
Abstract
Today, data replication is widely used in large-scale systems such as data grids to meet the requirements and challenges of managing these huge amounts of data. Indeed, replication is used to reduce the data access cost and access latency, to improve availability and performance, and to ensure reliability in grids. Most proposed replication strategies deal read-only case when accessing data, few approaches studies data consistency when the updates are allowed in data grids. In this paper, we present a contribution using a quorum-based management of replicas approach to maintain the consistency of these replicas, whose goal is to minimize quorum sizes to decrease replication costs and improve performances.
Introduction
Replication is a technique widely used by distributed systems on a medium and large scale, for database communities and even for grid communities. However, the grid environment presents different challenges, such as reduced latency and the availability of dynamic resources [10]. Given the complexity of such an environment, it is very difficult for a human to make decisions about data management especially about those that need to be replicated. To this end, the solicitation of good replication strategy is required (for the right placement of replicas to improve performance). However, replication strategies introduce an additional load related to the management of these replicas and especially to the consistency (of replicated data) that must be assured and maintained. The basic principle for maintaining the consistency of replicated data is to require the locking of at least one common copy for conflicting operations (reads/writes) [25]. Different replication protocols have been proposed to ensure consistency of replicated data. The simplest solution is ROWA (Read One Write All); where one copy is sufficient for a read operation while all copies are required to successfully perform a write operation. Another protocol known as Quorum Consensus (or majority vote) was suggested; where a write quorum (number of copies) is required to perform a write operation, and a read quorum is required to perform a read operation. All quorum-based protocols aim to minimize sizes of quorums in order to reduce data access costs. In this context, we contribute with a new replica management approach in data grid, based on quorums, to improve data access performance. This approach aims to minimize sizes of quorums by distributing the replicas of the grid into groups. To evaluate our approach, we compared it with two approaches (ROWA and Quorum Consensus approaches). The obtained results show that our approach significantly improves data access performance.
The rest of the paper is organized as follows. In the second section, some work related to data replication and to data consistency based on quorums will be presented. In section three, our approach will be presented. The results of the experiments will be discussed in section four, where our approach will be compared to the ROWA approach and the Quorum Consensus approach. Section five provides a comparative study of related work. The sixth section will be reserved for conclusion and future work.
Literature review
Replication strategies for data grids is an active research domain [1, 2, 5, 24]. These strategies are centralized, which makes them likely to be failing and can become a bottleneck when data requests increase. A common point of these strategies is that they only consider read-only cases to access the data. Therefore, these approaches are not suitable for applications where data replicas can be modified [9].
Few data replication techniques have focused on consistency in data grids [3, 16]. Some of them have used quorum-based protocols such as Quorum Consensus, Tree Quorum and Grid Quorum. These protocols are primarily intended for database systems [8]. They are considered (as well as ROWA protocol) the most popular in replica consistency management. Each protocol is mainly distinguished from the others by the number of replicas involved in performing a read or write operation.
The ROWA protocol (Read One Write All) [12] is a simple protocol. As its name indicates, it needs only one replica to read a data, but it requires all replicas to write a data.
The principle of the Quorum Consensus protocol [15] (also known as the majority vote) is based on suffrage (voting). In literature, the quorum is defined as the number of votes required for an election to be valid. Thus, since each data has several copies, we can apply this principle to modify or consult data. Therefore, the basic idea is to have the authorization of several copies (quorum) before performing read or write operation on a data. For example, for a data having
Let
A read operation on a data requires Qr votes to be able to perform it, and a write operation on a data requires Qw votes to be able to perform it,
In the Quorum Consensus protocol, the read and write quorums must satisfy the following constraints:
The first constraint guarantees the exclusion between a read operation and a write operation on a same data, while the second constraint guarantees the exclusion between two write operations on a same data.
The Tree quorum protocol [4] is based on a logical tree topology, the replicas are logically arranged in a tree structure. A write operation requires a quorum formed of the root, the majority of its children, the majority of the children of each of these children, and so on. Consequently, two simultaneous write operations will have at least one common replica at each level of the tree. The read quorum is formed of the root. If the root is not available, the quorum will be formed by the majority of its children. If one child of this majority is unavailable, he will be replaced by the majority of these children and so on.
In the Grid quorum protocol [23], the replicas are logically arranged in grid structure. The rectangular grid is the simplest form of the Quorum Grid. The
In order to improve the performances of a data replication protocol in large-scale systems, it is important not to overlook a few factors such as: the number of replicas used, the sites where replicas will be deposited, and how to maintain the consistency of these replicas.
In the following, we present other important works that have proposed data replication protocols based on quorums and that take into account some of the factors cited above to achieve their objectives.
In [8] the authors propose a new quorum-based data replication protocol in order to reduce the cost of data updates, to provide high availability and to maintain data consistency, with good response times and small read and write quorum sizes. They have developed an algorithm called DDG by logically decomposing the network into regions (zones). Each region groups the sites belonging to the same geographical partition. This decomposition is logically structured in a two-dimensional form. Where each line of this structure represents a region of the network, and the elements of the same row contain the geographically close sites. The DDG algorithm allows only one replica per region. The number of replicas for this approach should not exceed
In [14], a protocol named A2DS was proposed. It can be adapted to any two dimensional structure. The replicas are organized logically into any 2D structure (straight line, triangle, square, trapezoid, and rectangle). The authors introduce the new idea of obtaining other 2D structures (hexagon and octagon) by the composition of several basic 2D structures. In this protocol, a write quorum is formed of all replicas of any single level of the 2D structure, and a read quorum is formed of any single replica of every level of the 2D structure. Another protocol called ReadTwoWriteMajority was also proposed, where replicas are arranged logically into the rectangle structure for an even number of replicas, and are arranged logically into the trapezoid structure for an odd number of replicas. This protocol was proposed in order to bypass the drawbacks of ROWA protocol (write operations) and to preserve its advantages (read operations). The authors carried out a comparative analysis on the adaptation of these protocols on the different 2D structures.
The authors of [17] propose a data replication protocol named DR2M. This protocol organizes the nodes into a two-dimensional logical structure, they use voting technique to improve the availability and data access performance by reducing the number of replicas of data for read or write operations. The DR2M protocol uses quorums to organize nodes into clusters. It calculates the best number of quorums and the best number of nodes for each quorum. To replicate a data, the protocol selects the node located in the middle of the diagonal of the nodes of the structure.
