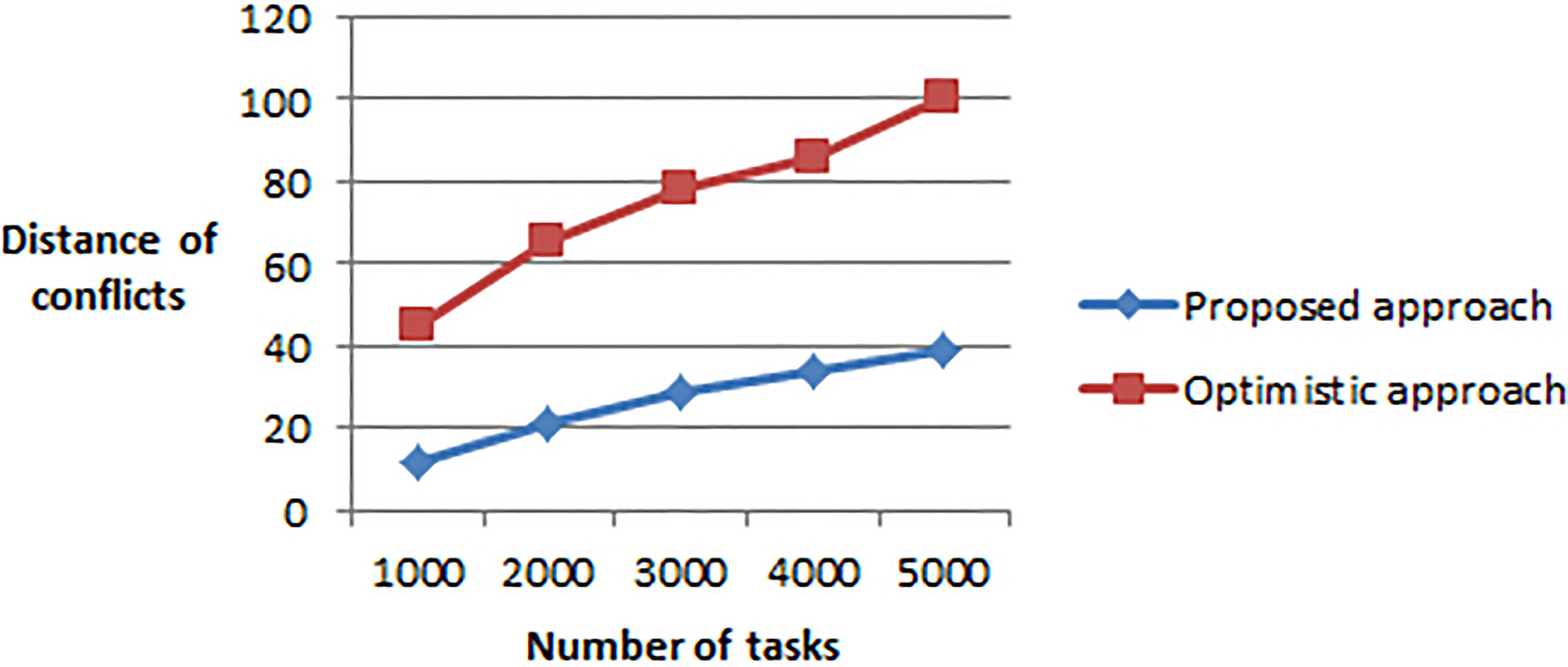
Concerning the assignment problem, we propose to duplicate some tasks if needed.
Compared to the works presented in Section 2.1, our work integrate a Replicas Manager that Creates or Removes Replicas if Needed. This decision is based on the assignment algorithm.
The works presented in Section 2.1, do the same thing but, do not consider that tasks submitted to the grid can modify certain replicas that create a problem of inconsistency.
This what makes our work original comparing with the existing works.
Authors in [21] propose a task placement and selection of data consistency mechanisms for real-time multicore applications.
Our work is related to this dual problem in a large scale environment.
Our Strategy doesn’t take into account, the fault tolerance in grid computing.
In this work, we realize a process of tasks assignment and data consistency management by replication of some Tasks and Data.
Our main goals are: (a) Reducing, whenever possible, the average response time of tasks submitted to the grid, (b) Respecting the constraints of dependency between tasks, (c) Managing data consistency, and, (d) Reducing communication costs.
Our strategy consists of four phases; two phases for tasks assignment (Static and Dynamic) and two phases for data consistency management (Pessimistic and optimistic).
To highlight the proposed strategy, we conducted a series of experiments by varying different parameters such as clusters with different characteristics, a set of dependent tasks and variable number of replicated files.
We used also a set of metrics such as the response time, number of conflicts of data and distance of conflicts. The proposed approaches, is able to manage the data consistency and minimize response time of tasks.
For a continuation of our work, we want to: (i) integrate our process in Griddsim [3] simulator, (ii) Define other metrics of performance to evaluate our strategy, (iii) Compare our approach with other existing works, and, (iv) We plan also to integrate our strategy to the middleware GLOBUS [5].
Footnotes
Authors’ Bios