The replication protocol presented in [18] is named TQR (Triple Quorum Replication). As its name indicates, this protocol is structured on the intersection of three quorums groups. It aims to reduce quorum sizes and maintain high data availability even when the network size increases. In this work, the authors have focused on the selection of copies to be replicated (which copy is selected to be replicated) by proposing a new replicas control strategy. In this approach some assumptions are made such as the number of nodes in a quorum, the similarity of read quorums and write quorums, and the same availability for both read and write operations.
The authors of [21] propose a new replication protocol called Dynamic Hybrid Protocol which combines between the grid quorum protocol and the tree quorum protocol. A logical tree structure is used for this protocol, it is composed of the two logical structures of the grid quorum and the tree quorum. It is a topology based on three configuration parameters (tree height, grid depth and number of descendants). The authors indicate in their analytical study that in order to obtain high write availability, we must reduce the height of the tree and the depth of the grid, and we must increase the number of descendants. However, in order to obtain high read availability, we must reduce the height of the tree and the number of descendants and we must increase the depth of the grid.
In [22], the authors propose a dynamic load-balancing strategy based on the quorum system to improve the performance of replicas consistency. Nodes containing replicas are represented in a binary tree logical structure. To maintain data replicas consistency, when a read or write access request is addressed to a replica, a quorum is formed from the tree by the path from the root to a tree leaf. To improve performance, the authors complement replica consistency by a load balancing strategy according to the state of each quorum node. This strategy is based on the permutation between the nodes of the quorum sets in order to reduce the load and the communication time of read or write access requests.
The number of replicas, the consistency of these replicas, and the nodes that contain the replicas are very important concepts for designing and developing a replication strategy.
In addition, if replication strategies are dynamic and quorum-based, quorum values (quorum sizes) must be calculated every time the number of replicas changes. This operation is very costly especially on a large scale (data grid). This influences the system performance such as response times.
In this context, and in order to minimize the cost and to improve replication performance we contribute by a new replica management approach named Imbricated Quorum (IQ), which is based on the formation of groups of quorum.
Principle
In a data grid, a dynamic replication strategy moves, adds or deletes the replicas dynamically. Adding and removing replicas inevitably influence quorum values (quorum sizes). Therefore, these values must also be managed dynamically.
However, the dynamic definition of quorum sets is costly. Because each time the number of replicas changes, the read and write quorums values must be recalculated, before any new read or write operation. Therefore, the problem is to minimize the number of these calculations. Which leads us to reduce the quorum sets sizes. For this, we reduce the number of replicas involved in a quorum by distributing replicas in groups. Consequently, the number of replicas involved in read or write operations is reduced.
Let
Example of distribution of replicas in groups.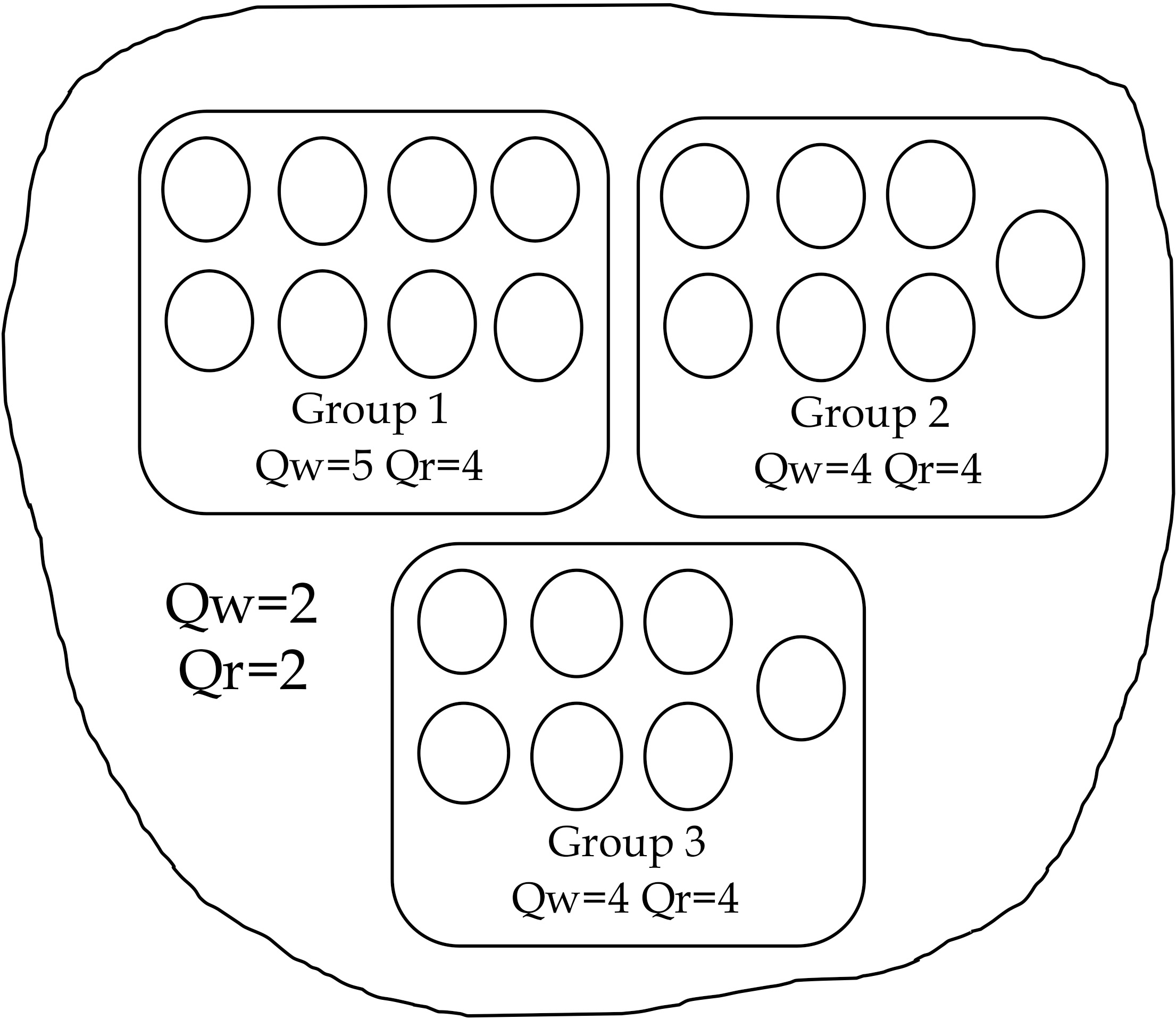
For example, in Fig. 1, the total number of replicas
Group 1 contains 8 replicas and each of groups 2 and 3 contains 7 replicas. By applying Quorum Consensus, the read quorum value Qr
On the other hand, the updating cost of the quorum values is reduced if the number of replicas changes. For example, if one replica is added to Group 1, only the quorum values of this group will be updated (Qr
In the following, we define the quorum sizes of our approach (Imbricated Quorum).
We will use cluster term instead group term.
Below are some notations to be used.
Nclt: the total number of clusters in the grid such as Nclt
rep_clt
QCw: write quorum of grid (applied on clusters).
QCr: read quorum of grid (applied on clusters).
Qw
Qr
Quorums obtained by applying Imbricated Quorum are:
Write quorum on clusters concerned by a write access is:
Read quorum on clusters concerned by a read access is:
Write quorum on replicas of cluster
Read quorum on replicas of cluster
Global write quorum of Imbricated Quorum (quorum on the replicas of the whole grid) is:
Global read quorum of Imbricated Quorum (quorum on the replicas of the whole grid) is:
We will show that the quorum sizes obtained by our approach (Imbricated Quorum) are better than those obtained by Quorum Consensus.
We have:
Write quorum of Quorum Consensus is:
Read quorum of Quorum Consensus is:
Nclt
For write quorum,
Then the write quorum size of Imbricated Quorum is less than that of Quorum Consensus.
For read quorum,
Then the read quorum size of Imbricated Quorum is less than that of Quorum Consensus.
To form the groups of replicas, we first distribute all the nodes of the grid in groups. In distributed systems, there are several methods for grouping a set of nodes and for determining the leaders of these groups [7, 11, 13, 20, 19]. They can be based on different metrics such as network latency, bandwidth, free storage space, neighbourhood, availability
Since node availability is a very important parameter in the grids and to improve performance, in our approach we propose a grouping method based on the availability. The formation of groups by this method is done on basis of the availability of the nodes, where the most available node is likely to be the leader of its group. Each grid node has a value that indicates its availability. The node that has the highest availability value is selected. In case of equality between several nodes, the node with the smallest identifier will be selected.
This grouping is performed independently of the replicas and their placements (grouping of all nodes of the grid and not of the replicas).
This task is performed in three steps:
For example, for node 0 (see Fig. 2 and Table 1), the most available node among all nodes {0, 3, 9} is node 3, since its availability equals 70% among {35%, 70 %, 68%}.
When this step is completed for all the nodes of Fig. 2, we will obtain the results of Table 1.
Set of nodes and their chief
Set of nodes and their chief
Set of nodes and their leader
Example of grouping based on availability.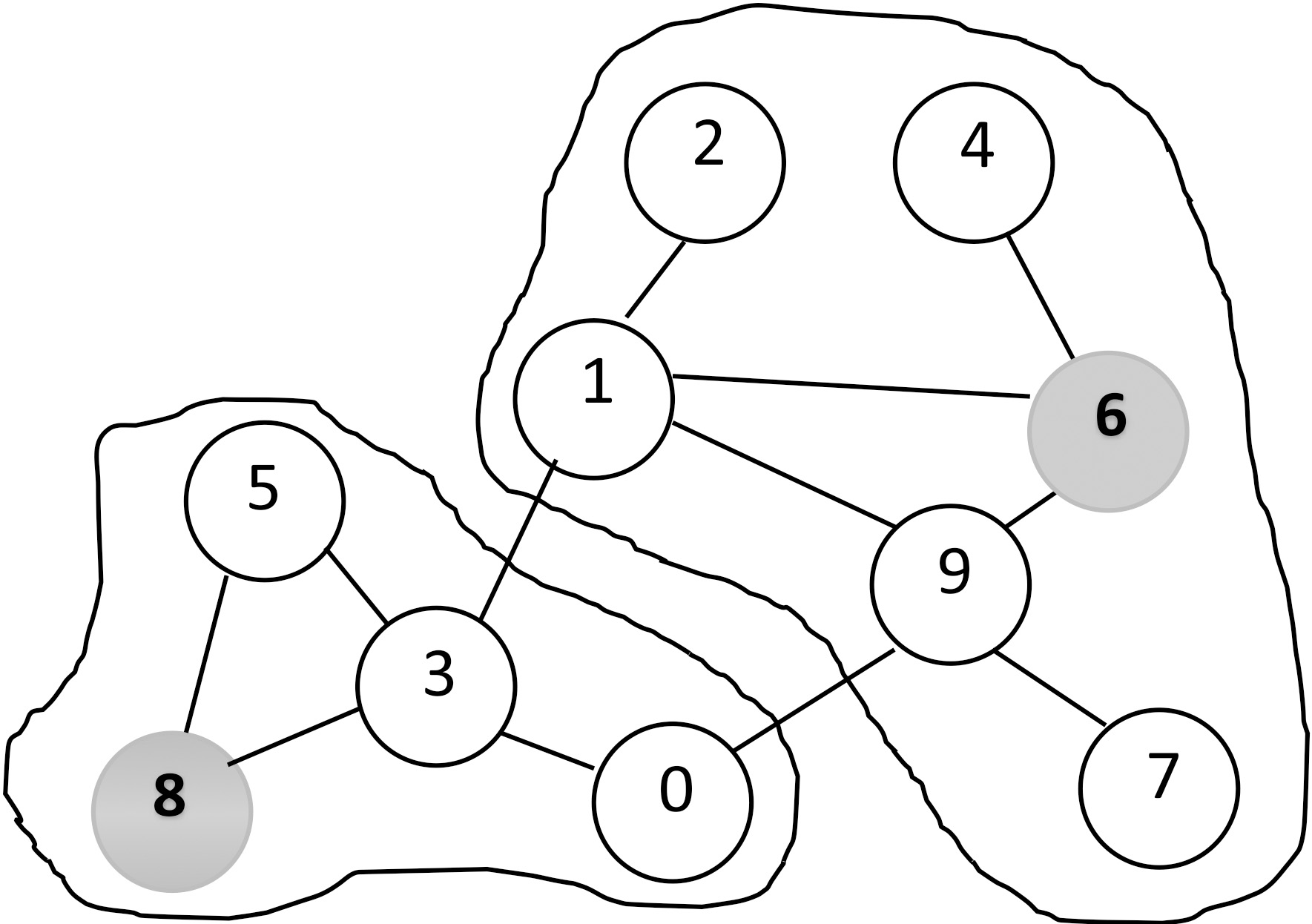
For example, the chief of node 0 is 3, node 3 points at 8 and 8 is the chief of itself. Thus, the leader of node 0 will be node 8, and so on.
When this step is completed for all the nodes, we will obtain the results of Table 2.
The number of formed clusters will equal to the number of obtained leaders (see Fig. 2).
This method favours the most available nodes, which improves the data availability in grid if these nodes possess replica.
Algorithm 1 describes the availability-based grouping method.
The runtime complexity of this algorithm is
Each time the number of replicas is changed (adding or deleting replicas), the quorum sizes of Quorum Consensus protocol must be updated for the entire system. However, in our approach, quorum updates will only be done within the cluster where the number of replicas has changed.
The formation of quorums and query processing are performed by the cooperation of a set of agents, where we assign to each cluster an agent that will represent its leader (called intra-cluster agent), in addition to an agent that coordinates tasks between the different clusters (called inter-cluster agent). Each intra-cluster agent will have a global view of its cluster (see Fig. 3), and the inter-cluster agent will have a global view of the data grid (of all clusters of the data grid).
Diagrammatic representation of grid environment including nodes, clusters, agents.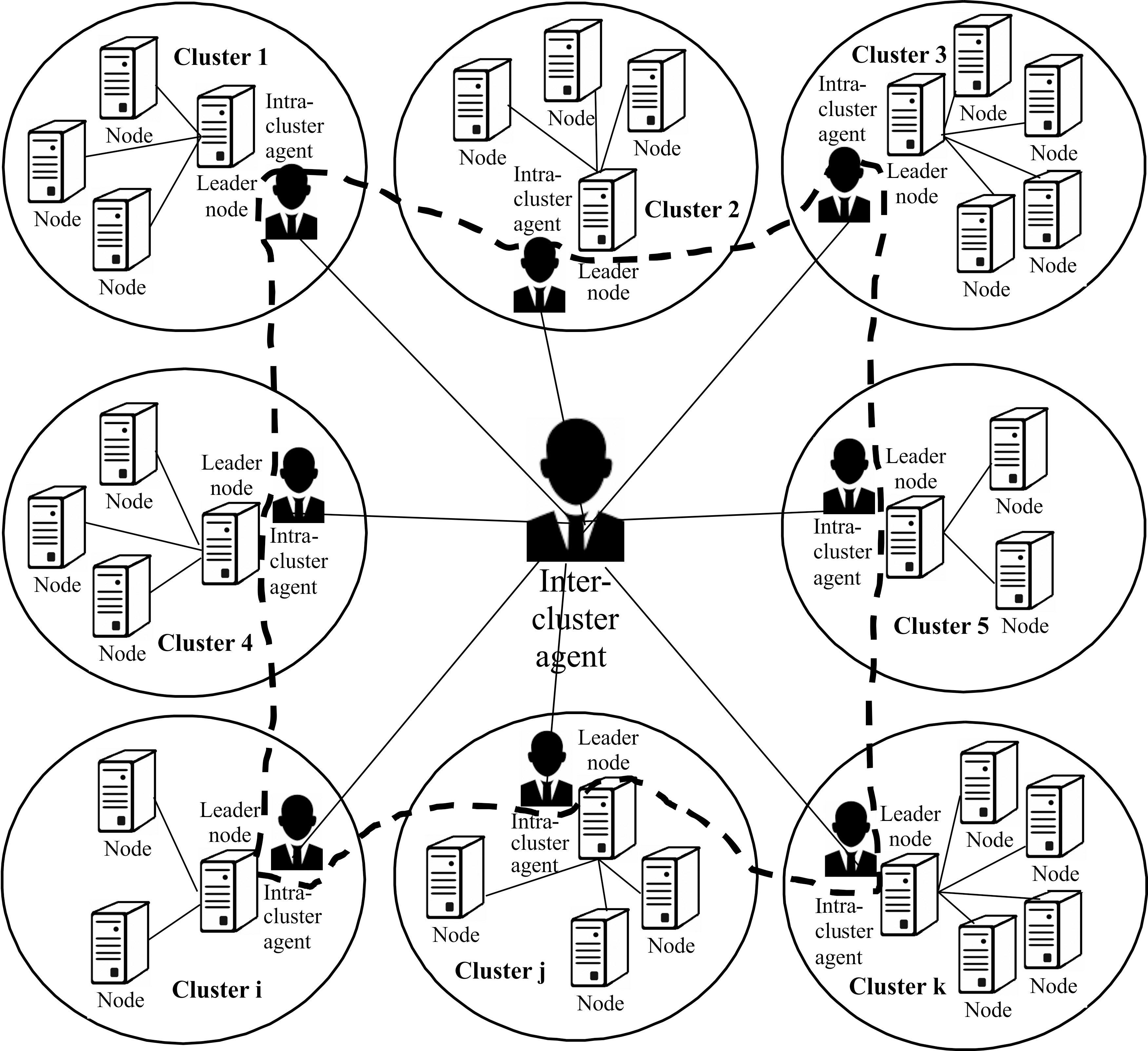
Thus, we distinguish two types of agents:
Clusters formation. Update read and write quorum sizes of grid (if necessary in case the cluster number changes) by applying Eq. (1) or Eq. (2). The locking and unlocking of the leaders nodes involved in a quorum when accessing replicas (read/write). Diffusion of updates to leaders in case of a write operation.
Each replica of a data in the grid has a version number used to determine the most recent replica. When a node requests read or write access to a data, a query that asks for the version numbers of the different replicas is formulated first. When the most recent replica is determined (having the highest version number), an effective access (read or write) is performed to the node possessing this replica (the most recent).
So, when a node requests access to a data, it sends request to its cluster leader. When its leader receives the request, the intra-cluster agent forwards it to the inter-cluster agent. The inter-cluster agent sends a query to each intra-cluster agent, asking it to determine the most recent replica in its cluster. Each intra-cluster agent determines the replica having the latest version, then sends the address of that replica and its version to the inter-cluster agent. The inter-cluster agent collects the responses from different intra-cluster agents, and when the quorum (applied on clusters) is reached, it determines the most recent replica in whole grid and it transmits the version number and address of this replica to the intra-cluster agent that issued the query (cluster agent of node that wanted to access the data). After the access operation is completed, each intra-cluster agent unlocks the locked replicas of its cluster, and the inter-cluster agent frees the locked leaders. In writing case, the update of the replicas and their versions (new versions) must be achieved before unlocking.
Activity diagram for cooperation between agents.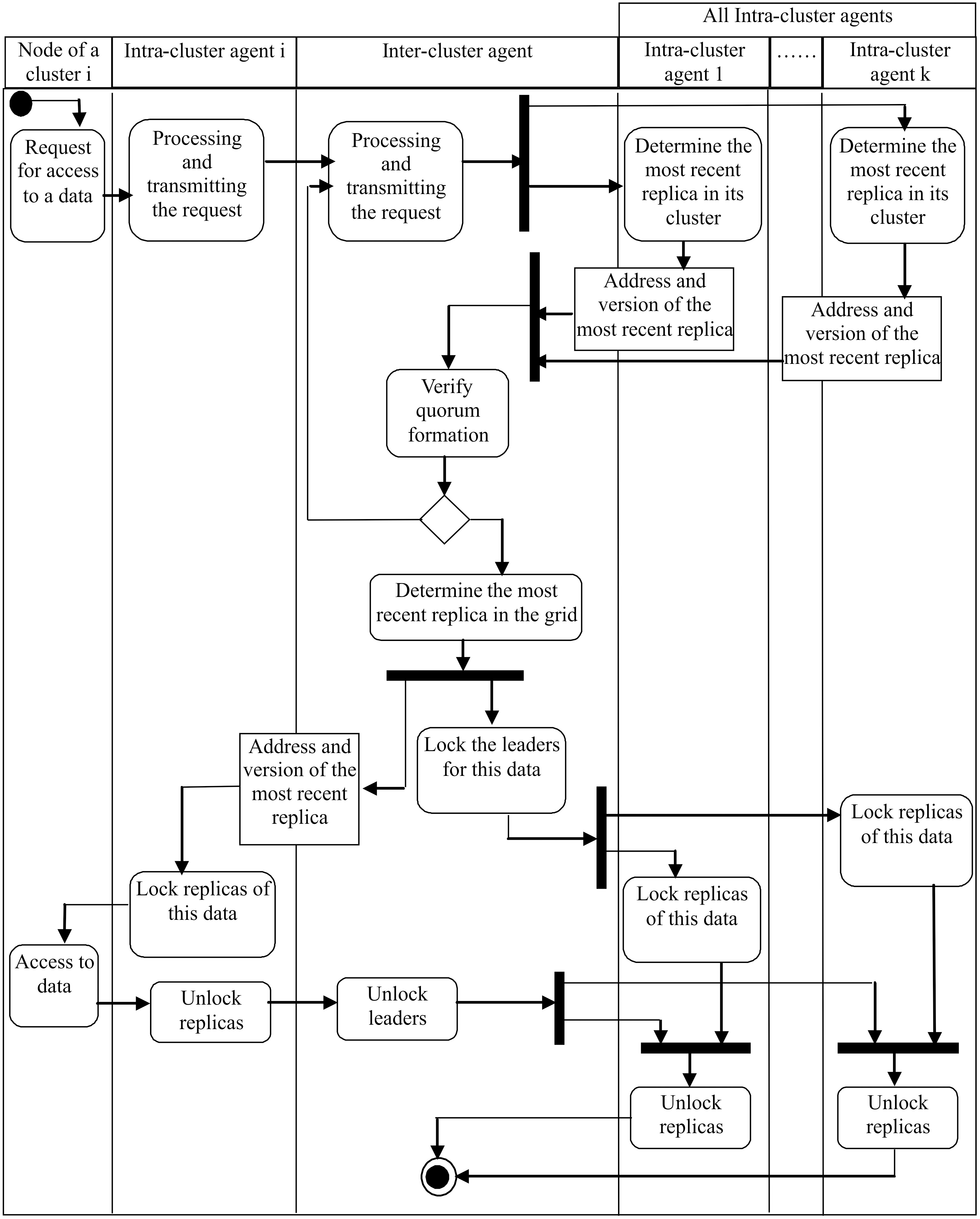
To locate the most recent replica in each cluster, each intra-cluster agent sends request to each node of its cluster which possess a replica, asking it the replica version and address. Then it collects the responses from different nodes, and when the quorum (applied on replicas of its cluster) is reached, it determines the most recent replica in its cluster and transmits the version number and address of this replica to the inter-cluster agent.
The activity diagram of Fig. 4 illustrates this cooperation between agents for responding to access request to a data sent by the node of cluster “i”.
Algorithm 2 describes the process to be executed by the agents to determine the most recent replica for a data access operation.
Algorithm 2 can be executed in two modes: either in intra-cluster mode by an intra-cluster agent or in inter-cluster mode by the inter-cluster agent.
In this algorithm, the word “element” is generic, it can represent: either a cluster node possessing a replica if the algorithm is executed in intra-cluster mode or a cluster leader if the algorithm is run in inter-cluster mode.
In the case of read access request, the variable
In order to improve performance, determination of the most recent replica as well as its address in a cluster can be performed asynchronously. Indeed, when a leader is free and not solicited, its intra-cluster agent can determine the most recent replica in its cluster.
To evaluate our approach, we used a simulator called “GREP-SIM” [6]. This simulator allows us to generate any tree hierarchical topology. We have modelled a tree topology inspired by the “CERN” data grid architecture.
In this simulator, each node in the grid is capable of specifying the performance of its processor, the locally replicated data, its storage capacity, and the detailed history of the requests passing through this node (the passage of a request by this node during its routing from a client to its serving node). We can also assign to each node other information, such as its availability.
During the simulation, the number of replicas does not remain fixed and changes, since in this simulator, replicas can be added, deleted and placed dynamically. This will allow us to evaluate our approach in a dynamic environment where the number of replicas changes, and compare it with two other approaches: the ROWA approach and especially the Quorum Consensus approach. The whole system of the grid will be influenced by the change of number of replicas with the Quorum Consensus approach, unlike our approach where only the cluster where the number of replicas has changed will be influenced.
We have extended this simulator by adding and integrating our IQ technique of replicas management (grouping of nodes, formation of quorums and queries processing).
Simulated grid model
Figure 5 shows a reduced example of the simulated grid topology. It consists of 12 nodes (one root and 11 intermediate nodes), and 12 leaves representing the clients. This simulator allows us to generate a tree topology with a large number of nodes (500 nodes in the simulation below). It also allows us to generate and distribute replicas of the different data.
Simulation results
The simulations were performed using defined parameters in Table 3.
Simulation parameters
Simulation parameters
Structure of the simulated grid.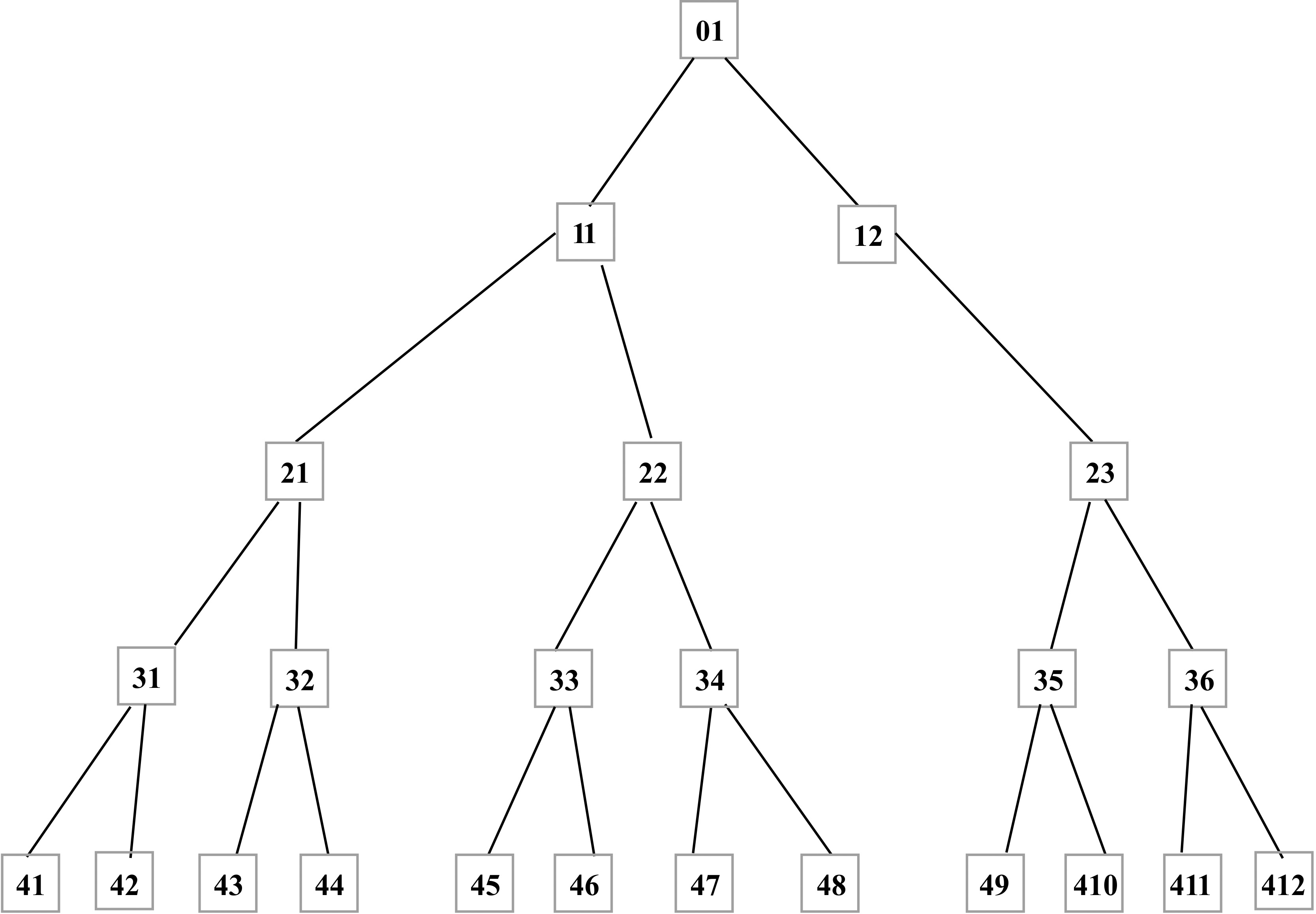
The simulator begins to form the clusters. Then, a random distribution of the replicas will be done. From this distribution and for the same chronological order of arrival of the client requests, the simulator calculates response times for each request (read or write), by applying the three replication protocols: ROWA, Quorum Consensus (QC) and Imbricated Quorum (IQ). Thus, we can compare our protocol to the other two protocols.
The results obtained and modelled by the graph of Fig. 6 represent the average response times of some clients (first 14 clients). It shows that performance is clearly improved by using our approach. Indeed, we note a decrease of 39.85% of the IQ average response time compared to ROWA and 23.71% compared to QC.
Average response time per client.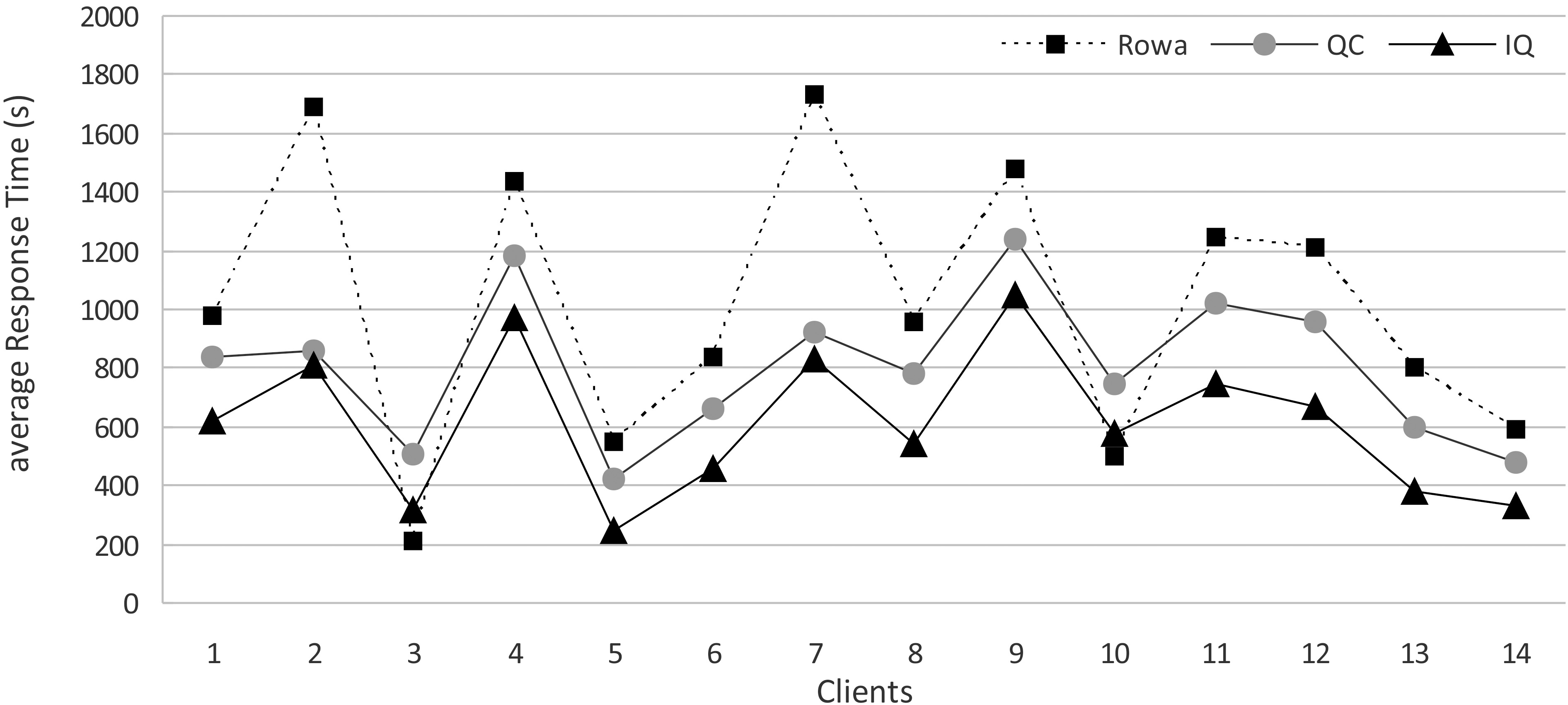
Average response times per number of replicas.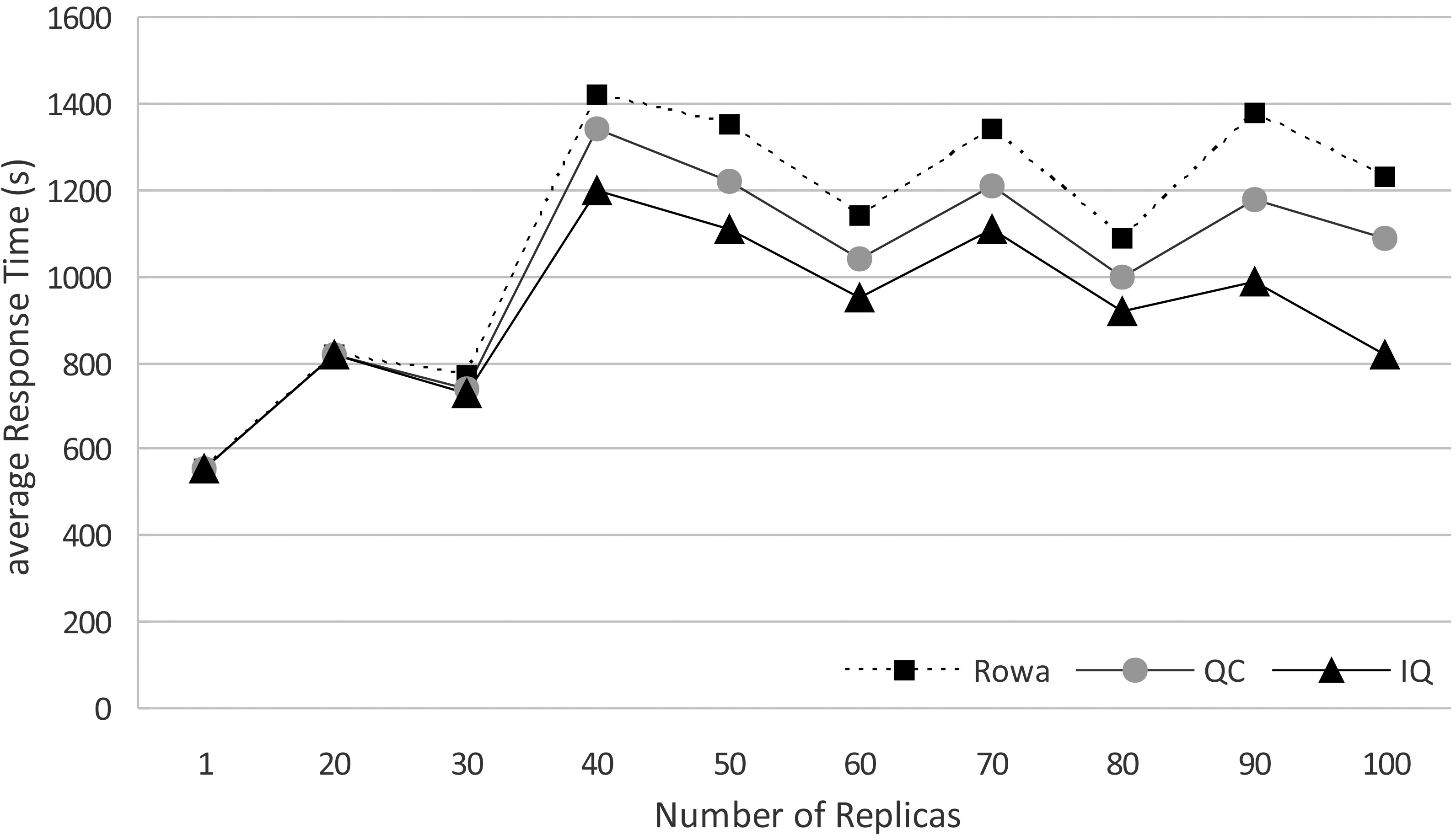
The best response times for clients 3 and 10 are obtained by ROWA protocol, because these clients have issued a negligible number of write requests in relation to the number of read requests.
(a) Average response time per request type; (b). Average response time per request type; (c). Gap between average response times per request type.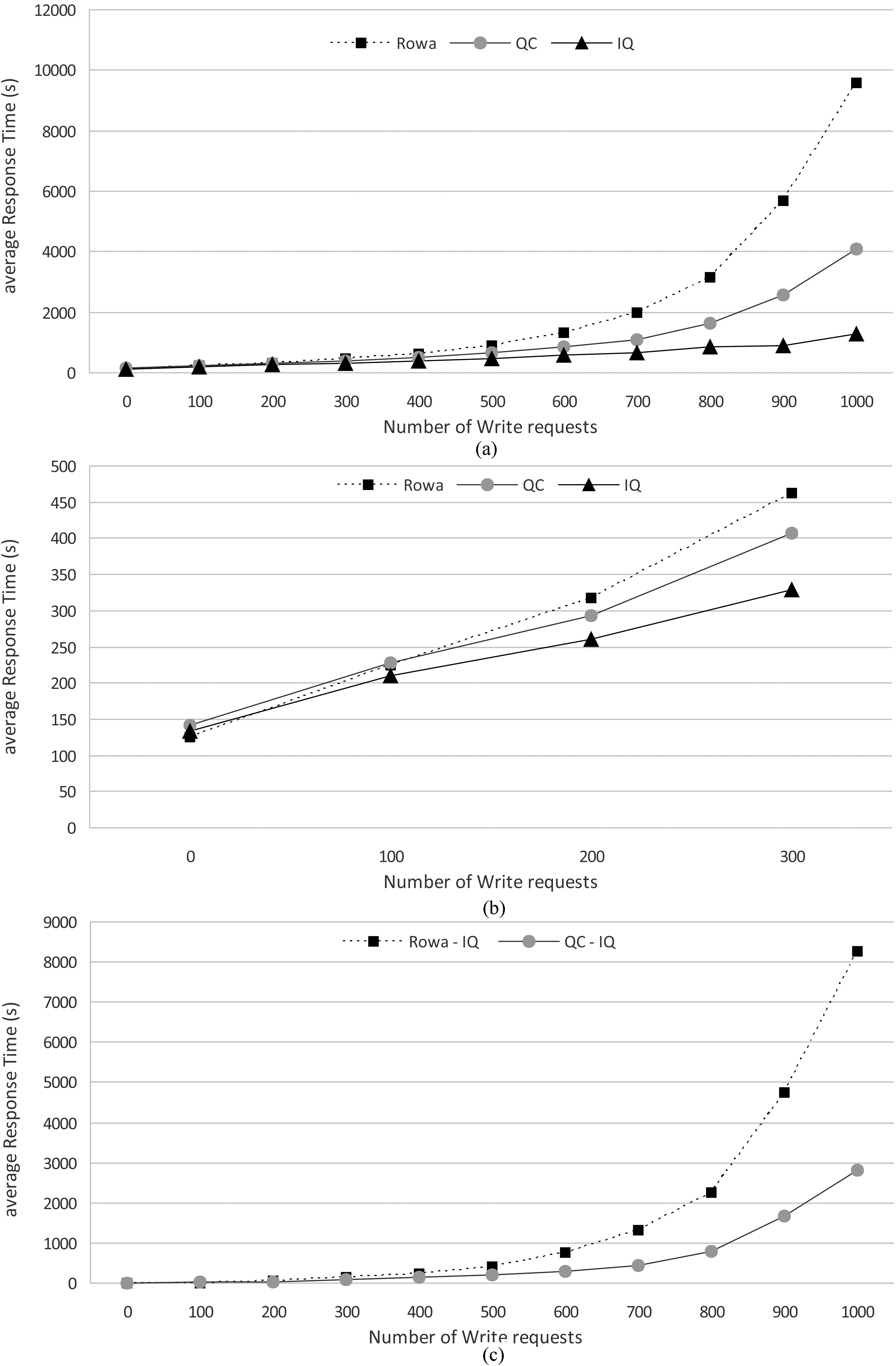
The results obtained and modelled by the graph of Fig. 7 represent the average response times per number of replicas. It shows that our approach significantly improves performance. IQ average response time is 17.07% less than ROWA, and is 9.71% less than QC.
The following results show where our approach is interesting. The results illustrated by Fig. 8a represents the average response times per number of write requests (number of write requests among 1000 requests). IQ approach improves average response times by 75.38% compared to ROWA approach, and by 51.98% compared to QC approach.
Figure 8b (detailed in Fig. 8a) shows that if number of write requests is very small (almost zero), ROWA approach is better than IQ approach, but IQ approach is always better than QC.
We also note that our approach is better than the other two approaches since the gap between the average response times of IQ and of the other two approaches (ROWA and QC) increases rapidly when the number of write requests increases. This gap is almost linear as illustrated in Fig. 8c.
In the following, based on the literature review of Section 2, we summarize a critical study of the main related works.
We start with the two approaches with which we compared our approach in simulation.
The strength of the ROWA protocol [12] is the reliability of the read operations. Its advantages are low costs and high availability for read operations. However, its drawbacks are high costs and none fault tolerance for write operations, since all replicas must be updated for each write operation (failed to update only one replica causes the failure of entire write operation).
In case writing, the Quorum Consensus protocol [15] improves costs and offers greater availability. However, in case of reading the costs are higher because of the number of copies involved in the operation.
With these two approaches and especially with the Quorum Consensus approach, the whole system of the grid will be influenced by the change of number of replicas, unlike our approach where only the cluster where the number of replicas has changed will be influenced. When the number of replicas is changed, the quorum sizes of Quorum Consensus protocol must be updated for the whole system. However, the quorum sizes in our approach must be updated only within the cluster where the number of replicas has changed.
Other points can also be noted for the following proposed approaches.
In [8], since the proposed replication algorithm is limited by the number of replicas, it can only replicate data in very few places, which represents a limit for this approach, because it provides low availability especially in the case where sites possessing replicas fail.
In [14], the authors carried out a comparative analysis on the adaptation of the two proposed protocols on the different 2D structures and did not experiment them to see these performances in terms of response times.
In [17], the authors studied and experimented only the performances of the availability and they neglected the performances of the response times and the consistency costs.
In [18], the proposed approach is limited by several assumptions (number of nodes in a quorum, the similarity of read quorums and write quorums, and the same availability for both read and write operations). These authors also studied and experimented only the performances of the availability and they neglected the performances of the response times and the consistency costs.
In [21], the authors only studied their protocol on a reduced number of nodes, and no precision were given on the large scale.
In the proposed approach in [22], the number of replicas is fixed since the system is assumed to be static during the application of the proposed simulation algorithms.
Like these related works, our approach is based on quorums. And like these works, our approach aims to minimize the quorum sizes.
However, in these works as noted above, the following three points are not considered at the same time, namely the number of replicas, the scaling, and the response time performance. In our work, we take into account these three points. Indeed, we have proposed a replicas management approach in large-scale distributed systems (such as data grids), where the number of replica vary (not fixe), and which aims to improve performance by decreasing quorum sizes.
Conclusion and future work
In this work, we contributed to the replicated data management in data grids. We designed a quorum-based approach. This approach, called Imbricated Quorum, has been formulated with the aim of minimizing the read and write quorum sizes, to minimize the number of replicas involved in read or write operations, based on the distribution of all replicas of the grid into groups.
The simulated data grid is logically modelled by a tree architecture. Our approach was compared to ROWA approach and Quorum Consensus approach.
The results obtained show that our approach (Imbricated Quorum) improves data access performance in large-scale systems such as data grids. Indeed, these results show that our approach is considerably better than the other two approaches (ROWA and QC), since the quorum size in IQ is significantly lower than the other two approaches. These results are based on specific working environments, nevertheless, they are promising.
In the future, we project to extend this work in several directions. In the near future, it is envisaged to discuss the contribution of clustering to our approach. We plan to enrich our approach by the principle of collaboration and distributed negotiation between agents. We will also look at the study of availability, the addition of the notion of weighted votes and even the study of load balancing to improve performance. Finally, we project to validate our proposed approach on real data grids.
Footnotes
Authors’ Bios